







本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下:
也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
目录
1 正则化方法
如果神经网络过度拟合了数据(即存在高方差问题),一种解决方法是使用更多的数据进行训练。
但如果你无法准备足够多的训练数据,那么另一种解决的方法是正则化(Regularization)。正则化通常有助于避免过拟合,或者减少错误率。

在逻辑回归中,成本函数 J 是 ω 和 b 的函数,其中 ω 是一个高维矢量,b 则是一个实数。在成本函数 J 的基础上增加一项(关于 ω 的 L2 范数),得到如下函数
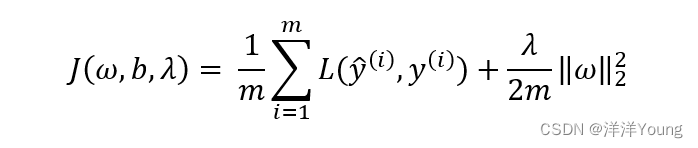
其中 λ 称为正则化参数,这种方法也叫做 L2 正则化(L2 Regularization)。

另一种正则化的方法是增加关于 ω 的 L1 范数,称为 L1 正则化(L1 Regularization)。如果使用 L1 正则化, ω 最终会是稀疏的(换句话说,ω 中会有很多 0)。

在神经网络中,每一层的权重 W 是一个矩阵,因此正则项使用 W 的 Frobenius 范数,用下标 F 表示。
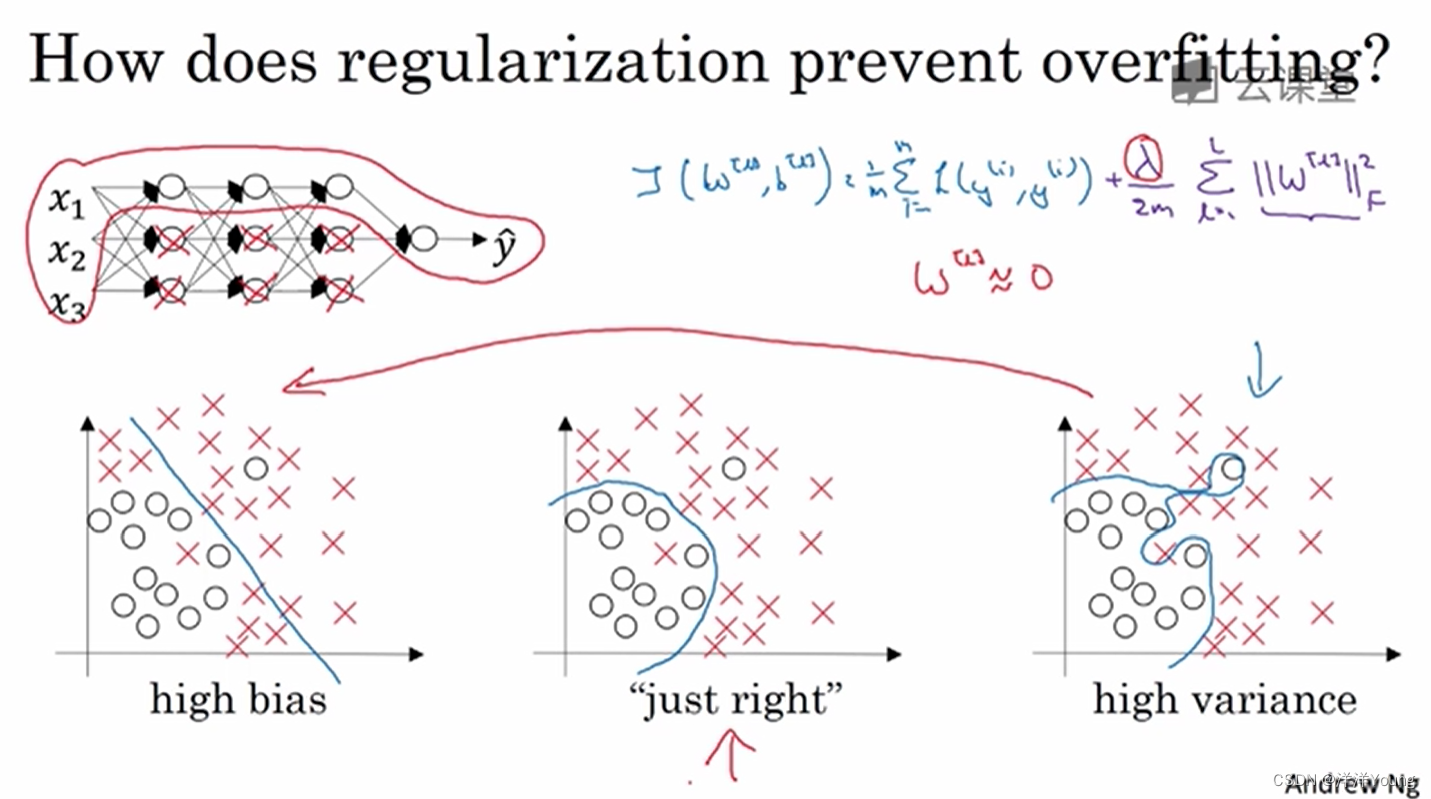
当正则化参数 λ 设置得较大时,最终神经网络各层的权值会接近 0,这会使神经网络从复杂朝着简单的方向演化,模型从过拟合(Overfitting)趋于欠拟合(Underfitting)。当 λ 设为某个值时,模型的评估结果介于高方差与高偏差中间。
2 Dropout 随机失活
除了 L2 正则化,还有一种常用的方法—— Dropout 随机失活。
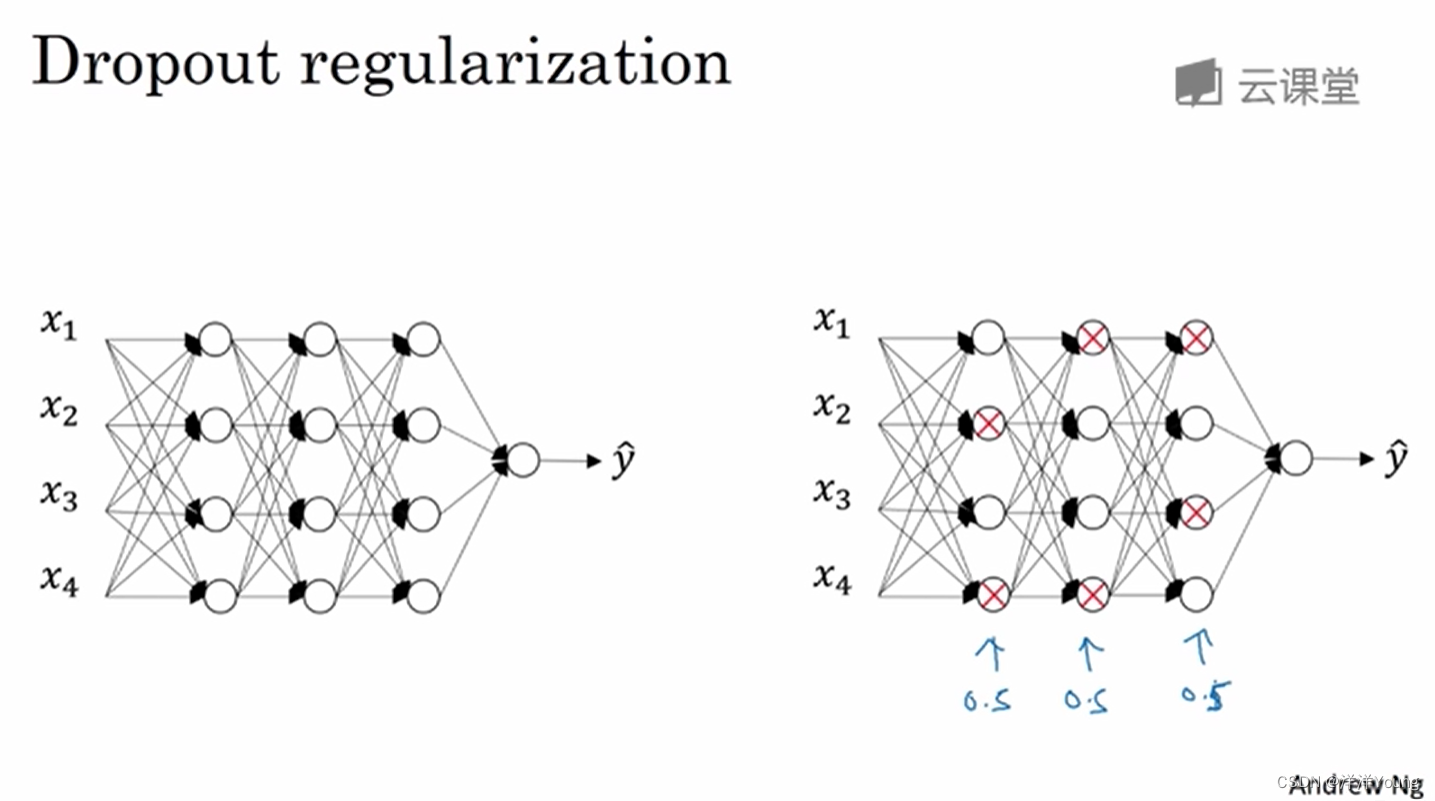
在采用 Dropout 规则的优化算法中,算法会遍历神经网络的每一层,并根据设定的概率,决定每个节点的激活输出得以保留还是消除。
对于不同的训练样本,算法保留的神经网络节点是不同的,这种方法称为 Dropout 随机失活。当采用 Dropout 时,我们在训练一个简化的神经网络,这对防止过拟合是有帮助的。
















 8921
8921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











