










推荐序2
成为一名优秀的游戏客户端开发者,不仅需要常年的实践积累与思考,更需要夯实的基础为支撑。大部分开发者都很努力刻苦,但是为什么不同开发者之间的能力参差不齐?这是因为日常开发过程中的经验很多时候只是冰山一角,冰山之下隐藏的奥秘却少为人知。挖掘隐匿于冰山之下的宝藏需要开发者具有夯实的基础。所谓“九层之台,起于累土”,古人警示名言用在此处最为恰当
2021-03-24
译者序
网络上针对各式各样的问题也有针对性的解决方案,但是这些零碎的信息难以让读者形成系统的认知,很容易使读者陷入优化的陷阱或者很容易生搬硬套其他项目分享的经验对自己的项目加以限制。最终可能确实提升了部分性能,却可能严重地牺牲了游戏的美术品质、体验等
生搬硬套其他的项目对自己的项目加以限制
没有系统的认知很容易陷入优化的陷阱
2021-03-24
软件工程中有一句名言“没有银弹!”,对于优化更是如此,有的项目可能受限于Draw Call,有的可能受限于像素填充率,有的可能受限于显存带宽。若想针对自己的项目进行特定优化,而不是将网络上的所有方法强加于一身,需要开发人员建立对性能优化的系统认知,真正做到知其所以然,这样才能根据自己的项目选择最合适的优化方案,做到尽量保证美术质量的同时提升性能
2021-03-24
前言
性能优化的目标之一是最大化地利用可用资源,包括CPU资源,如消耗的CPU循环数、使用的主存空间大小(称为RAM),也包括GPU资源[GPU有自己的内存空间(称为VRAM)]、填充率、内存带宽等。然而,性能优化最重要的目标是确保没有哪个资源不合时宜地导致性能瓶颈,优先级最高的任务得到优先执行。哪怕很小的、间歇性的停顿或性能方面的延迟都会破坏玩家的体验,打破沉浸感,限制我们尝试创建体验的潜力。另一个需要考虑的事项是,节省的资源越多,便能够在游戏中创造出更多的活动,从而产生更有趣、更生动的玩法。
没有哪一个资源不合时宜的出现或者占用资源
优先级最高的得到优先执行的待遇,这个待遇确实给到了没有
2021-03-24
同样重要的是,要决定何时后退一步,停止增强性能。在一个拥有无限时间和资源的世界里,总会有另一种方法让游戏变得更好、更快、更高效。在开发过程中,必须确定产品达到了可接受的质量水平。如果不这样做,就会重复实现那些很少或没有实际好处的变更,而每个变更都可能引入更多的bug。 判断一个性能问题是否值得修复的最佳方法是回答“用户会注意到它吗?”。如果这个问题的答案是“不”,那么性能优化就是白费力气。软件开发中有句老话: 过早的优化是万恶之源。
无
2021-03-24
https://github.com/ PacktPublishing/Unity-2017-Game-Optimization-Second-Edition
2021-02-20
第1章 研究性能问题
从多个子系统(CPU、GPU、内存、物理引擎、管道渲染等)中收集性能数据,并将它们与我们认为可以接受的数据进行比较。这些数据可以用来识别应用程序中的瓶颈,执行额外的检测,并确定问题的根源。
2021-03-24
在花费哪怕一分钟来修复性能之前,需要首先证明存在性能问题。在有充分的理由之前花时间重写和重构代码是不明智的,因为预先优化很少能解决问题。一旦找到了性能问题的证据,下一个任务就是准确地找出瓶颈所在。确保理解为什么会出现性能问题是很重要的,否则可能会浪费更多的时间来应用补丁,而这些补丁只不过是有根据的猜测。这样做往往意味着只解决了问题的一个方面,而不是问题的根本原因,因此问题可能会在未来以其他方式,或以我们尚未发现的方式表现出来。
2021-03-24
1.1 Unity Profiler
要分析独立运行的项目,应确保在构建应用程序时启用了Development Build和Autoconnect Profiler标志。
【】Profiler使用的端口
2021-02-20
Profiler使用54998~55511的端口来广播分析数据。如果系统存在防火墙,请确保这些端口可用于向外发送数据。
2021-04-05
有两种不同的方式可以将Android设备连接到Unity Profiler:通过Wi-Fi连接或使用Android Debug Bridge(ADB)工具。
2021-04-05
执行下面的步骤,通过Wi-Fi连接Android设备:
(1) 确保当构建应用程序时启用了Development Build和Autoconnect Profiler标志。
(2)将Android和桌面设备(Apple Mac或Windows PC)连接到本地Wi-Fi网络。
(3)通过USB线缆将Android连接到桌面设备。
(4)像往常一样使用Build & Run选项构建应用程序。
(5)在Unity编辑器中打开Profiler,在Connected Player下选择设备。
接下来,应该会构建应用程序,并通过USB连接推送到Android设备,而Profiler应该会通过Wi-Fi进行连接。之后应该看到Profiler窗口正在收集Android设备的分析数据。
第二种方式是使用ADB。这是Android SDK中的调试工具套件。为了使用ADB进行分析,可以执行下面的步骤:
(1)确保根据Unity的Android SDK/NDK安装向导安装了Android SDK: https://docs.unity3d.com/Manual/android-sdksetup.html。
(2)通过USB线缆将Android设备连接到桌面设备。
(3)确保构建应用程序时启用了Development Build和Autoconnect Profiler标志。
(4)像往常一样使用Build & Run选项构建应用程序。
(5)在Unity编辑器中打开Profiler,并在Connected Player下选择设备。
2021-04-05
在每个子系统中收集数据的深度
2021-02-20
记录所分析的数据。在启用此选项时,将连续记录数据
2021-02-21
这导致运行时的指令注入成本比正常情况下要大得多,并要使用大量的内存,因为在运行时收集的是整个调用堆栈的数据
2021-02-21
收集Unity Editor自身的数据
2021-02-21
如果尝试统计某个全局方法调用了多少次,或者确认这些调用中的某次调用比预计消耗了更多的GPU和内存,Raw Hierarchy模式会很有用
2021-03-29
Timeline模式将细分视图垂直组织到不同的部分,代表运行时的不同线程,例如主线程、渲染线程和各种后台工作线程,称为Unity Job System,用于加载诸如场景和其他资源等活动。水平轴表示时间,所以宽方块消耗的CPU时间比窄方块更多,方块的水平大小也表示相对时间,更容易比较两个调用所消耗的时间。垂直轴代表调用栈,因此更深的链表示在那个栈上有更多调用。
2021-03-29
Timeline模式提供了一种非常清晰、条理分明的方式,以明确调用栈中的哪个方法消耗的时间最多,以及处理时间如何与同一帧中调用的其他方法进行比较。这允许用最少的努力来评估导致性能问题的最大原因。
2021-03-29
在图1-5中,调用了3个不同的MonoBehaviour组件,超出了16.667毫秒的预算
2021-03-29
用于保存Profiler收集的数据的内存
2021-02-21
Detailed 模式显示每个GameObjects和MonoBehaviours为其Native和Managed表示所消耗的内存。它还有一列,解释为什么对象可能消耗内存以及它可能何时被销毁
2021-02-21
1.2 性能分析的最佳方法
良好的代码实践和项目资源管理通常使性能问题的根源查找变得相对简单,唯一的真正问题是如何改进代码
2021-03-29
软件开发的通用目标是使代码简洁,功能丰富且快速。实现其中一个相对容易,但实现两个将花费更多的时间和精力,而实现3个几乎是不可能的。
2021-03-29
软件开发的通用目标是使代码简洁,功能丰富且快速。实现其中一个相对容易,但实现两个将花费更多的时间和精力,而实现3个几乎是不可能的。
2021-03-24
软件开发的通用目标是使代码简洁,功能丰富且快速。实现其中一个相对容易,但实现两个将花费更多的时间和精力,而实现3个几乎是不可能的
【】精辟、犀利
2021-03-24
我们常常很容易被无效的数据分散注意力,或者因为缺乏耐心或者忽略了一个细微的细节而匆忙得出结论。许多人在软件调试过程中都遇到过这样的情况:如果简单地挑战并验证前面的假设,就可以更快地找到问题的根源。查找性能问题也一样。 一份任务清单有助于让我们专注于这个问题,而不是浪费时间去追逐所谓的“幽灵”。
一份任务清单有助于让我们专注于这个问题,而不是浪费时间去追逐所谓的“幽灵”。
2021-03-24
我们常常很容易被无效的数据分散注意力,或者因为缺乏耐心或者忽略了一个细微的细节而匆忙得出结论。许多人在软件调试过程中都遇到过这样的情况:如果简单地挑战并验证前面的假设,就可以更快地找到问题的根源。查找性能问题也一样。 一份任务清单有助于让我们专注于这个问题,而不是浪费时间去追逐所谓的“幽灵”。当然,每个项目都是不同的,有自己独特的困难需要克服,但是下面的检查表足够通用,适用于任何Unity项目:
【】重要厉害! 通用检查表
- 验证目标脚本是否出现在场景中
- 验证脚本在场景中出现的次数是否正确
- 验证事件的正确顺序 : 日志上标记数字
- 最小化正在进行的代码更改
- 尽量减少内部干扰
- 尽量减少外部干扰
打出的日志标记上“数字”
2021-03-24
我们有时会假设某些事情已经发生了,但事实并非如此
【】游戏引擎运行机制
2021-03-29
Unity的主线程并不像简单的控制台应用程序那样运行。在这样的应用程序中,代码执行时有明显的起点(通常是main()函数),然后我们直接控制游戏引擎,在那里初始化主要子系统,接着游戏运行在一个很大的while循环(通常称为游戏循环)中,检查用户输入,更新游戏,渲染当前的场景,重复下去。此循环只在玩家选择退出游戏时退出。
2021-02-22
后期初始化
2021-02-21
后期更新
2021-02-21
最难调试/最不可预测的类型可能是WaitForSeconds yield类型。Unity引擎是不确定的,这意味着即使在相同的硬件上,一个会话和下一个会话中的行为也会稍微不同
2021-02-22
在协调程序启动和结束之间调用的Update()回调数量是可变的,因此,如果协调程序依赖于某个对象的Update()特定调用次数,就会出问题。一旦协同程序启动,最好保持它的简单性和独立性,不受其他行为的影响。违反这条规则可能很诱人,但若违反,将来的一些更改肯定会以意想不到的方式与协程交互,从而导致调试过程漫长而痛苦,其中有一个很难重现的能破坏游戏的错误。
2021-02-22
产生许多嘈杂的峰值
【】禁用VSync功能
2021-02-22
在性能测试期间监视CPU峰值时,应该确保在“CPU使用情况”区域下禁用VSync复选框。导航到Edit | Project Settings | Quality,然后导航到当前选择的平台的子页面,就可以完全禁用VSync功能。
【】日志非常昂贵
2021-02-22
Unity的Debug.Log()和类似的方法,如Debug.LogError()和Debug.LogWarning(),在CPU使用率和堆内存消耗方面非常昂贵,这会导致发生垃圾回收,甚至丢失CPU循环。
2021-02-22
可用内存不足通常会干扰测试,因为它会导致更多的缓存丢失,对虚拟内存页文件交换的硬盘访问,应用程序的响应速度通常较慢。
2021-02-22
分隔符方法BeginSample()和EndSample()仅在开发构建过程中编译,因此,它们不会在未选中开发模式的版本构建过程中编译或执行
【】对代码独立分析的技术
2021-02-22
自定义CPU分析 Profiler只是我们可用的工具之一。有时我们可能希望对代码执行定制的分析和日志记录。也许我们不确定Unity Profiler是否给出了正确的答案,也许认为它的开销太大了,或者只是想完全控制应用程序的每个方面。不管我们的动机是什么,了解一些对代码执行独立分析的技术是一项有用的技能。毕竟我们不太可能在整个游戏开发生涯中都使用Unity。
2021-02-22
在测试CPU使用情况时,真正需要的是一个准确的计时系统,一种快速、低成本的信息记录方法,以及一些用于测试它们的代码
2021-02-22
using块通常用于安全地确保非托管资源在超出作用域时被正确销毁。当using块结束时,它将自动调用对象的Dispose()方法来处理任何清理操作。为了实现这一点,对象必须实现IDisposable接口,这迫使它定义Dispose()方法。
2021-02-22
另一个需要担心的问题是应用程序的预热时间。当场景启动时,如果大量数据需要从磁盘上加载,初始化复杂的子系统,如物理和渲染系统,在执行其他操作之前需要解析大量的Awake()和Start()回调,则Unity有很大的启动成本。这种早期的开销可能只持续一秒钟,但如果代码也在早期初始化期间执行,则会对测试结果产生重大影响。如果想要准确地测试,任何运行时测试都应该在应用程序达到稳定状态之后才开始,这一点至关重要。
2021-03-24
因此作为备份计划,可以将目标代码块打包到Input.GetKeyDown()检查中,以便在调用它时进行控制
2021-03-24
1.3 关于分析的思考
关于如何正确使用任何一种数据收集工具的建议,可以归纳为3种不同的战略:
【】数据收集战略
- 理解Profiler工具
- 减少干扰
- 关注问题
2021-03-24
对工具的优点、缺陷、特性和限制了解得越多,就越能理解它提供的信息,所以花时间在场景设置下使用它是值得的
2021-03-24
如果一个很高的CPU使用峰值没有超过60 FPS或30 FPS基准条(取决于应用程序的目标帧率),那么明智的方法是忽略它,搜索别处的CPU性能问题,因为无论怎么改进有问题的代码块,最终用户也可能永远不会注意到它,因此并不是一个影响用户体验的关键问题。
2021-03-24
使用彩色复选框来缩小搜索范围
2021-02-22
此外,GameObjects可以停用
2021-02-22
如果逐渐停用对象,在停用特定对象时,性能突然变得更容易接受,那么显然该对象与问题的根源有关。
2021-02-22
第2章 脚本策略
2.1 使用最快的方法获取组件
GetComponent( )方法只比GetComponent(typeof(T))方法快一点点,而GetComponent(string)方法明显比其他两个方法慢得多
2021-04-05
2.2 移除空的回调定义
太多的组件计算一个可以共享的结果。
【】60FPS,应在16.667毫秒内完成所有Update
2021-02-22
记住,在Update()回调中编写的每一行代码,以及那些回调调用的函数,都会消耗帧速率预算。要达到60FPS,每帧应在16.667毫秒内完成所有Update()回调中的所有工作。
2021-04-05
2.5 Update、Coroutines和InvokeRepeating
它们不应该与线程混淆,线程以并发方式在完全不同的CPU内核上运行,而且多个线程可以同时运行。相反,协程以顺序的方式在主线程上运行,这样在任何给定时刻都只处理一个协程,每个协程通过yield语句决定何时暂停和继续
【】协程
2021-02-23
这种方法的主要好处是,这个函数只调用_aiProcessDelay值指示的次数,在此之前它一直处于空闲状态,从而减少对大多数帧的性能影响。然而,这种方法有其缺点。 首先,与标准函数调用相比,启动协程会带来额外的开销成本(大约是标准函数调用的三倍),还会分配一些内存,将当前状态存储在内存中,直到下一次调用它。这种额外的开销也不是一次性的成本,因为协程经常不断地调用yield,这会一次又一次地造成相同的开销成本,所以需要确保降低频率的好处大于此成本。
【】协程停止条件、重新启动方法
2021-02-25
一旦初始化,协程的运行独立于MonoBehaviour组件中Update()回调的触发,不管组件是否禁用,都将继续调用协程。如果执行大量的GameObject构建和析构操作,协程可能会显得很笨拙。 再次,协程会在包含它的GameObject变成不活动的那一刻自动停止,不管出于什么原因(无论它被设置为不活动的还是它的一个父对象被设置为不活动的)。如果GameObject再次设置为活动的,协程不会自动重新启动。
【】协程可以提高帧率
2021-02-25
将方法转换为协程,可减少大部分帧中的性能损失,但如果方法体的单次调用突破了帧率预算,则无论该方法的调用次数怎么少,都将超过预算。因此,这种方法最适用于如下情况:
即由于在给定的帧中调用该方法的次数太多而导致帧率超出预算,而不是因为该方法本身太昂贵。
这些情况下,我们别无选择,只能深入研究并改进方法本身的性能,或者减少其他任务的成本,将时间让给该方法,来完成其工作。
不太明白 : 01-将方法转换为协程,可以减少性能损失的原理
2021-02-25
委托函数是C#中非常有用的结构,允许将本地方法作为参数传递给其他方法,通常用于回调
【】协程使用的两个原则
2021-02-25
协程很难调试,因为它们不遵循正常的执行流程;在调用栈上没有调用者。可以直接指责为什么协程在给定的时间触发,如果协程执行复杂的任务,与其他子系统交互,就会导致一些很难察觉的缺陷,因为他们在其他代码不希望的时刻触发,这些缺陷也往往是极其难重现的类型。如果希望使用协程,最好使它们尽可能简单,且独立于其他复杂的子系统。
2021-02-25
停止InvokeRepeating()调用的两种方法:
- 第一种方法是调用CancelInvoke(),它停止由给定的MonoBehaviour(注意它们不能单独取消)发起的所有InvokeRepeating()回调;
- 第二种方法是销毁关联的MonoBehaviour或它的父GameObject。禁用MonoBehaviour或GameObject都不会停止InvokeRepeating()。
2021-03-24
2.6 更快的GameObject空引用检查
事实证明,对GameObject执行空引用检查会导致一些不必要的性能开销。
与典型的C#对象相比,GameObject和MonoBehaviour是特殊对象,因为它们在内存中有两个表示:
- 一个表示存在于管理C#代码的相同系统管理的内存中,C#代码是用户编写的(托管代码),
- 而另一个表示存在于另一个单独处理的内存空间中(本机代码)。
【】跨越“本机-托管”的桥接
数据可以在这两个内存空间之间移动,但是每次这种移动都会导致额外的CPU开销和可能的额外内存分配。 这种效果通常称为跨越本机-托管的桥接。如果发生这种情况,就可能会为对象的数据生成额外的内存分配,以便跨桥复制,这需要垃圾收集器最终执行一些内存自动清理操作
2021-03-24
另一种方法是System.Object.ReferenceEquals(),它生成功能相当的输出,其运行速度大约是原来的两倍
2021-03-24
这是一个值得在未来记住的警告
2021-03-24
2.7 避免从GameObject取出字符串属性
避免从GameObject取出字符串属性
【】使用GameObject的tag、name会增加内存
2021-03-24
通常,从对象中检索字符串属性与检索C#中的任何其他引用类型属性是相同的;这种检索应该不增加内存成本。
然而,从GameObject中检索字符串属性是另一种意外跨越本机-托管桥接的微妙方式。 GameObject中受此行为影响的两个属性是tag和name。因此,在游戏过程中使用这两种属性是不明智的,应该只在性能无关紧要的地方使用它们,比如编辑器脚本。然而,Tag系统通常用于对象的运行时标识,这对于某些团队来说是一个重要问题。
【】使用CompareTag会避免桥接
2021-03-24
幸运的是,tag属性最常用于比较,而GameObject提供了CompareTag()方法,这是比较tag属性的另一种方法,它完全避免了本机-托管的桥接。
2021-03-24
这应该非常清楚地表明,必须尽可能避免访问name和tag属性。如果需要对标记进行比较,应该使用CompareTag()。但是,name属性没有对应的方法,因此应该尽可能使用tag属性。
【】硬编码字符串
2021-03-24
请注意,向CompareTag()传递字符串字面量(如"Player")不会导致运行时内存分配,因为应用程序在初始化期间分配这样的硬编码字符串,在运行时只是引用它们。
2021-03-24
2.9 避免运行时修改Transform的父节点
避免运行时修改Transform的父节点
【】避免在同一帧中拓展缓冲区
2021-03-24
另一种降低这个过程成本的方法是让根Transform在需要之前就预先分配一个更大的缓冲区,这样就不需要在同一帧中拓展缓冲区,给它重新指定另一个GameObject到缓冲区中。这可以通过修改Transform组件的hierarchyCapacity属性来实现。如果能够估计父元素包含的子Transform数量,就可以节省大量不必要的内存分配
The transform **capacity **of the transform’s hierarchy data structure.
Unity **internally **represents each transform hierarchy, i.e. a root and all it’s deep children, with its own packed data structure. This data structure is **resized **when the number of transforms in it exceeds its capacity.
Setting the capacity to a value slightly larger than the maximum expected size can reduce memory usage and improve performance of Transform.SetParent and Object.Destroy for very large hierarchies.
