







在上一篇文章中,我们通过改进U-Net的代码实现了去噪扩散概率模型,但是似乎图像还是不太清晰,有棋盘格伪影问题,这一篇文章我们就来做一些优化。
文章目录
1 棋盘格伪影问题(Checkerboard Problem)
Checkerboard Problem指的是在图像生成任务中,由于反卷积或上采样方式不当,导致输出图像中出现棋盘格状的伪影(checkerboard artifacts)。这些伪影并不是原图真实内容的一部分,而是网络结构(特别是上采样部分)带来的副作用。如下图所示:
这是上一篇文章中随机噪声被模型上采样处理后的图像片段,棋盘格伪影问题增加了不相关的图案结构,使模型难以专注于关键特征。
为什么会出现棋盘格状伪影?
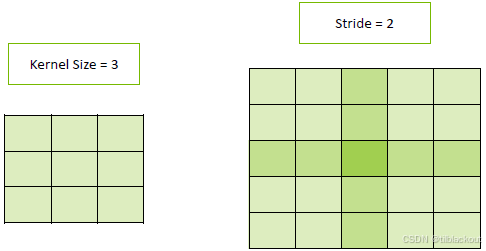
在上图中,左侧显示的是一个 Kernel Size = 3 的卷积核,右侧展示的是将该卷积核应用于某个特征图的过程,其中 Stride = 2,即每次卷积操作移动两个像素。
当使用步幅大于 1 的转置卷积(或标准卷积)进行上采样时,并不是所有输出像素位置都被均匀覆盖或更新。这是因为:
- 卷积核每次跳跃两个位置,意味着中间的像素位置会被跳过;
- 被覆盖的位置(图中较深绿色方格)会受到卷积核多次作用,因此更新值较多;
- 没有被覆盖或仅被部分覆盖的位置(浅绿色区域),则更新次数少甚至完全没有更新;
- 这种“非均匀更新”会造成某些区域比其他区域更亮或更暗,形成周期性的强弱纹理对比。
最终,这种“更新不均”的现象在图像中就表现为棋盘格状的纹理。想象你在画一张画,每次拿一块印章盖色块,stride = 2 就意味着你每次跳两个格子才盖一次,中间的格子就可能永远没被盖或者只被边缘蹭到一点,这样整体图案就不均匀了。
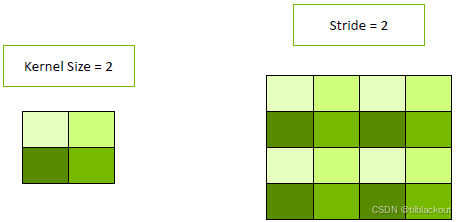
上图显示了 kernel size = 2 且 stride = 2 的情况,更容易出现 checkerboard。因为每个输出像素来自于固定的 kernel 区域,步幅越大、不重叠区域越多,越容易出现断层或棋盘格。
总结
Kernel size 与 stride 配置不当,会导致卷积核不能均匀覆盖整个输出特征图,从而造成某些像素更新频繁、某些更新稀疏的现象,进而在输出图像中引入周期性的强弱纹理 —— 这就是所谓的棋盘格伪影。
所以这篇文章,我们将做一些优化,包括:
- 实现 Group Normalization(组归一化)
- 实现 GELU(高斯误差线性单元)
- 实现 Rearrange Pooling(重排池化)
- 实现 Sinusoidal Position Embeddings(正弦位置编码)
- 定义一个反向扩散函数来模拟
p - 再次尝试生成服装图像
2 优化
就像之前一样,让我们使用 FashionMNIST 来进行实验:
# 导入 PyTorch 库
import torch
# 导入神经网络模块
import torch.nn as nn
# 导入功能性操作函数(如激活函数等)
import torch.nn.functional as F
# 导入自动求导模块
from torch.autograd import Variable
# 导入优化器 Adam
from torch.optim import Adam
# 可视化工具
# 导入绘图模块 matplotlib
import matplotlib.pyplot as plt
# 用于绘制模型结构图
from torchview import draw_graph
# 用于图形展示
import graphviz
# 用于在 Jupyter 中显示图片
from IPython.display import Image
# 用户自定义的工具库
# 导入其他工具函数
from utils import other_utils
# 导入 DDPM 相关的工具函数
from utils import ddpm_utils
# 设置图像大小
IMG_SIZE = 16
# 图像通道数(灰度图像)
IMG_CH = 1
# 每批训练样本数量
BATCH_SIZE = 128
