







 本文深入介绍了面向数据设计(DOD)的概念,对比了DOD与面向对象编程(OOP)的差异。Unity的DOTS技术栈利用DOD实现高性能,包括Job System、Burst Compiler和Entity Component System。通过示例,文章阐述了缓存友好的内存布局、并行化和编译器优化的重要性,强调了数据访问模式对性能的影响。面向数据设计对于优化游戏引擎性能,尤其是在大规模场景中的应用,具有显著优势。
本文深入介绍了面向数据设计(DOD)的概念,对比了DOD与面向对象编程(OOP)的差异。Unity的DOTS技术栈利用DOD实现高性能,包括Job System、Burst Compiler和Entity Component System。通过示例,文章阐述了缓存友好的内存布局、并行化和编译器优化的重要性,强调了数据访问模式对性能的影响。面向数据设计对于优化游戏引擎性能,尤其是在大规模场景中的应用,具有显著优势。
上一章,我们安装了ECS套件,也进行了一些介绍,但是比较笼统。没有一些基础知识储备,很难开始编写代码。本章首先翻译和整理了部分Unity官方的DOTS知识,需要对面向数据有更深刻的认识。
DOD知识准备
要学习DOTS,你不能只是获取API文档并深入研究,当然API文档也很不健全和友好。
你必须了解:
面向数据设计的基本概念
Unity中的面向数据设计
因为篇幅问题,本章介绍面向数据设计的基本概念。
面向数据设计(DOD)与许多开发人员在其整个职业生涯中都在使用的面向对象编程(OOP) 相比是一个巨大的变化。这意味着 DOTS 的学习曲线可能很陡峭,并且有很多陷阱可能会阻止您获得您希望的性能优势。所以本学习笔记就是对这部分知识的总结和建议。
第一部分:了解面向数据的设计
1. 了解DOD
面向数据的设计(DOD) 是面向对象编程(OOP)的一种根本不同的方法,许多开发人员将其用作他们的主要(或唯一)编程范式。
面向对象编程(OOP)是将你的代码结构化成现实世界的事物类型的类。一个类的实例代表一个单一对象。通常数据部分都隐藏在私有变量中,有一些方法可以对数据进行操作。还有继承的对象来表现相似但是不同的对象,结果是这些单独的对象分散在整个内存中。OOP对人类来说是直观的理解,但是CPU执行效率并不高。
相比之下,DOD考虑的是数据,以及最好的在内存中构建数据,以便让CPU有效的访问。DOD封装的不是整个对象,而是将对象分解为组件,再将组件分组为数组,然后遍历数组进行数据计算和转换。DOD用例考虑的是组件,而不是对象。要成功的使用DOD,你要忘记封装、数据隐藏、继承、多态、引用类型,对你没帮助。
我们通过一个例子来看看OOP和DOD的区别,这是一个虚构游戏“沙滩球模拟器:特别版”的屏幕截图。玩家已经激活了一个能量提升来移动所有的绿球。

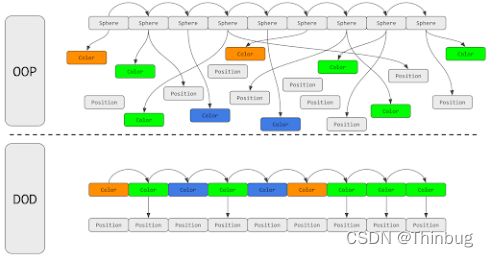
在OOP中,代码遍历检查每个类的颜色,并设置位置,虽然数组是连续的,但是内存数据量过大,导致CPU的Cache命中率过低。在DOD中,球体只有颜色和位置数据,同样容量存放的数据更多,这样就可以加大CPU的Cache命中率,从而加快处理速度。
2. Unity中的DOD
大约2018年Unity发布了Mega-City演示(更多其他DOTS资源),MegaCity大约包含了:
*4.5M Mesh renderers
200K Unique objects per building
100K Individual audio sources
5K Dynamic vehicles
60 FPS
要达到这种高性能,关键方面是:
1,缓存友好的内存布局(Cache friendly memory layout)
2,并行化(Parallelization)
3,编译器优化(Compiler optimization)
新的 Unity-Tech-Stack 包含几个新库。它们都是根据这些原则创建的。
- Job-System让您可以在多个 CPU 上并行工作,这在 Unity 之前是不可能的。
- Burst-Compiler使用LLVM 生成超快速矢量化代码。
- Entity-Component-System帮助您以缓存有效的方式存储和访问您的数据
- Collections-API让您可以直接访问非托管内存