变换的层级视图数据结构的变换容量。
Unity 内部使用自己的打包数据结构表示每个变换的层级视图,即一个根及其所有深层子项。当其中的变换数量超过其容量时,将调整该数据结构的大小。
将容量设置为略大于最大预期大小的值可减少内存使用量,并提高超大层级视图的 Transform.SetParent 和 Object.Destroy 的性能。
总结 : 设置hierarchyCapacity的值稍大于期望的值有两个好处
- 减少内存使用量
- 提升函数SetParent和Object.Destroy 的执行性能 ,(执行的更快)
2021-03-24
2.10 注意缓存Transform的变化
【】改变Transform的数据代价不小啊
Transform组件只存储与其父组件相关的数据。这意味着访问和修改Transform组件的position、rotation和/或scale属性会导致大量未预料到的矩阵乘法计算,从而通过其父Transform为对象生成正确的Transform表示。对象在Hierarchy窗口中的位置越深,确定最终结果需要进行的计算就越多。
然而,这也意味着使用localPosition、localRotation和localScale的相关成本相对较小,因为这些值直接存储在给定的Transform中,可以进行检索,不需要任何额外的矩阵乘法。因此,应该尽可能使用这些本地属性值。 遗憾的是,将数学计算从世界空间更改为本地空间,会使原本很简单(且已解决)的问题变得过于复杂,因此进行这样的更改会破坏实现方案,并引入大量意外的bug。有时,为了更容易地解决复杂的3D数学问题,牺牲一点性能是值得的。
不断更改Transform组件属性的另一个问题是,也会向组件(如Collider、Rigidbody、Light和Camera)发送内部通知,这些组件也必须进行处理,因为物理和渲染系统都需要知道Transform的新值,并相应地更新。
- 父物体的矩阵运算
- 使用local的优点、缺点
- 向其他组件内部通知
无
2021-03-24
由于内存中Transform的重组,这些内部通知的速度在Unity 5.4中得到了极大的提高,但我们仍然需要了解它们的成本。
无
2021-03-24
在复杂的事件链中,在同一帧中多次替换Transform组件的属性是很常见的(尽管这可能是过度工程设计的警告信号)。每次发生这种情况时,都会触发内部消息,即使它们发生在同一帧甚至同一个函数调用期间。因此,应该尽量减少修改Transform属性的次数,方法是将它们缓存在一个成员变量中,只在帧的末尾提交它们,如下所示:
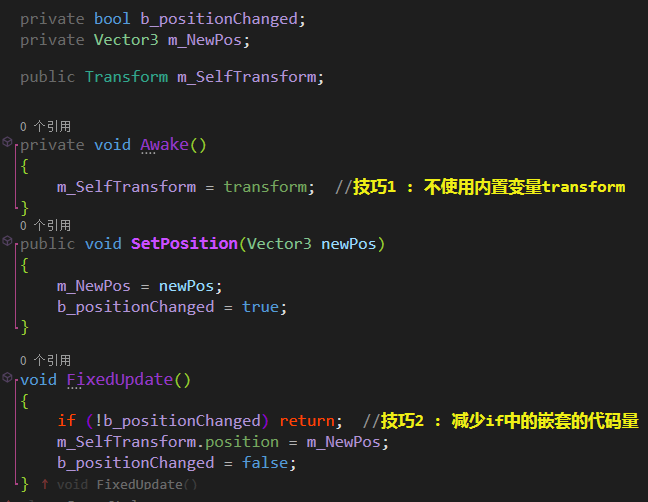
无
2021-03-24
2.11 避免在运行时使用Find()和SendMessage()方法
避免在运行时使用Find()和SendMessage()方法
无
2021-03-24
只要在MonoBehaviour中创建公共字段,当组件被选中时,Unity会自动序列化并在Inspector窗口中显示该值。然而,从软件设计的角度来看,公共字段总是危险的。这些变量可以在任何时间、任何地点通过代码进行更改,因此很难跟踪变量,还很可能会引入许多意想不到的bug。
无
2021-03-01
最佳实践通常是显式指定访问级别。
无
【】代替方式1:单例
2021-03-01
单例模式对于管理共享资源或繁重的数据流量(如文件访问、下载、数据解析和消息传递)非常有用。单例模式确保了有一个入口点来进行这些活动,而不是让大量不同的子系统来竞争共享资源,并可能造成彼此的瓶颈。
无
2021-03-02
在大多数项目中主要使用单例模式的方式作为一些共享功能的全局访问点,并设计为在应用程序的初始化期间创建一次,存在于应用程序的整个生命周期,只在应用程序关闭期间销毁。
无
【】代替方式2:静态类字段
2021-03-02
静态类字段可以像这样内联初始化
无
2021-03-02
但StaticEnemyManager类举例说明了如何使用静态类来提供外部对象之间的信息或通信,从而提供了比使用Find()或SendMessage()更好的选择。
无
【】代替方式3:全局消息传递系统
2021-03-02
解决对象间通信问题的最后建议的方法是实现一个全局消息传递系统,任何对象都可以访问该系统,并将消息通过该系统发送给任何可能对侦听特定类型的消息感兴趣的对象。对象可以发送消息或侦听消息(有时两者都可以),侦听器的职责是确定它们感兴趣的消息。消息发送者可以广播消息而不关心正在听的人,可以通过系统发送消息,而不管消息的具体内容。到目前为止,这种方法是最复杂的,可能需要一些努力来实现和维护,但它是一个优秀的长期解决方案,可以在应用程序变得越来越复杂时保持对象通信的模块化、解耦和快速。
无
2021-03-02
随着系统越来越多地被使用,会在代码中逐步引入越来越多的依赖项。
无
2021-03-03
消息传递系统
无
2021-03-03
进一步探索“依赖注入”的概念
无
2021-03-04
监听对象
无
2021-03-03
我们可能希望广播一个通用通知消息,并让所有侦听器执行一些操作来响应
无
2021-03-03
我们定义的委托应该提供一种通过参数检索消息的方法,并返回一个响应,该响应确定侦听器是否应该停止处理消息,以及何时停止处理。决定是否停止处理可以通过返回一个简单的布尔值来实现,该值为true意味着这个侦听器已处理完消息,消息的处理必须停止,该值为false意味着此侦听器未处理消息,消息传递系统应该尝试下一个侦听器。
无
2021-03-03
添加到队列之前
无
2021-03-04
分离侦听器
无
2021-03-05
2.12 禁用未使用的脚本和对象
由于可见性回调必须与渲染管线通信,因此GameObject必须附加一个可渲染的组件,例如MeshRenderer或SkinnedMeshRenderer。必须确保希望接收可见性回调的组件也与可渲染对象连接在同一个GameObject上,而不是连接到其父或子GameObject上,否则它们不会调用。
无
2021-03-24
2.13 使用距离的平方而不是距离
Vector3类也提供了sq****rMagnitude属性,它提供了同样可作为距离的结果,只是该值是平方。这意味着如果也将需要比较的距离进行平方,就可以执行基本相同的比较,而不需要昂贵的平方根计算。
2.14 最小化反序列化行为
Unity的序列化系统主要用于场景、预制件、ScriptableObjects和各种资产类型(往往派生自ScriptableObject)。当其中一种对象类型保存到磁盘时,就使用YAML (Yet Another Markup Language,另一种标记语言)格式将其转换为文本文件,稍后可以将其反序列化为原始对象类型。所有的GameObject及其属性都会在序列化预制件或者场景时序列化,包括私有的和受保护的字段,它们的所有组件,及其子GameObjects和组件等。 构建应用程序时,这些序列化的数据会捆绑在大型二进制数据文件中,这些文件在Unity内部被称为序列化文件。在运行时从磁盘读取和反序列化数据是一个非常慢的过程(相对而言),因此所有的反序列化活动都伴随着显著的性能成本。
2021-03-24
可以使用两种方法来最小化反序列化的成本。
2.14.1 减小序列化对象
2021-03-24
2.14.2 异步加载序列化对象
2021-03-24
通过显式地调用Resources.Unload()可以释放这些数据,这将释放内存空间,供以后重用
【】显著减少场景的加载时间
2021-03-24
如果有许多不同的预制件,其中的组件包含许多倾向于共享数据的属性,例如游戏设计值,如命中率、力量、速度等,那么所有这些数据都将序列化到使用它们的每个预制件中。更好的方法是将这些公共数据序列化到ScriptableObject中,然后加载并使用它。这减少了存储在预制文件中的序列化数据量,并可以避免过多的重复工作,显著减少场景的加载时间。
2021-03-24
2.15 叠加、异步地加载场景
同步加载是通过调用SceneManager.LoadScene()加载场景的典型方法,其中主线程将阻塞,直到给定的场景完成加载。这通常会导致糟糕的用户体验,因为游戏在加载内容时似乎会卡住
【】异步叠加式加载
2021-03-24
对于未来的场景加载,可能希望减少性能影响,让玩家继续操作下去。加载场景需要很多工作,场景越大,加载时间越长。然而,异步叠加式加载选项提供了巨大的优势:可以让场景逐渐加载到背景中,而不会对用户体验造成明显的影响。为此,可以使用SceneManager.LoadSceneAsync()并传递LoadSceneMode.Additive,以加载模式参数。
【】卸载场景
2021-03-24
场景也可以卸载,从内存中清除出来。这将删除任何不再需要的使用Update()的组件,节省一些内存或提升一些运行时性能。同样,这可以通过SceneManager.UnloadScene()和SceneManager.UnloadSceneAsync()同步或异步地完成。这是一个巨大的性能优势,因为根据玩家在关卡中的位置只使用需要的内容,但请注意,不可能卸载单一场景的小块。如果原始场景文件很大,那么卸载它将卸载所有内容。原来的场景必须分解成更小的场景,然后根据需要加载和卸载。同样,应该只在确定玩家不再能看到场景的组成对象时才开始卸载场景,否则玩家将看到物体凭空消失。最后要考虑的是,场景卸载会导致许多对象被销毁,这可能会释放大量内存并触发垃圾回收。在使用这个技巧时,有效地使用内存也很重要。
2021-03-24
2.16 创建自定义的Update()层
【】分散峰值
想象一下,成千上万的MonoBehaviour在场景开始时一起初始化,每个MonoBehaviour同时启动一个协程,每500毫秒处理一次AI任务。它们极有可能在同一帧内触发,导致CPU使用率在一段时间内出现一个巨大的峰值,接着会临时下降,然后在处理下一轮AI时再次出现峰值。理想情况下,我们希望随时间分散这些调用。
下面是这个问题的可能解决方案:
- 每次计时器过期或协程触发时,生成一个随机等待时间。
- 将协程的初始化分散到每个帧中,这样每个帧中只会启动少量的协程初始化。
- 将调用更新的职责传递给某个God类,该类对每个帧的调用数量进行了限制。
无
2021-03-24
这种剧烈的设计更改会带来许多危险和意想不到的副作用
【】全局游戏一个最底层的基类
2021-03-24
优化更新的一个可能更好的方法是根本不使用Update(),或者更准确地说,只使用一次。当Unity调用Update()时,实际上是调用它的任何回调,都要经过前面提到的本机-托管的桥接,这可能是一个代价高昂的任务。换句话说,执行1000个单独的Update()回调的处理成本比执行一个Update()回调要高,后者调用1000个常规函数。调用Update()数千次的工作量并不是CPU很容易承担的,这主要是因为桥接。因此,让一个God类MonoBehaviour使用它自己的Update()回调来调用自定义组件使用的自定义更新样式的系统,可以最小化Unity需要跨越桥接的频率。
2021-03-24
接口类本质上建立了一个契约,任何实现接口类的类都必须提供一系列特定的方法。换句话说,如果知道对象实现了一个接口类,就可以确定哪些方法是可用的
2021-03-05
接口类的优点在于它们改善了代码库的解耦能力,允许替换大型子系统,只要坚持使用接口类,它就能继续按预期工作。
2021-03-05
如果确保所有自定义组件都继承自UpdateableComponent类,那么实际上用一个Update()回调和N个虚函数调用替换了Update()回调的N次调用。这可以节省大量的性能开销,因为虽然调用虚函数(开销比非虚拟函数调用略多,因为它需要调用重定向到正确的地方),仍然将更新行为的绝大多数放在托管代码中,尽可能避免Native-Managed桥。这个类甚至可以扩展为提供优先级系统,如果它检测到当前帧花费的时间太长,就可以跳过低优先级任务,还有许多其他的可能性。
2021-03-24
第3章 批处理的优势
本文提到Unity中的批处理时,通常指的是两种用于批处理网格数据的主要机制:动态批处理和静态批处理。这两种方法本质上是几何体合并的两种不同形式,用于将多个对象的网格数据合并到一起,并在单一指令中渲染它们,而不是单独准备和绘制每个几何体。
2021-03-24
3.1 Draw Call
Draw Call只是一个从CPU发送到GPU中用于绘制对象的请求。
2021-03-24
在请求Draw Call之前,需要完成一些工作。首先,网格和纹理数据必须从CPU内存(RAM)推送到GPU内存(VRAM)中,这通常发生在场景初始化期间,但仅限于场景文件知道的纹理和网格。
2021-03-24
接着,CPU必须配置处理对象(这些对象就是Draw Call的目标)所需的选项和渲染特性,为GPU做好准备。
2021-03-24
在渲染对象之前,必须为准备管线渲染而配置的大量设置常常统称为渲染状态(Render State)。除非这些渲染状态选项发生了变化,GPU将为所有传入的对象保持相同的渲染状态,并以类似的方式渲染它们。 更改渲染状态是一个耗时的过程。例如,如果将渲染状态设置为使用一个蓝色纹理文件,然后要求它渲染一个巨大的网格,那么渲染会非常快,整个网格都显示为蓝色。然后,可以再渲染9个完全不同的网格,它们都显示为蓝色,因为没有改变所使用的纹理。然而,如果想用10种不同的纹理渲染10个网格,就将花费更长的时间。这是因为在为每个网格发送Draw Call指令之前,需要使用新的纹理来准备渲染状态。
无
2021-03-24
用于渲染当前对象的纹理在Graphics API中实际上是一个全局变量,而在并行系统内修改全局变量说起来容易做起来难。在诸如GPU这样的大规模并行系统中,实际上必须在修改渲染状态之前一直等待,直到所有当前的作业达到同一个同步点为止(换句话说,最快的内核需要停下,等待最慢的内核赶上,这浪费了它们可以用于其他任务的时间),到达此同步点后,需要重新启动所有的并行作业。这会浪费很多时间,因此请求改变渲染状态的次数越少,Graphics API 越能更快地处理请求。 可以触发渲染状态同步的操作包括但不限于:
- 立刻推送一张新纹理到GPU中,
- 修改着色器、照明信息、阴影、透明度和其他任何图形设置。
无
2021-03-24
一旦配置了渲染状态,CPU就必须决定绘制哪个网格,使用什么纹理和着色器,以及基于对象的位置、旋转和缩放(这些都在一个名为变换的4×4矩阵中表示,这正是Transform组件名字的由来)决定在何处绘制对象,然后发送指令到GPU以绘制它。为了使CPU和GPU之间的通信保持活跃,新指令被推入一个名为Command Buffer的队列中。这个队列包含CPU创建的指令,以及GPU每次执行完前面的命令后从中提取的指令。 批处理提升此过程的性能的诀窍在于,新的Draw Call不一定意味着必须配置新的渲染状态。如果两个对象共享完全相同的渲染状态信息,那么GPU可以立刻开始渲染新对象,因为在最后一个对象完成渲染之后,还维护着相同的渲染状态,这消除了由于同步渲染状态而浪费的时间,也减少了需要推入Command Buffer中的指令数,减少了CPU和GPU上的工作负载。
无
2021-03-24
3.2 材质和着色器
如果想要最小化渲染状态修改的频率,可以减少场景中使用的材质数量。这将同时提升两个性能;
- CPU每帧将花费更少的时间生成指令,并传输给GPU;
- 而GPU不需要经常停止,重新同步状态的变更。
2021-03-06
可以看到Game窗口的Stats弹出框中的Batching值共有9个批处理。该值严格等于渲染场景使用的Draw Call数量
无
2021-03-06
理论上可以通过减少系统修改渲染状态信息的频率,来最小化Draw Call的数量。因此,我们的一部分目标是减少使用的材质数。然而,如果所有对象都设置为使用相同的材质,性能依然没有任何提升,批处理数量依然是9,如图3-2所示。 图3-2 Game窗口的Stats弹窗依然显示9个批处理 这是因为渲染状态变更的数量没有真正减少,也没有高效地合并网格信息。遗憾的是,管线渲染不够智能,意识不到我们在重复写入完全相同的渲染状态,并要求它一次又一次地渲染相同的网格。
无
2021-03-24
3.3 Frame Debugger
在Profiler的Rendering区域中单击Breakdown View Options中的Frame Debugger按钮
无
【】列出了所有的DrallCall的窗口
2021-03-24
但最有用的区域是左边面板的Drawing部分,其中列出了场景中的所有Draw Call。
无
2021-03-06
3.4 动态批处理
批处理在运行时生成(批处理是动态产生的)。 批处理中包含的对象在不同的帧之间可能有所不同,这取决于哪些网格在主摄像机视图中当前是可见的(批处理的内容是动态的)。 甚至能在场景中运动的对象也可以批处理(对动态对象有效)。
无
2021-03-24
【】动态批处理对网格的要求
如下所示包含了为给定网格执行****动态批处理的要求:
- 所有网格实例必须使用相同的材质引用。
- 只有ParticleSystem和MeshRenderer组件进行动态批处理。
- SkinnedMeshRenderer组件(用于角色动画)和所有其他可渲染的组件类型不能进行批处理。
- 每个网格至多有300个顶点。
- 着色器使用的顶点属性数不能大于900。
- 所有网格实例要么使用等比缩放,要么使用非等比缩放,但不能两者混用。
- 网格实例应该引用相同的光照纹理文件。
- 材质的着色器不能依赖多个过程。
- 网格实例不能接受实时投影。
- 整个批处理中网格索引的总数有上限,这与所用的Graphics API和平台有关,一般索引值在32~64K之间(查看文档或前述的博客,以获得特定的数据)。
无
2021-03-06
顶点属性只是网格文件中基于每个顶点的一段信息,每一段通常表示为一组浮点数。它包括但不限于顶点位置(相对于网格的根),法线向量(一个从对象表面指向外面的向量,通常用于光照计算),一套或多套纹理UV坐标(用于定义一张或多张纹理如何包裹网格),甚至可能包括每个顶点的颜色信息(通常用于自定义光照或扁平化着色、低多边形风格的对象)
【】验证顶点属性数目最好的方式
2021-03-07
查看网格的原始数据文件,其中包含的顶点属性信息会比Unity载入内存的少,这是由于引擎会将网格数据从几个原始数据格式转化为内部格式。因此,不要假设3D建模工具提供的顶点属性数量是最终的数量**。验证属性数的最好方式是将网格对象拖到场景中**,在Project窗口中找到MeshFilter组件,在Inspector窗口的Preview子区域中查看verts值。
无
【】一张网格最多有900个属性
2021-03-07
在伴随的着色器中,每个顶点使用的属性数据越多,900个属性预算就消耗得越多,从而减少了网格允许拥有的顶点数量,这些顶点不再能用于动态批处理。例如,简单的漫反射着色器只能给每个顶点使用3个属性:位置、法线和一组UV坐标。因此,动态批处理可以使用这个着色器来支持总共有300个顶点的网格。然而,在更复杂的着色器中,每个顶点需要5个属性,只能支持不超过180个顶点的网格的动态批处理。另外,请注意,即使在着色器中每个顶点使用不到3个顶点属性,动态批处理仍然只支持最多300个顶点的网格,因此只有相对简单的对象才适合动态批处理。
一个网格最多允许有900个属性。
比如一个顶点3个“属性”,那么这个网格最多允许有300个“顶点”
【】如何查看不能进行批处理的原因
2021-03-07
如果单击Frame Debugger中的一个Draw Call项,就会显示标签为“Why this draw call can’t be batched with the previous one(这个Draw Call为什么不能与前一个Draw Call批处理)”的部分。大多数情况下,下方的解释文本说明了哪个条件没有满足(至少是它检测到的首个条件),以及有什么调试批处理行为的有用方法。
无
2021-03-07
属于这两组的对象会放到两个不同的批处理中。
指的是等比缩放和非等比缩放这两组
2021-03-07
只有使用负数缩放,才会产生这个奇怪的效果。如果所有缩放仅仅是等比缩放和非等比缩放,那么Unity应能相应地进行对象的批处理合并。
无
2021-03-07
要渲染大量的简单网格时,动态批处理是非常有用的工具。使用大量外观几乎相同的简单物体时,该系统的设计是非常完美的。应用动态批处理的可能情况如下:
- 到处是石头、树木和灌木的森林。
- 有很多简单而常见的元素(计算机、走廊、管道等)的建筑、工厂或空间站。
- 一个游戏,包含很多动态的非动画对象,还包含简单的几何体和粒子特效(如几何战争这样的游戏)。
#### 【】组织动态批处理的唯一条件 如果阻止两个对象动态批处理的唯一条件是,它们**使用了不同的纹理**,就应该花点时间和精力**合并纹理**(通常称为图集),并重**新生成网格UV**,以便进行动态批处理。这可能会牺牲纹理的质量,或者纹理文件会变大(这是需要知道的缺点,第6章深入讨论GPU内存带宽时详细论述),但这是值得的。
无
2021-03-24
**要渲染大量的简单网格时,动态批处理是非常有用的工具。**
无
2021-03-19
为了使场景中动态批处理的数量保持合适的水平,需要连续不断地检查Draw Call数量,并观察Frame Debugger数据,以确保最新的修改不会意外取消对象的动态批处理资格。然而,与往常一样,如果证实这会造成性能瓶颈,那么仅需要关心Draw Call性能。
无
2021-03-24 ### 3.5 静态批处理 静态批处理系统有自己的要求: 顾名思义,
- 网格必须标记为Static(具体而言是Batching Static) 每个被静态批处理的网格都需要额外的内存。
- 合并到静态批处理中的顶点数量是有上限的,并随着Graphics API和平台的不同而不同,一般为32~64K个顶点(具体信息请查看文档/前述的博客)。
网格实例可以来自任何网格数据源,但它们必须使用相同的材质引用。
无
2021-03-24
静态批处理的额外内存需求取决于批处理的网格中复制的次数。
静态批处理在工作时,将所有标记为Static的可见网格数据复制到一个更大的网格数据缓冲中,并通过一个Draw Call传到管线渲染中,同时忽略原始网格。如果所有进行静态批处理的网格都各不相同,那么与正常渲染对象相比,这不会增加内存使用量,因为存储网格需要的内存空间量是相同的。
如果网格各不相同,与不使用“静态批处理”所使用的的内存是相同的。
【】静态批处理可以节省内存
2021-03-07
使用静态批处理渲染1000个相同的树对象,消耗的内存是不使用静态批处理渲染相同树的1000倍。
如果没有正确地使用静态批处理,将导致一些严重的内存消耗和性能问题。
【】静态批处理何时生效
2021-03-07
试图确定静态批处理在场景中的整体效果有一些困难,因为在Edit模式下静态批处理没有生效。这些处理在运行时生效,因此在手动测试之前,难以确定静态批处理提供了什么优势。应该使用Frame Debugger来验证静态批处理是否正确生成,以及是否包含了预期的对象。
无
2021-03-19
大多数情况下,应该尝试让任何期望被静态批处理的网格出现在场景的原始文件中。然而,如果需要动态实例化,或者使用叠加方式加载场景,就可以使用StatciBatchUtility.Combine()方法控制静态批处理。该工具方法有两个重载形式:一个形式需要提供根GameObject,该对象中所有带网格的子GameObject对象都会转换到新的静态批处理组中(如果使用了多个材质,就会创建多个组),另一种重载形式需要提供GameObject列表和一个根GameObject,该重载形式会自动将列表中的对象作为根对象的子节点,以相同的方式生成新的静态批处理组。
无
2021-03-19
静态批处理总结 静态批处理是一种强大但危险的工具。如果使用得不明智,就很容易通过内存消耗(可能导致应用程序崩溃)和应用程序的渲染成本造成巨大的性能损失。它还需要大量的手动调整和配置,以确保正确生成批处理,也不会由于使用各种Static标记而意外引发一些不期望的负面效果。然而,它有一个显著的优势:它可以用于不同形状和巨大尺寸的网格,这是动态批处理无法提供的。
无
2021-03-24
3.6 本章小结
动态批处理和静态批处理系统不是银弹。我们不能盲目地将它们应用到任何场景上,并期望得到性能提升。如果应用程序和场景碰巧符合它的一系列参数,那么这些方法就能显著地减少CPU负载和渲染瓶颈。否则,就需要做一些额外的工作,给场景做一些准备,使之满足批处理特性的需求。总之,只有深刻理解了这些批处理系统以及它们的工作原理,才能帮助我们确定这项特性可以在何时何地使用。
需要深刻理解
2021-03-07
大量简单网格 : 动态批处理
不同形状、巨大网格 : 静态批处理
第4章 着手处理艺术资源
如何存储、加载和维护这些资源
无
2021-03-24
4.1 音频
运行时音频处理会成为CPU和内存消耗的重要来源。
无
2021-03-24
在Project窗口中选中导入的音频文件时,Inspector窗口将显示多个导入设置。这些设置决定了一切,包括加载行为、压缩行为、质量、采样率,以及(在Unity的后期版本中)是否支持双声道音频(多通道音频,通过球面谐波组合音轨,以创建更真实的音频体验)。
无
2021-03-24
通过以下3种设置可以指定音频文件的加载方式:
- Preload Audio Data
- Load In Background
- Load Type
#### 【】Preload Audio Data 2021-03-29
禁用Preload Audio Data会告诉Unity引擎,在场景初始化期间跳过音频文件资源的加载,这会将加载活动推迟到需要使用音频文件时,换句话说,**当调用Play()或PlayOneShot()时****加载****音频文件**。禁用此选项将加快场景初始化,但这也意味着第一次播放文件时,CPU需要立即访问磁盘,检索文件,将其加载到内存,解压缩并播放。这是一个**同步操作**,它将阻塞主线程直到其完成
【】Load In Background
2021-03-29
使用Load In Background选项。该选项会将音频加载更改为异步任务;因此,加载不会阻塞主线程。启用此选项后,对AudioClip.LoadAudioData()的实际调用将立即完成,但请记住,在单独线程上完成加载之前,文件还没准备好用于播放。可以通过AudioClip.loadState属性来复查AudioClip组件的当前加载状态
2021-03-29
现代游戏通常在关卡中实现方便的停止点,以执行诸如加载或卸载音频数据之类的任务——例如,几乎不发生任何操作的楼间电梯或长走廊
【】Load Type
2021-03-29
最后是Load Type选项,它指示音频数据如何加载。有3种选择: Decompress On Load Compressed in Memory Streaming
无
2021-03-29
1- Decompress On Load
此设置压缩磁盘上的文件以节省空间,并在首次加载时将其解压缩到内存中。这是加载音频文件的标准方法,应该在大多数情况下使用。解压缩文件需要一段时间,这会导致加载过程中的额外开销,但会减少播放音频文件时所需的工作量。
2021-03-29
2- Compressed In Memory
此设置在加载音频时只是将其直接从磁盘复制到内存中。只有在播放音频文件时,才会在运行期间对其进行解压缩。这将在播放音频剪辑时牺牲运行时CPU,但在音频剪辑保持休眠状态时,提高了加载速度,减少了运行时内存消耗。因此,此选项最适合频繁使用的大型音频文件;或者在内存消耗上遇到难以置信的瓶颈,并且愿意牺牲一些CPU周期来播放音频剪辑。
加载快,用时解压缩,播放时牺牲一些CPU周期。
2021-03-07
3- Streaming
最后,此设置(也称为缓冲)将在运行时加载、解码和播放文件,具体做法是逐步将文件推过一个小缓冲区,在缓冲区中一次只存在整个文件的一小部分数据。此方法对特定音频剪辑使用的内存量最小,但运行时CPU使用的内存量最大。由于文件的每个回放实例都需要生成自己的缓冲区,因此此设置有一个不幸的缺点,即多次引用音频剪辑,会导致内存中同一音频剪辑的多个副本必须单独处理,如果胡乱使用,会导致运行时CPU成本。因此,此选项最好用于定期播放的单实例音频剪辑,这种音频剪辑不需要与自身的其他实例或甚至与其他流式音频剪辑重叠。例如,此设置最好与背景音乐和环境音效一起使用,这些音效需要在场景的大多数时间里播放。
