










10000个tokens 经过transformer的self-attention之后,会变成什么形状的数据?
这个问题的答案是**10000×d**,其中d是模型的隐藏维度(hidden dimension)也是输入数据的维度。
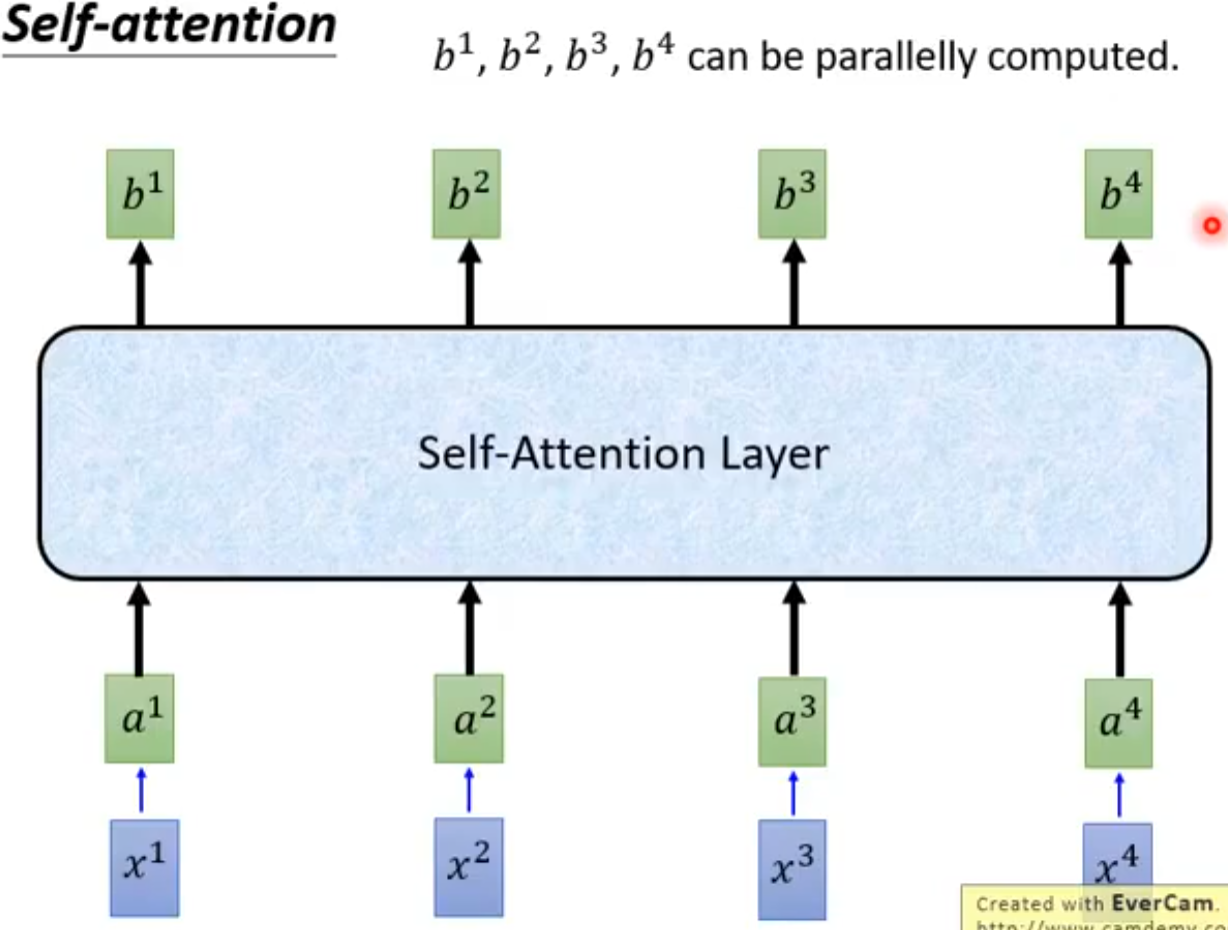
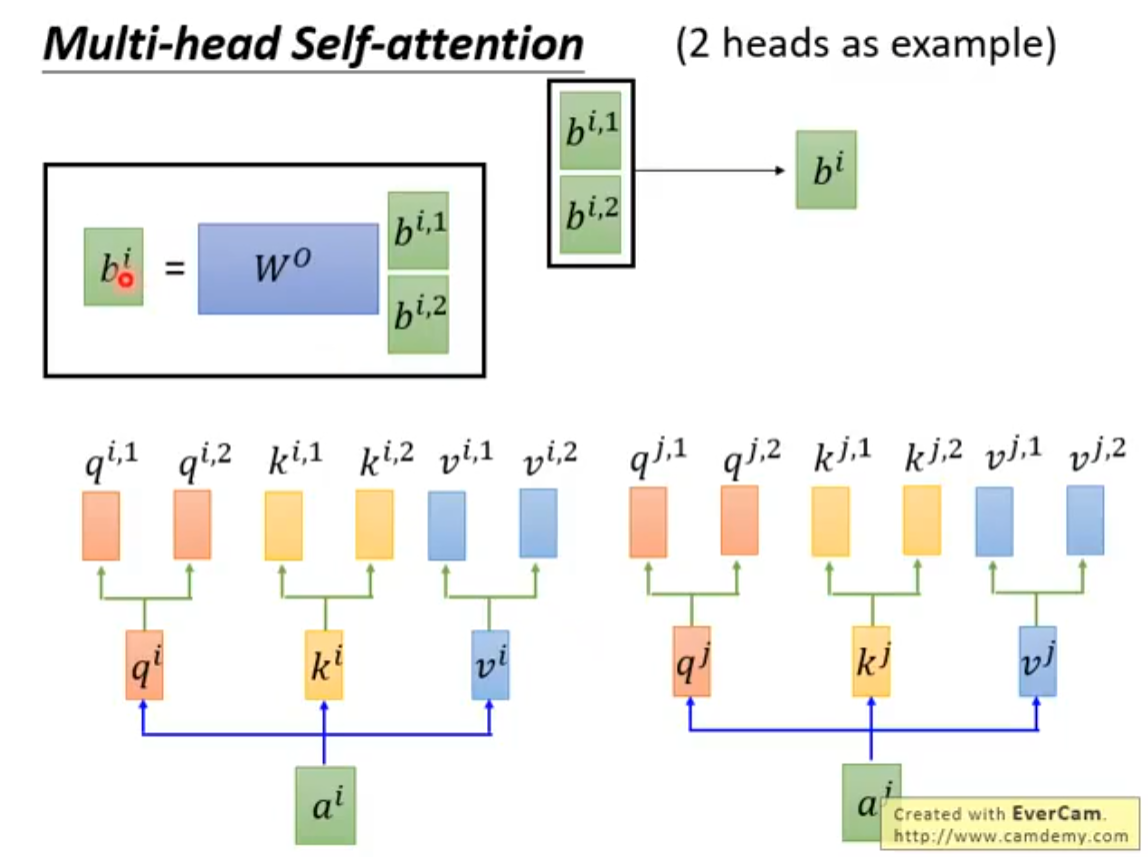
transformer的self-attention机制的作用是将输入序列中每个token与其他所有token之间的相关性进行加权求和,从而得到一个新的输出向量,它包含了输入序列中所有token的信息。
transformer的self-attention机制的具体步骤如下:

--------------------------------------------------------------------------------------------------------------------------------
超详细解读:The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.



















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











