










主题模型LDA
在开始下面的旅程之前,先来总结下我们目前所得到的最主要的几个收获:
- 通过上文的第2.2节,我们知道beta分布是二项式分布的共轭先验概率分布:
- “对于非负实数
和
,我们有如下关系
- “对于非负实数
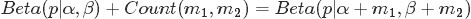
其中
对应的是二项分布
的计数。针对于这种观测到的数据符合二项分布,参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomial 共轭。”
- 通过上文的3.2节,我们知道狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布:
- “ 把
从整数集合延拓到实数集合,从而得到更一般的表达式如下:
- “ 把
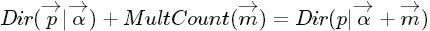
针对于这种观测到的数据符合多项分布,参数的先验分布和后验分布都是Dirichlet 分布的情况,就是 Dirichlet-Multinomial 共轭。 ”
-
以及贝叶斯派思考问题的固定模式:
- 先验分布
+ 样本信息
后验分布
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验分布
后,人们对
。
- 先验分布
- 顺便提下频率派与贝叶斯派各自不同的思考方式:
- 频率派把需要推断的参数θ看做是固定的未知常数,即概率
虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;
- 而贝叶斯派的观点则截然相反,他们认为待估计的参数
- 频率派把需要推断的参数θ看做是固定的未知常数,即概率
OK,在杀到终极boss——LDA模型之前,再循序渐进理解基础模型:Unigram model、mixture of unigrams model,以及跟LDA最为接近的pLSA模型。
为了方便描述,首先定义一些变量:
表示词,
表示所有单词的个数(固定值)
表示主题,
是主题的个数(预先给定,固定值)
表示语料库,其中的
是语料库中的文档数(固定值)
表示文档,其中的
表示一个文档中的词数(随机变量)
4.1 各个基础模型
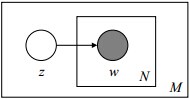
4.1.1 Unigram model
对于文档



其图模型为(图中被涂色的w表示可观测变量,N表示一篇文档中总共N个单词,M表示M篇文档):
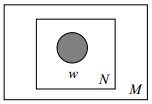
或为:

unigram model假设文本中的词服从Multinomial分布,而我们已经知道Multinomial分布的先验分布为Dirichlet分布。
上图中的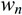
- p是词服从的Multinomial分布的参数
- α是Dirichlet分布(即Multinomial分布的先验分布)的参数。
一般α由经验事先给定,p由观察到的文本中出现的词学习得到,表示文本中出现每个词的概率。
4.1.2 Mixture of unigrams model
,再根据该主题生成文档,该文档中的所有词都来自一个主题。假设主题有
 ,生成文档
的概率为:
,生成文档
的概率为:
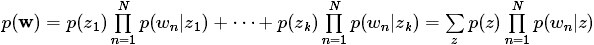
4.2 PLSA模型
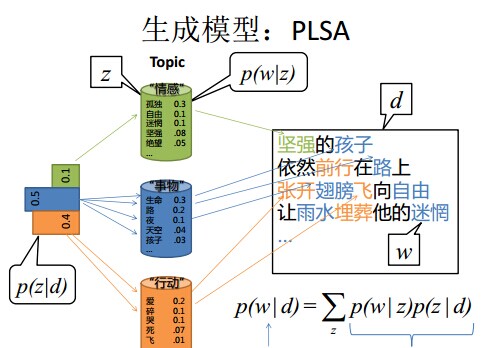
4.2.1 什么是pLSA模型
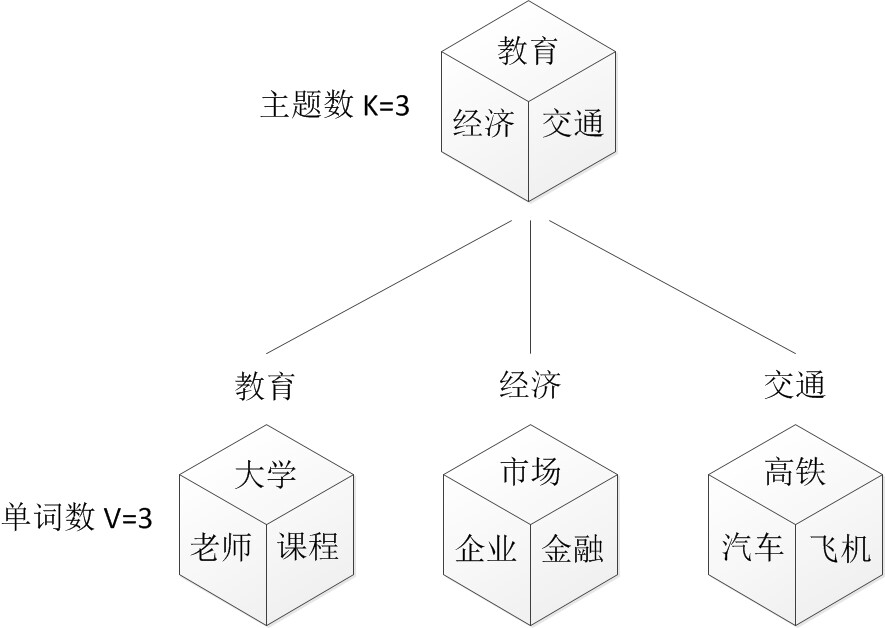
- 1. 假设你每写一篇文档会制作一颗K面的“文档-主题”骰子(扔此骰子能得到K个主题中的任意一个),和K个V面的“主题-词项” 骰子(每个骰子对应一个主题,K个骰子对应之前的K个主题,且骰子的每一面对应要选择的词项,V个面对应着V个可选的词)。
- 比如可令K=3,即制作1个含有3个主题的“文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令V = 3,制作3个有着3面的“主题-词项”骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
- 2. 每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
- 上面这个投骰子产生词的过程简化下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如可能选取教育主题的概率是0.5,选取经济主题的概率是0.3,选取交通主题的概率是0.2,那么这3个主题的概率分布便是{教育:0.5,经济:0.3,交通:0.2},我们把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。
- 同样的,从主题分布中随机抽取出教育主题后,依然面对着3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如大学这个词被选中的概率是0.5,老师这个词被选中的概率是0.3,课程被选中的概率是0.2,那么这3个词的概率分布便是{大学:0.5,老师:0.3,课程:0.2},我们把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
- 所以,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
- 3. 最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
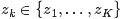 。同时定义:
。同时定义:
表示海量文档中某篇文档被选中的概率。
表示词
在给定文档
中出现的概率。
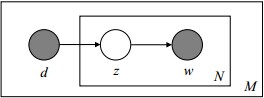
- 怎么计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率
- 怎么计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率
表示具体某个主题
在给定文档
表示具体某个词
下出现的概率,与主题关系越密切的词,其条件概率
- 按照概率
- 选定文档
- 选定
 是已知的。
,训练出文档-主题
和主题-词项
,如下公式所示:
是已知的。
,训练出文档-主题
和主题-词项
,如下公式所示:
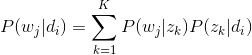
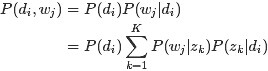
由于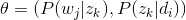
用什么方法进行估计呢,常用的参数估计方法有极大似然估计MLE、最大后验证估计MAP、贝叶斯估计等等。因为该待估计的参数中含有隐变量z,所以我们可以考虑EM算法。
4.2.2 EM算法的简单介绍
EM算法,全称为Expectation-maximization algorithm,为期望最大算法,其基本思想是:首先随机选取一个值去初始化待估计的值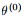
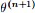
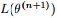
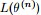
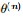

