




 本文详细介绍了卷积神经网络(CNN)的概念、结构特点及其应用。包括CNN的基本原理、卷积层、池化层、全连接层的作用,以及如何通过Python的TensorFlow框架实现手写数字识别。
本文详细介绍了卷积神经网络(CNN)的概念、结构特点及其应用。包括CNN的基本原理、卷积层、池化层、全连接层的作用,以及如何通过Python的TensorFlow框架实现手写数字识别。
上一章最后提到了多层神经网络(deep neural network,DNN),也叫多层感知机(Multi-Layer perceptron,MLP)。
当下流行的DNN主要分为应对具有空间性分布数据的CNN(卷积神经网络)和应对具有时间性分布数据的RNN(递归神经网络,又称循环神经网络)。
概念
CNN是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
结构
卷积神经网络通常包含以下几种层:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
1.卷积层
每一层计算的操作本质上即输入层和权重的卷积!这也就是卷积神经网络名字的由来。
主要参数:
W : 输入单元的大小(宽或高)
F : 感受野(receptive field)
S : 步幅(stride)
P : 补零(zero-padding)的数量
K : 深度,输出单元的深度
2.池化层
池化(pool)即下采样(downsamples),目的是为了减少特征图。池化操作对每个深度切片独立,规模一般为 2*2,相对于卷积层进行卷积运算,池化层进行的运算一般有以下几种:
最大池化(Max Pooling)。取4个点的最大值。这是最常用的池化方法。
均值池化(Mean Pooling)。取4个点的均值。
高斯池化。借鉴高斯模糊的方法。不常用。
可训练池化。训练函数 ff ,接受4个点为输入,出入1个点。不常用。
3.全连接层
全连接层和卷积层可以相互转换:
对于任意一个卷积层,要把它变成全连接层只需要把权重变成一个巨大的矩阵,其中大部分都是0 除了一些特定区块(因为局部感知),而且好多区块的权值还相同(由于权重共享)。
相反地,对于任何一个全连接层也可以变为卷积层。比如,一个K=4096 的全连接层,输入层大小为 7∗7∗512,它可以等效为一个 F=7, P=0, S=1, K=4096 的卷积层。换言之,我们把 filter size 正好设置为整个输入层大小。
特点
1.局部感知:通过上一章可以看出,传统神经网络把输入层和隐含层进行全连接,这使得计算量非常的庞大。而卷积神经网络在这部分进行了优化,即巻积层对隐含单元和输入单元间的连接加以限制:每个隐含单元仅仅只能连接输入单元的一部分。每个隐含单元连接的输入区域大小叫r神经元的感受野(receptive field)。卷积层的参数包含一系列过滤器(filter),每个过滤器训练一个深度,有几个过滤器输出单元就具有多少深度。
2.权重共享:我们把同一深度的平面叫做深度切片,那么同一个切片应该共享同一组权重和偏置。我们仍然可以使用梯度下降的方法来学习这些权值,只需要对原始算法做一些小的改动, 这里共享权值的梯度是所有共享参数的梯度的总和。这样做的好处是重复单元能够对特征进行识别,而不考虑它在可视域中的位置。另一方面,权重共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
3.多卷积核&层&map
深度调参是门手艺,卷积神经网络的卷积核大小、卷积层数、每层map个数等对其效果及计算量都影响巨大,卷积网络本身就是个bp网络, 他调整卷积核的权值是跟数据传播完全逆向的过程。对于某层的实际输出和目标输出的差值。需要对这一层进行权值矩阵的导数求解,即雅各比行列式。然后再逆向对上一层做同样的修正(即训练) 所以层数决定调整的迭代次数。至于其侧重方向,有一位大♂师曾这样说过:喜欢小而深,厌恶大而短。

框架
CNN主要流行框架有:
1.Caffe:源于Berkeley的主流CV工具包,支持C++,python,matlab,Model Zoo中有大量预训练好的模型供使用
2.TensorFlow:Google的深度学习框架,TensorBoard可视化很方便,数据和模型并行化好,速度快
3.Torch:Facebook用的卷积神经网络工具包,通过时域卷积的本地接口,使用非常直观,定义新网络层简单
实例代码:
以降维小结内章的手写数字为例(python的TensorFlow框架):

