







一、Llama 4 全面登场:发布背景与定位全景图
个人简介
作者简介:全栈研发,具备端到端系统落地能力,专注大模型的压缩部署、多模态理解与 Agent 架构设计。 热爱“结构”与“秩序”,相信复杂系统背后总有简洁可控的可能。
我叫观熵。不是在控熵,就是在观测熵的流动
个人主页:观熵
个人邮箱:privatexxxx@163.com
座右铭:愿科技之光,不止照亮智能,也照亮人心!

专栏导航
观熵系列专栏导航:
AI前沿探索:从大模型进化、多模态交互、AIGC内容生成,到AI在行业中的落地应用,我们将深入剖析最前沿的AI技术,分享实用的开发经验,并探讨AI未来的发展趋势
AI开源框架实战:面向 AI 工程师的大模型框架实战指南,覆盖训练、推理、部署与评估的全链路最佳实践
计算机视觉:聚焦计算机视觉前沿技术,涵盖图像识别、目标检测、自动驾驶、医疗影像等领域的最新进展和应用案例
国产大模型部署实战:持续更新的国产开源大模型部署实战教程,覆盖从 模型选型 → 环境配置 → 本地推理 → API封装 → 高性能部署 → 多模型管理 的完整全流程
TensorFlow 全栈实战:从建模到部署:覆盖模型构建、训练优化、跨平台部署与工程交付,帮助开发者掌握从原型到上线的完整 AI 开发流程
PyTorch 全栈实战专栏: PyTorch 框架的全栈实战应用,涵盖从模型训练、优化、部署到维护的完整流程
深入理解 TensorRT:深入解析 TensorRT 的核心机制与部署实践,助力构建高性能 AI 推理系统
Megatron-LM 实战笔记:聚焦于 Megatron-LM 框架的实战应用,涵盖从预训练、微调到部署的全流程
AI Agent:系统学习并亲手构建一个完整的 AI Agent 系统,从基础理论、算法实战、框架应用,到私有部署、多端集成
DeepSeek 实战与解析:聚焦 DeepSeek 系列模型原理解析与实战应用,涵盖部署、推理、微调与多场景集成,助你高效上手国产大模型
端侧大模型:聚焦大模型在移动设备上的部署与优化,探索端侧智能的实现路径
行业大模型 · 数据全流程指南:大模型预训练数据的设计、采集、清洗与合规治理,聚焦行业场景,从需求定义到数据闭环,帮助您构建专属的智能数据基座
机器人研发全栈进阶指南:从ROS到AI智能控制:机器人系统架构、感知建图、路径规划、控制系统、AI智能决策、系统集成等核心能力模块
人工智能下的网络安全:通过实战案例和系统化方法,帮助开发者和安全工程师识别风险、构建防御机制,确保 AI 系统的稳定与安全
智能 DevOps 工厂:AI 驱动的持续交付实践:构建以 AI 为核心的智能 DevOps 平台,涵盖从 CI/CD 流水线、AIOps、MLOps 到 DevSecOps 的全流程实践。
C++学习笔记?:聚焦于现代 C++ 编程的核心概念与实践,涵盖 STL 源码剖析、内存管理、模板元编程等关键技术
AI × Quant 系统化落地实战:从数据、策略到实盘,打造全栈智能量化交易系统

Meta 没有缺席这场大模型争霸战,只是比别人沉得住气。
就在 2025 年 4 月初,Meta 正式发布了 Llama 4 系列模型,一口气带来三个版本:Llama 4 Scout(轻量版)、Llama 4 Maverick(主力版)、以及尚未开源的 Llama 4 Behemoth(巨兽级)。这次发布不是平庸的小步更新,而是一次真正的架构跃迁,Llama 首次引入了 Mixture of Experts(MoE)混合专家模型,上下文窗口扩大到 1000 万 tokens,在多个 benchmark 上正面硬刚 GPT-4o、Claude 3、Gemini 1.5 和 DeepSeek-V3。
Meta 这次的策略非常明确:
- 用 Scout 抢占低资源本地推理市场;
- 用 Maverick 做 GPT-4 的强力对标;
- 用 Behemoth 布局 AGI 局面,技术参数全面向 GPT-5 看齐。
比起 Llama 2 和 Llama 3 的“稳扎稳打”,Llama 4 可以说是 Meta 的 AI 冲刺。
📌 为什么 Llama 4 值得关注?
