







#MCP 协议知识分享#
第一章:前言——在多模态风口下,MCP 正在重塑 AI 协同方式
🧠 为什么多模态 AI 需要一个“处理协议”?
近几年,大模型的发展经历了从“语言理解”到“多模态感知”的加速进化:文本、语音、图像、视频、动作等输入与输出能力被逐步集成到单一模型中。比如你可以对 GPT-4o 说话、展示一张图,它就能立刻用语音回答你——这不是魔法,而是一个核心系统正在背后默默调度,这就是 MCP(Multi-Channel Processing)协议。
但问题来了,多模态的组合并不意味着简单“堆功能”。
人类与 AI 的交互过程,早已从 “你说我答” 转向:
- 你边说,我边听,还得看你表情(图像)
- 我得判断你说话的情绪、内容重点、时机、上下文切换
- 最后用恰当的方式反馈:可能是声音,也可能是界面上生成的一段文本或一张图
而这套复杂的 实时协同机制,并不是传统 API 或单通道输入输出能完成的任务。这时候,MCP 就像是一个 AI 的“多通道神经中枢”,用来控制和管理 AI 如何处理来自多个来源的数据,协调多个子模型完成完整任务。
🔄 从调用模型到 orchestrate(协调)模型:一场范式转变
我们以往调用一个语言模型的方式通常如下:
input(text) → process → output(text)
但在多模态 AI 场景下,调用流程更像这样:
input(audio + text + image + video, 同时)→ 并行预处理 → 模型核心处理(结合所有模态) → 多通道输出(TTS + 文本 + 图像)
这类流程一旦缺乏“通道调度协议”,开发者就不得不自己拼接口、管理时间戳、协调各模块输入输出状态——这是极度繁琐且极易出错的。
MCP 的提出,正是为了解决这个问题,它本质上是:
- 一种底层调度协议
- 一套跨模态上下文编排机制
- 一个用于协调“多模型多通道协作”的运行框架
🚀 为什么说 MCP 是 GPT-4o 的“大脑总线”?
OpenAI GPT-4o 是首个原生支持 MCP 协议的多模态模型系列。它在系统设计层面,就不再是传统的“一个 API 响应一次请求”的模式,而是:
“将语音、文本、图像通道作为并行输入/输出流,通过 MCP 协议统一接收、调度、响应,实现类人交互体验。”
你可以理解为,GPT-4o 就像是一台多传感器机器人,而 MCP 就是这台机器人的“神经网络总线”,控制着:
- 哪些传感器(语音、图像、文字)正在说话?
- 哪些输出装置(嘴巴、显示屏)要启动?
- 当前需要哪个子模型协同工作?谁先说,谁先停?
- 多个通道的信息如何对齐?哪段语音对应哪段文字?
✅ MCP 带来的三大底层变革
| 能力维度 | 传统多模态 API | MCP 模型 |
|---|---|---|
| 通道处理 | 串行 | 并行 |
| 响应机制 | 请求-响应 | 事件驱动,流式 |
| 上下文协同 | 模态割裂 | 模态对齐,多通道整合 |
MCP 不只是技术创新,更代表着一种新的架构范式,它告诉开发者:
- 你不再需要将每个模态分开部署、手动整合
- 你可以开始构建原生流式、原生实时、多模态自然交互的系统
- 未来的 AI 应用,不是“调用模型”,而是驱动模型协议进行实时交互
第二章:什么是 MCP?多通道处理协议的底层原理详解
—
🔍 MCP 的定义与定位
MCP(Multi-Channel Processing Protocol) 是 OpenAI 提出的新一代底层交互协议,旨在让 AI 模型能够同时处理多个输入通道(如语音、图像、文字)并输出对应内容(如文本、语音、图像),同时保持高度实时性、上下文连续性与协同智能。
它并不是一个 API,不是用于“调用模型”的接口,而是一个协调输入/输出/处理的通信协议标准,定义了以下几件事:
- 如何接收和管理多个模态通道的数据流
- 如何在多个通道之间建立上下文联动
- 如何通过模型内部机制,实现动态推理调度
- 如何控制输出响应节奏、方式与通道
你可以把它类比为:
- Web 开发中的 HTTP 是信息传输协议;
- WebSocket 是实时通信协议;
- 而 MCP 是智能模型间“多模态通感与联动”的协调协议。
🧩 MCP 的核心组成部分
