






一、摘要
对于机器学习模型来说,从科学文本中抽取结构化知识仍然是一项具有挑战性的任务。本文提出了一种简单的联合命名实体识别和关系抽取(NERRE)的方法,并展示了如何对预训练的大型语言模型(GPT-3, Llama-2)进行微调,以抽取复杂科学知识。论文测试了材料化学中的三个代表性任务:固态杂质掺杂,金属有机框架(MOFs),以及一般成分/相/形态/应用信息抽取。记录是从单个句子或整个段落中抽取的,输出可以以简单的英语句子或更结构化的格式(如JSON对象列表)返回。这种方法代表了一种简单、可访问和高度灵活的构建大型数据库的途径,从研究论文中抽取结构化的专业科学知识。
原文:Structured information extraction from scientific text with large language models (Nature Communications, 2024)
二、引言
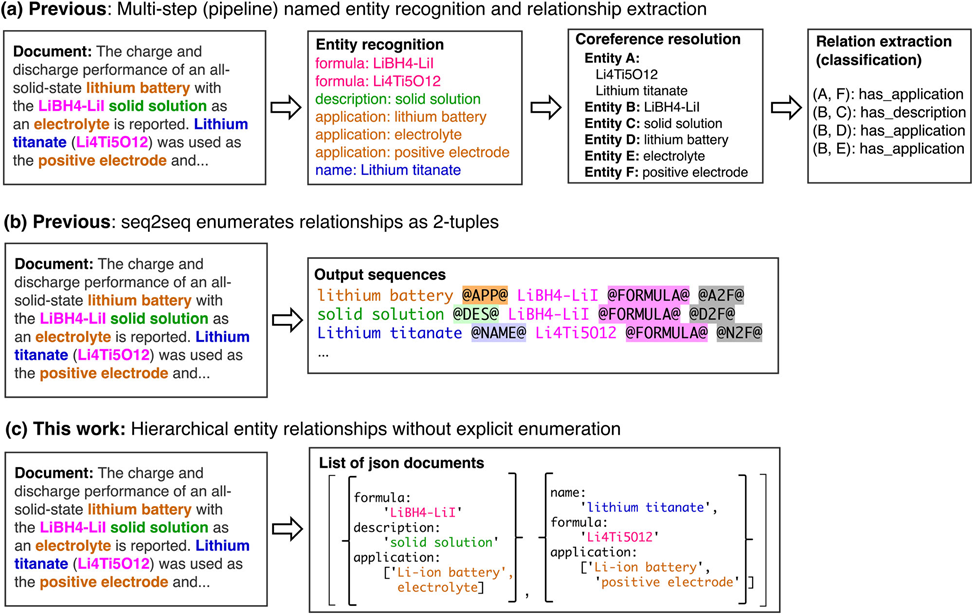
图1 以往关系抽取方法与本工作的对比。每种方法的目标都是从非结构化文本中抽取实体及其关系
如图1(a)所示传统的pipeline方法分两步进行关系抽取,第一步是命名实体识别,然后将识别的实体进行关系分类。(b) seq2seq的方法通过端到端的方式直接输出n元关系元组,但不适用于高度复杂和层级化的关系。© 论文提出了一种简单的复杂信息抽取方法,旨在准确抽取信息的结构化层次结构,从文本段落中同时抽取命名实体及其复杂关系。
大量研究表明LLM可以作为材料科学知识引擎,然而忽略了对复杂层次结构的实体关系表示抽取。论文提出的方法不同于直接使用LLM进行性能预测,旨在(准确地)抽取信息的结构化层次结构,以便与下游模型一起使用。对预训练好的LLM进行微调(例如,GPT-3或lama-2),输入一篇文章(例如,一篇研究论文摘要),并对prompt中包含的知识写一篇格式化的“摘要”。输出格式为英语句子或更结构化的模式,如JSON文档列表。