# 加载预处理过的 FashionMNIST 数据
data, dataloader = other_utils.load_transformed_fashionMNIST(IMG_SIZE, BATCH_SIZE)
# 判断是否使用 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
基于上一篇文章的内容,我们创建了一个 ddpm_util.py 文件,其中包含一个 DDPM 类,用来封装我们的扩散函数。现在我们使用它来设置和之前一样的 β时间调度策略。文件代码如下:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from utils import other_utils
class DDPM:
def __init__(self, B, device):
self.B = B
self.T = len(B)
self.device = device
# Forward diffusion variables
self.a = 1.0 - self.B
self.a_bar = torch.cumprod(self.a, dim=0)
self.sqrt_a_bar = torch.sqrt(self.a_bar) # Mean Coefficient
self.sqrt_one_minus_a_bar = torch.sqrt(1 - self.a_bar) # St. Dev. Coefficient
# Reverse diffusion variables
self.sqrt_a_inv = torch.sqrt(1 / self.a)
self.pred_noise_coeff = (1 - self.a) / torch.sqrt(1 - self.a_bar)
def q(self, x_0, t):
"""
The forward diffusion process
Returns the noise applied to an image at timestep t
x_0: the original image
t: timestep
"""
t = t.int()
noise = torch.randn_like(x_0)
sqrt_a_bar_t = self.sqrt_a_bar[t, None, None, None]
sqrt_one_minus_a_bar_t = self.sqrt_one_minus_a_bar[t, None, None, None]
x_t = sqrt_a_bar_t * x_0 + sqrt_one_minus_a_bar_t * noise
return x_t, noise
def get_loss(self, model, x_0, t, *model_args):
x_noisy, noise = self.q(x_0, t)
noise_pred = model(x_noisy, t, *model_args)
return F.mse_loss(noise, noise_pred)
@torch.no_grad()
def reverse_q(self, x_t, t, e_t):
"""
The reverse diffusion process
Returns the an image with the noise from time t removed and time t-1 added.
model: the model used to remove the noise
x_t: the noisy image at time t
t: timestep
model_args: additional arguments to pass to the model
"""
t = t.int()
pred_noise_coeff_t = self.pred_noise_coeff[t]
sqrt_a_inv_t = self.sqrt_a_inv[t]
u_t = sqrt_a_inv_t * (x_t - pred_noise_coeff_t * e_t)
if t[0] == 0: # All t values should be the same
return u_t # Reverse diffusion complete!