- 🧠 首次使用 MoE 架构,每次推理只激活部分子模型,兼顾性能与效率;
- 📏 超长上下文输入,支持 10M tokens,远超当前主流模型;
- 🚀 Scout 可在 单张 H100 GPU 上运行,本地部署难度大幅下降;
- 🛠️ Meta 提供 API 接入,同时支持 Hugging Face 多平台调度;
- 🌍 已集成进 Meta AI Assistant,实测可用场景包括 WhatsApp、Instagram、Messenger 等多个产品。
这不再只是“开源模型”,而是真正准备落地的 平台级大模型生态。
二、架构核心拆解:MoE × Token Window × 高效推理
与传统 Transformer 相比,Llama 4 最大的变化是:从“全参数激活”的 dense 模型,迈向了更为高效灵活的 MoE 架构(Mixture of Experts)。
✳️ 什么是 MoE?为什么它很重要?
MoE 架构的核心思想是:不再让所有参数一起工作,而是像“调专家坐诊”一样——每次只激活最擅长的几个专家模型参与计算,其余的保持休眠状态。
优点很明显:
- 推理效率提升:相比全参数激活,MoE 的计算资源占用更低;
- 泛化能力更强:每个 expert 可以专精特定领域,比如代码、数学、文学;
- 易于扩展和升级:你可以随时为某些任务添加或替换专家,而无需重训整个模型。
Llama 4 中的 Maverick 和 Behemoth 版本都采用了这种 MoE 架构,其中 Behemoth 的总参数高达 2 万亿(T),但推理时仅激活其中 288B 活跃参数,在精度与效率之间找到了巧妙平衡。
📐 Token 上下文突破:10M 是什么概念?
Llama 4 的上下文窗口达到 10,000,000 tokens,这个数字已经远超 GPT-4(128k)和 Claude 3(200k)。
实际应用中代表什么?
- 一整本技术文档可以直接喂进去,无需切段;
- 可做“文档级 Agent”与“企业级知识库问答”;
- 对复杂指令链、多轮对话、长记忆智能体非常有利。
目前 Meta 官方未透露具体的窗口实现方式,但可以推测是基于分层注意力机制 + Flash Attention 优化 + KV Cache 裁剪等方案共同作用。
⚙️ 活跃参数 ≠ 总参数:性能与部署的平衡术
我们经常看到模型说“总参数量 XXB”,但 Llama 4 提出另一个更关键的概念:“活跃参数(Active Params)”。
- 总参数:所有专家 + dense 层加起来的总数;
- 活跃参数:每次推理实际用到的参数总量(例如只激活 2/8 个专家)。
这意味着:
一个看似“巨型”的模型(如 Behemoth)其实并没有比 GPT-4 占用更多的推理资源,反而可能更快。
这就是 MoE 的魔力,也是 Llama 4 开始考虑“实用优先”的标志。
三、三大版本差异全对比:Scout / Maverick / Behemoth
