







RAM-Recognize Anything: A Strong Image Tagging Model
大语言模型(Large Language Models)已经给自然语言处理(NLP)领域带来了新的革命。在计算机视觉(CV)领域,Facebook近期推出的Segment Anything Model(SAM)工作,在视觉定位(Localization)任务上取得了令人振奋的结果。然而SAM作为一个极致的定位大模型,并没有识别(Recognition)能力,而识别是与定位同等重要的CV基础任务。现有的开放式检测、分割任务尝试同时做好识别和定位,却在两个任务上都不能达到极致。
视觉感知大模型Recognize Anything Model(RAM),提供最强的图像识别能力,RAM为图像识别领域提供了一种新的范式,使用海量无需人工标注的网络数据,可以训练出泛化能力强大的通用模型,甚至在垂域下可以超越人工标注训练的有监督模型。
一,RAM:
摘要
我们提出了 “识别万物模型”(RAM):一个用于图像标注的强大基础模型。RAM 在计算机视觉领域的大型模型发展方面迈出了坚实的一步,展示出了能以高精度识别任何常见类别的零样本能力。RAM 引入了一种图像标注的新范式,利用大规模的图像 - 文本对进行训练,而非依靠人工标注。
RAM 的开发包含四个关键步骤。
-
首先,通过自动文本语义解析大规模获取无标注的图像标签。
-
随后,通过统一图像字幕和标注任务来训练一个初步模型以进行自动标注,该模型分别由原始文本和解析后的标签进行监督。
-
第三,运用一个数据引擎来生成额外的标注并清理错误标注。
-
最后,使用经过处理的数据对模型重新训练,并利用一个规模更小但质量更高的数据集对其进行微调。
我们在众多基准测试上评估了 RAM 的标注能力,观察到了令人印象深刻的零样本性能,其表现显著优于 CLIP 和 BLIP。值得注意的是,RAM 甚至超过了完全监督方式的表现,并与谷歌标注 API 展现出了颇具竞争力的性能。我们将在https://recognize-anything.github.io/ 发布 RAM,以推动计算机视觉领域大型模型的发展。
1. Introduction
在大规模网络数据集上训练的大型语言模型(LLM)在自然语言处理(NLP)领域引发了一场革命。这些模型 [20, 5] 展现出了令人惊叹的零样本泛化能力,使其能够泛化到超出其训练领域的任务和数据分布上。在计算机视觉(CV)领域,“分割万物模型”(SAM)[12] 也通过数据规模的扩大展示出了卓越的零样本定位能力。
然而,“分割万物模型”(SAM)缺乏输出语义标签的能力,而输出语义标签与定位是同等重要的基础任务。多标签图像识别,也被称为图像标注,旨在通过识别给定图像的多个标签来提供语义标签。图像标注是一项重要且实用的计算机视觉任务,因为图像本身就包含多个涵盖物体、场景、属性和行动的标签。遗憾的是,现有的多标签分类、检测、分割以及视觉 - 语言方法中的模型在图像标注方面都表现出了不足之处,具体表现为适用范围有限或准确率较低,如图 1 所示。