else:
B_t = self.B[t - 1] # Apply noise from the previos timestep
new_noise = torch.randn_like(x_t)
return u_t + torch.sqrt(B_t) * new_noise
@torch.no_grad()
def sample_images(self, model, img_ch, img_size, ncols, *model_args, axis_on=False):
# Noise to generate images from
x_t = torch.randn((1, img_ch, img_size, img_size), device=self.device)
plt.figure(figsize=(8, 8))
hidden_rows = self.T / ncols
plot_number = 1
# Go from T to 0 removing and adding noise until t = 0
for i in range(0, self.T)[::-1]:
t = torch.full((1,), i, device=self.device).float()
e_t = model(x_t, t, *model_args) # Predicted noise
x_t = self.reverse_q(x_t, t, e_t)
if i % hidden_rows == 0:
ax = plt.subplot(1, ncols+1, plot_number)
if not axis_on:
ax.axis('off')
other_utils.show_tensor_image(x_t.detach().cpu())
plot_number += 1
plt.show()
# For use in notebook 05
@torch.no_grad()
def sample_w(
model, ddpm, input_size, T, c, device, w_tests=None, store_freq=10
):
if w_tests is None:
w_tests = [-2.0, -1.0, -0.5, 0.0, 0.5, 1.0, 2.0]
# Preprase "grid of samples" with w for rows and c for columns
n_samples = len(w_tests) * len(c)
# One w for each c
w = torch.tensor(w_tests).float().repeat_interleave(len(c))
w = w[:, None, None, None].to(device) # Make w broadcastable
x_t = torch.randn(n_samples, *input_size).to(device)
# One c for each w
c = c.repeat(len(w_tests), 1)
# Double the batch
c = c.repeat(2, 1)
# Don't drop context at test time
c_mask = torch.ones_like(c).to(device)
c_mask[n_samples:] = 0.0
x_t_store = []
for i in range(0, T)[::-1]:
# Duplicate t for each sample
t = torch.tensor([i]).to(device)
t = t.repeat(n_samples, 1, 1, 1)
# Double the batch
x_t = x_t.repeat(2, 1, 1, 1)
t = t.repeat(2, 1, 1, 1)
# Find weighted noise
e_t = model(x_t, t, c, c_mask)
e_t_keep_c = e_t[:n_samples]
e_t_drop_c = e_t[n_samples:]
e_t = (1 + w) * e_t_keep_c - w * e_t_drop_c
# Deduplicate batch for reverse diffusion
x_t = x_t[:n_samples]
t = t[:n_samples]
x_t = ddpm.reverse_q(x_t, t, e_t)
# Store values for animation
if i % store_freq == 0 or i == T or i < 10:
x_t_store.append(x_t)
x_t_store = torch.stack(x_t_store)
return x_t, x_t_store
现在我们创建一个DDPM对象:
# 设置每行图像显示数量
nrows = 10
# 设置每列图像显示数量
ncols = 15
# 计算时间步数 T,总共的扩散步骤数量
T = nrows * ncols
# 设置 Beta 开始值
B_start = 0.0001
# 设置 Beta 结束值
B_end = 0.02
# 生成线性变化的 Beta 序列
B = torch.linspace(B_start, B_end, T).to(device)
# 使用 DDPM 类初始化一个扩散模型对象
ddpm = ddpm_utils.DDPM(B, device)
2.1 Group Normalization 和 GELU
我们首先要改进的是标准卷积处理过程的优化。这个卷积模块将在我们的神经网络中被多次复用,因此非常关键。
2.1.1 Group Normalization
批归一化(Batch Normalization)会将每个卷积核通道的输出转换为z-score(标准分数)。它通过计算一批输入样本的均值和标准差来实现归一化。如果批量大小太小,这种方法的效果就会很差。
如下图所示:左边的图是 Batch Normalization,它对整个 batch 中每个通道在所有样本上的数据进行归一化(绿色区域跨多个样本 N),所以它依赖较大的 batch size 才能获得稳定的统计特性;右边的图是 Group Normalization(组归一化),它在每个样本内部对通道进行分组,再对每组中的特征进行归一化(绿色区域只在一个样本内),这样就避免了对 batch size 的依赖,更适合小 batch 或单样本的情况。
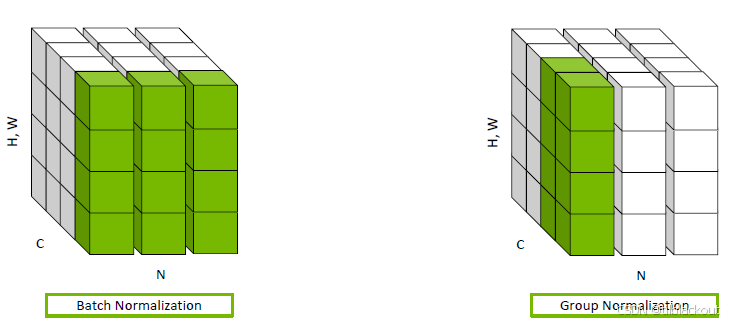
组归一化是针对每张图像单独地,对一组卷积核的输出进行归一化,相当于对一组特征进行“分组处理”。
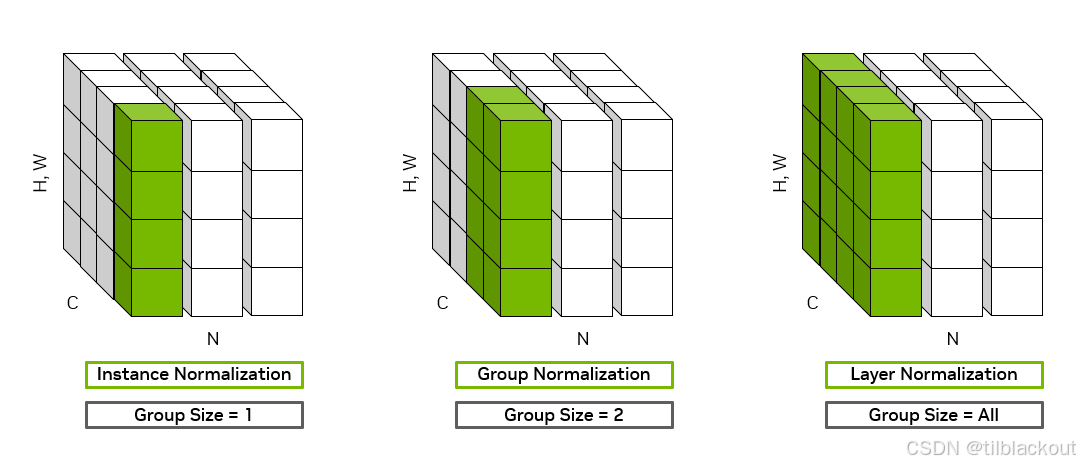
考虑到彩色图像通常有多个颜色通道,组归一化可能会对生成图像的颜色产生有趣的影响,这里就不扩展了。
2.1.2 GELU(Gaussian Error Linear Unit)
ReLU 是一种常见的激活函数,因为它计算快、梯度求导简单。然而它并不完美。当偏置项变得非常负时,ReLU 神经元会“死亡”,因为其输出和梯度都变为零。GELU 在计算上略有代价,但它试图“修复”ReLU,通过模仿其形状,同时避免梯度为零的问题。
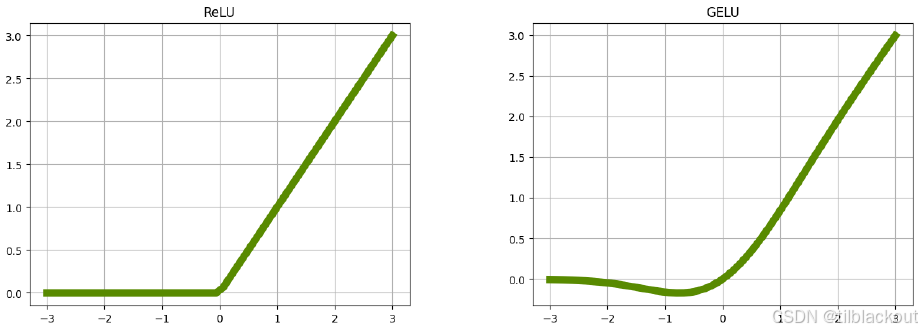
从图上你可以看到,ReLU 在小于等于 0 的区域是完全为 0 的,这意味着一旦输入是负的,这个神经元就“死了”(梯度也为 0,无法更新);而 GELU 在小于 0 时仍然有非零输出,只是变得很小很小,像是一个“平滑的 ReLU”,不会让神经元完全失活。
在这个小型的 FashionMNIST 实验中,我们不太可能遇到死神经元。但随着模型规模的增加,ReLU 死亡问题就更可能出现。这种柔和的处理方式让模型训练更稳定,尤其在深层网络或大模型中,GELU 能更好地保留和传递信息,不会一刀切地把负数全部归零。
# 定义一个包含 GELU 激活的卷积模块
class GELUConvBlock(nn.Module):
def __init__(
self, in_ch, out_ch, group_size):
super().__init__()
# 定义网络层列表
layers = [
# 添加一个 3x3 的二维卷积,padding 为 1 保持尺寸
nn.Conv2d(in_ch, out_ch, 3, 1, 1),
# 使用 Group Normalization
nn.GroupNorm(group_size, out_ch),
# 使用 GELU 激活函数
nn.GELU()
]
# 使用 nn.Sequential 组合网络层
self.model = nn.Sequential(*layers)
# 前向传播函数
def forward(self, x):
return self.model(x)
2.2 Rearrange Pooling(重排池化)
在前一个笔记中,我们使用了最大池化来将潜在图像的尺寸减半。但这真的是最好的方法吗?实际上,池化层的类型很多,包括最小池化、平均池化等等。那么,为什么不让神经网络自己决定哪些信息重要呢?