- Math library 添加了新的向量类型,如float3,您已经从着色器语言中了解了这些类型,并使 Burst-compiler 能够向量化您的数学运算
接下来,我们将解释这3个关键方面来达到高性能。
1,缓存友好的内存布局(Cache friendly memory layout)
缓存未命中(Cache Misses)
DOD的设计就是要组织数据进行有效管理,目标是尽可能的命中缓存,以便尽可能快的为CPU提供数据。
CPU的运行速度非常快,以至于RAM和CPU寄存器(Registers)之间带宽和延迟通常是瓶颈因素,而不是CPU本身。这就是为什么CPU和RAM之间会建立多个缓存的原因。
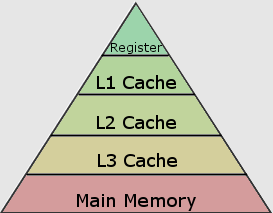
该图显示了一个金字塔,距离CPU寄存器越近内存就越小,访问速度也就越快。当CPU需要一个值,它首先从L1开始在缓存(Cache)中查找,如果它不在缓存中,就从内存中加载,这非常慢,下表显示了 Intel Core i7-8700K 的缓存大小。
| 缓存 | 尺寸 |
|---|---|
| L1 Cache(数据 Data) | 192 KB |
| L1 Cache(说明 Instructions) | 192 KB |
| L2 Cache | 1.5 MB |
| L3 Cache | 12 MB |
下表包含英特尔酷睿 i7-4770 的(近似)访问时间
| 操作 | CPU 周期 |
|---|---|
| 执行典型指令 | 1 |
| L1 | 4 |
| L2 | 12 |
| L3 | 36 |
| 从主存中获取 | 36 + ~100 纳秒 |
正如您所看到的,数据离 CPU 越远,将数据加载到寄存器中所需的时间就越长。为了避免那些较长的加载时间,要尽可能避免缓存未命中。因此,您需要了解如何访问缓存。
缓存行(Cache Lines)
今天的 CPU 不会逐字节访问内存。相反,它们以(通常)64 字节的块(称为高速缓存行)获取内存。例如,如果您遍历一个整数数组,则会同时加载 8 个整数值(64 字节缓存行大小/每个整数 4 字节 = 8)。这可以防止每次读取值时缓存未命中。此外,高速缓存也足够智能,可以根据指令预取所需的前一个或下一个高速缓存行。因此,您的访问模式越可预测,性能就会越好。
结构(Struct)与类(Class)的数据布局
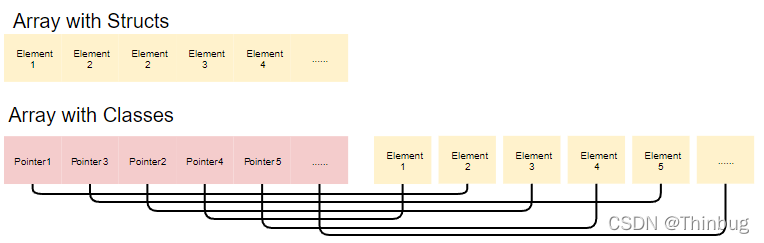
结构体数组或者原始类型数组(例如int[]),因为结构大小在编译时是已知的,所以可以连续打包到内存,这不适用于类的数组,由于类的多态性,每个元素可以有不同大小,所以无法连续打包。只有指针指向随机位置,具体取决于什么时候new的,而不是创建数组的时间。
我们编写一个例子测试:
using System.Collections;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using UnityEngine;
public struct StructA
{
public float f;
}
public class ClassA
{
public float f;
}
//UTF8 说明
public class CTest : MonoBehaviour
{
int allnum = 10000000;
int[] nolist;
int[] nolistRandom;
// Start is called before the first frame update
void Start()
{
nolist = new int[allnum];
for (int i = 0; i < allnum; i++)
{
nolist[i] = i;
}
nolistRandom = new int[allnum];
for (int i = 0; i < allnum; i++)
{
nolistRandom[i] = i;
}
}
// Update is called once per frame
private void OnEnable()
{
test();
}
void test()
{
//首先模拟内存分布数据
StructA[] alist = new StructA[allnum];
for (int i = 0; i < allnum; i++)
{
