







企业表相似类别筛选实战
项目背景
在当下RAG(检索增强生成)技术应用不断发展的背景下,掌握文本相似算法不仅能够助力信息检索,还可用于评估生成式LLM的效果。
介绍
文本分类是现实生活中常见的任务之一。在企业分类中,类别数量通常达到数百个,为了方便理清这些类别间的关系、筛选出相似类别变得尤为重要。本项目旨在解决这一需求。
本项目的代码开源在GitHub,欢迎Star和Donate! 地址:https://github.com/JieShenAI/csdn/tree/main/25/01/文本相似_企业表筛选_实战
通过网盘分享的文件:文本相似_企业表筛选_实战
链接: https://pan.baidu.com/s/1XyGK17jjZZ_kivJsDKE3pQ?free
效果展示
本文通过基于规则的google_bleu方法和基于向量的相似度计算,对企业类别间的相似度进行测算,并展示了两种方法的筛选结果。
候选集的表格为 alter_values.xls,通过遍历 init_values.xls 中的条目,从候选集中筛选出前 TopK 个最相似的条目。
基于规则的效果
规则方法主要基于字符层面的相似度计算,使用 google_bleu 算法完成,效果如下图所示:

行业分类属性列 来自 init_values.xls。
【0-9】属性列,代表与行业分类属性列中值相似的前 Top 10 个值,相似程度从高到低递减,0 属性列为最相似。
由google_bleu 支持字符串的相似得分计算,主要是基于字符层面的。
可以改进的点:在分词的时候,采用字分词,每个单字为一个词。在分词时,可通过引入 jieba分词 和自定义领域词典进行优化。
基于向量相似的效果
向量相似方法采用嵌入模型,能够抓取文本的深层语义信息,避免仅局限于字符表面匹配。
使用 jina-embeddings-v2-base-zh 作为嵌入模型,点击查看该模型的介绍 https://modelscope.cn/models/jinaai/jina-embeddings-v2-base-zh

使用基于向量的相似度计算,能够把握住文本深层次的语义信息,不会仅仅是表面的字符。
相比规则算法,向量方法能有效筛选出语义相近的类别,例如:
- 规则方法可能错误地将“房地产中介服务”筛选为与“中 国 共 产 党 机 关”相关的条目;
- 向量方法则能准确找到更贴合语义的结果,如“国家权力机构”或“共青团”。
基于规则:
| 行业分类 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 中国共产党机关 | 中国共产党机关 | 中成药生产 | 房地产中介服务 | 国家机构 | 国家权力机构 | 国家行政机构 | 其他国家机构 | 公共安全管理机构 | 生产专用起重机制造 | 其他未列明国家机构 |
基于向量:
| 行业分类 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 中国共产党机关 | 中国共产党机关 | 国家权力机构 | 共青团 | 国家行政机构 | 人民检察院 | 国家机构 | 监察委员会、人民法院和人民检察院 | 人民政协、民主党派 | 人民政协 | 基层群众自治组织及其他组织 |
可以发现基于规则找出的与中 国 共 产 党 机 关相关条目,其中居然包含有中成药生产、房地产中介服务 。
说明

