







来源:PaperEveryday
本文共3200字,建议阅读9分钟尽管存在大量网络规模的数据,并且出现了各种零样本可泛化模型,但由于变化标注成本高昂,当前的SCD仍然受到数据集的限制。论文信息
题目:Towards Generalizable Scene Change Detection
迈向可泛化的场景变化检测
作者:Jae - woo Kim、Ue - hwan Kim
一、论文创新点
提出全新任务公式化方法:提出GeSCD,首次全面解决场景变化检测研究中的泛化问题和时间一致性问题,为该领域研究提供新的方向与思路。
设计零样本场景变化检测模型:设计GeSCF模型,这是首个零样本场景变化检测模型。它以零样本方式利用分割一切模型(SAM),通过初始伪掩码生成和几何语义掩码匹配模块,解决了SAM用于场景变化检测的技术难题,具有完全的时间一致性。
构建新的评估基准:构建了GeSCD基准,提出新的评估指标,收集ChangeVPR数据集,并制定新的评估协议。新指标能同时评估方法在环境和时间上的稳健性,ChangeVPR数据集涵盖多种环境场景,为衡量SCD模型的泛化性提供有效方式。
二、摘要
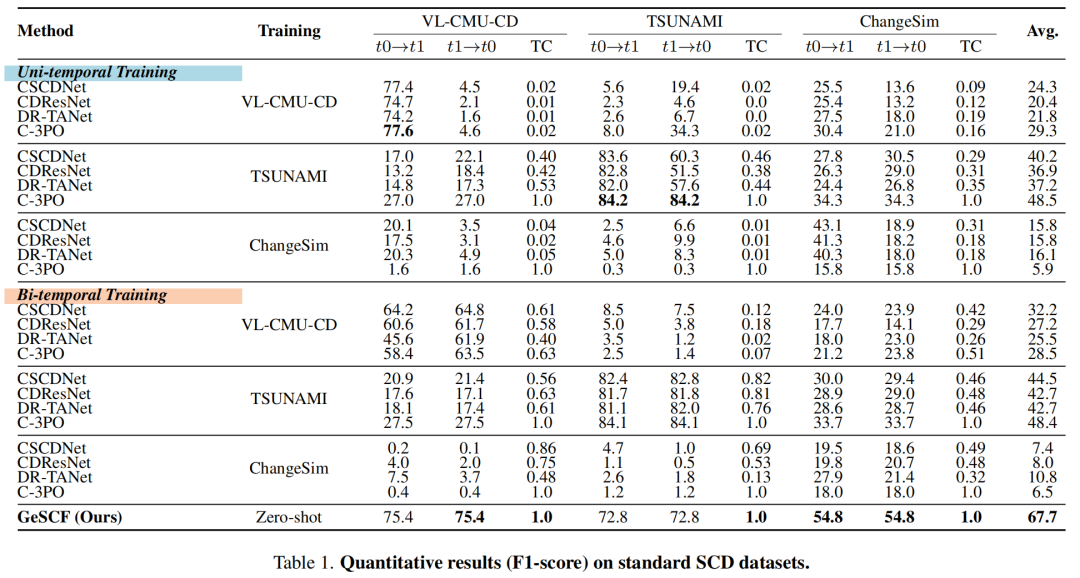
当前最先进的场景变化检测(SCD)方法在经过充分训练的研究数据上取得了令人瞩目的成果,但在未见环境和不同时间条件下却变得不可靠。在先前未见的环境中,领域内性能从77.6%骤降至8.0%,在不同时间条件下更是降至4.6%,这迫切需要可泛化的SCD方法和基准测试。在这项工作中,作者提出了可泛化场景变化检测框架(GeSCF),该框架致力于解决未见领域的性能问题和时间一致性问题,以满足对通用SCD日益增长的需求。