alist[i].f = i;
}
ClassA[] blist = new ClassA[allnum];
for (int i = 0; i < allnum; i++)
{
blist[i] = new ClassA();
blist[i].f = i;
}
ClassA[] clist = new ClassA[allnum];
for (int i = 0; i < allnum; i++)
{
clist[i] = new ClassA();
clist[i].f = i;
}
clist = clist.OrderBy(x => Random.value).ToArray();
var stopwatch = new Stopwatch();
System.GC.Collect();
stopwatch.Reset();
stopwatch.Start();
for (int i = 0; i < allnum; i++)
{
alist[i].f += Random.value;
}
stopwatch.Stop();
UnityEngine.Debug.Log("struct : " + (stopwatch.ElapsedTicks / 1000).ToString("F2"));
System.GC.Collect();
stopwatch.Reset();
stopwatch.Start();
for (int i = 0; i < allnum; i++)
{
blist[i].f += Random.value;
}
stopwatch.Stop();
UnityEngine.Debug.Log("Class A : " + (stopwatch.ElapsedTicks / 1000).ToString("F2"));
System.GC.Collect();
stopwatch.Reset();
stopwatch.Start();
for (int i = 0; i < allnum; i++)
{
clist[i].f += Random.value;
}
stopwatch.Stop();
UnityEngine.Debug.Log("Class B : " + (stopwatch.ElapsedTicks / 1000).ToString("F2"));
}
}
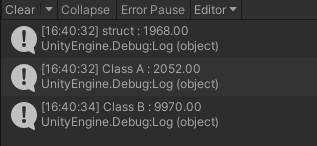
测试中每个类型对象数组创建了1000万个对象,数组每组大小40M。我们先创建好,然后用相同的赋值操作进行赋值进行比对。
struct是按顺序的,ClassA也是顺序的,ClassB是打乱的。
结果中看到struct是最快的,classA稍微多一点,classB就多了5倍左右。这个测试中,我们迭代了每个元素按照顺序的完整数据。
请记住:如果您测试缓存未命中,许多外部环境(如操作系统、线程和其他进程)会伪造您的测试结果,因为它们也使用缓存。
选择性数据访问
在许多用例中,您不需要访问整个数据,而只需要访问其中的一部分。常见的用例是:
- 你有很大的游戏世界,你只想处理当前可见的实体
- 您只想在整个网格的一部分上进行操作
- 您只想处理用户选择的实体
- 您将数据切成块,只想访问一个
正如我们在上面的测试中看到的,按顺序排列数据以避免随机访问非常重要。在某些用例中,这是不可能的。下一个示例将测试不同的访问模式如何影响缓存未命中。
int[] steps = new[] {1, 2, 4, 8, 16, 32, 64, 128, 256}
for (int k = 0; k < steps.Length; k++)
{
int stepSize = steps[k];
int[] arr = new int[32* 1024 * 1024];
for (int i = 0; i < arr.Length; i += stepSize )
{
arr[i] *= 3;
}
}
// This code is a little bit simplified. With bigger step sizes,
// less samples on the array are done, but you can find the
// full source of all experiments in the Appendix.