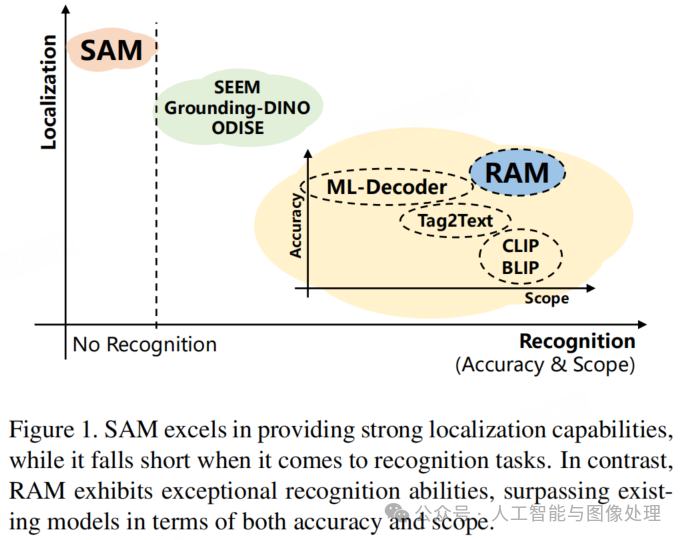
有两个核心因素阻碍了图像标注的进展。
-
难点在于收集大规模的高质量数据。具体而言,目前缺少一个通用且统一的标签系统以及一个高效的数据标注引擎,该引擎需具备对包含大量类别的大规模图像进行半自动甚至自动标注的能力。
-
缺乏高效且灵活的模型设计,这种设计应能够利用大规模弱监督数据来构建一个具备开放词汇且功能强大的模型。
为解决这些关键瓶颈问题,本文引入了 “识别万物模型”(RAM),这是一个用于图像标注的强大基础模型。RAM 克服了与数据相关的诸多挑战,包括标签系统、数据集以及数据引擎方面的挑战,同时也突破了模型设计方面的局限。
- 标签系统:我们首先建立一个通用且统一的标签系统。我们纳入了来自热门学术数据集(分类、检测和分割数据集)以及商业标注产品(谷歌、微软、苹果)中的各类别。我们的标签系统是通过将所有公开标签与文本中的常见标签进行合并而获得的,这样就涵盖了大部分常见标签,数量适中,共 6449 个。其余的开放词汇标签可通过开集识别的方式来确定。
- 数据集:如何利用标签系统对大规模图像进行自动标注是另一个挑战 [30]。受 CLIP [22] 和 ALIGN [11] 的启发(它们利用大规模公开可用的图像 - 文本对来训练强大的视觉模型),我们在图像标注方面采用了类似的数据集。为了利用这些大规模图像 - 文本数据进行标注,参照 [9, 10],我们对文本进行解析,并通过自动文本语义解析来获取图像标签。这一过程使我们能够依据图像 - 文本对获取多种多样的无标注图像标签集合。
- 数据引擎:然而,来自网络的图像 - 文本对本身存在噪声,往往包含缺失或错误的标签。为提高标注质量,我们设计了一个标注数据引擎。在处理缺失标签方面,我们利用现有模型来生成额外的标签。对于错误标签,我们首先定位图像内与不同标签相对应的特定区域。随后,我们运用区域聚类技术来识别并剔除同一类别中的异常值。此外,我们会过滤掉在整幅图像及其对应区域之间呈现出相悖预测的标签,以此确保标注更加干净、准确。
- 模型:Tag2Text [10] 通过整合图像标注与图像字幕,并结合使用轻量级识别解码器 [18] 以及原始图像编码器,展现出了卓越的图像标注能力。然而,Tag2Text 的有效性局限于识别固定且预先定义好的类别。与之相反,“识别万物模型”(RAM)通过将语义信息融入标签查询中,能够对之前未见过的类别进行泛化。这种模型设计使得 RAM 能够增强对任何视觉数据集的识别能力,突显了其在多样化应用方面的潜力。
得益于大规模、高质量的图像 - 标签 - 文本数据以及图像标注与字幕的协同整合,我们开发出了一个强大的 “识别万物模型”(RAM)。RAM 代表了一种图像标注的新范式,它表明了一个基于有噪声、无标注数据训练而成的通用模型能够超越完全监督模型。RAM 的优势总结如下:
-