要使用此方法,只需要定义所需的输出结构(例如,具有一组预定义键的JSON对象列表),并使用它注释100-500个文本段落,然后,LLM对这些示例进行微调,结果模型能够以相同的结构化表示(如图1(c)所示格式)准确地输出抽取的信息。此外,该方法可以利用在线LLM APIs,允许用户在不了解LLM内部工作方式的情况下训练定制模型,利用LLM将文章转换成格式精确、结构化的科学文本摘要。
三、方法
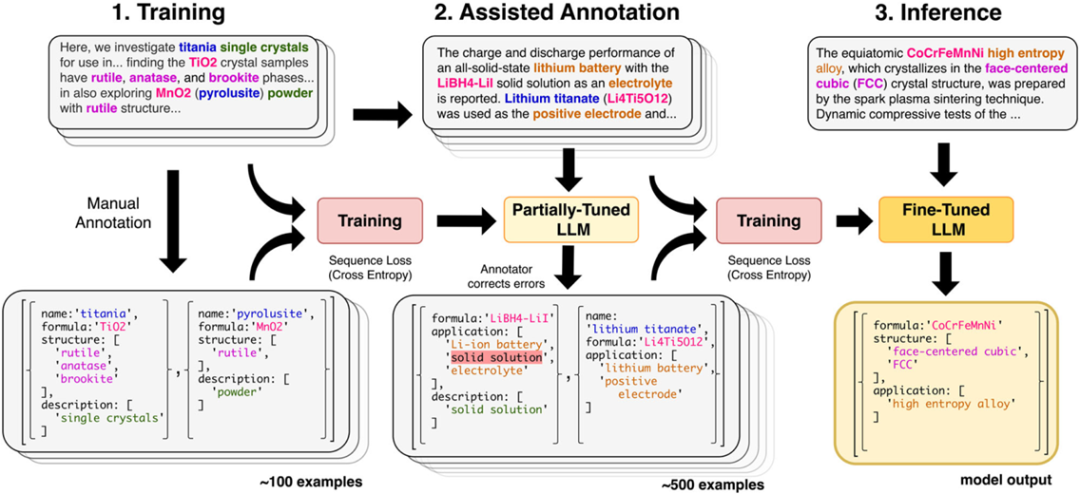
图2 文档级联合命名实体识别和关系抽取的sequence-to-sequence方法
1. General sequence-to-sequence NERRE
利用手动注释的400 - 650个文本抽取对,微调Llama-2和GPT-3对NERRE任务进行评估。所有训练样本使用预定义的schame格式化所需的抽取信息。这些schame的复杂程度各不相同,从具有预定义句子结构的英文句子到JSON对象列表或嵌套JSON对象。原则上,许多其他可能的模式(例如,YAML、伪代码)也可能是有效的,尽管这里不探讨这些模式。一旦对符合模式的足够数据进行微调,模型就能够在新的文本数据上以高精度执行相同的信息抽取任务。该模型以与训练示例相同的模式输出补全。通常将这种方法称为“LLM-NERRE”。
训练GPT-3和llama-2进行NERRE任务的流程图如图2所示。在第一步中,根据预定义的模式从摘要中标注JSON文档,并训练大型语言模型(LLM)。第二步,使用这个初步(中间)模型,通过对部分训练好的模型进行预标注和人工校正,加速额外训练数据的标注过程。错误示例以红色突出显示。这个步骤可以重复多次,每次后续的部分微调都会提高性能。在最后一步,LLM在完整的数据集上进行微调,并用于推理,从新文本中抽取所需的信息。如图3和图4所示,结构化输出可以进一步解码并后处理为分层知识图。
2. Task and schema design