这就引出了 einops 库中的 Rearrange 层。我们可以用变量来表示每个维度,然后使用括号 () 来标识需要组合(乘在一起)的维度。
例如,下面这段代码中我们使用了:
Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2)
其中:
b表示 batch维度c表示通道维度h表示高度维度w表示宽度维度p1和p2都等于 2
等式左侧的意思是“将高度和宽度维度各自一分为二”,右侧的意思是“将被分割出的维度拼接到通道维度上”。你可以理解为,把每个 2×2 的小块提取出来,展开到通道维度上,这样网络可以在“更细的粒度上”理解图像区域,相比传统池化能保留更多空间细节。
你可以尝试更换左边的变量顺序,比如将 h 和 p1 互换,或是将 p1 设置为 3,观察输出结果发生了什么变化。
# 从 einops 导入 Rearrange 层
from einops.layers.torch import Rearrange
# 定义重排规则:将空间维度分解再合并进通道维度
rearrange = Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2)
# 定义一个测试图像张量
test_image = [
[
[
[1, 2, 3, 4, 5, 6],
[7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18],
[19, 20, 21, 22, 23, 24],
[25, 26, 27, 28, 29, 30],
[31, 32, 33, 34, 35, 36],
]
]
]
# 转换为 PyTorch 张量
test_image = torch.tensor(test_image)
# 打印原始图像
print(test_image)
# 应用 rearrange 层
output = rearrange(test_image)
# 输出重排后的结果
output
输出:

接下来,我们可以将该输出送入 GELUConvBlock,让神经网络自己决定如何在“池化区域”中加权每个值。注意这里 GELUConvBlock 的输入通道变成了 4 * in_chs,这是因为通道数已经乘上了 p1 * p2。
# 定义 Rearrange Pooling 模块
class RearrangePoolBlock(nn.Module):
def __init__(self, in_chs, group_size):
super().__init__()
# 重排操作:将空间维度展开进通道维度
self.rearrange = Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2)
# 应用卷积模块
self.conv = GELUConvBlock(4 * in_chs, in_chs, group_size)
# 前向传播
def forward(self, x):
x = self.rearrange(x)
return self.conv(x)
现在我们拥有了重新定义 DownBlock 和 UpBlock 所需要的组件。为了缓解棋盘格伪影问题,我们加入了多个 GELUConvBlock。
# 定义下采样模块
class DownBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super(DownBlock, self).__init__()
# 定义下采样结构:两层卷积 + 一层池化
layers = [
GELUConvBlock(in_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
RearrangePoolBlock(out_chs, group_size)
]
# 使用 Sequential 组合
self.model = nn.Sequential(*layers)
# 前向传播
def forward(self, x):
return self.model(x)
相比 DownBlock,UpBlock 接收一个额外的输入(用于跳跃连接 skip)。
# 定义上采样模块
class UpBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super(UpBlock, self).__init__()
# 定义上采样结构:反卷积 + 多层卷积
layers = [
# 上采样 + 通道压缩
nn.ConvTranspose2d(2 * in_chs, out_chs, 2, 2),
