







前言
说到正则化大家应该都不陌生,这个在机器学习和深度学习中都是非常常见的,常用的正则化有L1正则化和L2正则化。提到正则化大家就会想到是它会将权重添加到损失函数计算中来降低模型过拟合的程度。了解更多一点的同学还会说,L1正则化会让模型的权重参数稀疏化(部分权重的值为0),L2正则化会让模型的权重有趋于0的偏好。
不知道大家有没有想过为什么L1正则化会让部分权重的值为0?为什么L2正则化会让权重会有偏向于0?为什么正则化可以防止过拟合?正则化究竟是怎么来的? 带着这些问题,我们来看这篇文章,会帮助大家一一解答。
正则化的由来
在介绍正则化之前,我们先来看一张图
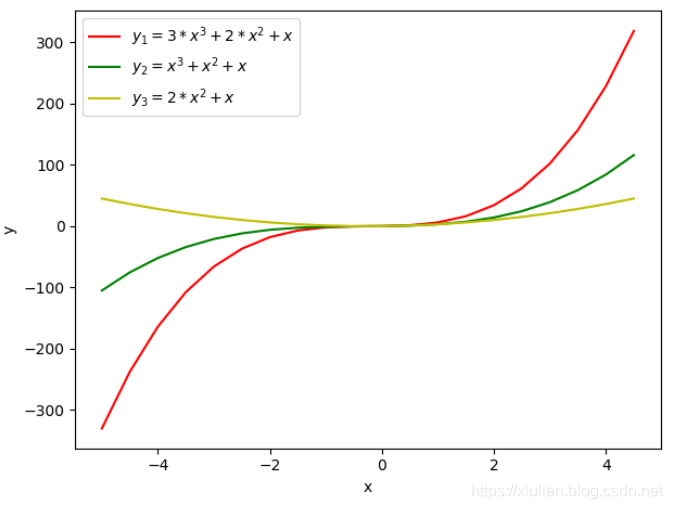
在上图中我们绘制了三条不同的曲线
y
1
、
y
2
、
y
3
y_1、y_2、y_3
y1、y2、y3,从曲线函数值的变化不难看出,
y
1
y_1
y1的函数值变化最大,
y
2
和
y
3
y_2和y_3
y2和y3的函数值相对来说要平缓一些。通过函数的表达式可以看出,
y
2
y_2
y2相对于
y
1
y_1
y1来说自变量的系数值变小了,
y
3
y_3
y3相对
y
1
y_1
y1来说自变量少了一个,我们可以理解为少的那个自变量的系数为0。
通常如果函数的取值变化的幅度更大,我们会认为函数更复杂,函数的方差更大。所以,上面的三个函数中,函数
y
1
y_1
y1的复杂度最高。通过函数图像可以发现,降低自变量的系数值,或者减少函数自变量的个数等价于自变量的系数为0是可以降低函数复杂度的。
在构建模型之前,我们是不知道数据的分布,如果模型过于简单就会导致欠拟合,如果模型过于复杂就会过拟合。通常我们为了模型能够更好的拟合数据都是使得模型处于过拟合,为了降低模型的过拟合就需要使得模型部分权重为0或者降低模型的权重,所以我们会为损失函数添加一个惩罚项,数学表达式如下
J
~
(
θ
;
X
,
y
)
=
J
(
θ
;
X
,
y
)
+
α
Ω
(
θ
)
\widetilde J(\theta;X,y)=J(\theta;X,y) + \alpha \Omega(\theta)
J
(θ;X,y)=J(θ;X,y)+αΩ(θ)
上式中的
J
(
θ
;
X
,
y
)
J(\theta;X,y)
J(θ;X,y)表示原目标函数(没有添加正则化),
Ω
(
θ
)
\Omega(\theta)
Ω(θ)表示模型参数的惩罚项,惩罚项系数
α
∈
[
0
,
∞
)
\alpha\in[0,\infty)
α∈[0,∞),
α
\alpha
α越大表示正则化惩罚越大。
需要注意:我们在对模型的参数做惩罚的时候,其实只是添加了模型的权重参数并不包括偏置参数,因为模型的偏置参数数量相对于权重参数数量来说要少的多,而且每个权重参数会指定两个变量如何相互作用,而偏置只是控制一个单一的变量,所以我们不对偏置做正则化也不会导致太大的方差。而且,如果对偏置进行正则化可能会导致明显的欠拟合。