我们可以将 MCP 拆解为四个关键模块来理解:
1. 多通道输入结构(Multi-Channel Input Stream)
MCP 允许用户在同一时间发送不同类型的数据通道,如:
audio_channel: 音频流输入(语音识别)text_channel: 文字输入(命令 / 补充指令)image_channel: 图像输入(视觉内容)meta_channel: 附加控制参数(用户信息、意图指令)
MCP 将它们统一打包成一套数据帧(frame),通过统一时序机制输入给模型核心。
2. 通道调度与上下文编排器(Context Orchestrator)
这是 MCP 的“灵魂模块”,功能包括:
- 同步多通道内容:如将语音内容和图像结合,形成多模态理解上下文
- 排序与缓冲机制:音频/视频/图像数据传输速度不一,MCP 提供统一时间戳调度机制
- 处理优先级管理:在语音+图像同时输入时,根据意图动态决定优先处理哪个通道
这类似于一个“多传感器融合中枢”,让 AI 在多线程中保持稳定运行。
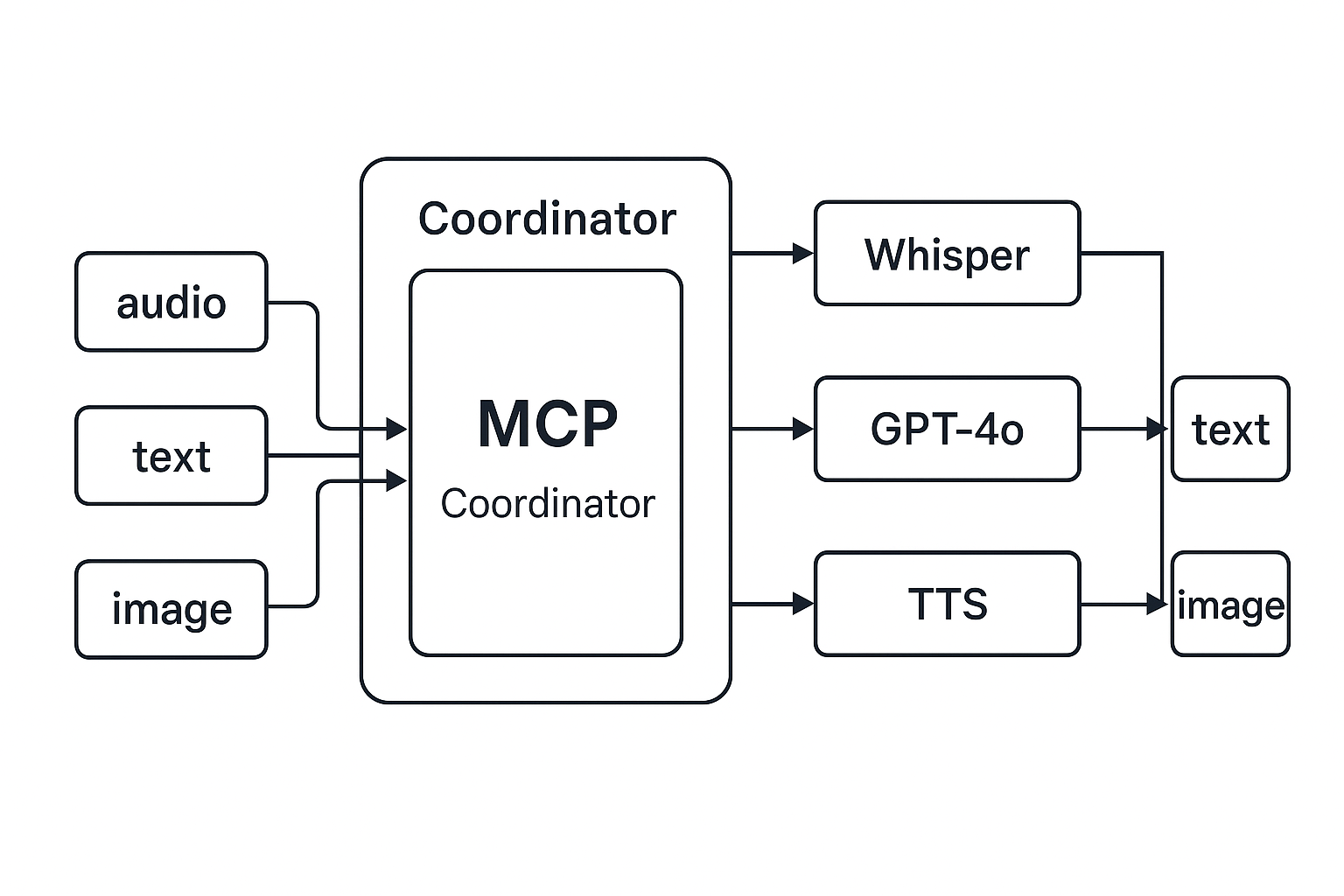
3. 推理执行路由器(Processing Router)
一旦输入通道数据整合完毕,MCP 会将其传送给:
- Whisper 模块 → 做转写(语音 → 文本)
- Vision 模块 → 做图像内容理解
- LLM 模块 → 进行主逻辑推理与输出生成
- TTS 模块 → 文本输出转语音
**MCP 管理这些模块的调用顺序、数据格式、输出目标。**这一机制让开发者不再需要人工拼接多个模型 API,而是像操作一个智能协调中心。
4. 输出通道与节奏控制器(Output Channel & Pacer)
MCP 同样支持多通道输出,最典型的如:
text_response_channel: 文本流式输出audio_response_channel: 语音合成输出image_response_channel: 动态图片生成(可选)
MCP 支持 按需输出(on-demand)与流式输出(streaming) 两种机制,并具备响应节奏控制能力,保证模型输出内容“符合用户对话节奏”,而非“机械式一次吐完”。
⚙️ MCP 的通信格式与事件机制
MCP 协议是一种事件驱动协议,类似于 WebSocket 中的消息结构,它常用的消息类型包括:
| 消息类型 | 说明 |
|---|---|
start_channel | 初始化某个通道,例如开启音频输入 |
input_frame | 一帧输入数据,如音频的一段 |
buffering | 模型处理过程中暂缓反馈 |
transcribe_result | 语音识别中间结果 |
generate_output | LLM 推理结果,可能是 text / audio / image |
end_channel | 停止通道 |
error | 处理出错或数据格式异常 |
每个消息都携带:
channel_id:表示当前所属通道timestamp:全局对齐时钟frame_id:帧编号,用于数据顺序管理metadata:通道特征描述(如语种、采样率)
MCP 协议天然具备可扩展性,你可以想象将来加入 video_channel、action_channel 等通道,只需扩展协议字段,无需重写模型核心。
📊 对比:MCP 与传统 API 的关键差异
| 维度 | 传统多模态 API | MCP 协议 |
|---|---|---|
| 输入方式 | 串行单模态 | 多通道并发流输入 |
| 响应机制 | 完整请求后返回 | 事件驱动、支持流式输出 |
| 模型调用 | 开发者手动拼接多个模型 | 自动路由调度子模型执行 |
| 通道对齐 | 不支持 | 内置缓冲 & 时间戳同步 |
| 开发体验 | 高耦合、易错 | 协议驱动、统一接入点 |
🧠 类比:MCP 就像 AI 的“脑干”
- 人类大脑中,脑干控制着听觉、视觉、语音、动作等感官的协调调度;
- 而 MCP 协议,就像是 AI 模型的脑干,控制各“感知模块”何时启用、如何协作、何时输出。
它不做决策本身,但它决定了模型如何听得见、看得清、说得出——这是智能模型系统性演化的关键。