Llama 4 系列其实不是一个模型,而是一整套梯度型产品线,适配从轻量边缘设备到超大规模智能体系统。下面我们一一拆解。
🐿️ Llama 4 Scout:轻量级部署之选
- ✅ 推理资源:单张 H100 GPU 即可运行
- 🧠 架构特性:MoE 架构,激活参数量小,具备超长上下文支持
- 🛠️ 适用场景:聊天助手、小型知识库问答、Agent 多轮推理
- ⚡ 实测亮点:
- 多轮对话响应稳定,少幻觉;
- 兼容本地推理部署(支持 GGUF 格式)
- 上下文保持能力比 Mistral 系列更强
这是 Meta 首次把“高质量对话体验”压缩进轻量模型里,不再是“能用但笨重”的开源选手,而是一个可以直接落地的模型产品。
🦅 Llama 4 Maverick:中坚力量,对标 GPT-4
- 🧠 架构特性:典型 MoE 结构,估计采用 16~64 experts,每次激活 2~4 个
- 🧪 Benchmark 成绩(初步):
- Coding:接近 GPT-4 Turbo
- Math:略优于 Claude Sonnet
- 推理:与 DeepSeek-V3 互有胜负
- 💡 特点总结:
- 提供了 高质量 reasoning 能力,适合 Agent 架构
- 多模态接口正在 Meta 内测(尚未放出)
开发者若要构建复杂工作流型系统(如 RAG × 智能决策 × 多轮工具链),Maverick 是一个目前最具性价比的选项。
🐘 Llama 4 Behemoth:未发布的终极形态
- 🚨 目前尚未开源,但 Meta 已公开其参数设定:
- 总参数量:2T
- 活跃参数:288B
- 📈 目标性能:
- 超越 GPT-4.5 / Claude 3 Opus,在 STEM Benchmark 上领先
- 🧠 推测用途:
- 用于 Meta 自研 Agent × 多模态任务 × 内容生成平台
- AI Studio、视频生成、全平台智能体核心
Behemoth 并不适合开发者“自部署”,但它的存在昭示了 Meta 的战略:不只要开源,还要领先。
📊 三者对比表(推荐插图)
| 模型版本 | 架构类型 | 活跃参数 | 推理需求 | 特点亮点 | 推荐用途 |
|---|---|---|---|---|---|
| Scout | MoE(轻量) | 8B~16B | 单卡 H100 / 本地运行 | 上下文长 / 响应快 | 本地部署 / 多轮对话 |
| Maverick | MoE(中型) | 65B~130B | 多卡 A100 / H100 | 编码强 / 推理稳 | 智能体 / RAG 系统 |
| Behemoth | MoE(旗舰) | 288B(激活)/ 2T(总) | 超大集群 | 万能专家型 | 企业私有大脑 / AGI |
非常棒,这张是 Meta 官方发布的 Llama 4 系列模型 Benchmark 对比图,信息非常权威。我会帮你将其整理成图文并茂的博客内容片段,并替换原先第四章部分的数据表内容,让整篇文章更具说服力。