上式中的参数
θ
\theta
θ包含了权重和偏置,而我们只需要对权重做正则化。所以,L1正则化和L2正则化可以改成如下表达式
J
~
(
ω
;
X
,
y
)
=
J
(
ω
;
X
,
y
)
+
α
Ω
(
ω
)
l
1
:
Ω
(
ω
)
=
∥
ω
∥
1
=
∑
i
=
1
n
∣
ω
i
∣
l
2
:
Ω
ω
=
∥
ω
∥
2
2
=
∑
i
=
1
n
ω
i
2
\begin{aligned} &\widetilde J(\omega;X,y) = J(\omega;X,y) + \alpha \Omega(\omega)\\ &l_1:\Omega(\omega) = \|\omega\|_1=\sum_{i=1}^{n}{|\omega_i|}\\ &l_2:\Omega{\omega} = \|\omega\|_2^2=\sum_{i=1}^{n}{\omega_i^2}\\ \end{aligned}
J
(ω;X,y)=J(ω;X,y)+αΩ(ω)l1:Ω(ω)=∥ω∥1=i=1∑n∣ωi∣l2:Ωω=∥ω∥22=i=1∑nωi2
正则化的影响
在正则化的由来中,我们直观的介绍了为什么需要加入正则化?接下来我们来介绍一下为什么
l
1
l_1
l1正则化会使得模型的部分参数为0,
l
2
l_2
l2正则化会使得模型的参数接近0。为了更好的证明,接下来的公式可能会有点多,不过我会尽可能的详细让大家更好的理解
1.直观理解
为了帮助大家从直观上理解正则化的效果,接下来我们将通过画图来观察
l
1
l_1
l1正则化和
l
2
l_2
l2正则化的效果
前面我们介绍了正则化其实就是在原代价函数的基础上多增加了一项参数的惩罚项,目的就是为了不让网络的参数过大而导致模型过拟合,所以我们其实可以将正则化后的代价函数理解为在最小化原代价函数的基础上多增加了一个参数的约束函数,对于约束函数的要求就是它需要小于某个常数C
J
~
(
ω
;
X
,
y
)
=
J
(
ω
;
X
,
y
)
+
α
Ω
(
ω
)
=
>
m
i
n
J
(
ω
;
X
,
y
)
s
.
t
.
α
Ω
(
ω
)
≤
C
\begin{aligned} &\widetilde J(\omega;X,y)=J(\omega;X,y) + \alpha\Omega(\omega) =>\\ &minJ(\omega;X,y) \\ &s.t.\alpha\Omega(\omega) \leq C \end{aligned}
J
(ω;X,y)=J(ω;X,y)+αΩ(ω)=>minJ(ω;X,y)s.t.αΩ(ω)≤C
- l 1 l_1 l1正则化
我们将
l
1
l_1
l1正则化效果等价于求原代价函数的最小值和对权重参数的约束函数,这里为了便于作图我们只考虑二维情况
m
i
n
J
(
ω
;
X
,
y
)
s
.
t
.