第三章:MCP 能干什么?六大关键能力与典型场景全面解析
✅ MCP,不只是让 AI 同时“听”和“看”
很多人误以为 MCP 就是“多个输入同时进来”的管道协议。其实远不止如此。MCP 的本质,是为多模态 AI 系统提供了:
“通道感知 + 同步理解 + 协调执行 + 流式输出” 的全链路能力
它的出现,第一次让 AI 有了类似于「大脑神经系统」的“信号协调机制”,把各个“感官”和“反应器官”接入到统一的“认知流程”中。
🧠 能力一:多通道并行输入处理(True Parallel Input)
🌐 描述:
传统模型只能「一次处理一个输入」,比如:
- 先上传图片,再输入文字;
- 先说一句话,再等 AI 回应。
而 MCP 可以在同一时刻同时接收多个输入通道的数据帧,并在内部进行合并调度处理。例如:
- 你边说话(语音通道),边指着一张图(图像通道)提问;
- MCP 会将语音识别 + 图像理解结合为一个完整语义上下文。
✅ 技术实现要点:
- 使用 channel ID + timestamp 做帧级同步;
- 输入帧打包为带时间顺序的多通道流;
- 自动分类、缓冲、排序处理。
🛠️ 应用场景:
- AI 导游系统:边听你讲,边看你镜头下的景点;
- 医疗问诊机器人:边听症状描述,边查看上传检查图。
🔄 能力二:跨模态上下文对齐(Cross-Modal Semantic Fusion)
🌐 描述:
人类能轻松地把“你刚说的”和“我刚看到的”整合为一段完整语义。但传统模型无法做到这一点。
MCP 支持基于时间轴和对话轮次的多模态对齐机制,自动判断:
- 图像 A 是语音 B 中提到的“这个”
- 用户上一条输入内容是否需要和当前图像信息整合
✅ 技术实现要点:
- 基于输入帧时间戳做上下文拼接;
- 模型内部构建跨模态嵌入空间;
- 构建“模态指代关系”(e.g. “这个” = 图像内物体)
🛠️ 应用场景:
- 文档助手:你上传图表,随后说“把这个转成表格”,MCP 帮你对上“这个”;
- 智能家居:你说“打开这个灯”,MCP 根据你看向的位置判断你指的是哪一盏。
🔁 能力三:流式响应生成(Streaming Multi-Modal Output)
🌐 描述:
以往模型是“等你输入完 → 一次性输出结果”,而 MCP 支持边听边理解边输出,实现:
- 语音转写实时显示(边说边出文字)
- 文字输出同时进行语音播报
- 多模态协同响应(如语音 + 动作)
✅ 技术实现要点:
- 支持多通道
stream_output; - 输出节奏与输入节奏联动;
- 各输出模块(TTS、Text、Image)可分帧异步输出
🛠️ 应用场景:
- 实时语音翻译器:用户一边说,AI 一边翻译并语音输出;
- 智能客服:用户还没说完,AI 已经先说“我了解您的问题……”
🕒 能力四:低延迟与节奏控制(Realtime Pacing)
🌐 描述:
MCP 支持通过帧缓冲和节奏控制策略实现毫秒级交互响应:
- 自动对输入帧做滑动窗口预测
- 动态调整 TTS 输出速度匹配用户说话节奏
- 延迟控制在对话友好范围内(如 300ms 内)
✅ 技术实现要点:
- 可配置 response delay;
- 内建输出节奏协调器(pacer);
- 输出 pause / resume 控制能力
🛠️ 应用场景:
- 智能语音导航助手(如 GPT-4o 车载版)
- 老年陪伴 AI 语速控制系统
🧠 能力五:模型自动调度与模块组合(Model Routing)
🌐 描述:
MCP 本身不做推理,而是扮演“多模型调度器”,可以同时协同以下模块:
- Whisper:语音识别
- GPT-4o:多模态推理核心
- TTS:语音合成
- Vision:图像理解
开发者不需要自己接 API 拼模块,而是一次调用,MCP 自动调动所有必要子模型完成完整流程。
✅ 技术实现要点:
- MCP 内建模型注册表;
- 自动推理输入类型 → 匹配执行路径;
- 支持模型缓存与复用优化
🛠️ 应用场景:
- Agent 系统中的多模型调度
- 大模型系统组合(RAG + TTS + OCR)统一输出入口
🤖 能力六:支持多智能体协同(Multi-Agent Ready)
🌐 描述:
