







 本文详细介绍了语义分割任务中的IoU(交并比)与MIoU(平均交并比)概念,包括它们的定义、计算方法及应用场景,并通过混淆矩阵直观展示各类别预测准确率。
本文详细介绍了语义分割任务中的IoU(交并比)与MIoU(平均交并比)概念,包括它们的定义、计算方法及应用场景,并通过混淆矩阵直观展示各类别预测准确率。
一.IOU理解
在语义分割的问题中,交并比就是该类的真实标签和预测值的交和并的比值
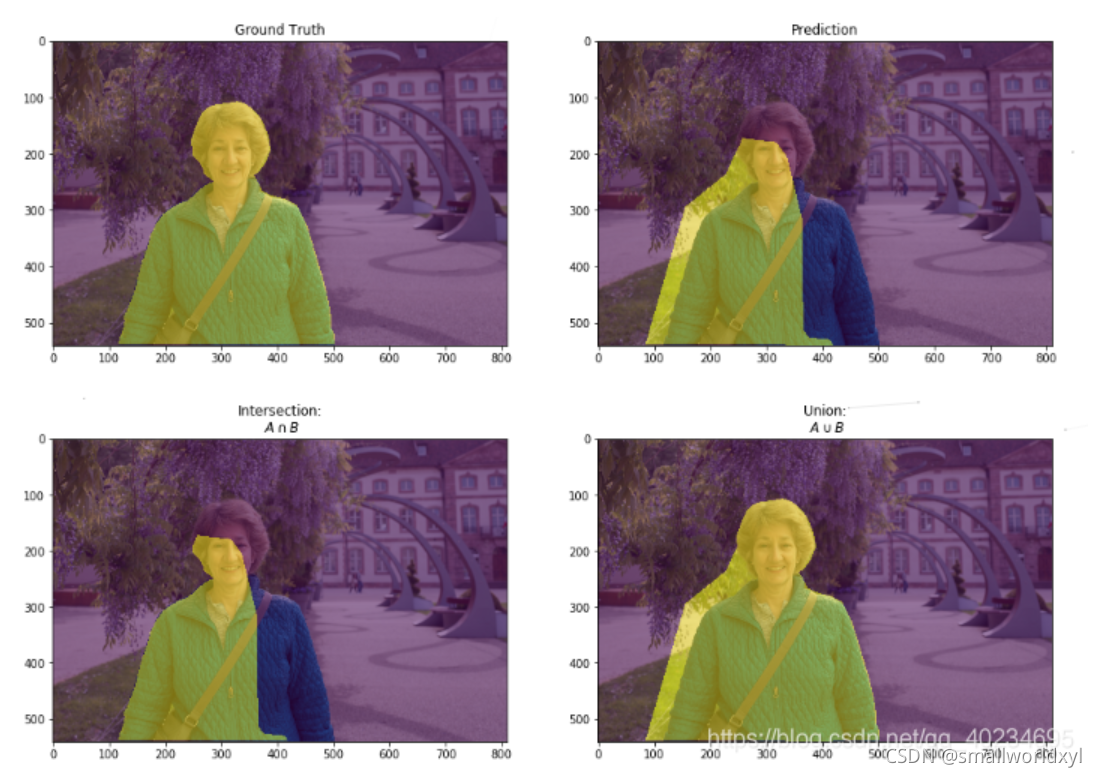
单类的交并比可以理解为下图:
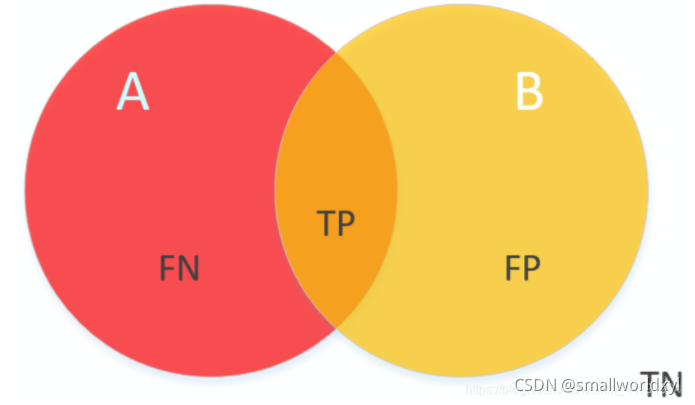
TP: 预测正确,真正例,模型预测为正例,实际是正例
FP: 预测错误,假正例,模型预测为正例,实际是反例
FN: 预测错误,假反例,模型预测为反例,实际是正例
TN: 预测正确,真反例,模型预测为反例,实际是反例
IoU = TP / (TP + FN + FP)
二.MIoU
MIOU就是该数据集中的每一个类的交并比的平均,计算公式如下:
Pij表示将i类别预测为j类别。