data: 存放原始数据目录;
rule.py: 基于规则的相似度筛选代码;
vector.py: 基于向量的相似度筛选代码;参考 chroma. https://python.langchain.com/docs/integrations/vectorstores/chroma/
向量筛选.csv 与 规则筛选.csv 是最终的输出结果;
- 代码复用:通过对两个表格与表头的替换,即可实现代码复用;
基于企业名称的筛选
Github 地址,只有代码没有数据:https://github.com/JieShenAI/csdn/tree/main/25/01/%E5%85%AC%E5%8F%B8%E5%90%8D%E7%A7%B0%E7%9B%B8%E4%BC%BC%E7%AD%9B%E9%80%89
通过网盘分享的文件:公司名称相似筛选
为了数据安全,对表格中的一部分数据进行了删除
链接: https://pan.baidu.com/s/1IMrA0TFv8wqAoQEKYMtTXA?free
原始数据:
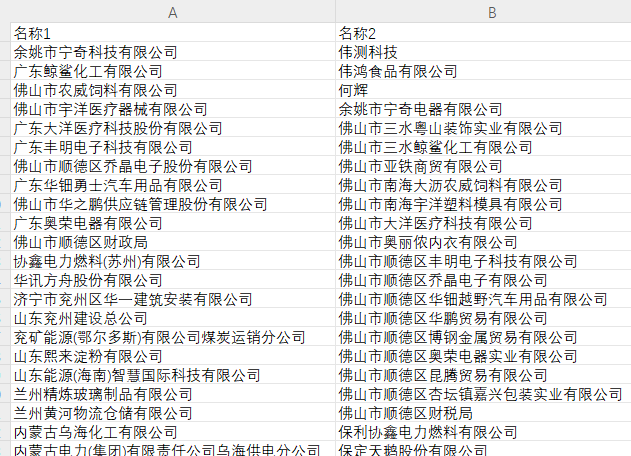
在所有的 名称2属性列 中找出,与 名称1属性列相似的公司名。
相似公司筛选结果:
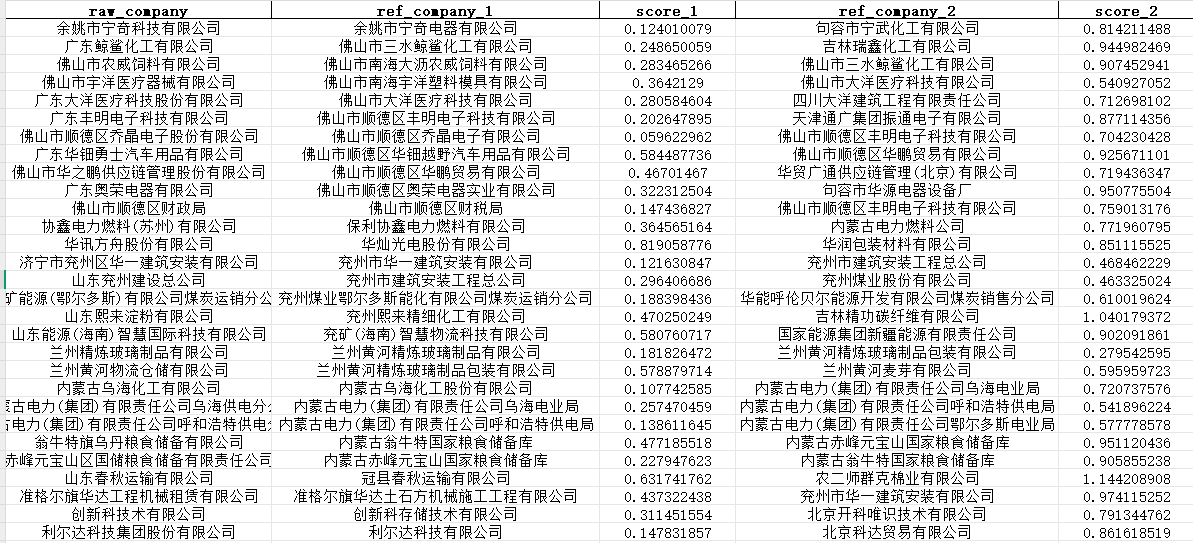
为了避免公司名称中,一些关键词的干扰,把一些词汇删除后再编码为向量计算相似度。
下述就是要删除的词汇:
def delete_words(text):
DELETW_WORDS = [
"有限公司",
"有限责任公司",
"股份有限公司",
"控股集团公司",
"控股有限责任公司",
"控股股份有限公司",
"集团",
"公司",
"合作社",
]
for word in DELETW_WORDS:
text = text.replace(word, "")
return text
fold = "data/"
for file in os.listdir(fold):
file_name = os.path.join(fold, file)
if not file_name.endswith(".xlsx"):
continue
tmp_df = pd.read_excel(file_name)
raw_companies = tmp_df["名称1"].to_list()
ref_companies = tmp_df["名称2"].to_list()
documents = [
Document(
page_content=delete_words(ref_company),
id=idx,
metadata={"ref_company": ref_company},
)
for idx, ref_company in enumerate(ref_companies)
]
# 向量数据库
vector_store = Chroma(
collection_name=file,
embedding_function=hf_embedding,
)
vector_store.add_documents(documents=documents)
data = []
for raw_company in tqdm(raw_companies):
if not isinstance(raw_company, str):
continue
relevant_companies = vector_store.similarity_search_with_score(
delete_words(raw_company), k=TOP_K
)
ans = [raw_company]
for relevant_company, score in relevant_companies:
ans.append(relevant_company.metadata["ref_company"])
ans.append(score)
data.append(ans)
tmp_df = pd.DataFrame(
data,
columns=["raw_company"]
+ sum([[f"ref_company_{i}", f"score_{i}"] for i in range(1, TOP_K + 1)], []),
)
output_file = os.path.join("output", file)
tmp_df.to_excel(output_file, index=False)
print(f"Output saved to {output_file}")
候选的公司名,经过delete_words删除掉一些词,再计算embedding。原始的公司名保存在metadata。
Document(
page_content=delete_words(ref_company),
id=idx,
metadata={"ref_company": ref_company},
)
相关文章推荐
三种文本相似计算方法:规则、向量与大模型裁判.https://blog.csdn.net/sjxgghg/article/details/145209050


















 48
48

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