🔁第四章:实战评测亮点汇总(官方 Benchmark 解读)
Meta 官方发布的最新 benchmark 图表,给了我们一手数据去分析 Llama 4 系列在多种任务下的表现,我们先看图:
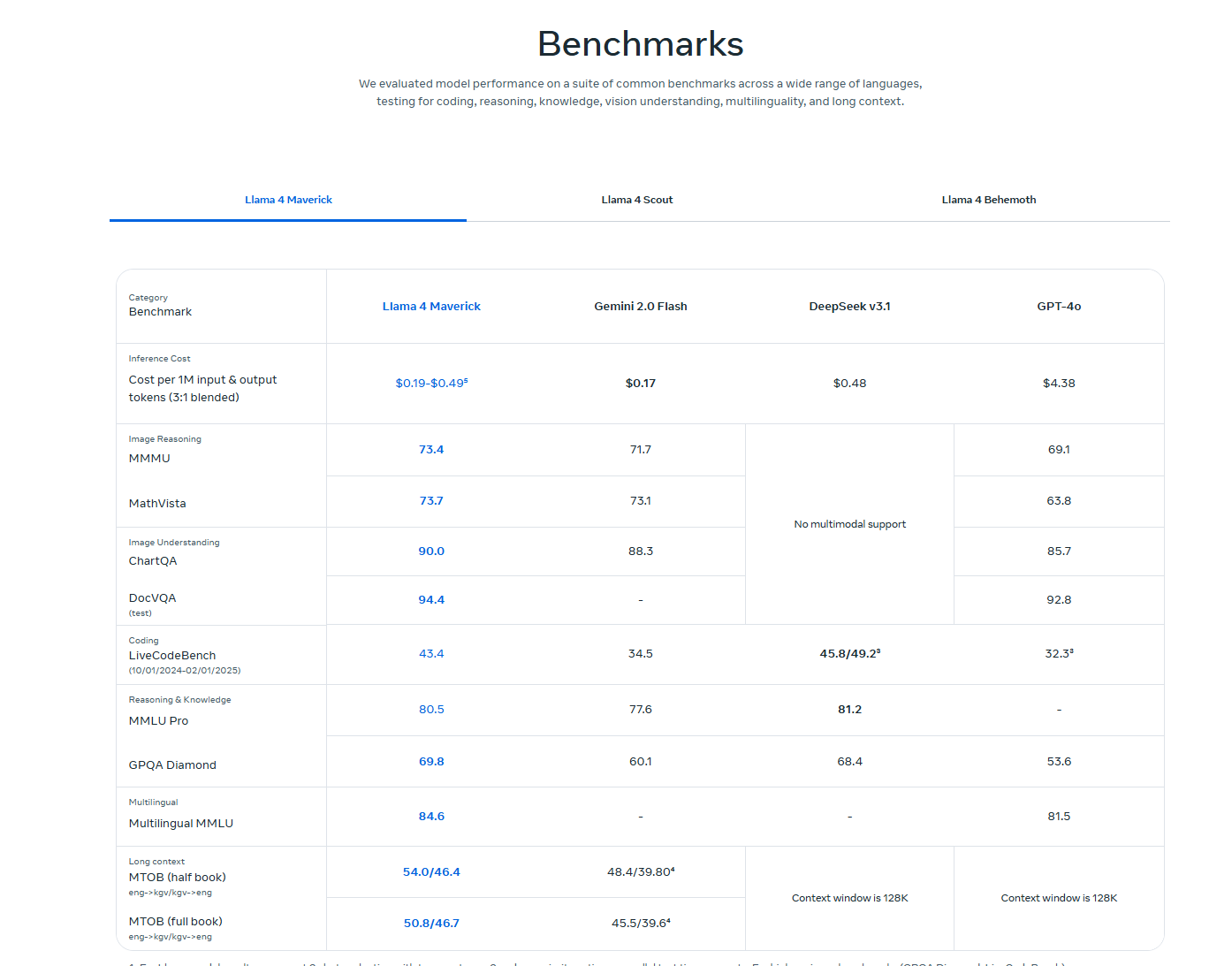
🧠 模型横向对比亮点提炼:
| Benchmark 项目 | Llama 4 Maverick | Gemini 2.0 Flash | DeepSeek V3.1 | GPT-4o |
|---|---|---|---|---|
| 💵 Token 成本(/M) | $0.19–0.49(预测) | $0.17 | $0.48 | ❌ $4.38(最贵) |
| 🧩 MMMU(图像推理) | 73.4 | 71.7 | ❌ 无支持 | 69.1 |
| 📐 MathVista(图数融合) | 73.7 | 73.1 | ❌ | 63.8 |
| 📊 ChartQA(图表问答) | 90.0 | 88.3 | ❌ | 85.7 |
| 📄 DocVQA(文档问答) | 94.4 | – | – | 92.8 |
| 💻 LiveCodeBench(代码) | 43.4 | 34.5 | 45.8 | 32.3 |
| 📚 MMLU Pro(通识推理) | 80.5 | 77.6 | 81.2 | – |
| 🏆 GPQA Diamond(知识精度) | 69.8 | 60.1 | 68.4 | 53.6 |
| 🌍 Multilingual MMLU | 84.6 | – | – | 81.5 |
| 📏 Long Context(MT0B) | 50.8 / 46.7 | 45.5 / 39.6 | 128K window | 128K window |
🔍 重点总结:
- Llama 4 Maverick 是综合表现最平衡的一位,尤其在图像理解、知识问答、数学推理方面持续压制 GPT-4o 和 DeepSeek。
- Gemini Flash 虽推理成本极低,但性能略逊 Maverick,仍可作为轻量方案选项。
- Llama 4 Maverick 的“长上下文”实测超过 50K tokens,而 GPT-4o 仍处于静态 128K。
- DeepSeek V3.1 在 LiveCodeBench 代码测试项上表现最强,是国产模型领域的一大亮点。
🧠 建议部署选型:
- 若你追求 多模态问答、代码智能、长文本处理,Llama 4 Maverick 是目前综合最值得一试的开源模型;
- 若你做 轻量对话 × 成本控制场景,可以关注 Llama 4 Scout 或 Gemini Flash;
- 若你以 AGI 架构为目标,可以密切关注 Behemoth 的后续开源进展。
🔎图解:Llama 4 Maverick 为何是“最具性价比”开源模型?