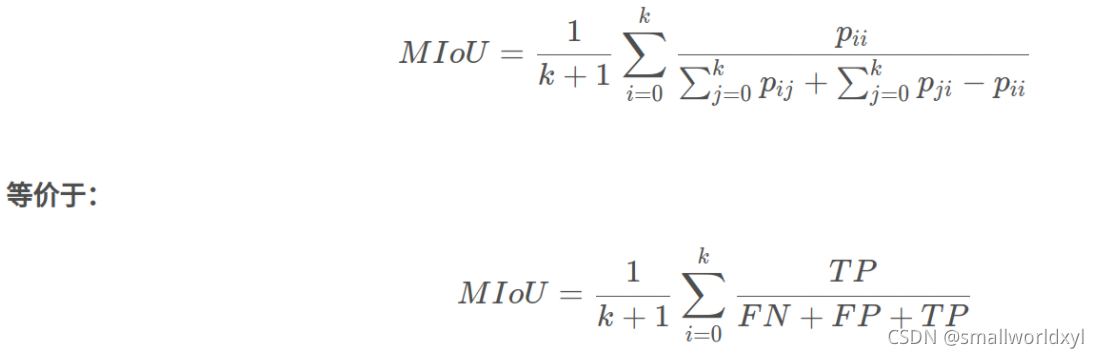
三.混淆矩阵
1.原理
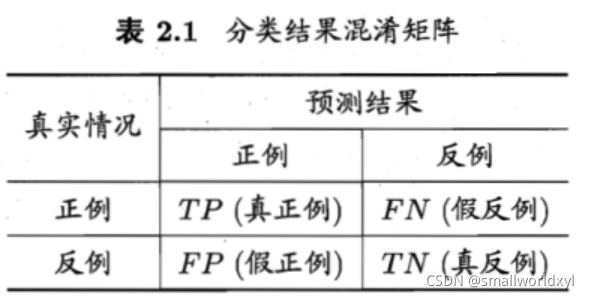
以西瓜书上的图为例:
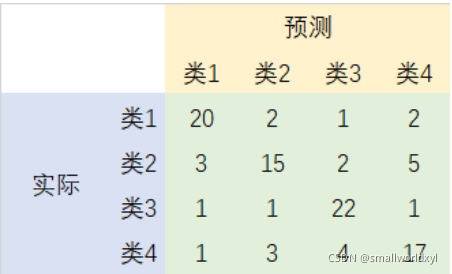
举一个简单的例子,假设有一个四种类别的分割实例,其混淆矩阵如下:
每一行之和是该类的真实样本数量,每一列之和是预测为该类的样本数量。第一行代表有20个实际为类1的样本被分为类1,有2个实际为类1的样本被分为类2,有1个实际为类1的样本被分为类3,有1个实际为类1的样本被分为类4。
2.代码
先介绍一个函数np.bincount。

其大致的意思是,给一个向量x,x中最大的元素记为j,返回一个向量1行j+1列的向量y,y[i]代表i在x中出现的次数。
x中最大的数为7,那么它的索引值为0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
索引0出现了1次,索引1出现了3次......索引5出现了0次......
