







更多优质内容,请关注公众号:智驾机器人技术前线
简介
IEEE Transactions on Robotics King-Sun Fu Memorial Best Paper Award这个奖项是为了表彰每年在《IEEE Transactions on Robotics》上发表的最佳论文。
以下是该奖项的一些信息:
-
奖项描述:每年颁发给在《IEEE Transactions on Robotics》上发表的最佳论文。
-
设立年份:2004年
-
奖项:1,000美元和证书
-
资金来源:由IEEE Robotics and Automation Society资助
-
评审依据:技术优势、原创性、对领域的潜在影响、陈述的清晰度以及对应用的实际意义
-
颁奖时间:每年ICRA会议上公布并颁奖
2004年Best Paper
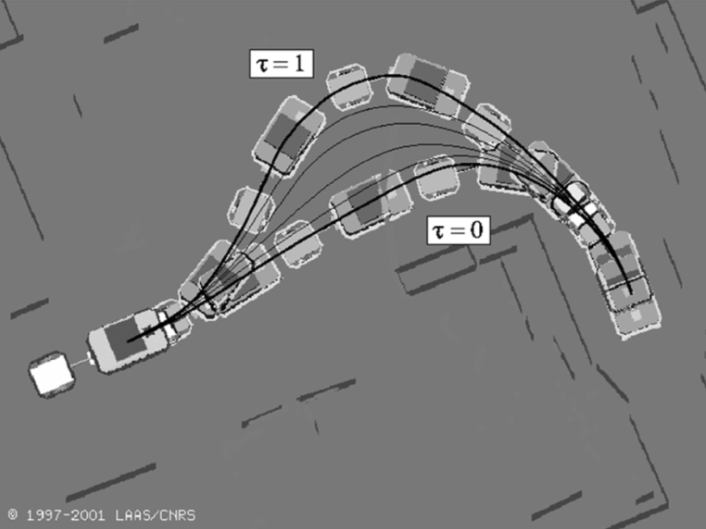
-
论文标题:Reactive Path Deformation for Nonholonomic Mobile Robots
-
作者:Florent Lamiraux, David Bonnafous, and Olivier Lefebvre
-
摘要
本文提出了一种新颖且通用的非完整系统路径优化方法。该方法应用于高度复杂环境中非完整移动机器人的响应式导航问题。对于机器人来说,已经给出了一条无碰撞的初始路径,但在跟随这条路径时检测到的障碍物可能会使其发生碰撞。当前路径会迭代地进行变形,以远离障碍物并满足非完整约束。该方法的核心思想是通过沿着当前路径扰动系统的输入函数来修改该路径,使优化准则减小。
2005年Best Paper
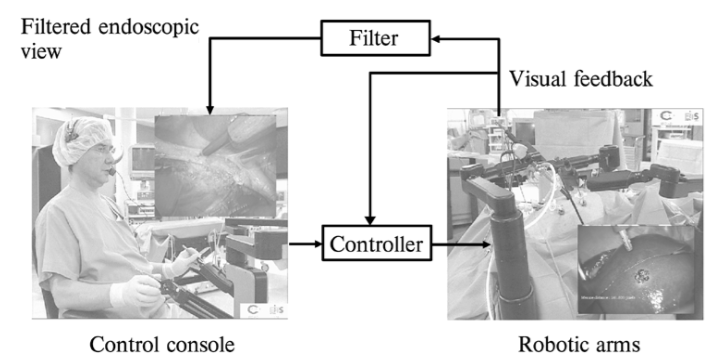
-
论文标题:Active Filtering of Physiological Motion in Robotized Surgery Using Predictive Control
-
作者:Romuald Ginhoux, Jacques Gangloff, Michel de Mathelin,Luc Soler, Mara M. Arenas Sanchez, Jacques Marescaux
-
摘要