# 多次应用 GELU 卷积块
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
GELUConvBlock(out_chs, out_chs, group_size),
]
# 使用 Sequential 组合
self.model = nn.Sequential(*layers)
# 前向传播,包含 skip connection 的拼接
def forward(self, x, skip):
x = torch.cat((x, skip), 1)
x = self.model(x)
return x
2.3 Time Embeddings(时间嵌入)
模型越能理解自己当前处于扩散过程的哪个时间步,就越有可能准确判断出噪声的程度。在之前的文章中,我们使用了 t/T 来创建时间嵌入。那么,有没有办法让模型更好地理解这个时间信息?
在扩散模型出现之前,这其实是NLP中常见的问题:对于较长的句子或对话,模型如何判断当前的语义位置?目标是用一组连续的数值来唯一表示一系列离散的时间步。直接使用 float 表示时间步不好,是因为神经网络会把它当作连续数值来处理,而不是“第几步”这种有明确位置含义的离散信息,这会导致模型难以准确感知时间上下文。
最终,研究者选择使用正弦和余弦的组合来进行位置编码。正余弦嵌入通过将每个时间步编码为一组固定频率的正弦和余弦函数值,为每个时间点生成唯一的、高维表示,能更清晰地传达“当前位置”的概念,帮助模型更好地理解扩散过程中的时间结构。
- 想了解这种编码为何有效及其背后原理,推荐阅读这篇:Master Positional Encoding。
# 导入数学库
import math
# 定义正弦位置嵌入模块
class SinusoidalPositionEmbedBlock(nn.Module):
def __init__(self, dim):
super().__init__()
# 嵌入向量维度
self.dim = dim
def forward(self, time):
# 获取设备信息
device = time.device
# 一半维度用于 sin,一半用于 cos
half_dim = self.dim // 2
# 生成指数衰减的频率因子
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
# 时间乘频率,构建位置嵌入
embeddings = time[:, None] * embeddings[None, :]
# 拼接 sin 和 cos 结果
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
为什么用
log(10000)?这是来自 Transformer 位置编码论文的核心思想:我们想让每个位置嵌入中的频率指数式变化,从慢到快地覆盖一个广泛的范围,即为了让频率呈指数级变化,从慢波动(长周期)到快波动(短周期),确保模型既能感知整体,也能感知局部。
我们会将 SinusoidalPositionEmbedBlock 的输出送入 EmbedBlock 中。而 EmbedBlock 不需要做任何修改:
# 定义嵌入模块,将嵌入向量转换为特征图
class EmbedBlock(nn.Module):
def __init__(self, input_dim, emb_dim):
super(EmbedBlock, self).__init__()
self.input_dim = input_dim
layers = [
# 第一层全连接
nn.Linear(input_dim, emb_dim),
# GELU 激活
nn.GELU(),
# 第二层全连接
nn.Linear(emb_dim, emb_dim),
# 展平为特征图格式
nn.Unflatten(1, (emb_dim, 1, 1))
]
self.model = nn.Sequential(*layers)
def forward(self, x):
# 预处理输入形状
x = x.view(-1, self.input_dim)
return self.model(x)
2.4 Residual Connections(残差连接)
解决棋盘格伪影的最后一个技巧是加入更多的残差(skip)连接。我们可以为初始卷积部分创建一个 ResidualConvBlock,当然也可以在 DownBlock 和 UpBlock 中增加类似结构。
# 定义残差卷积模块
class ResidualConvBlock(nn.Module):
def __init__(self, in_chs, out_chs, group_size):