np.bincount(x)
因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1])
如果minlength被指定,那么输出数组中的索引至少为它指定的数。即下标为0->minlength-1
我们可以看到x中最大的数为3,那么它的索引值为0->3
x = np.array([3, 2, 1, 3, 1])
本来bin的数量为4,现在我们指定了参数为7,因此现在bin的数量为7,所以现在它的索引值为0->6
np.bincount(x, minlength=7)
因此,输出结果为:array([0, 2, 1, 2, 0, 0, 0])
再来看混淆矩阵计算的代码
'''
产生n×n的分类统计表
参数a:标签图(转换为一行输入),即真实的标签
参数b:score层输出的预测图(转换为一行输入),即预测的标签
参数n:类别数
'''
def fast_hist(a, b, n):
#k为掩膜(去除了255这些点(即标签图中的白色的轮廓),其中的a>=0是为了防止bincount()函数出错)
k = (a >= 0) & (a < n)
return np.bincount(n * a[k].astype(int) + b[k], minlength=n**2).reshape(n, n)
输入a为标签图的向量,b为预测出的向量。n是类别个数。以如下这个例子举列,左边为真实的标签图,右边为预测的结果标签。
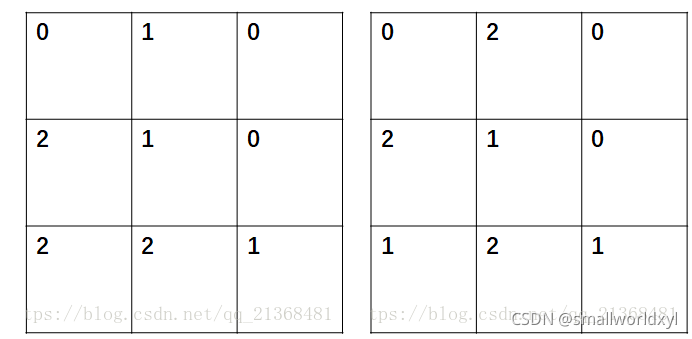
a=np.array([0,1,0,2,1,0,2,2,1])
b=np.array([0,2,0,2,1,0,1,2,1])
k = (a >= 0) & (a < 3)
k:
array([ True, True, True, True, True, True, True, True, True])
k的作用是防止出错,确保标签的分类都包含在n的类别中
n=3
n * a[k].astype(int)
b[k]
y=n * a[k].astype(int) + b[k]
array([0, 3, 0, 6, 3, 0, 6, 6, 3])
array([0, 2, 0, 2, 1, 0, 1, 2, 1])
y:
array([0, 5, 0, 8, 4, 0, 7, 8, 4])
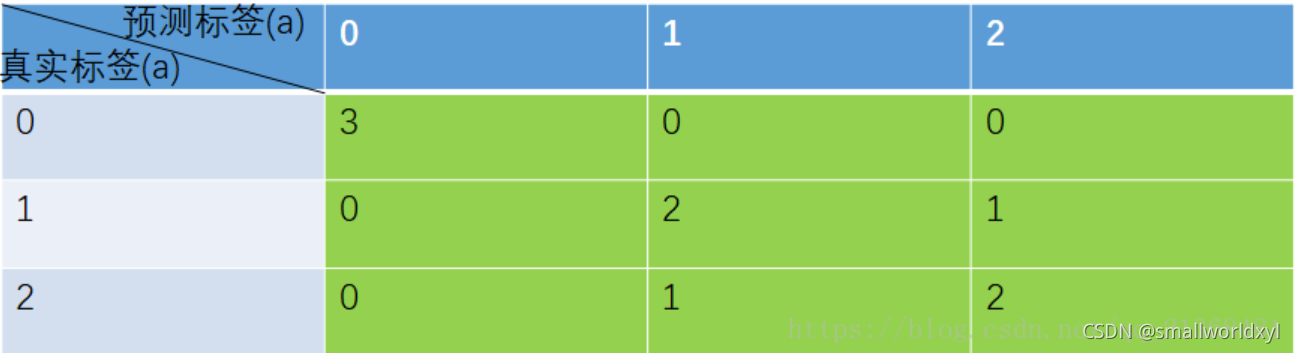
x=np.bincount(n * a[k].astype(int) + b[k], minlength=n**2).reshape(n, n)
x:
array([[3, 0, 0],
[0, 2, 1],
[0, 1, 2]], dtype=int64)
混淆矩阵如下图:
这里为什么要先对真实标签*n然后加上预测标签,再进行bincount。个人理解:
对真实标签*3可以将最后的结果每三个看成一组,从前到后分别代表该类真实为i类别,预测为0,1,2类别的个数,方便最后resize成3*3。
以真实标签中的0类别为例,真实标签中的0x3后还是0,与预测标签对位相加后,如果预测的也是0,那结果也是0,通过bincount,得到的最终向量第一个数是相加向量中0的个数,也就是代表预测为0真实也为0的个数。如果预测的是1,0x3+1=1,通过bincount会统计所有为1的个数放在结果的第二位,代表真实为0预测为1的个数。
其他分类同理。
四.利用混淆矩阵求iou和miou
计算每一个分类的iou代码,参数hist是混淆矩阵
def per_class_iu(hist):
# 矩阵的对角线上的值组成的一维数组/矩阵的所有元素之和,返回值形状(n,)
return np.diag(hist) / (hist.sum(1) + hist.sum(0) - np.diag(hist))
mIOU就是每一个类的IOU的平均,所以只需要对每一个类都按照上面计算IOU,再求平均获得mIOU就行了
计算miou代码
np.mean(per_class_iu(hist)
通过该矩阵可以计算
IoU类别0 = 3 / (3 + 0 + 0 + 0 + 0) = 1
IoU类别1 = 2 / (0 + 2 + 1 + 0 + 1) = 0.5
IoU类别2 = 2 / (0 + 1 + 2 + 0 + 1) = 0.5
MIoU = sum(IoUi) / 类别数 = (1 + 0.5 + 0.5) / 3 = 0.67
实际项目中的代码
# 设标签宽W,长H
def fast_hist(a, b, n):
#--------------------------------------------------------------------------------#
# a是转化成一维数组的标签,形状(H×W,);b是转化成一维数组的预测结果,形状(H×W,)
#--------------------------------------------------------------------------------#
k = (a >= 0) & (a < n)
#--------------------------------------------------------------------------------#
# np.bincount计算了从0到n**2-1这n**2个数中每个数出现的次数,返回值形状(n, n)
# 返回中,写对角线上的为分类正确的像素点
#--------------------------------------------------------------------------------#
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
def per_class_iu(hist):
return np.diag(hist) / np.maximum((hist.sum(1) + hist.sum(0) - np.diag(hist)), 1)
def per_class_PA(hist):
return np.diag(hist) / np.maximum(hist.sum(1), 1)
def compute_mIoU(gt_dir, pred_dir, png_name_list, num_classes, name_classes):