本文提出了一种预测控制方法,用于机器人辅助手术中主动机械滤除由呼吸或心跳引起的器官复杂周期性运动。针对呼吸运动或心脏运动的补偿,提出了两种不同的预测控制方案。对于呼吸运动,扰动的周期性特性已被纳入受控系统的输入-输出模型中,使机器人系统能够学习并预测干扰运动。为无约束广义预测控制器(GPC)提出了一种新的成本函数,其中参考轨迹跟踪与可预测周期性运动的抑制被解耦。心脏运动更为复杂,因为它们是两个周期性非谐波分量的组合。提出了一种自适应干扰预测器,它输出未来的预测干扰值。这些预测值用于通过使用常规GPC的预测特性来预测干扰。在实验室测试台和活体猪上展示了实验结果。它们证明了两种提出方法补偿复杂生理运动的有效性。
2006年Best Paper
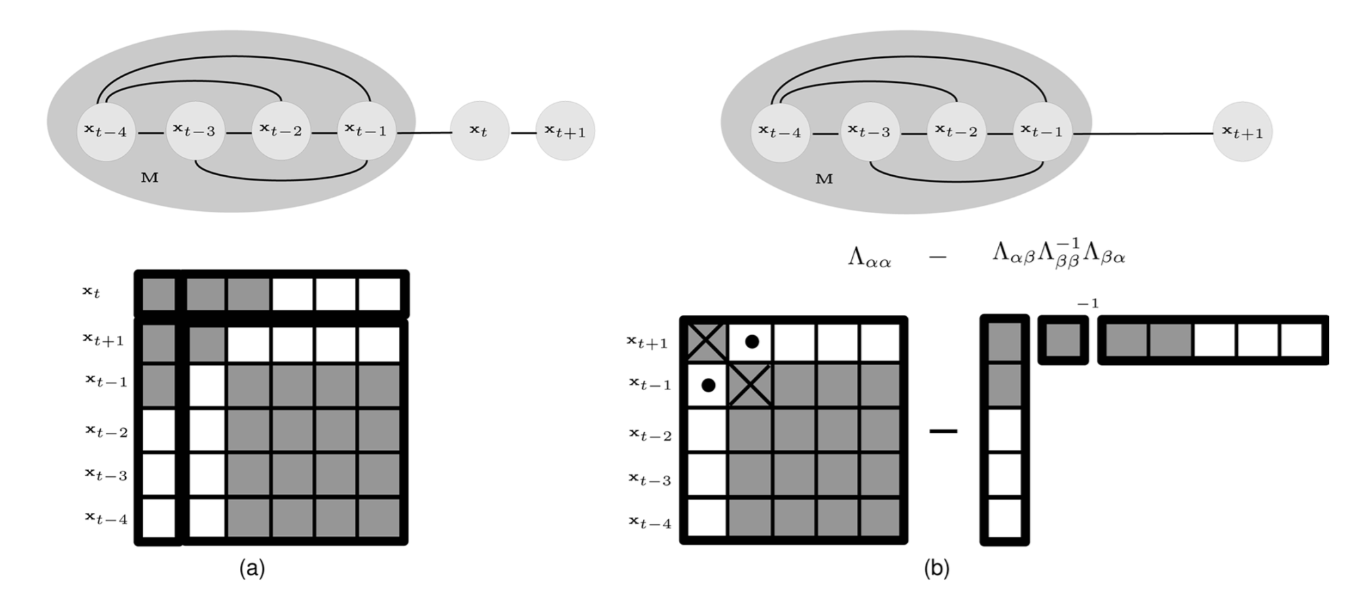
-
论文标题:Exactly Sparse Delayed-State Filters for View-Based SLAM
-
作者:Ryan M. Eustice, Hanumant Singh, John J. Leonard
-
摘要
本文报告了一个新的见解,即同时定位和建图(SLAM)信息矩阵在延迟状态框架中是完全稀疏的。这种框架用于基于视图的环境表示,该表示依赖于扫描匹配的原始传感器数据来获得机器人相对于其先前位置的运动的虚拟观测。延迟状态信息矩阵的精确稀疏性与其他最近基于特征的SLAM信息算法(如稀疏扩展信息滤波器或薄连接树滤波器)形成鲜明对比,因为这些方法必须进行近似,以迫使基于特征的SRAM信息矩阵稀疏。延迟状态框架的精确稀疏性的好处是,它允许人们利用信息空间参数化,而不会产生任何稀疏近似误差。因此,它可以产生与全协方差解等效的结果。该方法使用两个数据集的单目图像进行了实验验证:一个是具有地面实况的测试坦克实验,另一个是RMS泰坦尼克号的远程操作车辆调查。
2007年Best Paper
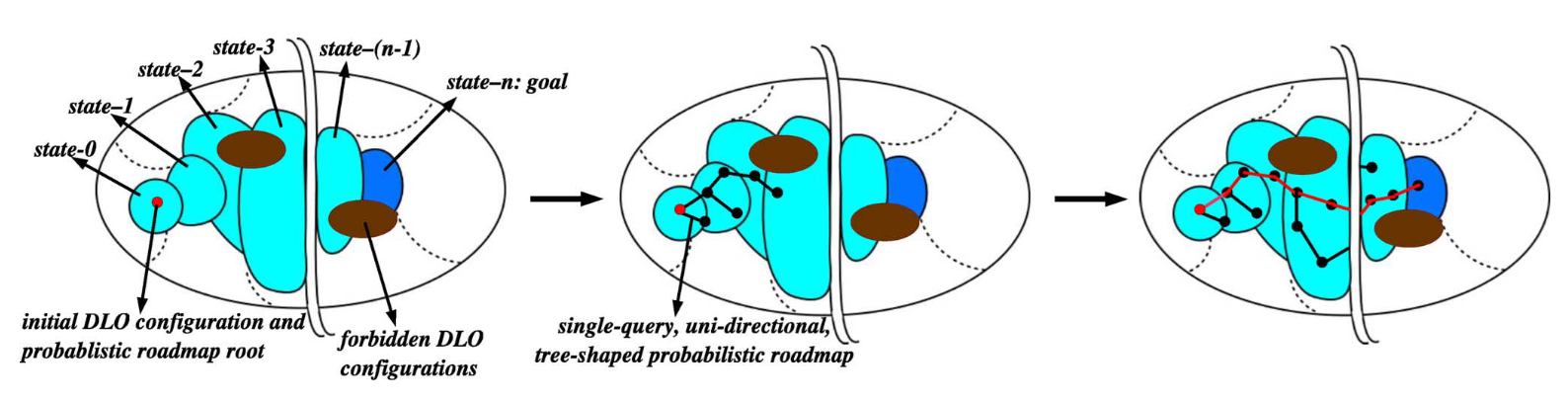
-
论文标题:Manipulation Planning for Deformable Linear Objects
-
作者:Mitul Saha, Pekka Isto
-
摘要