a
l
p
h
a
Ω
(
ω
)
=
∑
i
=
1
n
∣
ω
∣
=
∣
ω
1
∣
+
∣
ω
2
∣
≤
C
\begin{aligned} &minJ(\omega;X,y)\\ &s.t.alpha\Omega(\omega)=\sum_{i=1}^{n}|\omega|=|\omega_1|+|\omega_2|\leq C \end{aligned}
minJ(ω;X,y)s.t.alphaΩ(ω)=i=1∑n∣ω∣=∣ω1∣+∣ω2∣≤C
根据上两个式子,我们可以绘制出线性规划图如下
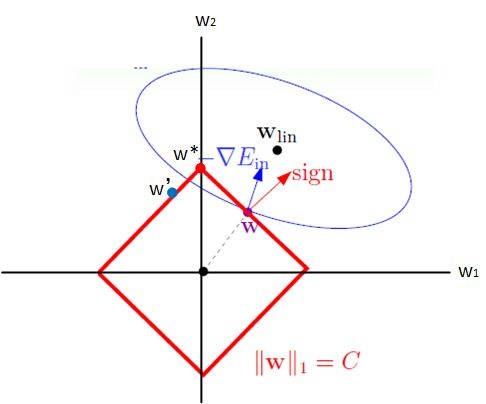
上图中的蓝色椭圆表示的是原代价函数的等高线,红色矩形表示的是权重的约束函数,图中的红色箭头表示的是约束函数的法向量方向,其中蓝色箭头表示的是原代价函数在该点的梯度方向(等高线的梯度方向与它的法向量方向一致)
因为约束函数的限制导致
ω
\omega
ω只能在红色矩形的边上进行移动来寻找最佳的
ω
∗
\omega^*
ω∗。当
ω
\omega
ω处于上图中的位置时,将原代价函数的梯度分解为沿约束函数的切线方向(即矩形的边)和法线方向,为了使得原代价函数取得最小值此时需要沿着梯度在约束函数的切线方向(左上方)移动。当
ω
\omega
ω移动到
ω
′
\omega'
ω′时,通过分解原代价函数的梯度可以发现,为了使得取得原代价函数的最小值应该沿着右上方移动,所以最终最优的
ω
∗
\omega^*
ω∗应该为矩形的顶点位置。
通过观察可以发现此时 ω ∗ \omega^* ω∗在坐标轴 ω 1 \omega_1 ω1方向的取值为0,这也就是为什么 l 1 l_1 l1正则化会使得权重参数稀疏的原因。
- l 2 l_2 l2正则化
同样,我们按照分析
l
1
l_1
l1正则化的思路进行分析
m
i
n
J
(
ω
;
X
,
y
)
α
Ω
(
ω
)
=
∑
i
=
1
n
ω
i
2
=
ω
1
2
+
ω
2
2
≤
C
\begin{aligned} &minJ(\omega;X,y)\\ &\alpha\Omega(\omega)=\sum_{i=1}^{n}\omega_i^2=\omega_1^2+\omega_2^2 \leq C \end{aligned}
minJ(ω;X,y)αΩ(ω)=i=1∑nωi2=ω12+ω22≤C
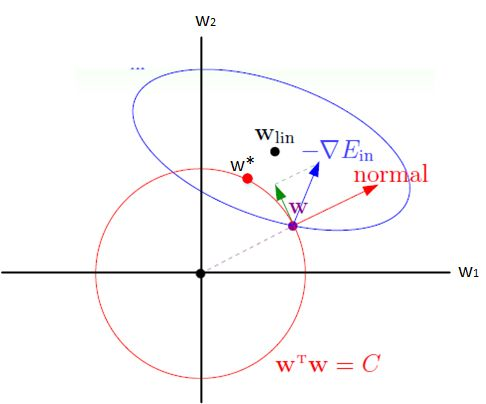
上图中蓝色椭圆表示是原代价函数的等高线,红色圆表示的是权重的约束函数它的半径是
C
\sqrt C
C,其中蓝色箭头表示的是原代价函数在该点的梯度方向,红色箭头表示的是约束函数在该点的法向量方向,绿色箭头表示的是约束函数在该点的切线方向。
还是按照上面的思想我们将梯度按切线方向和法线方向进行分解,为了使得原代价函数取得最小值,我们需要将
ω
\omega
ω按切线方向进行移动,当移动到
ω
∗
\omega^*
ω∗时,梯度方向与切线方向垂直时梯度沿切线方向的分量为0,此时原代价函数取得最小值,所以
ω
∗
\omega^*
ω∗为最优点。
通过观察上图可以发现,此时 ω 1 \omega_1 ω1的取值接近于0,这也就是为什么 l 2 l_2 l2正则化会使得权重趋于0的原因。
2.公式推导证明
- l 2 l_2 l2正则化
l
2
l_2
l2正则化也被称为权重衰减或岭回归,在神经网络中也被经常用到,因为它会使得权重向零点靠近(使得权重的取值趋于0)。为了更好的观察
l
2
l_2
l2正则化的影响,接下来我们观察一下在添加罚项之后,权重参数是如何更新的
l
2
正
则
化
:
J
~
(
ω
;
X
,
y
)
=
J
(
ω
;
X
,
y