print('Num classes', num_classes)
#-----------------------------------------#
# 创建一个全是0的矩阵,是一个混淆矩阵
#-----------------------------------------#
hist = np.zeros((num_classes, num_classes))
#------------------------------------------------#
# 获得验证集标签路径列表,方便直接读取
# 获得验证集图像分割结果路径列表,方便直接读取
#------------------------------------------------#
gt_imgs = [join(gt_dir, x + ".png") for x in png_name_list]
pred_imgs = [join(pred_dir, x + ".png") for x in png_name_list]
#------------------------------------------------#
# 读取每一个(图片-标签)对
#------------------------------------------------#
for ind in range(len(gt_imgs)):
#------------------------------------------------#
# 读取一张图像分割结果,转化成numpy数组
#------------------------------------------------#
pred = np.array(Image.open(pred_imgs[ind]))
#------------------------------------------------#
# 读取一张对应的标签,转化成numpy数组
#------------------------------------------------#
label = np.array(Image.open(gt_imgs[ind]))
# 如果图像分割结果与标签的大小不一样,这张图片就不计算
if len(label.flatten()) != len(pred.flatten()):
print(
'Skipping: len(gt) = {:d}, len(pred) = {:d}, {:s}, {:s}'.format(
len(label.flatten()), len(pred.flatten()), gt_imgs[ind],
pred_imgs[ind]))
continue
#------------------------------------------------#
# 对一张图片计算21×21的hist矩阵,并累加
#------------------------------------------------#
hist += fast_hist(label.flatten(), pred.flatten(),num_classes)
# 每计算10张就输出一下目前已计算的图片中所有类别平均的mIoU值
if ind > 0 and ind % 10 == 0:
print('{:d} / {:d}: mIou-{:0.2f}; mPA-{:0.2f}'.format(ind, len(gt_imgs),
100 * np.nanmean(per_class_iu(hist)),
100 * np.nanmean(per_class_PA(hist))))
#------------------------------------------------#
# 计算所有验证集图片的逐类别mIoU值
#------------------------------------------------#
mIoUs = per_class_iu(hist)
mPA = per_class_PA(hist)
#------------------------------------------------#
# 逐类别输出一下mIoU值
#------------------------------------------------#
for ind_class in range(num_classes):
print('===>' + name_classes[ind_class] + ':\tmIou-' + str(round(mIoUs[ind_class] * 100, 2)) + '; mPA-' + str(round(mPA[ind_class] * 100, 2)))
#-----------------------------------------------------------------#
# 在所有验证集图像上求所有类别平均的mIoU值,计算时忽略NaN值
#-----------------------------------------------------------------#
print('===> mIoU: ' + str(round(np.nanmean(mIoUs) * 100, 2)) + '; mPA: ' + str(round(np.nanmean(mPA) * 100, 2)))
return mIoUs
参考博文:
https://blog.csdn.net/sinat_29047129/article/details/103642140
https://blog.csdn.net/u012370185/article/details/94409933
https://blog.csdn.net/qq_21368481/article/details/80424754
https://blog.csdn.net/xlinsist/article/details/51346523
https://blog.csdn.net/weixin_44791964/article/details/107687970

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









