







第三章 搭建向量知识库
此为动手学大模型应用开发的读书笔记,小白一枚,有错欢迎大佬指错,也欢迎大家去看原版
向量及向量知识库
词向量与向量
在机器学习和自然语言处理(NLP)中,**词向量(word embedding)**是一种以单词为单位将每个单词转化为实数向量的技术。词向量背后的主要想理念是相似或相关的对象在向量空间中的距离应该很近。
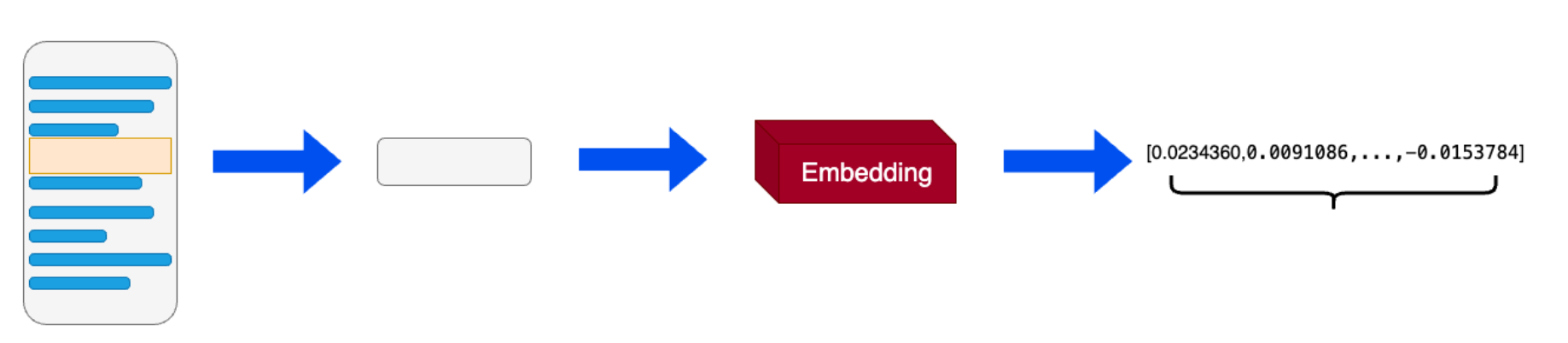
词向量虽然可以在一定程度上捕捉并表达文本中的语义信息,但忽略了单词在不同语境中的意思会受到影响这一现实。因此在RAG应用中使用的向量技术一般为通用文本向量(Universal text embedding),该技术可以对一定范围内任意长度的文本进行向量化,与词向量不同的是向量化的单位不再是单词而是输入的文本,输出的向量会捕捉更多的语义信息。
在**RAG(Retrieval Augmented Generation,检索增强生成)**方面向量的优势主要有两点:
- 向量比文字更适合检索
- 向量比其它媒介的综合信息能力更强
在搭建 RAG 系统时,我们往往可以通过使用向量模型来构建向量,我们可以选择:
- 使用各个公司的 Embedding API
- 在本地使用向量模型将数据构建为向量
向量数据库
向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统,其主要关注向量数据的特征和相似值,它用于高效计算和管理大量向量数据。
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索,它通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。因此,在处理海量向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
以下是三个向量数据库:
- Chroma:是一个轻量级向量数据库,拥有丰富的功能和简单的 API,具有简单、易用、轻量的优点,但功能相对简单且不支持GPU加速,适合初学者。
- Weaviate:是一个开源向量数据库。除了支持相似度搜索和最大边际相关性(MMR,Maximal Marginal Relevance)搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索,从而提高搜索结果的相关性和准确性。
- Qdrant:使用 Rust 语言开发,有极高的检索效率和RPS(Requests Per Second),支持本地运行、部署在本地服务器及Qdrant云三种部署模式。且可以通过为页面内容和元数据制定不同的键来复用数据。
使用 Embedding API
PS:为了方便embedding api调用,应将密钥填入llm_universe下的.env文件,代码将自动读取并加载环境变量。
由于本人能力有限,所以只实践了智谱API,想了解别的模型,推荐大家去看原版搭建知识库
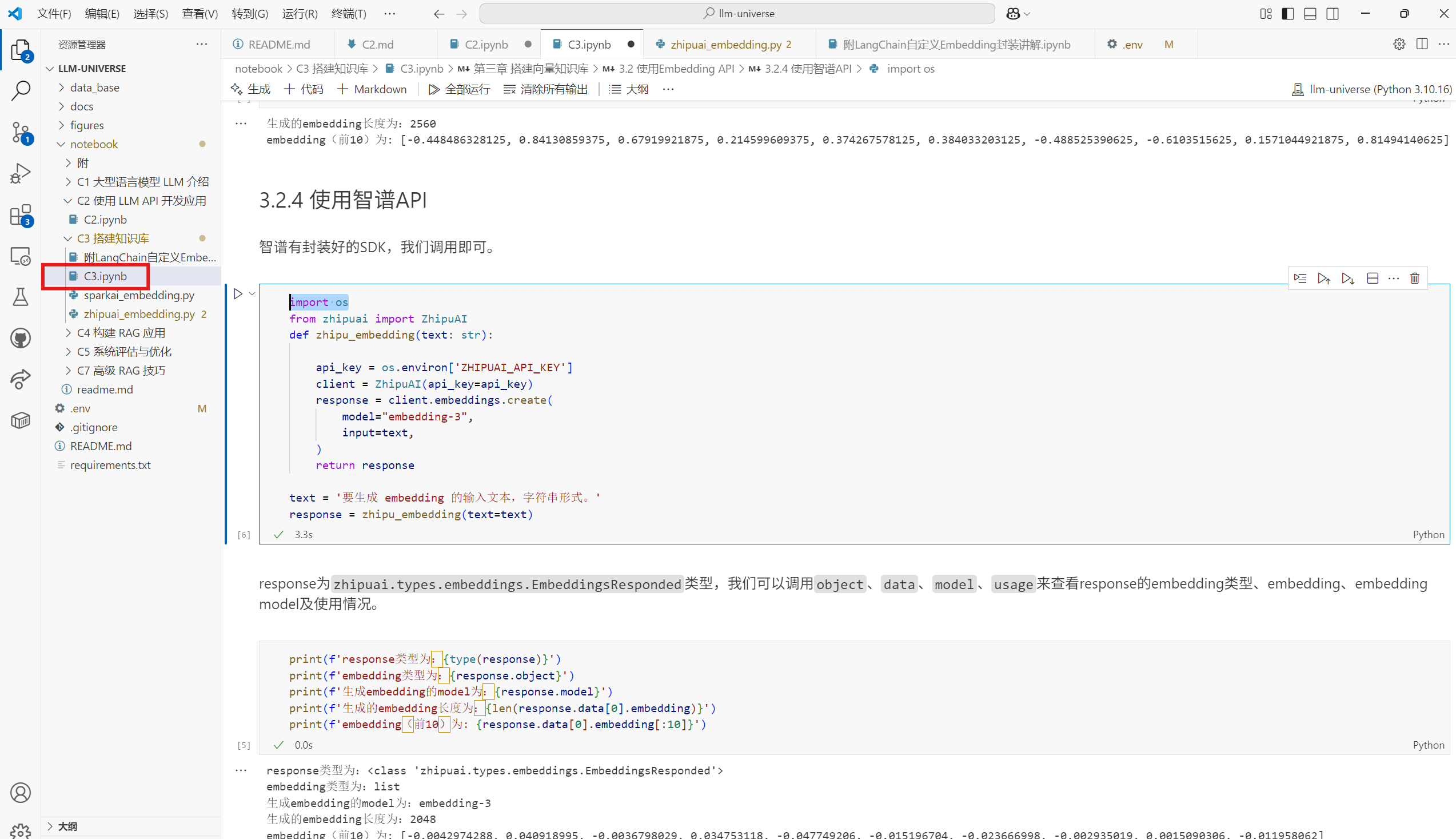
使用智谱API
智谱有封装好的SDK,直接调用即可
import os #导入操作系统模块,用于访问环境变量
from zhipuai import ZhipuAI
def zhipu_embedding(text: str):
api_key = os.environ['ZHIPUAI_API_KEY'] #从环境变量中获取智谱 AI 的 API 密钥
client = ZhipuAI(api_key=api_key) #初始化 ZhipuAI 客户端,传入 API 密钥
response = client.embeddings.create(
model="embedding-3",
input=text,
) # 调用 embeddings.create 接口,使用 "embedding-3" 模型对输入文本进行向量化
return response #返回包含 embedding 向量的响应
text = '要生成 embedding 的输入文本,字符串形式。'
response = zhipu_embedding(text=text)
response为zhipuai.types.embeddings.EmbeddingsResponded类型,我们可以调用object、data、model、usage来查看response的embedding类型、embedding、embedding model及使用情况。
print(f'response类型为:{type(response)}')
print(f'embedding类型为:{response.object}')
print(f'生成embedding的model为:{response.model}')
print(f'生成的embedding长度为:{len(response.data[0].embedding)}')
print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
response类型为:<class 'zhipuai.types.embeddings.EmbeddingsResponded'>
embedding类型为:list
生成embedding的model为:embedding-3
生成的embedding长度为:2048
embedding(前10)为: [-0.0042974288, 0.040918995, -0.0036798029, 0.034753118, -0.047749206, -0.015196704, -0.023666998, -0.002935019, 0.0015090306, -0.011958062]
注意:这里和章节二一样,都是在vscode里的C3.ipynb中运行
数据处理
为了构建本地知识库,我们需要对以多种类型存储的本地文档进行处理,读取本地文档并通过前文描述的 Embedding 方法将本地文档的内容转化为词向量来构建向量数据库。
源文档选取
以Datawhale 的一些开源课程为例:
我们将知识库源数据放置在…/data_base/knowledge_db 目录下
数据读取
无论是PDF文档还是markdown文档,我们都可以分别使用 LangChain 中的 PyMuPDFLoader和 UnstructuredMarkdownLoader 来读取数据。
PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
以下是读取PDF的例子:
from langchain_community.document_loaders import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
文档加载后储存在 pages 变量中:
page的变量类型为List- 打印
pages的长度可以看到 pdf 一共包含多少页
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 196 页
page 中的每一元素为一个文档,变量类型为 langchain_core.documents.base.Document, 文档变量类型包含两个属性
page_content包含该文档的内容。meta_data为文档相关的描述性数据。
pdf_page = pdf_pages[1]
print(f"每一个元素的类型:{type(pdf_page)}.",
f"该文档的描述性数据:{pdf_page.metadata}",
f"查看该文档的内容:\n{pdf_page.page_content}",
sep="\n------\n")
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'file_path': '../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf', 'page': 1, 'total_pages': 196, 'format': 'PDF 1.5', 'title': '', 'author': '', 'subject': '', 'keywords': '', 'creator': 'LaTeX with hyperref', 'producer': 'xdvipdfmx (20200315)', 'creationDate': "D:20230303170709-00'00'", 'modDate': '', 'trapped': ''}
------
查看该文档的内容:
前言
“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读
者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推
导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充
具体的推导细节。”
读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周
老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书
中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南瓜书只能算是我
等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二
下学生”。
使用说明
• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书
为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;
• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得
有点飘的时候再回来啃都来得及;
• 每个公式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识
我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;
• 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub 的
Issues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块
提交你希望补充的公式编号或者勘误信息,我们通常会在24 小时以内给您回复,超过24 小时未回复的
话可以微信联系我们(微信号:at-Sm1les);
配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU
在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版)
最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases
编委会
主编:Sm1les、archwalker、jbb0523
编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226
封面设计:构思-Sm1les、创作-林王茂盛
致谢
特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、
spareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。
扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”
版权声明
本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。
以下是读取markdown的例子:
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md")
md_pages = loader.load()
print(f"载入后的变量类型为:{type(md_pages)},", f"该 Markdown 一共包含 {len(md_pages)} 页")
载入后的变量类型为:<class 'list'>, 该 Markdown 一共包含 1 页
md_page = md_pages[0]
print(f"每一个元素的类型:{type(md_page)}.",
f"该文档的描述性数据:{md_page.metadata}",
f"查看该文档的内容:\n{md_page.page_content[0:][:200]}",
sep="\n------\n")
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md'}
------
查看该文档的内容:
第一章 简介
欢迎来到面向开发者的提示工程部分,本部分内容基于吴恩达老师的《Prompt Engineering for Developer》课程进行编写。《Prompt Engineering for Developer》课程是由吴恩达老师与 OpenAI 技术团队成员 Isa Fulford 老师合作授课,Isa 老师曾开发过受欢迎的 ChatGPT 检索插件,并且在教授 LLM (Larg
