







概述
简而言之,机器学习模型使用输入数据并产生预测。预测的质量直接对应于您训练模型的数据质量;垃圾进,垃圾出。查看这篇文章,了解在哪里使用 AI 以及如何正确应用它。
我们将通过具体的代码示例和一些合成数据来训练我们的模型。任务是根据白细胞(白细胞)计数和血压确定肿瘤是良性(无害)还是恶性(有害)。这是我们创建的合成数据集,没有临床相关性。
设置
我们将为可重复性播下种子。
import numpy as np
import randomSEED = 1234# Set seed for reproducibility
np.random.seed(SEED)
random.seed(SEED)完整数据集
我们将首先用整个数据集训练一个模型。稍后我们将删除数据集的一个子集,并查看它对我们模型的影响。
加载数据
import matplotlib.pyplot as plt
import pandas as pd
from pandas.plotting import scatter_matrix# Load data
url = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors.csv"
df = pd.read_csv(url, header=0) # load
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df.head()| 白细胞计数 | 血压 | 肿瘤类 | |
|---|---|---|---|
| 0 | 15.335860 | 14.637535 | 良性 |
| 1 | 9.857535 | 14.518942 | 恶性的 |
| 2 | 17.632579 | 15.869585 | 良性 |
| 3 | 18.369174 | 14.774547 | 良性 |
| 4 | 14.509367 | 15.892224 | 恶性的 |
# Define X and y
X = df[["leukocyte_count", "blood_pressure"]].values
y = df["tumor_class"].values
print ("X: ", np.shape(X))
print ("y: ", np.shape(y)) X: (1000, 2)
y: (1000,)
# Plot data
colors = {"benign": "red", "malignant": "blue"}
plt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], s=25, edgecolors="k")
plt.xlabel("leukocyte count")
plt.ylabel("blood pressure")
plt.legend(["malignant", "benign"], loc="upper right")
plt.show()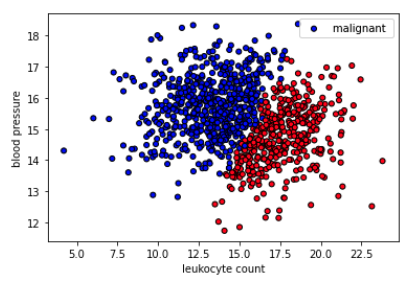
我们希望为我们的任务选择具有强预测信号的特征。如果你想提高性能,你需要通过收集和添加新信号来不断地做特征工程。因此,您可能会遇到与现有特征具有高度相关性(正交信号)的新特征,但它可能仍具有一些独特的信号来提高您的预测性能。
# Correlation matrix
scatter_matrix(df, figsize=(5, 5));
df.corr()| 白细胞计数 | 血压 | |
|---|---|---|
| 白细胞计数 | 1.000000 | -0.162875 |
| 血压 | -0.162875 | 1.000000 |
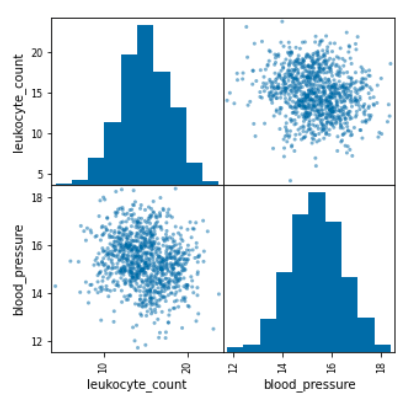
拆分数据
import collections
from sklearn.model_selection import train_test_splitTRAIN_SIZE = 0.70
VAL_SIZE = 0.15
TEST_SIZE = 0.15def train_val_test_split(X, y, train_size):
"""Split dataset into data splits."""