super().__init__()
# 第一个卷积层
self.conv1 = GELUConvBlock(in_chs, out_chs, group_size)
# 第二个卷积层
self.conv2 = GELUConvBlock(out_chs, out_chs, group_size)
def forward(self, x):
# 第一次卷积
x1 = self.conv1(x)
# 第二次卷积
x2 = self.conv2(x1)
# 残差连接(跳跃连接)
out = x1 + x2
return out
下面是更新后的模型。注意最后一行的变化了吗?我们又添加了一个残差连接:将 ResidualConvBlock 的输出与最终输出模块 self.out 拼接起来。这条连接非常关键,是所有改动中对减少棋盘格伪影影响最大的一项。
# 定义 UNet 网络结构
class UNet(nn.Module):
def __init__(self):
super().__init__()
# 输入图像通道
img_chs = IMG_CH
# 下采样的通道数
down_chs = (64, 64, 128)
# 上采样通道(与下采样通道顺序相反)
up_chs = down_chs[::-1]
# 潜空间图像尺寸
latent_image_size = IMG_SIZE // 4
# 时间嵌入维度
t_dim = 8
# 基础分组数
group_size_base = 4
# 小组归一化分组数(新)
small_group_size = 2 * group_size_base
# 大组归一化分组数(新)
big_group_size = 8 * group_size_base
# 初始卷积使用残差块(新)
self.down0 = ResidualConvBlock(img_chs, down_chs[0], small_group_size)
# 下采样模块(新)
self.down1 = DownBlock(down_chs[0], down_chs[1], big_group_size)
self.down2 = DownBlock(down_chs[1], down_chs[2], big_group_size)
self.to_vec = nn.Sequential(nn.Flatten(), nn.GELU())
# 潜向量的嵌入线性层
self.dense_emb = nn.Sequential(
nn.Linear(down_chs[2]*latent_image_size**2, down_chs[1]),
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[1]),
nn.ReLU(),
nn.Linear(down_chs[1], down_chs[2]*latent_image_size**2),
nn.ReLU()
)
# 时间嵌入模块(新)
self.sinusoidaltime = SinusoidalPositionEmbedBlock(t_dim)
self.temb_1 = EmbedBlock(t_dim, up_chs[0])
self.temb_2 = EmbedBlock(t_dim, up_chs[1])
# 上采样模块
self.up0 = nn.Sequential(
nn.Unflatten(1, (up_chs[0], latent_image_size, latent_image_size)),
GELUConvBlock(up_chs[0], up_chs[0], big_group_size) # 新
)
self.up1 = UpBlock(up_chs[0], up_chs[1], big_group_size)
self.up2 = UpBlock(up_chs[1], up_chs[2], big_group_size)
# 输出模块 + 最后一个跳跃连接
self.out = nn.Sequential(
nn.Conv2d(2 * up_chs[-1], up_chs[-1], 3, 1, 1),
nn.GroupNorm(small_group_size, up_chs[-1]), # 新
nn.ReLU(),
nn.Conv2d(up_chs[-1], img_chs, 3, 1, 1)
)
def forward(self, x, t):
# 编码器路径
down0 = self.down0(x)
down1 = self.down1(down0)
down2 = self.down2(down1)
latent_vec = self.to_vec(down2)
