







- 题目:Flexible and Efficient QoS Provisioning in AXI4-Based Network-on-Chip Architecture
- 时间:2022
- 期刊:TCAD
- 研究机构:KTH瑞典皇家理工学院
1 缩写
- TDM: Time-Division Multiplexing
- NI: Network Interface
- VC: Virtual Channel
2 参考文献
2 Introduction
本篇论文的主要贡献:
- 在NI中设计了AXI4信号格式和NoC数据包格式之间的数据转换,使得NoC设计独立于AXI4协议。
- 我们定义了三种不同的QoS服务,并设计了一个基于片上网络的通信架构
- 我们在每个NI中提出了一个流量转换器单元,智能地将数据包从一个拥塞严重的子网分发到另一个拥塞较少的子网,从而提高NoC性能。
- 我们在VC子网中提出了三种不同的流量控制机制,并在实验部分比较了它们在数据包延迟方面的性能结果。
- 我们建立了一个周期精确的模拟器来模拟我们提出的系统的行为。我们从系统吞吐量、数据包传输延迟和排队延迟方面展示了性能评估结果。
- 在模拟器中,我们提出了一个基于两级马尔可夫模型进程(MMP)的流量生成器,用于更好地模拟节点中的实际进程/线程。在我们的实验中报告了流量生成结果。
3 Background
Industrial Designs for AXI4-Based QoS 当然,这些组件都没有详细的架构细节
- Xilinx: 基于AXI QoS信号控制优先级
- Synopsys: 有QoS regulator和QoS arbiter,如果流量大于期望的速率,QoS regulator可以限制流量,QoS arbiter优先服务高优先级请求
- Intel / Altera: end-to-end flow controller, arbiter, bandwidth regulator
AXI4 ordering
AXI消息请求发生在主节点和从节点,由于NoC无序传输,所以在master端和slave端需要ordering unit,这样router, switch和traffic converter都不需要考虑排序问题;当然也要避免死锁问题
QoS请求
- Latency Critical Service (LCS): 类似CPU,需要保证低延时传输,但对带宽不需要保证
- Guaranteed Rate Service (GRS): 类似GPU,可以容忍延时,但要保证带宽
- Unspecified Rate Service (URS): 类似SATA和USB,不保证带宽和延时,只是尽可能的传输数据
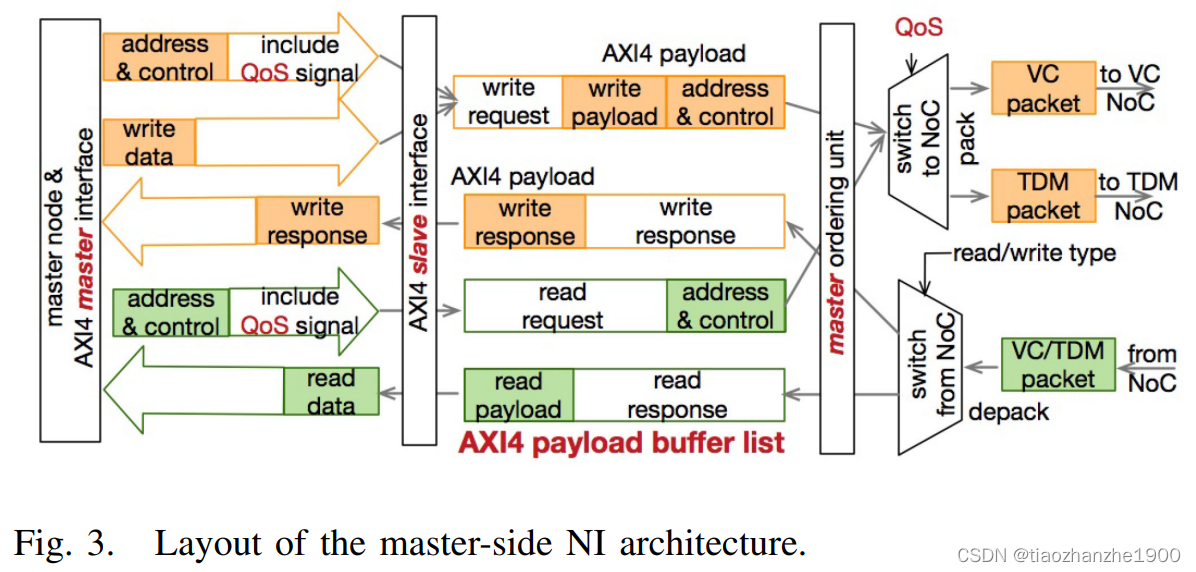
4 System Design
**Message Format Conversion: ** 有两种思路
- AXI有5个通道,那我在NoC中也设置5个通道,当然这样利用率会很低
- 将AXI信号转换成读请求、响应包、写请求等,由共享的NoC资源传输
所以NI的功能包括
- 接受并处理AXI各通道以及NoC的信号
- 将数据格式从AXI转换成NoC packet
- slave端的NI将请求的包的QoS继承给相应的包,使QoS方案可以往返传输
- 题目:FlooNoC: A Multi-Tb/s Wide NoC for Heterogeneous AXI4 Traffic
- 时间:2023
- 期刊:IEEE Design & Test
- 研究机构:ETH
这篇论文关注了基于NoC的AXI的排序问题,AXI是支持乱序响应的,但同一个ID的需要按顺序返回,NoC要支持的话需要增加排序单元/状态管理单元,会增加硬件开销,也会有扩展性的问题
The logic required to track outstanding transactions and adhere to the ordering constraints increases exponentially in complexity with the network diameter.
The AXI4 protocol specification [12] requires that transactions with the same ID are always
returned in order.
Furthermore, as the ID is also used for routing a response, the protocol requires that the ID width must increase at each interconnection (hop) to retain the uniqueness of the transactions and their IDs.
This presents a major challenge when scaling up AXI4 to large and complex systems with many hops between the initiator and targets, as state information is required for each ID for ordering while the number of possible IDs is growing.
这里的解决方法是,假设NoC采用确定性路由,那么同一个地址的传输肯定是按顺序响应的,同时在NI增加reorder buffer和reorder table

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