MCP 协议是天然为未来多智能体协作设计的:
- 每个 Agent 可注册自己的输入/输出通道
- MCP 统一调度这些 Agent 接收、处理、传输消息
- 实现一个“模型生态系统”的信号总线
✅ 技术实现要点:
- 支持多 channel → 多 processor 映射
- 实现通道转发、接力与多 Agent 中继
- 可拓展为 MPC(Multi-Process Communication)模式
🛠️ 应用场景:
- AI 辅助编程平台(语音 agent、代码 agent、审校 agent 协同)
- 家庭 AI 群体系统(语音助手 + 设备控制 + 提醒服务并存)
第四章:MCP 的协议设计结构解析(通信格式 × 消息流 × 通道状态机)
🧠 MCP 协议本质:一个模型级别的“实时信号协同协议”
要理解 MCP,不能用传统 HTTP 或 REST API 的视角来看,它不是一次请求返回结果的单向流程,而是一个持续的、多通道、多模态的数据帧协同系统。
更准确地说,MCP 是一个面向「实时 AI 推理系统」设计的协议框架,结构上接近 WebSocket,但更复杂:
| 类型 | HTTP | WebSocket | MCP |
|---|---|---|---|
| 数据模型 | 请求-响应 | 持久连接,单通道 | 多通道帧流,模型调度感知 |
| 通信方向 | 单向 | 双向 | 多路并发、可扩展中继 |
| 内容粒度 | 文本块 | 数据帧 | 多模态帧 + 元数据 + 控制信令 |
📦 MCP 消息通信模型:三层结构
MCP 协议通信基于三个层级:
1. 通道层(Channel)
- 每一个输入/输出模态通道都是一个逻辑实体
- 通道可被识别、暂停、恢复、重定向
示例通道 ID(可配置):
text_in、audio_in、image_intext_out、audio_out、tts_feedback
2. 帧层(Frame)
- 每个通道传输的数据是由一帧帧组成的
- 每帧带有结构化信息,如数据体、时间戳、顺序编号、通道标签
典型帧结构(JSON):
{
"channel_id": "audio_in",
"frame_id": "000324",
"timestamp": 1700009212.473,
"payload": "<base64-audio-data>",
"metadata": {
"lang": "en-US",
"codec": "pcm_s16le"
}
}
3. 消息事件层(Event)
- 用于标识一次完整的通道行为或生命周期事件
- 如
start,buffering,generate_output,end,error
示例事件消息:
{
"event": "generate_output",
"channel_id": "text_out",
"timestamp": 1700009213.985,
"payload": "Sure! The Eiffel Tower is located in Paris.",
"stream": true
}
🧭 通道状态机设计:MCP 的实时交互基础
每一个 MCP 通道在生命周期中都要经历以下几个状态:
[INIT] → [ACTIVE] → [BUFFERING] → [PROCESSING] → [STREAM_OUTPUT] → [END]
状态说明:
| 状态 | 描述 |
|---|---|
| INIT | 通道建立但未开始传输数据 |
| ACTIVE | 正在接收输入帧 |
| BUFFERING | 帧数据暂存,等待处理器就绪 |
| PROCESSING | 调度模型开始处理帧数据 |
| STREAM_OUTPUT | 模型开始流式生成输出 |
| END | 通道关闭,所有数据处理完成 |
每次状态变更都通过事件消息显式触发。
这就像是一条条“可管理的模态流水线”,由 MCP 来保证队列稳定、通道顺序、资源调度。
🔄 MCP 消息流流程图(交互视角)
以一个“语音提问 → 图文回答 + TTS”完整流程为例:
1. Client --> MCP : start_channel(audio_in)
2. Client --> MCP : input_frame(audio_in, frame_001)