数据清洗
为了让数据库的数据是有序的、优质的、精简的,我们需要进行删除低质量数据。可以看到上文中读取的pdf文件不仅将一句话按照原文的分行添加了换行符\n,也在原本两个符号中间插入了\n,我们可以使用正则表达式匹配并删除掉\n。
import re #导入Python的正则表达式模块 re
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content) # match.group(0) 表示整个匹配的字符串
print(pdf_page.page_content)
前言
“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读
者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推
导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充
具体的推导细节。”
读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周
老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书
中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南瓜书只能算是我
等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二
下学生”。
使用说明
• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书
为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得
有点飘的时候再回来啃都来得及;• 每个公式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识
我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;• 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub 的
Issues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块
提交你希望补充的公式编号或者勘误信息,我们通常会在24 小时以内给您回复,超过24 小时未回复的
话可以微信联系我们(微信号:at-Sm1les);
配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU
在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版)
最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases
编委会
主编:Sm1les、archwalker、jbb0523
编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226
封面设计:构思-Sm1les、创作-林王茂盛
致谢
特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、spareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。
扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”
版权声明
本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。
进一步分析数据,我们发现数据中还有不少的•和空格,我们使用replace方法去掉即可。
pdf_page.page_content = pdf_page.page_content.replace('•', '') # 将 pdf_page.page_content 中的所有项目符号 '•' 替换为空字符串
pdf_page.page_content = pdf_page.page_content.replace(' ', '')
# 将 pdf_page.page_content 中的所有项目符号 '•' 替换为空字符串
print(pdf_page.page_content)
前言
“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读
者通过西瓜书对机器学习有所了解,所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推
导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充
具体的推导细节。”
读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周
老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书
中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以......本南瓜书只能算是我
等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二
下学生”。
使用说明
南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书
为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;对于初学机器学习的小白,西瓜书第1章和第2章的公式强烈不建议深究,简单过一下即可,等你学得
有点飘的时候再回来啃都来得及;每个公式的解析和推导我们都力(zhi)争(neng)以本科数学基础的视角进行讲解,所以超纲的数学知识
我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub的
Issues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块
提交你希望补充的公式编号或者勘误信息,我们通常会在24小时以内给您回复,超过24小时未回复的
话可以微信联系我们(微信号:at-Sm1les);
配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU
在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1版)
最新版PDF获取地址:https://github.com/datawhalechina/pumpkin-book/releases
编委会
主编:Sm1les、archwalker、jbb0523
编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226
封面设计:构思-Sm1les、创作-林王茂盛
致谢
特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、spareribs、sunchaothu、StevenLzq在最早期的时候对南瓜书所做的贡献。
扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”
版权声明
本作品采用知识共享署名-非商业性使用-相同方式共享4.0国际许可协议进行许可。
上文中读取的md文件每一段中间隔了一个换行符,我们同样可以使用replace方法去除。
md_page.page_content = md_page.page_content.replace('\n\n', '\n') # 将md_page.page_content 中连续的两个换行符 '\n\n' 替换为单个换行符 '\n'
print(md_page.page_content)
第一章 简介
欢迎来到面向开发者的提示工程部分,本部分内容基于吴恩达老师的《Prompt Engineering for Developer》课程进行编写。《Prompt Engineering for Developer》课程是由吴恩达老师与 OpenAI 技术团队成员 Isa Fulford 老师合作授课,Isa 老师曾开发过受欢迎的 ChatGPT 检索插件,并且在教授 LLM (Large Language Model, 大语言模型)技术在产品中的应用方面做出了很大贡献。她还参与编写了教授人们使用 Prompt 的 OpenAI cookbook。我们希望通过本模块的学习,与大家分享使用提示词开发 LLM 应用的最佳实践和技巧。
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 DeepLearning.AI 的姊妹公司 AI Fund 的团队一直在与许多初创公司合作,将这些技术应用于诸多应用程序上。很兴奋能看到 LLM API 能够让开发人员非常快速地构建应用程序。
在本模块,我们将与读者分享提升大语言模型应用效果的各种技巧和最佳实践。书中内容涵盖广泛,包括软件开发提示词设计、文本总结、推理、转换、扩展以及构建聊天机器人等语言模型典型应用场景。我们衷心希望该课程能激发读者的想象力,开发出更出色的语言模型应用。
随着 LLM 的发展,其大致可以分为两种类型,后续称为基础 LLM 和指令微调(Instruction Tuned)LLM。基础LLM是基于文本训练数据,训练出预测下一个单词能力的模型。其通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。例如,如果你以“从前,有一只独角兽”作为 Prompt ,基础 LLM 可能会继续预测“她与独角兽朋友共同生活在一片神奇森林中”。但是,如果你以“法国的首都是什么”为 Prompt ,则基础 LLM 可能会根据互联网上的文章,将回答预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用RLHF(reinforcement learning from human feedback,人类反馈强化学习)技术,根据人类对模型输出的反馈进一步增强模型遵循指令的能力。通过这种受控的训练过程。指令微调 LLM 可以生成对指令高度敏感、更安全可靠的输出,较少无关和损害性内容。因此。许多实际应用已经转向使用这类大语言模型。
因此,本课程将重点介绍针对指令微调 LLM 的最佳实践,我们也建议您将其用于大多数使用场景。当您使用指令微调 LLM 时,您可以类比为向另一个人提供指令(假设他很聪明但不知道您任务的具体细节)。因此,当 LLM 无法正常工作时,有时是因为指令不够清晰。例如,如果您想问“请为我写一些关于阿兰·图灵( Alan Turing )的东西”,在此基础上清楚表明您希望文本专注于他的科学工作、个人生活、历史角色或其他方面可能会更有帮助。另外您还可以指定回答的语调, 来更加满足您的需求,可选项包括专业记者写作,或者向朋友写的随笔等。
如果你将 LLM 视为一名新毕业的大学生,要求他完成这个任务,你甚至可以提前指定他们应该阅读哪些文本片段来写关于阿兰·图灵的文本,这样能够帮助这位新毕业的大学生更好地完成这项任务。本书的下一章将详细阐释提示词设计的两个关键原则:清晰明确和给予充足思考时间。
文档分割
文档分割指将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。( chunk 是检索的元单位)
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。


chunk_size指每个块包含的字符或 Token(如单词、句子等)的数量chunk_overlap指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。CharacterTextSplitter(): 按字符来分割文本。MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。TokenTextSplitter(): 按token来分割文本。SentenceTransformersTokenTextSplitter(): 按token来分割文本Language(): 用于 CPP、Python、Ruby、Markdown 等。NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
数据处理中最核心的一步是如何对文档进行分割,其往往决定了检索系统的下限
搭建并使用向量数据库
前序配置
import os
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,你需要如下配置
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
# os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = '../../data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
print(file_paths[:3])