作者的方法以零样本方式利用预训练的分割一切模型(SAM)。为此,作者设计了初始伪掩码生成和几何语义掩码匹配模块,能够无缝地将用户引导的提示和基于单图像的分割转换为无需引导的双输入图像的场景变化检测。此外,作者定义了可泛化场景变化检测(GeSCD)基准,以及新颖的指标和评估协议,以推动SCD在泛化性方面的研究。在此过程中,作者引入了ChangeVPR数据集,这是一个包含具有各种环境场景(包括城市、郊区和农村环境)的具有挑战性的图像对集合。在多个数据集上进行的广泛实验表明,GeSCF在现有SCD数据集上平均性能提升了19.2%,在ChangeVPR数据集上提升了30.0%,几乎使先前方法的性能翻倍。作者相信这项工作能够为稳健且可泛化的SCD研究奠定坚实的基础。
三、GeSCF
3.1 动机和概述
尽管存在大量网络规模的数据,并且出现了各种零样本可泛化模型,但由于变化标注成本高昂,当前的SCD仍然受到数据集的限制。因此,作者的研究动机源于SCD如何从像SAM这样的网络规模训练模型中受益。通过解决这个问题,作者旨在克服创建可泛化SCD模型这一长期障碍,最终提出了GeSCF模型。
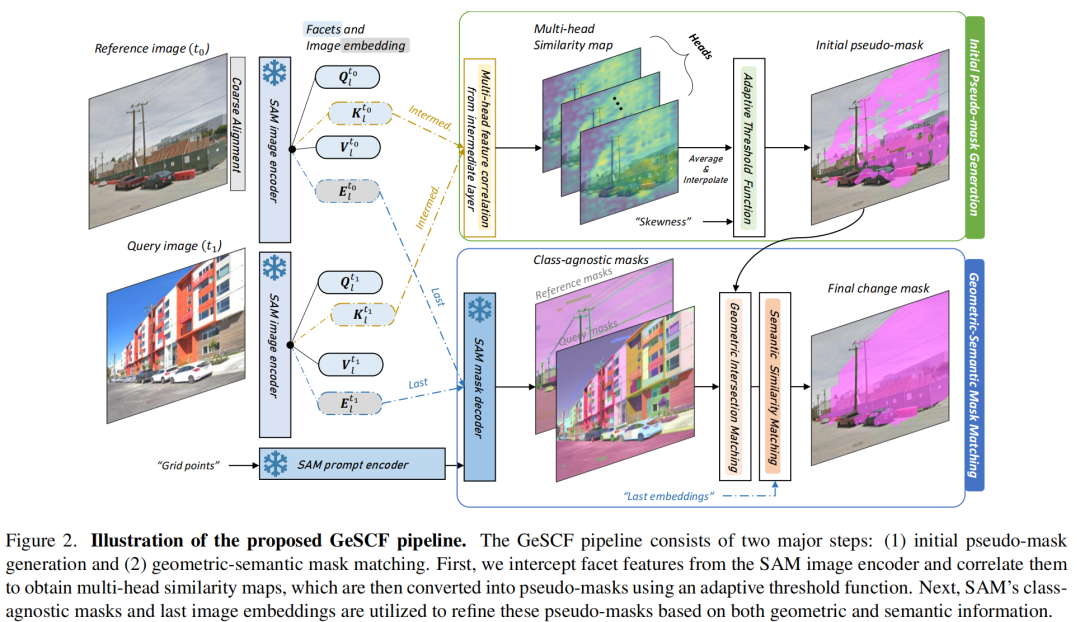
图2展示了GeSCF的流程。GeSCF通过初始伪掩码生成和几何语义掩码匹配这两个关键阶段,解决了为单图像输入的可提示交互式分割而设计的SAM与为识别图像对变化而设计的SCD之间的技术差距。首先,作者从图像编码器中截取并关联查询、键和值中的一个特征面,以获得丰富的多头相似性图;然后,使用基于偏度的算法对低相似性像素进行自适应阈值处理,将这些相似性图转换为二值伪掩码。最后,利用SAM的类别无关掩码的几何属性细化伪掩码;再通过比较双时相图像中相应掩码嵌入的语义相似性,进一步验证这些掩码,确保检测到的变化是有意义且上下文准确的。