对机器人操控的研究主要集中于操纵刚性物体。然而,许多重要的应用领域需要操纵可变形物体,尤其是可变形线性物体(DLOs),如绳索、电缆和缝合线。这些物体的处理要复杂得多,因为它们可以表现出更多样化的行为,而且几乎不可避免地需要两个或更多的机器人手臂进行良好协调的动作。本文描述了一种新的运动规划器,用于操纵DLOs并打结(包括自结和围绕简单静态物体的结),使用两个合作的机器人手臂。该规划器融合了新的想法以及来自结理论、机器人运动规划和计算建模的现有概念和技术。与传统的运动规划问题不同,规划器要实现的目标是世界的一个拓扑状态,而不是几何状态。为了寻找操纵路径,规划器在DLO的构型空间中构建了一个拓扑偏差的概率路径图。在路径图构建过程中,它使用逆运动学来确定由DLO配置所暗示的连续机器人配置,并测试它们的可行性。此外,受到现实生活的启发,规划器使用静态的“针”(类比于编织中使用的针)来保持DLO在操纵过程中的稳定性,并使最终的操纵计划对DLO物理模型的不完善具有鲁棒性。实现的规划器已在图形模拟和双PUMA-560硬件平台上进行了测试,以实现各种结,如单套结、领结、蝴蝶结(鞋带)和帆结。
2008年Best Paper
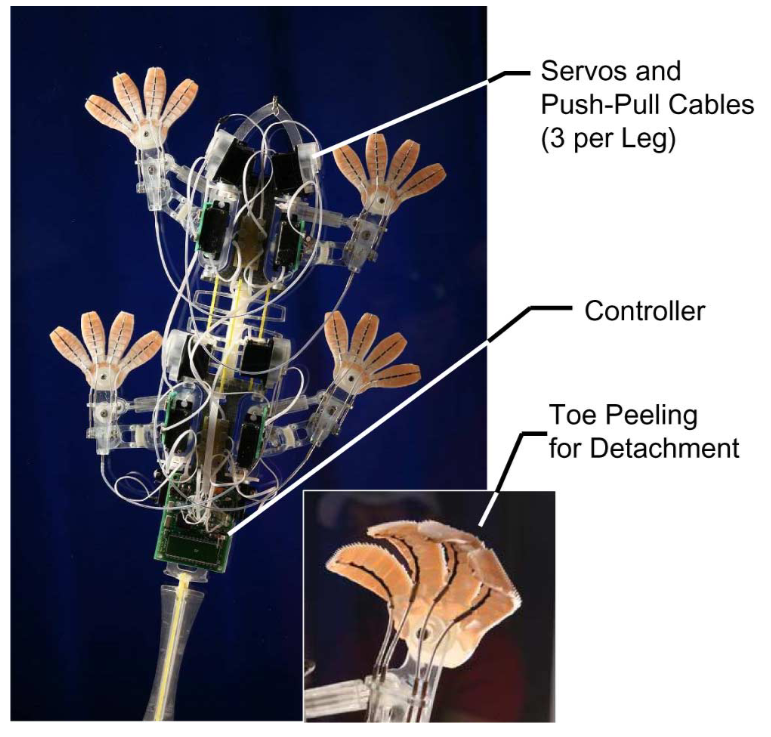
-
论文标题:Smooth Vertical Surface Climbing with Directional Adhesion
-
作者:Sangbae Kim, Matthew Spenko, Salomon Trujillo, Barrett Heyneman, Daniel Santos, Mark R. Cutkosky
-
摘要
Stickybot 是一种仿生机器人,能够在玻璃、塑料和陶瓷砖等光滑垂直表面上以每秒 4 厘米的速度攀爬。该机器人采用了几种从壁虎身上借鉴的设计原则,包括一系列顺应结构、定向粘附以及控制切向接触力以实现粘附控制。我们描述了用于创建欠驱动、多材料结构的设计和制造方法,这些结构能够适应从厘米到微米不同长度尺度的表面。在最精细的尺度上,Stickybot 脚趾的底部覆盖着小角度聚合物茎的阵列。像壁虎使用的定向粘附结构一样,当从脚趾尖向脚踝方向切向拉动时,它们很容易粘附;当朝相反方向拉动时,它们会释放。与顺应结构和定向粘附结合使用的是一种力控制策略,它平衡了脚部之间的力,并促进了脚趾的平滑附着和脱离。
2009年Best Paper
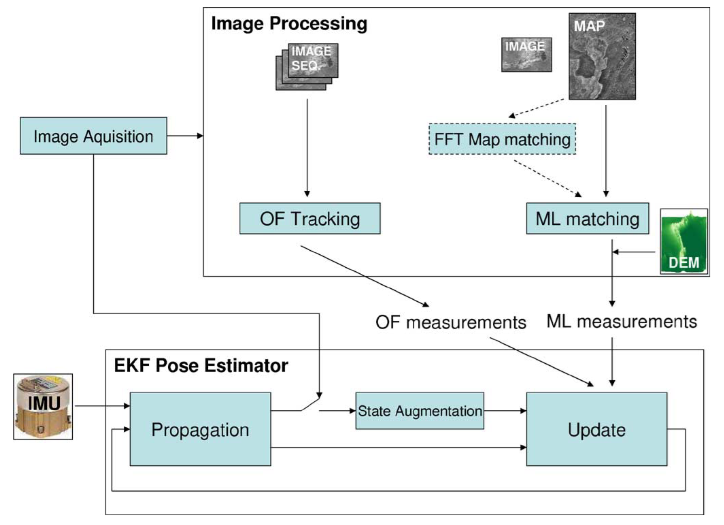
-
