









 这个NLP专栏涵盖了数据增强、智能标注技术,如Label studio和hugging face的实体识别方案,以及意图识别算法、多分类任务。文章深入探讨信息抽取,包括关键词抽取、文本和多模态信息抽取,并涉及深度学习可解释性、模型性能优化和压缩。此外,还介绍了知识图谱构建的相关技术,如实体关系抽取。
这个NLP专栏涵盖了数据增强、智能标注技术,如Label studio和hugging face的实体识别方案,以及意图识别算法、多分类任务。文章深入探讨信息抽取,包括关键词抽取、文本和多模态信息抽取,并涉及深度学习可解释性、模型性能优化和压缩。此外,还介绍了知识图谱构建的相关技术,如实体关系抽取。
NLP专栏简介:数据增强、智能标注、意图识别算法|多分类算法、文本信息抽取、多模态信息抽取、可解释性分析、性能调优、模型压缩算法等


专栏链接:NLP领域知识+项目+码源+方案设计
订阅本专栏你能获得什么?
前人栽树后人乘凉,本专栏提供资料:数据增强、智能标注、意图识别算法|多分类算法、文本信息抽取、多模态信息抽取、可解释性分析、性能调优、模型压缩算法等项目代码整合,省去你大把时间,效率提升。 帮助你快速完成任务落地,以及科研baseline。
本人后续会持续整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识,后续会不断增添实战环节(比赛、论文、现实应用等)。
- 对于机器学习这块规划为:基础入门机器学习算法—>简单项目实战—>数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。
- 对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)
- 自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)—>知识融合---->知识推理---->图谱应用
上述对于你掌握后的期许:
- 对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)
- 可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)
- 掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。
这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中),后续会持续实现。
1.专栏目录如下:持续更新中
试读博文仅,简单展示一下目录流程,详细内容的xmind见:点击查看:详细版内容介绍

2.文章合集
2.1 数据标注(智能标注)
A.1[数据标注]:强烈推荐数据标注平台doccano----简介、安装、使用、踩坑记录
A.2【数据标注】:基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
A.3【数据标注】基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