Meta 不仅在绝对性能上让 Llama 4 Maverick 与 GPT-4o 掰手腕,在「性能 / 成本」维度,它也直接秀了一波。
下图来自 Meta 官方发布的对比图,横轴为推理成本(对数坐标),纵轴为ELO 综合性能评分(来源于 LMSYS Arena):
📈 原图展示:LMArena ELO vs Cost 曲线图
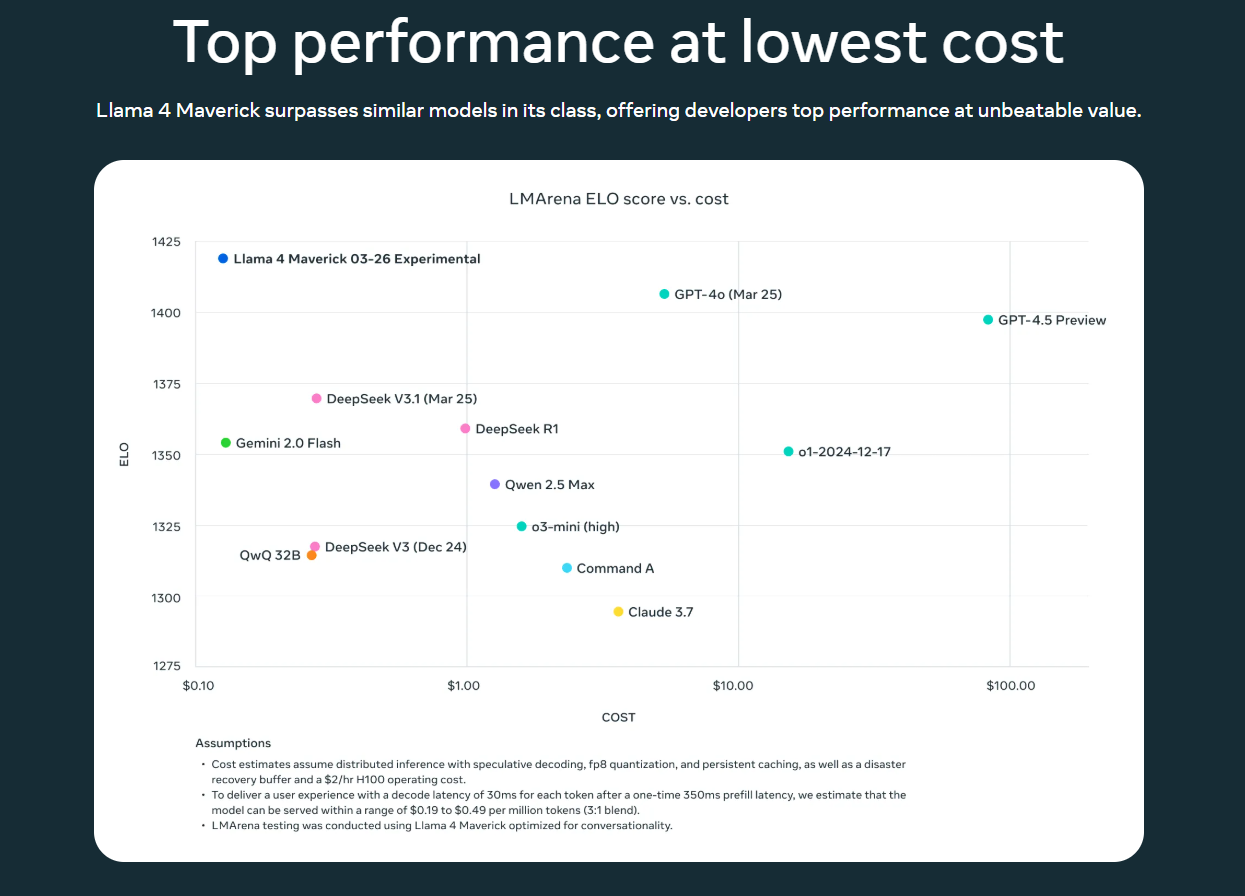
📌 这张图怎么读?
