









1 CLIP4CLIP
利用CLIP实现视频检索:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
CLIP4Clip 是基于CLIP进行视频检索的工作,作者通过大量的实验,验证了如何基于预训练好的图文CLIP 模型,通过迁移学习,或者finetune来完成视频检索的任务。
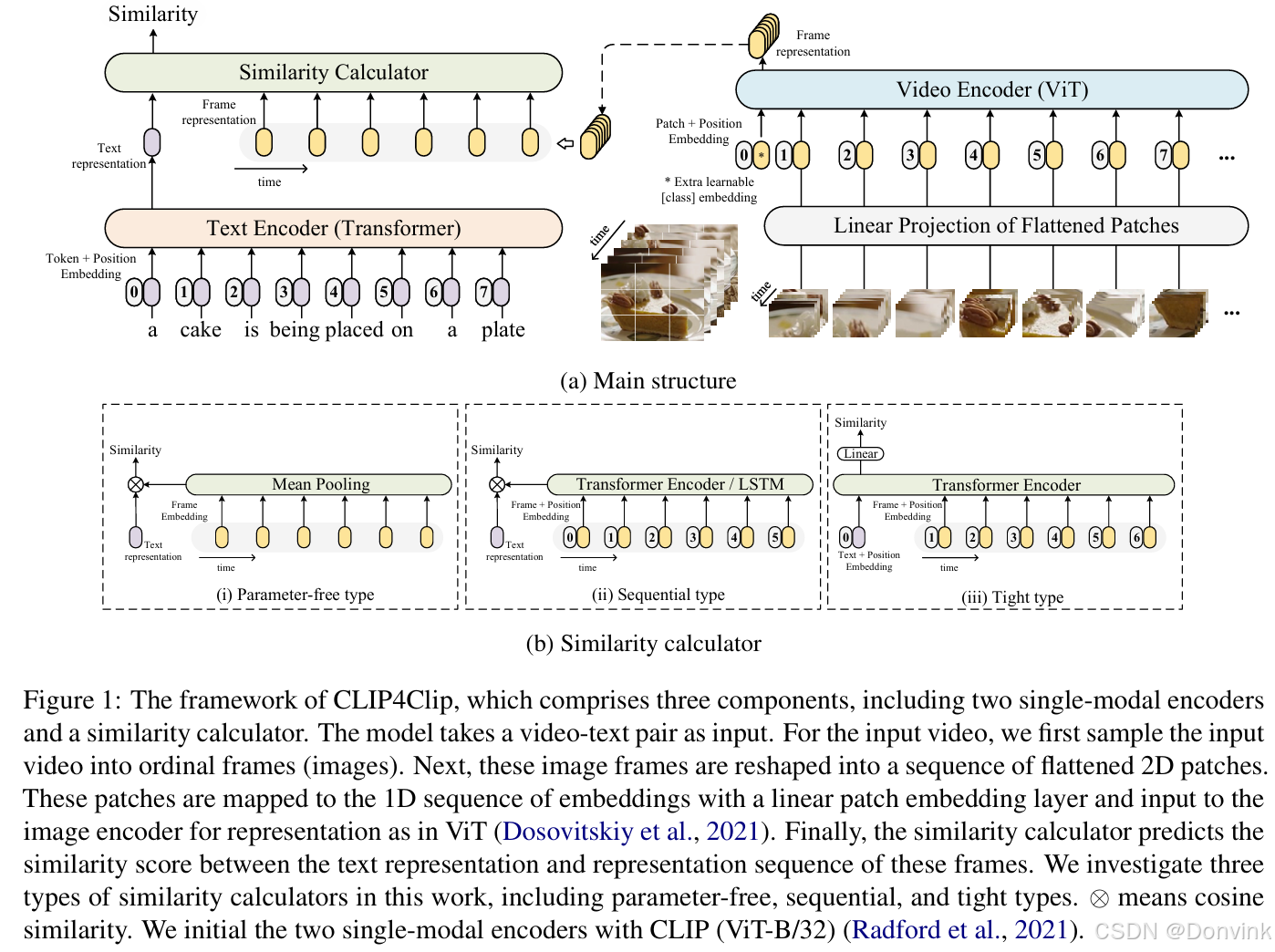
模型结构如下图所示,模型主体结构复用CLIP的模型结构,也因此可以load CLIP的 pretrain 模型。主体模型分为Video Encoder、Text Encoder 和 Similarity Calculator。