A.4.【数据标注】基于Label studio的训练数据标注指南:文本分类任务
A.5.[数据标注]:基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
B.1【智能标注】:基于 hugging face 预训练模型的实体识别方案:生成doccano要求json格式
B.2【智能标注】:主动学习(Active Learning)简介综述汇总以及主流技术方案
B.3【智能标注】:基于Labelstudio的UIE半监督深度学习的智能标注方案(云端版),提效。
B.4【智能标注】:基于Labelstudio的UIE半监督智能标注方案(本地版),赶快用起来啦。
2.2. 文本分割算法
-
自然语言处理长文本场景下的信息结构化实践:文本分割(话题分割、段落分割、Text segmentation、TextTiling算法)标题生成两大任务
-
NLP:长文本场景下段落分割(文本分割、Text segmentation)算法实践----一种结合自适应滑窗的文本分割序列模型
-
自然语言处理文本分割[Text segmentation]:PoNet算法使用多粒度Pooling结构替代attention的网络
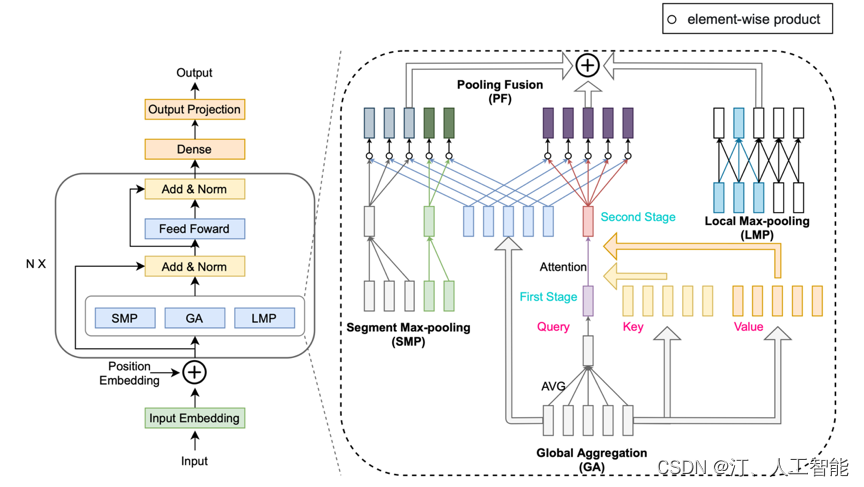

2.2 信息抽取
2.2.0 关键词抽取
自然语言处理[信息抽取]:MDERank关键词提取方法及其预训练模型----基于嵌入的无监督 KPE 方法 MDERank
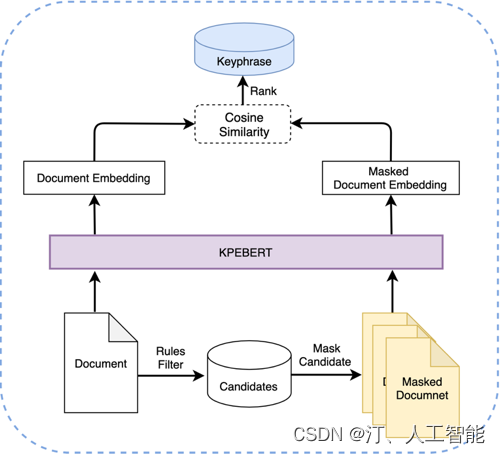
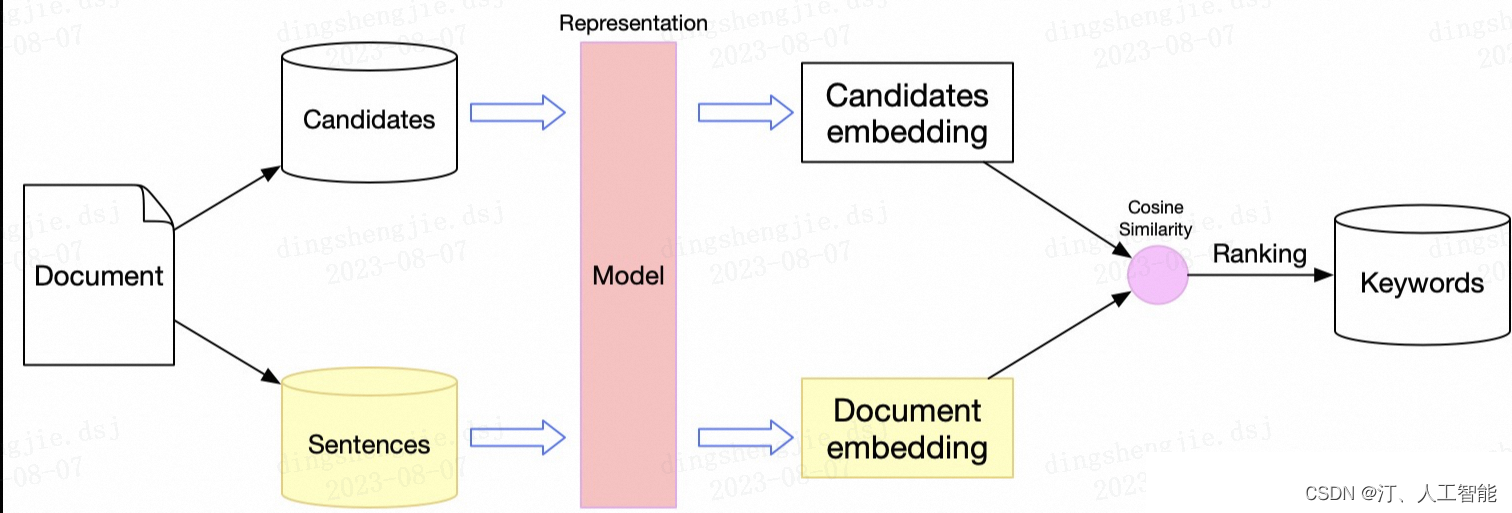
2.2.1文本信息抽取
C.1 百度飞桨:ERNIE 3.0 、通用信息抽取 UIE、paddleNLP的安装使用[一]
C.2 产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
C.3 知识图谱项目实战(一):瑞金医院MMC人工智能辅助构建知识图谱–初赛实体识别
C.4.1快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
C.4.2快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
C.4.3 快递单信息抽取【三】–五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
C.4.4 Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
C.4.5 PaddleNLP UIE–小样本快速提升性能(含doccona标注)
C.6基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习
C.7[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
C.9 文档级关系抽取:基于结构先验产生注意力偏差SSAN模型