论文标题:Vision-Aided Inertial Navigation for Spacecraft Entry, Descent, and Landing
-
作者:Anastasios I. Mourikis, Nikolas Trawny, Stergios I. Roumeliotis, Andrew E. Johnson, Adnan Ansar, Larry Matthies
-
摘要
在本文中,我们介绍了一种名为VISINAV(视觉辅助惯性导航)算法,该算法能够实现精确的行星着陆。VISINAV系统的前端视觉部分提取了下降图像与表面地图之间的二维到三维对应关系,以及通过一系列下降图像的二维到二维特征轨迹。扩展卡尔曼滤波器(EKF)将这两种类型的视觉特征观测与惯性测量单元的测量紧密结合。该滤波器以资源自适应的方式计算着陆器相对于地形的位置、姿态和速度的精确估计,因此能够实时处理。除了对算法的技术分析外,本文还展示了来自探空火箭测试飞行的验证结果,显示在接触时速度估计误差仅为0.16米/秒,位置估计误差为6.4米。这些结果大大改进了当前没有视觉更新的终端下降导航的最新技术水平,并满足了未来行星探索任务的要求。
2010年Best Paper

-
论文标题:Design and Control of Concentric-Tube Robots
-
作者:Pierre E. Dupont, Jesse Lock, Brandon Itkowitz, Evan Butler
-
摘要
一种新颖的基于预弯弹性管的同心组合的机器人构建方法。通过管子之间的旋转和伸展,它们的曲率以弹性方式相互作用,以定位和定向机器人的尖端,以及控制机器人沿其长度的形状。在这种方法中,柔性管子既构成了机器人的连杆也构成了关节。由于执行器连接在管子的近端,机器人本身形成了一条细长的曲线,非常适合用于微创医疗程序。本文展示了这项技术的潜力。提出了设计原则,并推导出一个包含管子弯曲和扭转的通用运动学模型。还描述了使用此模型进行实时位置控制的实验演示。
2011年Best Paper
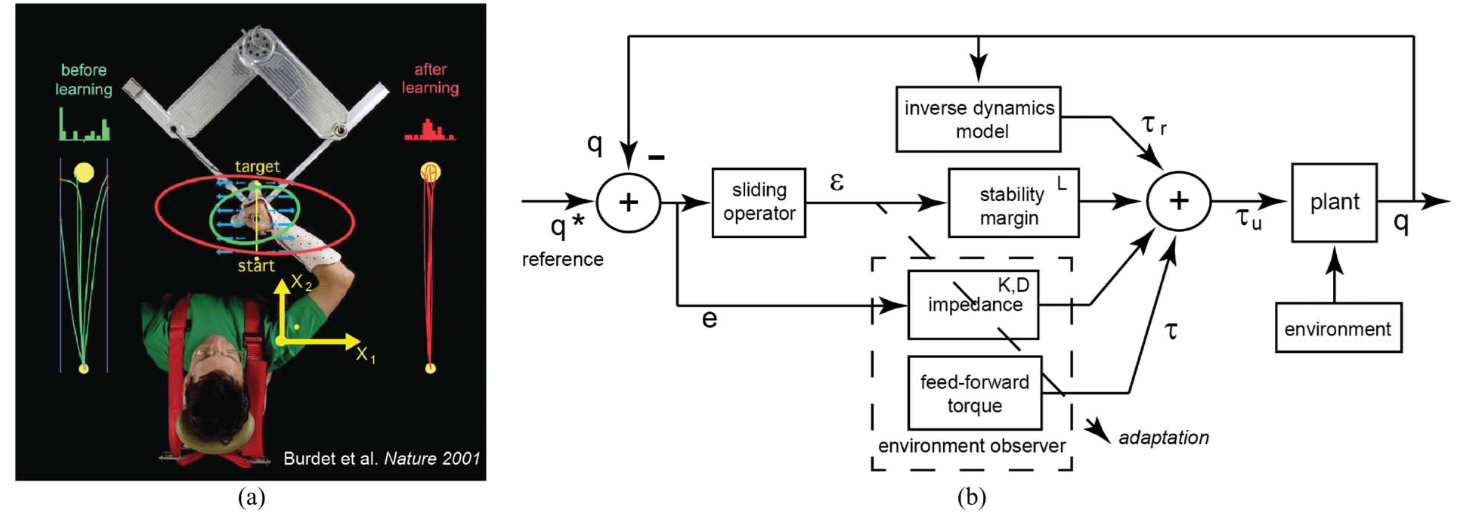
-
论文标题:Human-Like Adaptation of Force and Impedance in Stable and Unstable Interactions
-