import tensorflow as tf
from sklearn.datasets import load_digits
import numpy as np
from time import time
digits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.astype(np.float32).reshape(-1,1)
#print (X_data.shape)
#print (Y_data.shape)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
from sklearn.preprocessing import OneHotEncoder
Y = OneHotEncoder().fit_transform(Y_data).todense() #one-hot编码
# 转换为图片的格式 (batch,height,width,channels)
X = X_data.reshape(-1,8,8,1)
batch_size = 8 # 使用MBGD算法,设定batch_size为8
def generatebatch(X,Y,n_examples, batch_size):
for batch_i in range(n_examples // batch_size):
start = batch_i*batch_size
end = start + batch_size
batch_xs = X[start:end]
batch_ys = Y[start:end]
yield batch_xs, batch_ys # 生成每一个batch
tf.reset_default_graph()
# 输入层
tf_X = tf.placeholder(tf.float32,[None,8,8,1])
tf_Y = tf.placeholder(tf.float32,[None,10])
# 卷积层+激活层
conv_filter_w1 = tf.Variable(tf.random_normal([3, 3, 1, 10]))
conv_filter_b1 = tf.Variable(tf.random_normal([10]))
relu_feature_maps1 = tf.nn.relu(\
tf.nn.conv2d(tf_X, conv_filter_w1,strides=[1, 1, 1, 1], padding='SAME') + conv_filter_b1)
# 池化层
max_pool1 = tf.nn.max_pool(relu_feature_maps1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print (max_pool1)
# 卷积层
conv_filter_w2 = tf.Variable(tf.random_normal([3, 3, 10, 5]))
conv_filter_b2 = tf.Variable(tf.random_normal([5]))
conv_out2 = tf.nn.conv2d(relu_feature_maps1, conv_filter_w2,strides=[1, 2, 2, 1], padding='SAME') + conv_filter_b2
print (conv_out2)
# BN归一化层+激活层
batch_mean, batch_var = tf.nn.moments(conv_out2, [0, 1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros([5]))
scale = tf.Variable(tf.ones([5]))
epsilon = 1e-3
BN_out = tf.nn.batch_normalization(conv_out2, batch_mean, batch_var, shift, scale, epsilon)
print (BN_out)
relu_BN_maps2 = tf.nn.relu(BN_out)
# 池化层
max_pool2 = tf.nn.max_pool(relu_BN_maps2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print (max_pool2)
# 将特征图进行展开
max_pool2_flat = tf.reshape(max_pool2, [-1, 2*2*5])
# 全连接层
fc_w1 = tf.Variable(tf.random_normal([2*2*5,50]))
fc_b1 = tf.Variable(tf.random_normal([50]))
fc_out1 = tf.nn.relu(tf.matmul(max_pool2_flat, fc_w1) + fc_b1)
# 输出层
out_w1 = tf.Variable(tf.random_normal([50,10]))
out_b1 = tf.Variable(tf.random_normal([10]))
pred = tf.nn.softmax(tf.matmul(fc_out1,out_w1)+out_b1)
loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss)
y_pred = tf.argmax(pred,1)
bool_pred = tf.equal(tf.argmax(tf_Y,1),y_pred)
accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 准确率
print ('begin')
t0 = time()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(1001): # 迭代周期
for batch_xs,batch_ys in generatebatch(X,Y,Y.shape[0],batch_size): # 每个周期进行MBGD算法
sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys})
if(epoch%100==0):
res = sess.run(accuracy,feed_dict={tf_X:X,tf_Y:Y})
print (epoch,res)
res_ypred = y_pred.eval(feed_dict={tf_X:X,tf_Y:Y}).flatten() # 只能预测一批样本,不能预测一个样本
#print (res_ypred)
print ('end')
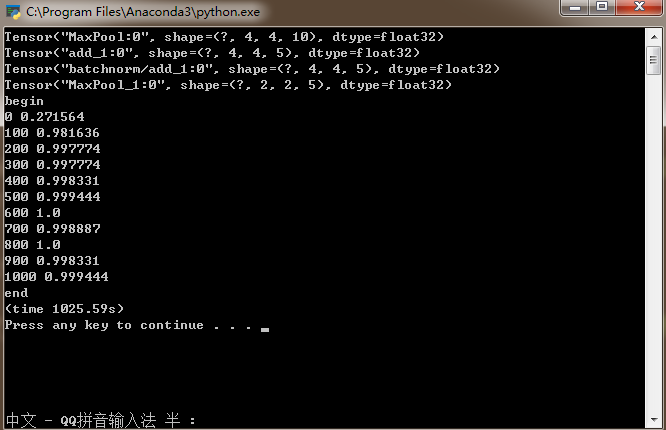
print ("(time %.2fs)" %(time() - t0))其准确率:
相关学习资源
http://blog.csdn.net/qq_25762497/article/details/51052861#详解卷积神经网络cnn
https://www.cnblogs.com/nsnow/p/4562308.html
http://blog.csdn.net/cxmscb/article/details/71023576

















 2417
2417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