强大且通用:如图 2 所示,RAM 展现出了卓越的图像标注能力,具备强大的零样本泛化能力;
-
可复现且成本低:RAM 借助开源且无标注的数据集,其复现成本较低。而且,最强版本的 RAM 仅需使用 8 个 A100 GPU 训练 3 天;
-
灵活且用途广泛:RAM 具有显著的灵活性,能够适应各种应用场景。通过选择特定的类别,RAM 可直接被部署以满足特定的标注需求。此外,当与定位模型(Grounding DINO 和 SAM)相结合时,RAM 能构成一个强大且通用的视觉语义分析流程。

2. RAM
2.1. 模型结构
如图 3 所示,我们通过文本语义解析提取图像标签,在无需昂贵的人工标注的情况下提供了大规模的标签。RAM 的整体架构与 Tag2Text [10] 相似,它由三个关键模块组成:一个用于特征提取的图像编码器,一个紧随其后的用于标注的图像 - 标签识别解码器 [18],以及一个用于生成字幕的文本生成编码器 - 解码器。图像特征通过图像 - 标签交互编码器和识别解码器中的交叉注意力层与标签进行交互。在训练阶段,识别头学习预测从文本中解析出来的标签,而在推理阶段,它充当图像到标签的桥梁,通过预测标签为图像字幕提供更明确的语义指导。
与 Tag2Text [10] 相比,RAM 在模型设计方面的核心进步在于引入了开放词汇识别。Tag2Text 只能识别其在训练期间见过的类别,而 RAM 则能够识别任何类别。
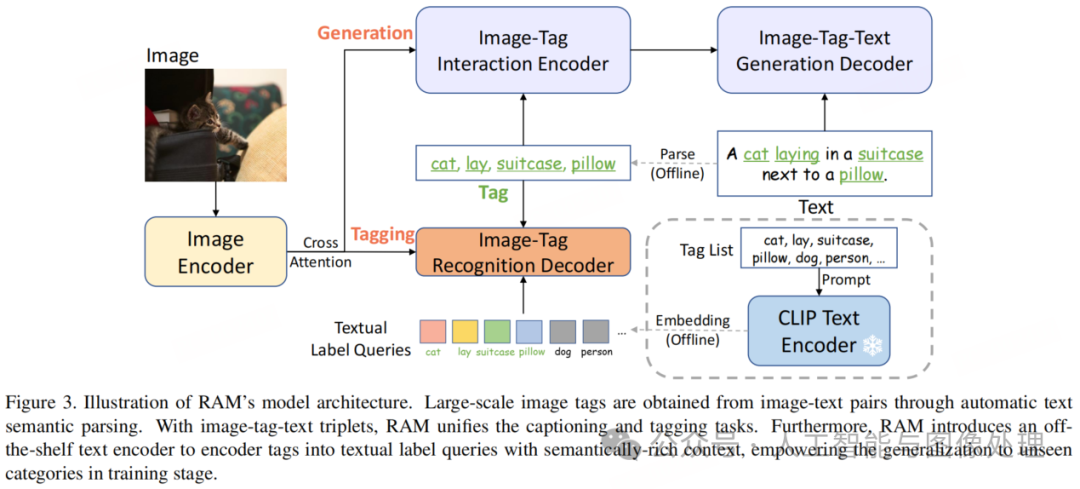
2.2. Open-Vocabulary 识别
Open-Vocabulary Recognition(开放词汇识别)是指机器学习模型能够识别和分类那些在训练过程中未出现的类别。
文本标签查询:受 [23, 28] 的启发,关键的改进在于将语义信息融入识别解码器的标签查询中,这有助于在训练阶段对之前未见过的类别进行泛化。为实现这一点,我们利用一个现成的文本编码器对标签列表中的各个标签进行编码,从而为文本标签查询提供语义丰富的上下文。相比之下,原始识别解码器 [10, 18] 中所采用的标签查询是随机可学习的嵌入向量,它们与未见过的类别缺乏语义关联,因此局限于预先定义的已知类别。
实现细节:我们采用 Swin - 变换器 [19] 作为图像编码器,因为它在视觉 - 语言 [10] 和标注领域 [18] 都展现出了比普通视觉 Transformer(ViT)更好的性能。用于文本生成的编码器 - 解码器是 12 层变换器,而标签识别解码器是一个 2 层变换器。我们利用来自 CLIP [22] 的现成文本编码器,并执行提示集成 [22] 来获取文本标签查询。我们还采用 CLIP 图像编码器来提取图像特征,通过图像 - 文本特征对齐进一步提升模型对未见过类别的识别能力。
2.3 模型效率