3.2 预备知识
由于GeSCF利用从SAM图像编码器截取的一组图像特征,作者首先回顾这些特征是如何获得的。
特征面:SAM图像编码器采用视觉Transformer(ViT)架构,每个ViT块包含多头自注意力层和多层感知器。在第 个ViT块的多头自注意力层中,查询、键和值特征面表示为 ,其中 、 、 和 分别表示头数、高度、宽度和通道维度。
图像嵌入和掩码嵌入:类似地,作者从第 个ViT块的最后一个多层感知器层中提取图像嵌入 。此外,给定图像嵌入 和任意二值掩码 ,作者通过在二值掩码 非零的所有空间位置上对图像嵌入 求平均,计算掩码嵌入 ,从而获得掩码图像的单个向量表示。
3.3 初始伪掩码生成
正如文献[23]所示,SAM在同一自然场景的掩码嵌入之间保留了语义相似性。此外,如先前研究观察到的,注意力图可以捕获图像中有语义意义的对象。基于这些基础见解,作者通过将SAM的应用扩展到双时相图像,并利用不同层的多头特征面,而不是仅依赖单图像嵌入,扩展了对SAM特征空间的利用。
多头特征关联:给定一对双时相RGB图像,作者首先估计双时相图像之间的粗略变换。然后,从第 个ViT块的第 个头中截取特征面 、 ( 、 和 中的一个),并计算多头特征关联:
其中 对输入图像大小进行空间重塑和双线性插值。公式(1)中的关联是一个交换操作,即使顺序颠倒,也会生成相同的相似性图 。随后,相似性图在头维度上求平均,利用 个头之间的语义多样性。
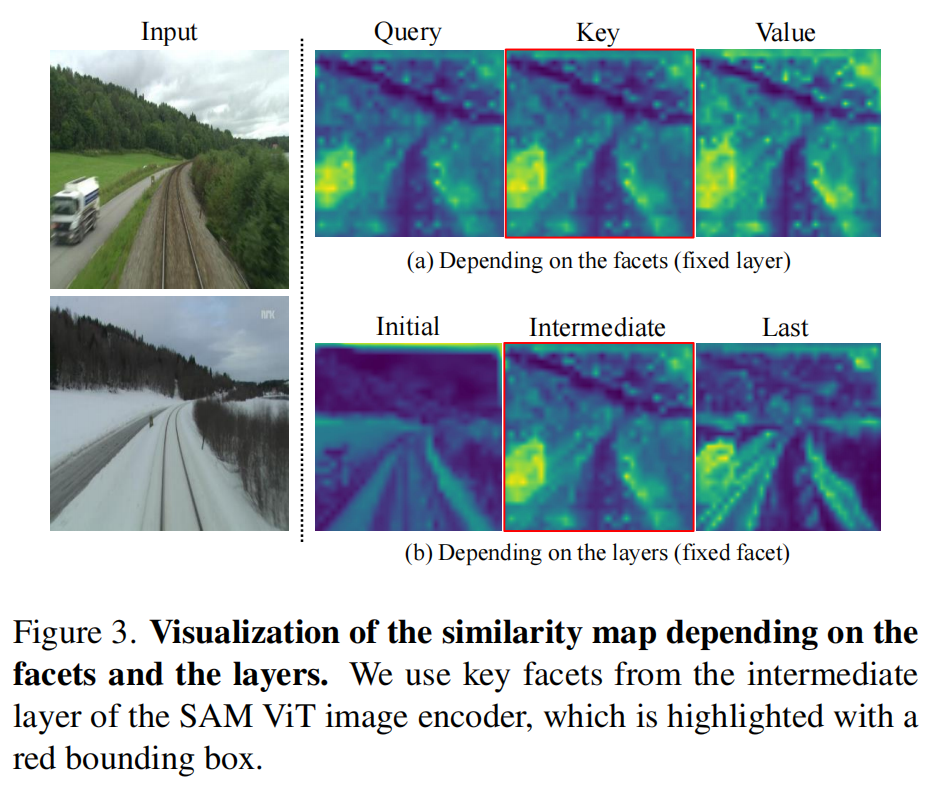