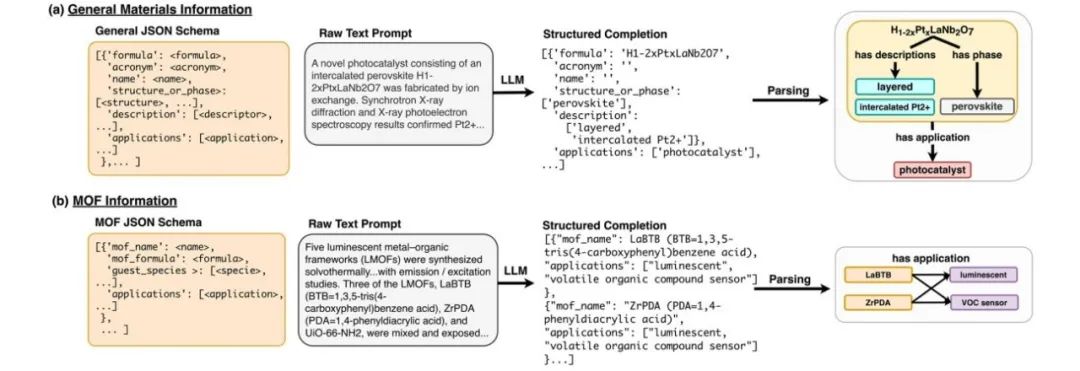
图3 用于NERRE任务的(a)一般信息抽取模式(b)MOF抽取模式
2.1 General materials information schema
在之前的工作中,将NER集中在与材料科学特别相关的一组特定实体类型上:材料、应用、结构/相标签、合成方法等。然而,并没有将这些被标注的实体链接在一起,以记录它们之间的关系,而不仅仅是一个简单的“bag-of-entities”方法。这项工作训练LLM执行“一般材料信息提取”任务,该任务捕获实体和它们之间复杂的交互网络。
为这项任务设计的模式封装了固体化合物及其应用的重要信息子集。列表中的每个实体都是一个自包含的JSON文档,与文本中提到的材料一一对应。材料实体按在文本中的出现顺序进行排序。每个实体的根以化合物的名称和/或其化学式开头。如果没有提到材料的名称或公式,则不会从文本中抽取有关该材料的任何信息。还抽取材料名称/公式中提到的首字母缩略词,尽管在只提到首字母缩略词的情况下,不会为该化合物创建材料实体。非固体化合物(离子、液体、溶剂、溶液等)一般不抽取。在JSON文档中,对于每种材料具有唯一的名称、公式和缩略词字段的给定字符串值,description、structure_or_phase和applications表示为任意长度的字符串列表。
如图3所示,LLM基于一个特定的模式(期望的输出结构,图左边部分)与原始文本prompt,基于LLM训练输出一个结构化的JSON格式列表。然后对输出进行解析,以完成关系图构建(图最右边部分)。针对不同的任务,设计不同的任务schame,基于LLM预测输出。图3(a)表示一般信息抽取任务的schame和标注样本。结构化输出的JSON对象表示在文本中出现的所有化学材料实体,具体包括每种材料可能有的名称、配方、首字母缩略词、描述符、应用和/或晶体结构/相信息。
2.2 metal–organic framework (MOF) schema.