# 时间嵌入
latent_vec = self.dense_emb(latent_vec)
t = t.float() / T # 将时间步标准化到 [0, 1]
t = self.sinusoidaltime(t) # 生成位置编码(新)
temb_1 = self.temb_1(t)
temb_2 = self.temb_2(t)
# 解码器路径 + 时间嵌入
up0 = self.up0(latent_vec)
up1 = self.up1(up0 + temb_1, down2)
up2 = self.up2(up1 + temb_2, down1)
# 输出 + 最后一条残差连接(拼接 down0)
return self.out(torch.cat((up2, down0), 1)) # 新
创建模型实例,查看参数量并编译模型:
# 创建 UNet 模型实例
model = UNet()
# 打印参数数量
print("Num params: ", sum(p.numel() for p in model.parameters())) # 输出1979777
# 使用 torch.compile 优化模型运行效率
model = torch.compile(model.to(device))
3 训练模型
终于到了训练模型的时候了。让我们看看之前做的所有改进是否真的带来了提升。
# 使用 Adam 优化器,学习率设置为 0.001
optimizer = Adam(model.parameters(), lr=0.001)
# 设置训练轮数
epochs = 5
# 设置模型为训练模式
model.train()
# 开始训练循环
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
# 梯度清零
optimizer.zero_grad()
# 随机生成时间步 t,范围在 [0, T) 之间,大小为 batch 大小
t = torch.randint(0, T, (BATCH_SIZE,), device=device).float()
# 获取输入图像数据,并转到设备上
x = batch[0].to(device)
# 计算损失
loss = ddpm.get_loss(model, x, t)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 每训练一个 epoch 且每 100 步打印一次损失和采样图像
if epoch % 1 == 0 and step % 100 == 0:
print(f"Epoch {epoch} | step {step:03d} Loss: {loss.item()} ")
# 使用当前模型采样图像并显示
ddpm.sample_images(model, IMG_CH, IMG_SIZE, ncols)
部分输出如下:

我们放大看一看,你能认出哪张是鞋、哪张是包、哪张是衬衫吗?
# 设置模型为评估模式
model.eval()
# 设置输出图像尺寸
plt.figure(figsize=(8,8))
# 每组图像显示的列数,应该能整除 T
ncols = 3
# 显示 10 组采样图像
for _ in range(10):
ddpm.sample_images(model, IMG_CH, IMG_SIZE, ncols)
部分输出如下:
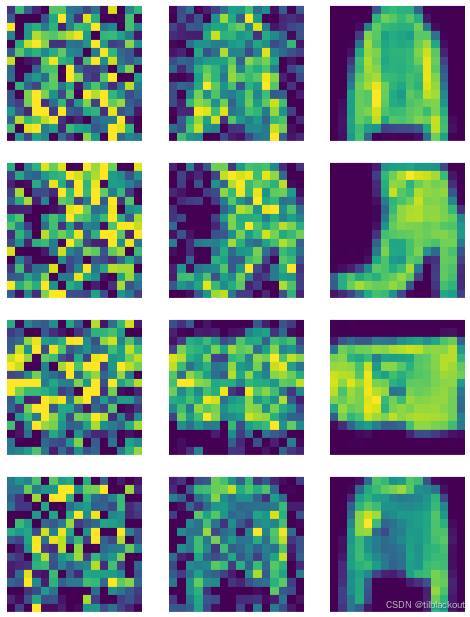
4 总结
这篇文章围绕扩散模型的图像生成过程进行改进,逐步搭建并优化了一个能生成 FashionMNIST 图像的扩散网络。作者从基础出发,首先引入了 Group Normalization 和 GELU 激活函数,替代传统的 BatchNorm 和 ReLU,以提升在小 batch 下的稳定性和表达能力。接着,利用 Rearrange Pooling 替代 MaxPooling,让网络可以通过结构性重排自主决定哪些局部特征重要。同时,加入了基于正余弦函数的 Sinusoidal Position Embedding,让模型能够准确感知当前所处的扩散时间步。为了进一步缓解棋盘格伪影问题,文章引入了多个 Residual Connections,构建了新的 DownBlock、UpBlock 和最终的 UNet 架构。
但目前模型还无法控制生成类别,下一篇文章我们就来解决这个问题…


















 3397
3397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