无
2021-03-29
【】音频剪辑编码格式
PCM、Vorbis、ADPCM
2021-03-29
与Compressed设置一起使用的压缩算法取决于目标平台
2021-03-29
Ogg Vorbis压缩格式在解压缩时,其大小通常是压缩大小的10倍左右,而ADPCM在解压缩时,其大小是压缩大小的4倍左右。
2021-03-29
PCM格式是一种无损的、未压缩的音频格式,提供接近模拟音频的效果。它以更大的文件大小换取更高的音频质量,最适用于极短暂且需要高清晰度的音效,否则任何压缩都会降低体验。【人声】
2021-03-29
ADPCM格式在大小和CPU消耗方面都比PCM高效得多,但是压缩会产生相当大的噪声。如果将其作为具有大量混乱的短声音效果,例如爆炸、碰撞和冲击声音,则可以隐藏噪声,而我们不会注意到任何产生的失真。【特效】
2021-03-29
理解了音频文件格式、加载方法和压缩模式后,接着探索一些通过调整音频行为来提高性能的方法。
无
2021-03-29
1.最小化活动音源数量
2021-03-29
由于这些工具通常提供许多更微妙的性能增强功能,因此建议使用预先存在的解决方案,而不是推出自己的解决方案,因为从音频文件类型、立体声/3D音频、分层、压缩、过滤器、跨平台兼容、高效内存管理等方面考虑有很多复杂性。
2021-03-29
2.为3D声音启用强制为单声道
2021-03-29
在立体声音频文件上启用Force to Mono(强制为单声道)设置会将来自两个音频通道的数据混合到一个通道中,文件的总磁盘和内存空间使用量有效地降低了50%。一般不要给二维音效启用此选项,二维音效通常用于创建特定的音频体验
2021-03-29
3.重新采样到低频
2021-03-29
4.考虑所有的压缩格式
2021-03-29
5.注意流媒体
2021-03-29
6.通过混音器组应用过滤效果以减少重复
2021-03-29
一个文件可以通过一组不同的过滤器进行调整,以产生完全不同的声音效果。
2021-03-29
音频混音器的官方教程非常详细地介绍了该主题: https://unity3d.com/learn/tutorials/modules/beginner/5-pre-order-beta/audiomixer-and-audiomixer-groups
2021-03-29
7.谨慎地使用远程内容流
【】托管资源丢弃引用会自动释放资源
2021-03-29
WWW类提供audioClip属性,如果AudioClip对象是通过WWW对象下载的音频文件,则该属性用于访问AudioClip对象。但是,请注意,访问此属性将在每次调用时分配一个全新的AudioClip资源,类似于其他WWW资源获取方法。一旦不再需要此资源,就必须使用Resources.UnloadAsset()方法释放它。 不像托管资源,丢弃引用(将引用设置为null)不会自动释放这些资源,因而它会持续占用内存。因此,应当仅通过audioClip属性获取一次AudioClip,此后仅使用该AudioClip引用,当不再需要时释放它。
2021-03-29
在Unity 2017中,WWW类已被UnityWebRequest类替代,它使用了新的HLAPI和LLAPI网络层。这个类提供了各种实用程序来下载和访问以文本文件为主的内容。基于多媒体的请求应该通过UnityWebRequestMultimedia辅助类发送。因此,如果请求AudioClip,就应调用UnityWebRequestMultimedia.GetAudioClip()创建请求,调用DownloadHandlerAudioClip.GetContent()在下载完成后取出音频内容。 新版本的API旨在更有效地存储和提供请求的数据,通过DownloadHandlerAudio- Clip.GetContent()多次重新获取音频剪辑不会导致额外的分配。相反,它只返回对最初下载的音频剪辑的引用。
2021-03-29
8.考虑用于背景音乐的音频模块(Audio Module)文件
2021-03-29
4.2 纹理文件
在游戏开发中经常混淆纹理和精灵的概念,因此需要区分它们——纹理只是简单的图像文件、一个颜色数据的大列表,以告知插值程序,图像的每个像素应该是什么颜色,而精灵是网格的2D等价物,通常只是一个四边形(一对三角形合并成的长方形网格),用于渲染面向当前相机的平面
2021-03-29
纹理图像文件通常由类似Adobe Photoshop或Gimp等工具生成,接着以类似音频文件的方式导入项目中。在运行时,这些文件加载进内存,推送到GPU的显存,并在给定的Draw Call期间,由着色器渲染到目标精灵或网格上。
2021-03-29
1.减小纹理文件的大小
【】Scene窗口的Mipmaps
2021-03-19
将Scene窗口的Draw Mode设置切换为Mipmaps,可以观察应用程序中某些时刻使用了哪个Mip Map级别。在玩家的当前视图中,如果纹理大于它们的合适大小(浪费了额外的细节),纹理就以红色高亮显示;而如果纹理太小,则会以蓝色高亮显示,说明玩家正在以很差的纹理像素比观察低质量的纹理。
【】禁用Anisotropic Filtering
2021-03-19
无论哪种情况,靠近相机的线都相当清晰,但与相机距离变远时则发生变化。没有开启Anisotropic Filtering时,距离相机越远的线越模糊不清,而开启Anisotropic Filtering时,这些线依然清晰。 应用于纹理的Anisotropic Filtering的强度可以通过Aniso Level设置逐个纹理地手动修改,也可以在Edit | Project | Quality设置内使用An****isotropic Textures选项全局启用/禁用该特性。 与Mip Mapping很像,Anisotropic Filtering很昂贵,有时没有必要使用。如果场景中的一些纹理肯定不会从倾斜的角度看到(例如远处的背景对象、UI元素、公告板粒子效果纹理),就可以安全地禁用Anisotropic Filtering,以节省运行时开销。
开启之后,距离相机很远,依然会很清晰
2021-03-08
5.考虑使用图集
2021-03-08
图集是一种技术,它将许多较小的、独立的纹理合并到一个较大的纹理文件中,从而最小化材质的数量,因此最小化所需使用的Draw Call数量
2021-03-08
需要做的额外工作是修改网格或精灵对象的UV坐标,只采样大纹理文件中所需的部分,但好处是明显的;如果程序的瓶颈在CPU,则减少Draw Call就会降低CPU工作负载,提升帧率
2021-03-08
图集是在UI元素和包含许多2D图形的游戏中应用的一种常见策略。当使用Unity开发移动游戏时,图集是必不可少的技术,因为在这些平台上,Draw Call会成为最常见的瓶颈。然而,我们不希望手动生成这些图集文件。如果可以继续逐个编辑纹理,并自动将它们合并到一个大文件中,事情将变得更简单。 Unity资源商店有很多与GUI相关的工具,这些工具提供了自动将纹理打包到图集的特性。在互联网上有一些独立的程序,可以处理这项工作,而Unity能以资源的形式为精灵生成图集。这可以通过Asset | Create | Sprite Atlas创建。
2021-03-08
图集不一定要用于2D图形和UI元素。如果创建了很多低分辨率的纹理,则可以将此技术应用到3D网格上。若3D游戏具有简单纹理的分辨率,或是扁平着色的低多边形风格,都可以这种方式使用图集。
2021-03-09
由于动态批处理效果只影响非动画的网格(也就是MeshRenderer而不是SkinnedMeshRenderer),因此不要将动画角色的纹理文件合并到图集。由于它们是动画的,GPU需要将每个对象的骨骼乘以当前动画状态的变换。这意味着需要为每个角色进行独立的计算,不管他们是否共享了材质,该计算都将导致额外的Draw Call。
2021-03-09
图集的缺点主要是开发时间和工作流成本。要彻底检查现有的项目才能使用图集,这需要花费大量的精力,只是为了辨别是否值得使用图集就需要做很多工作。此外,还需要注意纹理文件的生成,这对于目标平台来说可能太大了。
2021-03-09
通常来说,如果移动游戏采用非常简单的2D艺术风格,就可能不需要使用图集。然而,如果移动游戏尝试使用高质量的资源或任何类型的3D图形,就应该尽可能在开始开发时集成图集,因为很可能项目很快就达到纹理吞吐量的限制,甚至可能需要对每个平台和每个设备做优化,以吸引更广泛的受众。 与此同时,应该仅在Draw Call数量超过硬件可接受的合理范围时,才考虑将图集应用到高质量的桌面游戏中,因为依然想让很多纹理保持高分辨率,以使品质最大化。低品质的桌面游戏也可能避免使用图集,因为Draw Call很可能不是最大的瓶颈。 当然,不管什么产品,如果由于Draw Call太多而受限于CPU,也尝试过其他替代技术,那么图集在多数情况下是非常有效的性能提升方案。
2021-03-08
6.调整非方形纹理的压缩率
2021-03-08
第一个建议是避免非正方形和/或非2的n次幂的纹理。如果图形可以放到2的n次幂的方形纹理中,不会由于挤压/拉伸而导致品质下降太多,就应该做出这些修改,以获得更好的CPU和GPU性能
2021-03-08
7.Sparse Textures Sparse Textures
也称为Mega-Textures或Tiled-Textures,提供了一种运行时从磁盘传输纹理数据流的方式。相对而言,如果CPU以秒为单位执行操作,那么磁盘将以天为单位执行操作。因此,通常的建议是,应该尽可能避免游戏运行时的硬盘访问
2021-03-09
Unity开发人员如果认为自己的水平足够高,可以尝试Sparse Texturing了,应该花点时间进行一些研究,以检查Sparse Texturing是否适合他们的项目,因为它可以显著地提升性能。
2021-03-09
8.程序化材质
程序化材质也称为Substances
是一种在运行时通过使用自定义数学公式混合小型高质量的纹理样本,通过程序化方式生成纹理的手段。程序化材质的目标是在初始化期间以额外的运行时内存和CPU处理为代价,极大地减少应用程序的磁盘占用,以便通过数学操作而不是静态颜色数据来生成纹理。 纹理文件有时是游戏项目中最大的磁盘空间消耗者,众所周知,下载时间对下载完成率和人们尝试游戏有着巨大的负面影响(甚至游戏是免费的)。程序化材质允许牺牲一些初始化和运行时处理能力,以换取更快速的下载。这对于想要通过图形逼真度进行竞争的移动游戏很重要。
2021-03-09
9.异步纹理上传
【】禁用Read/Write Enable
最后一个还没提到的纹理导入选项是Read/Write Enable。
默认情况下,该选项是禁用的,禁用该选项的好处是纹理可以使用Asynchronous Texture Uploading特性,该特性有两个优势:纹理会从磁盘异步上传到RAM中;且当GPU需要纹理数据时,传输发生在渲染线程,而不是主线程。纹理会推送到环形缓冲区中,一旦缓冲区中包含新数据,数据就会持续不断地推送到GPU。如果缓冲区中没有新数据,就提前退出处理并等待,直到请求新的纹理数据。 最终,这减少了每帧准备渲染状态所花费的时间,允许将更多的CPU资源花在游戏玩法、物理引擎等逻辑模块中。当然,有时依然在主线程中花费时间准备渲染状态,但将纹理上传任务移到一个独立线程,节省了主线程中大量的CPU时间。
然而,开启纹理的读写访问功能,本质上是告知Unity,我们想要随时读取和编辑该纹理。这暗示着GPU需要随时刷新对它的访问,因此禁用该纹理的异步纹理上传功能;所有上传任务必须在主线程中执行。我们可能想要开启该选项,以模拟在画布上画画,或者将网络上的图像数据写入已有的纹理,但缺点是在纹理上传之前,GPU必须始终等待对纹理所做的修改,因为无法预测什么时候发生变更。
“纹理上传任务(到GPU的VRAM中)”移到一个独立线程,节省了主线程中大量的CPU时间
另外,由于异步纹理上传特性仅适用于明确导入到项目中且在构建时存在的纹理,因为该特性仅在纹理打包到可流式传输的特殊资源中才会生效,所以,任何通过LoadImage(byte[])生成的纹理,由外部位置导入或下载的纹理,或者通过Resources.Load从Resources文件夹加载的纹理(它们都隐含LoadImage(byte[])调用)都不会转换为可流式传输的内容,因此无法使用异步纹理上传特性。
异步纹理上传特性允许花费的时间上限和Unity为了推送要上传的纹理而使用的循环缓冲区总大小都是可以调整的。可以在Edit | Project Settings | Quality | Other菜单下进行设置,设置选项分别为Async Upload Time Slice和Async Upload Buffer Size。
【】设置一个合适的Async Upload Buffer Size值
Async Upload Time Slice的值可以设置为期望Unity在渲染线程中花费在异步纹理上传的最大毫秒数。将Async Upload Buffer Size值设置为可能需要使用的最大纹理文件的大小或许是明智的,如果在同一帧需要加载多个新的纹理,就需要再增加一点儿额外的缓冲区。复制纹理数据的循环缓冲区会根据需要拓展大小,但这通常比较昂贵。由于我们可能已经提前知道所需循环缓冲区的大小,因此也可以将它设置为期望大小的最大值,以避免需要重新调整缓冲区大小时导致的潜在帧率下降。
【】调整“异步上传”允许花费的时间上限
2021-03-24
异步纹理上传特性允许花费的时间上限和Unity为了推送要上传的纹理而使用的循环缓冲区总大小都是可以调整的。
可以在Edit | Project Settings | Quality | Other菜单下进行设置,设置选项分别为Async Upload Time Slice和Async Upload Buffer Size。
Async Upload Time Slice的值可以设置为期望Unity在渲染线程中花费在异步纹理上传的最大毫秒数。
将Async Upload Buffer Size值设置为可能需要使用的最大纹理文件的大小或许是明智的,如果在同一帧需要加载多个新的纹理,就需要再增加一点儿额外的缓冲区。复制纹理数据的循环缓冲区会根据需要拓展大小,但这通常比较昂贵。由于我们可能已经提前知道所需循环缓冲区的大小,因此也可以将它设置为期望大小的最大值,以避免需要重新调整缓冲区大小时导致的潜在帧率下降。
2021-03-24
4.3 网格和动画文件
网格和动画文件。这些文件类型其实是顶点和蒙皮骨骼数据的大型数组,可以应用各种技术最小化文件大小,同时使其外观相似,却不完全相同
2021-03-24
4.3.1 减少多边形数量
这是提升性能的最明显的方法,应该始终加以考虑。事实上,由于不能使用Skinned Mesh Renderer对对象进行批处理,这是减少动画对象的CPU和GPU运行时开销的好方法之一。
2021-03-24
4.3.2 调整网格压缩
Unity为导入的网格文件提供了4种不同的网格压缩设置:Off、Low、Medium和High。增加此设置将把浮点数据转换为固定值,降低顶点位置/法线方向的精度,简化顶点颜色信息等。这对包含许多彼此相邻的小部件(比如栅栏或格栅)的网格有明显的影响。如果通过程序生成网格,就可以通过调用MeshRenderer组件的Optimize()方法来实现相同类型的压缩(当然,这需要一些时间来完成)。
2021-03-24
Edit | Project Settings | Player | Other Settings中也有两个全局设置,可以影响网格数据的导入方式。这两个设置选项为Vertex Compression和Optimize Mesh Data。
2021-03-24
可以使用Vertex Compression选项配置在启用Mesh Compression的情况下导入网格文件时被优化的数据类型,因此,如果想要精确的法线数据(用于照明),但不关心位置数据,就可以在这里配置它。遗憾的是,这是一个全局设置,会影响所有导入的网格(但它可以基于每个平台进行配置,因为它是一个Player设置)。 开启Optimize Mesh Data将剔除该网格当前使用的材质所不需要的数据。因此,如果网格包含切线信息,但着色器不需要切线信息,那么Unity将在构建期间忽略它。 在每种情况下,这样做的好处是减少了应用程序的磁盘占用,却要花费额外的时间来加载网格,因为在需要数据之前必须花费额外的时间解压缩数据。
2021-03-10
如果使用,应该进行严格的测试。
2021-03-10
如果网格经常在运行时以不同的比例重新出现,那么Unity需要将这些数据保存在内存中,以便更快地重新计算新的网格,因此启用Read-Write Enable标志是明智的。要禁用它,Unity不仅需要在每次重新引入网格时重新加载网格数据,还需要同时制作重新缩放的副本,这会导致潜在的性能问题。
2021-03-10
4.3.4 考虑烘焙动画 【新知识】
这个技巧需要通过当前使用的3D套索和动画工具修改资产,因为Unity本身不提供这样的工具。动画通常存储为关键帧信息,它跟踪特定的网格位置,并在运行时使用蒙皮数据(骨骼形状、赋值、动画曲线等)在它们之间插值。与此同时,烘焙动画意味着不需要插值和蒙皮数据,就可以有效地将每帧每个顶点的每个位置****采样并硬编码到网格/动画文件中。
2021-03-10
4.3.5 合并网格
将网格强力地合并成单个的大型网格,便于减少Draw Call,特别是当网格对于动态批处理来说太大,不能与其他静态批处理组很好地配合时。这本质上等同于静态批处理,但它是手动执行的,所以,如果静态批处理可以处理这个过程,我们就不必浪费精力了。
4.4 Asset Bundle和Resource
【】从此以后远离使用Resource
当涉及构建时,Resource System的可伸缩性不是很大。所有资源都合并到一个大型序列化文件二进制数据blob中,其中包含一个索引列表,列出了可以在其中找到的各种资产。向列表中添加更多的数据时,这可能很难管理,并且需要很长时间来构建。
2021-03-24
其次,Resource System以**Nlog(N)**的方式从序列化文件中获取数据,所以需要警惕N的值。再次,Resource System使应用程序难以基于每个设备提供不同的素材数据,而Asset Bundle很容易实现这一点
2021-03-24
Asset Bundle与Resource拥有许多相同的功能,比如从文件中加载,异步加载数据和卸载不再需要的数据。然而,Asset Bundle还提供了更多的功能,如内容流式传输、内容更新、内容生成和共享。这些都可以极大地提高应用程序的性能。可以提供磁盘空间占用更小的应用程序,让用户在开始游戏之前或游戏运行过程中下载额外的内容,在运行时流式传输素材,以最小化应用程序的首次加载时间,基于每个平台提供更优化的素材,而不是给用户推送完整的应用程序。
2021-03-24
下面发于2017年4月的Unity博客帖子展示了Asset Bundle系统如何在运行期间更高效地使用内存,Resource System无法通过内存池提供该方式: https://blogs.unity3d.com/2017/04/12/asset-bundles-vs-resources-a-memory-showdown/
第5章 加速物理
物理引擎是一类独特的子系统,其行为和一致性是影响产品质量的主要因素,花时间改进其行为通常是值得的。
2021-03-24
理解Unity的物理引擎如何工作:
- 时间步长和FixedUpdate
- 碰撞器类型
- 碰撞
- 射线发射
- 刚体激活状态
物理性能优化:
- 如何构造场景以优化物理行为
- 使用相应的碰撞器类型
- 优化碰撞矩阵
- 提升物理一致性并避免容易出错的行为
- 布娃娃(Ragdoll)和其他基于关节的(Joint-based)对象
2021-03-29
5.1 物理引擎的内部工作情况
Unity技术上有两种不同的物理引擎:用于3D物理的Nvidia的PhysX和用于2D物理的开源项目Box2D。
然而,Unity对它们的实现是高度抽象的,从通过主Unity引擎配置的更高级别Unity API的角度来看,两个物理引擎解决方案以功能相同的方式运行。
2021-03-29
该时间步长在Unity中称为Fixed Update Timestep,它的值默认设置为20毫秒(每秒50次更新)。
【】Unity完整执行顺序图
2021-03-29
完整的执行顺序图可以通过下面的网址找到:
https://docs.unity3d.com/Manual/ExecutionOrder.html
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-d7Igq2Bf-1624418015856)(https://cdn.nlark.com/yuque/0/2021/svg/158471/1619069851762-da52f58f-13a1-4db9-ab34-555b4b1427a0.svg#align=left&display=inline&height=2397&margin=%5Bobject%20Object%5D&originHeight=2397&originWidth=1151&size=0&status=done&style=none&width=1151)]
【】复盘
第一次 : 物理 、输入、游戏逻辑、渲染
第二次 : 物理、输入、游戏逻辑、Scene渲染、GUI渲染、退出释放资源
2021-03-29
为了确保对象在固定更新之间平稳移动,物理引擎(Unity内的)根据下一次固定更新之前的剩余时间,在处理当前状态之后,在上一个状态和应处于的状态之间对每个对象的可见位置进行插值。这种插值可以确保对象的移动非常平稳,尽管它们的物理位置、速度等更新的频率低于渲染帧率。
2021-03-29
1.最大允许的时间步长
需要注意的是,如果自上次固定更新(例如,游戏暂时卡顿)以来已经过了很长时间,那么固定更新将继续在相同的固定更新循环中计算,直到物理引擎赶上当前时间。如果上一帧花了100ms用于渲染(例如,一个突然的CPU峰值导致主线程阻塞了很长时间),那么物理引擎将需要更新5次。由于默认固定更新的时间步长为20毫秒,在再次调用Update()之前还需要调用5次FixedUpdate()方法。当然,如果在这5次固定更新时有很多物理活动需要处理,例如总共花费了超过20毫秒处理它们,那么物理引擎将继续调用第6次更新。 因此,在物理活动较多时,物理引擎处理固定更新的时间可能比模拟的时间要长。例如,如果用30毫秒来处理一个固定的更新,模拟20毫秒的游戏,它就已经落后了,需要它处理更多的时间步长来尝试和跟上,但这可能会导致它落后得更远,需要它处理更多的时间步长,等等。在这些情况下,物理引擎永远无法摆脱固定的更新循环,并允许另一帧进行渲染。这个问题通常称为死亡螺旋。
但是,为了防止物理引擎在这些时刻锁定游戏,存在允许物理引擎处理每个固定更新循环的最长时间。此阈值称为允许的最大时间步长(Maximum Allowed Timestep),如果当前一批固定更新的处理时间太长,则它将停止并放弃进一步的处理,直到下一次渲染更新完成。这种设计允许渲染管线至少将当前状态进行渲染,并允许用户输入以及游戏逻辑在物理引擎出现异常的罕见时刻做出一些决策。 该设置可以通过Edit | Project Settings | Time | Maximum Allowed Timestep来访问。
2021-03-29
2. 物理更新和运行时变化
当物理引擎以给定的时间步长处理时,它必须移动激活的刚体对象(带有Rigidbody组件的GameObject),检测新的碰撞,并调用相应对象的碰撞回调。Unity文档明确指出,应在FixedUpdate()和其他物理回调中处理对刚体对象的更改,原因正是如此。这些方法与物理引擎的更新频率紧密耦合,而不是游戏循环的其他部分,如Update()。 这意味着,诸如FixedUpdate()和OnTriggerEnter()的回调函数是安全更改Rigidbody的位置,而诸如Update()和对WaitForSeconds或WaitForEndOfFrame的协程则不是。忽略这一建议可能会导致意想不到的物理行为,因为在物理引擎有机会捕获和处理所有这些对象之前,可能会对同一个对象进行多次更改。 对Update()回调中的对象应用力或脉冲而不考虑这些调用的频率是特别危险的。
物理系统相关的更改放在FixedUpdate、OnColliderEnter等物理函数中?
2021-03-10
从逻辑上讲,在任何给定的固定更新迭代中花费的时间越多,在下一次游戏逻辑和渲染过程中的时间就越少。由于物理引擎几乎没有任何工作要做,而且FixedUpdate()回调有很多时间来完成它们的工作,因此大多数情况下这会导致一些小的、不明显的后台处理任务。然而,在某些游戏中,物理引擎可能在每次固定更新期间执行大量计算。这种物理处理时间上的瓶颈会影响帧率,导致它在当物理引擎负担越来越大的工作负载时急剧下降。基本上,渲染管线将尝试正常进行,但每当需要进行固定更新时(物理引擎处理时间很长),渲染管线在帧结束之前几乎没有时间生成当前画面,导致突然的停顿。还要加上物理引擎过早停止的视觉效果,因为它达到了Maximum Allowed Timestep。所有这些加在一起会产生非常糟糕的用户体验。
2021-03-10
动态碰撞器只意味着GameObject包含Collider(多个碰撞器类型中的一个)组件和Rigidbody组件。通过将Rigidbody添加到Collider所附加的相同对象上,物理引擎将会将该碰撞器视为带有包围物理对象的立体,它会对外部的力(例如重力)和与其他Rigidbody的碰撞做出反应。如果一个动态碰撞器与另一个碰撞器发生碰撞,它们都会基于牛顿运动定律做出反应
2021-03-10
也可以使用没有附加Rigidbody组件的碰撞器,这种称为静态碰撞器。这种碰撞器有效地起到了无形屏障的作用,动态碰撞器可以撞到这些屏障,但是静态碰撞器不会做出响应。
【】3种碰撞检测机制
2021-03-10
Discrete设置可以实现离散碰撞检测,有效地根据物体的速度和经过的时间,在每个时间步长将对象传送一小段距离。一旦所有对象都被移动了,物理引擎就会对所有重叠执行边界立体检查,将它们视为碰撞,并根据它们的物理属性和重叠方式来处理它们。如果小对象移动得太快,此方法可能会有丢失碰撞的风险。
其余的两个设置都将启用连续碰撞检测,其工作方式是从当前时间步长的起始和结束位置插入碰撞器,并检查在这个时间段中是否有任何碰撞。这降低了错过碰撞的风险,生成了更精确的模拟,但代价是CPU开销显著高于离散碰撞检测。
Continuous设置仅在给定碰撞器和静态碰撞器之间启用连续碰撞检测。
同一碰撞器与动态碰撞器之间的碰撞仍将使用离散碰撞检测。
同时,ContinuousDynamic设置使碰撞器与所有静态和动态碰撞器之间能够进行连续碰撞检测,其在资源消耗方面最为昂贵。
2021-03-10
在绝大多数情况下,物体在20毫秒的时间步长内移动的距离相对于物体的大小要小得多,因此碰撞很容易被离散碰撞检测方法捕获。
| 但做实验的时候发现了一个很诡异的事情,就是发生碰撞的主体一定是要带刚体的,即只有带刚体的碰撞体****去撞其他碰撞体时,双方才会收到碰撞事件,以下是我做的实验:
一、控制A(刚体加碰撞体)撞击 静止的B(只有碰撞体),双方能收到碰撞事件。
二、控制B(只有碰撞体)撞击 静止的A(刚体加碰撞体),双方收不到碰撞事件。
三、让A(刚体加碰撞体)自由下落,然后控制B(只有碰撞体)去撞击A,双方能受到碰撞事件。
| 得出的结论似乎是如果碰撞双方只有一个有刚体,那么那个刚体一定要处于运动的状态下才会有碰撞事件发生。 |
|---|
【】关于“碰撞”的总结
根据上面的实验得出,如果要收到触发事件,必须满足如下三个条件:
- 必须都要有碰撞器组件(Collider),其实上面的碰撞事件同样也需要这个前提条件。
- 必须有一个物体带刚体组件,并且处于运动状体中(包括主动运动去撞击别人和在运动过程中被别人撞击)。