)
+
α
2
ω
T
ω
对
应
的
梯
度
为
:
∇
ω
J
~
(
ω
;
X
,
y
)
=
∇
ω
J
(
ω
;
X
,
y
)
+
α
ω
\begin{aligned} & l_2正则化:\widetilde J(\omega;X,y) = J(\omega;X,y) + \frac{\alpha}{2}\omega^T\omega\\ & 对应的梯度为:\nabla_\omega\widetilde J(\omega;X,y) = \nabla_\omega J(\omega;X,y) + \alpha\omega \end{aligned}
l2正则化:J
(ω;X,y)=J(ω;X,y)+2αωTω对应的梯度为:∇ωJ
(ω;X,y)=∇ωJ(ω;X,y)+αω
使用单步梯度下降更新权重,更新公式如下:
ω
←
ω
−
ϵ
(
∇
ω
J
(
ω
;
X
,
y
)
+
α
ω
)
ω
←
(
1
−
ϵ
α
)
ω
−
ϵ
∇
ω
J
(
ω
;
X
,
y
)
\begin{aligned} & \omega \gets \omega - \epsilon(\nabla_\omega J(\omega;X,y) + \alpha\omega) \\ &\omega \gets (1-\epsilon\alpha)\omega - \epsilon\nabla_\omega J(\omega;X,y) \end{aligned}
ω←ω−ϵ(∇ωJ(ω;X,y)+αω)ω←(1−ϵα)ω−ϵ∇ωJ(ω;X,y)
上式中的,
ϵ
\epsilon
ϵ指的是学习率,
α
\alpha
α指的是权重衰减系数,这两个参数通常都是小于1的。
通过单步的权重的梯度更新公式可以发现,权重每次在更新之前都需要乘以一个小于1的系数,相当于每次更新权重的时候都对它做了衰减,在经过多次权重更新之后会,权重的系数会接近于0,最终会导致权重也接近0,假设权重的系数为0.9,经过100次权重的迭代更新,最终权重系数会变为
0.
9
100
≈
2.7
∗
1
0
−
5
0.9^{100}\thickapprox2.7*10^{-5}
0.9100≈2.7∗10−5(注:这里没有考虑梯度的大小,只是简单表明这种趋势)。
上面只是一个单步的权重更新过程,接下来我们推导一下在整个训练过程中,权重的更新过程,为了简化分析我们假设
ω
∗
\omega^*
ω∗为
J
(
ω
)
J(\omega)
J(ω)取得最小值时的权重向量,根据泰勒公式
f
(
x
)
=
f
(
x
0
)
0
!
+
f
′
(
x
0
)
1
!
(
x
−
x
0
)
+
f
′
′
(
x
−
x
0
)
2
!
(
x
−
x
0
)
2
+
.
.
.
+
f
(
n
)
(
x
−
x
0
)
n
!
(
x
−
x
0
)
n
+
R
(
x
)
n
\begin{aligned} {f(x)=\frac{f(x_0)}{0!}}+\frac{f^{'}(x_0)}{1!}(x-x_0)+\frac{f^{''}(x-x_0)}{2!}(x-x_0)^2+... \\+\frac{f^{(n)}(x-x_0)}{n!}(x-x_0)^n+R(x)^n \end{aligned}
f(x)=0!f(x0)+1!f′(x0)(x−x0)+2!f′′(x−x0)(x−x0)2+...+n!f(n)(x−x0)(x−x0)n+R(x)n
假设
J
(
ω
)
J(\omega)
J(ω)二阶可导,我们对其进行二次近似的泰勒展开则有
J
^
(
ω
)
=
J
(
ω
∗
)
0
!
+
J
′
(
ω
∗
)
1
!
(
ω
−
ω
∗
)
+
J
′
′
(
ω
∗
)
2
!