['../../data_base/knowledge_db/prompt_engineering/6. 文本转换 Transforming.md', '../../data_base/knowledge_db/prompt_engineering/4. 文本概括 Summarizing.md', '../../data_base/knowledge_db/prompt_engineering/5. 推断 Inferring.md']
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:
file_type = file_path.split('.')[-1]
if file_type == 'pdf':
loaders.append(PyMuPDFLoader(file_path))
elif file_type == 'md':
loaders.append(UnstructuredMarkdownLoader(file_path))
# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
page_content包含该文档的内容。meta_data为文档相关的描述性数据。
text = texts[1]
print(f"每一个元素的类型:{type(text)}.",
f"该文档的描述性数据:{text.metadata}",
f"查看该文档的内容:\n{text.page_content[0:]}",
sep="\n------\n")
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/prompt_engineering/4. 文本概括 Summarizing.md'}
------
查看该文档的内容:
第四章 文本概括
在繁忙的信息时代,小明是一名热心的开发者,面临着海量的文本信息处理的挑战。他需要通过研究无数的文献资料来为他的项目找到关键的信息,但是时间却远远不够。在他焦头烂额之际,他发现了大型语言模型(LLM)的文本摘要功能。
这个功能对小明来说如同灯塔一样,照亮了他处理信息海洋的道路。LLM 的强大能力在于它可以将复杂的文本信息简化,提炼出关键的观点,这对于他来说无疑是巨大的帮助。他不再需要花费大量的时间去阅读所有的文档,只需要用 LLM 将它们概括,就可以快速获取到他所需要的信息。
通过编程调用 AP I接口,小明成功实现了这个文本摘要的功能。他感叹道:“这简直就像一道魔法,将无尽的信息海洋变成了清晰的信息源泉。”小明的经历,展现了LLM文本摘要功能的巨大优势:节省时间,提高效率,以及精准获取信息。这就是我们本章要介绍的内容,让我们一起来探索如何利用编程和调用API接口,掌握这个强大的工具。
一、单一文本概括
以商品评论的总结任务为例:对于电商平台来说,网站上往往存在着海量的商品评论,这些评论反映了所有客户的想法。如果我们拥有一个工具去概括这些海量、冗长的评论,便能够快速地浏览更多评论,洞悉客户的偏好,从而指导平台与商家提供更优质的服务。
接下来我们提供一段在线商品评价作为示例,可能来自于一个在线购物平台,例如亚马逊、淘宝、京东等。评价者为一款熊猫公仔进行了点评,评价内容包括商品的质量、大小、价格和物流速度等因素,以及他的女儿对该商品的喜爱程度。
python prod_review = """ 这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。 公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说, 它有点小,我感觉在别的地方用同样的价钱能买到更大的。 快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。 """
1.1 限制输出文本长度
我们首先尝试将文本的长度限制在30个字以内。
```python from tool import get_completion
prompt = f""" 您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个字。
评论: {prod_review} """
response = get_completion(prompt) print(response) ```
熊猫公仔软可爱,女儿喜欢,但有点小。快递提前一天到货。
我们可以看到语言模型给了我们一个符合要求的结果。
注意:在上一节中我们提到了语言模型在计算和判断文本长度时依赖于分词器,而分词器在字符统计方面不具备完美精度。
1.2 设置关键角度侧重
在某些情况下,我们会针对不同的业务场景对文本的侧重会有所不同。例如,在商品评论文本中,物流部门可能更专注于运输的时效性,商家则更关注价格和商品质量,而平台则更看重整体的用户体验。
我们可以通过增强输入提示(Prompt),来强调我们对某一特定视角的重视。
1.2.1 侧重于快递服务
```python prompt = f""" 您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个字,并且侧重在快递服务上。
评论: {prod_review} """
response = get_completion(prompt) print(response) ```
快递提前到货,公仔可爱但有点小。
通过输出结果,我们可以看到,文本以“快递提前到货”开头,体现了对于快递效率的侧重。
1.2.2 侧重于价格与质量
```python prompt = f""" 您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对三个反引号之间的评论文本进行概括,最多30个词汇,并且侧重在产品价格和质量上。
评论: {prod_review} """
response = get_completion(prompt) print(response) ```
可爱的熊猫公仔,质量好但有点小,价格稍高。快递提前到货。
通过输出的结果,我们可以看到,文本以“可爱的熊猫公仔,质量好但有点小,价格稍高”开头,体现了对于产品价格与质量的侧重。
1.3 关键信息提取
在1.2节中,虽然我们通过添加关键角度侧重的 Prompt ,确实让文本摘要更侧重于某一特定方面,然而,我们可以发现,在结果中也会保留一些其他信息,比如偏重价格与质量角度的概括中仍保留了“快递提前到货”的信息。如果我们只想要提取某一角度的信息,并过滤掉其他所有信息,则可以要求 LLM 进行 文本提取(Extract) 而非概括( Summarize )。
下面让我们来一起来对文本进行提取信息吧!