3. MCP --> Whisper: decode frame, transcribe
4. MCP --> GPT-4o : input = [transcribed text + context]
5. GPT-4o --> MCP : output_frame(text_out, part_1)
6. MCP --> TTS : text_out → speech
7. MCP --> Client : output_frame(audio_out, audio_frame_1)
8. Client <-- MCP : end_channel
📍此过程中,MCP 并没有“做推理”,但它掌握整个感知-处理-输出流程的节奏控制权。
📎 MCP 接口字段总览(开发视角)
| 字段 | 类型 | 描述 |
|---|---|---|
channel_id | string | 通道唯一 ID |
event | string | start / frame / end 等事件类型 |
frame_id | string | 数据帧序号 |
timestamp | float | 时间戳,支持排序与延迟分析 |
payload | string (base64/text) | 输入/输出内容 |
metadata | object | 编码格式、语种、帧长等参数 |
stream | boolean | 是否为流式输出 |
priority | int (optional) | 输入优先级(高级场景用) |
💡 MCP 协议的可扩展性设计
MCP 协议不是写死的,它具有以下扩展能力:
- 自定义通道类型(如
gesture_in,sensor_in,html_out) - 接入外部 Agent 中继通道(构建多 Agent 联动)
- 打包多帧的高吞吐模式(帧批处理)
- 异步通道组:不同模态输入可以并发独立处理
🛠️ 示例:MCP 流式语音输入的最小实现片段(伪代码)
def on_audio_frame_received(frame):
# 语音帧接收后,封装为 MCP 输入帧
mcp.send({
"event": "input_frame",
"channel_id": "audio_in",
"timestamp": time.time(),
"frame_id": gen_frame_id(),
"payload": base64.b64encode(frame),
"metadata": {"codec": "pcm_s16le", "lang": "en-US"}
})
第五章:MCP 能带来什么?现实与未来场景下的深度应用价值
🔍 从“多模态模型”到“通道驱动智能体”的转变
在 MCP 出现之前,开发者面对多模态任务的典型困扰是这样的:
- 图像模型用一套 API,语音识别用另一套,语言模型还得额外接入
- 数据通道之间毫无上下文连贯性,指令延迟、模态误解频繁发生
- 每一次交互需要手动串联模型,写繁琐中间层,还难以实时响应
MCP 协议打破了这一割裂局面,将模型之间的“输入输出关系”变成了“通道流”与“事件协调”机制,从而让 AI 从“单一模型工具”进化为:
⚙️ 多通道协同处理的“统一智能体”运行架构
🧠 现实应用场景一:AI 语音助手的“类人对话升级”
👇 传统方式:
- 用户说一句话 → 后端转写 → 再丢给模型 → 输出后 → TTS 再合成语音
- 整体响应延迟大、无打断、无节奏控制
✅ 使用 MCP 后:
- 音频帧实时接入(
audio_in) - Whisper 同步转写(
transcribe_result) - GPT-4o 同步生成文字(
text_out) - TTS 输出流式语音(
audio_out)
🌀 最终体验:
用户话还没说完,助手就开始回答,而且可以灵活打断、提问、补充说明
📦 商业落地场景:
- 汽车语音助手(导航、娱乐、车辆控制)
- 电话客服 AI(更自然、更实时)
- 老人语音陪伴系统(语速调节,模态融合)
🔍 应用场景二:多模态搜索问答系统(图+声+文本查询)
👇 用户场景:
- 用户上传一张表格图像,并问:“这张表里最高的数是哪一个?”