(
ω
−
ω
∗
)
2
因
为
J
(
ω
)
在
ω
∗
取
得
最
小
值
,
所
以
J
′
(
ω
∗
)
=
0
,
令
J
′
′
(
ω
∗
)
=
H
J
^
(
ω
)
=
J
(
ω
∗
)
+
1
2
(
ω
−
ω
∗
)
T
H
(
ω
−
ω
∗
)
\begin{aligned} & \hat{J}(\omega) =\frac{J(\omega^*)}{0!}+\frac{J^{'}(\omega^*)}{1!}(\omega-\omega^*)+\frac{J^{''}(\omega^*)}{2!}(\omega-\omega^*)^2\\ &因为J(\omega)在\omega^*取得最小值,所以J^{'}(\omega^*)=0,令J^{''}(\omega^*)=H\\ & \hat{J}(\omega) = J(\omega^*) +\frac{1}{2}(\omega-\omega^*)^TH(\omega-\omega^*) \end{aligned}
J^(ω)=0!J(ω∗)+1!J′(ω∗)(ω−ω∗)+2!J′′(ω∗)(ω−ω∗)2因为J(ω)在ω∗取得最小值,所以J′(ω∗)=0,令J′′(ω∗)=HJ^(ω)=J(ω∗)+21(ω−ω∗)TH(ω−ω∗)
为了让
J
^
(
ω
)
\hat{J}(\omega)
J^(ω)取得最小值,我们令其导数为0,因为
J
(
ω
∗
)
{J}(\omega^*)
J(ω∗)为常数,所以它的导数为0,我们就直接省略了
∇
ω
J
^
(
ω
)
=
H
(
ω
−
ω
∗
)
=
0
\nabla_\omega\hat{J}(\omega)=H(\omega-\omega^*)=0
∇ωJ^(ω)=H(ω−ω∗)=0
接下来我们研究添加
l
2
l_2
l2正则化之后的对
J
^
(
ω
)
\hat{J}(\omega)
J^(ω)的影响,我们假设
ω
~
\widetilde\omega
ω
为
l
2
l_2
l2正则化之后
J
^
(
ω
)
\hat{J}(\omega)
J^(ω)的最优解,可得它的导数为
α
ω
~
+
H
(
ω
~
−
ω
∗
)
=
0
(
α
I
+
H
)
ω
~
=
H
ω
∗
ω
~
=
(
α
I
+
H
)
−
1
H
ω
∗
\begin{aligned} & \alpha\widetilde\omega+H(\widetilde\omega-\omega^*)=0 \\ & (\alpha I+H)\widetilde\omega = H\omega^* \\ & \widetilde\omega = (\alpha I + H)^{-1}H\omega^* \end{aligned}
αω
+H(ω
−ω∗)=0(αI+H)ω
=Hω∗ω
=(αI+H)−1Hω∗
上式中的
I
I
I表示的是单位矩阵,通过上式不难发现,当正则化的惩罚项系数
α
\alpha
α为0时,此时
ω
~
\widetilde\omega
ω
的最优解就等于
ω
∗
\omega^*
ω∗,接下来我们讨论一下当惩罚项系数不为0的时。因为
H
H
H是
J
J
J在
ω
∗
\omega^*
ω∗的Hessian矩阵,所以
H
H
H是一个对称矩阵,我们可以对其做特征分解,可得
H
=
Q
Λ
Q
T
H=Q\Lambda Q^T
H=QΛQT,其中
Λ
\Lambda
Λ为对角矩阵,
Q
Q
Q为一组特征向量的标准正交基,代入上式可得
ω
~
=
(
α
I
+
Q
Λ
Q
T
)
−
1
Q
Λ
Q
T
ω
∗
=
(
α