训练阶段:RAM 先在分辨率为 224 的大规模数据集上进行预训练,然后使用规模小但质量高的数据集在分辨率为 384 的情况下进行微调。经验表明,RAM 收敛速度很快,通常只需经过极少的轮次(一般少于 5 轮次)就能实现收敛。这种快速收敛在有限的计算资源下提升了 RAM 的可复现性。例如,在 400 万张图像上预训练的 RAM 版本仅需 1 天的计算时间,而在 1400 万张图像上预训练的 RAM 最强版本在 8 个 A100 GPU 上也仅需 3 天的计算时间。
推理阶段:轻量级的图像 - 标签识别解码器有效地确保了 RAM 在图像标注方面的推理效率。此外,我们去除了识别解码器中的自注意力层,这不仅进一步提高了效率,还避免了标签查询之间可能存在的干扰。因此,与只能处理固定类别和数量不同,RAM 允许针对任何想要自动识别的类别和数量定制标签查询,增强了它在各种视觉任务和数据集上的实用性。
3. 数据
3.1. 标签系统
这项工作在制定标签系统时遵循了三条指导原则:
-
在图像 - 文本对中频繁出现的标签更具价值,因为它们在图像描述方面具有代表性意义。这些经常出现的标签往往能反映出图像内容中较为关键和常见的元素,有助于准确地对图像进行标注和描述。
-
标签应体现多种领域和情境。我们对标签的定义包含了来自不同来源的物体、场景、属性以及行动等内容,这有助于模型泛化到复杂的、未曾见过的场景中。如此一来,模型在面对各式各样的图像时,能够依据这些丰富的标签信息更好地识别和理解图像内容。
-
标签的数量需要适中。过多的标签数量可能会导致高昂的标注成本。若标签数量过多,无论是人工标注还是通过其他方式进行标注处理,都会耗费大量的人力、物力以及时间等资源,不利于整个系统的高效运作和实际应用。
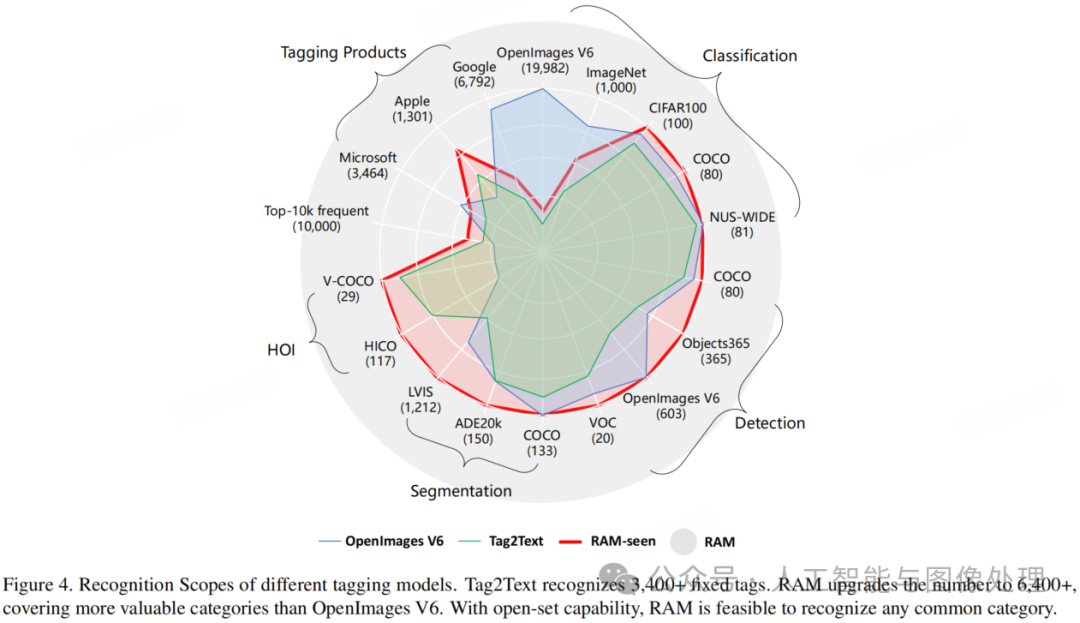
起初,我们通过对 SceneGraph-Parser [25] 稍作修改后,利用它将来自预训练数据集的 1400 万句话解析为标签。然后,我们从出现频率最高的前 1 万个标签中手工挑选出一些标签。我们的挑选有意涵盖了众多用于分类、检测和分割的热门数据集里的标签,如图 4 所示。虽然大多数数据集的标签都能被完全涵盖,但 ImageNet 和 OpenImages V6 属于例外情况,因为它们的标签呈现情况比较特殊。
此外,我们还部分涵盖了来自领先标注产品的标签,这些标签是通过使用开源图像并借助公开 API [2, 3, 1] 获取的。因此,RAM 能够识别多达 6449 个固定标签,这比 Tag2Text [10] 所能识别的标签数量要多得多,并且其中包含的有价值标签的比例也更高。
为减少冗余,我们通过多种方法收集同义词,包括人工核查、参考 WordNet [7]、对标签进行翻译和合并等操作。同一同义词组内的标签会被赋予相同的标签 ID,最终在该标签系统中形成了 4585 个标签 ID。
3.2. 数据集
与 BLIP [15] 和 Tag2Text [10] 类似,我们在广泛使用的开源数据集上对模型进行预训练。采用了 400 万(4M)图像和 1400 万(14M)图像这两种设置。