C.10[完整版]文档级关系抽取:基于结构先验产生注意力偏差SSAN模型
C.11医疗领域实体抽取:UIE Slim最新升级版含数据标注、serving部署、模型蒸馏等教学,助力工业应用场景快速落地
C.12 军事领域关系抽取:UIE Slim最新升级版含数据标注、serving部署、模型蒸馏、可视化高亮展示等,助力工业应用场景快速落地
2.2.2 多模态信息抽取
C.8 基于ERNIELayout&PDFplumber-UIEX的多方案学术论文信息抽取
持续更新中
2.3 意图识别分类算法
D.1应用实践:Paddle分类模型大集成者[PaddleHub、Finetune、prompt]
D.2 基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
D.3 基于ERNIR3.0文本分类以CAIL2018-SMALL数据集罪名预测任务为例【多标签】
D.4 基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
D.5 基于ERNIR3.0文本分类:WOS数据集为例(层次分类)
D.6 小样本学习在文心ERNIE3.0多分类任务应用–提示学习
D.7 UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)
D.8零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
D.9“中国法研杯”司法人工智能挑战赛:基于UTC的多标签/层次分类小样本文本应用,Macro F1提升13%+
2.4 深度学习可解释性
E.1[可解释性分析]:AiTrust下预训练和小样本学习在中文医疗信息处理挑战榜CBLUE表现
E.2[可解释性分析]:推广TrustAI可信分析:通过提升数据质量来增强在ERNIE模型下性能
2.5 模型性能优化&模型压缩
F.1【性能优化模型压缩】UIE_Slim满足工业应用场景,解决推理部署耗时问题,提升效能,知识蒸馏,模型剪裁。
F.2【性能优化模型压缩】知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
F.3【性能优化模型压缩】在数据增强、蒸馏剪枝下ERNIE3.0分类模型性能提升
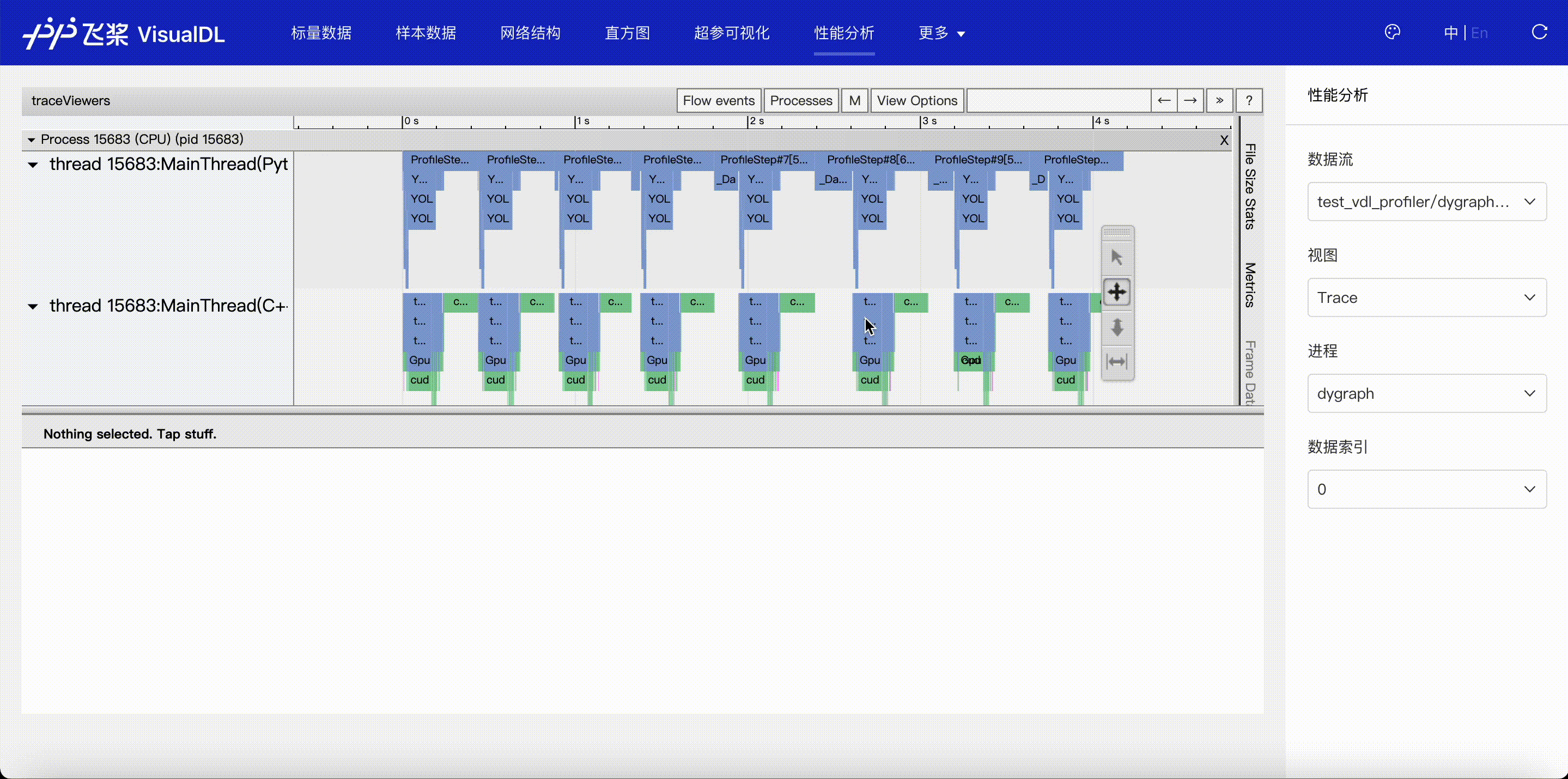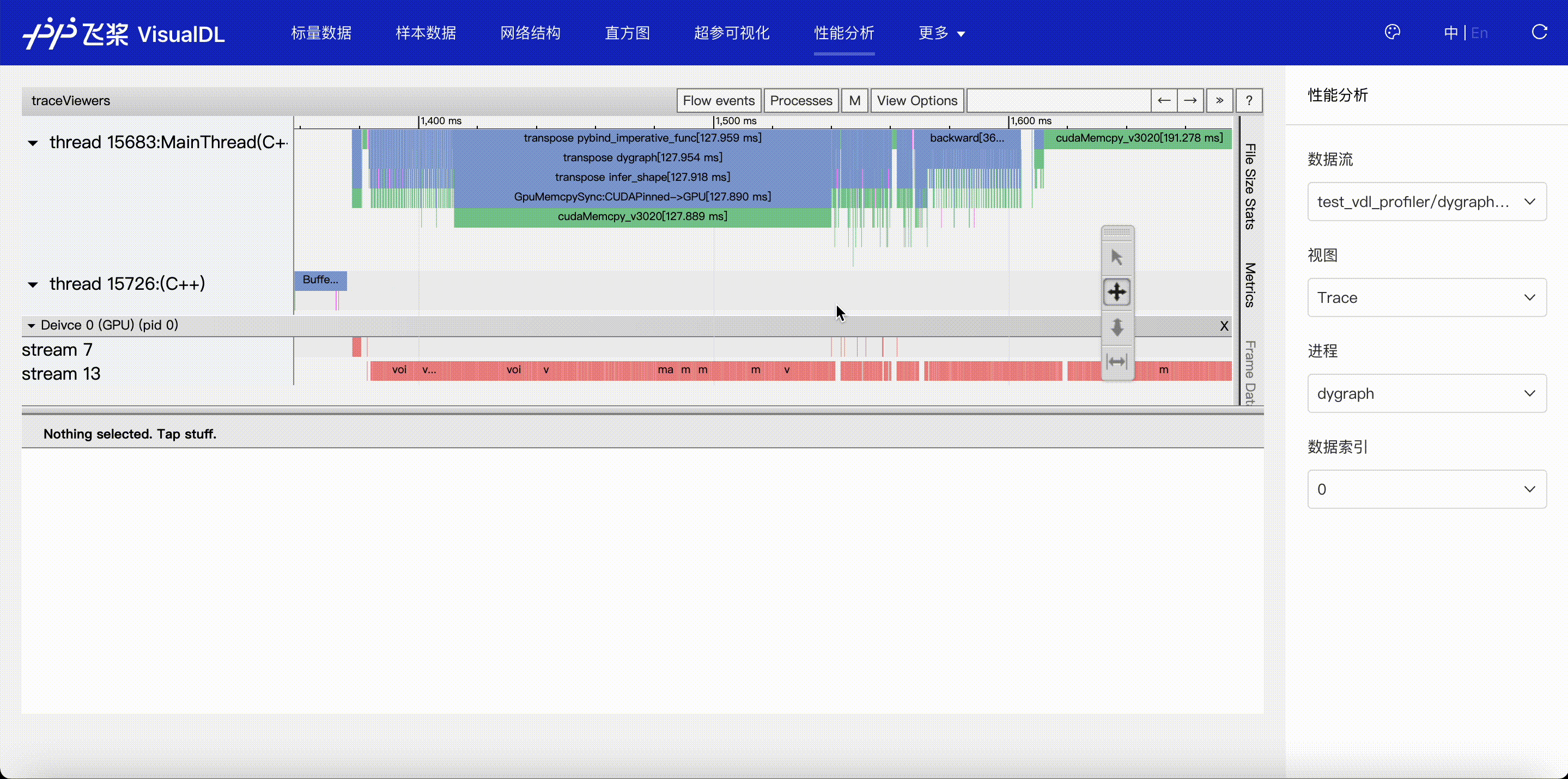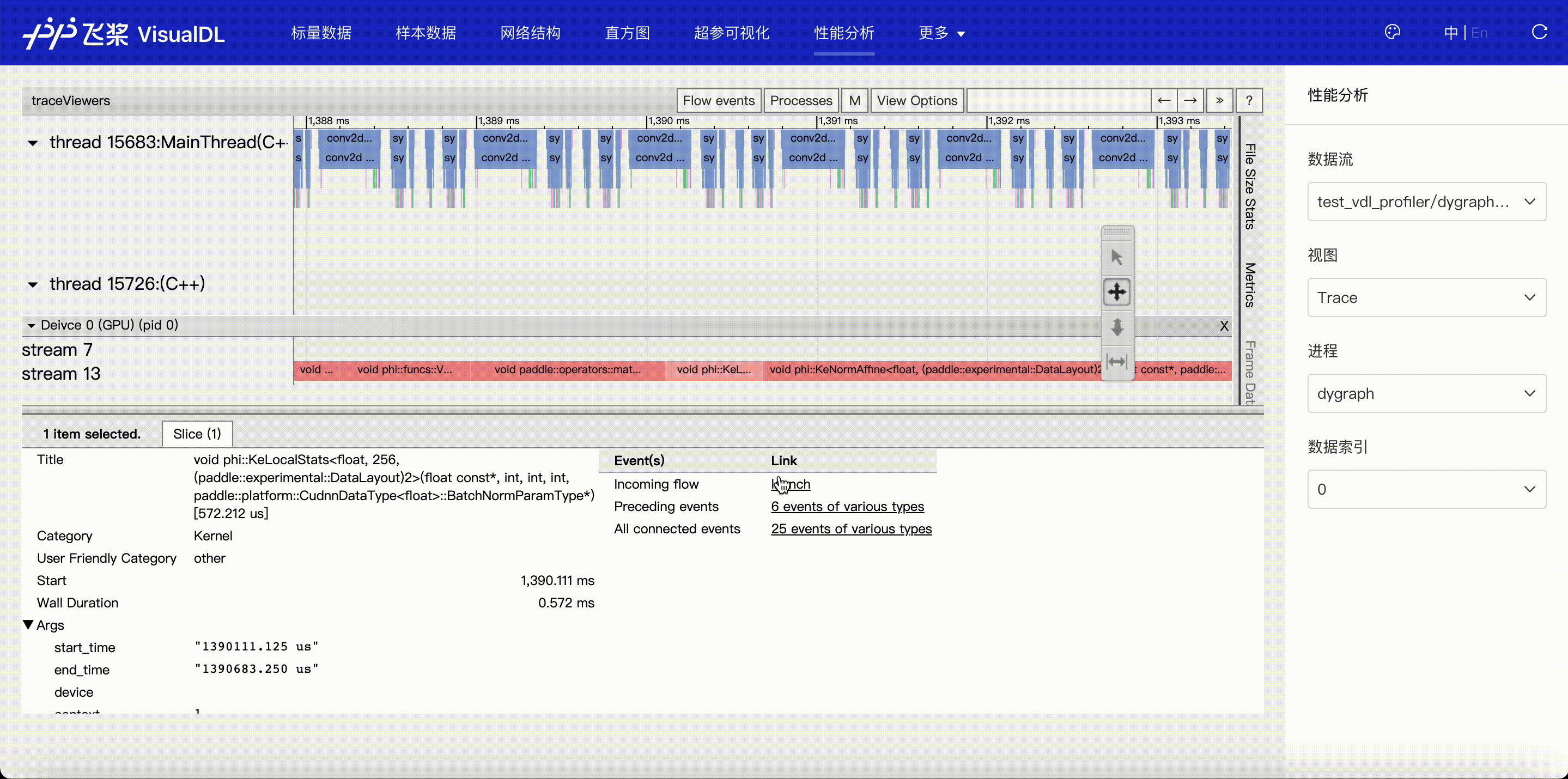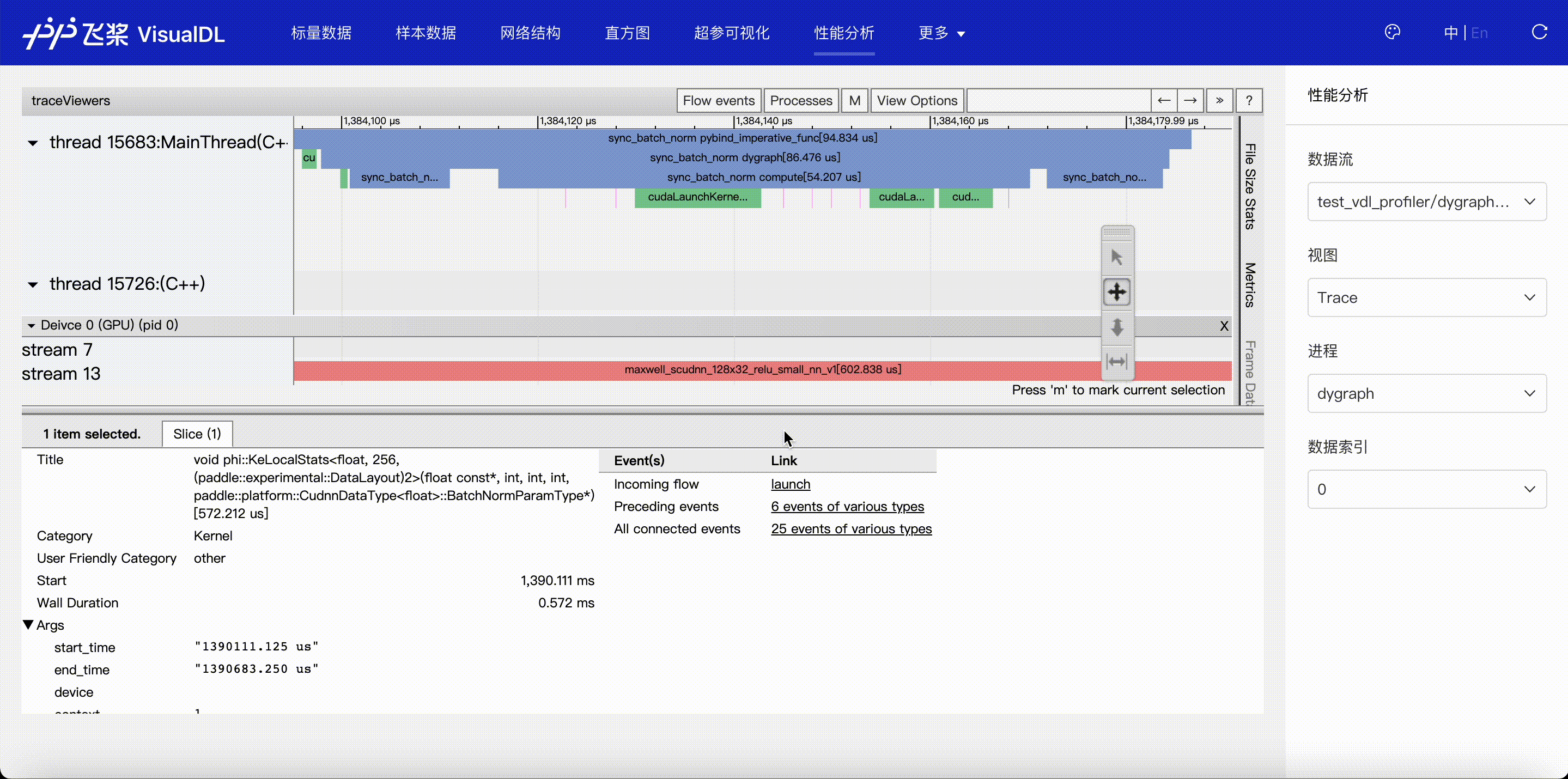
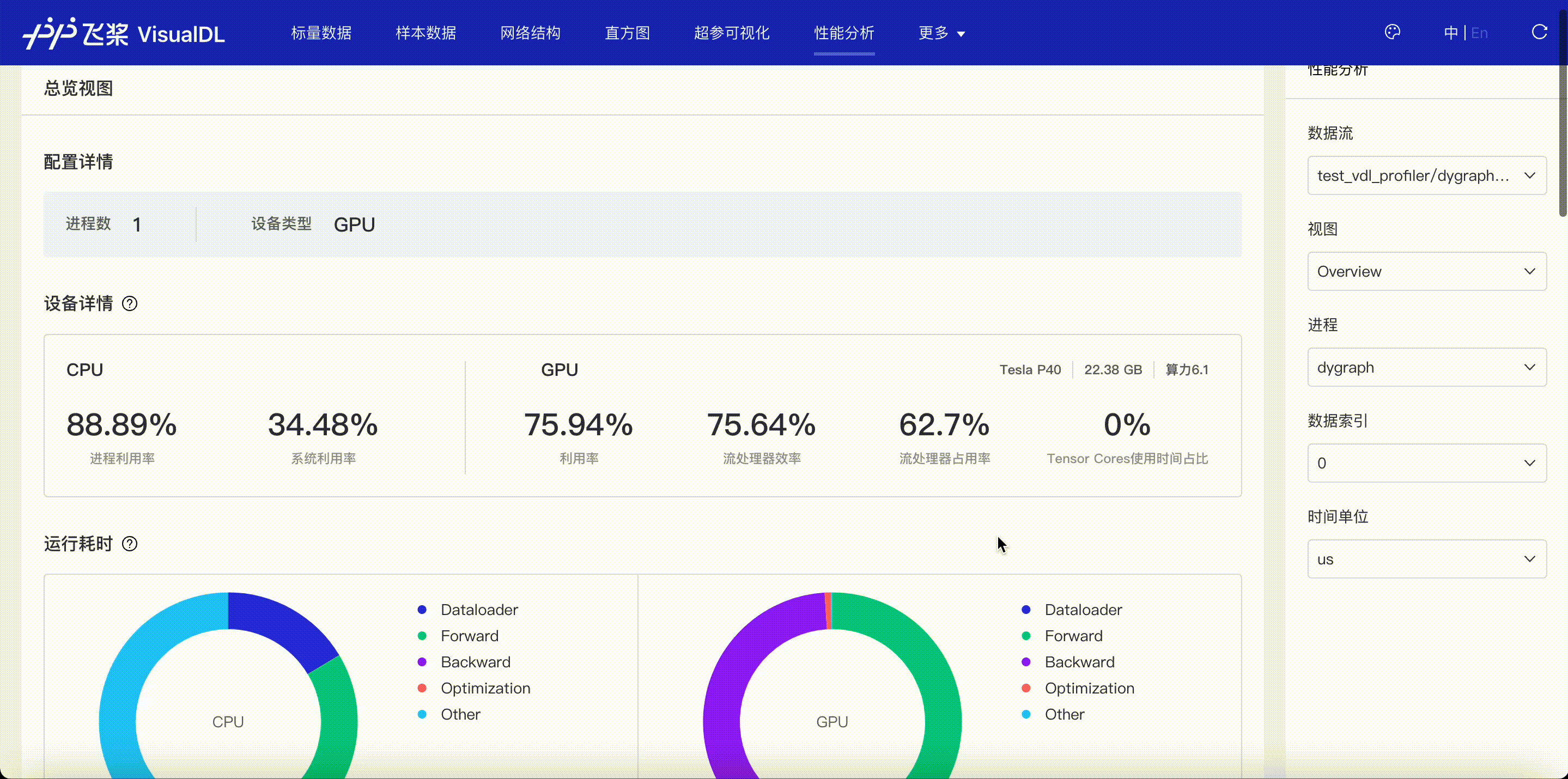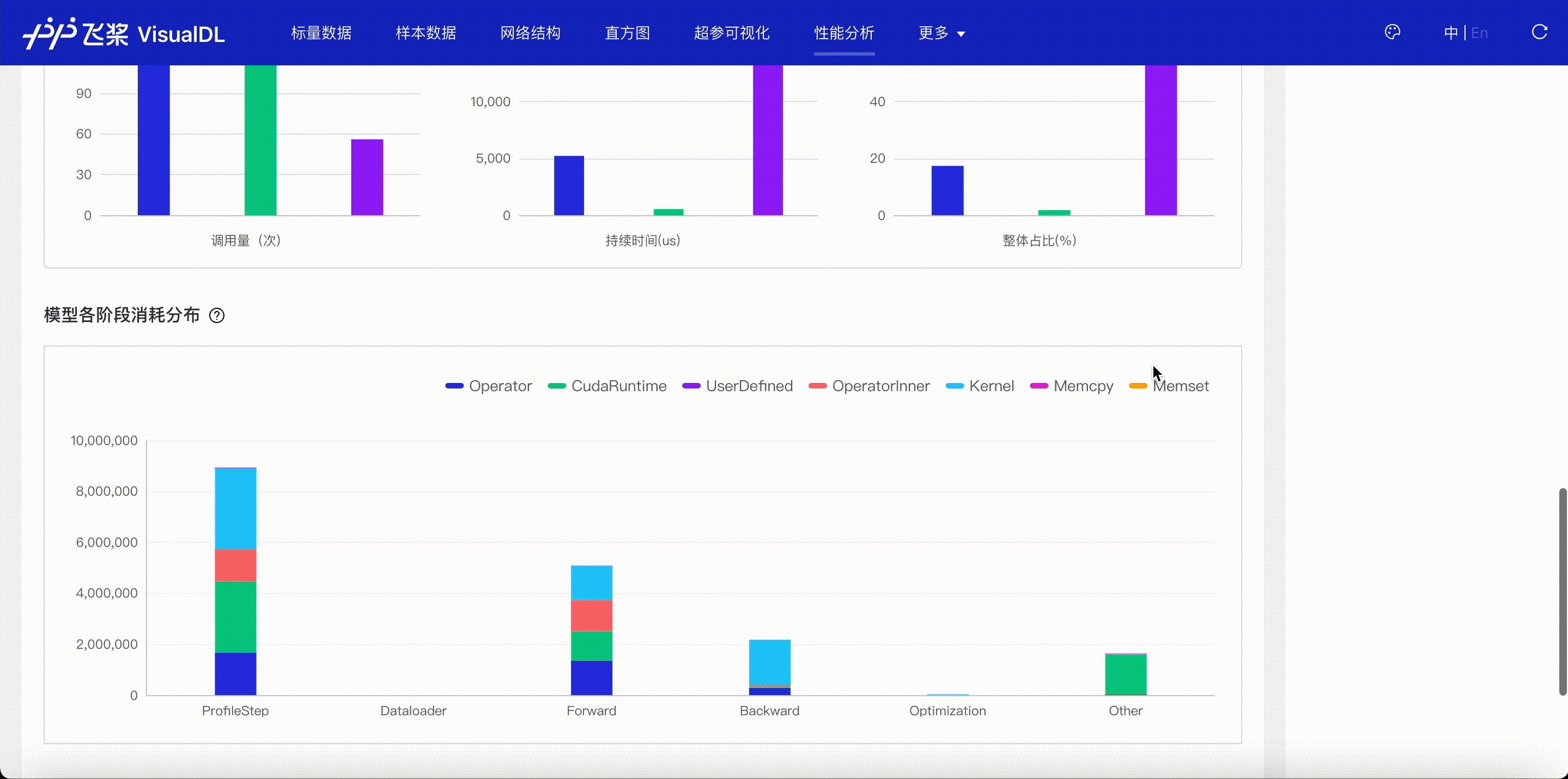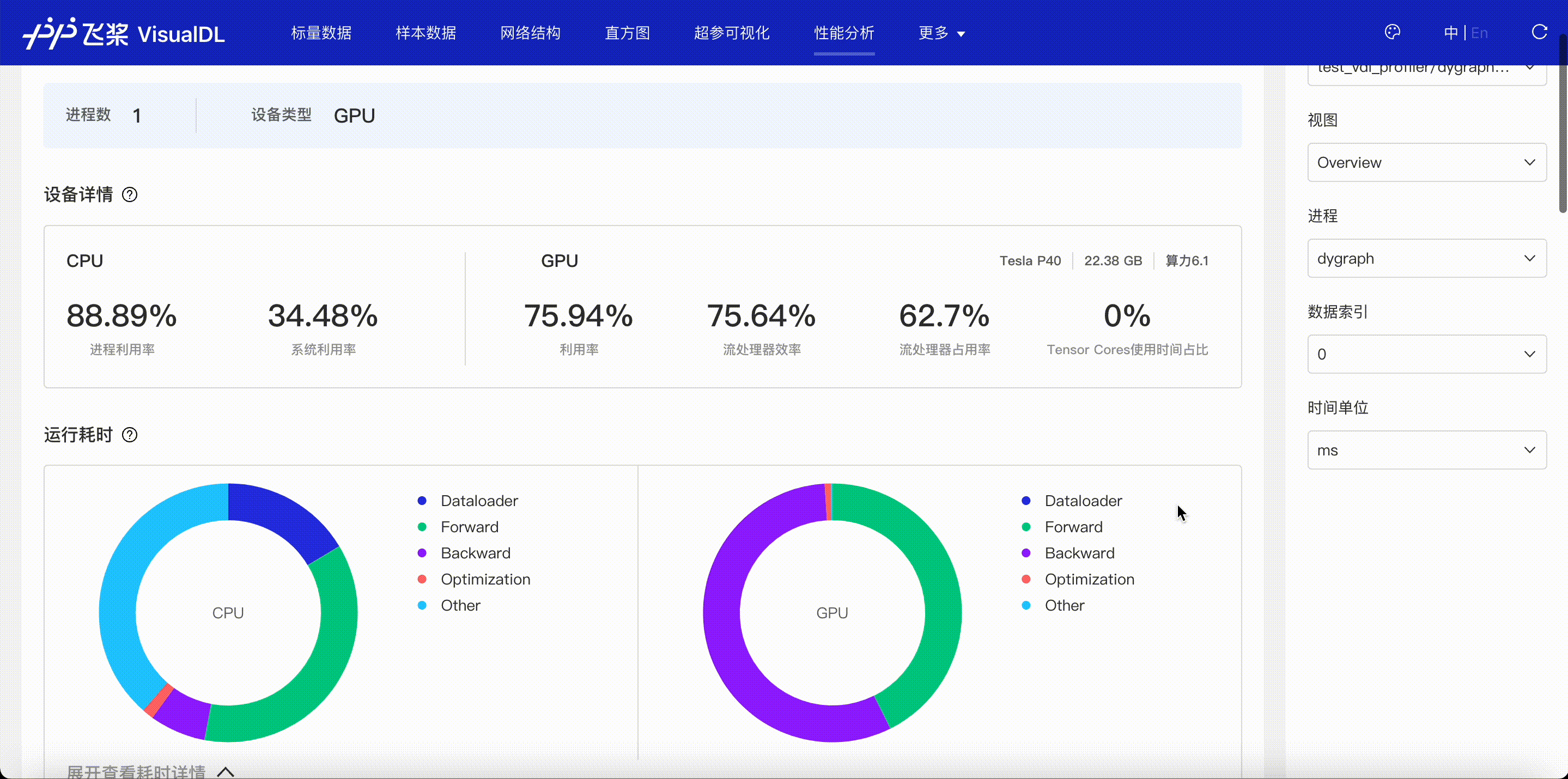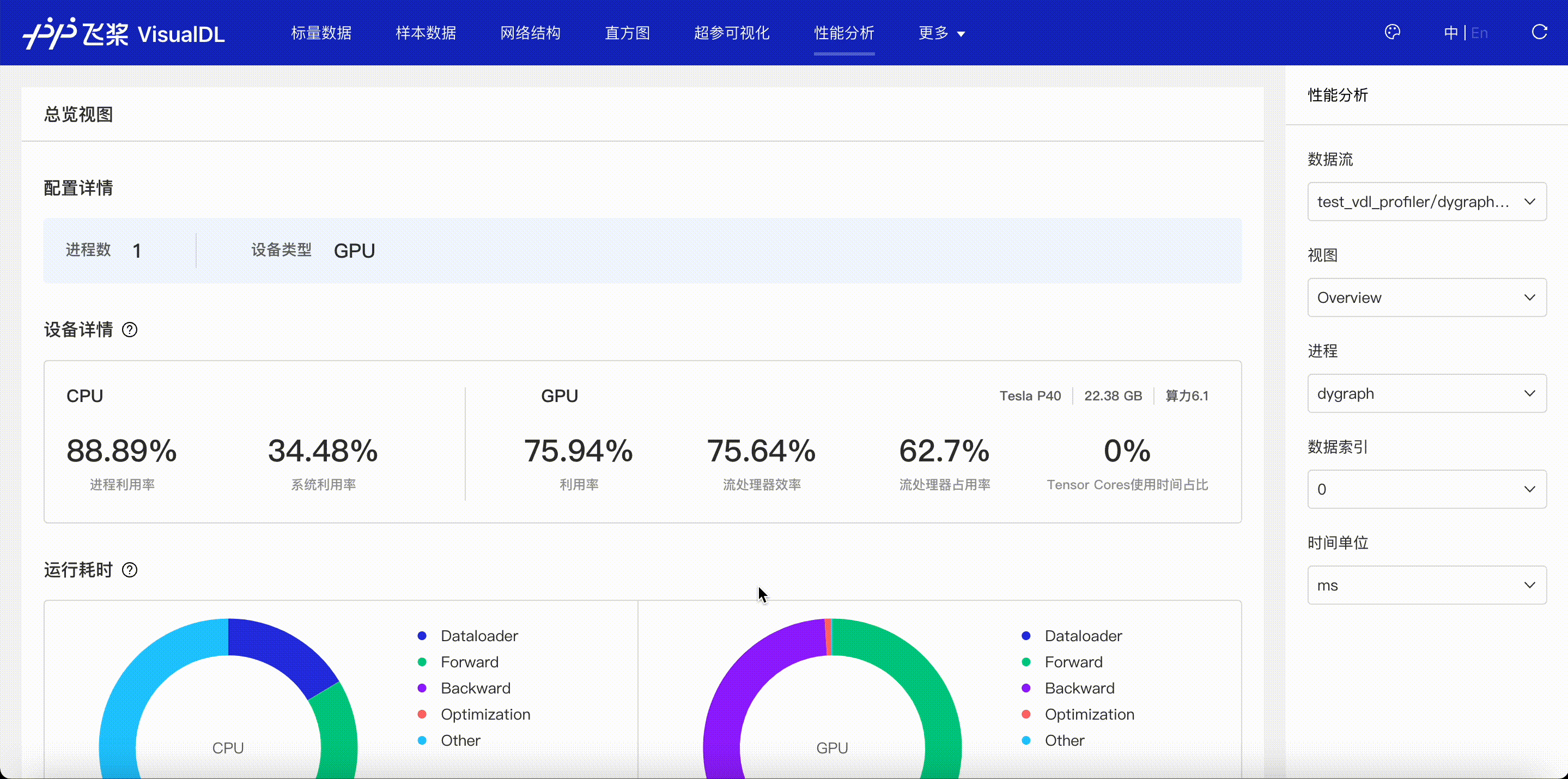
