






从单张图像生成灵活视角(如360°旋转、缩放)的3D场景是计算机视觉领域的核心挑战,其难点在于单视角图像缺乏3D几何信息,现有方法在视角跨度大时易出现模糊或结构失真。针对这一瓶颈,本文提出FlexWorld框架,通过两阶段创新实现突破:首先,基于预训练视频扩散模型构建高质量新视角生成器(V2V),利用深度估计数据提升跨视角一致性,解决大角度视角变换下的内容生成问题;其次,设计渐进式场景扩展策略,通过几何感知融合将局部生成内容逐步整合为全局一致的3D场景。
©️【深蓝AI】编译
该框架在多项指标和数据集上超越现有方法,首次实现了从单图生成高保真动态场景(如全景旋转与缩放),为影视制作、虚拟现实等需多视角交互的应用提供了新思路。研究意义不仅在于技术突破,更验证了视频模型在静态场景动态化中的潜力,为数据驱动的3D重建开辟了高效路径。
论文出处:arXiv
论文标题:lexWorld: Progressively Expanding 3D Scenes for Flexiable-View Synthesis
论文作者:Luxi Chen, Zihan Zhou, Min Zhao, Yikai Wang, Ge Zhang, Wenhao Huang, Hao Sun, Ji-Rong Wen, Chongxuan Li
项目地址:FlexWorld: Progressively Expanding 3D Scenes for Flexiable-View Synthesis