Q
I
Q
T
+
Q
Λ
Q
T
)
−
1
Q
Λ
Q
T
ω
∗
=
[
Q
(
α
I
+
Λ
)
Q
T
]
−
1
Q
Λ
Q
T
ω
∗
=
Q
(
α
I
+
Λ
)
−
1
Λ
Q
T
ω
∗
=
Q
Λ
α
I
+
Λ
Q
T
ω
∗
\begin{aligned} \widetilde\omega &= (\alpha I+Q\Lambda Q^T)^{-1}Q\Lambda Q^T\omega^*\\ &=(\alpha QIQ^T+Q\Lambda Q^T)^{-1}Q\Lambda Q^T\omega^*\\ &=[Q(\alpha I + \Lambda)Q^T]^{-1}Q\Lambda Q^T\omega^*\\ &=Q(\alpha I + \Lambda)^{-1}\Lambda Q^T\omega^*\\ &=Q\frac{\Lambda }{\alpha I+\Lambda}Q^T\omega^* \end{aligned}
ω
=(αI+QΛQT)−1QΛQTω∗=(αQIQT+QΛQT)−1QΛQTω∗=[Q(αI+Λ)QT]−1QΛQTω∗=Q(αI+Λ)−1ΛQTω∗=QαI+ΛΛQTω∗
通过上面的式子可以发现,
l
2
l_2
l2正则化的效果就是沿着
H
H
H矩阵特征向量所定义的轴缩放未正则化
J
(
ω
)
J(\omega)
J(ω)的解
ω
∗
\omega^*
ω∗。因为
I
I
I是单位矩阵,我们可以将缩放的系数改成这种形式
λ
i
λ
i
+
α
\frac{\lambda_i}{\lambda_i+\alpha}
λi+αλi,其中
λ
i
\lambda_i
λi指的是矩阵
H
H
H的特征向量每个轴值的大小,也就是特征分解之后特征值的大小。
通过修改后的衰减系数不难发现,当特征值
λ
i
≫
α
\lambda_i\gg \alpha
λi≫α时,此时
α
\alpha
α的影响可以忽略不计,正则化的缩放系数会趋于1,正则化基本没有影响。当特征值
λ
i
≪
α
\lambda_i\ll \alpha
λi≪α时,可以将缩放系数改为
1
α
λ
i
+
1
\frac{1}{\frac{\alpha}{\lambda_i}+1}
λiα+11,因为
α
≫
λ
i
\alpha \gg \lambda_i
α≫λi所以
α
λ
i
≫
1
\frac{\alpha}{\lambda_i} \gg 1
λiα≫1,所以缩放系数
λ
i
α
≪
1
,
\frac{\lambda_i}{\alpha} \ll 1,
αλi≪1,缩放系数趋于0使得权重也会趋于0。
- l 1 l_1 l1正则化
上面我们推导了添加了
l
2
l_2
l2正则化之后对权重的影响,通过最后推导得到式子可以解释为什么l2正则化会让权重趋于0。接下来,我们以类似的方式来推导
l
1
l1
l1正则化对于权重的影响
l
1
正
则
化
:
J
~
(
ω
;
X
,
y
)
=
J
(
ω
;
X
,
y
)
+
α
∥
ω
∥
1
梯
度
为
:
∇
ω
J
~
(
ω
;
X
,
y
)
=
∇
ω
J
(
ω
;
X
,
y
)
+
α
s
i
g
n
(
ω
)
\begin{aligned} & l_1正则化:\widetilde J(\omega;X,y) = J(\omega;X,y) + \alpha\|\omega\|_1 \\ & 梯度为:\nabla_\omega\widetilde J(\omega;X,y) = \nabla_\omega J(\omega;X,y) + \alpha sign(\omega) \end{aligned}