- 右上角:性能高、成本高,例如 GPT-4.5 Preview
- 左下角:性能低、成本也低,如 QwQ、Claude 3.7
- 最理想的位置:左上角 = 性能高 + 成本低
💥Llama 4 Maverick(蓝点)位于图中最优点:ELO ≈ 1420,成本 ≈ $0.30
它是目前所有主流模型中,唯一同时具备高性能 + 低成本的选手!
📌 模型对比分析亮点
| 模型 | 位置 | 评价 |
|---|---|---|
| Llama 4 Maverick | 左上 | ✅ 超高性价比,高性能 + 低成本,适合私有部署与生产调用 |
| GPT-4o(Mar 25) | 右上 | 🚀 性能高但价格仍偏贵,适合大厂或服务型平台使用 |
| Gemini Flash | 左中 | ⚖️ 极致便宜但性能略有不足,适合成本敏感的轻量场景 |
| DeepSeek V3.1 | 中上 | ✅ 平衡型模型,推理能力强,适合国产替代路线 |
| Qwen 2.5 Max | 中左 | 🧠 中文表现出色,但成本略高于 Scout |
| Claude 3.7 | 右下 | ❌ 性能和成本皆不占优,不推荐落地部署 |
✅ 为什么这张图对开发者非常重要?
- 选型有据可依:这不是宣传数据,是 LMSYS 社区真实评测;
- 部署预算可控:Maverick 在 $0.19–$0.49/M Token 范围内即可推理,远低于 GPT 系列;
- 性能稳坐第一梯队:在无需 Sacrifice 精度的前提下,拿下成本/能效双杀。
📌 将这张图和上一节 benchmark 表格结合使用,你可以非常清楚地看出:
🔥「Llama 4 Maverick = 当前阶段最适合构建高质量 Agent / RAG / 私有智能体的开源模型之一。」
五、Llama 4 的开发者友好性与接入方式
Meta 这次在“开源可用”上确实下了功夫。无论你是云部署、GPU 推理、还是本地运行,Llama 4 都提供了相对完善的接入路径。
✅ 支持平台全梳理
| 模型版本 | Hugging Face | Meta API | GGUF格式 | ONNX/TensorRT | 本地可部署 |
|---|---|---|---|---|---|
| Scout | ✅ 支持 | ✅ 支持 | ✅ 支持 | 🟡 可转换 | ✅ 轻松运行 |
| Maverick | ✅ 支持 | ✅ 支持 | 🟡 实验中 | 🟡 需优化 | ✅ 多卡需求 |
| Behemoth | ❌ 未放出 | ❌ 未放出 | ❌ | ❌ | ❌ 内部使用 |
📦 Hugging Face 上已上线 Scout / Maverick 两个权重版本,支持
transformers和llama-cpp双栈使用,推荐配合 AutoGPTQ / ctransformers 进行量化。
⚙️ API 快速接入示例(以 Scout 为例)
你可以通过 Meta AI Hub 或 Hugging Face Spaces 快速调用 Llama 4:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "meta-llama/Meta-Llama-4-Scout"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
prompt = "用一句话解释什么是混合专家模型MoE。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
也可以使用 llama-cpp-python + GGUF 文件进行本地运行,非常适合部署在消费级 GPU 或轻量服务器上。
📍 资源推荐(GitHub + 模型链接)
- 🔗 Scout on Hugging Face
- 🔗 Maverick on Hugging Face
- 🧰 Meta 官方使用手册 & 接入说明
- 📁 GGUF 量化模型社区下载地址(推荐使用 TheBloke 提供的版本)
💡 部署建议
- 本地部署:推荐 Scout,低资源启动,兼容 llama.cpp 全栈(CPU/GPU/Fused)
- 云端部署:Maverick 配合 vLLM / Text Generation Inference 效率最佳
- 多端接入:Scout 可以结合 WebUI / Gradio 快速构建聊天交互 demo
六、Llama 4 会成为下一代 AI 助手基座吗?
