









详解PyTorch中的ModuleList和Sequential
https://mp.weixin.qq.com/s/y0PvZMgFyfK6FrY0fJ0zSw
不同点1:
nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数。
不同点2:
nn.Sequential可以使用OrderedDict对每层进行命名
不同点3:
nn.Sequential里面的模块按照顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言。
不同点4:
有的时候网络中有很多相似或者重复的层,我们一般会考虑用 for 循环来创建它们,而不是一行一行地写,比如:
layers = [nn.Linear(10, 10) for i in range(5)]那么这里我们使用ModuleList
layers = [nn.Linear(10, 10) for i in range(5)]
self.linears = nn.ModuleList(layers)vgg.features.children() 、modules()
nn.Sequential(*features[3:7])
PyTorch: .add()和.add_(),.mul()和.mul_(),.exp()和.exp_()
https://www.cnblogs.com/picassooo/p/12583881.html
Pytorch何时能够使用inplace操作
Dataset
class torch.utils.data.Dataset
表示数据集的抽象类。
所有用到的数据集都必须是其子类。这些子类都必须重写以下方法:__len__:定义了数据集的规模;__getitem__:支持0到len(self)范围内的整数索引。
DataLoader
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False,
sampler=None, batch_sampler=None, num_workers=0,
collate_fn=<function default_collate>, pin_memory=False,
drop_last=False, timeout=0, worker_init_fn=None)
数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。参数:
dataset(Dataset) – 要加载数据的数据集。
batch_size(int, 可选) – 每一批要加载多少数据(默认:1)。
shuffle(bool, 可选) – 如果每一个epoch内要打乱数据,就设置为True(默认:False)。
sampler(Sampler, 可选)– 定义了从数据集采数据的策略。如果这一选项指定了,shuffle必须是False。
batch_sampler(Sampler, 可选)– 类似于sampler,但是每次返回一批索引。和batch_size,shuffle,sampler,drop_last互相冲突。
num_workers(int, 可选) – 加载数据的子进程数量。0表示主进程加载数据(默认:0)。
collate_fn(可调用 , 可选)– 归并样例列表来组成小批。
pin_memory(bool, 可选)– 如果设置为True,数据加载器会在返回前将张量拷贝到CUDA锁页内存。
drop_last(bool, 可选)– 如果数据集的大小不能不能被批大小整除,该选项设为True后不会把最后的残缺批作为输入;如果设置为False,最后一个批将会稍微小一点。(默认:False)
timeout(数值 , 可选) – 如果是正数,即为收集一个批数据的时间限制。必须非负。(默认:0)
worker_init_fn(可调用 , 可选)– 如果不是None,每个worker子进程都会使用worker id(在[0, num_workers - 1]内的整数)进行调用作为输入,这一过程发生在设置种子之后、加载数据之前。(默认:None)
注意:
默认地,每个worker都会有各自的PyTorch种子,设置方法是base_seed + worker_id,其中base_seed是主进程通过随机数生成器生成的long型数。而其它库(如NumPy)的种子可能由初始worker复制得到, 使得每一个worker返回相同的种子。(见FAQ中的My data loader workers return identical random numbers部分。)你可以用torch.initial_seed()查看worker_init_fn中每个worker的PyTorch种子,也可以在加载数据之前设置其他种子。
警告:
如果使用了spawn方法,那么worker_init_fn不能是不可序列化对象,如lambda函数。
random_split
torch.utils.data.random_split(dataset, lengths)以给定的长度将数据集随机划分为不重叠的子数据集。
参数:
- dataset (Dataset) – 要划分的数据集。
- lengths(序列)– 要划分的长度。
train
train(mode=True)
将模块转换成训练模式。
这个函数只对特定的模块类型有效,如 Dropout和BatchNorm等等。如果想了解这些特定模块在训练/测试模式下各自的运作细节,可以看一下这些特殊模块的文档部分。
zero_grad()
zero_grad()
讲模块所有参数的梯度设置为0。
nn.Sequential
class torch.nn.Sequential(*args)