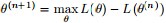
EM的关键便是要找到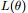
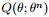
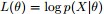
所以EM算法的一般步骤为:
- 1. 随机选取或者根据先验知识初始化
- 2. 不断迭代下述两步
- ①给出当前的参数估计
- ②重新估计参数θ,即求
- ①给出当前的参数估计
- 3. 上述第二步后,如果
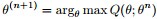
上述过程好比在二维平面上,有两条不相交的曲线,一条曲线在上(简称上曲线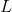
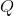
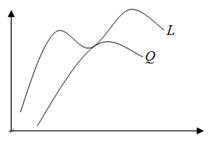
以下是详细介绍。
假定有训练集,包含m个独立样本,希望从中找到该组数据的模型p(x,z)的参数。
然后通过极大似然估计建立目标函数--对数似然函数:
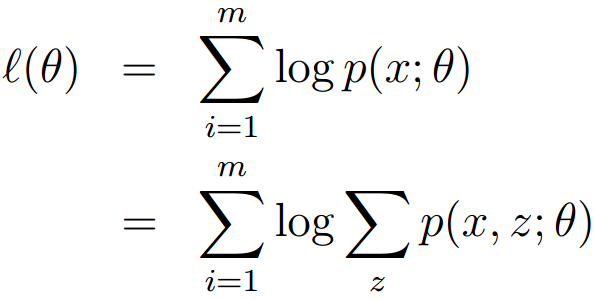
这里,z是隐随机变量,直接找到参数的估计是很困难的。我们的策略是建立的下界,并且求该下界的最大值;重复这个过程,直到收敛到局部最大值。
令Qi是z的某一个分布,Qi≥0,且结合Jensen不等式,有:
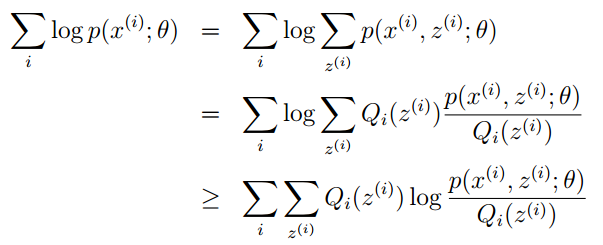
为了寻找尽量紧的下界,我们可以让使上述等号成立,而若要让等号成立的条件则是:
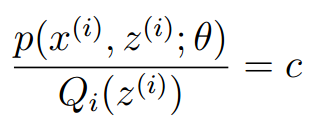
换言之,有以下式子成立:,且由于有:
所以可得:
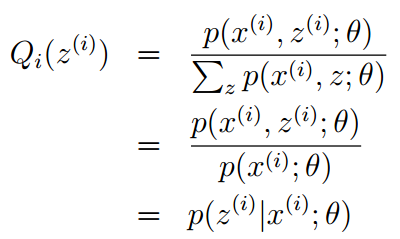
最终得到EM算法的整体框架如下:
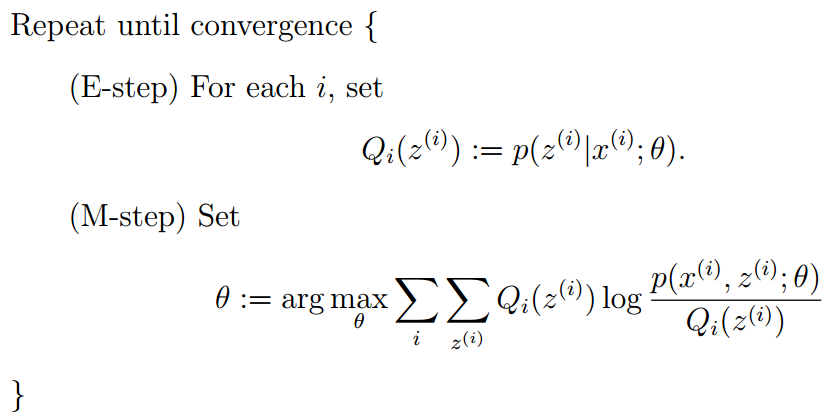
OK,EM算法还会在本博客后面的博文中具体阐述。接下来,回到pLSA参数的估计问题上。
4.2.3 EM算法估计pLSA的两未知参数
首先尝试从矩阵的角度来描述待估计的两个未知变量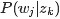
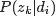
- 假定用
表示词表
在主题
上的一个多项分布,则
可以表示成一个向量,每个元素
表示词项
出现在主题
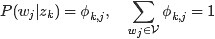
- 用
表示所有主题
在文档
上的一个多项分布,则
可以表示成一个向量,每个元素
表示主题
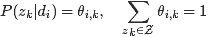
这样,巧妙的把
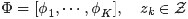
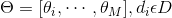
由于词和词之间是相互独立的,所以整篇文档N个词的分布为:
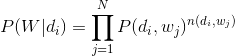