X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)
X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)
return X_train, X_val, X_test, y_train, y_val, y_test# Create data splits
X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(
X=X, y=y, train_size=TRAIN_SIZE)
print (f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print (f"X_val: {X_val.shape}, y_val: {y_val.shape}")
print (f"X_test: {X_test.shape}, y_test: {y_test.shape}")
print (f"Sample point: {X_train[0]} → {y_train[0]}")X_train: (700, 2), y_train: (700,)
X_val: (150, 2), y_val: (150,)
X_test: (150, 2), y_test: (150,)
Sample point: [11.5066204 15.98030799] → malignant
标签编码
from sklearn.preprocessing import LabelEncoder# Output vectorizer
label_encoder = LabelEncoder()# Fit on train data
label_encoder = label_encoder.fit(y_train)
classes = list(label_encoder.classes_)
print (f"classes: {classes}")classes: ["benign", "malignant"]
# Convert labels to tokens
print (f"y_train[0]: {y_train[0]}")
y_train = label_encoder.transform(y_train)
y_val = label_encoder.transform(y_val)
y_test = label_encoder.transform(y_test)
print (f"y_train[0]: {y_train[0]}") y_train[0]: malignant
y_train[0]: 1
# Class weights
counts = np.bincount(y_train)
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"counts: {counts}\nweights: {class_weights}")counts: [272 428]
weights: {0: 0.003676470588235294, 1: 0.002336448598130841}
标准化数据
from sklearn.preprocessing import StandardScaler# Standardize the data (mean=0, std=1) using training data
X_scaler = StandardScaler().fit(X_train)# Apply scaler on training and test data (don't standardize outputs for classification)
X_train = X_scaler.transform(X_train)
X_val = X_scaler.transform(X_val)
X_test = X_scaler.transform(X_test)# Check (means should be ~0 and std should be ~1)
print (f"X_test[0]: mean: {np.mean(X_test[:, 0], axis=0):.1f}, std: {np.std(X_test[:, 0], axis=0):.1f}")
print (f"X_test[1]: mean: {np.mean(X_test[:, 1], axis=0):.1f}, std: {np.std(X_test[:, 1], axis=0):.1f}")X_test[0]: mean: 0.0, std: 1.0
X_test[1]: mean: 0.0, std: 1.0
模型
import torch
from torch import nn
import torch.nn.functional as F# Set seed for reproducibility
torch.manual_seed(SEED)INPUT_DIM = 2 # X is 2-dimensional
HIDDEN_DIM = 100
NUM_CLASSES = 2class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, num_classes):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x_in):
z = F.relu(self.fc1(x_in)) # ReLU activation function added!
z = self.fc2(z)
return z# Initialize model
model = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)
print (model.named_parameters)<bound method Module.named_parameters of MLP( (fc1): Linear(in_features=2, out_features=100, bias=True) (fc2): Linear(in_features=100, out_features=2, bias=True) )>
训练
from torch.optim import AdamLEARNING_RATE = 1e-3
NUM_EPOCHS = 5
BATCH_SIZE = 32# Define Loss
class_weights_tensor = torch.Tensor(list(class_weights.values()))
loss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)# Accuracy
def accuracy_fn(y_pred, y_true):
n_correct = torch.eq(y_pred, y_true).sum().item()
accuracy = (n_correct / len(y_pred)) * 100
return accuracy# Optimizer
optimizer = Adam(model.parameters(), lr=LEARNING_RATE)# Convert data to tensors
X_train = torch.Tensor(X_train)
y_train = torch.LongTensor(y_train)
X_val = torch.Tensor(X_val)
y_val = torch.LongTensor(y_val)
X_test = torch.Tensor(X_test)
y_test = torch.LongTensor(y_test)# Training
for epoch in range(NUM_EPOCHS*10):
# Forward pass
y_pred = model(X_train)
# Loss
loss = loss_fn(y_pred, y_train)
# Zero all gradients
optimizer.zero_grad()
# Backward pass
loss.backward()
# Update weights
optimizer.step()
if epoch%10==0:
predictions = y_pred.max(dim=1)[1] # class
accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)
print (f"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}")Output:
Epoch: 0 | loss: 0.70, accuracy: 49.6 Epoch: 10 | loss: 0.54, accuracy: 93.7 Epoch: 20 | loss: 0.43, accuracy: 97.1 Epoch: 30 | loss: 0.35, accuracy: 97.0 Epoch: 40 | loss: 0.30, accuracy: 97.4
评估
import json
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_fscore_supportdef get_metrics(y_true, y_pred, classes):
"""Per-class performance metrics."""
# Performance
performance = {"overall": {}, "class": {}}
# Overall performance
metrics = precision_recall_fscore_support(y_true, y_pred, average="weighted")
performance["overall"]["precision"] = metrics[0]
performance["overall"]["recall"] = metrics[1]
performance["overall"]["f1"] = metrics[2]
performance["overall"]["num_samples"] = np.float64(len(y_true))
# Per-class performance
metrics = precision_recall_fscore_support(y_true, y_pred, average=None)
for i in range(len(classes)):
performance["class"][classes[i]] = {
"precision": metrics[0][i],
"recall": metrics[1][i],
"f1": metrics[2][i],
"num_samples": np.float64(metrics[3][i]),
}
return performance# Predictions
y_prob = F.softmax(model(X_test), dim=1)
y_pred = y_prob.max(dim=1)[1]# # Performance
performance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)
print (json.dumps(performance, indent=2))Output:
{
"overall": {
"precision": 0.9461538461538461,
"recall": 0.9619565217391304,
"f1": 0.9517707041477195,
"num_samples": 150.0
},
"class": {
"benign": {
"precision": 0.8923076923076924,
"recall": 1.0,
"f1": 0.9430894308943091,
"num_samples": 58.0
},
"malignant": {
"precision": 1.0,
"recall": 0.9239130434782609,
"f1": 0.96045197740113,
"num_samples": 92.0
}
}
}
推理
我们将绘制一个点,我们知道它属于恶性肿瘤类。我们训练有素的模型可以准确预测它确实是恶性肿瘤!