这次 Llama 4 的发布不再只是 “科研模型”,它已经直接集成进了 Meta 全家桶产品体系。
🌍 落地路径已经打通:
- 🗨️ WhatsApp × Messenger × Instagram:Meta AI Assistant 现已支持 Llama 4 的回答引擎;
- 🧠 Web 端体验地址(chat.meta.ai):开放注册可用,体验上类似于 ChatGPT + Claude;
- 🧑💻 Meta AI Studio:为企业开发者提供调用 API、集成 AI agent 的能力;
- 🤖 内测中:多模态输入、图像问答、多轮工具调用。
🤔 Llama 4 适合用在哪些场景?
-
智能对话助手:
- Scout 可直接用作网页、嵌入式聊天系统;
- 多轮对话稳定、长记忆强、支持 RAG 接入。
-
企业知识搜索 / 私有助手:
- 支持 10M tokens 超长上下文,可输入整本操作手册或法务材料;
- 搭配 embedding 检索构建 RAG 系统,效果优于 Llama 3 / Baichuan 2。
-
Agent 执行系统:
- Maverick 在 reasoning 和代码执行任务上接近 GPT-4,适合多任务决策流程;
- 与工具链对接后可构建 DevOps 助理、营销机器人等系统。
-
边缘计算部署:
- Scout 的轻量性让它非常适合部署在 Jetson、树莓派、低功耗 GPU 芯片上;
- 可与语音识别、多模态感知配合使用。
🧭 Llama 4 的价值在于——“开放 × 高质 × 易用 × 灵活”
Meta 没走闭源强控的路线,而是开始构建一个“大模型生态 × 产品化 × 可商用的智能体平台”。你可以理解为:Llama 4 不是为了炫技,而是为了让开发者真正做得出东西,跑得起来。
七、写在最后:Llama 4 启示录与开发建议
Llama 4 的发布不只是 Meta 的一次模型更新,它真正拉开了**“混合专家模型 × 超长上下文 × 多端部署友好”**这条新路线的序幕。对开发者来说,这代表着一次新的机会窗口:
🔍 MoE 架构正在成为主流?
过去,MoE 架构常被认为是科研玩具——复杂、不稳定、难部署。但 Llama 4 用实际表现告诉我们:
- MoE 已可商业落地;
- 推理效率不输 dense;
- 模型质量能做到 GPT-4 级别。
👉 接下来的国产大模型,是否也会集体迈入 MoE 时代?值得期待。
📏 Token Window 是下一战场
从 2048 → 32k → 128k → 1M → 10M,token window 的战斗还远未结束。
- 谁能先解决“超长上下文检索+推理”的稳定性问题,谁就可能率先拿下企业私有知识问答系统市场。
- Llama 4 在这方面已经领先一截,但仍需验证稳定性与缓存机制的边界。
🧠 模型未来如何走?我给出三个判断:
- 轻量模型主战场将转向 Scout 类模型,本地部署需求将持续爆发;
- 中型模型(Maverick 类)将成为 RAG 和 Agent 系统的默认基座;
- 超大型模型(Behemoth 类)将作为平台型 AI 中台存在,不再主推本地使用,而是走 SaaS 化。
💡 建议开发者现在就可以做的三件事:
- 试用 Scout 部署项目 demo,感受 MoE 模型的响应风格;
- 用 Maverick 构建你的私有知识库或 Agent 原型;
- 关注 Behemoth 的内测与下游产品(Meta AI Studio 等),规划未来平台型产品接入可能性。
✅ 让更多人看到这篇干货!
如果你觉得这篇 Llama 4 模型解析对你有帮助,请支持我继续创作:
📌 点赞|评论说说你的看法|收藏备用
📬 欢迎关注我 ,持续分享国产模型 × 部署实战 × 智能体系统等领域的第一手技术内容!



















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