Video Encoder:采用CLIP的 image encoder(ViT-B/32),视频数据输入多帧图像,那么输出也是多帧的图像特征;
Text Encoder : 采用CLIP 的Text encoder(Transformer结构),进行文本的特征提取;
Similarity Calculator:Similarity Calculator 是用来度量如何衡量多帧特征和文本特征相似度的模块,论文给出了三种结构,如下图的b)。
2 ActionCLIP
基于CLIP,浙大提出ActionCLIP,用检索的思想做视频动作识别:ActionCLIP: A New Paradigm for Video Action Recognition
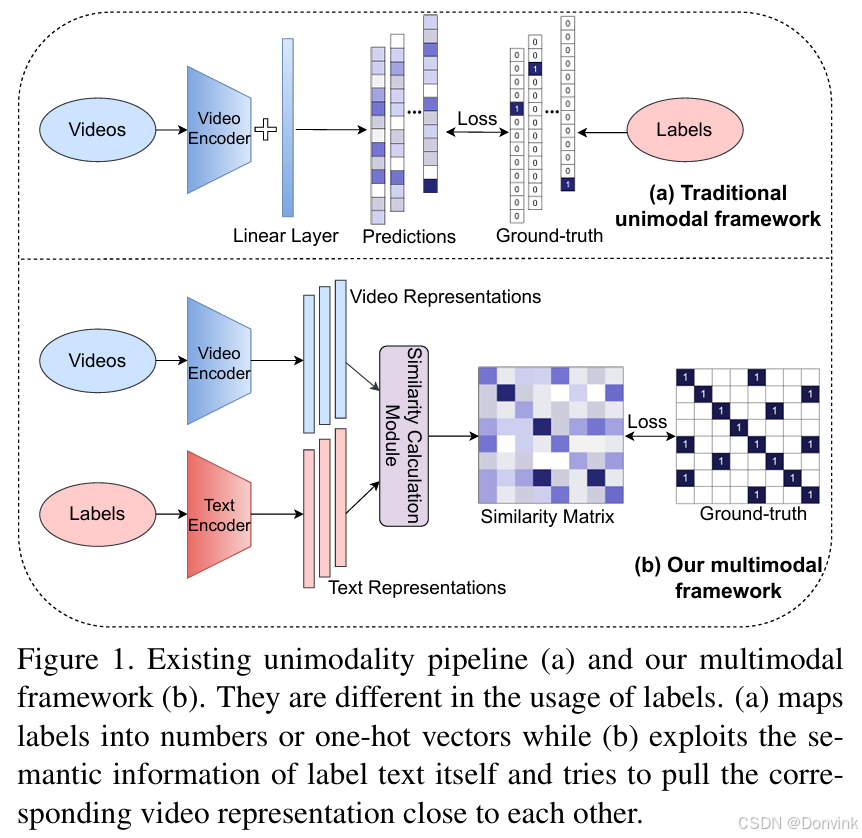
ActionCLIP和传统方法对比:
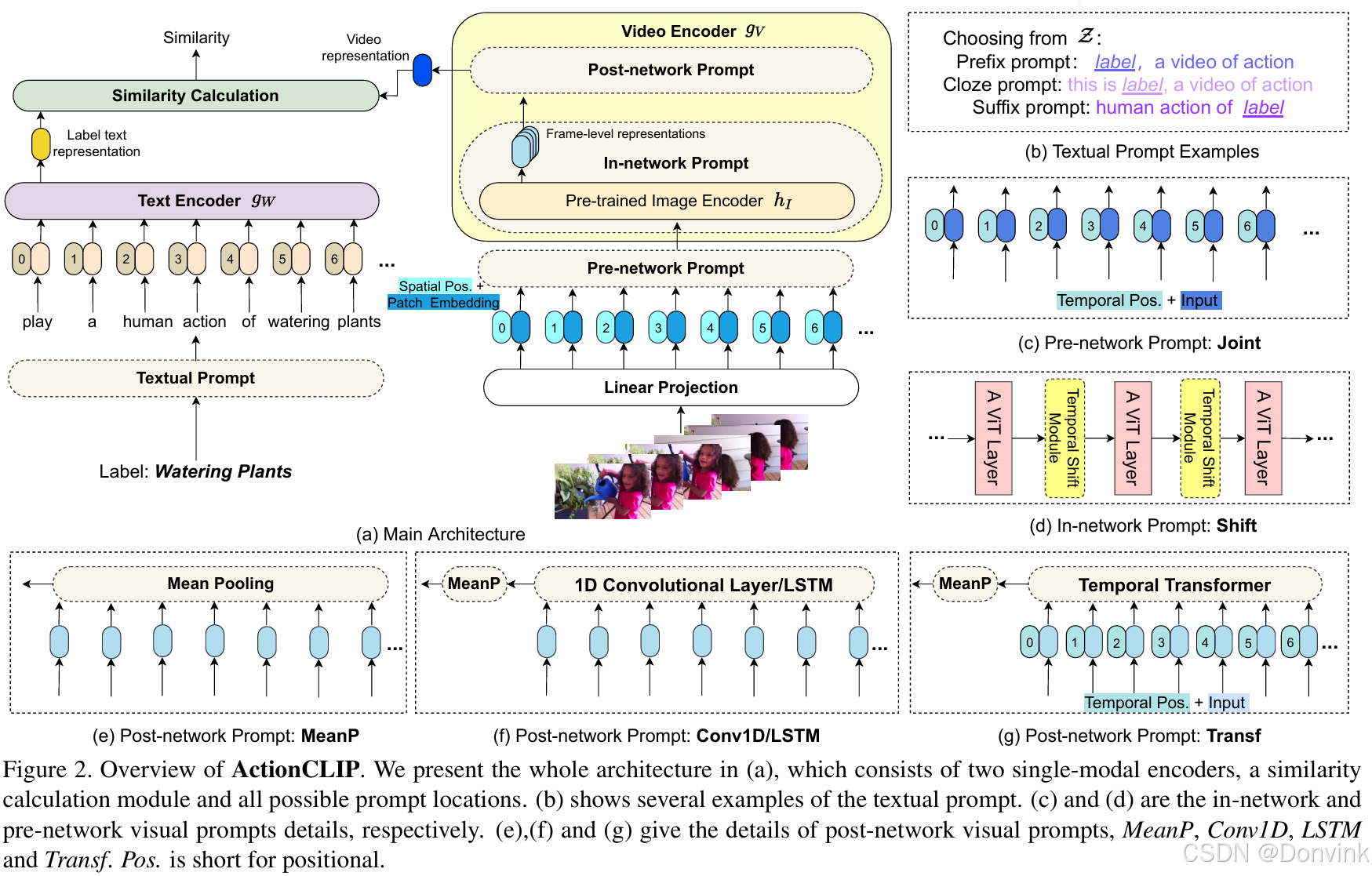
模型结构如下图所示:
3 CLIP-ViL
多模态 CLIP-ViL:
论文:How Much Can CLIP Benefit Vision-and-Language Tasks?
作者将 CLIP 的预训练参数用来初始化 ViL 模型,然后再各种视觉-文本多模态任务上进行微调,测试结果。
4 AudioCLIP
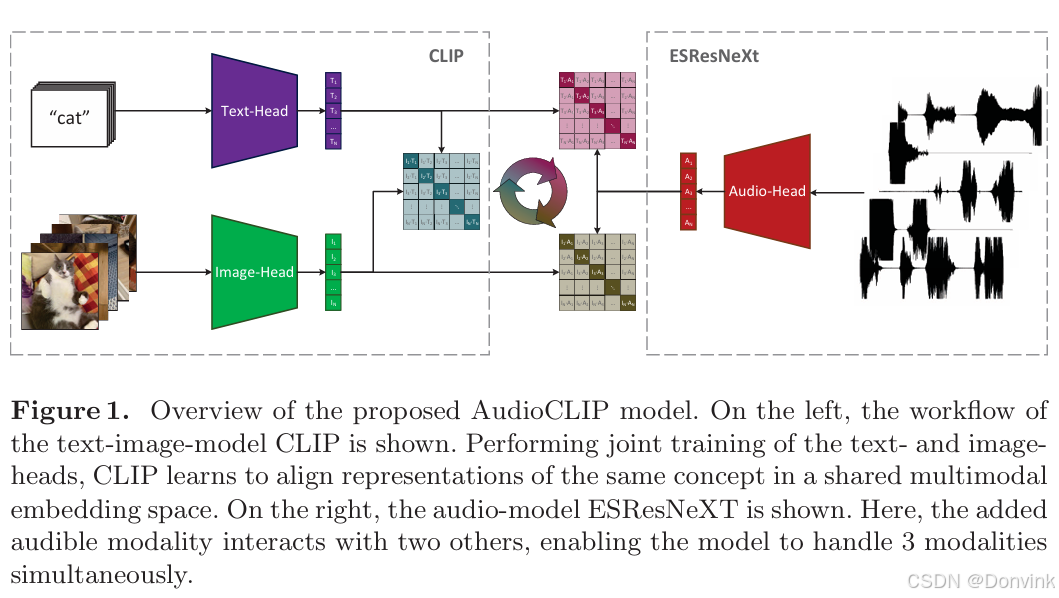
将CLIP应用于语音领域:AudioCLIP: Extending CLIP to Image, Text and Audio