图1|效果演示:能够从具有大范围变化的多样化相机轨迹下的不完整场景渲染中生成高质量视频©️【深蓝AI】编译
1. 引入
该研究旨在从单张图像创建具有灵活视角的三维场景,这在考古保护和自动导航等领域具有变革性潜力。然而,该任务本质上是一个病态问题:单个二维观察结果无法提供足够的信息来解析完整的三维结构。特别是在拓展至极端视角(如180°旋转)时,先前被遮挡或完全缺失的内容可能会出现,从而引入显著的不确定性。
生成式模型,尤其是扩散模型,为这一问题提供了一种系统且有效的解决方案。尽管现有方法通常依赖于预训练的生成模型作为新视角合成的先验知识,但仍然存在显著的局限性。基于图像的扩散方法往往会累积几何误差,而基于视频的扩散方法在处理动态内容和摄像机监督不足方面表现不佳。近年来,一些研究尝试引入点云先验以提高一致性,尽管展现了一定的前景,但在大视角变化的情况下仍然缺乏可扩展性。
为此,该研究提出了FlexWorld,一种用于从单张图像生成灵活视角三维场景的方法。与现有方法不同,FlexWorld 通过合成和整合新的三维内容,逐步扩展持久化的三维表示。该框架由两个核心组件构成:(1) 一个强大的视频到视频(V2V)扩散模型,可从粗略场景渲染的不完整视角生成完整的视图图像;(2) 一个几何感知的三维场景扩展过程,该过程提取新的三维内容并将其整合到全局结构中。特别地,该研究通过在高精度深度估计的训练数据上微调先进的视频基础模型,使得 V2V 模型能够在大范围摄像机变化的情况下生成高质量的内容。基于此,场景扩展过程结合摄像机轨迹规划、场景融合和优化,使得从单张图像逐步构建详细的三维场景成为可能。
大量实验表明,FlexWorld 在高质量视频和灵活视角三维场景合成方面的有效性。特别是,V2V 模型在多个基准测试数据集上均超越了当前最先进的基线方法,同时在摄像机可控性方面表现出色。此外,在三维场景生成任务中,FlexWorld 亦展现出卓越的视觉质量和一致性,使得该框架能够生成高保真度的 360° 旋转和缩放视角场景。
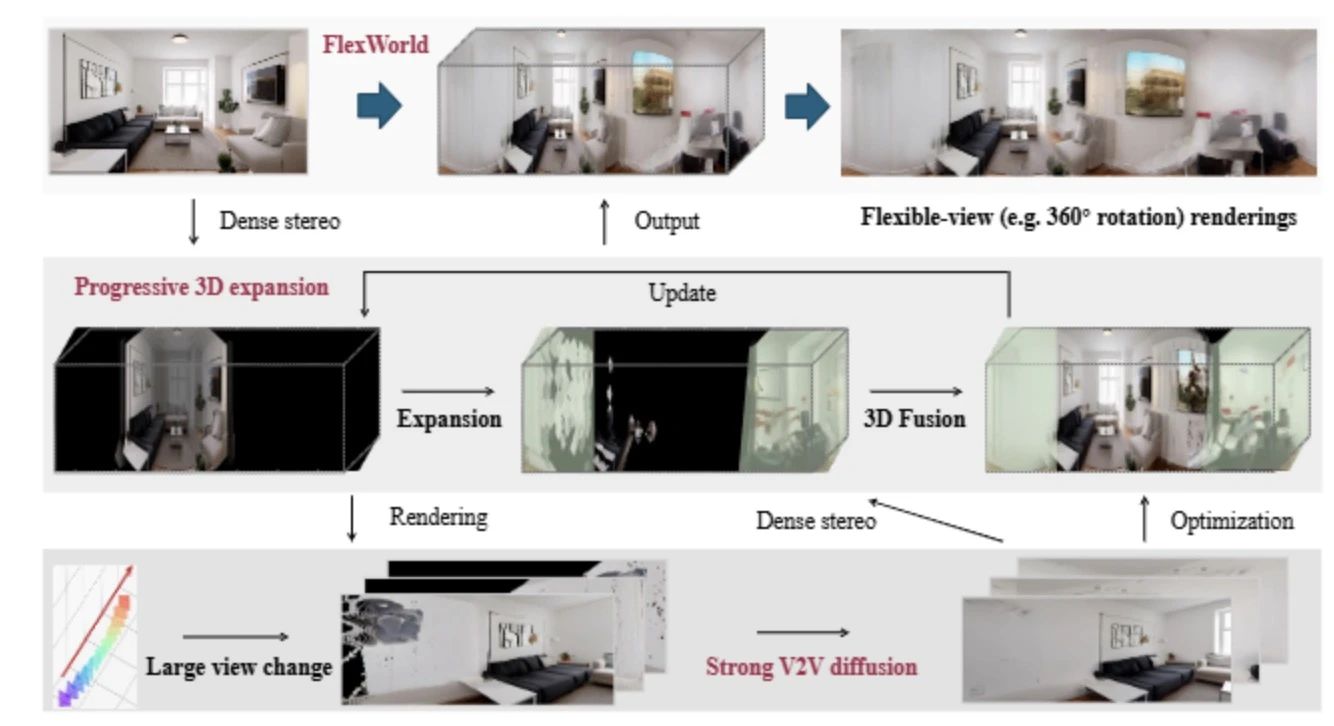
图2|全文方法总览©️【深蓝AI】编译
2. 具体方法与实现
FlexWorld的方法总览如图1所示,FlexWorld训练了一个强大的视频到视频(V2V)扩散模型,能够从由粗糙3D场景渲染的不完整视角生成高质量视频。它通过密集立体模型从精炼视频中估计新的3D内容,逐步扩展3D场景。最终,从单张图像中,它生成一个能够渲染灵活视角的详细3D场景。
2.1 渐进式灵活视角三维场景扩展
由于单个视频中的视角有限,难以生成完整的三维场景,该研究提出了一种渐进式场景扩展方法 FlexWorld。其核心包括两部分:
1. 基于摄像机轨迹的全新视角视频合成:探索未知区域,生成新视角的视频。
2. 几何感知的三维场景扩展:将新生成的三维内容整合到全局场景中,同时保持几何一致性。
在该过程中,V2V 模型用于从粗糙场景的渲染视图生成高质量的视图视频。该部分主要讨论几何感知的三维场景扩展,包括以下三个关键步骤:
(1) 摄像机轨迹规划
摄像机轨迹决定了需要扩展的区域。然而,如果某些区域缺乏三维信息,V2V 模型的摄像机控制能力会受到限制。因此,该研究优先引导摄像机移动至包含三维信息的区域,确保输入视频始终包含可用于学习的三维内容。具体步骤如下:
● 从单张输入图像构建初始粗糙场景,并通过 拉远变焦(zoom-out) 生成新视角,以扩展场景范围。
● 交替进行 180° 旋转,以丰富场景细节,最终实现完整的 360° 视角。
(2) 场景融合
从生成的视频中提取三维信息,并将其整合到全局场景中。具体方法如下:
● 选择 𝑚 个关键帧,从生成的视频中提取点云。
● 使用 DUSt3R 生成每个关键帧的初始深度图,并同时生成参考视图的深度图。
● 计算参考视图的深度尺度,并对关键帧深度进行对齐:
● 将关键帧深度投影回三维点云,并转换为 3DGS 表示,随后优化整个场景。
(3) 细化过程
为了进一步提高视觉质量,该研究采用 SDEdit 方法,通过 FLUX.1-dev 图像扩散模型执行去噪优化:
其中,是扩散过程的时间步,
是去噪模型,
是优化后的图像。最终,该研究使用优化后的图像来细化 3DGS 场景。