400 万图像的设置包含两个人工标注的数据集,即 COCO [16](含 11.3 万张图像、55.7 万个字幕)和视觉基因组 [13](含 10.1 万张图像、82.2 万个字幕),以及两个大规模的基于网络的数据集,即概念字幕 [6](含 300 万张图像、300 万个字幕)和 SBU 字幕 [21](含 84.9 万张图像、84.9 万个字幕)。
1400 万图像的设置建立在 400 万图像设置的基础之上,额外增加了概念 1200 万 [6](含 1000 万张图像、1000 万个字幕)数据集。
3.3 数据引擎
鉴于我们的训练数据集主要是开源性质的,大多是从互联网上抓取而来,我们遇到了数量不容忽视的缺失标签和错误标签问题。为缓解这一问题,我们设计了一个自动数据引擎来生成额外的标签并清理错误标签。
生成:我们的第一步是使用从字幕中解析出的字幕和标签来训练一个基准模型,这与 Tag2Text [10] 中使用的方法类似。然后,我们利用这个基准模型分别借助其生成能力和标注能力来补充字幕和标签。将原始字幕和标签与生成的字幕、相应的解析标签以及生成的标签合并,形成一个临时数据集。这一步骤使得 400 万图像数据集中的标签数量从 1200 万显著增加到 3980 万。
清理:为解决错误标签的问题,我们首先使用 Grounding-Dino [29] 来识别并裁剪所有图像内与特定类别相对应的区域。随后,我们基于 K-Means++[4] 对该类别下的区域进行聚类,并剔除与异常值(占 10%)相关联的标签。同时,我们还会利用基准模型移除那些未对该特定类别做出预测的标签。这样做的动机在于,通过对区域而非整幅图像进行预测,标注模型的精度能够得到提高。
4. 实验
4.1. 实验设置
测试基准:我们在不同计算机视觉任务(包括分类、检测和分割)的各类流行基准数据集上对模型进行了全面评估,相关内容总结于表 1 中。对于分类任务,我们采用了 OpenImages V6 [14] 数据集,它包含 9605 个类别。然而,由于 OpenImages 数据集中存在标签缺失以及标注错误等问题,我们精心整理了两个高质量的子集:OpenImages - common,它包含 214 个标注良好的常见类别;以及 OpenImages - rare,由 200 个不在我们用于开集实验的标签系统内的类别组成。此外,为了便于更好地进行零样本评估,我们使用了一个名为 OPPO - common 的内部测试集,该测试集具有很高的标注质量。
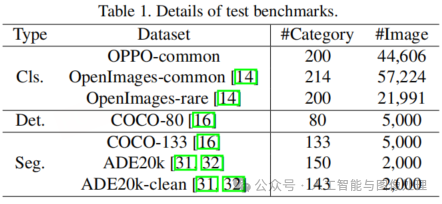
对于检测和分割数据集,我们选择了广受认可的 COCO [16] 数据集以及 ADE20K [31, 32] 数据集。在这些数据集中,我们仅将语义标签作为图像级标注的真值,而忽略边界框和掩码信息。需要注意的是,ADE20K 包含大量非常小的真值标注以及偏离主流概念的模糊类别,例如 “自助餐” 这一类别。因此,我们通过移除一些小目标以及模糊类别创建了一个名为 ADE20K - clean 的 ADE20K 子集。