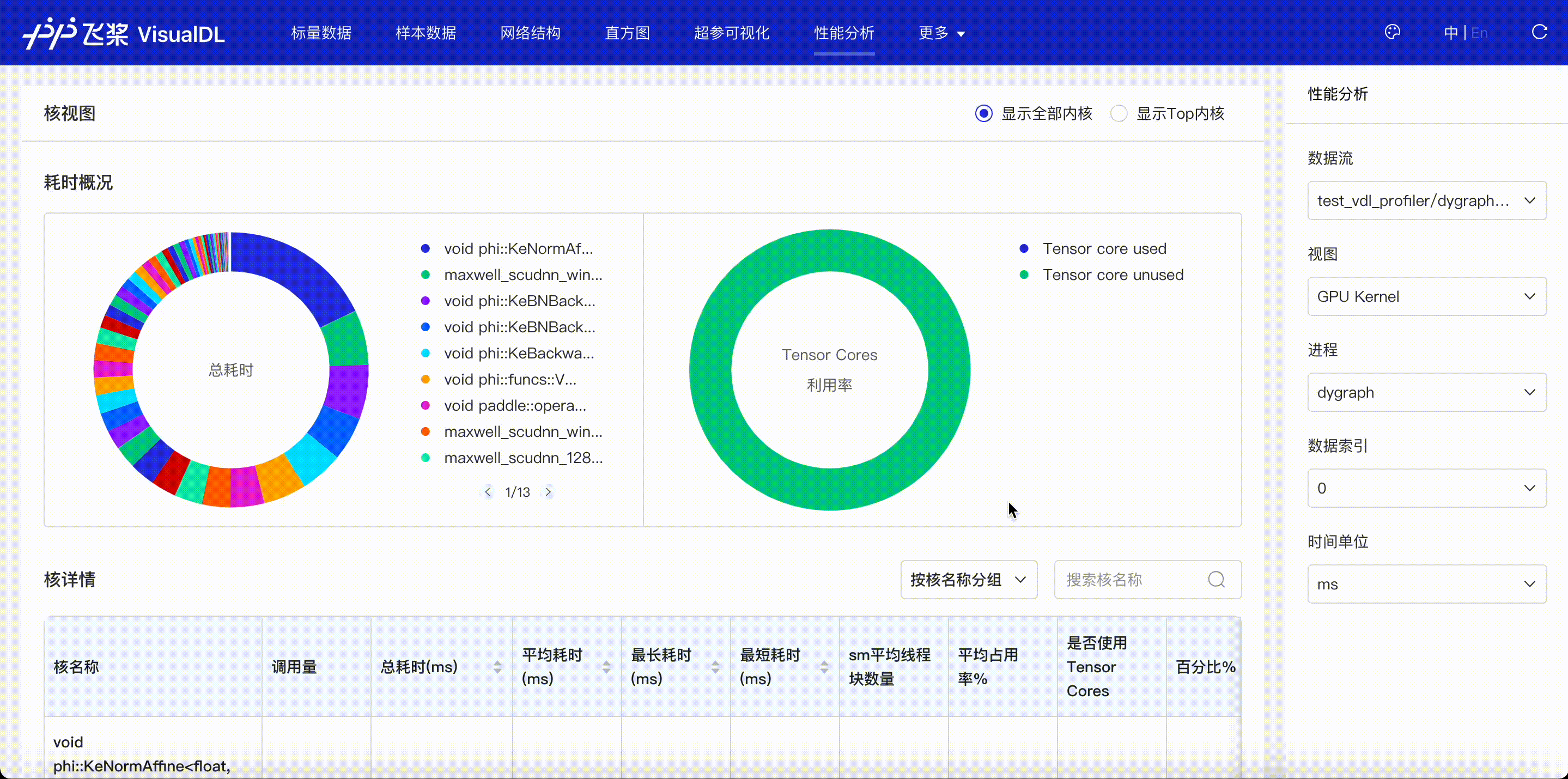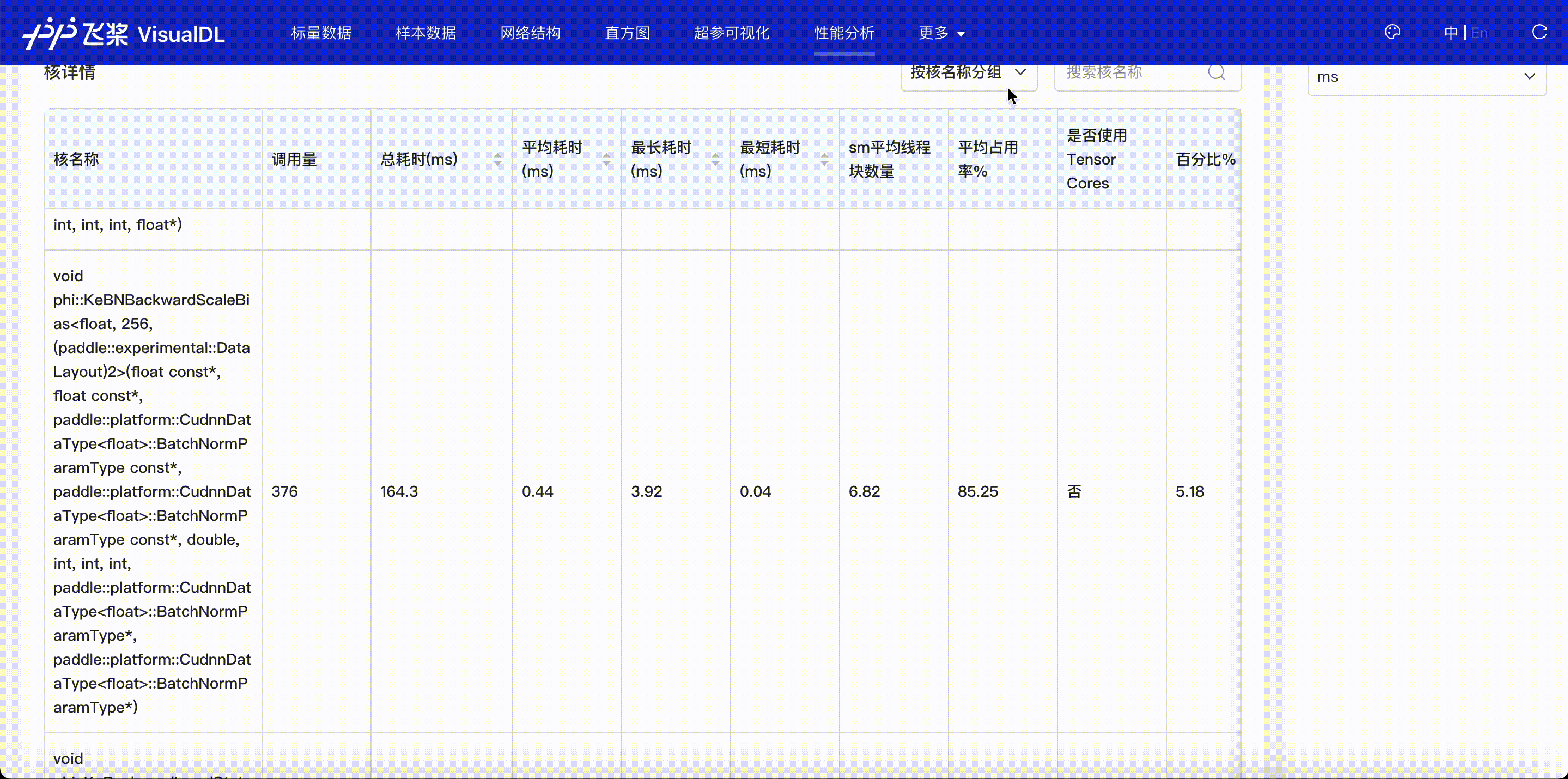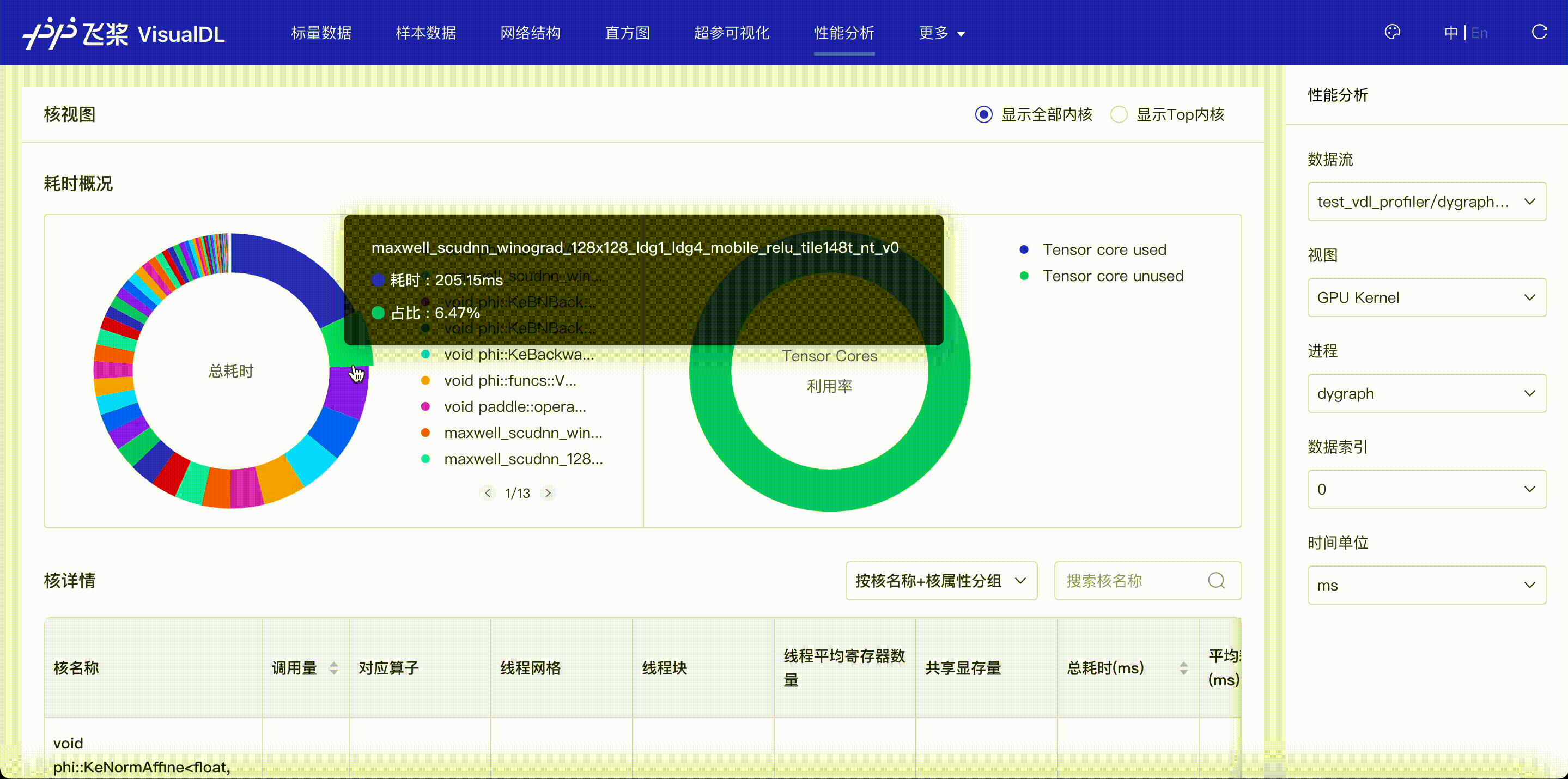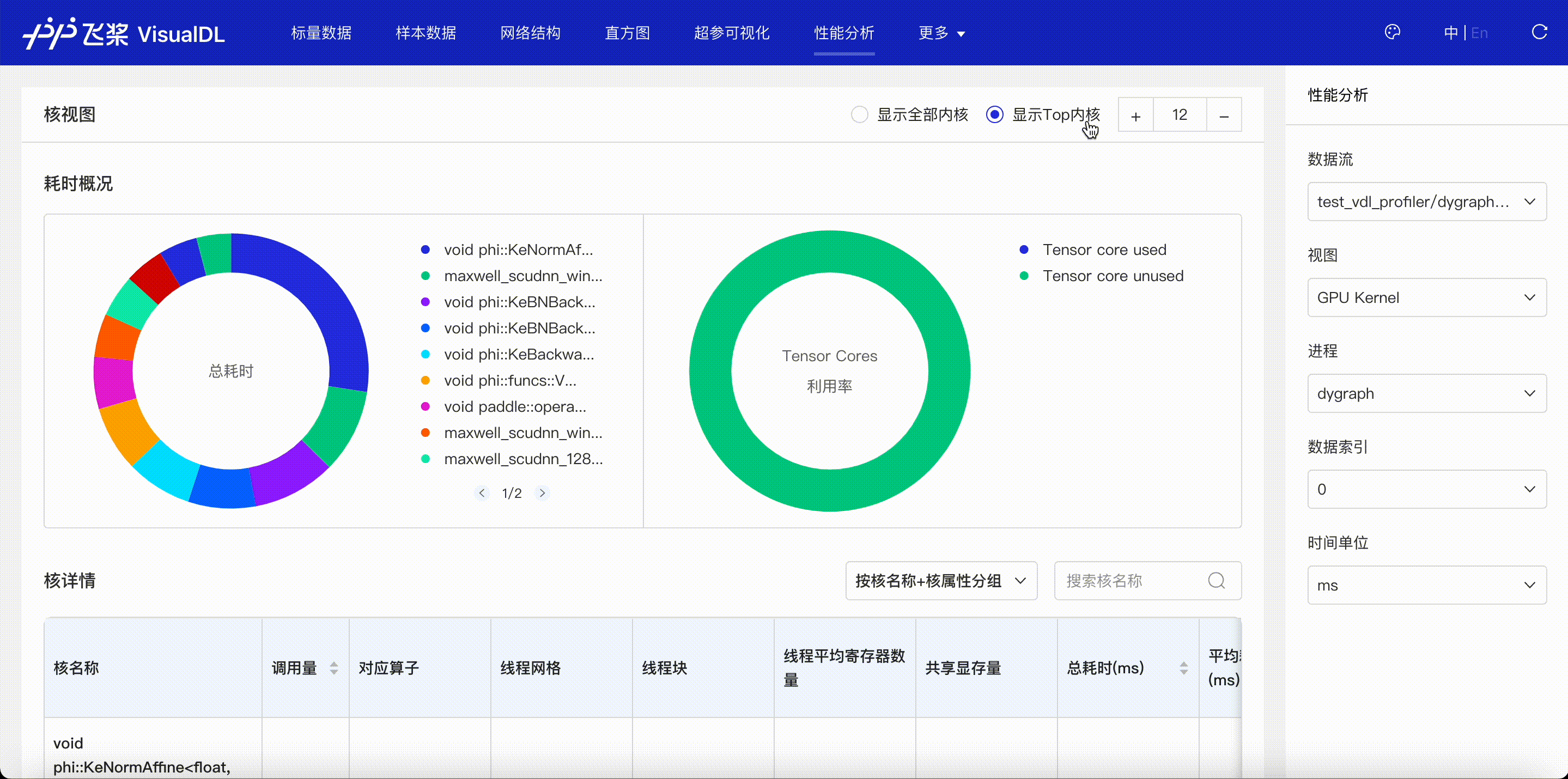
F.4【性能优化模型压缩】Paddle模型性能分析工具Profiler:定位瓶颈点、优化程序、提升性能
F.5【性能优化模型压缩】VisualDL 2.0应用升级–基于「手写数字识别」模型的全功能展示
F.6【性能优化模型压缩】可视化分析工具VisualDL 2.4强势来袭!新增:动态图模型可视化和性能分析
2.6 其他NLP技术
G.1用python进行精细中文分句(基于正则表达式),HarvestText:文本挖掘和预处理工具
G.2 NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】【ERNIE模型首选】
G.3 PaddleHub–飞桨预训练模型应用工具{风格迁移模型、词法分析情感分析、Fine-tune API微调}【一】
G.4PaddleHub–{超参优化AutoDL Finetuner}【二】
G.5 PaddleHub实战篇{词法分析模型LAC、情感分类ERNIE Tiny}训练、部署【三】
G.6 PaddleHub实战篇{ERNIE实现文新闻本分类、ERNIE3.0 实现序列标注}【四】
3.部分效果展示
3.1 智能标注
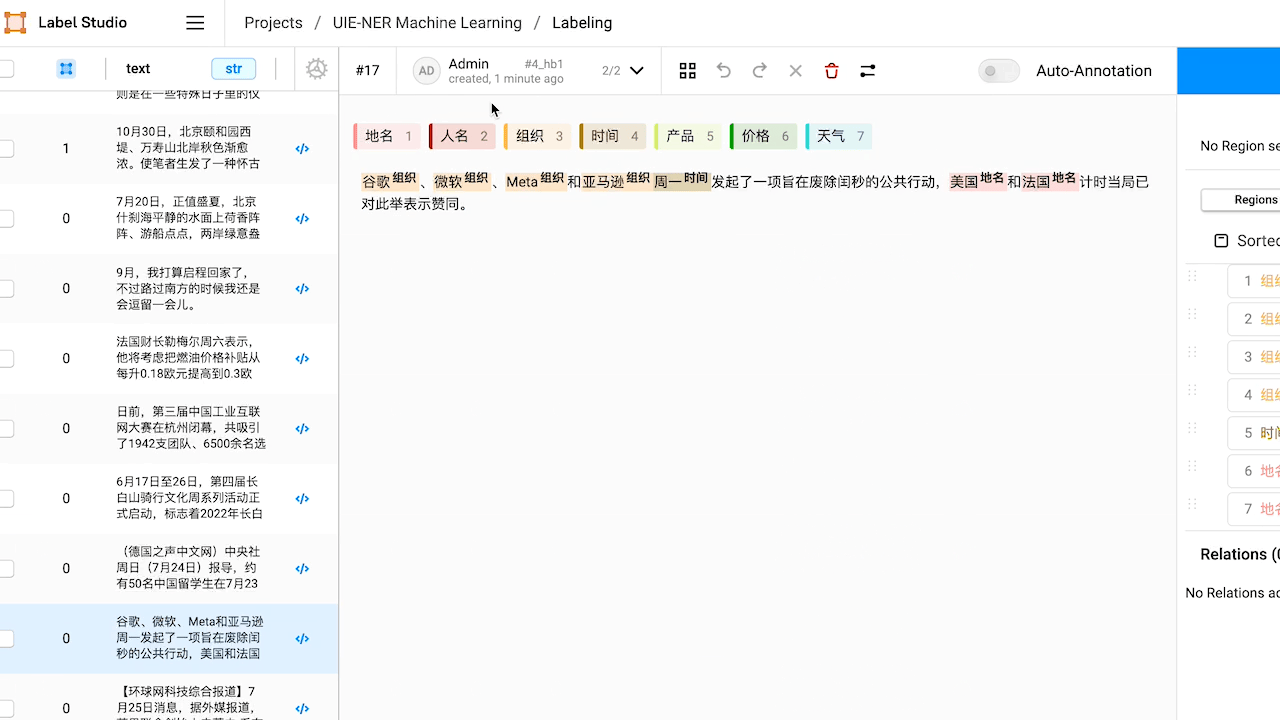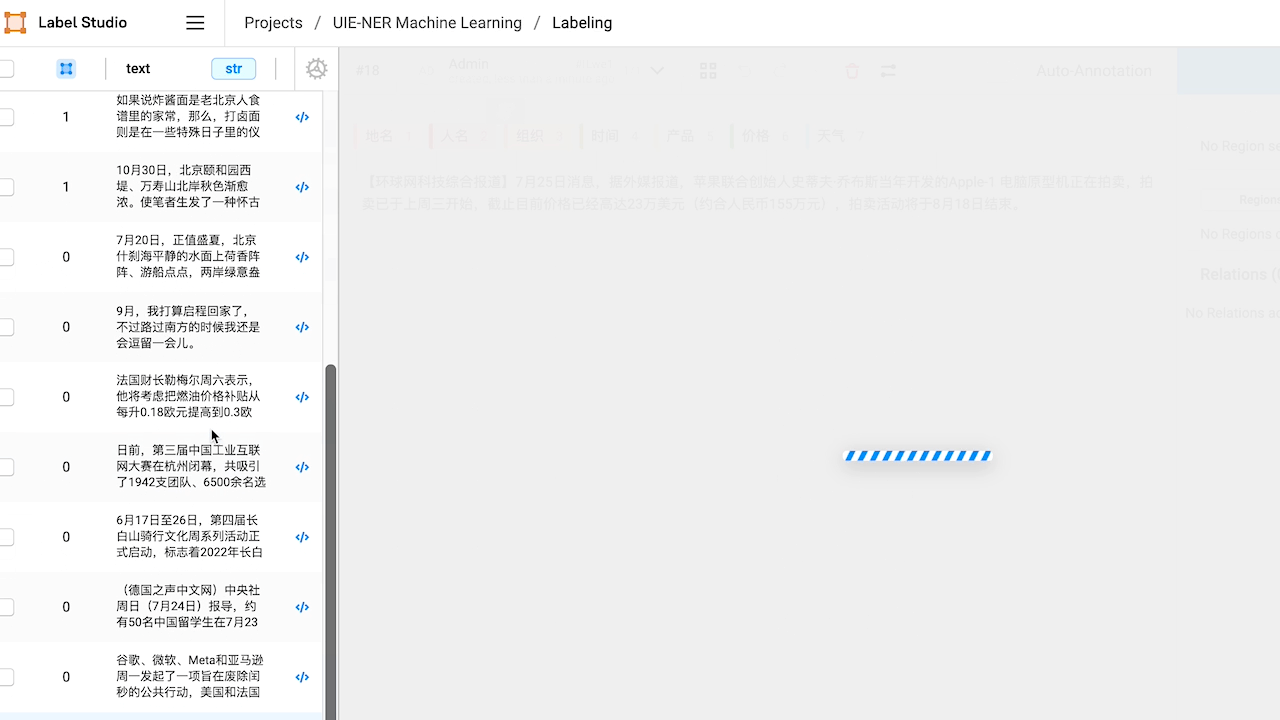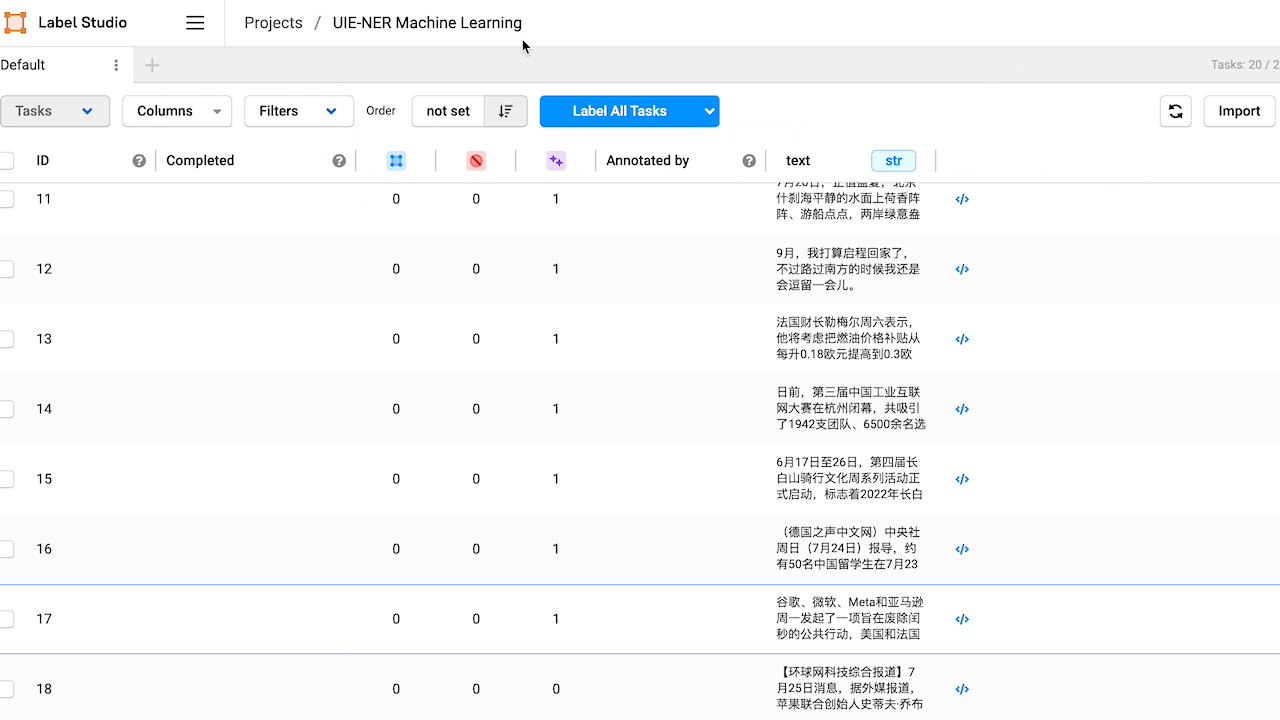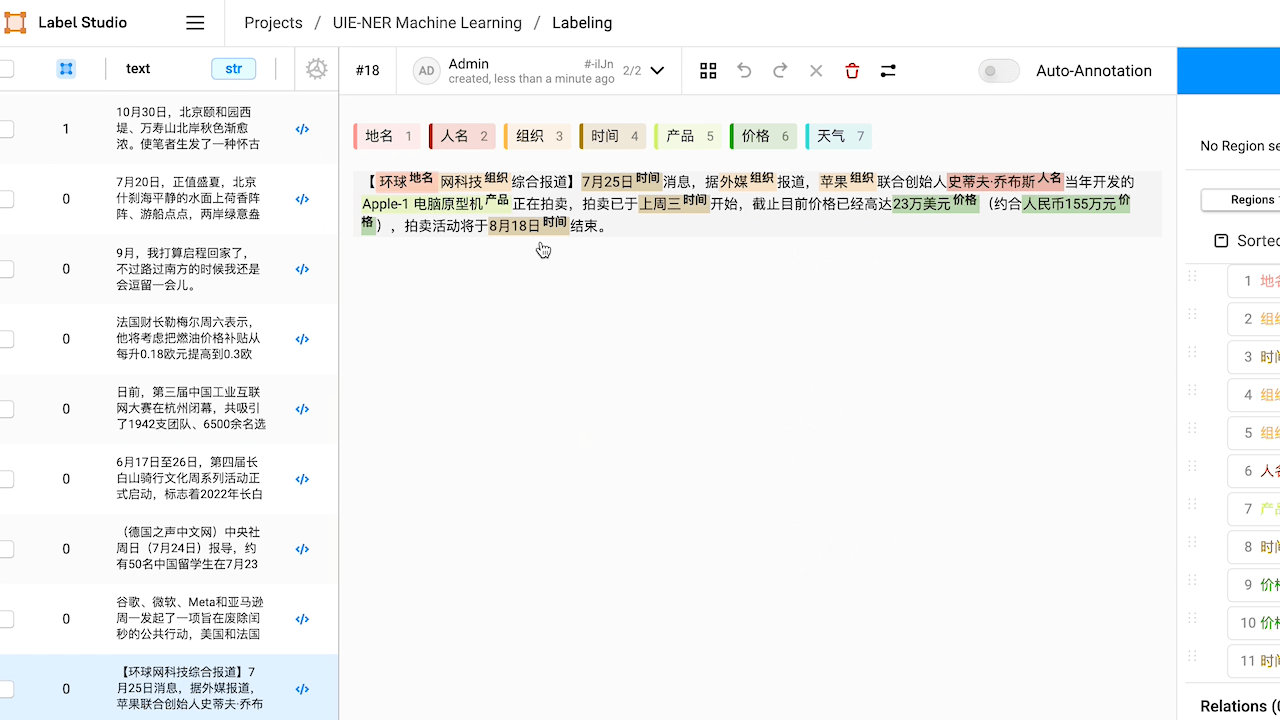
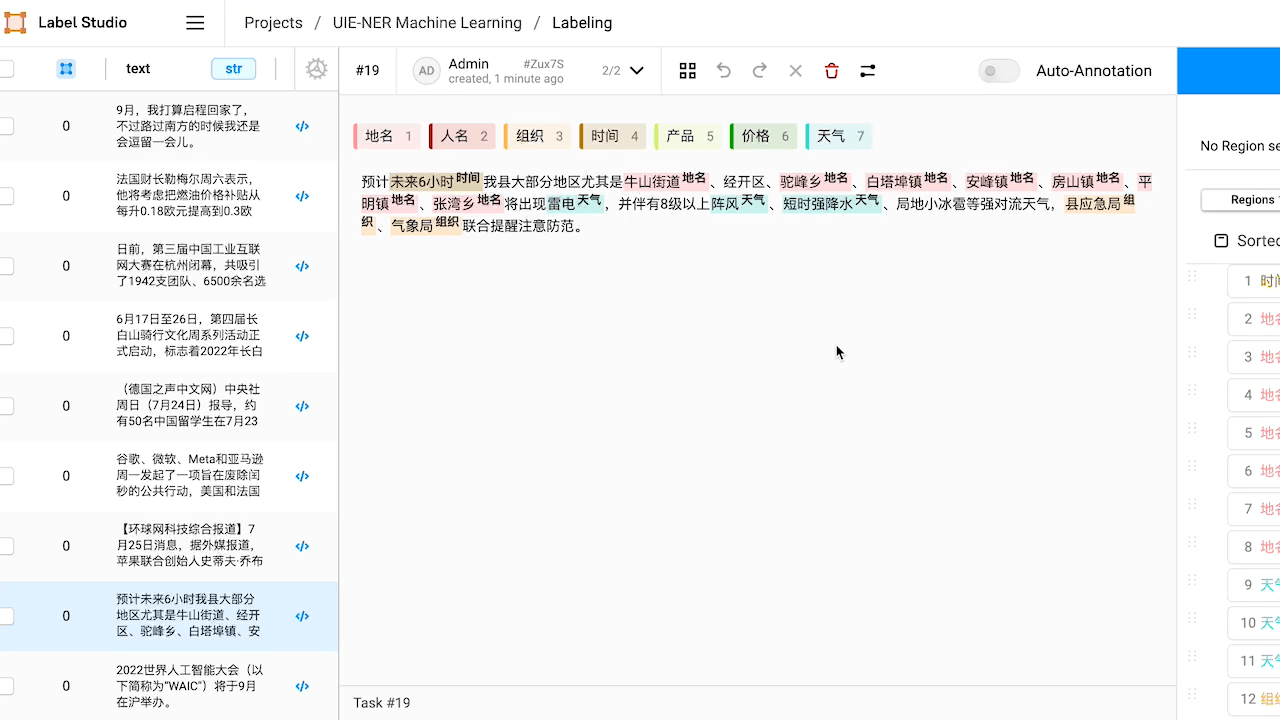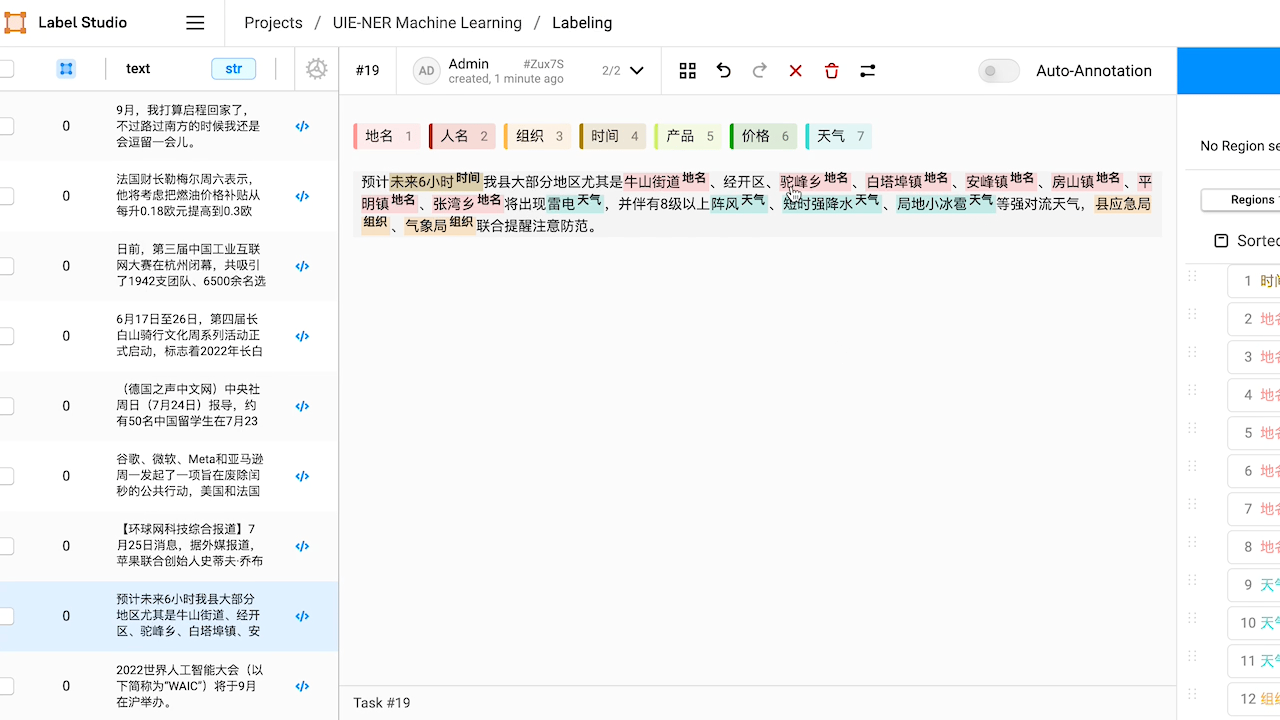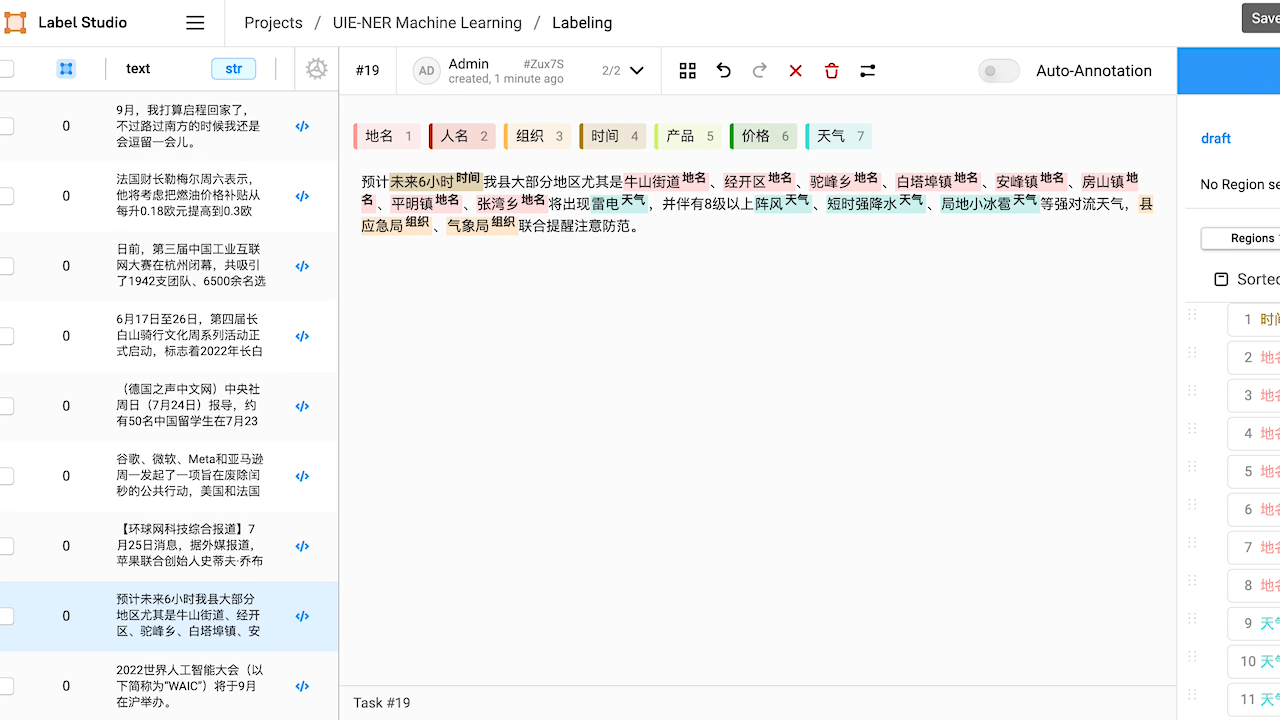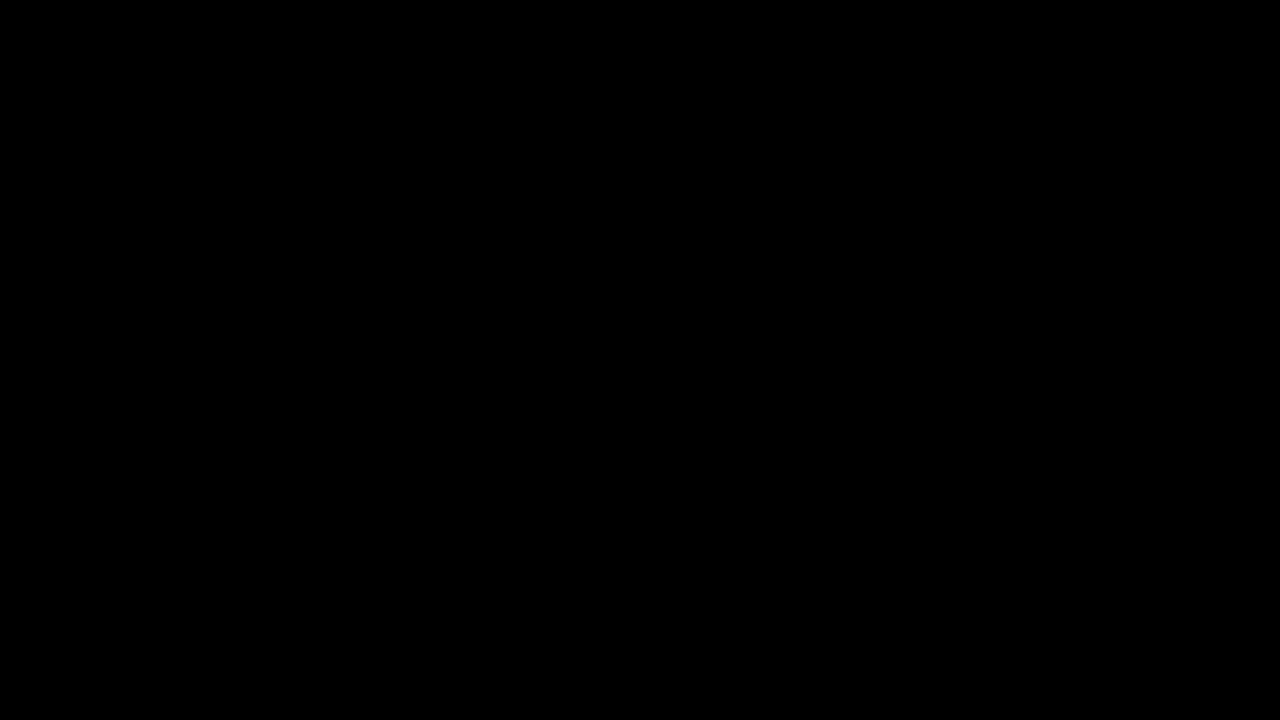
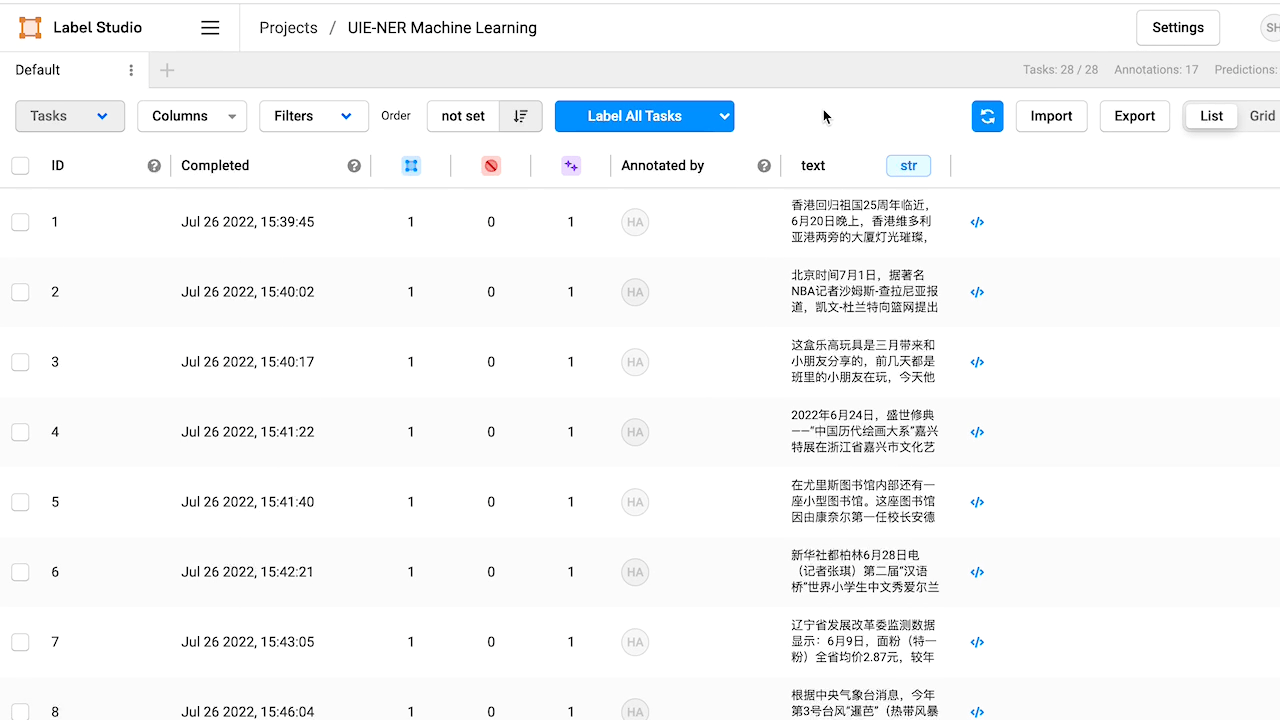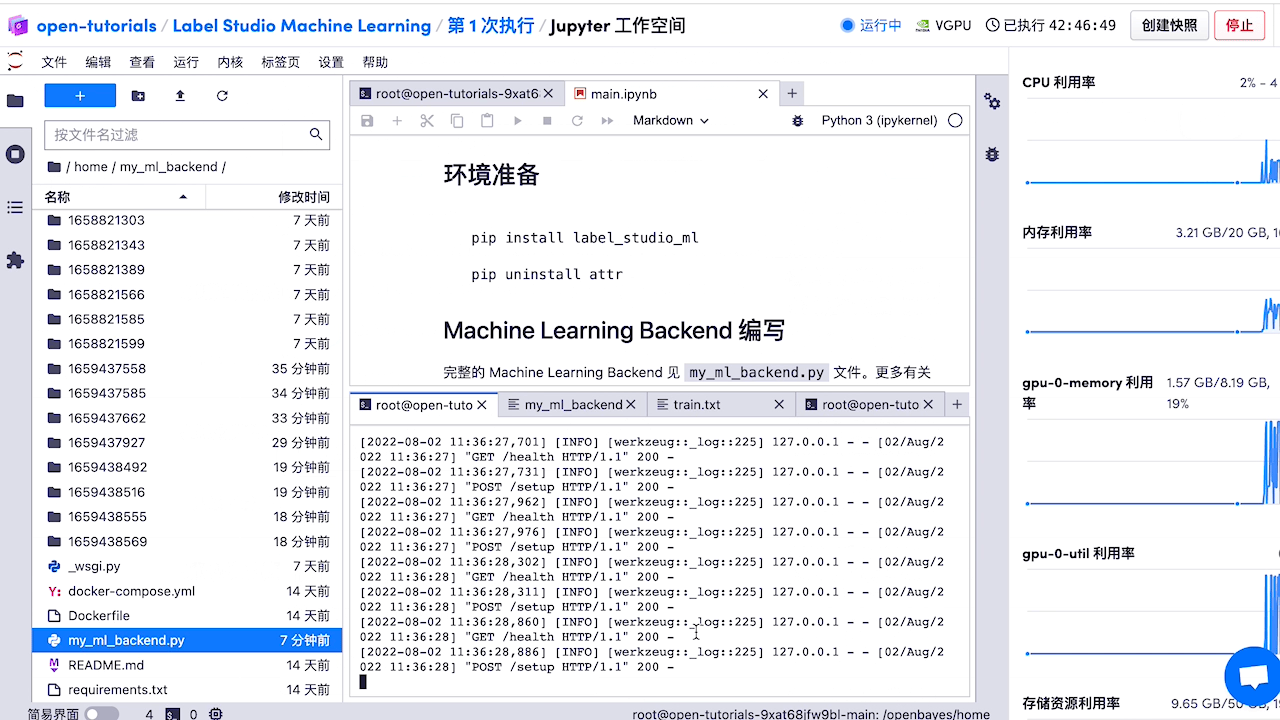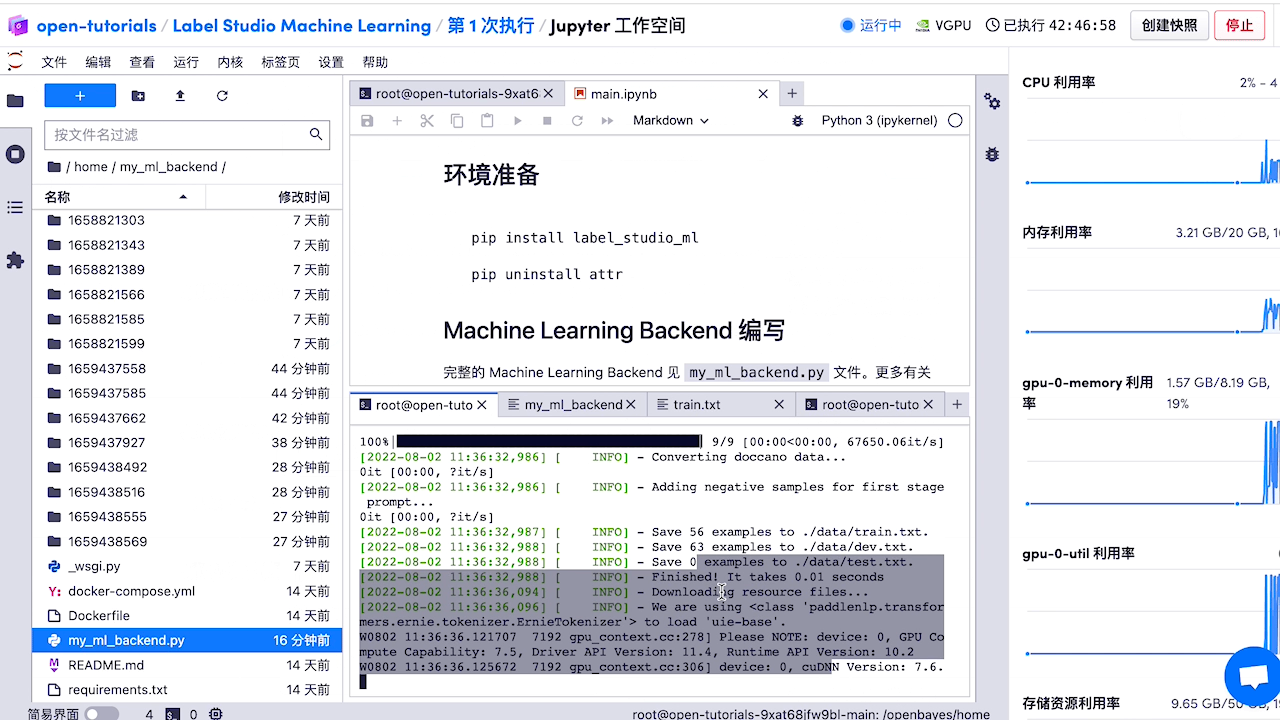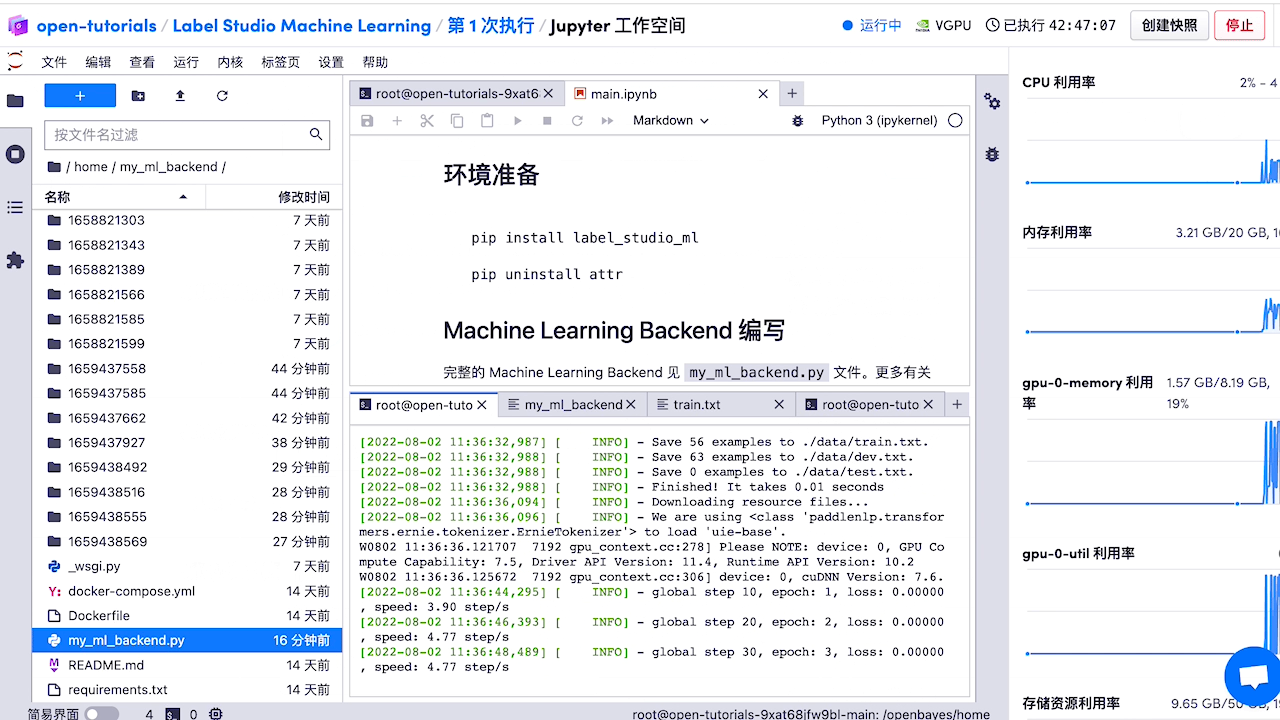
3.2 命名实体识别,关系抽取
部分效果展示

黄峥,1980年出生于浙江杭州,拼多多公司创始人,本科毕业于浙江大学、硕士学位毕业于威斯康星大学麦迪逊分校。
{'公司': [{'text': '拼多多', 'start': 16, 'end': 19, 'probability': 0.935215170074585, 'relations': {'高管': [{'text': '黄峥', 'start': 0, 'end': 2, 'probability': 0.9996391253586268}]}}]}
