







更多优质内容,请关注公众号:智驾机器人技术前线
论文信息
-
标题:Exploring the Causality of End-to-End Autonomous Driving
-
作者:Jiankun Li, Hao Li, Jiangjiang Liu, Zhikang Zou, Xiaoqing Ye, Fan Wang, Jizhou Huang, Hua Wu, Haifeng Wang
-
项目地址:https://github.com/bdvisl/DriveInsight
摘要
深度学习模型在自动驾驶领域得到了广泛应用,尤其是越来越受到关注的端到端解决方案。然而,这些模型的黑箱特性引发了人们对其在自动驾驶中的可信度和安全性的担忧,以及如何调试因果关系已成为一个紧迫的问题。尽管已有一些关于自动驾驶可解释性的研究,但目前还没有系统的解决方案来帮助研究人员调试和识别导致端到端自动驾驶最终预测动作的关键因素。在这项工作中,我们提出了一种全面的方法来探索和分析端到端自动驾驶的因果关系。首先,我们通过使用控制变量和反事实干预进行定性分析,验证了最终规划所依赖的基本信息。然后,我们通过可视化和统计分析关键模型输入的响应,定量评估影响模型决策的因素。最后,基于对多因素端到端自动驾驶系统的全面研究,我们在闭环模拟器CARLA中开发了一个强大的基线和用于探索因果关系的工具。它利用基本输入源获得一个设计良好的模型,从而具有高度竞争力的能力。据我们所知,我们的工作是首次揭开端到端自动驾驶的神秘面纱,将黑箱变成白箱。彻底的闭环实验表明,我们的方法可以应用于端到端自动驾驶解决方案的因果调试。
主要贡献
-
提出了首个调试和分析解决方案及基线,通过明确解释多因素决策的因果关系,揭开黑盒端到端自动驾驶的神秘面纱。
-
进行了详尽的定量消融和反事实干预实验,并提出了两种类型的响应可视化方法:组件级可视化,它从响应的时间一致性和场景相关性的角度进行了深入分析;以及激活图可视化,它展示了语义特征影响的空间分布。
-
首先采用反事实推理来定性找出导致最终预测动作的最有影响的特征,然后应用基于注意力的策略来定量分析每个因素对调整端到端模型的贡献,能够全面理解决策过程。
核心思想与方法
整体架构
本文所提出的算法命名为DriveInsight,整体架构如图1所示。给定多视图图像和点云输入,首先引入特定模态编码器来单独提取并转换它们的独特特征到鸟瞰图(BEV)表示。随后,利用多模态和时间融合模块,整合这些表示以派生统一的BEV特征。最后,应用规划解码器根据生成的BEV标记和其他环境指标预测自车未来轨迹。
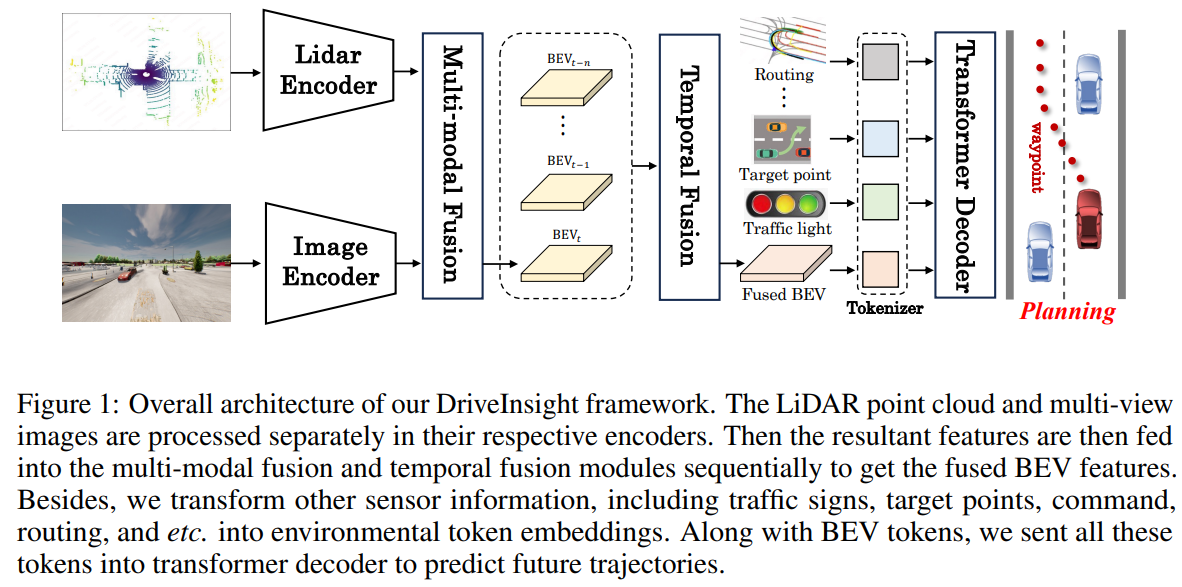
image
特定模态编码器
-
相机编码器:对于多视图相机图像,我们首先采用图像主干架构(例如ResNet [16])与特征金字塔网络,提取富含语义的多尺度图像特征。按照广泛采用的LSS [32],我们使用估计的深度将多视图特征提升到3D锥体,并将锥体溅射到参考平面上以生成BEV特征。具体来说,该过程首先由深度预测网络(DepthNet)预测每个像素的离散深度分布,然后使用这些分布将每个像素散布到沿相机射线的离散点上。在每个点上,结果特征被确定为预测深度与相应像素特征的乘积。在BEV特征的每个网格内,使用锥体池化进行聚合,该池化结合了网格内点的特征。