- 产生触发事件的两个物体会相互穿越,准确的说是因为开启IsTrigger那个物体会被物理引擎锁忽略掉,所以会产生两个物体穿越的情况
2021-03-12
有两种不同的网格碰撞器:Convex(凸的)和Concave(凹的)。不同之处在于,凹形形状至少具有一个大于180° 的内角(形状的两个内部边缘之间的角度)
【】触发体积,非物理对象
2021-03-12
碰撞器组件还包含IsTrigger属性,允许将它们视为非物理对象,但当其他碰撞器进入或离开它们时仍调用物理事件。这些称为触发体积(Trigger Volume)
【】凹形只能做“静态碰撞器”/“触发体积”
2021-03-12
请注意,由于处理物体间碰撞的复杂性,凹面网格碰撞器不能是动态碰撞器。凹形只能用作静态碰撞器或触发体积。如果试图将Rigidbody组件添加到凹面网格碰撞器中,Unity将完全忽略它。
【】碰撞矩阵
2021-03-12
物理引擎具有一个碰撞矩阵,该矩阵定义允许哪些对象与哪些其他对象发生碰撞。当处理边界体积重叠和碰撞时,物理引擎将自动忽略不适合此矩阵的对象。这节省了碰撞检测阶段的物理处理,还允许对象彼此移动而不发生任何碰撞。
2021-03-12
碰撞矩阵系统通过Unity的层(Layer)系统工作。矩阵表示层与层每个可能的组合,启用复选框意味着在碰撞检测阶段将检查这两个层中的碰撞器
2021-03-12
请注意,对于整个项目,总共只能有32个层(因为物理引擎使用32位位掩码来确定层间冲突的机会),因此必须将对象组织为对层敏感,这些层将在整个项目生命周期中进行拓展
2021-03-12
用于确定静止状态的测量值,在不同的物理引擎中往往会有所不同;可以使用Rigidbody的线速度和角速度、动能、动量或其他一些物理属性来计算。Unity的两个物理引擎(2D和3D)都是通过评估物体的质量归一化动能来工作的,这基本上可以归结为物体速度平方的大小。
【】物理引擎休眠状态的阈值作用
2021-03-12
将阈值设置得太低,意味着对象不太可能进入休眠状态,因此继续在物理引擎中为每次固定更新消耗少量的处理成本,即使它不做任何重要的事情。
同时,如果将阈值设置得太高,则意味着一旦物理引擎决定缓慢移动的物体需要进入休眠状态,它们就会突然停止。可以在Edit | Project Settings | Physics | Sleep Threshold下修改控制休眠状态的阈值。还可以从Profiler窗口的Physics Area中获取活动Rigidbody对象的总数。
2021-03-12
比如射击。其实现方式通常是执行从玩家到目标位置的射线投射,并在其路径中找到任何符合的目标(即使它只是一堵墙)。
2021-03-12
还可以通过Physics.OverlapSphere()检查在空间中固定点的有限距离内获得目标列表。这通常用于实现效果区域的游戏功能,如手榴弹或火球爆炸。甚至可以使用Physics.SphereCast()和Physics.CapsuleCast()在空间中向前投射整个对象。这些方法通常用来模拟宽激光束,或者只是确定什么东西在移动角色的路径中。
【】调试物理问题的工具
2021-03-12
一个更适合帮助调试物理问题的工具是Physics Debugger,它可以通过Window | Physics Debugger打开。这个工具可以帮助从Scene窗口中过滤出不同类型的碰撞器,从而更好地了解哪些对象相互碰撞。当然,这对确定问题的条件和复现问题没有太大帮助。

2021-03-12
另一个经常让人头痛的原因是试图重现物理问题。由于用户输入(通常在Update()中处理)和物理行为(在FixedUpdate()中处理)之间的非确定性,重现冲突始终是一个挑战。尽管物理时间步长的发生具有相对的规律性,但是模拟在一个会话和下一个会话之间的每个Update()上都有不同的计时,因此即使记录了用户输入时间并自动重放场景,尝试在对应时刻应用记录的输入,每次也不会完全相同。所以可能得不到完全相同的结果。 可以将用户输入的处理移到FixedUpdate(),如果用户输入控制刚体的行为,诸如玩家按下某些按键,就将力应用到不同的方向,这种移动会有帮助。然而,这将可能导致输入等待或延迟,因为在物理引擎响应被按下的键之前,需要等待0到20毫秒(基于固定的更新时间步长频率)。如跳跃或激活行为这样的即时输入,通常为了避免按键丢失,最好总是在Update()中处理。诸如Input.GetKeyDown()的辅助函数,只会当玩家在当前帧按下给定按键时返回true,在下一次Update()时返回false。如果试图在FixedUpdate()时读取按键事件,将永远不知道用户按下了键,除非在这两个帧之间恰好发生了物理时间步长。这可以与输入缓冲/跟踪系统一起使用,但如果仅仅为了复现一个物理错误而实现该系统,那么肯定不值得。
2021-03-12
5.2 物理性能优化
【】所有对象位置接近(0,0,0)
同样,保持所有对象在世界空间的位置接近(0,0,0),将具有更好的浮点数精度,提高模拟的一致性。空间模拟器和自由运行游戏试图模拟非常大的空间,通常使用一个技巧,要么秘密地将玩家传送回世界的中心,要么固定它们的位置,在这种情况下,空间的任何一个体积都被划分,这样物理计算总是用接近0的值来计算
【】应该尽量使所有的物理物体接近(0,0,0)的坐标位置
2021-03-24
除非已经深陷于项目,以至于在后期改变和重新测试所有的东西都很麻烦,否则应该尽量使所有的物理物体接近(0,0,0)的坐标位置
【】运行中避免实例化、移动、旋转、缩放静态Collider对象
2021-03-12
物理引擎自动生成两个单独的数据结构,分别包含静态碰撞器和动态碰撞器。遗憾的是,如果在运行时将新对象引入静态碰撞器数据结构,那么必须重新生成它,类似于为静态批处理调用StaticBatchingUtility.Combine()。这可能会导致显著的CPU峰值。在游戏中避免实例化新的静态碰撞器是至关重要的。 此外,仅移动、旋转或缩放静态碰撞器也会触发此重新生成的过程,应避免。
【】开启 Kinematic 后的效果
2021-03-12
- 如果碰撞器希望在不与其他物体发生物理碰撞的情况下移动,那么应该附加一个Rigidbody,使其成为动态碰撞器,并开启Kinematic标志。此标志防止对象对来自对象间碰撞的外部脉冲做出反应,类似于静态碰撞器,但对象仍可以通过其Transform组件或通过施加到其Rigidbody组件上的力(最好在固定更新期间)移动。
- 由于Kinematic对象不会对撞击它的其他物体做出反应,它在运动时会简单地把其他动态碰撞器推开。
别人撞我,我不作出反应
我撞别人,把别人推开
#### 【】触发体积不适合处理“精确真实”的碰撞反应 2021-03-12
这两种类型的重要区别是OnCollider...()回调**提供了一个Collision对象**作为回调参数,它包括诸如精确的碰撞位置(能很好用于粒子特效的位置)和接触法线(如果希望在碰撞后手动移动对象)等有用信息,而OnTrigger...()回调则没有提供这类信息。
因此,不应该尝试使用触发体积对碰撞做出反应,因为没有足够的信息使得碰撞看起来准确。
2021-03-12
创建一个非触发体积对象,给它一个无穷小的质量(这样碰撞对象就不会受到它的影响),并在碰撞时立即摧毁它(因为质量差如此大的碰撞可能会使这个小对象非常活跃)。
【】碰撞矩阵检查
2021-03-12
应该对碰撞矩阵中所有潜在的层组合执行这样的逻辑健全性检查,以查看是否在浪费宝贵的****时间检查不必要的对象对之间的碰撞。
2021-03-12
【】5.2.5 首选离散碰撞检测
离散碰撞检测的消耗相当低,因为只传送一次对象并在附近的对象对之间执行一次重叠检查,在一个时间步长的工作量相当小。执行连续(Continuous)碰撞检测所需的计算量要大得多,因为它涉及在两个对象的起始位置和结束位置之间插入两个对象,同时分析这些点之间可能发生的任何轻微的边界体积重叠,因为它们可能在时间步长中发生。 因此,连续碰撞检测选项的消耗比离散检测方法高出一个数量级,而连续动态(ContinuousDynamic)碰撞检测设置的消耗甚至比连续碰撞检测高出一个数量级。将太多的对象设置为使用任意一种连续碰撞检测类型,都会导致复杂场景中的性能严重下降。在任何一种情况下,消耗都会乘以在任何给定帧期间需要比较的对象数量,无论比较碰撞器是静态的还是动态的。
2021-03-12
因此,应该支持绝大多数对象采用离散设置,而只在极端情况下使用连续碰撞检测设置。当重要的碰撞经常被游戏世界中比较静态的部分忽略时,应该使用连续设置。例如,如果希望确保玩家角色不会从游戏世界中掉落,或者不会在移动得太快时意外地穿越墙壁,就只对这些对象应用连续碰撞检测。最后,只有在希望捕捉快速移动的动态碰撞器对之间的碰撞的情况下才应该使用连续动态设置。
2021-03-12
【】5.2.6 修改固定更新频率
在某些情况下,离散碰撞检测在大范围内可能不够好。也许整个游戏包含着许多小的物理对象,而离散碰撞检测根本无法捕获足够的碰撞来保持产品质量。然而,将一个连续碰撞检测设置用于所有对象,对性能来说则太过昂贵了。在这种情况下,可以尝试一个选项:可以自定义物理时间步长,通过修改引擎检查固定更新的频率,为离散碰撞检测系统提供更好的捕获此类碰撞的机会。
增加这个值(减少频率),则在物理引擎再次处理物理过程之前为CPU提供更多的时间来完成其他任务,或者从另一个角度来看,在处理下一次物理计算之前给了物理引擎更多的时间来处理最后一个时间步长。
每次更改固定时间步长值时执行大量测试变得非常重要。即使完全理解了这个值的工作原理,也很难预测游戏过程中的总体结果是什么样子的,以及结果是否符合质量要求。
2021-03-12
创建一个测试场景可能是有帮助的,该场景将一些高速对象相互抛向对方,以验证结果是否可接受,并在进行固定时间步长更改时运行该场景。
【】支持和维护成本高于价值
2021-03-12
自动化测试的支持和维护成本往往高于它的价值
2021-03-12
总是把连续的碰撞检测作为最后的手段来抵消我们所观察到的一些不稳定性
2021-03-12
默认设置的消耗最大值是0.333秒,如果超过该值,则会显示为帧率的显著下降(仅3 FPS)
【】避免定期调用射线投射方法消耗大
2021-03-12
所有射线投射方法都非常有用,但它们相对于其他方法来说消耗较大,特别是CapsuleCast()和SphereCast()方法。应该避免在Update()回调或协程中定期调用这些方法,只在脚本代码中的关键事件调用它们。
【】触发体积替代射线检测
2021-03-13
- 如果在场景中使用持续的“线、射线或区域”效果碰撞区域(例如安全激光、持续燃烧的火焰、光束武器等),并且对象保持相对静止,那么使用简单的触发体积就可能更好地模拟它们。
【】如何减小射线的处理量
- 如果不能进行此类替换,且确实需要使用这些方法进行持久的投射检查,那么应该使用层遮罩来最小化每个射线投射的处理量。如果使用Physics.RaycastAll()方法,这一点尤其如此。
2021-03-13
一种更好的方法是使用RaycastAll()的另一个重载版本,它接受LayerMask值作为参数。该参数为射线过滤碰撞,其方式与碰撞矩阵一样,它仅对给定层的对象进行测试
2021-03-13
该优化对于Physics.RaycastHit()函数来说并不是很好,因为该版本只为射线与之碰撞的第一个对象提供光线碰撞信息,而不管是否使用LayerMask。
2021-03-13
图形和物理之间的这种分离表示允许优化一个系统的性能,而不(必然)对另一个系统产生负面影响。
【】超昂贵的3种碰撞器
2021-03-13
某些特殊的物理碰撞器组件,例如,TerrainCollider、Cloth和WheelCollider,在某些情况下比所有基础碰撞器甚至网格碰撞器的消耗都要高上几个数量级。不应该在场景中包含这些组件,除非它们是绝对必要的。
具有Cloth组件的游戏应该考虑在低质量环境下运行时,在没有这些组件的情况下实例化不同的对象,或者简单地设置布料行为的动画。
使用WheelCollider组件的游戏应该尽量少使用Wheel碰撞器。拥有4个以上车轮的大型车辆可以仅使用4个车轮模拟类似的行为,同时模拟附加车轮的图形表示。
【】大部分刚体都在休眠,不要随意添加刚体了
2021-03-13
物理引擎的休眠特性会给游戏带来一些问题。首先,一些开发人员没有意识到,许多刚体在应用程序的大部分生命周期中都在休眠。这往往会导致开发人员假设,可以(例如)在游戏中增加一倍的刚体数量,而总成本只会增加一倍。这种假设不太现实。碰撞频率和活动物体的总累积时间更有可能以指数形式而不是线性形式增加。每次在模拟中引入新的物理对象,都会导致意外的性能成本。当决定增加场景的物理复杂性时,应该记住这一点。
【】唤醒刚体
2021-03-13
其次,在运行时修改Rigidbody组件的任何属性,例如mass、drag以及useGravity会重新唤醒对象。
【】岛屿效应式“休眠”、链式反应式“唤醒”
2021-03-13
休眠的物理对象有产生岛屿效应的危险。当大量刚体互相接触,并随着系统动能的降低,逐渐休眠变形成岛屿。
然而,由于它们依然互相接触,一旦这些对象被唤醒,便会产生链式反应,唤醒周围的所有刚体。由于这一瞬间大量对象需要重新进入物理模拟,将会产生较大的CPU峰值。甚至,由于对象太近,在对象再次休眠之前,会有大量潜在的碰撞对需要处理。 最好通过降低场景的复杂性,以避免该情况,但如果发现无法做到这一点,可以寻找方法来检测岛屿的形成,然后战略性地销毁其中的一些,以防止产生大型岛屿。然而,在所有刚体之间进行定期的距离比较并不是一项很低消耗的任务。物理引擎本身已经在广泛阶段剔除期间执行了这样的检查,但是,Unity没有通过物理引擎API公开这些数据。任何解决这个问题的方法都取决于游戏的设计方式;
【?】休眠阈值
2021-03-13
注意,休眠阈值可以在Edit | Project Settings | Physics | Sleep Threshold下修改。
【】将刚体连接在一起=高成本
2021-03-13
在物理引擎中,使用关节、弹簧和其他方法将刚体连接在一起是相当复杂的模拟。由于将两个对象连接在一起而产生相互依赖的交互作用(内部表示为运动约束),系统必须经常尝试求解必要的数学方程。当物体链的任何一部分的速度发生变化时,需要使用这种多迭代方法来计算精确的结果。 因此,必须在限制处理器解决特定情况的最大尝试次数和限制所得结果的准确性之间找到平衡。处理器不应在一次碰撞上花费太多时间,因为物理引擎在同一次迭代中必须完成许多其他任务。但是,最大迭代次数也不应减少得太多,因为它只近似于最终的解决方案,所以它的运动看起来比用更多时间计算的结果更不可信。
【】 Default Solver Iterations
2021-03-13
处理器允许尝试的最大迭代次数称为Solver Iteration Count,可在Edit | Project Settings | Physics | Default Solver Iterations下修改
在大多数情况下**,六次迭代的默认值是完全可以接受的。然而,如果游戏包含非常复杂的关节(Joint)系统,就可能希望增加该次数,以防止任何不稳定(或完全爆炸)的CharacterJoint**行为,而一些项目可能期望通过减少这个次数而避免过高的计算。
为了真实的模拟刚体运动,需要多次迭代计算求解必要的数学方程。
【】减少迭代计算量方法2
2021-03-13
请注意,该值是默认的Solver Iteration Count——应用于任何新建的刚体。可以在运行时通过Physics.defaultSolverIterations属性修改此值,但这样做不会影响先前存在的刚体。如有必要,可以在刚体构造之后通过Rigidbody.solverIterations属性修改它们的Solver Iteration Count。
【】Default Solver Velocity Iterations
2021-03-13
如果发现游戏中使用复杂的基于关节的对象(如碎布娃娃)经常遇到不稳定、违反物理规则的情况,那么应该考虑逐渐增加Solver Iteration Count,直到问题被控制。如果布娃娃从碰撞的物体中吸收了太多的能量,处理器在被要求放弃之前无法将解迭代到合理的结果,则通常会出现这些问题。此时,其中一个连接点变成了超新星,把其余的连接点一起拖进了轨道。Unity对此问题有一个单独的设置,可以在Edit | Project Settings | Physics | Default Solver Velocity Iterations下找到。增大该值将使处理器有更多的机会在基于关节的对象碰撞期间计算合理的速度,并有助于避免上述情况。同样,这是一个默认值,因此它只应用于新创建的刚体。
可以在运行时通过Physics.defaultSolverVelocityIterations属性修改该值,也可以通过Rigidbody.solver- VelocityIterations属性在特定的刚体上自定义该值。
【】物理2D对处理器迭代次数的设置名
2021-03-13
物理2D对处理器迭代次数的设置名为Position Iterations和Velocity Iterations。
2021-03-13
暂时不谈在游戏世界里扔尸体会导致的发病率,我们可以看到一个复杂的物体链乱动,击中很多心理上有趣的点。
【】只有7个关节的布娃娃
2021-03-14
Unity在GameObject | 3D Object | Ragdoll…下提供了简单的布娃娃生成工具(布娃娃向导Ragdoll Wizard)。该工具可用于从给定的对象中创建布娃娃,具体方法是选择相应的子GameObject,以给任何给定身体部位或肢体附加关节和碰撞器组件。该工具通常创建13个不同的碰撞器并关联关节(骨盆、胸部、头部、每条手臂两个碰撞器,每条大腿3个碰撞器)。
2021-03-14
但是,只使用七个碰撞器(骨盆、胸部、头部和每个肢体一个碰撞器),可以大大降低消耗成本,代价是牺牲了布娃娃的真实性。为此,可以删除不需要的碰撞器,手动将角色关节的connectedBody属性重新指定给适当的父关节(将手臂碰撞器连接到胸部,将腿部碰撞器连接到骨盆)。
2021-03-14
请注意,在使用Ragdoll Wizard创建碎布娃娃的过程中指定了一个质量值。此质量值在不同的关节上适当分布,因此表示对象的总质量。应该确保与游戏中的其他对象相比,不会将质量值应用得太高或太低,以避免潜在的不稳定性。
2021-03-14
【】避免布娃娃间碰撞
当允许布娃娃与其他布娃娃碰撞时,布娃娃的性能成本呈指数级增长,因为任何关节碰撞都要求处理器计算应用于所有连接到它的关节的合成速度,然后计算每个连接到它们的关节,这样两个布娃娃必须完成多次计算
2021-03-14
这对处理器来说是一项艰巨的任务,所以应该避免它。最好的方法就是简单地使用碰撞矩阵。
2021-03-14
一旦布娃娃到达它的最终目的地,就不再需要它作为一个可交互的对象留在游戏世界中。然后,当不再需要布娃娃时,可以禁用、销毁它,或用更简单的替代品替换它(一个好的技巧是用只包含七个关节的更简单版本替换它们,如前所述)
2021-03-14
【】确定何时使用物理
提高特性性能最明显的方法是尽量避免使用它。对于游戏中所有可移动的物体,应该花点时间问问自己,是否有必要使用物理引擎。如果没有,应该寻找机会用更简单、消耗更低的东西来取代它们。
2021-03-14
缓动(Tweening)是一个常用于描述中间过程的术语,它是随着时间的推移逐步将变量从一个值插入另一个值的行为。Unity Asset Store上有许多有用(以及免费)的缓动库,可以提供很多有用的功能。尽管如此,请注意这些库中可能存在较差的优化。
2021-03-14
确保从场景中删除不必要的物理工作,或者使用物理替换通过脚本代码执行时代价高昂的行为。这些机会和你自己的创造力一样广泛和深远。识别这种机会的能力需要经验,但这是一项至关重要的技能,在当前和未来的游戏开发项目中提升性能时,它将提供良好的服务。
2021-03-24
5.3 本章小结
当涉及消耗较大的系统(如物理引擎)时,最好的技术就是回避
【】最好的技术就是回避
2021-03-24
第6章 动态图形
毫无疑问,现代图形设备的管线渲染相当复杂。即使在屏幕上渲染一个三角形,也需要执行大量的图形API调用,其中包括许多任务,如为挂接到操作系统的相机视图创建缓冲区(通常是通过某种视窗系统),为顶点数据分配缓冲区,建立数据通道以将顶点和纹理数据从RAM传输到VRAM,配置这些内存空间来使用一组特定的数据格式,确定对相机可见的对象,为三角形设置并初始化Draw Call,等待管线渲染完成其任务,最后将渲染的图像显示到屏幕上。然而,绘制这样一个简单对象的方法看似复杂,过于工程化,其原因很简单——渲染常常需要重复相同的任务,而所有这些初始设置使未来的渲染任务完成得非常快。
2021-03-24
GPU用来完成大量任务的并行处理,但是在不破坏并行性的情况下,它们处理的复杂性是有限的。GPU的并行性要求,非常快速地复制大量的数据。在设置管线渲染期间,要配置内存数据通道,以便图形数据能够通过。因此,如果这些通道为要传递的数据类型进行了适当的配置,那么它们将更有效地运行。然而,设置不当将导致相反的结果。
2021-03-24
- 简要探讨管线渲染,重点介绍CPU和GPU起作用的部分
- 概述如何确定渲染是否受到CPU和GPU的限制
- 一系列性能优化技术和特性,具体如下:
- GPU实例化
- 细节级别(LOD)和其他筛选组
- 遮挡剔除
- 粒子系统
- Unity用户界面
- 着色器优化
- 照明和阴影优化
- 特定移动设备的渲染增强
2021-03-24
6.1 管线渲染
研究CPU受限的程序相对比较简单,因为所有的CPU工作都被包装为从磁盘/内存中加载数据和调用图形API指令。但是,GPU受限的程序很难分析,因为其根本原因可能源自于管线渲染中很多潜在的地方。在确定GPU瓶颈的过程中,可能需要采用一些猜测或过程排除法来查找原因。
【】渲染精要概述
2021-03-24
我们知道,CPU通过图形****API向GPU设备发送渲染指令,再通过硬件驱动程序发送给GPU设备,这样渲染指令列表会累积在一个称为“命令缓冲区”的队列中。这些命令由GPU逐一处理,直到“命令缓冲区”为空。只要GPU能在下一帧开始之前跟上指令的速度和复杂度,帧速就保持不变。然而,如果GPU跟不上,或者CPU花费太多时间生成命令,帧速率将开始下降。
2021-03-24
前端是指渲染过程中GPU处理顶点数据的部分。它(GPU)从CPU中接收网格数据(一大堆顶点信息)并发出Draw Call。然后GPU将从网格数据中收集顶点信息,通过顶点着色器进行传输,对数据按1:1的比例进行修改和输出。之后,GPU得到一个需要处理的图元列表(三角形——3D图形中最基本的形状)。接下来,光栅化器获取这些图元,确定最终图形的哪些像素需要绘制,并根据顶点的位置和当前的相机视图创建图元。这个过程中生成的像素列表称为片元,将在后端进行处理。
【顶点着色器】输出【图元列表】-->【光栅化器】输出【片元】
【】顶点着色器
2021-03-14
顶点着色器是类似C的小程序,用来确定想要的输入数据和数据处理方式,并向光栅化器输出一组信息用来生成片元。这也是进行曲面细分处理的地方,曲面细分由几何着色器(有时也称为曲面细分着色器)处理,和顶点着色器类似,它们也是上传到GPU****的小脚本程序,不同的是它们可以1对多的方式输出顶点,因此可通过编程的方式生成其他几何图形。
2021-03-14
后端描述了管线渲染中处理片元的部分。每个片元都通过片元着色器(也称为像素着色器)来处理。与顶点着色器相比,片元着色器往往涉及更复杂的活动,例如深度测试、alpha测试、着色、纹理采样、光照、阴影以及一些可行的后期效果处理。之后这些数据绘制到帧缓冲区,帧缓冲区保存了当前图像,一旦当前帧的渲染任务完成,图像就发送到显示设备(例如显示器)。
【片元着色器】处理后输出数据到【帧缓冲区】中 ,等待被渲染,然后输送到【显示设备】
【】使用两个帧缓冲区
2021-03-14
正常情况下,图形API默认使用两个帧缓冲区(尽管可以给自定义的渲染方案生成更多的帧缓冲区)。在任何时候,一个帧缓冲区包含渲染到帧中、并显示到屏幕上的数据;另一个帧缓冲区则在GPU完成命令缓冲区中的命令后被激活,进行图形绘制。一旦GPU完成swap buffers命令(CPU请求完成指定帧的最后一条指令),就翻转帧缓冲区,以呈现新的帧。GPU则使用旧的帧缓冲区绘制下一帧。每次渲染新的帧时,都重复此过程,因此,GPU只需要两个帧缓冲区就可以处理这个任务。
【】后端瓶颈的两个指标
2021-03-14
在后端,有两个指标往往是瓶颈的根源——填充率和内存带宽
2021-03-14
【】填充率
填充率是一个使用非常广泛的术语,它指的是GPU绘制片元的速度。然而,这仅仅包含在给定的片元着色器中通过各种条件测试的片元。片元只是一个潜在的像素,只要它未通过任一测试,则会被立即丢弃。这可以大大提升性能,因为管线渲染可跳过昂贵的绘制步骤,开始处理下一个片元。
【】Z-测试
2021-03-15
一个可能导致片元被丢弃的测试是Z-测试,它检查较近对象的片元是否已经绘制在同样的片元位置(Z是指从相机的视角观察的深度维度)。如果已被绘制,则丢弃当前片元。如果没有绘制,片元将通过片元着色器推送,在目标像素上绘制,并在填充率中消耗一个填充量。
【】60HZ就是60帧
2021-03-15
显卡制造商通常将特定的填充率作为显卡的特性进行宣传,通常以千兆像素每秒的形式进行宣传,但该表达并不恰当,准确来讲应该是千兆片元每秒;但是这个定义是学术性的。无论哪种说法,填充率越高,说明设备通过管线渲染可处理的片元数量越多。因此,如果以每秒30千兆像素,目标帧速率为60Hz计算,在到达填充率瓶颈之前,每帧可处理30 000 000 000/60=5亿个片元。
60HZ就是60帧
2021-03-15
遗憾的是,没有完美的事情。填充率也会被其他高级渲染技术所消耗,例如阴影和后期效果处理需要提取同样的片元数据,在帧缓冲区中执行自己的处理。即便如此,由于渲染对象的顺序,我们总是会重绘一些相同的像素。这称为过度绘制,这是衡量填充率是否有效使用的一个重要指标。
【!】Overdraw Shading模式找出【过渡绘制】
2021-03-15
过度绘制 通过使用叠加alpha混合和平面着色来渲染所有对象,过度绘制的多少就可以直观地显示出来。过度绘制多的区域将显示得更加明亮,因为相同的像素被叠加混合绘制了多次。这恰是Scene窗口的Overdraw Shading模式显示场景经过了多少过度绘制的方式。
2021-03-15
过度绘制得越多,覆盖片元数据所浪费的填充率就越多。
【】UI避免在透明队列中【】
2021-03-15
注意,实际上有几种不同的队列用于渲染,它们可以分为两种类型:不透明队列和透明队列。如前所述,在不透明队列中渲染的对象可以通过Z-测试剔除片元。然而,在透明队列中渲染的对象不能这样做,因为它们的透明特性意味着,不管有多少对象挡在前面,都不能假设它们不需要绘制,这将导致大量的过度绘制。所有的Unity UI对象通常都在透明队列中渲染,这也是过度绘制的主要来源。
【】消耗内存带宽的方式
2021-03-15
只要从GPU VRAM的某个部位将纹理拉入更低级别的内存中,就会消耗内存带宽。这通常发生在对纹理采样时,其中片元着色器尝试选择匹配的纹理像素(或纹素),以便在给定的位置绘制给定的片元。
相同区域,还都有一个小得多的本地纹理缓存,来存储GPU最近使用的纹理
2021-03-15
如果需要的纹理已经存在于内核的本地纹理缓存中,那么采样通常如闪电般快速,几乎感觉不到。否则,需要从VRAM中提取纹理信息,才能进行采样。这实际上是纹理的有效缓存数据丢失,因为现在需要花些时间从VRAM中寻找并提取需要的纹理。这种传输会消耗一定数量的可用内存带宽,这个量相当于VRAM中存储的纹理文件的总大小(由于GPU级别的压缩技术不一样,因此它可能不是原始文件的大小或者其在RAM中的大小)。
2021-03-15
如果在内存带宽方面遇到瓶颈,GPU将继续获取必要的纹理文件,但整个过程将受到限制,因为纹理缓存将等待获取数据后,才会处理给定的一批片元。GPU无法及时将数据推回到帧缓冲区,以渲染到屏幕上,整个过程被堵塞,帧速率也会降低。
【】估算内存带宽【】每秒96GB
2021-03-15