一种顺序容器。传入Sequential构造器中的模块会被按照他们传入的顺序依次添加到Sequential之上。相应的,一个由模块组成的顺序词典也可以被传入到Sequential的构造器中。
为了方便大家理解,举个简单的例子:
# 构建Sequential的例子
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# 利用OrderedDict构建Sequential的例子
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
Convolution layers (卷积层)
Conv1d
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
利用指定大小的一维卷积核对输入的多通道一维输入信号进行一维卷积操作的卷积层。
在最简单的情况下,对于输入大小为 ,输出大小为
,输出大小为 的一维卷积层,其卷积计算过程可以如下表述:
的一维卷积层,其卷积计算过程可以如下表述:
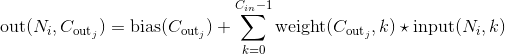
这里的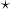 符号实际上是一个互相关(cross-correlation) 操作符(大家可以自己查一下互相关和真卷积的区别,互相关因为实现起来很简单,所以一般的深度学习框架都是用互相关操作取代真卷积),
符号实际上是一个互相关(cross-correlation) 操作符(大家可以自己查一下互相关和真卷积的区别,互相关因为实现起来很简单,所以一般的深度学习框架都是用互相关操作取代真卷积), 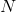 is a batch size,
is a batch size, 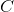 代表通道的数量,
代表通道的数量,  代表信号序列的长度。
代表信号序列的长度。
-
stride参数控制了互相关操作(伪卷积)的步长,参数的数据类型一般是单个数字或者一个只有一个元素的元组。 -
padding参数控制了要在一维卷积核的输入信号的各维度各边上要补齐0的层数。 -
dilation参数控制了卷积核中各元素之间的距离;这也被称为多孔算法(à trous algorithm)。这个概念有点难解释,这个链接link用可视化的方法很好地解释了dilation的作用。 -
groups控制了输入输出之间的连接(connections)的数量。in_channels和out_channels必须能被groups整除。举个栗子,> * 当 groups=1, 此Conv1d层会使用一个卷积层进行所有输入到输出的卷积操作。
> * 当 groups=2, 此时Conv1d层会产生两个并列的卷积层。同时,输入通道被分为两半,两个卷积层分别处理一半的输入通道,同时各自产生一半的输出通道。最后这两个卷积层的输出会被concatenated一起,作为此Conv1d层的输出。
> * 当 groups=
in_channels, 每个输入通道都会被单独的一组卷积层处理,这个组的大小是
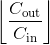
Note
取决于你卷积核的大小,有些时候输入数据中某些列(最后几列)可能不会参与计算(比如列数整除卷积核大小有余数,而又没有padding,那最后的余数列一般不会参与卷积计算),这主要是因为pytorch中的互相关操作cross-correlation是保证计算正确的操作(valid operation), 而不是满操作(full operation)。所以实际操作中,还是要亲尽量选择好合适的padding参数哦。
Note
当groups == in_channels 并且 out_channels == K * in_channels(其中K是正整数)的时候,这个操作也被称为深度卷积。 举个创建深度卷积层的例子,对于一个大小为 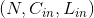 的输入,要构建一个深度乘数为
的输入,要构建一个深度乘数为K的深度卷积层,可以通过以下参数来创建: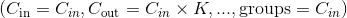 。
。
Note
当程序的运行环境是使用了CuDNN的CUDA环境的时候,一些非确定性的算法(nondeterministic algorithm)可能会被采用以提高整个计算的性能。如果不想使用这些非确定性的算法,你可以通过设置torch.backends.cudnn.deterministic = True来让整个计算过程保持确定性(可能会损失一定的计算性能)。对于后端(background),你可以看一下这一部分Reproducibility了解其相关信息。
Conv1d的参数:
- in_channels (int) – 输入通道个数
- out_channels (int) – 输出通道个数
- kernel_size (int or tuple) – 卷积核大小
- stride (int or tuple, optional) – 卷积操作的步长。 默认: 1
- padding (int or tuple, optional) – 输入数据各维度各边上要补齐0的层数。 默认: 0
- dilation (int or tuple, optional) – 卷积核各元素之间的距离。 默认: 1
- groups (int, optional) – 输入通道与输出通道之间相互隔离的连接的个数。 默认:1
- bias (bool, optional) – 如果被置为
True,向输出增加一个偏差量,此偏差是可学习参数。 默认:True
Shape:
-
输入:

-
输出:
 其中
其中
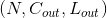
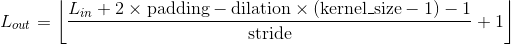
| 内部Variables: |
- weight (Tensor) – Conv1d模块中的一个大小为(out_channels, in_channels, kernel_size)的权重张量,这些权重可训练学习(learnable)。这些权重的初始值的采样空间是
 , 其中
, 其中 。
。 - bias (Tensor) – 模块的偏差项,大小为(out_channels),可训练学习。如果构造Conv1d时构造函数中的
bias被置为True,那么这些权重的初始值的采样空间是, 其中 。
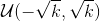

例子:
>>> m = nn.Conv1d(16, 33, 3, stride=2)
>>> input = torch.randn(20, 16, 50)
>>> output = m(input)
Conv2d
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
利用指定大小的二维卷积核对输入的多通道二维输入信号进行二维卷积操作的卷积层。
在最简单的情况下,对于输入大小为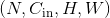 ,输出大小为
,输出大小为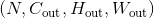 的二维维卷积层,其卷积计算过程可以如下表述:
的二维维卷积层,其卷积计算过程可以如下表述:
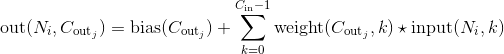
这里的符号实际上是一个二维互相关(cross-correlation) 操作符(大家可以自己查一下互相关和真卷积的区别,互相关因为实现起来很简单,所以一般的深度学习框架都是用互相关操作取代真卷积), is a batch size, 代表通道的数量, 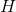 是输入的二维数据的像素高度,
是输入的二维数据的像素高度,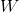 是输入的二维数据的像素宽度。
是输入的二维数据的像素宽度。
-
stride参数控制了互相关操作(伪卷积)的步长,参数的数据类型一般是单个数字或者一个只有一个元素的元组。 -
padding参数控制了要在二维卷积核的输入信号的各维度各边上要补齐0的层数。 -
dilation参数控制了卷积核中各元素之间的距离;这也被称为多孔算法(à trous algorithm)。这个概念有点难解释,这个链接link用可视化的方法很好地解释了dilation的作用。 -
groups控制了输入输出之间的连接(connections)的数量。in_channels和out_channels必须能被groups整除。举个栗子,> * 当 groups=1, 此Conv1d层会使用一个卷积层进行所有输入到输出的卷积操作。
> * 当 groups=2, 此时Conv1d层会产生两个并列的卷积层。同时,输入通道被分为两半,两个卷积层分别处理一半的输入通道,同时各自产生一半的输出通道。最后这两个卷积层的输出会被concatenated一起,作为此Conv1d层的输出。
> * 当 groups=
in_channels, 每个输入通道都会被单独的一组卷积层处理,这个组的大小是
kernel_size, stride, padding, dilation这几个参数均支持一下输入形式:
- 一个
int数字 – 二维数据的高和宽这两个维度都会采用这一个数字。- 一个由两个int数字组成的
tuple– 这种情况下,二维数据的高这一维度会采用元组中的第一个int数字,宽这一维度会采用第二个int数字。
Note
取决于你卷积核的大小,有些时候输入数据中某些列(最后几列)可能不会参与计算(比如列数整除卷积核大小有余数,而又没有padding,那最后的余数列一般不会参与卷积计算),这主要是因为pytorch中的互相关操作cross-correlation是保证计算正确的操作(valid operation), 而不是满操作(full operation)。所以实际操作中,还是要亲尽量选择好合适的padding参数哦。
Note 当groups == in_channels 并且 out_channels == K * in_channels(其中K是正整数)的时候,这个操作也被称为深度卷积。
换句话说,对于一个大小为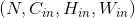 的输入,要构建一个深度乘数为
的输入,要构建一个深度乘数为K的深度卷积层,可以通过以下参数来创建: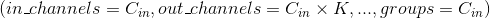 。
。
Note
当程序的运行环境是使用了CuDNN的CUDA环境的时候,一些非确定性的算法(nondeterministic algorithm)可能会被采用以提高整个计算的性能。如果不想使用这些非确定性的算法,你可以通过设置torch.backends.cudnn.deterministic = True来让整个计算过程保持确定性(可能会损失一定的计算性能)。对于后端(background),你可以看一下这一部分Reproducibility了解其相关信息。
Conv2d的参数:
- in_channels (int) – 输入通道个数
- out_channels (int) – 输出通道个数
- kernel_size (int or tuple) – 卷积核大小
- stride (int or tuple, optional) –卷积操作的步长。 默认: 1
- padding (int or tuple, optional) – 输入数据各维度各边上要补齐0的层数。 默认: 0
- dilation (int or tuple, optional) –卷积核各元素之间的距离。 默认: 1
- groups (int, optional) – 输入通道与输出通道之间相互隔离的连接的个数。 默认:1
- bias (bool, optional) – 如果被置为
True,向输出增加一个偏差量,此偏差是可学习参数。 默认:True
Shape:
-
输入:

-
输出:
 其中
其中

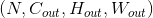
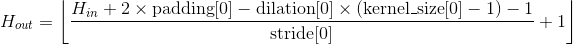
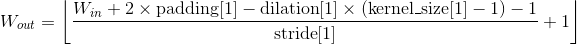
| 内部Variables: |
- weight (Tensor) – Conv2d模块中的一个大小为 (out_channels, in_channels, kernel_size[0], kernel_size[1])的权重张量,这些权重可训练学习(learnable)。这些权重的初始值的采样空间是 , 其中
 。
。 - bias (Tensor) – 块的偏差项,大小为(out_channels),可训练学习。如果构造Conv2d时构造函数中的
bias被置为True,那么这些权重的初始值的采样空间是,其中。
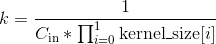
例子:
>>> # With square kernels and equal stride
>>> m = nn.Conv2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> # non-square kernels and unequal stride and with padding and dilation
>>> m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
ConvTranspose2d
class torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
利用指定大小的二维转置卷积核对输入的多通道二维输入信号进行转置卷积(当然此卷积也是互相关操作,cross-correlation)操作的模块。
该模块可以看作是Conv2d相对于其输入的梯度(the gradient of Conv2d with respect to its input, 直译), 转置卷积又被称为小数步长卷积或是反卷积(尽管这不是一个真正意义上的反卷积)。
-
stride控制了转置卷积操作的步长 -
padding控制了要在输入的各维度的各边上补齐0的层数,与Conv1d不同的地方,此padding参数与实际补齐0的层数的关系为层数 = kernel_size - 1 - padding,详情请见下面的note。 -
output_padding控制了转置卷积操作输出的各维度的长度增量,但注意这个参数不是说要往转置卷积的输出上pad 0,而是直接控制转置卷积的输出大小为根据此参数pad后的大小。更多的详情请见下面的note。 -
dilation控制了卷积核中各点之间的空间距离;这也被称为多孔算法(à trous algorithm)。这个概念有点难解释,这个链接link用可视化的方法很好地解释了dilation的作用。 -
groups控制了输入输出之间的连接(connections)的数量。in_channels和out_channels必须能被groups整除。举个栗子,> * 当 groups=1, 此Conv1d层会使用一个卷积层进行所有输入到输出的卷积操作。
> * 当 groups=2, 此时Conv1d层会产生两个并列的卷积层。同时,输入通道被分为两半,两个卷积层分别处理一半的输入通道,同时各自产生一半的输出通道。最后这两个卷积层的输出会被concatenated一起,作为此Conv1d层的输出。
> * 当 groups=
in_channels, 每个输入通道都会被单独的一组卷积层处理,这个组的大小是 。
。
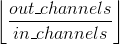
kernel_size, stride, padding, output_padding 这几个参数均支持一下输入形式:
- 一个
int数字 – 二维维数据的高和宽这两个维度都会采用这一个数字。- 一个由两个int数字组成的
tuple– 这种情况下,二维数据的高这一维度会采用元组中的第一个int数字,宽这一维度会采用第二个int数字。
Note
取决于你卷积核的大小,有些时候输入数据中某些列(最后几列)可能不会参与计算(比如列数整除卷积核大小有余数,而又没有padding,那最后的余数列一般不会参与卷积计算),这主要是因为pytorch中的互相关操作cross-correlation是保证计算正确的操作(valid operation), 而不是满操作(full operation)。所以实际操作中,还是要亲尽量选择好合适的padding参数哦。
Note
padding 参数控制了要在输入的各维度各边上补齐0的层数,与在Conv1d中不同的是,在转置卷积操作过程中,此padding参数与实际补齐0的层数的关系为层数 = kernel_size - 1 - padding, 这样设置的主要原因是当使用相同的参数构建Conv2d 和ConvTranspose2d模块的时候,这种设置能够实现两个模块有正好相反的输入输出的大小,即Conv2d的输出大小是其对应的ConvTranspose2d模块的输入大小,而ConvTranspose2d的输出大小又恰好是其对应的Conv2d模块的输入大小。然而,当stride > 1的时候,Conv2d 的一个输出大小可能会对应多个输入大小,上一个note中就详细的介绍了这种情况,这样的情况下要保持前面提到两种模块的输入输出保持反向一致,那就要用到 output_padding参数了,这个参数可以增加转置卷积输出的某一维度的大小,以此来达到前面提到的同参数构建的Conv2d 和ConvTranspose2d模块的输入输出方向一致。 但注意这个参数不是说要往转置卷积的输出上pad 0,而是直接控制转置卷积的输出各维度的大小为根据此参数pad后的大小。
Note
当程序的运行环境是使用了CuDNN的CUDA环境的时候,一些非确定性的算法(nondeterministic algorithm)可能会被采用以提高整个计算的性能。如果不想使用这些非确定性的算法,你可以通过设置torch.backends.cudnn.deterministic = True来让整个计算过程保持确定性(可能会损失一定的计算性能)。对于后端(background),你可以看一下这一部分Reproducibility了解其相关信息。
Parameters:
- in_channels (int) – 输入通道的个数
- out_channels (int) – 卷积操作输出通道的个数
- kernel_size (int or tuple) – 卷积核大小
- stride (int or tuple, optional) – 卷积操作的步长。 默认: 1
- padding (int or tuple, optional) –
kernel_size - 1 - padding层 0 会被补齐到输入数据的各边上。 默认: 0 - output_padding (int or tuple, optional) – 输出的各维度要增加的大小。默认:0
- groups (int, optional) – 输入通道与输出通道之间相互隔离的连接的个数。 默认:1
- bias (bool, optional) – 如果被置为
True,向输出增加一个偏差量,此偏差是可学习参数。 默认:True - dilation (int or tuple, optional) – 卷积核各元素之间的距离。 默认: 1
Shape:
- 输入:
- 输出: 其中