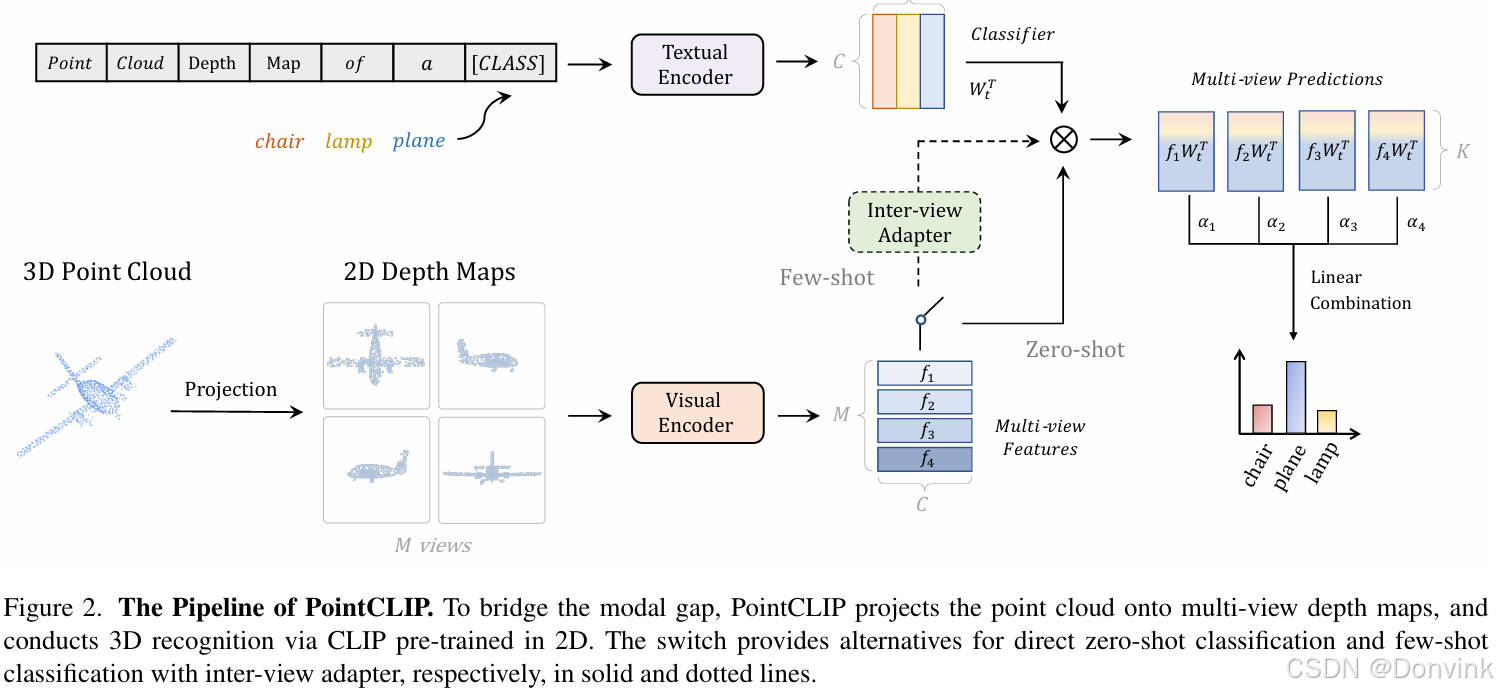
5 PointCLIP
论文: PointCLIP: Point Cloud Understanding by CLIP
作者通过现将 3D 点云投射为多张 2D 的深度图,实现了在3D图上利用 2D 图像数据训练 的CLIP 模型。
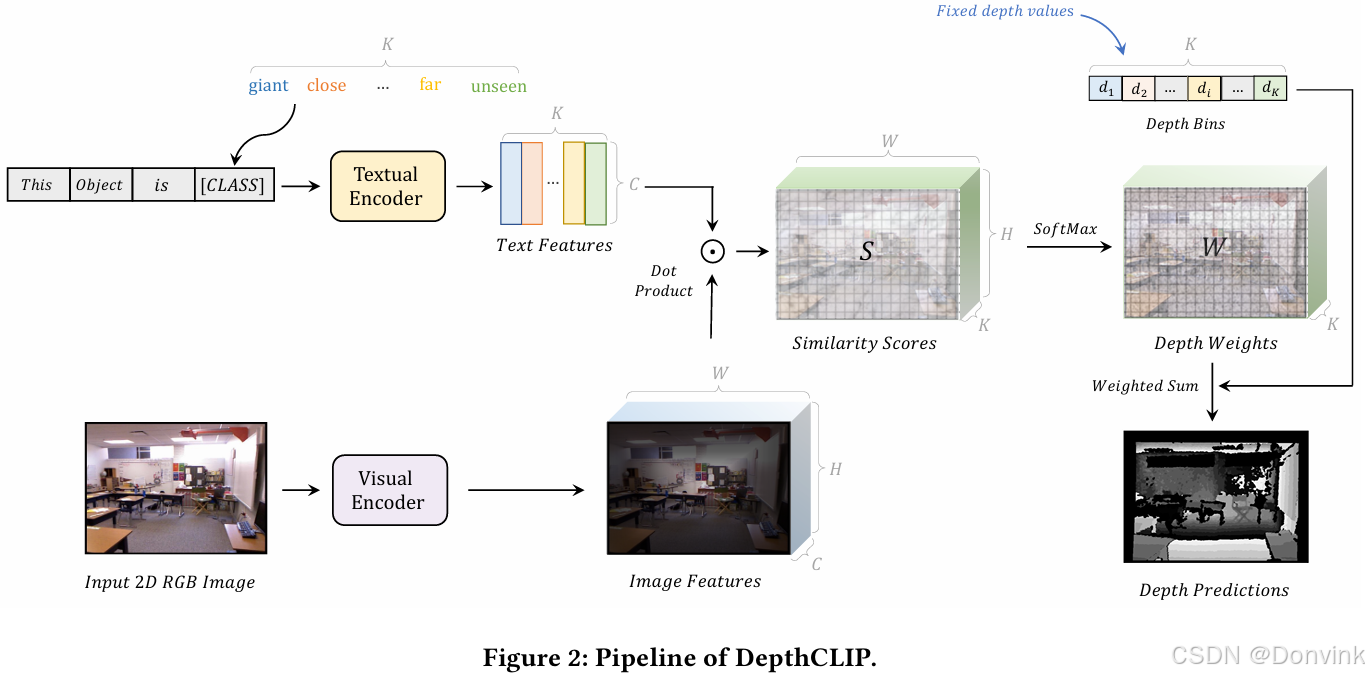
6 DepthCLIP
Can Language Understand Depth?
摘要:除了图像分类,对比语言-文本预训练(CLIP)在广泛的视觉任务中取得了显著的成功,包括对象级和3D空间理解。然而,将从CLIP学习到的语义知识转移到更复杂的量化目标任务中仍然具有挑战性,例如几何信息深度估计。在本文中,我们建议将CLIP应用于零样本单目深度估计,称为DepthCLIP。DepthCLIP发现输入图像的补丁,可以响应某个语义距离标记,然后投影到量化的深度箱中进行粗估计。在没有任何训练的情况下,我们的DepthCLIP超越了现有的无监督方法,甚至接近早期的有监督网络。DepthFormer是第一个从语义语言知识中进行零样本适应以量化下游任务并执行零样本单目深度估计的方法。

















 2377
2377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