特征面和层选择:如图3所示,SAM特征面的相似性图有效地突出了语义变化,同时相对不受季节或光照差异等视觉变化的影响。具体而言,作者的特征选择策略遵循以下原则:(a)与其他视觉变化相比,语义变化应在相似性图中显著出现;(b)变化区域的相似性值应与周围区域形成明显对比;(c)未变化区域的伪影应最小化或不明显。作者通过实验观察到,所有特征面都满足原则(a);然而,当使用键(或查询)特征面而不是值特征面时,原则(b)和(c)尤为明显。此外,作者发现这些原则在中间层比在初始层或最后一层更显著。因此,作者利用中间层键特征面的相似性图作为后续伪掩码生成步骤的输入。
自适应阈值函数:从任意相似性图创建二值掩码最直接的方法是应用固定阈值(例如, ),相似性得分低于此阈值的被分类为变化。然而,这种固定阈值方法存在固有限制,因为它没有考虑每个相似性图中 “变化” 的相对性。例如,如果所有其他值都接近1,相似性得分0.7可能表示变化;但如果大多数值接近0,则可能不表示变化。因此,“变化” 的感知取决于上下文,需要一种自适应阈值方法来考虑每个图中相似性得分的相对分布。
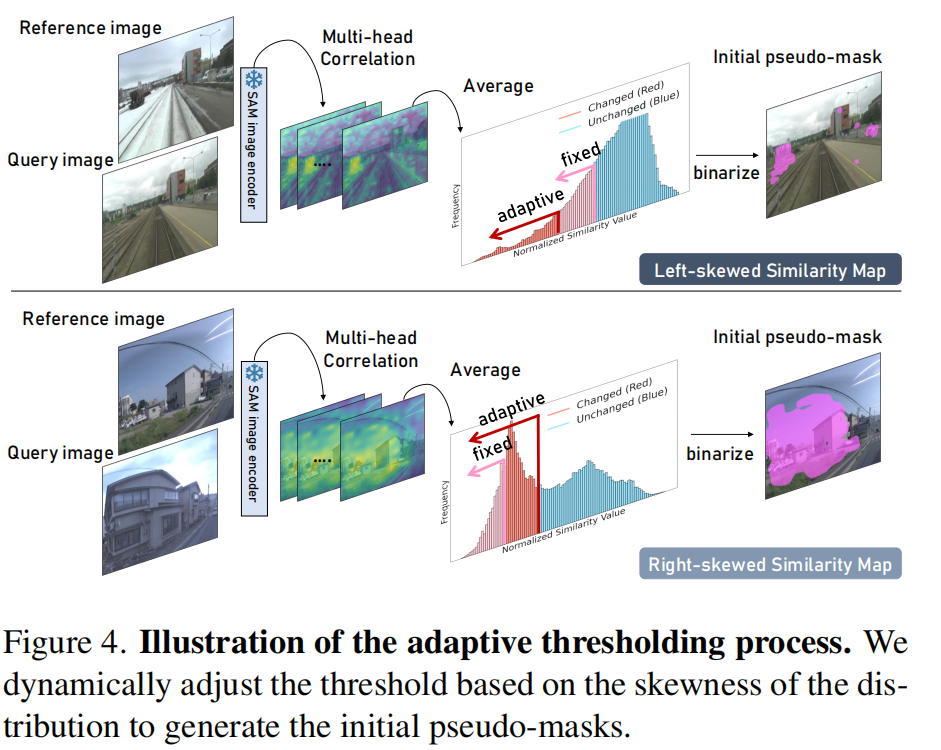
因此,将相似性图二值化的一个关键因素是相似性分布的偏度( )(见图4)。对于右偏分布,大多数像素显示较低的相似性得分,而高分值有一个长尾,需要较低的阈值来将分布的较大部分捕获为变化。相反,对于左偏分布,大多数得分较高,低分值有一个小尾巴,需要较高的阈值以避免误报。为此,作者提出了一种基于分布偏度的动态调整自适应阈值函数,实现了一种更准确、上下文敏感的伪掩码生成方法,具体公式如下:
其中 是基线阈值, 是归一化常数, 是偏度敏感因子, 是分布的偏度, 根据偏度调整阈值方向。通过将计算出的自适应阈值应用于使用平均绝对偏差(MAD)归一化的相似性图,作者获得了后续几何语义掩码匹配所需的初始伪掩码。