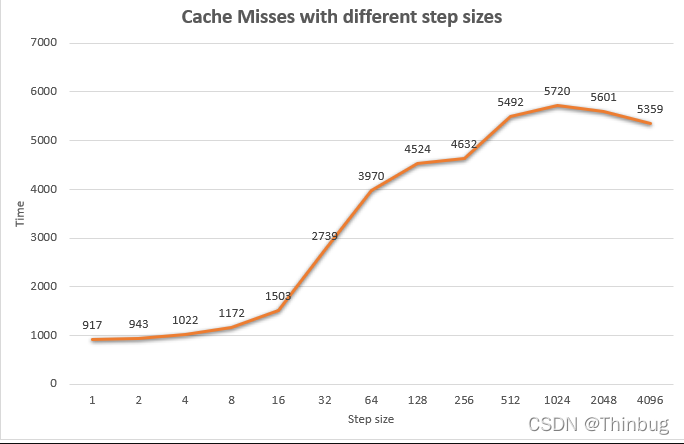
正如您所看到的,步长越大,即使完成相同数量的计算,运行时间就越长。进一步增加步长意味着完全随机访问您的内存。有趣的是步长 16 和 32 之间的图形跳转。这里超出了缓存行大小(16 * 4 字节 = 64 字节)。步长为 32 时,每次数据访问相当于缓存未命中,运行时间几乎翻了一番,从 1503 到 2739。
这也是如果你创建一个二维矩阵,它的行主要遍历将比它的列主要遍历更快的原因。一行存储在连续的内存位置中,因此在高速缓存行中被提取。
面向对象与面向数据的数据布局
这个示例中,展示了与面向数据相比,数据如何以面向对象的方式存储。
// The struct defines a sphere in a object oriented way
public struct ObjectOrientedSphere {
Vector3 position;
Color color;
double radius;
};
ObjectOrientedSphere[] objectOrientedSpheres;
// The class defines several spheres in a data oriented way. The data is tightly packed into arrays
public class DataOrientedSphere {
Vector3[] position;
Color[] color;
double[] radius;
};
// Assume you have a list of ObjectOrientedSpheres that you want to move
// every frame by 1
public void MoveObjectOriented(ObjectOrientedSphere[] spheres)
{
for (int i=0; i<spheres.Length; i++)
{
spheres[i].position += 1;
}
}
// This code does the same for the DataOrientedSphere
public void MoveDataOriented(DataOrientedSphere spheres)
{
Point[] positions = spheres.position;
for (int i=0; i<positions.Length; i++)
{
positions[i] += 1;
}
}
该示例以两种不同的方式定义球体。ObjectOrientedSphere 的定义与您对日常程序员生活的期望一样。结构或类包含对象工作所需的所有数据。DataOrientedSphere 以可以更有效地访问数据的方式定义数据,只需创建一个对象并存储每个值的数据,而不是为每个对象存储数据。这里重要的一点是,如果知道需要访问不带颜色和半径的位置数据,则应该将它们彼此分开。
上面的代码中,一个球体大小是24字节,下面的测试就是更改球体大小(通过增加其他属性),那么按顺序进行Move移动球,会发生什么呢?