评估指标:为评估模型的性能,我们采用了多种评估指标。在消融实验以及与其他分类模型进行对比时,我们使用平均精度均值(mAP)来汇报结果。对于那些无法获取平均精度均值的模型,我们运用精确率 / 召回率指标,并手动调整不同模型的阈值,以确保各项评估之间具有可比性。
4.2. 与最先进的模型对比
与多标签分类模型的比较。我们将RAM与多标签分类领域中最先进的(SOTA)模型进行了比较,如表 2 所示。一般来说,通用型模型通常在特定领域缺乏专业能力,而专业型模型则难以将其能力泛化到自身专业领域之外。具体而言,有监督的专业型模型 ML-Decoder [23] 在其指定的专业领域 OpenImages 中表现出色,但在将能力泛化到其他领域以及应对未见过的类别时面临挑战。多知识迁移模型(MKT)[8] 是一种通过迁移来自 CLIP 的知识进行标注的通用型模型,它无法在所有领域都达到令人满意的准确率。Tag2Text [10] 在零次标注方面能力很强,但缺乏处理开放集场景的能力。
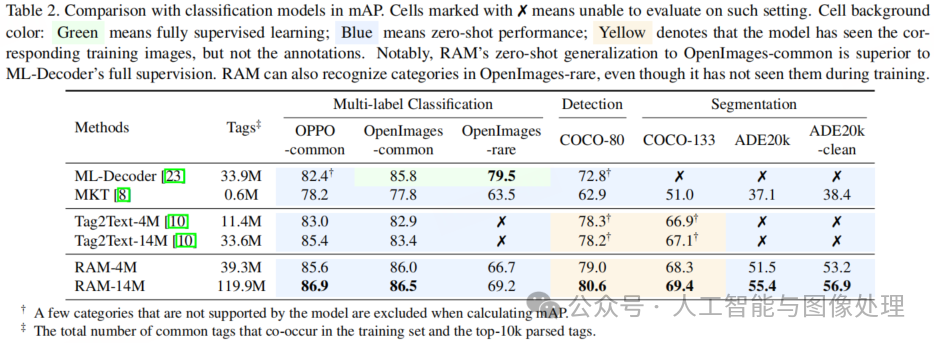
RAM展现出了令人瞩目的标注能力,呈现出了出色的准确率和广泛的覆盖范围。尤其值得注意的是 RAM-4M 的表现,它在 OpenImages-common 数据集上超越了 ML-Decoder。ML-Decoder 依赖来自 OpenImages 的 900 万张带标注图像,而我们的 RAM-4M 利用 400 万张无标注的图像 - 文本数据作为训练集就实现了更高的准确率。这一改进得益于利用了从 400 万张图像中提取出的 3930 万个常用标签,其表现优于仅使用从 900 万张图像中提取的 3390 万个常用标签进行训练的 ML-Decoder。此外,随机注意力模型(RAM)凭借可利用的 6400 多个已见过的常用类别以及其开放词汇的能力,能够识别任何常见类别。
与检测及分割模型的比较。表 3 中的对比结果显示,有监督的检测和分割模型在诸如 COCO 数据集这类涵盖类别数量有限的特定领域表现出色。然而,当要识别更多类别的时候,这些模型就面临诸多挑战。一方面,由于它们需要更复杂的网络以及更大的输入图像尺寸来完成额外的定位任务,因此会耗费多得多的计算资源。尤其是 ODISE [26],因其采用了扩散模型以及较大的输入图像分辨率,推理耗时很长。另一方面,检测和分割模型训练数据的可扩展性有限,这导致这些模型的泛化性能较差。尽管 Grounding-DINO [17] 属于通用型模型,但它在应对大规模类别时也难以取得令人满意的性能。相比之下,RAM展现出了令人瞩目的开放集能力,超越了现有的检测和分割模型。RAM展示出了能在更广泛的类别范围内进行泛化的能力,为传统检测和分割模型所面临的挑战提供了一个强有力的解决方案。
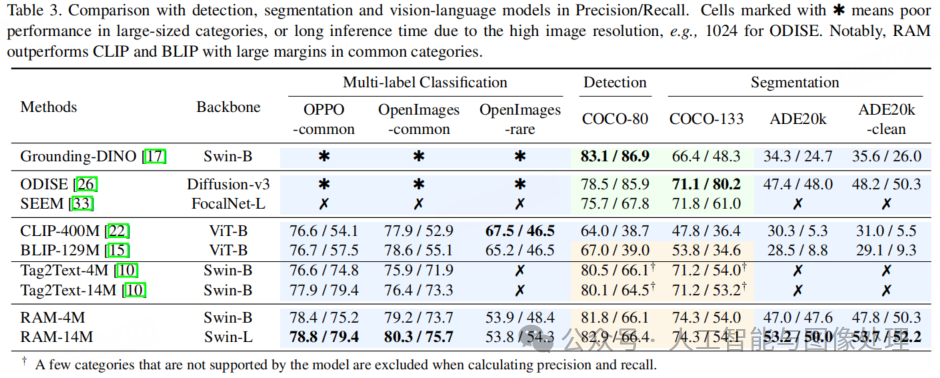