l1正则化:J
(ω;X,y)=J(ω;X,y)+α∥ω∥1梯度为:∇ωJ
(ω;X,y)=∇ωJ(ω;X,y)+αsign(ω)
上式中的sign函数为符号函数,函数图像如下

当函数输入值
x
<
0
x < 0
x<0时输出值恒等于-1,输入值为0时输出值也等于0,输入值
x
>
1
x>1
x>1时输出值恒等于1,sign函数经常被用来表示阶跃函数
我们将
J
(
ω
;
X
,
y
)
J(\omega;X,y)
J(ω;X,y)使用二阶的泰勒展开式来代替,可以将
l
1
l_1
l1正则化后的代价函数转换为如下形式
J
^
(
ω
)
=
J
(
ω
∗
)
+
1
2
(
ω
−
ω
∗
)
T
H
(
ω
−
ω
∗
)
+
α
∥
ω
∥
1
=
J
(
ω
∗
)
+
∑
i
[
1
2
H
i
,
i
(
ω
i
−
ω
i
∗
)
2
+
α
∣
ω
i
∣
]
\begin{aligned} \hat{J}(\omega) &= J(\omega^*) +\frac{1}{2}(\omega-\omega^*)^TH(\omega-\omega^*) + \alpha\|\omega\|_1\\ &=J(\omega^*) + \sum_{i}{[\frac{1}{2}H_{i,i}(\omega_i-\omega_i^*)^2+\alpha|\omega_i|]} \end{aligned}
J^(ω)=J(ω∗)+21(ω−ω∗)TH(ω−ω∗)+α∥ω∥1=J(ω∗)+i∑[21Hi,i(ωi−ωi∗)2+α∣ωi∣]
接下来我们看看如何求解
ω
i
\omega_i
ωi,上式中的
J
(
ω
∗
)
J(\omega^*)
J(ω∗)是常数我们不用考虑,主要考虑求和式中的二次项式和绝对值式来使得整个代价函数取得最小值,为了求得后两项和的最小值,我们对其求导并令求导后的结果等于0来求
ω
i
\omega_i
ωi
H
i
,
i
(
ω
i
−
ω
i
∗
)
+
α
s
i
g
n
(
ω
i
)
=
0
(
ω
i
−
ω
i
∗
)
+
α
H
i
,
i
s
i
g
n
(
ω
i
)
=
0
ω
i
=
ω
i
∗
−
α
H
i
,
i
s
i
g
n
(
ω
i
)
ω
i
=
s
i
g
n
(
ω
i
∗
)
∣
ω
i
∗
∣
−
α
H
i
,
i
s
i
g
n
(
ω
i
)
\begin{aligned} & H_{i,i}(\omega_i-\omega_i^*)+\alpha sign(\omega_i)=0 \\ & (\omega_i-\omega_i^*)+\frac{\alpha}{H_{i,i}}sign(\omega_i)=0 \\ & \omega_i = \omega_i^* -\frac{\alpha}{H_{i,i}}sign(\omega_i) \\ & \omega_i = sign(\omega_i^*)|\omega_i^*| - \frac{\alpha}{H_{i,i}}sign(\omega_i) \end{aligned}
Hi,i(ωi−ωi∗)+αsign(ωi)=0(ωi−ωi∗)+Hi,iαsign(ωi)=0ωi=ωi∗−Hi,iαsign(ωi)ωi=sign(ωi∗)∣ωi∗∣−Hi,iαsign(ωi)
我们可以将上式中
ω
i
\omega_i
ωi分为两种情况,第一种是
ω
i
\omega_i
ωi和
ω
∗
\omega^*
ω∗同号即
s
i
g
n
(
ω
i
)
=
s
i
g
n