如何对内存带宽进行合理使用需要进行估算。例如:每个内核的内存带宽为每秒96GB,目标帧速率为每秒60帧,在到达内存带宽的瓶颈之前,GPU每秒可提取1.6GB(96/60)的纹理数据。当然,这不是一个确切的估算值,因为还存在一些缓存丢失的情况,但它提供了一个粗略的估算值。
【】因为一个“核”不可能用别的核的内存带宽
2021-03-15
内存带宽通常是基于每个内核列出,但是一些GPU制造商可能试图将“内核数”乘以内存带宽,得到一个很大但不符合实际情况的数,来误导用户。因此,需要进行对等的比较。
2021-03-15
请注意,这个值并不是游戏可以在项目、CPU RAM或VRAM中包含的纹理数据量的最大限制。其实,这个指标限制的是在一帧中可以发生的纹理交换量。同一纹理在一帧内可以被来回拉动多次,主要取决于着色器使用它们的次数、对象渲染的顺序以及纹理采样的频率。由于纹理缓存空间是有限的,因此只有少数对象可占用千兆字节的内存带宽。如果着色器需要大量的纹理,很可能造成缓存丢失,从而造成内存带宽瓶颈。如果多个对象需要不同的高质量纹理和多个二级纹理映射(法线映射、发散映射等),那么在非批处理模式下,瓶颈很容易被触发。在这种情况下,纹理缓存无法对单个纹理文件挂起足够的时间,来支撑下一个渲染过程的采样。
【】总结
填充率就是速度
内存带宽就是一秒可以发生的纹理交换量
2021-03-15
在现代游戏中,单个对象很少能在一个步骤中完成渲染,主要原因是光照和阴影。这些任务通常在片元着色器的多个过程中处理,对于多个光源中的每一个都处理一次,最后将结果进行合并,以应用多个灯光效果。这样,结果看起来更真实,至少在视觉上更具有吸引力。
【】阴影信息的收集过程概述
2021-03-15
阴影信息的收集需要多个过程。首先为场景设置阴影投射器和阴影接收器,分别用来创建和接收阴影。然后,每次渲染阴影接收器时,GPU都会从光源的角度将任何阴影投射器对象渲染成纹理,目标是收集每个片元的距离信息。对阴影接收器进行同样的动作,除了阴影投射器和光源重叠的片元外,GPU可将片元渲染得更暗,因为这类片元位于阴影投射器产生的阴影下。 之后,这些信息变成附加的纹理,称为纹理阴影(Shadowmap)。当从主相机视角渲染时,它们(主相机渲染的东西)将被混合在阴影接收器的表面。这使得位于光源和给定对象之间的某些位置变得更暗。Lightmap的创建过程与之类似,其为场景中的很多静态部分预生成光照信息。
2021-03-15
在管线渲染的所有过程中,光照和阴影往往会消耗大量的资源。我们需要为每个顶点提供法矢方向(指向远离表面的矢量),来确定光线如何从表面反射出去,同时需要附加的顶点颜色属性,来应用一些额外的着色。这为CPU和前端提供了更多要传递的信息。由于片元着色器需要多次传递信息来完成最终的渲染,因此后端在填充率(大量需要绘制、重绘、合并的像素)和内存带宽(为Lightmap和Shadowmap拉入和拉出的额外纹理)方面将处于繁忙状态。这就是为什么和大多数其他渲染特性相比,实时阴影异常昂贵,在启用后会显著增加Draw Call数的原因。
【】低面美术依赖良好的光照和阴影轮廓
2021-03-15
然而,光照和阴影可能是游戏美术和设计中两个最重要的部分,常常值得花费成本来满足额外的性能要求。优秀的光照和阴影可以化腐朽为神奇,因为专业的渲染如同魔法一样,可以让场景的视觉效果更有吸引力。甚至是低面美术风格(例如手游“纪念碑谷”)在很大程度上也依赖良好的光照和阴影轮廓,以便玩家区分不同的物体,并创造良好的视觉体验。 Unity提供了多种影响光照和阴影的特性,包括实时光照和阴影(每种都有多种类型)到名为Lightmapping的静态光照。这里有很多选项需要探索,如果不小心,很多事情可能导致性能问题。
【】【教程】所有光照特性手册
2021-03-15
Unity文档涵盖了所有光照特性的细节描述。下面的内容很值得认真阅读,因为这些系统影响着整个管线渲染,具体参考:
https://docs.unity3d.com/Manual/LightingOverview.html
https://unity3d.com/learn/tutorials/topics/graphics/introduction-lighting-and-rendering
2021-03-15
渲染有两种不同的方式:前向渲染和延迟渲染,它们对光照的性能都有很大的影响。这些渲染选项的设置可以在Edit | Project Settings | Player | Other Settings | Rendering找到,并根据每个平台进行配置。
2021-03-15
【】前向渲染
前向渲染是场景中渲染灯光的传统方式。在前向渲染过程中,每个对象都通过同一个着色器进行多次渲染。渲染的次数取决于光源的数量、距离和亮度。Unity优先考虑对对象影响最大的定向光源组件,并在基准通道中渲染对象,作为起点。然后通过片元着色器使用附近几个强大的点光源组件对同一个对象进行多次重复渲染。每一个点光源都在每个顶点的基础上进行处理,所有剩余的光源都通过“球谐函数”技术被压缩成一个平均颜色。
为了简化这些行为,可以将灯光的Render Mode调整为Not Important,并在Edit | Project Settings | Quality | Pixel Light Count中修改参数。这个参数值限制了前向渲染采集的灯光数量,但当Render Mode设置为Important时,该值将被任意灯光数覆盖。因此,应该慎重使用这个设置组合。 可以看出,使用前向渲染处理带有大量点光源的场景,将导致Draw Call计数呈爆炸式的增长,因为需要配置的渲染状态很多,还需要着色器通道。
复盘-前向渲染
- 多次渲染
- 大量光源的不合适
- 灯光的渲染模式改为not important
2021-03-15
关于前向渲染的更多信息请参考Unity文档,网址为:http://docs.unity3d. com/ Manual/ RenderTech- ForwardRendering.html。
2021-03-15
【】延迟渲染
延迟渲染有时又称为延迟着色,是一项在GPU上已使用十年左右的技术,但一直未能完全取代前向渲染,因为涉及一些手续,移动设备对它的支持也有限。 延迟着色这么命名,是因为实际的着色发生在处理的后期,也就是说延迟到后期才发生。它的工作原理是创建一个几何缓冲区(称为G-缓冲区),在该缓冲区中,场景在没有任何光照的情况下进行初始渲染。有了这些信息,延迟着色系统可以在一个过程中生成照明配置文件。 从性能角度来看,延迟着色的结果让人印象深刻,因为它可以产生非常好的逐像素照明,而且几乎不需要Draw Call。延迟着色的一个缺点就是无法独立管理抗锯齿、透明度和动画人物的阴影应用。在这种情况下,前向渲染技术就作为一种处理这些任务的备用选项,因此需要额外的Draw Call来完成。延迟着色的一个更大的问题是它往往需要高性能、昂贵的硬件来支持,且不能用于所有平台,因此很少有用户能使用它。
2021-03-15
Unity文档包含了延迟渲染技术及其优缺点的大量信息,网址是 http://docs. unity3d.com/Manual/RenderTech-DeferredShading.html。
2021-03-15
【】顶点照明着色(传统)
从技术角度讲,照明的方法不止两种。目前仅存的两种是顶点照明着色和很原始、功能粗放的延迟渲染版本。顶点照明着色是光照的大规模简化处理,因为光照是按顶点处理而不是按像素处理。换言之,整个表面都是基于射入灯光的颜色进行统一着色,而不是通过单个像素对表面进行混合照明着色。 许多甚至全部3D游戏都不会采用这种传统的技术,因为缺乏阴影和合适的照明功能支持,顶点照明着色要实现深度的可视化非常困难。该技术主要应用在一些不需要使用阴影、法线映射和其他照明功能的简单2D游戏。
2021-03-15
【】全局照明
全局照明(Global Illumination,GI),是烘焙Lightmapping的一种实现。Lightmapping类似于阴影映射技术创建的Shadowmap,其为每个表示额外照明信息的对象生成一个或多个纹理,然后在片元着色器的光照过程中应用于对象,以模拟静态光照效果。 这些Lightmap和其他形式的光照的最大区别是,Lightmap是在编辑器中预先生成(或烘焙)的,并打包到游戏的构建版本中。这确保在游戏运行时不需要不断地重新生成这些信息,从而节省大量的Draw Call和重要的GPU活动。由于可以烘焙这些数据,因此**有足够的时间来生成高质量的Lightmap **(当然,代价是需要处理所生成的更大量的纹理文件)。
【】Lightmapping+Light Probe 模拟真实光照
2021-03-16
由于这些信息是提前生成的,因此无法响应游戏中的实时活动,所以在默认情况下,任何Lightmapping信息只应用于场景中生成Lightmap时出现的静态对象。但是,可以将Light Probe添加到场景中,以生成一组额外的Lightmap纹理,这些纹理可以应用到附近移动的动态对象,使这些对象能够从预生成的光照中受益。这种方式不追求完美的像素精度,在运行时还要为额外的Light Probe和内存带宽的数据交换提供磁盘空间,但是它生成了一个更可信、更合适的灯光配置文件。
【】渐进式的Lightmap
2021-03-16
生成Lightmap的一个典型问题是,在当前设置下Lightmap从生成到获得视觉回馈所需的时间很长,因为Lightmapper经常尝试在一个过程中生成包含全部细节的Lightmap。如果用户尝试修改这些配置,则必须取消并重新启动整个作业。为了解决这个问题,Unity技术实现了渐进式的Lightmap,渐进式的Lightmap可随着时间的推移逐步执行Lightmapping任务,还允许计算时对配置信息进行修改。这使场景中Lightmap的显示过程变得越来越详细,因为它是后台运行,另外允许在运行时修改某些属性而不需要重新启动整个工作。这提供了准实时的回馈机制,极大改进了生成Lightmap的工作流程。
【】视锥剔除
2021-03-16
对于场景中的每个对象,渲染过程需要完成3个任务:
- 首先确定对象是否需要渲染(通过视锥剔除技术),
- 如果需要,就生成渲染对象的指令(因为单个对象的渲染可能产生数十个指令)
- 最后调用相应的图形API将指令发送到GPU。
【】多线程渲染何时启用
在没有****多线程渲染的情况下,这些任务都在CPU****的主线程上执行,那么主线程上的任何活动都将成为渲染的关键路径中的节点。
多线程渲染启动时,渲染线程会将指令推送到GPU,其他任务(例如剔除和生成指令)则分散在多个工作线程中。这种模式可以为主线程节省大量的CPU周期,而其他绝大部分任务都是在CPU的主线程中执行,例如物理和脚本代码。
多线程渲染特性一旦启用,将影响到CPU的瓶颈。在未启用该特性时,主线程将执行“为命令缓冲区生成指令”所需的所有工作,这意味着在其他地方提升的性能可以释放出来,让CPU生成指令。但是,当多线程渲染启动后,大部分的工作负载都被推送到独立的线程中,这意味着通过CPU提升主线程对渲染性能的影响很小。
2021-03-16
注意,不管多线程渲染是否开启,GPU的限制都是相同的。GPU总是以多线程的方式执行任务。
【】CommandBuffer类直接发出高级渲染指令
2021-03-16
Unity通过CommandBuffer类对外提供渲染API。这允许通过C#代码发出高级渲染命令,来直接控制管线渲染,例如采用特定的材质,使用给定的着色器渲染指定的对象,或者绘制某个程序几何体的N个实例。这种定制化的功能不如直接调用图形API那么强大,但是对Unity开发人员来讲,定制独特的图形效果是朝正确的方向迈出的一步。
2021-03-16
Unity文档中介绍了CommandBuffer如何使用这些特性,具体请参考: http://docs.unity3d.com/ScriptReference/Rendering.CommandBuffer.html。
【】使用本地插件生成渲染接口
2021-03-24
Unity在如何使用本地插件生成渲染接口方面提供了非常优秀的文档,具体请参考https://docs.unity3d.com/Manual/NativePluginInterface.html。
2021-03-24
6.2 性能检测问题
性能分析器可将管线渲染中的瓶颈快速定位到所使用的两个设备:CPU或者GPU。必须使用性能分析器窗口中的CPU使用率和GPU使用率来检查问题,这样可以知道哪个设备负荷较重。
【】禁用Vertical Sync
2021-03-24
为了执行准确的GPU受限的性能分析测试,应在Edit | Project Settings | Quality | Other | V Sync Count中禁用Vertical Sync,否则测试数据将受到干扰。
【】CPU要等待GPU
2021-03-17
如果采用层级模式深入查看CPU Usage区域的分解视图,会发现CPU的大部分时间都花在标记为Gfx.WaitForPresent的任务上。这是CPU等待GPU完成当前帧时浪费的时间。因此,尽管看起来瓶颈受两者的约束,但实际上瓶颈还是受GPU影响更多。即使启用了多线程渲染,CPU还是需要等管线渲染完成,才能开始下一帧的处理工作。
2021-03-17
Gfx.WaitForPresent通常用来表示CPU正在等待垂直同步完成,因此在本测试中需要禁用。
【】消除足够的未知因素
2021-03-17
如果在深入分析性能数据后还无法确定问题的根源,或者在GPU受限的情况下需要确定管线渲染的瓶颈所在,就应尝试使用暴力测试方法,即在场景中去除指定的活动,并检查性能是否有大幅提升。如果一个小的调整导致速度大幅提升,就说明找到了瓶颈所在的重要线索。如果消除足够的未知因素可以确保数据引导的方向是正确的,这种方法就不妨一试。
【】填充率受限还是内存带宽受限【】
2021-03-17
有两种好的暴力测试方法可用来测试GPU受限的应用程序,以确定是填充率受限还是内存带宽受限,这两种方法分别是降低屏幕分辨率和降低纹理分辨率。
2021-03-17
通过降低屏幕分辨率,可以让光栅器生成的片元****少许多,并在较小的像素画布上进行转化,以便进行后端处理。这将减少应用程序填充率的消耗,为管线渲染的关键部分提供缓冲的空间。因此,如果屏幕分辨率降低后性能突然提高,那么填充率应该是我们首要关注的问题
填充率 = 速度
2021-03-17
将分辨率从2560×1440降低到800×600,其改善系数约为8,这通常足以降低填充率的成本,使应用程序再次运行良好。
2021-03-17
如果在内存带宽上遇到瓶颈,那么降低纹理质量可能会显著提高性能。这样会减小纹理的大小,极大地降低片元着色器的内存带宽成本,允许GPU更快地获取必要的纹理。为了降低全局纹理质量,可进入Edit | Project Settings | Quality | Texture Quality,设置的值为Half Res、Quarter Res或Eighth Res。
2021-03-17
可以看出,CPU受限的应用程序都有足够的机会来提升性能。如果从其他活动中释放CPU周期,就可以通过更多的Draw Call来渲染更多的对象,当然请记住,每次渲染都将消耗GPU中更多的活动。但是,在改进管线渲染的其他部分时,还有一些额外的机会可以间接改进Draw Call计数。这包括遮挡剔除、调整光照和阴影行为以及修改着色器
2021-03-24
6.3 渲染性能的增强
6.3.1 启用/禁用GPU Skinning
第一个技巧是通过牺牲GPU Skinning来降低CPU或GPU前端的负载。Skinning是基于动画骨骼的当前位置变换网格顶点的过程。在CPU上工作的动画系统会转换对象的骨骼,用于确定其当前的姿势,但动画过程中的下一个重要步骤是围绕这些骨骼包裹网格顶点,以将网格放在最终的姿势中。为此,需要迭代每个顶点,并对连接到这些顶点的骨骼执行加权平均。** 该顶点处理任务可以在CPU上执行,也可以在GPU的前端执行,具体取决于是否启用了GPU Skinning选项**。
该功能可以在Edit | Project Settings | Player Settings | Other Settings | GPU Skinning下切换。该功能启用后,会将Skinning活动推送到GPU中,但注意,CPU仍必须将数据传输到GPU,并在命令缓冲区上为任务生成指令,因此不会完全消除CPU的工作负载。禁用此选项可以使CPU在传输网格数据之前解析网格的姿态,并简单地要求GPU按原样绘制,从而减轻GPU的负担。显然,如果场景中有很多动画网格,这个功能就非常有用,且可以将工作推到空闲的设备上,来设置边界。
2021-03-24
6.3.2 降低几何复杂度
这是一个GPU前端的技巧。第4章介绍了一些网格优化技术,这有助于减少网格的顶点属性。这里快速回顾一下,网格常常包含大量不必要的UV和法线矢量数据,因此应该仔细检查网格是否包含这种多余的信息。还应让Unity优化结构,这样可以在前端内读取顶点数据时最大限度地减少丢失缓存的情形。 我们的目标只是降低实际的顶点数量。
这有3种方法。
- 第一种方法是让美术团队手动调整,生成多边形数更少的网格,或使用网格抽取工具来简化网格。
- 第二种方法是简单地从场景中移除网格,但这应该是最后的手段。
- 第三种方法是实现网格的自动剔除特性,如详细级别(Level of Detail, LOD),参见本章后面的内容。
#### 【】曲面细分 2021-03-24
通过几何着色器进行曲面细分非常有趣,因为曲面细分是一种相对还未充分使用的技术,可以真正使图形效果在使用最常见效果的游戏中脱颖而出。但是,它也极大地增加了前端处理的工作量。 除了改进曲面细分算法或减轻其他前端任务的负载,来使曲面细分任务有更多的空闲空间外,并没有其他简单的技巧可以改进曲面细分。不管哪种方式,如果前端遇到瓶颈,却在使用曲面细分技术,就应仔细检查曲面细分是否消耗了前端的大量资源。
【】在材质级别使用GPU实例化
2021-03-17
GPU实例化利用对象具有相同渲染状态的特点,快速渲染同一网格的多个副本,因此只需要最少的Draw Call。这其实和动态批处理一样,只不过不是自动处理的过程。
2021-03-17
选中Enable Instancing复选框,可以在材质级别上应用GPU实例化,修改着色器代码,就可以引入变化。这样,就可以为不同的实例提供不同的旋转、比例、颜色等特性。这对于渲染森林和岩石区域等场景很有用,在这种场景中,可以渲染成百上千个有细微差异的网格副本。
2021-03-17
Skinned Mesh Renderer无法应用到GPU实例化,其原因和不能使用动态批处理类似,并不是所有的平台和API都支持GPU实例化。
【】LOD
2021-03-17
LOD(Level Of Detail,LOD)是一个广义的术语,指的是根据对象与相机的距离和/或对象在相机视图中占用的空间,动态地替换对象。由于远距离很难分辨低质量和高质量对象之间的差异,一般不会采用高质量方式渲染对象,因此可能用更简化的版本动态替换远距离对象。LOD最常见的实现是基于网格的LOD,当相机越来越远时,网格会采用细节更少的版本替代。
2021-03-17
关于基于网格的LOD功能的更详细信息,请参阅Unity文档 .
2021-03-17
一个特性需要花费大量的开发时间才能完全实现;美工必须为同一对象生成多边形数较少的版本,而关卡设计师必须生成LOD组,并进行配置和测试,以确保它们不会在相机移近或移远时出现不和谐的转换。
2021-03-17
注意,一些开发游戏中间件的公司提供了第三方工具,来自动生成LOD网格。这类LOD网格的易用性、质量损失和成本效益的对比值得研究。
2021-03-17
基于网格的LOD还会消耗磁盘占用空间、RAM和CPU;替代网格需要捆绑在一起加载到RAM中,并且LODGroup组件必须定期测试相机是否移动到新位置,以修改LOD级别。但管线渲染的优点相当显著。动态渲染较简单的网格,减少了需要传递的顶点数据量,并潜在减少了渲染对象时需要的Draw Call数量、填充率和内存带宽。 由于要实现基于网格的LOD功能需要牺牲很多,开发人员应该自动假设基于网格的LOD是有益的,避免预先优化。过度使用该特性会增加应用程序其他部分的性能负担,并占用宝贵的开发时间,这一切都是出于偏执。只有当我们开始观察到管线渲染中出现问题,并且CPU、RAM和开发时间都有空闲时才使用。
2021-03-17
话虽如此,拥有广阔视野和大量摄像机运动的场景,可能需要考虑尽早实现这种技术,因为增加的距离和大量可见的物体可能会极大地增加顶点数。相反,总是在室内的场景,或者相机俯视视角的场景,使用这种技术都没有什么好处,因为对象总是与相机保持类似的距离。示例包括实时策略(RealTime Strategy,RTS)和多人在线战斗竞技场(Multiplayer Online Battle Arena,MOBA)游戏。
【】剔除组
2021-03-17
剔除组(Culling Groups)是Unity API的一部分,允许创建自定义的LOD系统,作为动态替换某些游戏或渲染行为的方法。希望应用LOD的示例包括用较少骨骼的版本替换动画角色,应用更简单的着色器,在很远的距离上跳过粒子系统生成过程,简化AI行为等。
2021-03-17
查看Unity文档,以获取有关剔除组的更多信息,网址为: https:/ /docs. unity3d. com/ Manual/ CullingGroupAPI. Html。
2021-03-17
6.3.6 使用遮挡剔除
减少填充率消耗和过度绘制的最佳方法之一是使用Unity的遮挡剔除系统。该系统的工作原理是将世界分割成一系列的小单元,并在场景中运行一个虚拟摄像机,根据对象的大小和位置,记录哪些单元对其他单元是不可见的(被遮挡)。
【】遮挡剔除和视锥剔除不同
2021-03-17
请注意,这与视锥剔除技术不同,视锥剔除的是当前相机视图之外的对象。视锥剔除总是主动和自动进行的。因此遮挡剔除将自动忽略视锥剔除的对象。
【】如何操作去使用“遮挡剔除”
2021-03-17
只有在StaticFlags下拉列表下正确标记为Occluder Static和/或Occludee Static的对象才能生成遮挡剔除数据。
Occluder Static是静态物体的一般设置,它们既能遮挡其他物体,也能被其他物体遮挡,例如摩天大楼或山脉,这些物体可以隐藏其他物体,也能隐藏在其他物体后面。
Occludee Static是一种特殊的情况,例如透明对象总是需要利用它们后面的其他对象才能呈现出来,但如果有大的对象遮挡了它们,则需要隐藏它们本身。
2021-03-17
当然,因为必须为遮挡剔除启用Static标志,所以此功能不适用于动态对象。
2021-03-17
启用遮挡剔除功能将消耗额外的磁盘空间、RAM和CPU时间。需要额外的磁盘空间来存储遮挡数据,需要额外的RAM来保存数据结构,需要CPU处理资源来确定每个帧中哪些对象需要被遮挡。遮挡剔除数据结构必须正确配置,以创建场景中适当大小的单元,单元越小,生成数据结构所需的时间就越长。但是,如果为场景进行了正确的配置,遮挡剔除可以剔除不可见的对象,减少过度绘制和Draw Call数,来节省填充率。
【】仍然会计算阴影
2021-03-17
请注意,即使对象被遮挡剔除,也必须计算其阴影,所以不会节省这些任务的Draw Call数和填充率。
2021-03-17
降低粒子系统密度和复杂性非常简单:使用更少的粒子系统,生成更少的粒子,使用更少的特殊效果。图集也是另一种降低粒子系统性能成本的常用技术。然而,对于粒子系统,还有一个重要的性能考虑因素,该因素不为人知,而且在后台进行,那就是粒子系统的自动剔除过程。
【】粒子删除系统的博客
2021-03-17
1.使用粒子删除系统 Unity Technologies发布了一篇关于这个主题的优秀博客文章,[网址](https:// blogs. unity3d. com/ 2016/ 12/ 20/ unitytips-particlesystemperformance-culling/)。
2021-03-17
如果有一些设置强制粒子系统变得不可预知或者非程序化,就不知道粒子系统的当前状态必须是什么,即使它以前是隐藏的,也可能需要进行全帧渲染,而不管它可见或可不见。破坏粒子系统可预测性的设置包括(但不限于)使粒子系统在世界空间中渲染,应用外力、碰撞和轨迹,或使用复杂的动画曲线。查看前面提到的博客文章,以获得非程序化情况的严谨列表。
【】有用的警告信息
2021-03-17
注意,当粒子系统的自动剔除功能被中断后,Unity会提供一种很有用的警告,如图6-7所示。
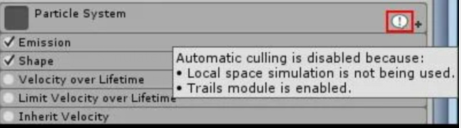
2021-03-17
【】避免粒子系统的递归调用
ParticleSystem组件中的很多方法都是递归调用。这些方法的调用需要遍历粒子系统的每个子节点,并调用子节点的GetComponent()方法获得组件信息。如果组件存在,则调用组件中对应的方法。
2021-03-17
有几个粒子系统API会受到递归调用的影响,例如Start()、Stop()、Pause()、Clear()、 Simulate()和isAlive()。显然不能完全避免这些方法的使用,因为这些都是粒子系统中最常见的方法。但是,这些方法都有一个默认为true的withChildren参数。给这个参数传递false值(例如:调用**Clear(false))**可以禁用递归行为和子节点的调用。因此,方法调用只会影响给定的粒子系统,从而降低调用的成本开销。
2021-03-17
但这并不总是很理想,因为通常我们希望粒子系统的所有子节点都受方法调用的影响。
因此,另一种方式是第2章采用的方式:缓存粒子系统组件,并手动迭代它们(确保每次传递给withChildren参数都是false)。
2021-03-17
事实上,Unity Technologies在2017年初就收购了Text Mesh Pro资源背后的公司,并将其作为内置功能整合到Unity UI中。
2021-03-17
【】下面探讨可用于提高Unity内置UI性能的技术。
1.使用更多画布
画布组件的主要任务是管理在层次窗口中绘制UI元素的网格,并在发出渲染这些元素所需的Draw Call。
画布的另一个重要作用是将网格合并进行批处理(条件是这些网格的材质相同),以降低Draw Call数。然而,当画布或其子对象发生变动时,这称为“画布污染”。当画布污染后,就需要为画布上的所有UI对象重新生成网格,才可发出Draw Call。这个重新生成网格的过程不是一个简单的任务,也是Unity项目中性能问题的常见来源,遗憾的是,很多因素都会导致画布污染。即使更改画布上的单个UI元素也会导致这种情况的发生。有很多因素会导致画布污染,只有很少因素不会(通常在指定状态下),所以最好还是谨慎行事,并假定任何变化都会导致这种后果。
【】更改UI元素的颜色属性不会“污染画布”
2021-03-17
唯一值得注意的是,更改UI元素的颜色属性不会污染画布。
2021-03-17
只要发现UI的改变(随着每一帧有时或一直发生变化)导致CPU使用率大幅上升,可以采用的一个解决方案就是使用更多的画布。一个常见的错误是在单个画布中构建整个游戏的UI并保持这种方式,因为游戏代码及其UI会让这变得越来越复杂。 这意味着需要检查UI中的任何元素在任何时候发生的改变,随着越来越多的元素填充到单个画布上,性能会变得越来越糟糕。
【】每个画布都是独立的
但是,每个画布都是独立的,不需要和UI中的其他画布进行交互,所以,将UI拆分为多个画布,可以将工作负载分离开,简化单个画布所需的任务。
【】画布上的子元素可以交互的条件
2021-03-17
确保将GraphicsRaycaster组件添加到与子画布相同的GameObject上,以便画布上的子元素可以相互交互。相反,如果画布上的子元素不可相互交互,就可以安全地从中删除任何GraphicsRaycaster组件,以减少性能消耗。
【】多画布的缺点
2021-03-17
在这种情况下,即使单个元素仍然发生变化,响应时需要重新生成的其他元素也更少,从而降低了性能成本。这种方法的缺点是,不同画布上的元素不会被批量组合在一起,因此,如果可能的话,应该尽量将具有相同材质的相似元素组合在同一画布中。
2021-03-17
为了便于组织,也可以将画布作为另一个画布的子节点,并应用相同的规则。这样一个画布的元素发生改变,另一个画布不会受影响。
2021-03-17
