







来源:专知
本文为论文介绍,建议阅读5分钟
我们提出了一种通过提升学习变异特征来衡量领域异质性的学习潜能指导度量。
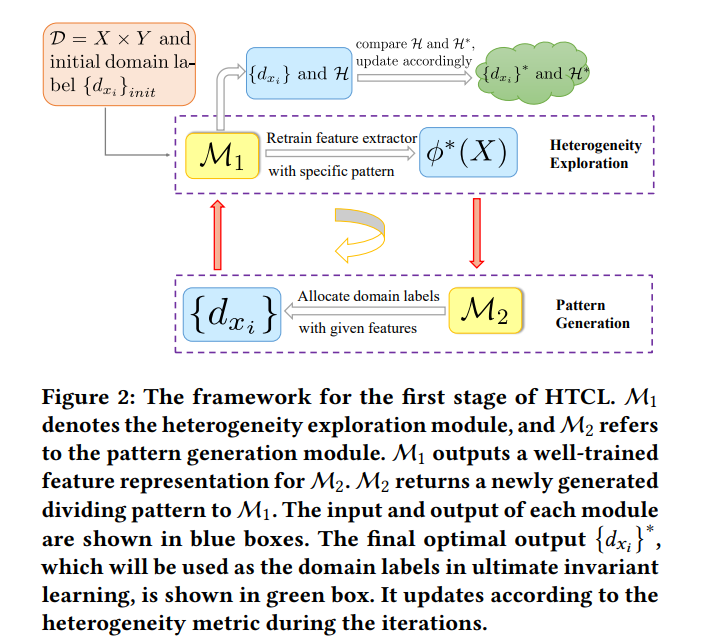
领域泛化(DG)是现实世界应用中普遍存在的问题,其目标是利用多个源领域来训练出对未见过的目标领域具有良好泛化能力的模型。由于领域标签(即每个数据点采样自哪个领域)自然存在,大多数DG算法将它们视为一种监督信息,以提高泛化性能。然而,由于缺乏领域异质性(即领域间的多样性),原始领域标签可能并非最优的监督信号。例如,一个领域中的样本可能更接近另一个领域,因此其原始标签可能会成为扰乱泛化学习的噪声。尽管有些方法试图通过重新划分领域并应用新生成的划分模式来解决这个问题,但由于缺乏衡量异质性的指标,他们选择的模式可能并非最异质的。在本文中,我们指出领域异质性主要存在于不变学习框架下的变异特征中。借助对比学习,我们提出了一种通过提升学习变异特征来衡量领域异质性的学习潜能指导度量。然后,我们注意到寻求基于方差的异质性和训练基于不变性的可泛化模型之间的差异。因此,我们提出了一种新的方法,称为基于异质性的两阶段对比学习(HTCL)来进行DG任务。在第一阶段,我们使用我们的对比度量生成最异质的划分模式。在第二阶段,我们采用以不变性为目标的对比学习,通过重建由领域和类别提示的稳定关系的对,更好地利用生成的领域标签进行泛化学习。大量实验表明,HTCL更好地挖掘了异质性,并产生了优秀的泛化性能。
https://arxiv.org/abs/2305.15889


















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