图3|不同模型方法生成效果对比:红色边界框标识了生成内容中的3D不一致性或视觉质量较差的部分。该研究提出的模型生成了更高质量且更一致的静态3D场景。©️【深蓝AI】编译
2.2 改进的扩散模型用于新视角合成
现有的 V2V 方法难以处理大视角变化(如 180° 旋转),主要原因包括:
1. 使用较弱的基础模型进行训练。
2. 训练数据质量较低,包含较多伪影。
该研究通过以下两方面改进 V2V 扩散模型:
(1) 视频条件训练
选择 CogVideoX-5B-I2V 作为基础模型,并引入视频条件训练。具体做法如下:
● 使用 3D-VAE 编码器压缩条件视频,并与噪声潜变量进行通道级拼接。
●设定摄像机轨迹,学习分布
,其中
是粗糙场景渲染的不完整视频,
是目标高质量视频。
(2) 高质量训练数据构建
由于现有数据集存在大量伪影,该研究提出新的数据构建流程:
● 使用 3DGS 重建完整的三维场景,获取更精准的深度估计。
● 在该场景上选取随机帧,提取深度图并回投至点云。
● 从合成数据集中采样复杂的摄像机轨迹,渲染 49 帧不完整视频。
● 将不完整视频与真实场景配对,构建高质量训练样本。
此外,为了支持静态场景和大摄像机变化,该研究选择 DL3DV-10K 作为训练数据集,并排除含有动态物体的 RealEstate10K 数据。经过训练后,该视频模型可在大视角变化下从不完整输入生成高质量新视角内容,极大提升了 FlexWorld 生成灵活视角三维场景的能力。

图4|展示了由密集立体模型MASt3R生成的初始点云渲染的不完整视频帧,以及该研究的3DGS重建结果。该研究生成的不完整视频与真实值对齐更好,从而提供了更高质量的训练对©️【深蓝AI】编译
3.实验
实验部分通过对比其在新视角合成和三维场景生成方面的性能,并通过消融实验验证关键组件的必要性,对比选择的方法为MotionCrtl,CameraCtrl,DimensionX,See3D与ViewCrafter,选用的数据集为:
● RealEstate10K:随机选取 300 段视频,采样步长为 1 至 3 帧。
● Tanks-and-Temples:从 14 个测试场景中随机选取 100 段视频,采样步长为 4 帧,并使用 MASt3R 进行摄像机标注。
每段视频包含 49 帧摄像机运动轨迹。对于生成帧数少于 49 的模型,采用 统一剔除 方式,使得摄像机轨迹长度匹配,随后我们一起来看看实验效果吧:

图5|视觉质量对比实验结果©️【深蓝AI】编译
定性结果(图5)表明,所有方法在一定程度上能够控制摄像机运动,其中 ViewCrafter、See3D 和 FlexWorld 具备较高的摄像机控制精度。然而,不同方法在 视觉质量 上表现存在显著差异:
MotionCtrl 存在较多伪影,而CameraCtrl 生成内容模糊,同时See3D 在大视角变化时难以生成全新内容,观察到ViewCrafter 输出内容整体偏暗,相比之下,FlexWorld 在视觉质量和摄像机控制方面均优于基线模型。
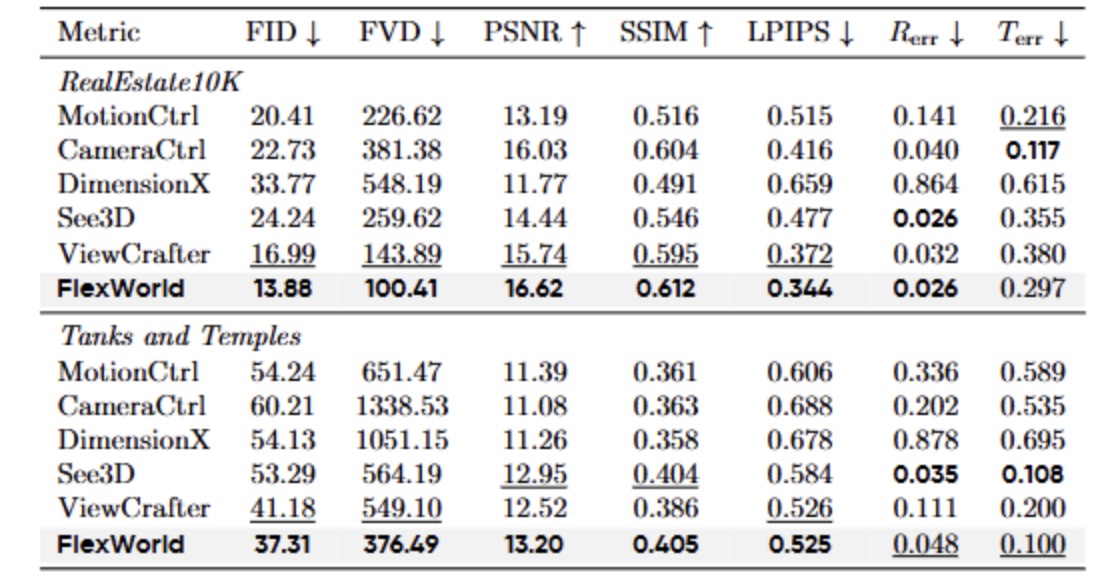
图6|视觉质量实验定量结果©️【深蓝AI】编译
实验结果(图6)表明,FlexWorld 在多个数据集上的各项指标均优于现有方法:
FID 和 FVD 最优,表明生成内容的分布与真实数据最接近;PSNR、SSIM 和 LPIPS 最优,说明生成内容的视觉质量更高;Rerr 和 Terr 误差最低,表明摄像机控制精度最佳。
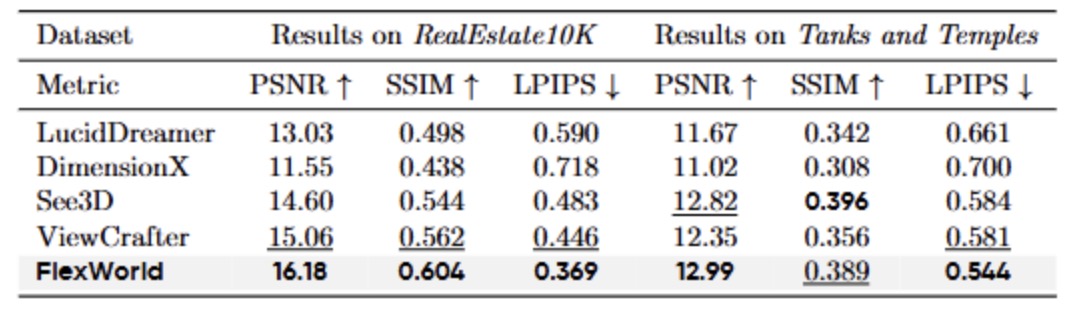
图7|三维场景生成对比实验定量结果©️【深蓝AI】编译

图8|三维场景生成对比实验可视化结果(定性)©️【深蓝AI】编译
定量分析(图 7)进一步验证了这一优势:FlexWorld 在几乎所有指标上均优于基线方法,仅在 Tanks 数据集的 SSIM 指标上略低于 See3D。定性分析(图 8)表明,FlexWorld 生成的三维场景在输入内容一致性方面显著优于基线模型,尤其是在新增视角区域,其生成内容展现出更高的视觉质量。综合定性与定量结果,FlexWorld 生成的三维场景不仅在 3D 结构一致性上表现优异,同时在视觉质量方面也展现了显著优势,证明了其在三维场景生成任务中的有效性。

图9|消融实验结果©️【深蓝AI】编译
作者还通过消融实验分析了 FlexWorld 关键组件的作用,结果如图 9 所示。首先,V2V 模型的重要性体现在用 ViewCrafter 替换 FlexWorld 的 V2V 模型后,生成内容出现明显模糊(见图 9a),这表明高质量的新视角视频对于场景扩展至关重要。其次,摄像机轨迹规划的重要性通过去掉 Zoom-out 轨迹的实验得以验证,生成场景的内容与输入视角不匹配,导致结构模糊(见图 9b),说明初始拉远变焦(Zoom-out)对于扩展三维场景不可或缺。最后,细化过程的重要性体现在去掉细化过程后,最终 3DGS 场景的细节显著减少(见图 9c),表明 FLUX.1-dev 细化过程能进一步提升视觉质量。综上所述,V2V 模型、摄像机轨迹规划和细化过程均为 FlexWorld 实现高质量三维场景生成的关键组件。
总结
该研究提出 FlexWorld,一个用于 从单张图像生成灵活视角三维场景 的框架。其核心包括:
● V2V 扩散模型,用于生成高质量的新视角图像。
● 渐进式三维场景扩展,通过摄像机轨迹规划、场景融合和优化,实现完整 3D 结构。
实验结果表明,FlexWorld 在新视角合成和三维场景生成方面均显著优于现有方法,并能支持 360° 旋转和缩放。该方法在 虚拟现实内容创作和 3D 旅游 方面具有重要应用潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