2.在静态和动态画布中分离对象
应该努力尝试在生成画布时,采用基于元素更新的时间给元素分组的方式。
【】元素可分为3组:静态、偶尔动态、连续动态。
静态UI元素永远不会改变,典型的示例有背景图像、标签等。
动态元素可以更改,偶尔动态对象只在做出响应时更改,例如UI按钮按下或暂停动作,
而连续动态对象会定期更新,例如动画元素。
【】拆分到个画布中
应该根据UI指定的部分,尝试将这3个组中的UI元素拆分到3个不同的画布,这将最大限度地减少重新生成元素期间浪费的工作量。
2021-03-17
3.为无交互的元素禁用Raycast Target
UI元素具有Raycast Target选项,允许该元素通过单击、触摸和其他用户行为进行交互。当以上任何一个动作发生时,GraphicsRaycaster组件将执行像素到边界框检查,以确定与之交互的是哪个元素,这是一个简单的迭代for循环。对非交互元素禁用此选项,就减少了GraphicsRaycaster需要迭代的元素数量,提高了性能。
2021-03-17
4.通过禁用父画布组件来隐藏UI元素
UI使用单独的布局系统来处理某些元素类型的重新生成工作,其操作方式类似于污染画布。UIImage、UIText和LayoutGroup都是属于这个系统的组件示例。很多操作可能导致布局系统被污染,其中最明显的是启用和禁用这些元素。但是,如果想禁用UI的一部分,只要禁用其子节点的画布组件,就可以避免布局系统的这种昂贵的重新生成调用。为此,可以将画布组件的enabled属性设置为false。
【】缺点
这种方法的缺点是,如果任何子对象具有Update()、FixedUpdate()、LateUpdate()或Coroutine()方法,就需要手动禁用它们,否则这些方法将继续运行。禁用画布组件,只会停止UI的渲染和交互,各种更新调用应继续正常执行。
2021-03-17
5.避免Animator组件
Unity的Animator组件从未打算用于最新版本的UI系统,它们之间的交互是不切实际的。每一帧,Animator都会改变UI元素的属性,导致布局被污染,重新生成许多内部UI信息。应该完全避免使用Animator,而使用自己的动画内插方法或使用可实现此类操作的程序。
2021-03-17
6.为World Space画布显式定义Event Camera
画布可用于2D和3D中的UI交互,这取决于画布的Render Mode设置是配置为Screen Space (2D)还是World Space (3D)。每次进行UI交互时,画布组件都会检查其eventCamera属性(在Inspector窗口中显示为Event Camera)以确定要使用的相机。默认情况下,2D画布会将此属性设置为Main Camera,但3D画布会将其设置为null。
遗憾的是,每次需要Event Camera时,都是通过调用FindObjectWithTag()方法来使用Main Camera。通过标记查找对象并不像使用Find()方法的其他变体那样糟糕,但是其性能成本与在给定项目中使用的标记数量呈线性关系。更糟的是,在World Space画布的给定帧期间,Event Camera的访问频率相当高,这意味着将此属性设置为null,将导致巨大的性能损失而没有真正的好处。因此,对于所有的World Space画布,应该将该属性手动设置为Main Camera。
2021-03-17
7.不要使用alpha隐藏UI元素
color属性中alpha值为0的UI元素仍会发出Draw Call。应该更改UI元素的isActive属性,以便在必要时隐藏它。
【】画布组下的元素不会发出DrallCall
另一种方法是通过CanvasGroup组件使用画布组,该组件可用于控制其下所有子元素的alpha透明度。画布组的alpha值设置为0,将清除其子对象,因此不会发出任何Draw Call。
2021-03-17
只要把其他UI元素的depth值设置为低于ScrollRect元素,就可以实现滚动式UI特性。但这并不是一种好的实现方案,因为ScrollRect中的元素不会被剔除,当ScrollRect移动时,需要为每帧重新生成每个元素。如果元素未被剔除,就应使用RectMask2D组件来裁剪和剔除不可见的子对象。此组件创建了一个空间区域,如果其中的任何子UI元素超出了RectMask2D组件的边界,就会被剔除。相对于渲染太多不可见对象的成本,确定是否剔除对象所付出的成本一般更划算。
【】在ScrollRect中禁用Pixel Perfect
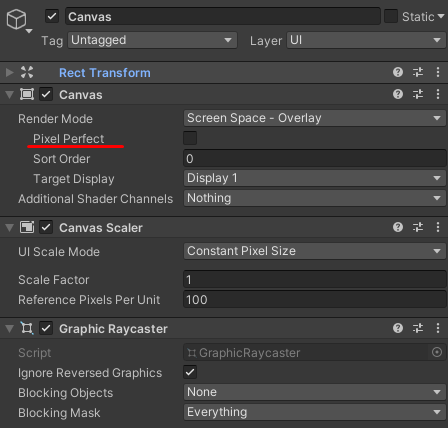
Pixel Perfect是画布组件上的一个设置,它强制其子UI元素与屏幕上的像素对齐。这通常是美术和设计的一个要求,因为UI元素将比禁用它时显示得更加清晰。虽然这种对齐操作是相当昂贵的,但它是强制性的,可以保证大部分的UI元素显示得更清晰。
但是,对于动画和快速移动的物体,由于涉及运动,因此Pixel Perfect没多大意义。
禁用ScrollRect元素的Pixel Perfect属性是一种节省大量成本的好方法。但是,由于Pixel Perfect设置会影响整个画布,因此为画布下的子对象启用ScrollRect,以便其他元素与其像素对齐。
提示:
在Pixel Perfect禁用时,不同类型的动画UI元素实际显示效果会更好。但一定要做一些测试,因为性能可以提升相当多。
8 . 手动停用ScrollRect活动
即使移动速度是每帧只移动像素的一小部分,画布也需要重新生成整个ScrollRect元素。一旦使用ScrollRect.velocity和ScrollRect.StopMovement()方法检测到帧的移动速度_低于某个阈值_,就可以手动冻结它的运动。这有助于大大降低重新生成的频率。
【】总结,ScrollRect相关
- ScrollRect单独设计在一个画布中
- 禁用Pixel Perfect
2021-03-19
9.使用空的“UIText”元素进行全屏交互
【】创建一个不生成任何“渲染信息”,只处理“边界框的交互检查”
大多数UI的常用实现是激活一个很大、透明的可交互元素来覆盖整个实体屏幕,并强制玩家必须处理弹出窗口才能进入下一步,但仍然允许玩家看到元素背后发生的事情(作为一种不让玩家完全脱离游戏体验的方法)。
这通常由UI Image元素完成,但可惜的是这可能会中断批处理操作,透明度在移动设备上可能会是一个问题。 解决这个问题的简单方法是使用一个没有定义字体或文本的UIText元素。
这将创建一个不需要生成任何可****渲染信息的元素,只处理****边界框的交互检查。
2021-03-19
10.查看Unity UI源代码
Unity在bitbucket库中提供了UI系统的源代码,具体网址为:https://bitbucket.org/ Unity-Technologies/ ui。 如果UI的性能上有重大问题,就可以查看源代码来确定问题的原因,并希望找到解决问题的方法。
有一个更极端的情况,但也是一个可能的选择,就是实际修改UI代码并编译它,并手动将其添加到项目中。
【】更多优化技巧
2021-03-19
通过以下页面,可以了解更多有用的UI优化技巧,网址。
2021-03-19
片元着色器是填充率和内存带宽的主要消耗者。
消耗成本取决于它们的复杂度:纹理采样的数量、使用的数学函数量以及其他因素。GPU的并行特性(在数百个线程之间共享整个作业的小部分)意味着线程中的任何瓶颈都将限制每一帧中通过该线程推送的片元数量。
2021-03-19
GPU并行处理器以类似的方式工作:每个处理器线程都是一个装配线,每个处理阶段都是一个团队,每个片元都是需要构建的东西。如果线程在处理单个阶段上花费了很长时间,那么在每个片元上都会浪费时间。这种延迟将成倍增加,以至于将来通过同一线程的所有片元都将被延迟。
这有点过于简单,但这有助于描述优化差的着色器代码消耗填充率的速度以及着色器性能的细微改进对后端性能的影响。 着色器的编程和优化是游戏开发的一个非常小众的领域。与典型的游戏玩法或引擎代码相比,它们抽象且高度专业化的特性需要非常不同的思维方式来生成高质量的着色器代码。它们通常具有数学技巧和后门机制,用于将数据提取到着色器中,例如预先计算值并将其放入纹理文件中。由于这一点和优化的重要性,着色器往往很难阅读和进行逆向工程。
2021-03-19
例如Shader Forge或Amplify Shader Editor。这简化了初始着色器代码生成的操作,但可能不会生成最有效的着色器形式。无论是编写自己的着色器,还是依赖预编写的/预生成的着色器,使用一些可靠的技术对它进行优化都是值得的。
【】检查着色器是否适合移动端
2021-03-19
应考虑对面向移动平台的常见着色器做测试,以检查它们是否适合游戏。
2021-03-19
2.使用小的数据类型
GPU使用更小的数据类型来计算比使用更大的数据类型(特别是在移动平台上)往往更快,因此可以尝试的第一个调整是用较小的版本(16位浮点)或甚至固定长度(12位定长)替换浮点数据类型(32位浮点)。前述数据类型的大小将根据目标平台偏好的浮点格式而有所不同。列出的大小都是最常见的。优化来自格式之间的相对大小,因为要处理的位数更少。
2021-03-19
3.在重排时避免修改精度
重排(Swizzling)是一种着色器编程技术,它将组件按照所需的顺序列出并复制到新的结构中,从现有向量中创建一个新的向量(一组数值)。 以下是一些重排的示例: 可以使用xyzw和rgba表示法依次引用相同的组件。不管是代表颜色还是向量,它们只是为了让着色器代码容易阅读。还可以按照想要的任何顺序列出组件,以填充所需的数据,并在必要时重复使用它们。
2021-03-19
在着色器中将一种精度类型转换为另一种精度类型是一项很耗时的操作,在重排时转换精度类型会更加困难。如果有使用重排的数学运算,请确保它们不会转换精度类型。在这些情况下,更明智的做法是从一开始就只使用高精度数据类型,或
2021-03-19
4.使用GPU优化的辅助函数
2021-03-19
请查看http://http.developer. nvidia. com/ CgTutorial/ cg_ tutorial_ appendix_ e.html,获得完整的CG标准库函数列表。 查看Unity文档,可以获得完整的、最新的include文件及其附带的辅助函数列表,网址为http://docs. unity3d.com/Manual/SLBuiltinIncludes.html。
2021-03-19
5.禁用不需要的特性
只要禁用不重要的着色器特性,就可以节省成本。着色器真的需要透明度、Z写入、alpha测试或alpha混合吗?调整这些设置或删除这些功能,是否可以很好地达到所需的效果而不会丢失太多的图形保真度?做这样的改变是降低填充率的一个好办法。
2021-03-19
8.减少数学计算的复杂度
复杂的数学会成为渲染流程中严重的瓶颈,因此应该尽可能限制其危害。完全可以提前计算复杂的数学函数,并将其输出作为浮点数据存储在纹理文件中,作为复杂数学函数的映射图。毕竟,纹理文件只是一个巨大的浮点值数据块,可以通过x,y和颜色(rgba)这三个维度进行快速索引。可以将这张纹理提供给着色器,并且在运行时在着色器中采样提前生成的表格,而不是在运行时进行复杂的计算。 很难对sin()和cos()等函数进行改进,因为这些方法已经针对GPU架构做了深度优化。但是一些复杂的方法(例如pow()、exp()、log())和自定义数学计算则可以进行很多优化,是优化的好选择。假设可以很容易地用x和y坐标对纹理中的结果进行索引。如果需要复杂的计算来生成这些坐标,那么这样可能并不值得。
【】提前计算,存储在一个列表中,顺序取出
2021-03-19
9.减少纹理采样
【】纹理越小越好的原因详解
纹理采样是所有内存带宽开销的核心消耗。
使用的纹理越少,制作的纹理越小,则效果越好。使用的纹理越多,则在调用过程中丢失的缓存就越多,制作的纹理越大,将它们传输****到纹理缓存中所消耗的内存带宽就越多。
因此应尽可能简化此类情况,以避免产生严重的GPU瓶颈。 更糟糕的是,不按顺序进行纹理采样可能会给GPU带来一些非常昂贵的缓存丢失。所以,如果这样做,纹理需要重新排序,以便按顺序进行采样。
例如,如果通过反转x和y坐标进行采样(例如,用tex2D(y, x)替代tex2D(x, y)),那么纹理查找操作将垂直遍历纹理,然后水平遍历纹理,几乎每次迭代都会造成缓存丢失。简单地旋转纹理文件数据,并按正确的顺序执行采样(tex2d(x,y)),可以节省大量性能损耗。
2021-03-19
10.避免条件语句
现代CPU在运行条件语句时,会使用许多巧妙的预测技术来利用指令级的并行性。这是CPU的一个特性,它试图在条件语句实际被解析之前预测条件将进入的方向,并使用不用于解析条件的空闲内核推测性地开始处理条件的最可能结果(例如:从内存提取数据,将浮点值复制到未使用的寄存器中)。如果最终发现决策是错误的,则丢弃当前结果并选择正确的路径。只要推测处理和丢弃错误结果的成本小于等待确定正确路径所花费的时间,并且正确的次数多于错误的次数,这就是CPU速度的净收益。
然而,由于GPU的并行性,该特性对于GPUS架构来说并不能带来很大的好处。GPU的内核通常由一些更高级别的结构来管理,这些结构指示其命令下的所有核心同时执行相同的机器代码级指令,例如一台大型冲压机可以同时对金属片进行分组冲压。因此,如果片元着色器要求浮点数乘以2,那么这个过程首先让所有内核在一个协同的步骤中将数据复制到适当的寄存器。只有当所有内核都完成对寄存器的复制后,才会指示内核开始第二步:在第二次同步操作中将所有寄存器乘以2。 因此,当该系统遇到一个条件语句时,它无法独立地解析这两条语句。而必须确定它的子内核中有多少将沿着条件语句的每条路径运行,并获取一条路径所需的机器码指令列表,从而为所有采用该路径的内核解析这些指令,并为每条路径重复这些步骤,直到处理完所有可能存在的路径。因此,对于if-else语句(两种可能性),它将告诉一组内核处理true路径,然后要求其余内核处理false路径。除非每个内核都采用相同的路径,否则它每次都必须处理两个路径。 因此,应该避免在着色器代码中使用分支和条件语句。当然,这取决于条件对于实现所需图形效果的重要性。但是,如果条件不依赖于每个像素的行为,通常会更好地消化不必要的数学成本,而不是增加GPU的分支成本。
2021-03-19
编译器尽力将着色器代码优化为更友好的GPU底层语言,这样,在处理其他任务时,就不需要等待获取数据。例如,在着色器中可能编写如下所示的未优化代码: 这段代码有一个数据依赖关系,由于对sum变量的依赖关系,每个计算都需要等上一个计算结束才能开始。但是,着色器编译器经常检测到这种情况,并将其优化为使用指令级并行的版本。以下代码是编译前一段代码后生成的和机器代码等效的高级代码: 在本例中,编译器将识别并从内存中并行提取4个值,并通过线程级并行性操作独立获取所有4个值之后完成求和。相对于串行地执行4个取值操作,并行操作可以节省很多时间。 然而,无法编译的长数据依赖链绝对会破坏着色器的性能。如果在着色器的源代码中创建一个强数据依赖关系,那么它将没有任何优化的空间。例如,下面的数据依赖关系会对性能造成很大的影响,因为,如果不等待另一个步骤来获取数据,当前步骤实际上是不可能完成的,因为对每个纹理进行采样需要事先对另一个纹理进行采样,而编译器不能假定在此期间数据没有变化。 以下代码描述了指令之间非常强的数据依赖性,因为每个指令都依赖从上一条指令中采样的纹理数据: 在任何时候,都应该避免这样的强数据依赖关系。
2021-03-19
12.表面着色器
Unity的表面着色器是片元着色器的简化形式,允许Unity开发人员以更简化的方式进行着色器编程。Unity引擎负责转换表面着色器代码,并对刚刚提到的一些优化点进行抽象。然而,它提供了一些可以用作替换的其他值,这降低了精度,但简化了代码生成过程中的数学运算。表面着色器的设计初衷是高效地处理常见情况,而最好的优化方式则是通过编写自定义的着色器来实现。 approxview属性近似于视图方向,减少了昂贵的操作。halfasview属性会降低视图向量的精度,但是要注意它对涉及多个精度类型的数学操作的影响。noforwardadd属性会限制着色器仅考虑单向光,这样着色器仅在一次过程中渲染,从而减少Draw Call并降低光照计算的复杂性。最后,noambient属性禁用着色器中的环境光照,删除一些不必要的额外数学运算。
2021-03-19
13.使用基于着色器的LOD
可以强制Unity使用更简单的着色器来渲染远端对象,这是一种节省填充率的有效方法,特别是将游戏部署到多个平台或需要支持多种硬件功能时。LOD关键字可以在着色器中用来设置着色器支持的屏幕尺寸参数。如果当前LOD级别不匹配此参数值,它将转到下一个回退的着色器,以此类推,直到找到支持给定尺寸参数的着色器。还可以在运行时使用maximumLOD属性更改给定着色器对象的LOD值。 该特性类似于前面介绍的基于网格的LOD,并使用相同的LOD值来确定对象的形式参数,因此应该采用这样的配置。 有关基于着色器的LOD的更多信息,请参见Unity文档: https:/ / docs.unity3d.com/Manual/SL- ShaderLOD.html。
2021-03-19
3.10 使用更少的纹理数据 这种方法简单直接,不失为一个值得考虑的好主意。不管是通过分辨率或者比特率来降低纹理质量,都不能获得理想质量的图形,但有时可以使用16位纹理来获得质量没有明显降低的图形。
2021-03-21
场景窗口有一个Mipmaps着色模式,它根据当前的纹理比例是否适合当前场景窗口的摄像机位置和方向,来决定是将场景中的纹理突出显示为蓝色还是红色。这将有助于识别哪些纹理适合于进一步优化。
2021-03-21
默认情况下,Unity将选择由纹理文件的Compression设置确定的最佳压缩格式。如果深入研究给定纹理文件的特定于平台的选项,就可以使用不同的压缩类型选项,列出给定平台支持的不同纹理格式。可以通过覆盖压缩的默认选项,来节省一些空间或提升性能。 尽管如此,请注意如果必须单独调整纹理压缩技术,请确保已经尝试过减少内存带宽的所有其他方法。这样,就可以通过特定的方式来支持不同的设备。许多开发人员都希望通过一个通用的解决方案来简化工作,而不是通过自定义和耗时的手动工作来获得较小的性能提升。 查看Unity文档,以了解所有可用的纹理格式以及Unity默认推荐的纹理格式,网址为https://docs.unity3d.com/Manual/class-TextureImporterOverride.html。
2021-03-21
如果内存带宽存在问题,就需要减少正在进行的纹理采样量。这里并没有什么特别的技巧而言,因为内存带宽只与吞吐量相关,所以我们考虑的主要指标是所推送的数据量。 减少纹理容量的一种方法是直接降低纹理分辨率,从而降低纹理质量。但这显然不理想,所以另一种方法是采用不同的材质和着色器属性在不同的网格上重复使用纹理。例如,适当变暗的砖纹理可能看起来像石墙。当然,这需要不同的渲染状态,这种方法不会节省Draw Call,但它可以减少内存带宽的消耗。 提示: 你是否注意到“超级马里奥”中云和灌木丛看起来很像,但颜色不同?这正是采用了相同的原理。
2021-03-21
还有一些方法可以将纹理组合到图集中,以减少纹理交换的次数。如果有一组纹理总是在相同的时间一起使用,那么它们可能会合并在一起。这样可以避免GPU在同一帧中反复拉取不同的纹理文件。
2021-03-21
最后,从应用程序中完全删除纹理始终是能采用的最后一个选项。
2021-03-21
与纹理相关的最后一个考虑因素是可用的VRAM数量。大多数从CPU到GPU的纹理传输都发生在初始化期间,但也可能发生在当前视图第一次需要某个不存在的纹理时。这个过程通常是异步的,并使用一个空白纹理,直到完整的纹理准备好渲染为止(请参阅第4章,注意这假设对纹理的读/写访问是禁用的)。因此,应该避免在运行时过于频繁地引入新纹理。
2021-03-21
1.用隐藏的GameObject预加载纹理
在异步纹理加载过程中使用的空白纹理可能会影响游戏质量。我们想要一种方法来控制和强制纹理从磁盘加载到内存,然后在实际需要之前加载到VRAM。 一个常见的解决方法是创建一个使用纹理的隐藏GameObject,并将其放在场景中一条路径的某个位置,玩家将沿着这条路径到达真正需要它的地方。一旦玩家看到该对象,就将纹理数据从内存复制到VRAM中,进行管线渲染(即使它在技术上是隐藏的)。该方法有点笨拙,但是很容易实现,适用于大多数情况。 还可以通过脚本代码更改材质的texture属性,来控制此类行为: GetComponent<Renderer>().material.texture=textureToPreload;
2021-03-21
2.避免“纹理抖动 ”
在极少数情况下,如果将过多的纹理数据加载到VRAM中而所需的纹理又不存在,则GPU需要从内存请求纹理数据,并覆盖一个或多个现有纹理,为其留出空间。随着时间的推移,内存碎片化的情况会越来越糟,这将带来一种风险,即刚从VRAM中刷新的纹理需要在同一帧内再次取出。这将导致严重的内存冲突,因此应尽全力避免发生这种情况。 在PS4、Xbox One和WiiU等现代主机上,这不是什么大问题,因为它们共享CPU和GPU的公共内存空间。考虑到设备总是运行单个应用程序,而且几乎总是呈现3D图形,这种设计是硬件级的优化。然而,大多数其他平台必须与多个应用程序共享时间和空间,其中GPU只是一个可选设备,并不总是使用。因此,它们为CPU和GPU提供了独立的内存空间,必须确保在任何给定时刻使用的纹理总量都低于目标硬件的可用VRAM。
2021-03-21
注意,这种抖动与硬盘抖动并不完全相同,在硬盘抖动中,内存在主内存和虚拟内存(交换文件)之间来回复制,但两者很类似。在任何一种情况下,数据都没必要在两个内存区域之间来回复制,因为在短时间内请求太多的数据,将导致两个内存区域中较小的那个区域无法容纳所有数据。
2021-03-21
当游戏从现代游戏机移植到桌面平台时,这样的抖动应该小心对待,因为它们可能是渲染性能变得糟糕的常见原因。
2021-03-21
1.谨慎地使用实时阴影
【】Hard Shadows所需代价最小
如前所述,阴影很容易成为Draw Call和填充率的最大消耗者之一,因此应该花时间调整这些设置,直到获得所需的性能和/或图形质量。在Edit | Project Settings | Quality | Shadows下有一些重要的阴影设置。对Shadows选项而言,Soft Shadows所需代价最大,Hard Shadows所需代价最小,No Shadows不需要产生代价。
【】这些参数影响shadow的性能
Shadow **Resolution、Shadow **Projection、Shadow ****Distance和Shadow ****Cascades也是影响阴影性能的重要设置。
2021-03-21
Shadow Distance(阴影距离)是运行时阴影渲染的全局乘数。在离相机很远的地方渲染阴影几乎没有什么意义,所以这个设置应该针对游戏以及在游戏期间希望看到的阴影量进行配置。这也是在选项屏幕中显示给用户的常见设置,用户可以选择渲染阴影的距离,以使游戏的性能与其硬件相匹配(至少在桌面计算机上)。 较高的Shadow Resolution(阴影分辨率)和Shadow Cascades(阴影级联)值将增加内存带宽和填充率的消耗。这两种设置都有助于抑制阴影渲染中生成伪影的影响,但代价是Shadowmap纹理尺寸会大得多,并将增加内存带宽和VRAM的消耗。
2021-03-21
Unity文档包含关于Shadowmap的混叠效果和Shadow Cascades功能如何帮助解决问题的很好总结,网址:http://docs.unity3d.com/Manual/DirLight- Shadows.html。
2021-03-21
值得注意的是,因为硬阴影和软阴影唯一的区别是着色器比较复杂,因此相对于硬阴影,软阴影并不会消耗更多的内存或CPU。这意味着有足够填充率的应用程序可以启用软阴影特性,来提高图形的保真度。
2021-03-21
2.使用剔除遮罩
灯光组件的Culling Mask属性是基于层的遮罩,可用于限制受给定灯光影响的对象。剔除遮罩是一种降低照明开销的有效方法,它假设图层交互也与如何使用图层进行物理优化有关。剔除遮罩的对象只能是单个图层的一部分,在大多数情况下,减少物理开销可能比减少照明开销更重要;因此,如果两者存在冲突,那么这可能不是理想的方法。
【】延迟着色只能禁用四个图层
2021-03-21
延迟着色的使用对剔除遮罩的支持很有限。因为延迟着色是以全局的方式处理照明,其只能从遮罩中禁用4个图层,限制了优化其行为的能力。
2021-03-21
3.使用烘焙的光照纹理
与在运行时生成光照和阴影相比,在场景中烘焙光照和阴影对处理器的计算强度要低很多。其缺点是增加了应用程序的磁盘占用、内存消耗和内存带宽滥用的可能性。
2021-03-21
有几个指标可以影响Lightmapping的成本,例如分辨率、压缩、是否使用预先计算的实时GI,当然还有场景中的对象数量。
光照纹理器为场景中所有标记为Lightmap Static的对象生成纹理,对象越多,则生成的纹理数据越多。
这可以利用加法或减法进行场景加载,以最小化每帧需要处理的对象数。当然,在加载多个场景时,这将引入更多的Lightmap数据,所以每次出现这种情况时,内存消耗都会大幅增加,只有在卸载旧场景后才会释放内存。
2021-03-21
注意,对于较新的设备来说,以下任何一种方法或所有方法最终都可能过时。移动设备的功能发展非常迅速,应用于移动设备的以下技术仅仅反映了过去5年左右的常规成果。应该检查这些方法背后的假设条件,以核实移动设备的局限性是否仍然适合移动市场。
2021-03-21
4.最小化纹理大小
与桌面GPU相比,大多数移动设备的纹理缓存都非常小。市场上仍然支持OpenGL ES 1.1或更低版本的设备非常少,比如iPhone 3G,但是这些设备支持的最大纹理大小也仅有1024×1024。支持OpenGL ES 2.0的设备,例如从iPhone 3GS到iPhone 6S,可以支持高达2048×2048的纹理。最后,支持OpenGL ES 3.0或更高版本的设备(如运行iOS7的设备)可以支持高达4096×4096的纹理。
提示: Android设备太多,无法一一列出,但是Android开发人员门户网站提供了支持OpenGLES的设备分类。这类信息会定期更新,以帮助开发人员确定Android市场支持的API,网站:https://developer.android.com/about/ dashboards/ index.html。 仔细检查选定的设备硬件,以确保它支持希望使用的纹理文件大小。然后,移动市场中常见的设备通常不是最新的设备。因此,如果希望游戏吸引更广泛的用户(增加其成功的机会),就必须愿意支持性能较弱的硬件。
注意,对GPU而言太大的纹理将在初始化期间被CPU压缩。这会浪费宝贵的加载时间,并且由于分辨率的失控降低将带来意想不到的质量损失。由于可用的VRAM和纹理缓存大小是有限的,因此纹理重用对移动设备显得至关重要。
5.确保纹理是“方形”且大小为“2的幂次方”
【】GPU级别的压缩
第4章就讨论过这个主题,但是GPU级纹理压缩主题值得重新讨论。如果纹理不是方形的,GPU很难对它进行压缩,因此请确保遵守通用的开发约定,并保持纹理是方形的,其大小为2的幂次方。
- 方形
- 2的幂次方
6.在着色器中尽可能使用“最低的精度格式”
移动GPU对着色器中的精确格式特别敏感,因此我们应使用最小的精度格式,例如half。在相关的说明中,出于同样的原因,应该完全避免精确格式的转换。
- 使用最小的精度格式
- 完全避免精确格式的转换
第7章 虚拟速度和增强加速度
7.1 XR开发
与传统的游戏和应用不同,VR程序需要把用户的舒适度作为一项优化指标。令人遗憾的是,对于早期的VR使用者来说,头晕、眩晕、眼疲劳、头痛,甚至身体失去平衡造成的伤害都太常见了,我们有责任控制这些对使用者造成的负面影响。本质上,内容对用户的舒适性和硬件一样重要,如果是为媒体构建内容,就需要认真对待。
2021-03-22
事实上,由于对自己游戏的熟悉,开发人员是最有偏见的测试人员。如果没有意识到这一点,测试时就可能绕过应用程序所产生的最令人恶心的行为,与经历同样情况的新用户相比,这个测试是不公平的.