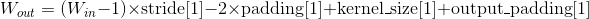
| Variables: |
- weight (Tensor) – 模块中的一个大小为 (in_channels, out_channels, kernel_size[0], kernel_size[1])的权重张量,这些权重可训练学习(learnable)。这些权重的初始值的采样空间是,其中 。
- bias (Tensor) – 模块的偏差项,大小为 (out_channels), 如果构造函数中的
bias被置为True,那么这些权重的初始值的采样空间是 ,其中 。
例子:
>>> # With square kernels and equal stride
>>> m = nn.ConvTranspose2d(16, 33, 3, stride=2)
>>> # non-square kernels and unequal stride and with padding
>>> m = nn.ConvTranspose2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
>>> input = torch.randn(20, 16, 50, 100)
>>> output = m(input)
>>> # exact output size can be also specified as an argument
>>> input = torch.randn(1, 16, 12, 12)
>>> downsample = nn.Conv2d(16, 16, 3, stride=2, padding=1)
>>> upsample = nn.ConvTranspose2d(16, 16, 3, stride=2, padding=1)
>>> h = downsample(input)
>>> h.size()
torch.Size([1, 16, 6, 6])
>>> output = upsample(h, output_size=input.size())
>>> output.size()
torch.Size([1, 16, 12, 12])
MaxPool2d
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
对输入的多通道信号执行二维最大池化操作。
最简单的情况下,对于输入大小为 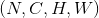 ,输出大小为
,输出大小为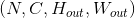 ,
,kernel_size为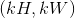 的池化操作,此池化过程可表述如下:
的池化操作,此池化过程可表述如下:

padding 参数控制了要在输入信号的各维度各边上要补齐0的层数。 dilation 参数控制了池化核中各元素之间的距离;这也被称为多孔算法(à trous algorithm)。这个概念有点难解释,这个链接link用可视化的方法很好地解释了dilation的作用。
kernel_size, stride, padding, dilation 等参数均支持以下类型输入:
- 一个单独的
int– 此时这个int会同时控制池化滑动窗的宽和高这两个维度的大小- 一个由两个
int组成的tuple– 这种情况下,高这一维度会采用元组中的第一个int数字,宽这一维度会采用第二个int数字。
Parameters:
- kernel_size – 最大池化操作的滑动窗大小
- stride – 滑动窗的步长,默认值是
kernel_size - padding – 要在输入信号的各维度各边上要补齐0的层数
- dilation – 滑动窗中各元素之间的距离
- return_indices – 如果此参数被设置为
True, 那么此池化层在返回输出信号的同时还会返回一连串滑动窗最大值的索引位置,即每个滑动窗的最大值位置信息。这些信息可以在后面的上采样torch.nn.MaxUnpool2d中被用到。 - ceil_mode – 如果此参数被设置为True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
Shape:
-
输入:

-
输出:
 , 其中
, 其中

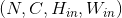
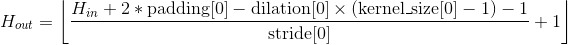
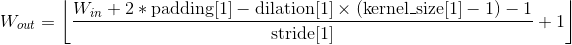
例子:
>>> # pool of square window of size=3, stride=2
>>> m = nn.MaxPool2d(3, stride=2)
>>> # pool of non-square window
>>> m = nn.MaxPool2d((3, 2), stride=(2, 1))
>>> input = torch.randn(20, 16, 50, 32)
>>> output = m(input)
MaxUnpool2d
class torch.nn.MaxUnpool2d(kernel_size, stride=None, padding=0)
MaxPool2d的逆过程,不过并不是完全的逆过程,因为在MaxPool2d的过程中,池化窗区域内的非最大值都已经丢失。 MaxUnpool2d的输入是MaxPool2d的输出,其中也包括包括滑动窗最大值的索引(即return_indices所控制的输出),逆池化操作的过程就是将MaxPool2d过程中产生的最大值插回到原来的位置,并将非最大值区域置为0。
Note
MaxPool2d操作可以将多个大小不同的输入映射到相同的输出大小。因此,池化操作的反过程,MaxUnpool2d的上采样过程的输出大小就不唯一了。为了适应这一点,可以在设置控制上采样输出大小的(output_size)参数。 具体用法,请参阅下面的输入和示例
Parameters:
- kernel_size (int or tuple) – 最大池化窗的大小
- stride (int or tuple) – 最大池化窗的步长。默认
kernel_size - padding (int or tuple) – 输入信号的各维度各边要补齐0的层数
Inputs:
input: 要执行上采样操作的张量indices:MaxPool2d池化过程中输出的池化窗最大值的位置索引output_size(选填): 指定的输出大小
Shape:
-
输入:
-
输出:
, 其中

也可以使用
output_size指定输出的大小
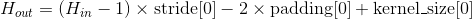
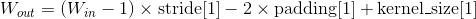
例子:
>>> pool = nn.MaxPool2d(2, stride=2, return_indices=True)
>>> unpool = nn.MaxUnpool2d(2, stride=2)
>>> input = torch.tensor([[[[ 1., 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12],
[13, 14, 15, 16]]]])
>>> output, indices = pool(input)
>>> unpool(output, indices)
tensor([[[[ 0., 0., 0., 0.],
[ 0., 6., 0., 8.],
[ 0., 0., 0., 0.],
[ 0., 14., 0., 16.]]]])
>>> # specify a different output size than input size
>>> unpool(output, indices, output_size=torch.Size([1, 1, 5, 5]))
tensor([[[[ 0., 0., 0., 0., 0.],
[ 6., 0., 8., 0., 0.],
[ 0., 0., 0., 14., 0.],
[ 16., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0.]]]])
AvgPool2d
class torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True)
对输入的多通道信号执行二维平均池化操作。 最简单的情况下,对于输入大小为 ,输出大小为,kernel_size为的池化操作,此池化过程可表述如下:
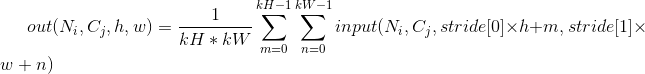
padding 参数控制了要在输入信号的各维度各边上要补齐0的层数。
kernel_size, stride, padding等参数均支持以下类型输入:
- 一个单独的
int– 此时这个int会同时控制池化滑动窗的宽和高这两个维度的大小- 一个由两个
int组成的tuple– 这种情况下,高这一维度会采用元组中的第一个int数字,宽这一维度会采用第二个int数字。
Parameters:
- kernel_size – 平均池化操作的滑动窗大小
- stride – 滑动窗的步长,默认值是
kernel_size - padding – 要在输入信号的各维度各边上要补齐0的层数
- ceil_mode – 如果此参数被设置为True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
- count_include_pad – 如果被设置为True, 那么在进行平均运算的时候也会将用于补齐的0加入运算。
Shape:
-
输入:
-
输出:
, 其中

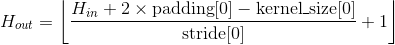

例子:
>>> # pool of square window of size=3, stride=2
>>> m = nn.AvgPool2d(3, stride=2)
>>> # pool of non-square window
>>> m = nn.AvgPool2d((3, 2), stride=(2, 1))
>>> input = torch.randn(20, 16, 50, 32)
>>> output = m(input)
ReLU
class torch.nn.ReLU(inplace=False)
Applies the rectified linear unit function element-wise 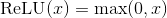
参数: inplace-选择是否进行覆盖运算

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