def plot_multiclass_decision_boundary(model, X, y):
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))
cmap = plt.cm.Spectral
X_test = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float()
y_pred = F.softmax(model(X_test), dim=1)
_, y_pred = y_pred.max(dim=1)
y_pred = y_pred.reshape(xx.shape)
plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())# Visualize the decision boundary
plt.figure(figsize=(8,5))
plt.title("Test")
plot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)
# Sample point near the decision boundary
mean_leukocyte_count, mean_blood_pressure = X_scaler.transform(
[[np.mean(df.leukocyte_count), np.mean(df.blood_pressure)]])[0]
plt.scatter(mean_leukocyte_count+0.05, mean_blood_pressure-0.05, s=200,
c="b", edgecolor="w", linewidth=2)
# Annotate
plt.annotate("true: malignant,\npred: malignant",
color="white",
xy=(mean_leukocyte_count, mean_blood_pressure),
xytext=(0.4, 0.65),
textcoords="figure fraction",
fontsize=16,
arrowprops=dict(facecolor="white", shrink=0.1))
plt.show()
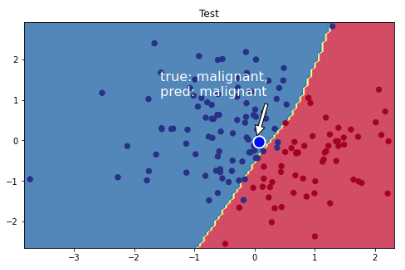
伟大的!我们在训练和测试数据拆分上都获得了出色的表现。我们将使用这个数据集来展示数据质量的重要性。
减少数据集
让我们移除决策边界附近的一些训练数据,看看模型现在有多健壮。
加载数据
# Raw reduced data
url = "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors_reduced.csv"
df_reduced = pd.read_csv(url, header=0) # load
df_reduced = df_reduced.sample(frac=1).reset_index(drop=True) # shuffle
df_reduced.head()| 白细胞计数 | 血压 | 肿瘤类 | |
|---|---|---|---|
| 0 | 16.795186 | 14.434741 | 良性 |
| 1 | 13.472969 | 15.250393 | 恶性的 |
| 2 | 9.840450 | 16.434717 | 恶性的 |
| 3 | 16.390730 | 14.419258 | 良性 |
| 4 | 13.367974 | 15.741790 | 恶性的 |
# Define X and y
X = df_reduced[["leukocyte_count", "blood_pressure"]].values
y = df_reduced["tumor_class"].values
print ("X: ", np.shape(X))
print ("y: ", np.shape(y))Output:
X: (720, 2) y: (720,)
# Plot data
colors = {"benign": "red", "malignant": "blue"}
plt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], s=25, edgecolors="k")
plt.xlabel("leukocyte count")
plt.ylabel("blood pressure")
plt.legend(["malignant", "benign"], loc="upper right")
plt.show()
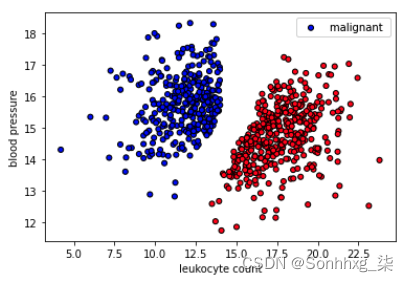
拆分数据
# Create data splits
X_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(
X=X, y=y, train_size=TRAIN_SIZE)
print (f"X_train: {X_train.shape}, y_train: {y_train.shape}")
print (f"X_val: {X_val.shape}, y_val: {y_val.shape}")
print (f"X_test: {X_test.shape}, y_test: {y_test.shape}")
print (f"Sample point: {X_train[0]} → {y_train[0]}")Output:
X_train: (503, 2), y_train: (503,) X_val: (108, 2), y_val: (108,) X_test: (109, 2), y_test: (109,) Sample point: [19.66235758 15.65939541] → benign
标签编码
# Encode class labels
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(y_train)
num_classes = len(label_encoder.classes_)
y_train = label_encoder.transform(y_train)
y_val = label_encoder.transform(y_val)
y_test = label_encoder.transform(y_test)# Class weights
counts = np.bincount(y_train)
class_weights = {i: 1.0/count for i, count in enumerate(counts)}
print (f"counts: {counts}\nweights: {class_weights}")Output:
counts: [272 231]
weights: {0: 0.003676470588235294, 1: 0.004329004329004329}
标准化数据
# Standardize inputs using training data
X_scaler = StandardScaler().fit(X_train)
X_train = X_scaler.transform(X_train)
X_val = X_scaler.transform(X_val)
X_test = X_scaler.transform(X_test)模型
# Initialize model
model = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)训练
# Define Loss
class_weights_tensor = torch.Tensor(list(class_weights.values()))
loss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)# Optimizer
optimizer = Adam(model.parameters(), lr=LEARNING_RATE)# Convert data to tensors
X_train = torch.Tensor(X_train)
y_train = torch.LongTensor(y_train)
X_val = torch.Tensor(X_val)
y_val = torch.LongTensor(y_val)
X_test = torch.Tensor(X_test)
y_test = torch.LongTensor(y_test)# Training
for epoch in range(NUM_EPOCHS*10):
# Forward pass
y_pred = model(X_train)
# Loss
loss = loss_fn(y_pred, y_train)
# Zero all gradients
optimizer.zero_grad()
# Backward pass
loss.backward()
# Update weights
optimizer.step()
if epoch%10==0:
predictions = y_pred.max(dim=1)[1] # class
accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)
print (f"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}")Output:
Epoch: 0 | loss: 0.68, accuracy: 69.8 Epoch: 10 | loss: 0.53, accuracy: 99.6 Epoch: 20 | loss: 0.42, accuracy: 99.6 Epoch: 30 | loss: 0.33, accuracy: 99.6 Epoch: 40 | loss: 0.27, accuracy: 99.8
评估
# Predictions
y_prob = F.softmax(model(X_test), dim=1)
y_pred = y_prob.max(dim=1)[1]# # Performance
performance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)
print (json.dumps(performance, indent=2))Output:
{
"overall": {
"precision": 1.0,
"recall": 1.0,
"f1": 1.0,
"num_samples": 109.0
},
"class": {
"benign": {
"precision": 1.0,
"recall": 1.0,
"f1": 1.0,
"num_samples": 59.0
},
"malignant": {
"precision": 1.0,
"recall": 1.0,
"f1": 1.0,
"num_samples": 50.0
}
}
}
推理
现在让我们看看之前的相同推理点现在如何在缩减数据集上训练的模型上执行。
# Visualize the decision boundary
plt.figure(figsize=(8,5))
plt.title("Test")
plot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)
# Sample point near the decision boundary (same point as before)
plt.scatter(mean_leukocyte_count+0.05, mean_blood_pressure-0.05, s=200,
c="b", edgecolor="w", linewidth=2)
# Annotate
plt.annotate("true: malignant,\npred: benign",
color="white",
xy=(mean_leukocyte_count, mean_blood_pressure),
xytext=(0.45, 0.60),
textcoords="figure fraction",
fontsize=16,
arrowprops=dict(facecolor="white", shrink=0.1))
plt.show()
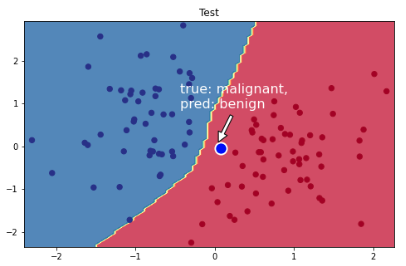
这是一个非常脆弱但非常现实的场景。基于我们减少的合成数据集,我们已经实现了一个在测试数据上泛化得非常好的模型。但是,当我们要求对之前测试的同一点(我们知道是恶性的)进行预测时,现在的预测是良性肿瘤。我们会完全错过肿瘤。为了缓解这种情况,我们可以:
- 获取更多关于我们关注的空间的数据
- 在接近决策边界时谨慎使用预测
带走
模型不是水晶球。因此,重要的是,在任何机器学习之前,我们要真正查看我们的数据并问自己它是否真正代表了我们想要解决的任务。该模型本身可能非常适合您的数据并且可以很好地概括您的数据,但如果数据质量较差,则该模型不可信。
一旦你确信你的数据质量很好,你终于可以开始考虑建模了。您选择的模型类型取决于许多因素,包括任务、数据类型、所需的复杂性等。
所以一旦你弄清楚你的任务需要什么类型的模型,从简单的模型开始,然后慢慢增加复杂性。您不想立即开始使用神经网络,因为这可能不是您的数据和任务的正确模型。在模型复杂性中取得平衡是数据科学家的关键任务之一。简单模型 → 复杂模型

















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