- 保持材质的数目尽可能少。这使得Unity更容易进行批处理。
- 使用纹理图集(一张大贴图里包含了很多子贴图)来代替一系列单独的小贴图。它们可以更快地被加载,具有很少的状态转换,而且批处理更友好。
- 如果使用了纹理图集和共享材质,使用Renderer.**sharedMaterial **来代替Renderer.material 。
- 使用光照纹理(lightmap)而非实时灯光。
- 使用LOD,好处就是对那些离得远,看不清的物体的细节可以忽略。
- 遮挡剔除(Occlusion culling)
- 使用mobile版的shader。因为简单
2021-03-22
用户在VR中会经历如下3种不适
- 运动晕眩
- 眼睛疲劳
- 迷失方向
2021-03-22
VR应用中需要达到的最重要的性能指标是高FPS的值,最好是90FPS或更高,这会带来更平滑的视觉体验,因为使用者的头部运动和外部运动之间的关联很少断开。任何一段时间的长期掉帧或FPS值始终低于该值,都可能给用户带来很多问题,应用程序在任何时候都表现良好是至关重要的。此外,还应该非常小心地控制用户的视角。应该避免改变HMD的视野(让用户自己决定它所面对的方向),避免在长时间内产生加速度,或导致不受控制的旋转和水平运动,因为这些极有可能引发用户的眩晕和平衡问题。
2021-03-22
在赛车游戏中放置倾斜转弯似乎可以极大地提高用户的舒适性,因为用户会自然地倾斜头部并调整平衡,以适应转弯。
2021-03-22
幸运的是,对于360 Video格式而言,行业标准的帧率(如24FPS或29.97FPS)似乎不会对用户的舒适性造成灾难性的影响。但注意该帧率仅适用于视频的回放。渲染FPS是一个单独的FPS值,它指示定位头部跟踪的平滑程度。渲染FPS必须始终非常高,以避免不适(理想情况下为90 FPS)。
7.2 性能增强
VR应用程序性能的最大威胁是GPU填充率,这是其他游戏中最可能出现的瓶颈之一,但对于VR来说,情况更为严重,因为高分辨率图像总是试图渲染到更大的帧缓冲区(因为有效地渲染了场景两次——每只眼睛一次)
2021-03-24
AR应用程序通常会在CPU和GPU中有极大的消耗,因为AR平台大量使用GPU的并行管道来解析对象的空间位置,并执行诸如图像识别之类的任务,还需要大量的Draw Call以支持这些行为。
【】该提示不是性能增强提示,而是一个需求
2021-03-24
该提示不是性能增强提示,而是一个需求。抗锯齿显著提高了XR项目的保真度,因为对象将更好地混合在一起,显示的像素感更少,提高了沉浸度,这可能会耗费大量的填充率。应该尽早启用这个特性,并假设它总是启用的情况下实现性能目标,禁用它只是绝对的最后手段。
2021-03-22
【】避免欧拉角
避免为任何类型的定向行为使用欧拉角。四元数旨在更好地描述角度(唯一的缺点是更抽象,调试时更难可视化),并在出现变化时能保持准确性,同时避免可怕的万向节死锁。计算时使用欧拉角,最终可能在多次旋转后导致不准确,这是很可能的,因为在VR和AR中,用户的视点每秒都会发生很多次微小的变化。
2021-03-23
【】跟上最新发展
Unity提供了一个包含VR设计和优化技巧的有用文章列表,随着媒体和市场的成熟和新技术的发现,会更新这些文章。它比本书的更新更及时,所以不时地查看它们,以获取最新的提示。上述文件列表的网址为https://unity3d.com/learn/tutorials/topics/ virtual-reality。
2021-03-24
还应该关注Unity的博客,以确保不会错过与XR API更改、性能增强和性能建议有关的重要内容。
7.3 本章小结
第8章将深入研究Unity的底层引擎以及构建它的各种框架、层和语言。本质上是从更高级的角度讨论脚本代码,并研究一些方法,以全面改进CPU和内存管理。
第8章 掌握内存管理
【】长期脱离底层问题,可能导致潜在灾难
通过Unity高效地使用内存需要对Unity引擎底层、Mono平台和C#语言有扎实的理解。同时,如果使用IL2CPP脚本后端,那么明智的做法是熟悉它的内部工作。对于一些开发人员来说,这可能有点令人生畏,因为它们选择Unity3D作为其游戏开发解决方案,主要就是为了避免引擎开发和内存管理带来的底层工作。游戏开发者更乐意关注高层话题,例如游戏玩法实现,关卡设计和艺术资源管理,但遗憾的是,现代计算机系统是个复杂的工具,如果长期脱离底层问题,可能导致潜在灾难。
2021-03-24
理解内存分配和C#语言特性在做什么,它们如何与Mono平台交互以及Mono如何与底层的Unity引擎交互,绝对是编写高质量、高效脚本代码的关键
2021-03-24
幸运的是,想要高效使用C#语言并不需要成为C#语言大师。本章将把这些复杂的主题归结为一种更易于理解的形式,并分为以下主题:
- Mono平台:
- 本地和托管内存域
- 垃圾回收
- 内存碎片
- **IL2CPP **
- 如何分析内存问题
- 不同的内存相关性能增强:
- 最小化垃圾回收
- 正确使用值类型和引用类型
- 正确地使用字符串
- 与Unity引擎相关的许多潜在增强
- 对象和预制体池
2021-03-24
8.1 Mono平台
Mono是一个开源项目,它基于API、规范和微软的.NET Framework的工具构建了自己的类库平台。本质上,它是.NET类库的开源重制,在几乎不访问原始源码的情况下完成,和微软的原始类库完全兼容。
2021-03-24
可以编译为**.NET**的通用中间语言(Common Intermediate Language,CIL)的任何语言都能与Mono平台集成。这些语言包括C#自身,还有F#、Java、VB .NET、PythonNet和IronPython等
2021-03-24
一个常见的错误观念是Unity引擎是构建在Mono平台之上的。这是错误的,因为基于Mono的层没有处理很多重要的游戏任务,如音频、渲染、物理以及时间的跟踪。Unity Technologies出于速度的原因构建了本地C++后端,允许它的用户将Mono作为脚本编写界面,控制该游戏引擎。因此,Mono只是底层Unity引擎的一个组成部分。这和很多其他的游戏引擎一样,在底层运行C++,处理诸如渲染、动画和资源管理这样的重要任务,而为要实现的玩法逻辑提供高级脚本语言。因此Unity Technologies选择Mono平台以提供该特性。
2021-03-24
本地代码通常是为特定平台编写的代码。例如,在Windows中编写代码来创建窗口对象,或和网络子系统交互的接口,与Mac、UNIX、Playstation4、XBox One等平台执行相同任务的代码是完全不同的。
2021-03-23
一些脚本语言也可以在运行时解释,这意味着它们不需要在执行之前进行编译。
原始指令动态转化为机器代码,并在运行时读取执行;当然这通常使代码执行得相对较慢。
C#不是这样!
2021-03-23
这样的语言常称为托管语言,其特点是托管代码。从技术上而言,这是微软创造的一个术语,指必须在公共语言运行时**(Common Language Runtime,CLR)运行的源码,和通过目标操作系统编译与运行的代码不同。
2021-03-23
由于CLR和其他语言存在的普遍和通用特性,它们具有相似的运行时环境(例如Java),因此出现了“托管”这一术语
2021-03-23
托管”指代依赖于独立运行时环境来执行,且由自动垃圾回收进行监控的代码。
2021-03-23
托管语言的运行时性能消耗通常比对应的本地代码更大,但这种严重性正在逐年变弱。部分由于工具和运行时环境的逐渐优化,部分由于平均设备的计算能力逐渐增强。尽管如此,使用托管语言的主要争论点依然是它们的自动内存管理。
手动管理内存是一项复杂的任务,需要很多年的艰难调试才能精通,但很多开发者认为托管语言解决该问题的方式不可预测,产品质量风险太大。这些开发者可能会提到托管代码的性能永远达不到和本地代码同样的级别,因此用托管代码构建高性能应用程序是很鲁莽的行为。 这在某种程度上是正确的,因为托管语言总是带来运行时开销,而我们失去了对运行时内存分配的部分控制。对于高性能服务器架构而言,这将是致命弱点;然而,对于游戏开发,由于不是所有的资源使用都将导致瓶颈,而最好的游戏也不一定充分利用程序的每个字节,因此使用托管语言成为一种平衡的行为。
例如,假定一个UI在本地代码中的刷新时间是30微秒,而由于有100%的额外开销(一个极端示例),在托管代码中刷新时间为60微妙。托管代码版本已经足够快速,而用户观察不到两者的差异,因此使用托管代码处理该任务没有任何危害。
2021-03-23
【】每个域存储不同的数据类型,关注不同的任务集。
Unity引擎中的内存空间本质上可以划分为3个不同的内存域。每个域存储不同的数据类型,关注不同的任务集。
【】3.1 托管域
2021-03-23
第一个内存域——托管域,大家应该非常熟悉。
该域是Mono平台工作的地方,我们编写的任何MonoBehaviour脚本和自定义的C#类在运行时都会在此域实例化对象,因此我们编写的任何C#代码都会很明确与此域交互。它称为托管域,因为内存空间自动被垃圾回收管理。
【】3.2 本地域 【!】
2021-03-23
第二个内存域——本地域——它更微妙,因为我们仅仅间接地与之交互。
Unity有一些底层的本地代码功能,它由C++编写,并根据目标平台编译到不同的应用程序中。该域关心内部内存空间的分配,如为各种子系统(诸如渲染管线、物理系统、用户输入系统)分配资源数据(例如纹理、音频文件和网格等)和内存空间。最后,它包括GameObejct和Component等重要游戏对象的部分本地描述,以便和这些内部系统交互。
 这也是大多数内建Unity类(例如Transform和Rigidbody组件)保存其数据的地方。
这也是大多数内建Unity类(例如Transform和Rigidbody组件)保存其数据的地方。
【】本地~托管桥的由来。
托管域也包含存储在本地域中的对象描述的包装器。因此,当和Transform等组件交互时,大多数指令会请求Unity进入它的本地代码,在那里生成结果,接着将结果复制回托管域。这正是托管域和本地域之间本地-托管桥的由来,这在前面章节中简单提过。
2021-03-23
当两个域对相同实体有自己的描述时,跨越它们之间的桥需要内存进行上下文切换,而这会为游戏带来很多相当严重的潜在性能问题。显然,由于跨越桥的开销,应该尽可能多地最小化此行为。第2章阐述了一些该方面的技术。
【】3.3 外部库
2021-03-23
第三个也是最后一个内存域是外部库,例如DirectX和OpenGL库,也包括项目中包含的很多自定义库和插件。在C#代码中引用这些类库将导致类似的内存上下文切换和后续成本。
2021-03-23
在大多数现代操作系统中,运行时的内存空间分为两种类型:栈和堆。
栈是内存中预留的特殊空间,专门用于存储小的、短期的数据值,这些值一旦超出作用域就会自动释放,因此称为栈。
顾名思义,它就像栈数据结构一样,从顶部压入与弹出数据。
栈包含了已经声明的任何本地变量,并在调用函数时处理它们的加载和卸载。这些函数调用通过所谓的调用栈进行拓展与收缩。
当对当前函数完成调用栈的处理时,它跳回调用栈中之前的调用点,并从之前离开的位置继续执行剩余内容。之前内存分配的开始位置总是已知的,没有理由执行内存清理操作,因为新的内存分配只会覆盖旧数据。因此,栈相对快速、高效。
2021-03-23
MB,Megabyte
2021-03-23
堆表示所有其他的内存空间,并用于大多数内存分配。
2021-03-23
在物理上栈和堆没有什么不同,它们都只是内存空间,包含存在于RAM中的数据字节。操作系统会请求并保存这些数据字节。不同之处在于使用它们的时机、场合和方式。
【】托管堆
2021-03-23
在托管语言中,内存释放通过垃圾回收器自动处理。在Unity程序的初始化期间,Mono平台向操作系统申请一串内存,用于生成堆内存空间(通常称为托管堆),供C#代码使用。这个堆空间开始时相当小,不到1兆字节,但是随着脚本代码需要新的内存块而增长。如果Unity不再需要它,那么该空间可以通过释放回操作系统来缩小。
2021-03-23
1.垃圾回收
垃圾回收器(Garbage Collector,GC)有一个重要工作,该工作确保不使用比所需要的更多的托管堆内存,而不再需要的内存会自动回收。
例如,如果创建一个GameObject,接着销毁它,那么GC将标记该GameObject使用的内存空间,以便以后回收。这不是一个立刻的过程,GC只会在需要的时候回收内存。
【】GC将拓展当前堆空间作为最后的手段
2021-03-23
当请求使用新的内存空间,而托管的堆内存中有足够的空闲空间以满足该请求时,GC只简单地分配新的空间并交给调用者。然而,如果托管堆中没有足够的空间,那么GC需要扫描所有已存在且不再使用的内存分配并清除它们。GC将拓展当前堆空间作为最后的手段。
2021-03-23
Unity使用的Mono版本中的GC是一种追踪式GC,它使用标记与清除策略。
该算法分为两个阶段:每个分配的对象通过一个额外的数据位追踪。该数据位标识对象是否被标记。这些标记设置为false,标识它尚未被标记。
2021-03-23
当收集过程开始时,它通过设置对象的标识为true,标记所有依然对程序可访问的对象。可访问对象要么是直接引用(例如栈上的静态或本地变量),要么是通过其他直接或间接可访问对象的字段(成员变量)来间接引用。本质上,它收集一系列依然被程序引用的对象。对程序而言,任何没有引用的对象本质上都是不可见的,而这些对象可以被GC回收。
第二阶段涉及迭代这类引用(GC将在程序的整个生命周期中跟踪这些引用),并基于它的标记状态决定它是否应该回收。如果对象被标记,那么在某处依然引用它,GC将无视它。然而,如果它没有被标记,那么它是回收的候选者。在该阶段,所有标记的对象都被跳过,但在下次垃圾回收扫描之前会将它们设置回false。
2021-03-23
一旦第二个阶段结束,所有没有被标记的对象被回收以释放空间,然后重新访问创建对象的初始请求
2021-03-23
如果GC已经为对象释放了足够的空间,那么在新释放的空间中分配内存并返回给调用者。然而,如果空间不够,就只能使用最后的补救手段,即必须通过向操作系统请求以拓展托管堆,此时最终可以分配内存空间并返回给调用者。
2021-03-23
程序中的所有对象很少以它们分配的顺序被回收,而且它们占用的内存大小很少一样。这导致了内存碎片。
2021-03-23
2.内存碎片
当以交替的顺序分配和释放不同大小的对象时,以及当释放大量小对象,随后会分配大量大对象时,就会出现内存碎片。
2021-03-23
图8-1 常见堆内存空间中的内存分配与回收
2021-03-23
【】内存碎片导致两个问题。
首先,从长期看,它显著地减少新对象的总可用内存空间,这取决于分配和回收的频率。它通常导致GC拓展堆,以便为新的分配腾出空间。其次,它使新的分配花费的处理时间更长,因为需要花费额外的时间查找足以容纳对象的新内存空间。
2021-03-23
堆中分配新的内存空间时,可用空间的位置和可用空闲空间的大小同样重要。无法跨越不同的内存部分切分对象,因此GC必须持续查找,在花时间进行详尽查找后,甚至还要花费更多时间,直到找到足够大的空间或增加整体的堆大小,以存放新对象。
无
2021-03-23
3.运行时的垃圾回收 因此在最坏的情况下,当游戏请求新的内存分配时,CPU在完成分配之前需要花费CPU周期完成下面的任务: (1)验证是否有足够的连续空间用于分配新对象。 (2)如果没有足够空间,迭代所有已知的直接和间接引用,标记它们是否可达。 (3)再次迭代所有这些引用,标识未标记的对象用于回收。 (4)迭代所有标识对象,以检查回收一些对象是否能为新对象创建足够大的连续空间。 (5)如果没有,从操作系统请求新的内存块,以便拓展堆。 (6)在新分配的块前面分配新对象,并返回给调用者。
1-使用静态定义
2-代码设计时尽量避免频繁分配内存
2021-03-23
.多线程的垃圾回收 GC运行在两个独立线程上:主线程和所谓的Finalizer Thread。当调用GC时,它运行在主线程上,并标志堆内存块为后续回收。这不会立刻发生。由Mono控制的Finalizer Thread在内存最终释放并可用于重新分配之前,可能会延迟几秒。
无
2021-03-24
由于这种延迟,不应该依赖内存一旦回收就可用这一观念,而且因此不应该浪费时间尝试消耗可用内存的最后一个字节。必须确保有某种类型的缓冲区用于未来的分配。
无
2021-03-24
8.2 代码编译
代码转换为通用中间语言(Common Intermediate Language,CIL),它是本地代码之上的一种抽象。这正是.NET支持多种语言的方式——每种语言都使用不同的编译器,但是它们都会转换为CIL,因此不管选择了什么语言,输出实际是一样的。CIL类似Java字节码,基于Java字节码,CIL本身是没用的,因为CPU不知道如何运行该语言中定义的指令。 在运行时,中间代码通过Mono虚拟机(VM)运行,VM是一种基础架构元素,允许相同代码运行在不同平台,而不需要修改代码本身。Mono虚拟机是.NET公共语言运行时(Common Language Runtime,CLR)的一个实现。因此,如果在iOS上运行,则游戏运行在基于iOS的虚拟机上;如果游戏运行在Linux上,就使用更适用于Linux的另一个虚拟机。这正是Unity允许编写一次代码,能魔法般地在多个平台上工作的方式。
无
2021-03-24
在CLR中,中间CIL代码实际上根据需要编译为本地代码。这种及时的本地编译可以通过AOT(Ahead-Of-Time)或JIT(Just-In-Time)编译器完成,选择哪一个取决于目标平台。这些编译器允许把代码段编译为本地代码,允许平台架构完成补全已写的指令,而不用重新编写它们。两种编译器类型主要的区别在于代码编译的时间。
无
2021-03-24
AOT编译是代码编译的典型行为,它发生于构建流程之前,在一些情况下则在程序初始化之前。不管是哪一种,代码都已经提前编译,没有后续运行时由于动态编译产生的消耗。当CPU需要机器码指令时,总是存在可用指令。
无
2021-03-24
JIT编译在运行时的独立线程中动态执行,且在指令执行之前。通常,该动态编译导致代码在首次调用时,运行得稍微慢一点,因为代码必须在执行之前完成编译。然而,从那时开始,只要执行相同的代码块,都不需要重新编译,指令通过之前编译过的本地代码执行。
无
2021-03-24
软件开发中的常见格言是:90%的工作只由10%的代码完成。这通常意味着JIT编译对性能的优势比简单直接地解释CIL代码强。然而,由于JIT编译器必须快速编译代码,它不能使用很多静态AOT编译器可以使用的优化技术。
无
2021-03-24
不是所有平台都支持JIT编译,当使用AOT时一些脚本功能不可用。Unity在下面网址提供了一个完整的限制列表: https://docs.unity3d.com/Manual/ScriptingRestrictions.html
无
2021-03-23
IL2CPP 几年前,Unity Technologies面临着一个选择,要么选择继续支持Unity越来越难跟上的Mono平台,要么实现自己的脚本后端。Unity Technologies选择了后者,而现在有很多平台支持IL2CPP,它是中间语言到C++的简称。
无
2021-03-23
Unity Technologies关于IL2CPP的初始博文,该决定背后的理由及其长期效益可以在https://blogs.unity3d.com/2014/05/20/the-future-of-scripting-in- unity/上找到。
无
2021-03-23
IL2CPP是一个脚本后端,用于将Mono的CIL输出直接转换为本地C++代码。由于应用程序现在运行本地代码,因此这将带来性能提升。这最终使Unity Technologies能更好地控制运行时行为,因为IL2CPP提供了自己的AOT编译器和VM,允许定制对GC等子系统和编译过程的改进。IL2CPP并不打算完全取代Mono平台,但它是我们可选的工具,改善了Mono提供的部分功能。
带来性能提升!
2021-03-23
。
无
2021-03-24
可以在下面网址找到当前支持IL2CPP的平台列表: https://docs.unity3d.com/Manual/IL2CPP.html
无
2021-03-24
8.3 分析内存
我们关心两个内存管理的问题:消耗了多少内存,以及分配新内存块的频繁程度
无
2021-03-24
可以通过Profiler窗口的Memory Area观察已经分配了多少内存,以及该内存域预留了多少内存。本地内存分配显示在标记为Unity的值中,甚至可以使用Detailed Mode和采样当前帧,获得更多详细信息,如图8-2所示。 图8-2 Profiler窗口中Memory Area的内存消耗信息—— Unity标签的值为本地内存
无
2021-03-24
注意Edit Mode下的内存消耗通常和独立版本大不相同,因为应用了各种调试以及编辑器挂接数据。在此进一步鼓励大家避免使用Edit Mode进行基准测试和测量。
使用真机+Profiler
2021-03-23
也可以使用Profiler.GetRuntimeMemorySize()方法获取特定对象的本地内存分配。
无
2021-03-23
托管对象的描述本质上链接到它们的本地描述。最小化本地内存分配的最好方式是优化使用的托管内存。 可以在Profiler窗口的Memory Area中验证为托管堆分配以及预留了多少内存,如图8-3中标签为Mono的值: 图8-3 Profiler窗口中Memory Area的内存消耗信息—— Mono标签的值为托管堆内存 也可以在运行时分别使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()方法确定当前使用和预留的堆空间。
无
2021-03-23
以用于度量内存管理健康度的最佳指标是简单观察GC的行为。它做的工作越多,所产生的浪费就越多,而程序的性能可能就越差。 可以同时使用Profiler窗口的CPU Usage Area(GarbageCollector复选框)和Memory Area(GC Allocated复选框)以观察GC的工作量和执行时间。
无
2021-03-24
内存效率问题的根源分析是一件具有挑战且耗时的操作。当观察GC行为的峰值时,它可能是前一帧分配太多内存的征兆而当前帧只分配了一点内存,此时请求GC扫描许多碎片化的内存,确定是否有足够的空间,并决定是否能分配新的内存块。它清理的内存可能在很长一段时间之前就分配好了,只有应用程序运行了很长时间,才能观察到这些影响,甚至在场景相对空闲时也会发生,并没有突然触发GC的明显原因。更糟的是,Profiler只能指出最后几秒发生了什么,而不能直接显示正在清除什么数据。 如果想要确定没有产生内存泄漏,必须谨慎并严格测试程序,在模拟通常的游戏场景或者创造GC在一帧中有太多工作需要完成的情况时,观察它的内存行为。
无
2021-03-24
8.4 内存管理性能增强
在大多数游戏引擎中,如果遇到性能问题,可以将低效的托管代码移植到更快的本地代码中
无
2021-03-23
本地插件通常用于与不是针对C#构建的系统和库交互。这迫使我们大多数时候都由于性能原因,需要尽可能使用C#脚本级别代码。
无
2021-03-23
最小化垃圾回收问题的一种策略是在合适的时间手动触发垃圾回收,当确定玩家不会注意到这种行为时就可以偷偷触发垃圾回收。垃圾回收可以通过System.GC.Collect()手动调用。 触发回收的好机会可以是加载场景时,当游戏暂停时,在打开菜单界面后的瞬间,在切换场景时,或任何玩家观察不到或不关心突然的性能下降而打断游戏的行为时。甚至可以在运行时使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()方法决定最近是否需要调用垃圾回收。 可以引发一些指定对象的释放。如果讨论的对象是Unity对象包装器之一,例如GameObject或MonoBehaviour组件,那么终结器(finalizer)将在本地域中首次调用Dispose()方法。此时,本地域和托管域里消耗的内存都将被释放。在一些特殊情况下,如果Mono包装器实现了IDisposable接口类(即它在脚本代码中提供Dispose()方法),那么可以真正控制该行为,并强制内存立刻释放。
无
2021-03-23
其他所有资源对象提供某种类型的卸载方法以清除任何未使用的资源数据,例如Resources.UnloadUnusedAssets()。实际的资源数据存储在本地域里,因此该方法不涉及垃圾回收技术,但思想基本相同。它将遍历特定类型的所有资源,检查它们是否不再被引用;如果资源没有被引用,则释放它们。然而,这同样是一个异步处理,不能保证什么时候释放。该方法在加载场景之后由内部自动调用,但这依然不能保证立刻释放内存。首选的方法是使用Resources.UnloadAsset(),一次卸载一个指定资源。该方法通常更快,因为不需要迭代整个资源数据集合,来确定哪个资源是未使用的。
无
2021-03-23
最好的垃圾回收策略是避免垃圾回收;如果分配很小的堆内存并且尽可能控制其使用,则不必担心发生频繁垃圾回收以及昂贵的性能开销
无
2021-03-23
如果JIT编译导致运行时性能下降,请注意实际上有可能在任何时刻通过反射强制进行方法的JIT编译。反射是C#语言一项有用的特性,它允许代码库探查自身的类型信息、方法、值和元数据。使用反射通常是一个非常昂贵的过程,应该避免在运行时,或者甚至仅在初始化或其他加载时间使用。不这样做容易导致严重的CPU峰值和游戏卡顿。
无
2021-03-23
可以使用反射手动强制JIT编译一个方法,以获得函数指针
无
2021-03-23
前面的代码仅对public方法有用。获取private或protected方法可以通过使用BindingFlags完成
无
2021-03-23
这类方法应该仅运行在确定JIT编译会导致CPU峰值的地方。这可以通过重启应用并分析方法的首次调用与随后所有后续调用来验证。调用差异会指出JIT编译的消耗。
无
2021-03-23
.NET类库中强制JIT编译的官方方法是RuntimeHelpers.PrepareMethod(),但在当前Unity使用的Mono版本(Mono 2.6.5)中没有正确实现该方法。在Unity引入更新版本的Mono工程之前,应该使用前面的方法。
无
2021-03-23
并非在Mono中分配的所有内存都通过堆进行分配。.NET Framework(C#语言只实现了.NET规范)有值类型和引用类型的概念,而当GC在执行标记-清除算法时,只有后者需要被GC标记。由于引用类型的复杂性、大小和使用方式,它们会(或需要)在内存中存在一段时间。大的数据集和从类实例化的任何类型的对象都是引用类型。这也包括数组(不管它是值类型的数组或是引用类型的数组)、委托、所有的类,诸如MonoBehaviour、GameObject和自定义的类。
无
2021-03-23
引用类型通常在堆上分配,而值类型可以分配在栈或堆上
无
2021-03-23
诸如bool、int和float这些基础数据类型都是值类型的示例。这些值通常分配在栈上,但一旦值类型包括在引用类型中,例如类或数组,那么暗示该值对于栈而言太大,或存在的时间需要比当前的作用域更长,因而必须分配在堆上,与包含它的引用类型绑定在一起。
无
2021-03-23
一个方法体中定义一个int类型的变量A。这个变量A就会分配在“栈”中。
2021-03-24
如果将一个整数创建为MonoBehaviour类定义的成员变量,那么它现在包含在一个引用类型(类)中,必须与它的容器一起分配在堆上:
无
2021-03-23
整型_data现在是一个额外的数据块,它消耗了包含它的TestComponent对象旁边的堆空间。如果TestComponent被销毁,那么整数也随之释放,不会在此之前释放。 类似地,如果将整数放到普通的C#类中,那么适用于引用类型的规则依然生效,对象会分配在堆上:
无
2021-03-23
因此,在类方法中创建临时值类型与将长期值类型存储为类的成员字段有很大的区别。在前一种情况下,将其保存在栈中,但后一种情况中,将其保存为引用类型,这意味着它可以在其他地方引用
无
2021-03-23
本例中,不能在TestFunction()方法结束时释放dataObj的指针,因为对该对象的总引用数量从2变为1。由于不是0,因此GC依然会在标记-清除期间标记它。需要在对象无法再访问之前设置_testDataObj为null,或让它引用别的对象。
无
2021-03-24
注意,值类型必须有一个值且不能为null。如果栈分配的类型被赋予引用类型,那么数据会简单地复制。即使对于值类型的数组,也是如此。
无
2021-03-24
引用功能的细微变化最终决定了某个对象是引用类型还是值类型,应该在有机会时尝试使用值类型,这样它们会在栈上分配而不是在堆上分配。任何情况下,只要发送的数据块的寿命不比当前作用域更长时,就是使用值类型而不是引用类型的好机会。表面上,数据是传递给相同类的另一个方法还是传递给另一个类的方法都不重要,它依然是一个值类型,该值类型存在于栈上,直到创建它的方法退出作用域。
无
2021-03-24
值类型和引用类型之间一个重要的差异是引用类型只不过是指向内存中其他位置的指针,它仅消耗4或8字节(32位或64位,取决于架构),不管它真正指向的是什么。当引用类型作为参数传递时,只有这个指针的值被复制到函数中。哪怕引用类型指向的是巨大的数组数据,由于被复制的数据非常小,该操作会非常快。
无
2021-03-24
同时,值类型包含存储在具体对象中的完整数据位。因此,不管是在方法中传递,还是保存在其他值类型中,值类型总是复制它所有的数据。在一些情况下,这意味着,与使用引用类型,让GC处理它相比,过多地将巨大的值类型作为参数传递会昂贵得多。对于大多数值类型,这不是问题,因为它们的大小和指针差不多,但下一节开始讨论结构体类型时,这个问题会很严重。
无
2021-03-24
数据也可以使用ref关键字,按引用传递,但这和值与引用类型的概念非常不同,尝试理解后台发生什么时,区分它们是很重要的
无
2021-03-24
如果使用类的唯一目的是在程序中向某处发送数据块,且数据的持续存在时间不需要超过当前作用域,那么可以使用struct类型来替代,因为class类型在堆上分配内存是没有充分理由的。
无
2021-03-24
仅将DamageResult的定义从class类型修改为struct类型,就能节省很多不必要的垃圾回收,因为值类型在栈上分配,而引用类型在堆上分配:
无
2021-03-24
这不是一刀切的解决方案。由于结构体是值类型,它将复制整个数据块,并传递到调用栈的下个方法中,不管数据块的大小。因此,如果struct对象通过值在很长调用链的5个不同方法中传递,那么5个不同的栈会同时进行数据复制。回想一下栈的释放是无消耗的,但栈的分配(包含了数据复制)并不是如此。数据复制的开销对于小的值可以忽略不计,例如一些整数或浮点数,但通过结构体一遍又一遍地传递极大的数据集,其开销明显不是可以忽略的,而且应该避免。 要解决此问题,可以使用ref关键字通过引用方式传递struct对象,以最小化每次复制的数据量(只复制一个指针)。然而,这可能很危险,因为通过引用传递结构体将允许后续方法修改struct对象,这种情况下最好将数据值设置为只读。这意味着值只能在构造函数中初始化,之后不能在它自己的成员函数中再次初始化,这防止在调用链中传递时发生意外改变。 当结构体包含在引用类型中时,上述方法也是正确的,如下代码:
无
2021-03-24
真正发生的事情是,当DataStruct对象(_memberStruct)在StructHolder内的堆上分配时,它依然是值类型,没有因为它是引用类型的成员变量,就被魔法般地转换为引用类型
无
2021-03-25
这些方法编写得有点荒谬,但它们表明了需要关心的重点
无
2021-03-25
注意,当分配引用类型的数组时,就是在创建引用的数组,每个引用都可以引用堆上的其他位置。然而,当分配值类型的数组时,是在堆上创建值类型的压缩列表。每个值类型由于不能设置为null,会初始化为0,而引用类型数组的每个引用会初始化为null,因为还没有被赋值。
无
2021-03-25
字符串本质上是字符数组,因此它们是引用类型,遵循与其他引用类型相同的所有规则;它们在堆上分配,从一个方法复制到另一个方法时唯一复制的就是指针
无
2021-03-25
字符串并不快速,只是比较方便。
无
2021-03-25
字符串对象类是不可变的,这意味着它们不能在分配内存之后变化。所以,当改变字符串时,实际上在堆上分配了一个全新的字符串以替换它,原来的内容会复制到新的字符数组中,并且根据需要修改对应字符,而原来的字符串对象引用现在指向新的字符串对象。在此情况下,旧的字符串对象不再被引用,不会在标记-清除过程中标记,最终被GC清除。因此,懒惰的字符串编程将导致很多不必要的堆分配和垃圾回收。
导致两个问题 : 1-内存重新分配 2-垃圾回收 。 然后理解导致这两个问题的原因。
2021-03-24
到目前为止,一切都很好。 然而,一旦修改localString的值,就会发生一点冲突。字符串是不可变的,因而不能修改它们,因此,必须分配一个包含值"World!"的字符串并将它的引用赋给localString的值;现在"Hello"字符串引用的数量变为1。因此,testString的值没有改变,它的值一直与为Debug.Log()打印的那样。调用DoSomething()之后,会在堆上创建一个新字符串,随后被垃圾回收,并没有修改任何数据。这正是课本上关于浪费的定义。
无
2021-03-29
到目前为止,一切都很好。 然而,一旦修改localString的值,就会发生一点冲突。字符串是不可变的,因而不能修改它们,因此,必须分配一个包含值"World!“的字符串并将它的引用赋给localString的值;现在"Hello"字符串引用的数量变为1。因此,testString的值没有改变,它的值一直与为Debug.Log()打印的那样。调用DoSomething()之后,会在堆上创建一个新字符串,随后被垃圾回收,并没有修改任何数据。这正是课本上关于浪费的定义。
1-字符串是不可变的
2-会创建一个新的字符串并将引用的地址赋值给它。
2021-03-26
如果修改DoSomething()的方法定义,通过ref关键字传入字符串引用,输出就会变为"World!”。当然,这和值类型是一样的,会导致很多开发者错误地假设字符串是值类型。然而,这是第四个,也是最后一个数据传递情形:引用类型通过引用传递,这允许修改原引用所引用的对象。
那段示例代码加上。
2021-03-25
每当这些值类型以处理对象的方式隐式地处理时,CLR会自动创建一个临时对象来存储或装箱内部的值,以便将其视为典型的引用类型对象。显然,这将导致堆分配,以创建包含的容器。
无
2021-03-26
装箱和将值类型作为引用类型的成员变量不同。装箱仅在通过转化或强制转化将值类型视为引用类型时发生。
无
2021-03-26
数据在内存中组织方式的重要性很容易被遗忘,但如果处理得当,会带来相当大的性能提升。不论何时,应当尽可能避免缓存丢失,这意味着在大多数情况下,内存中连续存储的大量数据应该按顺序迭代,而不是以其他迭代方式迭代。
无
2021-03-26
本质上,我们希望将大量引用类型和大量值类型分开。如果值类型(例如结构体)内有一个引用类型,那么GC将关注整个对象,以及它所有的成员数据、间接引用的对象。当发生标记-清除时,必须在移动之前验证对象的所有字段。然而,如果将不同类型分离到不同数组中,那么GC可以跳过大量数据。
无
2021-03-29
例如,如果有一个结构体对象数组,如下代码所示,那么GC只需要迭代每个结构体的每个成员,这是相当耗时的:
无
2021-03-29
然而,如果每次将所有数A05-据块重新组织到多个数组,那么GC会忽略所有基本数据类型,只检查字符串对象。下面的代码将使GC清除更快:
无
2021-03-29
这样做的原因是减少GC要检查的间接引用。当数据划分到多个独立数组(引用类型),GC会找到3个值类型的数组,标记数组,接着立刻继续其他工作,因为没有理由标记值类型数组的内容。此时依然必须迭代myStrings中的所有字符串对象,因为每个都是引用类型,它需要验证其中没有包含间接引用。技术上而言,字符串对象没有包含间接引用,但GC工作的层级只知道对象是引用类型还是值类型,因此它不知道字符串和类之间的差别。然而,GC依然不需要迭代额外的3000条数据(myInts、myFloats和myBools中的3000个值)。
1-数组本身是一个应用类型的数据 2-数组内的值类型不需要迭代检查 3-数组内的引用类型需要迭代检查
2021-03-29
每次调用Unity返回数组的API方法时,将导致分配该数据的全新版本。这些方法应该尽可能避免,或者仅调用很少次数并缓存结果,避免比实际所需更频繁的内存分配。
无
2021-03-28
这可以通过使用Object.GetInstanceID()改进,它返回一个整数,用于表示该对象的唯一标识值,在整个程序的生命周期中,该值不会发生变化,也不会在两个对象之间重用。如果以某种方式将这个值缓存在对象中,并将它作为字典中的键,那么元素的比较将比直接使用对象引用快两到三倍。
无
2021-03-28
然而,这种方法也有一些警告。如果实例ID值没有缓存(每次需要索引字典时就调用Object.GetInstanceID()),并使用Mono编译(不使用IL2CPP),那么元素的获取可能会很慢。这是因为它将调用一些非线程安全的代码来获取实例ID,在这种情况下,Mono编译器不能优化循环,与缓存的实例ID值相比较会导致一些额外的开销。如果使用IL2CPP编译,则不会发生这个问题,但是好处依然没有比提前缓存值那么大(缓存值的方式大约快50%)。因此,应该以某种方式缓存整型值,避免频繁调用Object.GetInstanceID()。
类定义的时候直接用一个int类型缓存一下!