哔哩哔哩公司的创始人是徐逸,徐逸是最早的哔哩哔哩创始人,但一直在幕后,没有特别公开。曾经是Acfun弹幕网的会员,然后模仿Acfun建立了自己的网站,现在是董事。 {'公司': [{'text': '哔哩哔哩公司', 'start': 0, 'end': 6, 'probability': 0.7246855227849665, 'relations': {'高管': [{'text': '徐逸', 'start': 11, 'end': 13, 'probability': 0.9985462800938478}]}}]}
城市内交通费7月5日金额114广州至佛山
从百度大厦到龙泽苑东区打车费二十元
上海虹桥高铁到杭州时间是9月24日费用是73元
上周末坐动车从北京到上海花费五十块五毛
昨天北京飞上海话费一百元
{"出发地": [{"text": "广州", "start": 15, "end": 17, "probability": 0.9073772252165782}], "目的地": [{"text": "佛山", "start": 18, "end": 20, "probability": 0.9927365183877761}], "时间": [{"text": "7月5日", "start": 6, "end": 10, "probability": 0.9978010396512218}]}
{"出发地": [{"text": "百度大厦", "start": 1, "end": 5, "probability": 0.968825147409472}], "目的地": [{"text": "龙泽苑东区", "start": 6, "end": 11, "probability": 0.9877913072493669}]}
{"目的地": [{"text": "杭州", "start": 7, "end": 9, "probability": 0.9929172180094881}], "时间": [{"text": "9月24日", "start": 12, "end": 17, "probability": 0.9953342057701597}]}
{#"出发地": [{"text": "北京", "start": 7, "end": 9, "probability": 0.973048366717471}], "目的地": [{"text": "上海", "start": 10, "end": 12, "probability": 0.988486130309397}], "时间": [{"text": "上周末", "start": 0, "end": 3, "probability": 0.9977407699595275}]}
{"出发地": [{"text": "北京", "start": 2, "end": 4, "probability": 0.974188953533556}], "目的地": [{"text": "上海", "start": 5, "end": 7, "probability": 0.9928200521486445}], "时间": [{"text": "昨天", "start": 0, "end": 2, "probability": 0.9731559534465504}]}