用于MOF任务的schame是基于前一节描述的一般材料信息模式,并对其进行了修改,以更好地适应MOF研究人员的需求。我们开发这个模式是为了抽取MOF名称(name)和化学式(formula), MOF名称是一个没有被广泛接受的标准的实体,化学式(formula)构成文档的根。如果没有名称或公式,则不会为该实例抽取任何信息。此外,由于人们对使用MOF进行离子和气体分离有很大的兴趣,我们抽取了guest species,这些guest species是已经结合、储存或吸附在MOF中的化学物质。抽取了MOF正在研究的应用,以字符串列表的形式(例如,“[‘heterogeneous catalyst’,‘DielsAlder reactions’]”)以及MOF的相关描述,例如其形态或处理历史,类似于一般的信息抽取模式。列表中的实体通常按照材料名称/公式在文本中出现的顺序进行添加。MOF抽取模型标记为MOF- json,示例如图3 (b)所示。图3(b)表示MOF任务的schame和标注样例,输出的JSON列表包含MOF名称和应用,并且两个MOF(LaBTB和ZrPDA)都链接到两个应用(luminescent and VOC sensor)。
2.3 Solid-state impurity doping schema
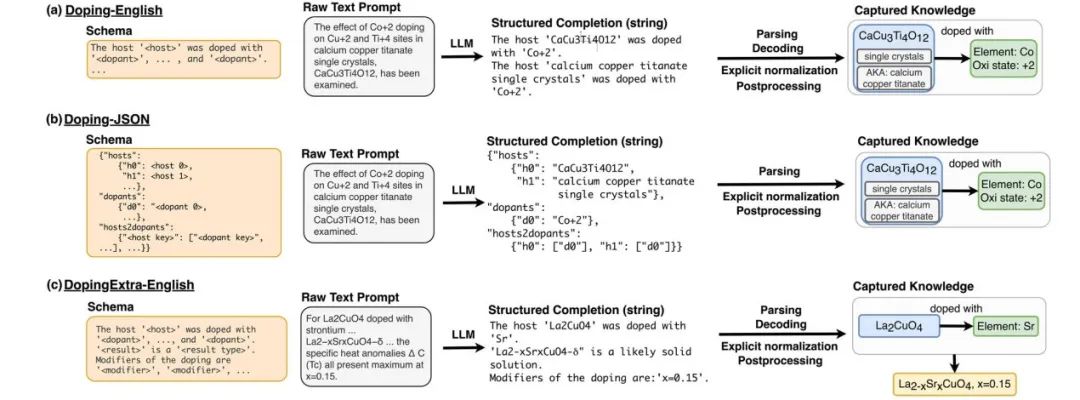
图4 用于NERRE的固态杂质掺杂任务模式
Doping-English和Doping-JSON模式旨在抽取两种实体类型(host和dopant)以及它们之间的关系(host-dopant),以英语句子或一个或多个JSON对象列表的形式输出。hosts被定义为host crystal、样品或材料类别,以及其直接上下文中的关键描述符(例如,“ZnO2 nanoparticles"”、“LiNbO3”、“half-Heuslers”)。掺杂剂被认为是任何元素或离子,有意添加的杂质,或特定的点缺陷或载流子(“hole-doped”,“S vacancies”)。一个主体可以掺杂一种以上的掺杂剂(例如,单独的单掺杂或共掺杂),或者相同的掺杂剂可以链接到一种以上的host材料。通常在一个句子中,可能有许多独立的dopant-host关系对,或者可能有许多不相关的dopant和host(没有关系)。除了每个关系将host与dopant连接之外,我们对dopant-host relations的数量或结构不加限制。Doping-JSON模式在一个句子中表示hosts和掺杂剂之间的关系图,使用唯一的键标识掺杂剂和host字符串。旨在模型微调期间学习这种相对松散的模式。一个单独的键,“hosts2dopants”,根据这些唯一的键描述成对关系。Doping-English模式将实体关系编码为自然语言摘要。Doping-English模式表示与Doping-JSON模式相同的信息,但更接近于我们测试的llm的自然语言预训练分布。当需要从同一个句子中抽取多个 items时,输出的句子用换行符分隔。