2021-03-28
启动一个协程消耗少量内存,但注
无
2021-03-28
闭包是很有用但很危险的工具。匿名方法和lambda表达式可以是闭包,但并不总是闭包。这取决于方法是否使用了它的作用域和参数列表之外的数据。
无
2021-03-28
.NET类库中也有两大特性通常会在使用时造成重大的性能问题。这往往是因为它们只作为对给定问题的应急解决方案,而没有花太多精力进行优化。这两个特性是LINQ和正则表达式。 LINQ提供了一种方式,把数组数据视为小型数据库,对它们使用类似SQL的语法进行查询。简单的代码风格和复杂的底层系统(通过使用闭包)暗示着,它有相当大的性能消耗。LINQ是一个好用的工具,但确实不适用于高性能、实时的应用程序,例如游戏,甚至不能运行在不支持JIT的平台上,例如iOS。 同时,通过Regex类使用的正则表达式允许执行复杂的字符串解析,以查找匹配特定格式的子串,替换部分字符串,或从不同输入构造字符串。正则表达式是另一个非常有用的工具,在基本上不需要它以所谓“聪明”的方式实现文本本地化等特性时,往往过度使用它,但此时直接的字符串替换可能更高效。
无
2021-03-29
应该尽可能少地使用它们,或者用更低消耗的方式替代它们,请一位LINQ或正则专家来解决问题,或者用Google搜索相关话题以优化使用它们的方式。
无
2021-03-29
在网上获得正确回答的最佳方式之一是简单地发表有误的答案。人们要么会乐于帮助我们,要么会反对我们的实现,他们认为纠正错误是他们的责任。首先确定对相关话题做了一些搜索。即使是最忙的人,如果他们发现我们事先付出了努力,通常也乐于提供帮助。
无
2021-03-29
如果习惯于为某个任务使用大型临时工作缓冲区,就应该寻找重用它们的机会,而不是一遍又一遍地重新分配它们,因为这样可以降低分配和垃圾回收所涉及的开销(通常称为内存压力)。应该将这些功能从针对特定情况的类中提取到包含大工作区的通用类上,以便多个类重用它。
无
2021-03-29
该系统的重要特性是允许池化对象决定当需要回收时应该如何回收。下面的IPoolableObject接口类很好地满足了该需求: 该接口类定义了两个方法:New()和Respawn(),应该分别在对象首次创建以及重新生成时调用。
无
2021-03-29
注意,使用栈对象的Peek()方法,因此并没有从栈中移除旧实例。我们期望ObjectPool管理所创建的所有对象引用。
使用的是Stack而不是List等集合。
2021-03-28
前面的对象池方案对于传统C#对象非常有用,但不适用于GameObject和MonoBehaviour等专门的Unity对象。这些对象往往会占用大量运行时内存,当创建和销毁它们时,会消耗大量CPU,在运行时还可能导致大量垃圾回收
无
2021-03-28
预制池的一般思想是创建一个系统,其中包含激活和非激活GameObject的列表,它们由相同的Prefab引用实例化而来
无
2021-03-28
销毁GameObject的行为是微不足道的;通过SetActive()将其active标记设置为false。这将禁用碰撞器和刚体的物理计算,将其从可渲染对象中移除,以及实际上在一个步骤中禁用了GameObject与所有内置的Unity引擎子系统的所有交互。唯一的例外是当前在对象上调用的协程,因为如第2章所述,协程是独立于任何Update()和GameObject活动调用的。因此,需要在这些对象的回收期间调用StopCoroutine()或StopAllCoroutine()。
无
2021-04-02
成功地重新生成GameObject相对复杂。当对象重新生成时,有很多设置在上次对象被激活时遗留下来,而必须重置以避免行为冲突。与此相关的一个常见问题是刚体的linearVelocity和angularVelocity属性。如果这些值没有在对象重新激活之前明确重置,那么重新生成的新对象会继续使用旧版本回收时设置的速度移动。
无
2021-04-02
由于生成GameObject需要给定一个预制体,我们将通过一个数据结构快速将预制体映射到管理它们的PrefabPool。同时,由于回收对象需要给定一个GameObject,我们将通过另一个数据结构,把已经生成的GameObject快速映射到最初生成它们的PrefabPool。满足这两个需求的最好选项是使用一对字典。
无
2021-03-28
Unity Technologies发布了一些博文,提及在某些情况下改善IL2CPP性能的有趣方法,但这些博文难以管理。如果使用IL2CPP且需要从应用程序中挤出最后一点性能,那么可以查看下面链接中的系列博文: https://blogs.unity3d.com/2016/07/26/il2cpp-optimizations-devirtualization/ https://blogs.unity3d.com/2016/08/04/il2cpp-optimizations-faster-virtual-method-calls/ https://blogs.unity3d.com/2016/08/11/il2cpp-optimizations-avoid-boxing
无
2021-03-28
Unity Technologies还发布了一些关于WebGL应用的博文,其中包括一些所有WebGL开发者都应该知道的关于内存管理的重要信息。可以在下面链接中找到: https://blogs.unity3d.com/2016/09/20/understanding-memory-in-unity-webgl/ https://blogs.unity3d.com/2016/12/05/unity-webgl-memory-the-unity-heap/
无
2021-03-28
8.5 Unity、Mono和IL2CPP的未来
Unity Technologies被取笑了一段时间的一个巨大的性能增强功能是名为C# Job System的功能。该功能依然在积极开发中,尚未添加到Unity的发布版本中,但是,尽早熟悉它是明智的,因为它将给Unity开发人员编写高性能代码的方式带来巨大的变化。使用这个系统的游戏与不使用这个系统的游戏在质量上的差异可能会变得非常明显,这可能会导致Unity开发社区的两极分化。
了解和利用新C# Job System的好处,使程序更有成功的潜力。 C# Job System的理念是能够创建在后台线程中运行的简单任务,以减轻主线程的工作负载。C# Job System非常适合于并行性差的任务,例如让成千上万个简单的AI代理同时在一个场景中操作,以及任何可以归结为成千上万个独立的小操作的问题。当然,也可以用于传统多线程行为,在后台执行一些不需要立刻得到结果的计算。C# Job System也引入一些编译器技术改进,获得比简单将任务移到独立线程中更大的性能提升。 编写多线程代码的一个大问题是存在竞争条件、死锁和难以重现和调试的bug的风险。C# Job System旨在使这些任务比平常更简单(但不是琐碎的)。Unity的创始人之一Joachim Ante在Unite Europe 2017上推出C# Job System的演讲,该演讲对C# Job System进行了预览,并引导我们了解Unity的代码编程方式需要如何改变。当然,不需要修改所写的所有代码,但是,如果了解它的工作原理,能够识别出可以应用它的场景,那么它应该被视为一种有价值的工具,在这种情况下,可以部署它,以实现巨大的性能改进。
2021-03-28
竞争条件是两个或多个计算争相完成,但真正的结果取决于它们完成的顺序。假定一个线程想给一个数字增加3,而另一个线程希望将它乘以4,结果将根据哪个操作先发生而不同。死锁是两个或更多线程竞争共享资源,而它们都需要完整的资源集才能完成任务,但每个线程都保留一小部分资源,拒绝放弃该资源给其他线程,在这种情况下,任何线程都无法完成工作,因为它们都没有所需的完整资源集。
2021-03-28
第9章
9.1 编辑器热键提示
在Hierarchy窗口中选中GameObject,并按下Ctrl + D(Command + D),可以复制GameObject。
使用Ctrl + Shift + N(Command + Shift + N),可以新建空的GameObject。
无
2021-04-02
按下Ctrl + Shift + A(Command + Shift + A),可以快速打开Add Component菜单。在该菜单中,可以输入要添加的组件名字。
无
2021-04-02
按下Shift + F或双击F键可以在Scene窗口中跟随选中的对象(假设Scene窗口打开且可见),这有助于跟踪高速对象或找出掉到场景之外的对象
无
2021-04-02
按住Alt键并在Scene窗口中使用鼠标右键拖动可以拉近和拉远相机(Alt + Ctrl +左键拖动)。
无
【】移动时对齐到网格上
2021-04-02
按住Ctrl键(译者注:Mac OS下为Command)并用左键拖动可以使选中的对象在移动时对齐到网格上。在调整对象周围的旋转小部件时,按住Ctrl(译者注:Mac OS下为Command)键也可以以相同的方式旋转。选择Edit | Snap Settings…打开窗口,可以基于每个轴编辑对齐对象的网格。
无
【】强制对齐
2021-04-02
在Scene窗口中移动对象时按住V键(需要先按住V再移动),可以强制对象通过顶点对齐到其他对象。这样,所选对象自动将其顶点对齐到与鼠标光标最近的对象上最近的顶点。这适用于对齐场景片段,例如地板、墙壁、平台和其他基于平铺的系统,不需要进行微小的手动位置调整。
无
2021-04-02
通过Shift + Delete(Command + Delete)可以从引用数组(如GameObject数组)中删除条目。这将去除元素并压缩数组。注意第一次按下时将清除引用,将其设置为null,第二次按下时将移除元素。对于基本类型(int、float等)的数组,不需要按住Shift键(Command),只需要按Delete键即可删除数组中的元素。
无
2021-04-02
在Scene视图中按下鼠标右键时,可以使用W、A、S和D以传统第一人称相机控制的方式围绕相机飞行。Q和E键也可以分别用于起飞和降落。
无
【】展开对象全部层级
2021-03-29
按住Alt键并单击Hierarchy窗口中的箭头(任何父对象名左边的灰色小箭头),可以展开对象的全部层级,而不是仅展开下一个层级的内容。这适用于Hierarchy窗口中的GameObject、Project窗口的文件夹和预制体、Inspector窗口中的列表等。
在Hierarchy或Project窗口中可以像传统RTS游戏一样保存和恢复对象。选中对象并按下Ctrl + Alt + <0-9> (Command + Alt + <0-9>)来保存当前选择。按下Ctrl + Shift + <0-9> (Command + Shift + <0-9>)可以恢复它。如果在调整时一遍又一遍地选择相同的一小部分对象,这是非常有用的。
无
【】当前窗口铺满屏幕
2021-03-29
按下Shift +空格,可以使当前窗口充满整个编辑器屏幕。再次按下会将窗口恢复为原来的位置和大小。
无
【】用代码创建自定义热键
2021-04-02
如果想快速暂停,这个组合键通常并不合适,因此最好创建一个用于暂停的自定义热键:
Debug.Break();
**
2021-04-02
在Visual Studio中按下Ctrl + Alt + M,接着按Ctrl + H可以实现相同的功能。
无
2021-04-02
9.2 编辑器UI提示
导航到Edit | Project Settings | Script Execution Order,可以指定哪些脚本优先执行其Update()和FixedUpdate()回调。如果尝试使用该特性解决复杂的问题(对时间敏感的系统除外,如音频处理系统),就表示组件之间存在糟糕且严重的耦合。从软件设计的角度而言,这可能是一个警告信号,表明可能需要从另一个角度处理问题。但是,该设置有助于快速修复。
无
2021-04-04
这可能潜在地导致冲突,因此每个人使用相同版本的元数据文件是有必要的。可以通过Edit | Project Settings | Editor | Version Control | Mode | Visible Meta Files开启该特性。
无
2021-04-04
将某些资源数据转换为只包含文本的格式而不是二进制数据也是有帮助的,这样可以手动编辑数据文件。这将很多数据文件变成人类可读的YAML格式。例如,如果使用Scriptable对象保存自定义数据,就可以使用文本编辑器搜索并编辑这些文件,而不需要全部在Unity编辑器和Serialization System中操作。这可以节省大量时间,尤其在搜索特定的数据值或对不同的派生类型执行多重编辑的情况下。该选项可以在Edit | Project Settings | Editor | Asset Serialization | Mode | Force Text中开启。
无
2021-04-04
在值的名称上右击并选择Revert Value to Prefab,可以还原独立的值。这将恢复选定的值,同时保持其余值不变。
无
2021-04-04
如果在Inspector窗口中序列化一组数据元素,通常会以标签Element N显示,而N描述了数组元素的索引,从0开始(见图9-4)。如果数组元素是一系列序列化的类或结构,而这些类或结构本身往往有多个子元素,则查找特定元素可能会比较困难。但是,如果对象中的第一个字段是字符串,则元素将以该字符串字段的值命名。
无
2021-04-04
如果在Preview部分顶部的条上右击,它将被分离并放大到单独的Preview窗口中,更容易看清网格。不必将分离的窗口设置回原来的位置,因为,如果分离的窗口关闭了,那么Preview部分将返回到Inspector窗口的底部。
无
2021-04-04
例如,t:texture normalmap将查找所有名字中包含normalmap单词的纹理文件。
无
2021-04-04
如果使用Asset Bundle和内建的标签系统,Project窗口的搜索条也允许使用l:< label type >通过标签搜索捆绑的对象。
无
2021-04-04
此功能不区分大小写,但输入的字符串必须与完整的组件名称匹配,搜索才能完成。从给定类型派生的组件也将显示,因此键入t:renderer将显示具有派生组件(如MeshRenderer和SkinnedMeshRenderer)的所有对象。
用父类进行搜索
2021-04-04
可以通过选择GameObject | Align View to Selected(注意,无论是Windows还是Mac OS,都没有此热键)将Scene窗口相机与所选对象对齐。这对于检查给定对象是否指向正确的方向很有用。
无
2021-04-04
由于Play模式的更改不会自动保存,因此最好修改Play模式中的颜色,使其明显地显示当前使用的模式。此值可以通过Edit | Preferences | Colors | Playmode tint进行设置。
无
2021-04-04
可以简单使用剪切板保存Play模式的改动。如果在Play模式下调整对象,对对象的设置满意后,则可以通过Ctrl + C(Command + C)复制对象到剪切板,并在退出Play模式时使用Ctrl + V(Command + V)将其粘贴回Scene。
无
2021-04-04
9.3 脚本提示
Assert类允许基于断言的调试,与基于异常的调试相比,有些开发人员更容易接受这种调试。有关断言的更多信息,请参阅Unity文档,网址为http://docs.unity3d.com/ ScriptReference/Assertions.Assert.html。
无
2021-04-04
中级和高级Unity开发者应该读一读C#关于特性的文档,并想象使用自己的特性帮助加速工作流
无
2021-04-04
通常,如果重新命名某变量,甚至通过IDE(不管是MonoDevelop或是Visual Studio)做了些重构,一旦Unity重新编译MonoBehaviour并对该组件的任何实例做出相应更改,变量的值将丢失。然而,如果想要在重新命名变量之后保持之前序列化的值,[FormerlySerializedAs]特性提供了难以置信的帮助,因为它会在编译期间将数据从该特性中命名的变量复制到给定的变量。不再有因为重命名而丢失的数据!
无
2021-04-04
注意在转化完成之后移除[FormerlySerializedAs]特性是不安全的,除非在包含特性之后,手动更改变量并将其重新保存到每个相关的预制体中。.prefab数据文件依然包含旧的变量名,需要[FormerlySerializedField]特性来指出当下次加载文件时在哪里定位数据(例如,编辑器关闭并重新打开)。因此,这是一个有用的特性,但是扩展的用法确实会使代码库混乱很多。
无
2021-04-04
SelectionBase]特性将组件所附加到的任何GameObject标记为在Scene窗口中选择对象时的根。当网格是其他对象的子节点,而期望首次单击该网格时选中父对象而不是MeshRenderer组件时,该特性会很有用。
无
2021-04-04
如果组件有强依赖性,可以使用[RequireComponent]特性强制关卡设计者附加重要组件到相同的GameObject上。这确保了设计者会满足代码库的任何依赖性,而不需要为它们编写一大堆文档。
无
2021-04-04
[ExecuteInEditMode]特性将强制在编辑模式下执行对象的Update()、OnGUI()和OnRenderObject()回调。然而有如下警告: 只有当场景中的某些内容发生变化(如移动相机或更改对象属性)时,才会调用Update()方法。 OnGUI()仅在Game窗口事件中调用,而不会在诸如Scene窗口等其他非Game窗口中调用。 OnRenderObject()在Scene窗口和Game窗口的任何重绘事件中调用。
无
2021-04-04
嵌套协程是一个有趣且有用的脚本领域,只是没有很好的文档记录。但是,在使用嵌套协程时,应该考虑以下第三方博文,其中包含了许多有趣的细节:http://www.zingweb.com/blog/2013/02/05/unity-coroutine-wrapper。
无
2021-04-04
查看http://docs.unity3d.com/ScriptReference/40-history.html上的API历史页面,可以确定何时将特定功能添加到Unity API。
无
2021-04-04
9.4 自定义编辑器脚本和菜单提示
可以用[MenuItem]特性在编辑器脚本中创建一个编辑器菜单项,但一个鲜为人知的功能是能够为菜单项设置自定义热键。
无
2021-04-04
使用%、#、&字符,也可以包括诸如Ctrl(Command)、Shift和Alt等修饰键。
无
2021-04-04
查看[MenuItems]的文档以获得可用热键、修饰键、特殊键以及如何创建验证方法的完整列表:http://docs.unity3d.com/ScriptReference/MenuItem.html。
无
2021-04-04
调用EditorGUIUtility.PingObject()可以在Hierarchy窗口中对对象进行ping操作,就像在Inspector窗口中单击GameObject引用一样。
无
2021-04-04
PropertyDrawer类是将Inspector窗口绘制委托给主Editor类中另一个类的高效方法。这有效地将输入和验证行为与显示行为分离开来,允许对每个字段的呈现进行更精细的调整控制,并更高效地重用代码。甚至可以使用PropertyDrawer覆盖Unity对内建对象的默认绘制,例如Vector和Quaternion。
无
2021-04-04
PropertyDrawer使用SerializedProperty类来完成单个字段的序列化,在编写编辑器脚本时应该优先使用它们,因为它们使用内置的撤销、重做和多编辑功能。数据验证可能有点问题,最好的解决方案是在setter属性中使用OnValidate()调用。Unity Technologies开发人员Tim Cooper在Unite 2013大会上详细说明了各种序列化和验证方法的好处和缺陷,可以在此找到这些说明:https://www.youtube.com/watch?v= Ozc_hXzp_KU。
无
2021-04-04
利用[ContextMenu]和[ContextMenuItem]特性可以将条目添加到组件的上下文菜单,甚至添加到各个字段的上下文菜单。这允许容易地为自定义组件定制Inspector窗口行为,而不需要编写大量Editor类或自定义Inspector窗口。
无
2021-04-04
高级用户可能会发现通过AssetImporter.userData变量将自定义数据存储在Unity元数据文件中很有用。还有许多机会利用Unity代码库的反射
无
2021-04-04
9.5 外部提示
Twitter hashtag #unitytips是Unity开发中有用的提示和技巧的一个很好的资源,事实上,本章中的许多技巧都源于此。然而,散列标签很难过滤出以前没有见过的提示,而且它经常滥用于市场营销。在http://devdog.io/blog可以找到一个很好的资源,它汇集了#unitytips的每周提示。
无
2021-04-04
如果Unity编辑器崩溃,不管是什么原因,对于场景文件都可能还原,方法是将下面文件重命名为包括.untiy扩展名,并将其复制到Assets文件夹:
无
2021-04-04
在几乎所有情况下,场景组织对工作流的好处都远比这种微不足道的性能损失更有价值。
无
2021-04-04
笔记来自iReader T6

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