例如64字节大小的球是:
public struct ObjectOrientedSphere64
{
public float Position;
public Vector3 Blocker1;
public Vector4 Blocker2;
public Vector4 Blocker3;
public Vector4 Blocker4;
}
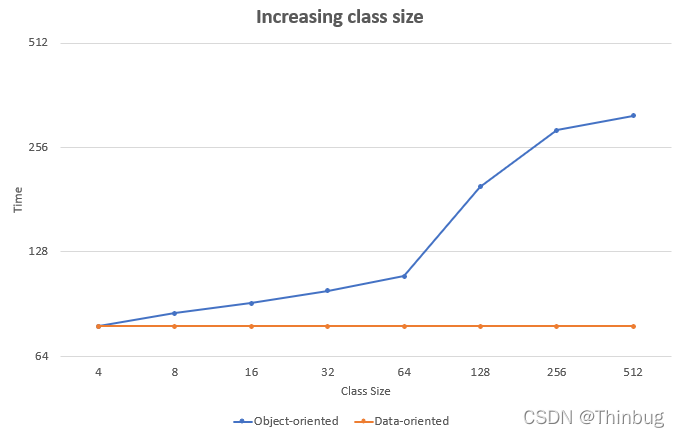
该图表显示,当您更改面向数据的球体的大小时(遍历的数组长度没有变化),性能保持不变。原因很明显,因为其他数据(颜色和半径)存储在完全独立的内存区域的其他数组中。相比之下,面向对象的领域变得越来越慢。在遍历数组时,会产生越来越多的缓存未命中。有趣的是,当您超过 64 字节的高速缓存行大小时,再次看到强烈的性能损失。
| 对象大小 | 面向对象 (µs) | 面向数据 (µs) | 比率 |
|---|---|---|---|
| 64 | 109 | 78 | 1,4 |
| 128 | 197 | 78 | 2,53 |
访问大小为 128 字节的对象几乎是访问大小为 64 字节的对象的两倍。面向对象的运行时间没有比现在差的原因是 CPU 非常擅长预测您接下来可能需要哪些数据。
如果对象变得越来越大,以面向对象的方式存储数据可以将性能降低多达 6 倍。
在前面的示例中,使用了 32 MB 的数组大小。让我们看看不同的数组大小是否会影响结果。
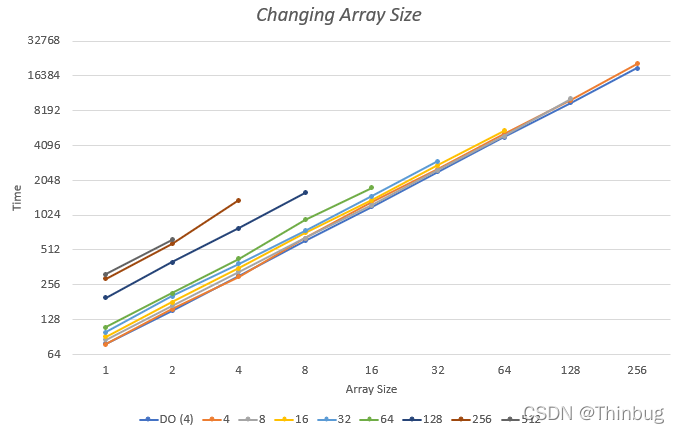
在垂直轴上标记了数组大小。该测试针对面向数据的球体(标记为 DO 4)和不同大小的面向对象的球体(标记为 4 – 512)运行。两个轴都是对数的。如您所见,所有数组大小和类大小的性能都保持线性。
缓存失效
当数据进入两个不同的缓存位置时会发生什么。例如,变量 float a 可能在CPU核心 1 和核心 2 的 L1 缓存中。当您更新该变量时会发生什么?
这种情况被称为数据竞争。当多个线程同时访问内存中的一个位置并且至少有一个线程打算改变该值时,就会发生这种情况。对我们来说幸运的是,CPU 可以解决这个问题。每当写入指向缓存中的内存位置时,内核对该内存位置的所有缓存引用都将失效。其他内核必须再次从主存储器加载该数据。但是,由于数据总是加载到缓存行中,因此整个缓存行无效,而不仅仅是更改的值。
这给多线程系统带来了新的问题。当两个或多个线程尝试同时修改属于同一缓存行的字节时,大部分时间都浪费在使缓存无效并再次从主内存中读取更新的字节上。这种效应称为虚假共享。
与关系数据库的关联
面向数据设计背后的思想与您对关系数据库的看法非常相似。优化关系数据库还可以更有效地使用缓存,尽管在这种情况下我们处理的不是 CPU 缓存而是内存页面。一个好的数据库设计人员也可能会将不经常访问的数据拆分到一个单独的表中,而不是创建一个包含大量列的表,因为只有少数列被使用过。
结论
对主存储器的随机访问比顺序访问慢大约 6 倍。
今天到这里了,下一章分享Unity中的面向数据设计。
引用:
面向数据的设计



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











