







00. 平台的业务
从平台这个概念本身来说,它提供的是支撑作用,通过整合、管理不同的基础设施、技术框架,一些通用的流程规范来形成一个通用的、易用的GUI来给用户使用。通用性是它的考量之一、也是所有平台的愿景之一:希望平台能适用于各个不同的业务线来产生价值。所以从业务上来说,作为一个平台本身是不会、也不应该有太多specific的业务功能的。当然这只是理想情况,有时候为了平台使用方的需求,也不得不加上一些业务领域特定的功能或者补丁来适应业务方,特别是平台建设初期,在没有太多业务的使用的时候。整体来看,平台自身的业务可谓是非常简单,可以用一张图来表示:
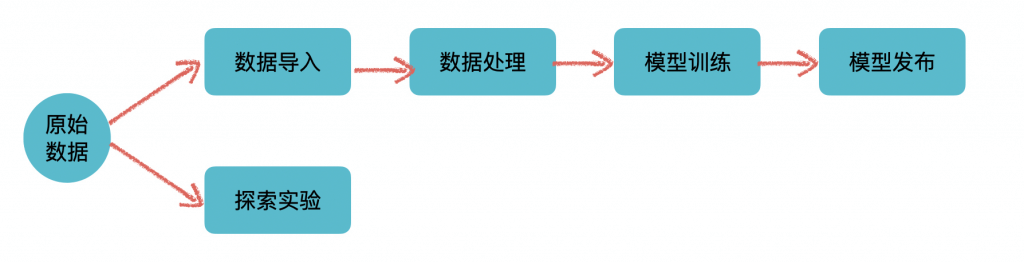
上面这个分支是标准的机器学习流程的抽象。从数据准备,数据处理,模型训练,再到模型上线实现价值完成整个流程。
下面这个分支,也是机器学习和数据科学领域中不可或缺的,主要指的是类似于Jupyter Notebook这类,提供高度灵活性和可视化的数据探索服务,用户可以在里面进行数据探索、尝试一些实验来验证想法。当然当平台拥有了SDK/CLI之后,也可以在里面无缝集成上面这条线里面的功能,将灵活性与功能性融合在一起。
01. 基础设施
上面提到平台本身是整合了不同的基础设施、技术框架和流程规范。在正式开始之前,有必要介绍下本文后续所使用的的基础设施和框架。
在容器化、云化的潮流中,Kubernetes基本上是必选的基础设施,它提供灵活易用的基础设施和应用管理能力,同时扩展性非常好。它可以用于
- 部署平台本身
- 调度一些批处理任务(这里主要指离线任务,如数据处理、模型训练。适用的技术为:Spark on kubernetes/Kubernetes Job),
- 部署常驻服务(一般指的是RESTful/gRPC等为基础的服务,如启动的Notebook、模型发布后的模型推理服务。适用的技术为Kubernetes Deployment/Kubernetes Statefulset/Service等)。
机器学习的主要场景下,数据量都是非常大的,所以Hadoop这一套也是必不可少的,其中包含基础的Hadoop(HDFS/HIVE/HBase/Yarn)以及上层计算框架Spark等。大数据技术体系主要用于数据存储和分布式数据处理、训练的业务。
最后就是一些机器学习框架,Spark系的(Spark MLlib/Angel),Python系的(Tensorflow/Pytorch)。主要用途就是模型训练和模型发布(Serving)的业务。
02.原始数据
原始数据,也叫做数据源,也就是机器学习的燃料。平台本身并不关心原始数据是如何被收集的,只关心数据存储的方式和位置。存储的方式决定了平台是否能支持此种数据的操作。存储的位置决定了平台是否有权限、有能力去读取到此数据。按主流的情况来看,原始数据的存储一般支持四类形式:
- **传统的数据库,例如RDS/NoSQL。**这类数据源见得比较少,因为一般在大数据场景下,通用的解决方案是将此类数据源通过一些工具导入到大数据体系中(如Sqoop)。对于此类数据源的支持也是很简单的,使用通用的Driver 或者 Connector即可。
- **以HDFS为媒介的通用大数据存储。**此类数据源使用较为广泛,最常见的是HDFS文件(parquet/csv/txt)和基于HDFS的HIVE数据源。另外,由于是大数据场景下的经典数据源,所以上层的框架支持较为完善。
- **NFS。**NFS由于其快速的读写能力,以及悠久的历史。很多企业内部都有此基础设施,因而已有的数据也极有可能存储在上面。
- **OSS(对象存储)。**最过于流行的要属S3了。对象存储是作为数据湖的经典方案,使用简单,存储理论上无限,和HDFS一样具备数据高可用,不允许按片段更改数据,只能修改整个对象是其缺点。
值得注意的是,NFS和OSS一般用于存储非结构化数据,例如图片和视屏。或者用于持久化输出目的,如容器存储,业务日志存储。而HDFS和数据库里面存放的都是结构化、半结构化的数据,一般都是已经经过ETL处理过的数据。存储的数据不一样决定了后续的处理流程的区别:
- NFS/OSS系数据源,基本上都是通过TensorFlow/Pytorch来处理,数据一般通过Mount或者API来操作使用。当然也有特例,如果是使用云服务,例如AWS的大数据体系的话,绝大多数场景下,是使用S3来代替HDFS使用的,这也得益于AWS本身对于S3的专属EMRFS的定制化。当然Spark本身等大数据处理框架也是支持此类云存储的。
- HDFS系和传统数据库系数据源,这个大数据框架、Python系框架都是可以的。
平台一般会内嵌对以上数据源的支持能力。对于不支持的其他存储,比如本地文件,一般的解决方案是数据迁移到支持的环境。
03.数据导入
这应该是整个平台里较为简单的功能,有点类似于元数据管理的功能,不过功能要更简单。要做的是在平台创建一个对应的数据Mapping。为保证数据源的可访问,以及用户的操作感知。平台要做的事情可以分为三步:
- 访问对应的数据源,以测试数据是否存在、是否有权限访问。
- 拉取小部分数据作为采样存放在平台中(如MySQL),以便于快速展示,同时这也是数据本身的直观展现(Sample)。对于图片、视频类的,只需要存储元信息(如资源的url、大小、名称),展示的时候通过Nginx之类的代理访问展示即可。
- 如果是有Schema的数据源,例如Hive表,数据源的Schema也需要获取到。为后续数据处理作为输入信息。
技术上来说,平台中会存在与各种存储设施交互的代码,大量的外部依赖。此时,外部依赖可能会影响到平台本身的性能和可用性,比如Hive的不可用、访问缓慢等,这个是需要注意的。
业务上来说,更多考量的是提高系统的易用性,举个例子,创建Hive表数据源,是不是可以支持自动识别分区,选择分区又或者是动态分区(支持变量)等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