作者:Chenguang Yang, Gowrishankar Ganesh, Sami Haddadin, Sven Parusel, Alin Albu-Schaeffer, Etienne Burdet
-
摘要
本文提出了一种新型的类人学习控制器,用于与未知环境进行交互。该控制器严格从最小化不稳定性、运动误差和effort中推导出来,通过适应前馈力和阻抗来补偿交互任务中环境中的干扰。与传统的学习控制器相比,这种新型控制器能够处理工具使用中典型的不稳定情况,并逐渐获得所需的稳定性裕度。模拟结果表明,这种控制器是人类运动适应的良好模型。机器人实现进一步展示了其在动态环境和人类中与关节扭矩控制机器人和可变阻抗执行器进行最优交互的能力,而无需交互力感测。
2012年Best Paper

-
论文标题:Reinforcement Learning With Sequences of Motion Primitives for Robust Manipulation
-
作者:Freek Stulp, Evangelos A. Theodorou, Stefan Schaal
-
摘要
物理接触事件通常允许将操纵任务自然分解为动作阶段和子目标。在运动基元范式中,每个动作阶段对应于一个运动基元,子目标对应于这些基元的目标参数。当前最先进的强化学习算法能够有效且稳健地优化非常高维问题中运动基元的参数。这些算法通常只考虑形状参数,这些参数决定了运动的起始点和终点之间的轨迹。然而,在操纵中,优化目标参数也至关重要,这些参数代表了运动基元之间的子目标。因此,我们扩展了路径积分(PI2)算法,以同时优化形状和目标参数。将同时形状和目标学习应用于运动基元序列,导致了新的算法PI2 SEQ。我们使用我们的方法来解决操纵中的一个基本挑战:提高日常拿起和放置任务的鲁棒性。
2013年Best Paper

-
论文标题:Robots Driven by Compliant Actuators: Optimal Control Under Actuation Constraints
-
作者:David J. Braun, Florian Petit, Felix Huber, Sami Haddadin, Patrick van der Smagt, Alin Albu-Schäffer, Sethu Vijayakumar
-
摘要