3.3意图识别多分类



input data: 黑苦荞茶的功效与作用及食用方法
label: 功效作用
---------------------------------
input data: 交界痣会凸起吗
label: 疾病表述
---------------------------------
input data: 检查是否能怀孕挂什么科
label: 就医建议
---------------------------------
input data: 鱼油怎么吃咬破吃还是直接咽下去
label: 其他
---------------------------------
input data: 幼儿挑食的生理原因是
label: 病因分析
---------------------------------
input data: a high degree of uncertainty associated with the emission inventory for china tends to degrade the performance of chemical transport models in predicting pm2.5 concentrations especially on a daily basis. in this study a novel machine learning algorithm, geographically -weighted gradient boosting machine (gw-gbm), was developed by improving gbm through building spatial smoothing kernels to weigh the loss function. this modification addressed the spatial nonstationarity of the relationships between pm2.5 concentrations and predictor variables such as aerosol optical depth (aod) and meteorological conditions. gw-gbm also overcame the estimation bias of pm2.5 concentrations due to missing aod retrievals, and thus potentially improved subsequent exposure analyses. gw-gbm showed good performance in predicting daily pm2.5 concentrations (r-2 = 0.76, rmse = 23.0 g/m(3)) even with partially missing aod data, which was better than the original gbm model (r-2 = 0.71, rmse = 25.3 g/m(3)). on the basis of the continuous spatiotemporal prediction of pm2.5 concentrations, it was predicted that 95% of the population lived in areas where the estimated annual mean pm2.5 concentration was higher than 35 g/m(3), and 45% of the population was exposed to pm2.5 >75 g/m(3) for over 100 days in 2014. gw-gbm accurately predicted continuous daily pm2.5 concentrations in china for assessing acute human health effects. (c) 2017 elsevier ltd. all rights reserved.
predicted result:
level 1: CS
level 2:
----------------------------
input data: previous research exploring cognitive biases in bulimia nervosa suggests that attentional biases occur for both food-related and body-related cues. individuals with bulimia were compared to non-bulimic controls on an emotional-stroop task which contained both food-related and body-related cues. results indicated that bulimics (but not controls) demonstrated a cognitive bias for both food-related and body related cues. however, a discrepancy between the two cue-types was observed with body-related cognitive biases showing the most robust effects and food-related cognitive biases being the most strongly associated with the severity of the disorder. the results may have implications for clinical practice as bulimics with an increased cognitive bias for food-related cues indicated increased bulimic disorder severity. (c) 2016 elsevier ltd. all rights reserved.