对于DopingExtra-English模式,我们引入了两个额外的实体:modifiers和result,没有显式链接(即仅有NER)。result实体表示为化学计量系数(如AlxGa1−xAs)中的公式,用于对来自一系列成分或结晶固溶体(例如,CaCu3−xCoxTi4O12)的样品进行实验。我们还包括化学计量,其中代数被替换(即x value specified),掺杂结果是一组特定的组合物(例如,CaCu2.99Co0.1Ti4O12)。Modifiers是松散限定实体边界的实体,封装了未被dopant、host或result捕获的dopant-host关系的其他描述符。这些描述符可以是极性(例如“n-type”,“n-SnSe”),掺杂量(例如“5 at.%”,“x < 0.3”),缺陷类型(如“substitutional”,“antisite”,“vacancy”)和其他具有dopant-host关系的Modifiers(如“高掺杂”,“简并掺杂”)。选择这些实体(dopant、host、result和Modifiers)来定义抽取基本掺杂信息的最基本的有效模式。
图4表示我们为固态杂质掺杂任务设计的3种schame输出(a)使用Doping-English模式将原始句子传递给模型,该模式输出包含一个host和一个或多个dopant实体的换行分隔的结构化句子。(b)基于Doping-JSON schame的模型输出一个嵌套的JSON对象。每个host实体都有自己的键值对,每个掺杂(dopant)实体也是如此。还有一个host2dopant关系列表,它将相应的dopant键链接到每个host键。(c)表示基于DopingExtra-English模式的模型抽取示例。schame的第一部分与a中相同,但是附加信息包含在dopant modifiers中,并且模式的末尾包含results的句子。
四、实验
实验数据集:
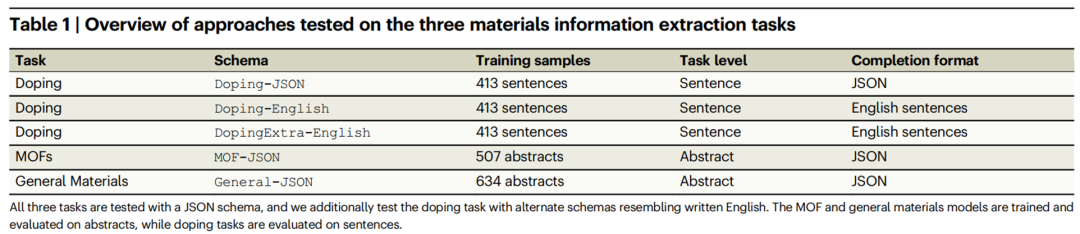
表1描述了三个联合命名实体识别和关系抽取(NERRE)材料信息抽取任务:(1)固态杂质掺杂任务就是从文本段落(句子)中识别宿主材料、掺杂剂和潜在的其他相关信息。(2)MOF任务是从文本(材料科学摘要)中识别化学公式、应用和MOF材料的进一步描述。(3)一般材料信息抽取任务是从文本(材料科学摘要)中识别无机材料、它们的公式、缩写、应用、标签和其他描述性信息。每个任务基于LLM都进行了微调,以遵循特定的模式,所有的模式均显示在表1中。
实验结果与结论:
关系抽取性能
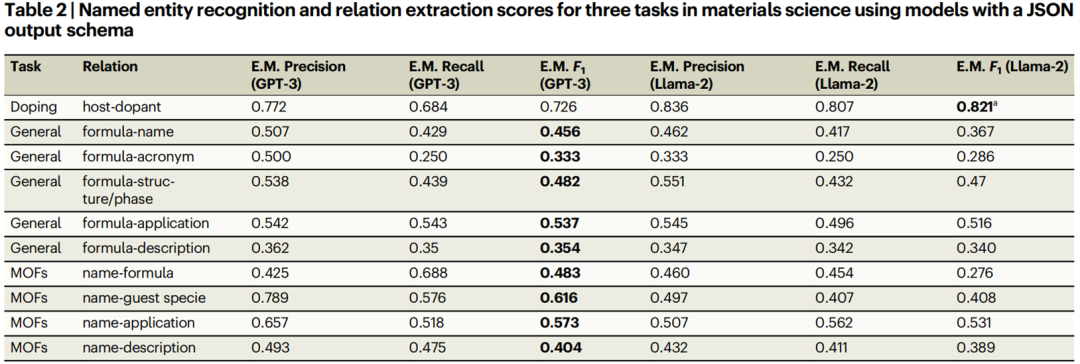