-
激光雷达编码器:对于给定的激光雷达点云,我们首先将输入点体素化到统一的体素箱中,并使用一系列3D稀疏卷积块在体素空间中提取局部3D形状信息,这与该领域中确立的方法一致。接下来,我们采用hourglass convolutional network 作为BEV特征提取器,将3D特征展平为2D BEV视图,以捕获富含上下文信息的BEV表示。为了最大限度地利用多尺度语义,我们采用特征金字塔网络整合来自不同层次级别的特征,从而产生具有尺度感知的BEV输出特征。
融合编码器
-
多模态融合:在将所有感官特征转换为统一的鸟瞰图(BEV)表示后,我们采用多模态融合技术来整合两组不同的特征,从而产生融合的多模态特征。最初,一系列2D卷积层被用于分别将两种不同的BEV特征标准化到统一的维度,然后这些特征被连接起来并通过一系列2D卷积层进行处理。为了增强通道间的交互作用,应用了多个压缩激励(Squeeze-and-Excitation, SE)块[19]来操作融合的特征。鉴于最终规划预测中的单一直接监督不足以有效处理高维多传感器输入的复杂性,我们引入了受DriveAdapter[25]启发的BEV特征图的补充特征级监督。
-
时间融合:为了充分利用广泛的历史信息,我们开发了时间融合模块,对齐并整合时间线索以实现更准确的预测。首先,我们构建了一个记忆库Q,用于存储从相邻帧和相对姿态中提取的上下文特征。请注意,记忆库中每个帧对应的特征都通过姿态变换映射到当前帧的坐标系中。在获取当前帧的BEV特征后,我们将这些特征与记忆库中存储的所有特征连接起来,并应用卷积层来减少通道维度,以节省计算资源。随后,使用一个SE块来促进交互,从而便于派生当前帧的时间融合特征。这些融合的特征随后被纳入记忆库,同时最早帧被移除以实现银行的必要更新。
规划解码器
规划解码器接收两个组件作为输入:第一个是BEV特征,它们简洁地模拟了当前环境的感知;第二个组件包括额外的结构化信息,主要包括三类:自车状态、环境信息和导航信息。自车状态信息包括当前时刻和历史时刻的速度,而环境信息包括有关高清地图、障碍物、交通灯和停车标志的结构化信息。通常,此类信息可以通过辅助任务模块由模型预测。然而,为了简化任务并专注于事故分析本身,本研究中相关数据直接由仿真环境提供。导航信息包括命令、目标点和路线。命令代表来自高层规划者的信息,如直行、右转、左转等。目标点指示目标的位置和方向,而路线是车道级别的密集导航点集合。BEV特征和结构化信息分别通过MLPs编码,然后连接以获得最终增强的特征,这为下游的行为规划提供了丰富且必要的指导。为了避免走捷径学习问题,在训练阶段我们采用dropout策略,即以一定概率随机掩蔽某些输入。在测试阶段,dropout率设置为0。遵循UniAD[21],我们使用基于查询的设计,使用自车查询与上述特征执行交叉注意力,最终获得自车的未来轨迹T。
实验
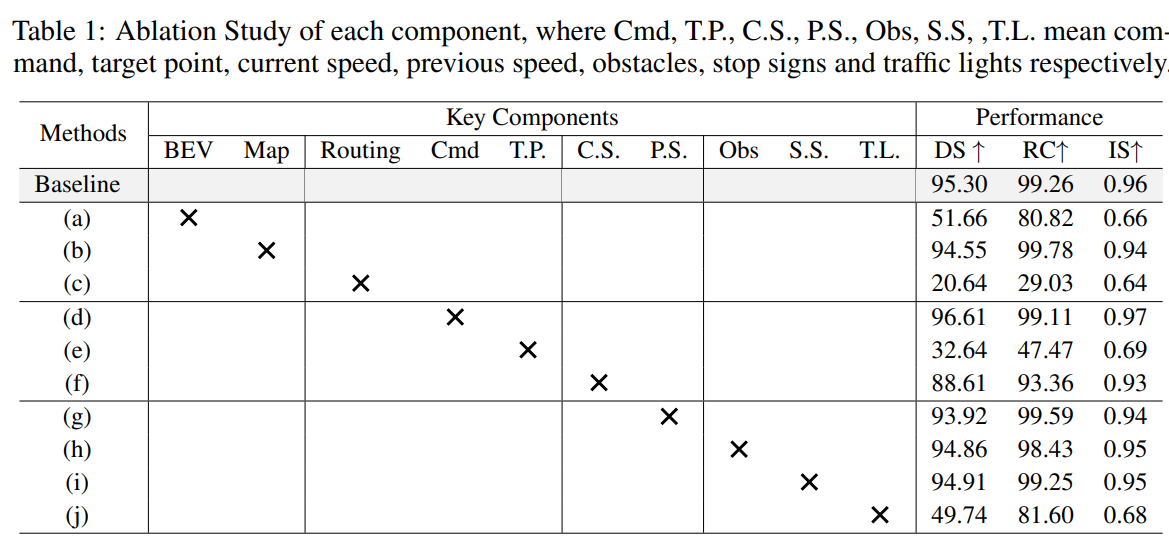
image