与视觉 - 语言模型的比较。尽管 CLIP [22] 和 BLIP [15] 具备开放集识别能力,但这些模型的准确率欠佳。此外,由于它们依靠对图像 - 文本对的密集嵌入进行余弦相似度计算,其可解释性也有限。相比之下,RAM展现出了更优的性能,在几乎所有数据集上都显著超越 CLIP 和 BLIP,准确率提升超过 20%。不过,值得注意的是,在 OpenImages-rare 数据集的情况下,RAM的表现略逊于 CLIP 和 BLIP。我们将这种差异归因于RAM所使用的训练数据集规模更小,以及在训练期间对稀有类别相对不够重视。
4.3 模型消融实验
在表 4 中,我们基于 Tag2Text [10] 研究了各种模型改进措施对RAM的影响,并得出了以下几个结果。
-
1)字幕添加与标注的训练整合能够提升标注能力。
-
2)通过利用 CLIP [22] 进行文本查询可以实现开放集识别能力,但这对训练中已见过的类别影响甚微。
-
3)标签系统的扩展对现有类别产生的影响极小,这可归因于新增类别增加了模型训练的难度。不过,这种扩展同时提高了模型的覆盖范围,并增强了其对未见过类别的开放集识别能力。

4.4. 数据引擎消融实验
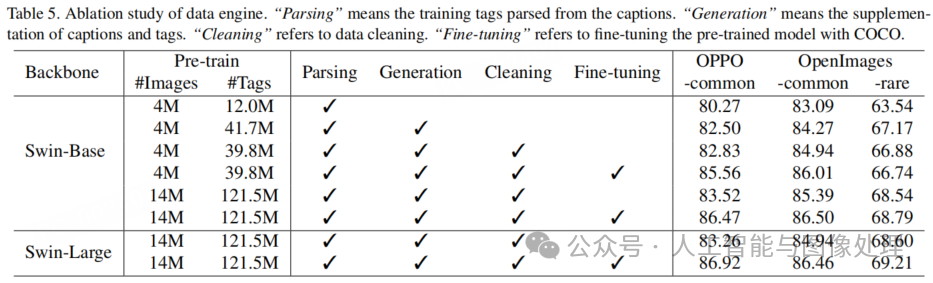
我们在表 5 中展示了对数据引擎的消融实验。研究结果总结如下:
-
将标签数量从 1200 万个增加到 4170 万个,显著提升了模型在所有测试集上的性能,这表明原始数据集中存在严重的标签缺失问题。
-
进一步清理部分类别的标签,使得 OPPO-common 和 OpenImages-common 测试集上的性能略有提升。受 Grounding-Dino 推理速度的限制,我们仅对 534 个类别进行了清理操作。
-
将训练图像的数量从 400 万张扩展到 1400 万张,使所有测试集的性能都有了显著提升。
-
采用更大的骨干网络会使 OpenImages-rare 测试集上的性能略有改善,但在常见类别上的性能甚至会略有下降。我们将这种现象归因于可用于超参数搜索的资源不足。
-
使用从 COCO 字幕数据集 [16] 解析出的标签进行微调,OPPO-common 和 OpenImages-common 测试集上的性能有了显著提升。COCO 字幕数据集为每张图像提供了五个描述性句子,提供了近似于一整套标签的全面描述。
5. 结论
我们提出了用于图像标注的强大基础模型 —— 识别万物模型(RAM),它开创了该领域的一种全新范式。RAM展现出了以高准确率识别任意类别的零次学习能力,超越了全监督模型以及诸如 CLIP 和 BLIP 等现有通用型方法的性能表现。RAM代表了计算机视觉领域大规模模型的一项重大进步,具备增强任何视觉任务或数据集识别能力的潜力。
二,相关地址:
论文地址:https://zhuanlan.zhihu.com/p/675019056
代码地址:https://github.com/OPPOMKLab/recognize-anything

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