```python prompt = f""" 您的任务是从电子商务网站上的产品评论中提取相关信息。
请从以下三个反引号之间的评论文本中提取产品运输相关的信息,最多30个词汇。
评论: {prod_review} """
response = get_completion(prompt) print(response) ```
产品运输相关的信息:快递提前一天到货。
二、同时概括多条文本
在实际的工作流中,我们往往要处理大量的评论文本,下面的示例将多条用户评价集合在一个列表中,并利用 for 循环和文本概括(Summarize)提示词,将评价概括至小于 20 个词以下,并按顺序打印。当然,在实际生产中,对于不同规模的评论文本,除了使用 for 循环以外,还可能需要考虑整合评论、分布式等方法提升运算效率。您可以搭建主控面板,来总结大量用户评论,以及方便您或他人快速浏览,还可以点击查看原评论。这样,您就能高效掌握顾客的所有想法。
```python review_1 = prod_review
一盏落地灯的评论
review_2 = """ 我需要一盏漂亮的卧室灯,这款灯不仅具备额外的储物功能,价格也并不算太高。 收货速度非常快,仅用了两天的时间就送到了。 不过,在运输过程中,灯的拉线出了问题,幸好,公司很乐意寄送了一根全新的灯线。 新的灯线也很快就送到手了,只用了几天的时间。 装配非常容易。然而,之后我发现有一个零件丢失了,于是我联系了客服,他们迅速地给我寄来了缺失的零件! 对我来说,这是一家非常关心客户和产品的优秀公司。 """
一把电动牙刷的评论
review_3 = """ 我的牙科卫生员推荐了电动牙刷,所以我就买了这款。 到目前为止,电池续航表现相当不错。 初次充电后,我在第一周一直将充电器插着,为的是对电池进行条件养护。 过去的3周里,我每天早晚都使用它刷牙,但电池依然维持着原来的充电状态。 不过,牙刷头太小了。我见过比这个牙刷头还大的婴儿牙刷。 我希望牙刷头更大一些,带有不同长度的刷毛, 这样可以更好地清洁牙齿间的空隙,但这款牙刷做不到。 总的来说,如果你能以50美元左右的价格购买到这款牙刷,那是一个不错的交易。 制造商的替换刷头相当昂贵,但你可以购买价格更为合理的通用刷头。 这款牙刷让我感觉就像每天都去了一次牙医,我的牙齿感觉非常干净! """
一台搅拌机的评论
review_4 = """ 在11月份期间,这个17件套装还在季节性促销中,售价约为49美元,打了五折左右。 可是由于某种原因(我们可以称之为价格上涨),到了12月的第二周,所有的价格都上涨了, 同样的套装价格涨到了70-89美元不等。而11件套装的价格也从之前的29美元上涨了约10美元。 看起来还算不错,但是如果你仔细看底座,刀片锁定的部分看起来没有前几年版本的那么漂亮。 然而,我打算非常小心地使用它 (例如,我会先在搅拌机中研磨豆类、冰块、大米等坚硬的食物,然后再将它们研磨成所需的粒度, 接着切换到打蛋器刀片以获得更细的面粉,如果我需要制作更细腻/少果肉的食物)。 在制作冰沙时,我会将要使用的水果和蔬菜切成细小块并冷冻 (如果使用菠菜,我会先轻微煮熟菠菜,然后冷冻,直到使用时准备食用。 如果要制作冰糕,我会使用一个小到中号的食物加工器),这样你就可以避免添加过多的冰块。 大约一年后,电机开始发出奇怪的声音。我打电话给客户服务,但保修期已经过期了, 所以我只好购买了另一台。值得注意的是,这类产品的整体质量在过去几年里有所下降 ,所以他们在一定程度上依靠品牌认知和消费者忠诚来维持销售。在大约两天内,我收到了新的搅拌机。 """
reviews = [review_1, review_2, review_3, review_4]
```
```python for i in range(len(reviews)): prompt = f""" 你的任务是从电子商务网站上的产品评论中提取相关信息。
请对三个反引号之间的评论文本进行概括,最多20个词汇。
评论文本: ```{reviews[i]}```
"""
response = get_completion(prompt)
print(f"评论{i+1}: ", response, "\n")
```
评论1: 熊猫公仔是生日礼物,女儿喜欢,软可爱,面部表情和善。价钱有点小,快递提前一天到货。
评论2: 漂亮卧室灯,储物功能,快速送达,灯线问题,快速解决,容易装配,关心客户和产品。
评论3: 这款电动牙刷电池续航好,但牙刷头太小,价格合理,清洁效果好。
评论4: 该评论提到了一个17件套装的产品,在11月份有折扣销售,但在12月份价格上涨。评论者提到了产品的外观和使用方法,并提到了产品质量下降的问题。最后,评论者提到他们购买了另一台搅拌机。
三、英文版
1.1 单一文本概括
python prod_review = """ Got this panda plush toy for my daughter's birthday, \ who loves it and takes it everywhere. It's soft and \ super cute, and its face has a friendly look. It's \ a bit small for what I paid though. I think there \ might be other options that are bigger for the \ same price. It arrived a day earlier than expected, \ so I got to play with it myself before I gave it \ to her. """
```python prompt = f""" Your task is to generate a short summary of a product \ review from an ecommerce site.