3.4 几何语义掩码匹配
在初始伪掩码的基础上,作者将重点提升到利用SAM的类别无关对象提议来检测对象级变化。从像素级分析到对象级考虑的转变,使得变化掩码更加全面和可解释。这里,作者引入了两种匹配策略:几何相交匹配(GIM)和语义相似性匹配(SSM)。
几何相交匹配:该策略的主要思想是通过评估SAM掩码与初始伪掩码的重叠程度来选择SAM掩码。作者计算每个SAM掩码与伪掩码之间的相交比 ,仅保留 的掩码,其中 是一个阈值。由于变化可能在双时相发生,作者对 和 图像都应用该过程,保持GeSCF的交换性。
语义相似性匹配:尽管GIM为潜在的对象级变化提供了合理的掩码,但由于初始伪掩码中的噪声,会包含一组未变化的掩码。为了解决这个问题,作者通过计算双时相图像掩码嵌入之间的余弦相似度,对重叠区域进行语义验证。具体来说,对于每个重叠掩码 ,作者分别从 和 时刻的第 个图像嵌入 中提取相应的掩码嵌入 和 。然后,作者使用余弦相似度 计算变化置信度得分,这有助于进一步优化GIM选择的掩码,并生成最终的变化掩码 。通过逐层分析,作者通过实验观察到,与初始层和中间层相比,最后一层的语义差异更为明显,因此在SSM过程中使用最终的图像嵌入。
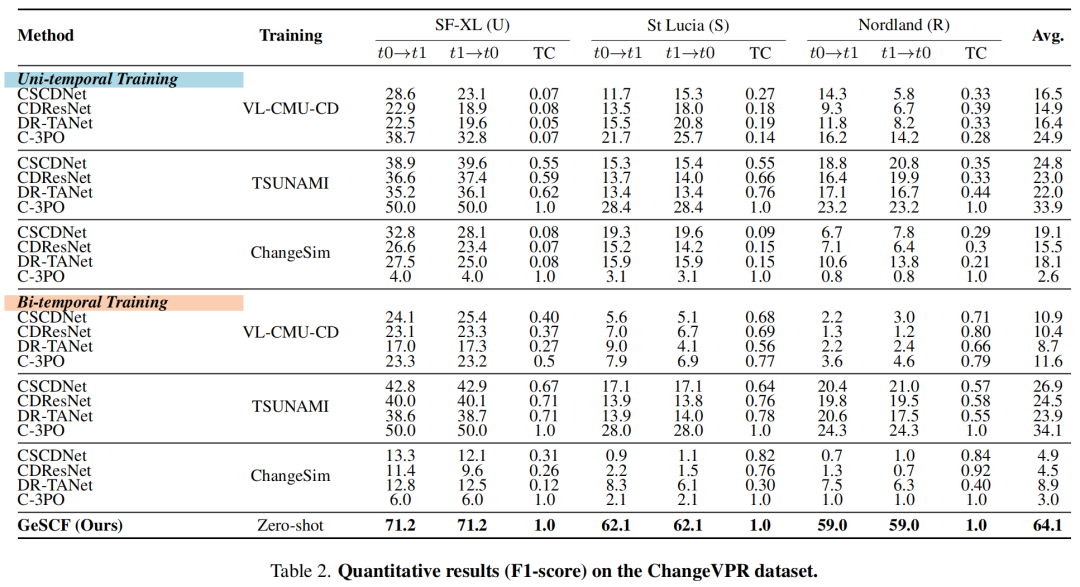
实验

声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与作者联系,作者将在第一时间回复并处理。
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 50
50

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