表2显示了GPT-3在测试的所有实体关系中,对于一般信息抽取和MOFs任务达到了最高的F1得分。这两个抽取任务的精确匹配F1得分通常比掺杂任务低约30%。在一般信息抽取中,formula-applications之间的关系具有最高的F1得分(F1=0.537),而formula-acronym和formula-description之间的关系则可靠性要低得多。MOF任务中有类似的发现,name-application(F1=0.573)和name-guest specie(F1=0.616)关系被最准确地抽取。Llama-2的得分平均比GPT-3的低20-30%,表明GPT-3有显著优势。在掺杂任务中,Llama-2具有最高的精度(0.836)、召回率(0.807)和F1(0.821),相对于F1,比GPT-3提高了13%。
表2中一般任务和MOF任务的F1值一般在0.3-0.6之间,这个F1值似乎太低了,不足以用于大规模的信息抽取任务。然而,MOF和general任务的分数有一个重要的警告。这些任务的注释包括隐式归一化(例如:“Lithium ion”→“Li-ion”)和误差修正(“silcion”→“silcion”),而掺杂任务的目的是完全按照文本中出现的样子抽取hosts和dopants。因此,上面显示的精确的单词匹配基础分数是信息抽取性能的近似下限,因为这个指标只比较单词之间的精确匹配。当人类专家阅读general模型和MOF模型的输出时,很明显,这些模型通常只在措辞或符号上有轻微的变化,就能抽取出真实的信息。在现实世界的信息抽取任务中,固有的模糊性也会对性能产生影响。例如,在MOF信息抽取中,MOF名称(如“ZIF-8”)比描述(如“由Cu2+和5-hydroxy-1,3-benzenedicarboxylic acid形成的介孔结构MOF”)更容易界定,后者可以用许多不同的措辞来书写。
为了考虑这些因素,我们对通用材料信息抽取数据集中随机选择10%的测试数据,根据人类专家的标注结果手动对输出进行评分。如果从实体中抽取的核心信息是在正确的JSON对象中(即,与正确的材料公式分组),我们标记抽取结果正确来计算“manual scores”,如果它们在错误的JSON对象中,则不正确,根本没有抽取,或者没有从原始摘要中合理地推断出来。与精确匹配分数(表2)相比,手动分数在三个方面具有灵活性:(1)实体规范化,(2)错误纠正,以及(3)在不同标签下对实体的多个合理注释(例如,“热塑性弹性体”可以被认为是application或description)。表2评估的是模型是否能够完全按照黄金标注中出现的样子抽取成对的单词,而表3中所示的手动得分评估的是模型是否抽取出与真实标签相同的信息——无论其确切形式如何。简单地说,如果领域专家同意模型的抽取和真实的抽取是等价的,那么模型的抽取就被标记为正确的。
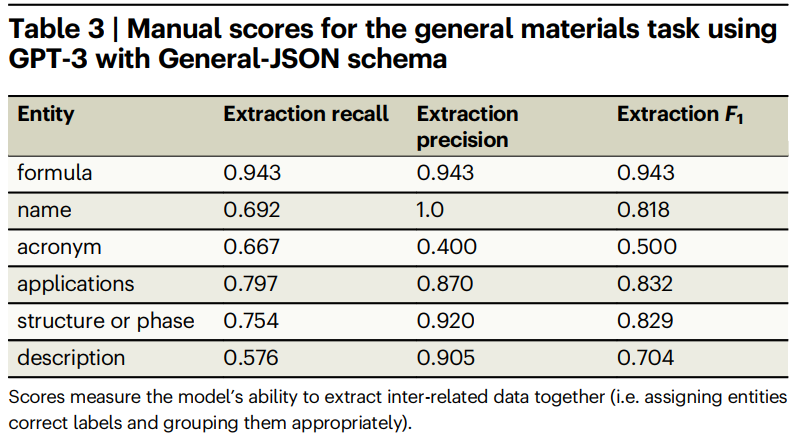
表3展示了基于手动评分调整后的得分。我们按实体分类这些得分;“name", “acronym", “application", “structure", 和“description"手动得分可以和表2中的formula-{name, application, structure, description}关系得分进行比较。可以看到,精确匹配评分严重低估了材料name(0.456 vs 0.818)、application(0.537 vs 0.832)、structure 0.482 vs 0.829)和description(0.354 vs 0.704)的表现。