Summarize the review below, delimited by triple backticks, in at most 30 words.
Review: {prod_review} """
response = get_completion(prompt) print(response) ```
This panda plush toy is loved by the reviewer's daughter, but they feel it is a bit small for the price.
1.2 设置关键角度侧重
1.2.1 侧重于快递服务
```python prompt = f""" Your task is to generate a short summary of a product \ review from an ecommerce site to give feedback to the \ Shipping deparmtment.
Summarize the review below, delimited by triple backticks, in at most 30 words, and focusing on any aspects \ that mention shipping and delivery of the product.
Review: {prod_review} """
response = get_completion(prompt) print(response) ```
The customer is happy with the product but suggests offering larger options for the same price. They were pleased with the early delivery.
1.2.2 侧重于价格和质量
```python prompt = f""" Your task is to generate a short summary of a product \ review from an ecommerce site to give feedback to the \ pricing deparmtment, responsible for determining the \ price of the product.
Summarize the review below, delimited by triple backticks, in at most 30 words, and focusing on any aspects \ that are relevant to the price and perceived value.
Review: {prod_review} """
response = get_completion(prompt) print(response) ```
The customer loves the panda plush toy for its softness and cuteness, but feels it is overpriced compared to other options available.
1.3 关键信息提取
```python prompt = f""" Your task is to extract relevant information from \ a product review from an ecommerce site to give \ feedback to the Shipping department.
From the review below, delimited by triple quotes \ extract the information relevant to shipping and \ delivery. Limit to 30 words.
Review: {prod_review} """
response = get_completion(prompt) print(response) ```
The shipping department should take note that the product arrived a day earlier than expected.
2.1 同时概括多条文本
```python review_1 = prod_review
review for a standing lamp
review_2 = """ Needed a nice lamp for my bedroom, and this one \ had additional storage and not too high of a price \ point. Got it fast - arrived in 2 days. The string \ to the lamp broke during the transit and the company \ happily sent over a new one. Came within a few days \ as well. It was easy to put together. Then I had a \ missing part, so I contacted their support and they \ very quickly got me the missing piece! Seems to me \ to be a great company that cares about their customers \ and products. """
review for an electric toothbrush
review_3 = """ My dental hygienist recommended an electric toothbrush, \ which is why I got this. The battery life seems to be \ pretty impressive so far. After initial charging and \ leaving the charger plugged in for the first week to \ condition the battery, I've unplugged the charger and \ been using it for twice daily brushing for the last \ 3 weeks all on the same charge. But the toothbrush head \ is too small. I’ve seen baby toothbrushes bigger than \ this one. I wish the head was bigger with different \ length bristles to get between teeth better because \ this one doesn’t. Overall if you can get this one \ around the $50 mark, it's a good deal. The manufactuer's \ replacements heads are pretty expensive, but you can \ get generic ones that're more reasonably priced. This \ toothbrush makes me feel like I've been to the dentist \ every day. My teeth feel sparkly clean! """
review for a blender
review_4 = """ So, they still had the 17 piece system on seasonal \ sale for around $49 in the month of November, about \ half off, but for some reason (call it price gouging) \ around the second week of December the prices all went \ up to about anywhere from between $70-$89 for the same \ system. And the 11 piece system went up around $10 or \ so in price also from the earlier sale price of $29. \ So it looks okay, but if you look at the base, the part \ where the blade locks into place doesn’t look as good \ as in previous editions from a few years ago, but I \ plan to be very gentle with it (example, I crush \ very hard items like beans, ice, rice, etc. in the \ blender first then pulverize them in the serving size \ I want in the blender then switch to the whipping \ blade for a finer flour, and use the cross cutting blade \ first when making smoothies, then use the flat blade \ if I need them finer/less pulpy). Special tip when making \ smoothies, finely cut and freeze the fruits and \ vegetables (if using spinach-lightly stew soften the \ spinach then freeze until ready for use-and if making \ sorbet, use a small to medium sized food processor) \ that you plan to use that way you can avoid adding so \ much ice if at all-when making your smoothie. \ After about a year, the motor was making a funny noise. \ I called customer service but the warranty expired \ already, so I had to buy another one. FYI: The overall \ quality has gone done in these types of products, so \ they are kind of counting on brand recognition and \ consumer loyalty to maintain sales. Got it in about \ two days. """
reviews = [review_1, review_2, review_3, review_4] ```
```python for i in range(len(reviews)): prompt = f""" Your task is to generate a short summary of a product \ review from an ecommerce site.
Summarize the review below, delimited by triple \
backticks in at most 20 words.