- 接着补充说:“顺便告诉我哪个区域最差。”
✅ MCP 实现路径:
image_in: 图像上传,解析成结构化数据(视觉模块)audio_in: 用户语音同步传入,转写为文字(Whisper)context_orchestrator: 自动对齐用户提问和图像内容gpt-4o: 理解问法,推理出答案,生成文字 + 表格 +语音text_out/audio_out: 输出回答
🎯 优势:
- 图文语音联合理解
- 指代关系可持续(“这张表”、“最差”都能指对)
🧠 应用场景三:多智能体协同平台的“通道协调基础设施”
在 AI Agent 体系中,我们常常构建多个 agent,例如:
- 语音 agent:识别和转写音频
- 编程 agent:读取上下文写代码
- 审核 agent:检查语义逻辑或安全性
🧱 MCP 的角色:
- 每个 agent 作为 MCP 通道注册节点
- 不同 agent 通过
channel_route机制串联起来 - MCP 调度各个通道任务并保持全局状态一致
这将演化出一个极具潜力的方向:
📡 通道驱动式 Agent 网络(Channel-Oriented Agent Fabric)
未来每个 Agent 都是 MCP 的一部分,像 USB 外设那样即插即用。
🔍 应用场景四:智能硬件与人机交互系统
在语音智能设备(如耳机、智能音箱、AR 眼镜)中,对“延迟容忍度极低”,且交互模态极其丰富:
| 场景 | 模态 |
|---|---|
| 语音输入 | 音频输入通道 |
| 图像输入 | 摄像头实时捕捉 |
| 手势或动作 | sensor_in 模拟通道 |
| 输出反馈 | TTS + 屏幕提示 + 振动反馈 |
MCP 的多通道结构可以原生支持:
- 传感器并发感知
- 多通道实时对齐
- 反馈输出分模态精准触达
🧠 这将是构建「新一代智能终端 AI 中枢」的关键基建能力。
📡 未来演化趋势:MCP 的“协议生态系统”潜力
MCP 不仅是 OpenAI 的私有协议,它也具备开放标准演进潜力:
🧩 模型层分离(Modular LLM Stack)
- 开源模型如 Whisper.cpp、Bark、GPT-NeoX 等将支持 MCP 接入点
- 实现 LLM-agnostic 的多通道调度接口
🤖 Agent 标准通讯协议
- MCP 可作为多智能体系统的标准通信协议
- 取代现有自定义 JSON-RPC、gRPC 方案,提供模态原生支持
🌐 云边协同传输协议
- 音频前处理在边缘执行
- 中间帧通过 MCP 转发至云端模型推理
- 最终结果再通过 MCP 通道反馈本地
这意味着未来智能终端、Agent 系统、大模型平台将有可能围绕 MCP 构建完整生态。
第六章:开发者如何使用 MCP?模型、通道、流式接入的实操指引
🎯 本章目标
本章将面向开发者,讲清楚:
- MCP 能在哪些模型中使用?
- 如何通过 OpenAI 接口接入 MCP?
- MCP 流式语音输入 / 多通道输出的最小实现示例
- 实战开发中如何管理通道、流式响应和模型协同
适合希望将 GPT-4o 系列(如 gpt-4o-transcribe)集成到智能语音、图文问答、Agent 系统中的研发者。
🧠 MCP 支持哪些模型?
目前 OpenAI 官方支持 MCP 的模型有三个(截至 2025 年 Q1):
| 模型名称 | 描述 | 典型用法 |
|---|---|---|
gpt-4o-transcribe | Whisper + GPT-4o 编排模型 | 实时语音转写 + 回答 |
gpt-4o-mini-transcribe | 精简版转写模型 | 边缘语音输入场景 |
gpt-4o-mini-tts | 文字转语音 | 语音响应输出 |
MCP 协议能力体现在这些模型的 多通道并行处理能力 + 流式输入输出机制 + 实时交互响应能力 上。
📦 MCP 通道结构与调用模型的关系
在实际调用中,每个 MCP 模型接口本质上仍通过 POST /v1/chat/completions 或 POST /v1/audio/transcriptions 实现,但其内部行为完全支持 MCP 的通道逻辑。
✅ 你只需要关注几个重点字段:
| 字段 | 说明 |
|---|---|
stream | 是否启用流式输出(推荐开启) |
response_format | 设置为 verbose_json 可获取多通道输出结构 |
input_mode | multi-channel 模式支持 MCP 结构(部分模型自动生效) |
audio_url / image_url | 音频或图像流输入来源 |
temperature | 控制生成波动 |
tools(可选) | 用于 agent 调度时注册能力 |
🚀 示例一:实时语音输入 + 流式文字输出(最小实现)
你可以用 WebSocket + Whisper 实现客户端向模型传输语音帧,并通过 MCP 协议接收流式返回的文字。
import openai
openai.api_key = "your-api-key"
response = openai.ChatCompletion.create(
model="gpt-4o-transcribe",
stream=True,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": {"audio_url": "https://yourdomain.com/audio-stream"}},
]
)
for chunk in response:
print(chunk['choices'][0]['delta'].get('content', ''), end='', flush=True)
🎯 效果:
- 音频实时发送给 MCP 处理器
- 实时转写 → 实时生成 → 实时输出文字流
🚀 示例二:语音提问 + 图像上传 → 多通道回答(MCP 多模态典型流程)
response = openai.ChatCompletion.create(
model="gpt-4o-transcribe",
stream=True,
messages=[
{
"role": "user",
"content": [
{"type": "audio", "audio_url": "https://yourcdn.com/voice.wav"},
{"type": "image", "image_url": "https://yourcdn.com/chart.png"},
{"type": "text", "text": "请帮我分析图表,并用中文解释"}
]
}
]
)
for chunk in response:
delta = chunk['choices'][0]['delta']
if "content" in delta:
print(delta['content'], end='', flush=True)
💡 支持 content 字段传入一个数组,MCP 将自动将不同类型分配给对应通道,并进行时间轴对齐与处理协同。
⚙️ 实战技巧:与 MCP 协议相关的开发建议
✅ 1. 启用 stream=True 获取最小延迟
- 流式响应是 MCP 的重要特性,适合语音助手类场景
✅ 2. 构造 multi-modal input 时保持顺序逻辑
- MCP 会使用顺序 + timestamp 联合对齐多模态输入
- 建议开发者按照自然交互顺序构造 messages
✅ 3. 利用返回 metadata 判断响应是否为多通道
- 返回结构中包含
channel_id/event_type等字段 - 可据此区分是文本输出还是 TTS 音频流
✅ 4. 对接 MCP 多通道输出时,需分发不同通道的响应结果
if chunk['channel_id'] == "audio_out":
play_audio(chunk['payload']) # 解码后播放
elif chunk['channel_id'] == "text_out":
print(chunk['payload']) # 文本展示
🧪 真实项目接入建议流程
| 步骤 | 描述 |
|---|---|
| 1. 场景确定 | 是图文助手?语音对话?Agent平台? |
| 2. 通道规划 | 输入:audio/text/image?输出:text/audio? |
| 3. 构建输入消息 | 构造 messages 参数,注意结构和顺序 |
| 4. 启用流式响应 | 设置 stream=True,逐帧解析响应内容 |
| 5. 对接终端输出 | 分通道将响应路由到 TTS / UI / 控制器 |
第七章:MCP 的未来与开放协议构想:多智能体的统一语言?