手动评分揭示了模型实际上能够从科学文本中正确抽取出关于各种材料科学主题的结构化知识。acronym有最低的得分,这是因为与其他类别相比,缩写在训练类中相对较少(整个数据集中只有52篇摘要出现,约占文档的9%),而且模型可能将缩写与化学公式混淆(例如,“AuNP”既是金纳米的缩写,也是有效的化学公式)。通常,上下文线索是区分此类情况的唯一方法,我们期望包括更多包含缩写的训练数据可能会提高缩写词的抽取得分。
Effect of different schemas
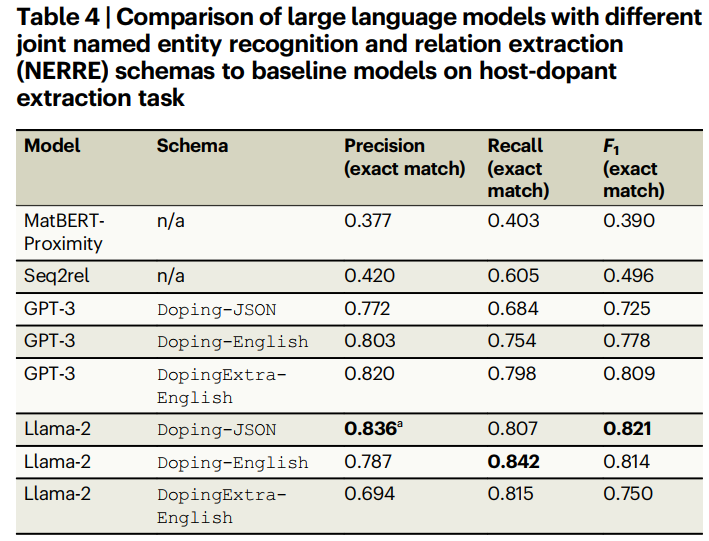
对于host-dopant抽取任务,我们评估了三种不同的输出模式,以确定某一种输出格式是否比其他格式更好。使用dopingenglish模式的模型输出具有特定结构的英语句子(例如,“The host ‘’ was doping with '’ .”),DopingExtra-English模型同样输出英语句子,但也包括一些额外的描述性信息(例如,是否其中一个hosts是固体溶液和/或特定掺杂剂的浓度)。对于Doping-JSON模式,我们使用了一个带有键“hosts”、“dopants”和“hosts2dopants”的JSON对象schame(它反过来又有一个键值对象作为其对应的值)。对于熟悉Python编程语言的读者来说,这些与Python字典对象相同,其中字符串作为键,字符串或其他字典作为值。我们包括与seq2rel基线比较,seq2rel是一种可比较的序列对序列方法,在相同的doping数据集上训练。我们还比较了MatBERT-Doping,这是一个训练了约450篇摘要的NER模型,结合了一个简单的启发式方法来确定dopant-host关系;即同一句子(样本)内的所有host和dopant都是相关的。我们把这个模型称为MatBERT-Proximity。因为一般的材料信息抽取和MOF信息抽取任务要复杂得多,所以我们没有尝试训练模型来输出英语句子(与JSON格式的字符串相反),因为结果序列很难解析为结构化的数据库实体。
如表4所示对于host-dopant任务,我们评估了3种不同的schame输出格式。三种不同schame的LLM-NERRE模型的性能显著优于MatBERT-Proximity或seq2rel基线模型。在这六个基于LLM的模型中,,Llama-2模型使用Doping-JSON模式表现最佳(F1 = 0.821),GPT-3/DopingExtra-English(F1 = 0.809)和Llama-2/Doping-English(F1 = 0.814)都在2%的误差范围内。
五、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 7831
7831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