image
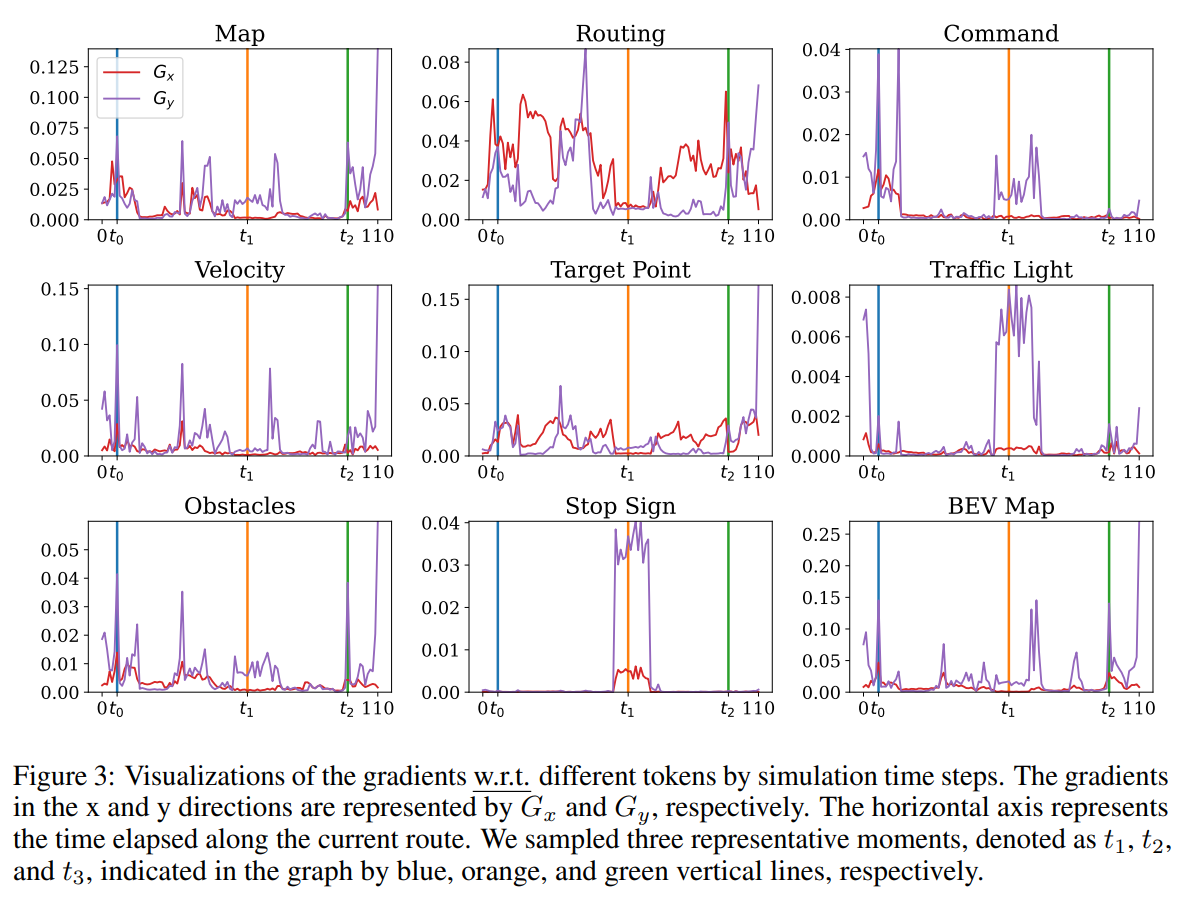
image

image

image

image
总结
在本文中,我们介绍了一种开创性的调试和分析解决方案,旨在通过明确阐释多因素决策的因果关系来揭开端到端自动驾驶的黑箱。我们的分析系统分为三个步骤:模块下降的定量分析、模块编辑的案例分析以及梯度响应值的可视化。我们使用流行的CARLA进行了大量的实验,以验证我们分析系统的可靠性。我们相信,这个系统可以作为端到端自动驾驶的基准,从而提高未来设计的可解释性和可靠性。
本文仅做学术分享,如有侵权,请联系删文!
更多优质内容,请关注公众号:智驾机器人技术前线















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