🔮 MCP,不只是一个协议,而是新一代智能系统的“通信基建”
当我们回顾互联网的发展,会发现几乎每一次技术爆炸都离不开一个关键因素:通信协议的标准化。
- HTTP 统一了浏览器和服务器的交流方式,成就了 Web
- TCP/IP 铺平了网络通信的高速公路
- gRPC、GraphQL 让服务之间高效对话
- WebSocket 解决了实时性、状态性传输问题
那么问题来了:
在多模态大模型 × 智能体协同 × 实时交互逐渐成为主流的未来,谁来定义 AI 模型之间的“通用语言”?
MCP,或许正是那个破局的底层协议。
🔁 从模型调用 API 到智能体协同协议:一次范式转移
我们从调用角度看,过去与未来的差异是显而易见的:
| 架构范式 | 特征 | 示例 |
|---|---|---|
| 模型调用 API(2020-2023) | 单模态 / 一问一答 | text → model → text |
| 多模态交互 API(2023-2024) | 支持图文/语音,但仍串行 | image + text → model → text |
| 多通道处理协议(2024-) | 流式 / 实时 / 多模态协同 | audio + image + text → MCP → multi-output |
| 智能体协作协议(预期) | 多 Agent 并发调度,自治协同 | Agent1 + Agent2 + Tool → Protocol Layer → Response |
MCP 就是从第二阶段向第三阶段跃迁的关键协议。
它的出现预示着:
- 模型不再是单一响应工具,而是具备“并发感知”和“协同决策”的智能处理体
- 多通道协同是“智能涌现”的前置条件
- 协议将逐步成为智能体之间的“语言”,就像 HTML 是网页的语言一样
🌐 MCP 未来将走向哪里?三大演化方向
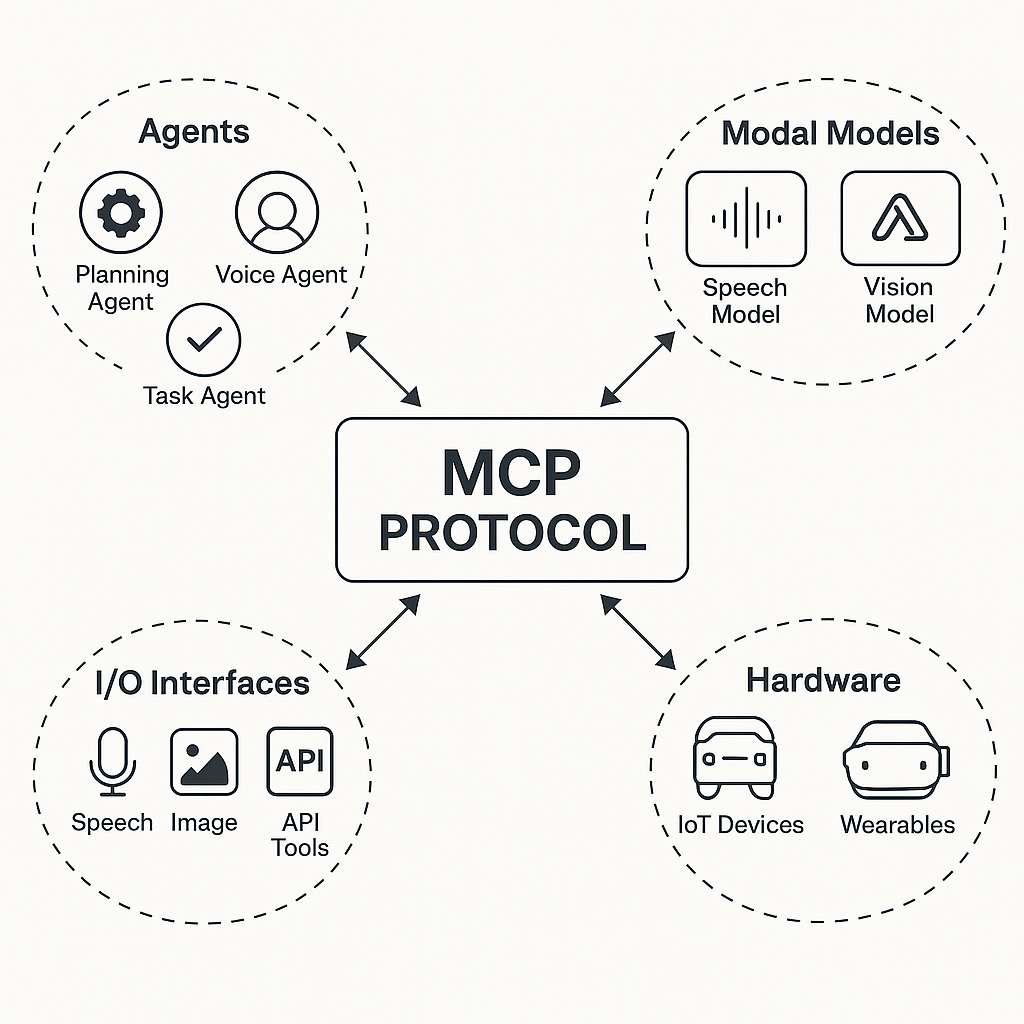
1️⃣ 向下开放:支持第三方模型适配 MCP
- 目前 MCP 主要用于 GPT-4o 系列,但如果协议文档开源,将允许:
- Whisper.cpp、Bark、Gemma 等模型适配为 MCP-compatible 模型
- Hugging Face 或企业内模型通过 Wrapper 接入 MCP 流
📦 这会带来一个生态的想象空间:所有开源模型之间用 MCP 通道对话
2️⃣ 向上扩展:构建智能体通信协议(MCP × Multi-Agent RPC)
- MCP 现阶段是“模型 I/O 层”,未来可上升为 Agent 层调度协议
- 每个 Agent 可注册通道,监听输入,转发输出,形成 “通道式协作网络”
举个例子:
用户说:总结这张图,并转成语音播报。