Review: ```{reviews[i]}```
"""
response = get_completion(prompt)
print(i, response, "\n")
```
0 Soft and cute panda plush toy loved by daughter, but small for the price. Arrived early.
1 Great lamp with storage, fast delivery, excellent customer service, and easy assembly. Highly recommended.
2 Impressive battery life, but toothbrush head is too small. Good deal if bought around $50.
3 The reviewer found the price increase after the sale disappointing and noticed a decrease in quality over time.
构建 Chroma 向量库
由于本人是小白,只实践了智谱,若想使用OpenAI,百度千帆,可以去看原版搭建知识库
# 使用我们自己封装的智谱 Embedding,需要将封装代码下载到本地使用
from zhipuai_embedding import ZhipuAIEmbeddings
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 定义持久化路径
persist_directory = '../../data_base/vector_db/chroma'
!rm -rf '../../data_base/vector_db/chroma' # 删除旧的数据库文件(如果文件夹中有文件的话),windows电脑请手动删除
from langchain_community.vectorstores import Chroma
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
print(f"向量库中存储的数量:{vectordb._collection.count()}")
向量库中存储的数量:1004
向量检索
Chroma的相似度搜索使用的是余弦距离,即:
similarity
=
cos
(
A
,
B
)
=
A
⋅
B
∥
A
∥
∥
B
∥
=
∑
1
n
a
i
b
i
∑
1
n
a
i
2
∑
1
n
b
i
2
\text { similarity }=\cos (A, B)=\frac{A \cdot B}{\|A\|\|B\|}=\frac{\sum_{1}^{n} a_{i} b_{i}}{\sqrt{\sum_{1}^{n} a_{i}^{2}} \sqrt{\sum_{1}^{n} b_{i}^{2}}}
similarity =cos(A,B)=∥A∥∥B∥A⋅B=∑1nai2∑1nbi2∑1naibi
- 其中 a i a_{i} ai和 b i b_{i} bi分别是向量A、B的分量
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用similarity_search函数
question="什么是大语言模型"
sim_docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(sim_docs)}")
检索到的内容数:3
for i, sim_doc in enumerate(sim_docs):
print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
检索到的第0个内容:
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 Deep
--------------
检索到的第1个内容:
第六章 文本转换
大语言模型具有强大的文本转换能力,可以实现多语言翻译、拼写纠正、语法调整、格式转换等不同类型的文本转换任务。利用语言模型进行各类转换是它的典型应用之一。
在本章中,我们将介绍如何通过编程调用API接口,使用语言模型实现文本转换功能。通过代码示例,读者可以学习将输入文本转换成所需输出格式的具体方法。
掌握调用大语言模型接口进行文本转换的技能,是开发各种语言类应用的重要一步。文
--------------
检索到的第2个内容:
学生计算的总费用:450x+10万美元
实际计算的总费用:360x+10万美元
学生计算的费用和实际计算的费用是否相同:否
学生的解决方案和实际解决方案是否相同:否
学生的成绩:不正确
三、局限性
开发大模型相关应用时请务必铭记:
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实
--------------
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
for i, sim_doc in enumerate(mmr_docs):
print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
MMR 检索到的第0个内容:
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 Deep
--------------
MMR 检索到的第1个内容:
学生计算的总费用:450x+10万美元
实际计算的总费用:360x+10万美元
学生计算的费用和实际计算的费用是否相同:否
学生的解决方案和实际解决方案是否相同:否
学生的成绩:不正确
三、局限性
开发大模型相关应用时请务必铭记:
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实
--------------
MMR 检索到的第2个内容:
行推导。
对于任意样本, 在不考虑样本本身之前(即先验), 若瞎猜一下它由第i 个高斯混合成分生成的概率
P (zj = i), 那么肯定按先验概率α1, α2, . . . , αk 进行猜测, 即P (zj = i) = αi 。若考虑样本本身带来的信
息(即后验), 此时再猜一下它由第i 个高斯混合成分生成的概率pM (zj = i | xj), 根据贝叶斯公式, 后验概
率pM (zj =
--------------
[:200]}“, end=”\n--------------\n")
```markup
MMR 检索到的第0个内容:
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 Deep
--------------
MMR 检索到的第1个内容:
学生计算的总费用:450x+10万美元
实际计算的总费用:360x+10万美元
学生计算的费用和实际计算的费用是否相同:否
学生的解决方案和实际解决方案是否相同:否
学生的成绩:不正确
三、局限性
开发大模型相关应用时请务必铭记:
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实
--------------
MMR 检索到的第2个内容:
行推导。
对于任意样本, 在不考虑样本本身之前(即先验), 若瞎猜一下它由第i 个高斯混合成分生成的概率
P (zj = i), 那么肯定按先验概率α1, α2, . . . , αk 进行猜测, 即P (zj = i) = αi 。若考虑样本本身带来的信
息(即后验), 此时再猜一下它由第i 个高斯混合成分生成的概率pM (zj = i | xj), 根据贝叶斯公式, 后验概
率pM (zj =
--------------
未完待续~,请看第四章

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