(
ω
i
∗
)
sign(\omega_i)=sign(\omega_i^*)
sign(ωi)=sign(ωi∗),第二种是
ω
i
\omega_i
ωi和
ω
∗
\omega^*
ω∗异号即
s
i
g
n
(
ω
i
)
≠
s
i
g
n
(
ω
i
∗
)
sign(\omega_i) \ne sign(\omega_i^*)
sign(ωi)=sign(ωi∗),我们先讨论第一种情况,为了帮助大家理解我们可以看看下图
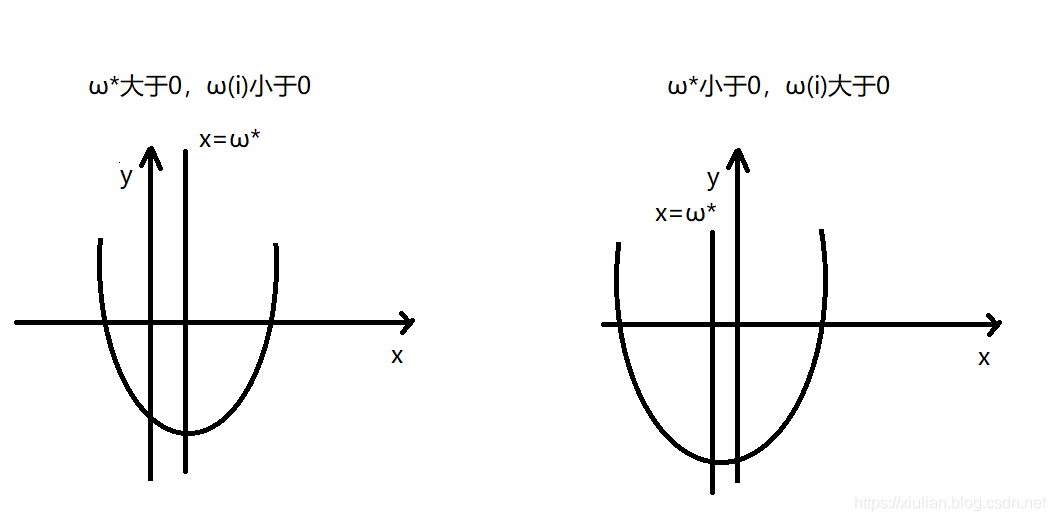
通过上图可以发现,当
ω
i
\omega_i
ωi与
ω
∗
\omega^*
ω∗异号时,无论是哪种情况为了使得损失函数最小,其最优值都是
ω
i
=
0
\omega_i=0
ωi=0此时能保证代价函数的二次项式和绝对值式都取得最小值。
当
ω
i
\omega_i
ωi和
ω
∗
\omega^*
ω∗同号时,可以将上式进行化简可得
ω
i
=
s
i
g
n
(
ω
i
∗
)
∣
ω
i
∗
∣
−
α
H
i
,
i
s
i
g
n
(
ω
i
∗
)
ω
i
=
s
i
g
n
(
ω
i
∗
)
(
∣
ω
i
∗
∣
−
α
H
i
,
i
)
\begin{aligned} & \omega_i = sign(\omega_i^*)|\omega_i^*| - \frac{\alpha}{H_{i,i}}sign(\omega_i^*) \\ & \omega_i = sign(\omega_i^*)(|\omega_i^*|-\frac{\alpha}{H_{i,i}}) \end{aligned}
ωi=sign(ωi∗)∣ωi∗∣−Hi,iαsign(ωi∗)ωi=sign(ωi∗)(∣ωi∗∣−Hi,iα)
- 当 ∣ ω i ∗ ∣ < α H i , i |\omega_i^*|<\frac{\alpha}{H_{i,i}} ∣ωi∗∣<Hi,iα时,此时会导致 ω i \omega_i ωi与 ω i ∗ \omega_i^* ωi∗异号,所以此时最优解是 ω i = 0 \omega_i=0 ωi=0
- 当 ∣ ω i ∗ ∣ > α H i , i |\omega_i^*|>\frac{\alpha}{H_{i,i}} ∣ωi∗∣>Hi,iα时,最优解为 ω i = ∣ ω i ∗ ∣ − α H i , i \omega_i=|\omega_i^*|-\frac{\alpha}{H_{i,i}} ωi=∣ωi∗∣−Hi,iα
所以,我们可以合并上式的结果得到最终的
ω
i
\omega_i
ωi的表达式为
ω
i
=
s
i
g
n
(
ω
i
∗
)
m
a
x
{
0
,
∣
ω
i
∗
∣
−
α
H
i
,
i
}
\omega_i=sign(\omega_i^*)max\{0,|\omega_i^*|-\frac{\alpha}{H_{i,i}}\}
ωi=sign(ωi∗)max{0,∣ωi∗∣−Hi,iα}
总结
我们通过画图和使用公式推导证明了
l
1
l_1
l1正则化和
l
2
l_2
l2正则化产生不同效果的原因,需要注意的是它们的共同点其实都是在衰减对于代价函数的值变化影响相对较小的权重,也就是特征值小的权重,而
l
1
l_1
l1正则化的效果是会使得这部分权重为0,
l
2
l_2
l2正则化会使得它们趋于0。


















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