predicted result:
level 1: Psychology
level 2:
----------------------------
input data: posterior reversible encephalopathy syndrome (pres) is a reversible clinical and neuroradiological syndrome which may appear at any age and characterized by headache, altered consciousness, seizures, and cortical blindness. the exact incidence is still unknown. the most commonly identified causes include hypertensive encephalopathy, eclampsia, and some cytotoxic drugs. vasogenic edema related subcortical white matter lesions, hyperintense on t2a and flair sequences, in a relatively symmetrical pattern especially in the occipital and parietal lobes can be detected on cranial mr imaging. these findings tend to resolve partially or completely with early diagnosis and appropriate treatment. here in, we present a rare case of unilateral pres developed following the treatment with pazopanib, a testicular tumor vascular endothelial growth factor (vegf) inhibitory agent.
predicted result:
level 1: Medical
level 2:
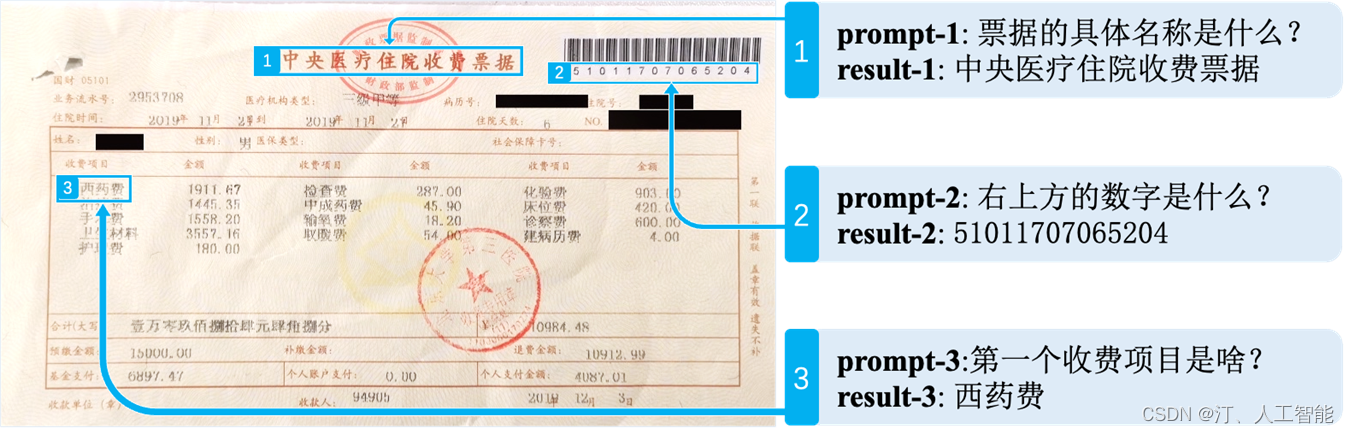
3.4 多模态信息抽取
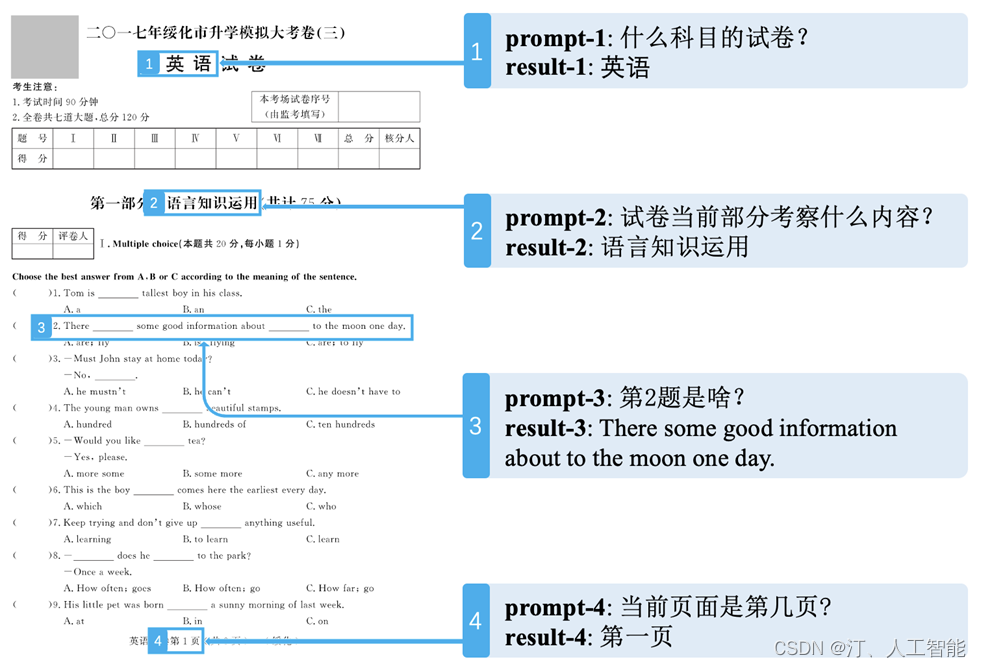


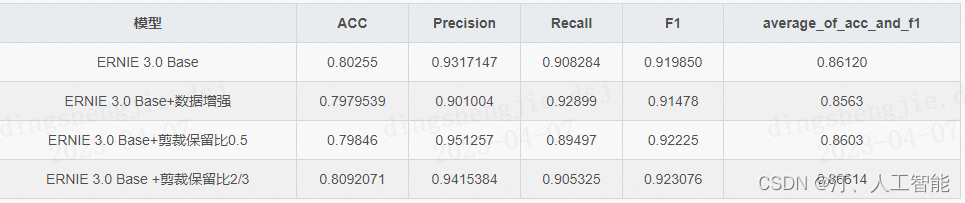
3.5 模型优化




















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