→ MCP Input: audio + image
→ Agent1: 图像理解 → Agent2: LLM 总结 → Agent3: TTS
→ MCP Output: audio_out(语音播报)
每个 Agent 本质上只处理自己的输入通道,MCP 成为多 Agent 协作的“消息总线”
3️⃣ 向侧边开放:接入设备、传感器、控制器等多类型通道
MCP 的通道机制并不限于人类输入,它可以用于:
- sensor_in:读取温度、动作、手势等环境信息
- device_out:控制智能设备(开关、投屏、设备震动等)
- system_feedback:接收系统状态,动态调整响应
📡 最终形态:MCP 作为 AI 运行时协议层,接通语言模型、Agent、设备与用户
✨ MCP 的野心与未来角色
| 角色 | 说明 |
|---|---|
| 模型 I/O 协议 | 多模态输入输出的统一调度 |
| 智能体通信协议 | 多 Agent 之间的事件信道 |
| AI 运行时中枢 | 驱动 Agent×模型×设备 的通用底层 |
| 多模态 RAG 支持层 | 文本、语音、图像查询的多通道协调 |
| 边云协同标准 | 在边缘计算场景下作为信号中介 |
如果 MCP 能够成为 开源协议 + 模型兼容层 + 调度中枢,那么它有可能成为:
“AI 时代的 WebSocket” —— 支撑一切多智能体系统运行的协议基础设施
🎁 全文总结 · 写给开发者与探索者
我们从第一章走到现在,完整梳理了 MCP 的来龙去脉。它不是一个 Buzzword,而是真正承载了未来 AI 协同运行逻辑的“协议大脑”。
未来你构建的任何 AI 系统 —— 无论是 Agent、助手、问答机器人、还是智能硬件系统,都极可能依赖:
✅ 多通道输入
✅ 流式实时反馈
✅ 多模型组合处理
✅ 多智能体交互
这一切,MCP 已经在架构层打下了基础。
你想要构建的不是“更复杂的模型堆叠”,而是“更聪明的通道协同”。
🎯 而现在,就是你上手 MCP 的最佳时机。
📌 写在最后
MCP 协议,作为多模态大模型时代的“通道大脑”,或许还只是刚刚露出地平线的一束曙光,但它所指向的方向,已经非常明确:
未来的 AI 不只是更大,而是更协同、更实时、更像人。
如果这篇文章让你对 MCP 有了更深的理解,也欢迎你做三件事👇:
👍 点个「赞」
让我知道你也看好 AI 通道协议的未来。
⭐ 收藏文章
方便以后复习,也许哪天你就要动手构建自己的多通道智能体了。
💬 评论区见
如果你对 MCP 有更多思考、应用设想,欢迎评论区交流,我们一起构建这个全新的智能协议生态。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