旨在接近人类敏捷性和效率表现的人形机器人通常在运动学和驱动方面都具有高度冗余。用于驱动这些设备的可变阻抗执行器能够同时、连续且独立地调节扭矩和阻抗(刚度和/或阻尼)。然而,这些执行器是非线性的,并且提出了许多约束,例如动态的范围内、速率和努力限制。对于这种冗余、非线性和受约束的系统,找到一种利用柔顺执行器内在动力学和能力的控制策略并非易事。在本研究中,我们提出了一个框架,用于优化扭矩和阻抗配置文件,以最大化任务性能,该框架针对复杂的硬件进行了调整,并结合了现实世界执行器的约束。模拟研究和硬件实验1) 展示了阻抗控制期间的驱动约束的影响,2) 展示了当前框架在现实世界执行器施加的约束下,同时进行扭矩和时间刚度优化的适用性,以及3) 在实验条件下验证了所提出方法的益处。
2014年Best Paper
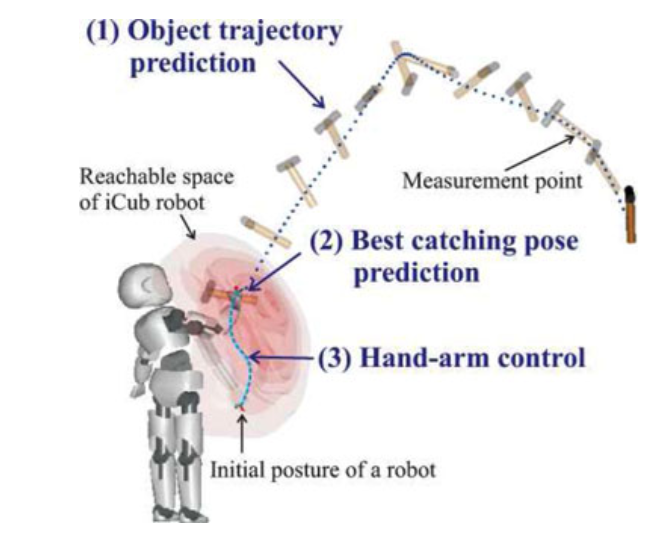
-
论文标题:Catching Objects in Flight
-
作者:Seungsu Kim, Ashwini Shukla, Aude Billard
-
摘要
我们解决了捕捉飞行中形状不规则物体的难题。这需要解决三个复杂问题:准确预测快速移动物体的轨迹、预测可行的捕捉配置以及规划手臂运动,所有这些都必须在毫秒级时间内完成。我们采用示范编程方法,通过投掷示例学习物体动力学和手臂运动的模型。我们提出了一种新的方法,以概率方式找到可行的捕捉配置。我们使用动态系统方法来编码多个示范中的运动。这使得在传感器不确定性存在的情况下,能够快速且反应灵敏地适应手臂运动。我们在模拟中使用iCub人形机器人,以及在现实世界实验中使用KUKA LWR 4+(7自由度手臂机器人)来捕捉锤子、网球拍、空瓶、部分装满的瓶子和纸板箱,以此验证了这种方法。
参考资料
https://www.ieee-ras.org/awards-recognition/publications-awards?view=article&id=70:ieee-transactions-on-robotics-king-sun-fu-memorial-best-paper-award&catid=69:society-awards

















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