再由于文档和文档之间也是相互独立的,所以整个语料库中词的分布为(整个语料库M篇文档,每篇文档N个词):
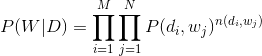
其中,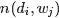
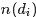
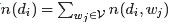
从而得到整个语料库的词分布的对数似然函数(下述公式中有个小错误,正确的应该是:N为M,M为N):
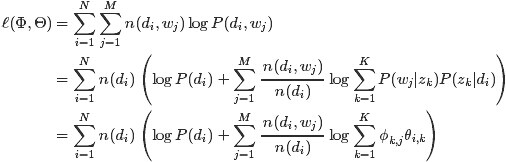
现在,我们需要最大化上述这个对数似然函数来求解参数
- E-step:假定参数已知,计算此时隐变量的后验概率。
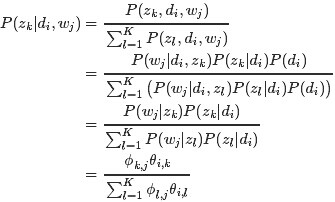
- M-step:带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数。
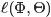 的结果,由于文档长度
的结果,由于文档长度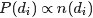 可以单独计算,所以去掉它不影响最大化似然函数。此外,根据E-step的计算结果,把
可以单独计算,所以去掉它不影响最大化似然函数。此外,根据E-step的计算结果,把 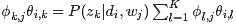 代入,于是我们只要最大化下面这个函数
代入,于是我们只要最大化下面这个函数 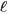 即可(下述公式中有个小错误,正确的应该是:N为M,M为N):
即可(下述公式中有个小错误,正确的应该是:N为M,M为N):
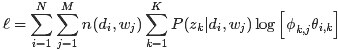
这是一个多元函数求极值问题,并且已知有如下约束条件(下述公式中有个小错误,正确的应该是:M为N):
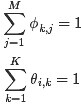
熟悉凸优化的朋友应该知道,一般处理这种带有约束条件的极值问题,常用的方法便是拉格朗日乘数法,即通过引入拉格朗日乘子将约束条件和多元(目标)函数融合到一起,转化为无约束条件的极值问题。
这里我们引入两个拉格朗日乘子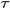
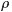
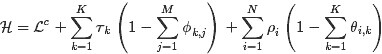
因为我们要求解的参数是

消去拉格朗日乘子,最终可估计出参数
综上,在pLSA中:
- 由于
- 而后,用
 ,用
,用 ,从而把
,从而把 - 最终求解出
4.3 LDA模型
事实上,理解了pLSA模型,也就差不多快理解了LDA模型,因为LDA就是在pLSA的基础上加层贝叶斯框架,即LDA就是pLSA的贝叶斯版本(正因为LDA被贝叶斯化了,所以才需要考虑历史先验知识,才加的两个先验参数)。
4.3.1 pLSA跟LDA的对比:生成文档与参数估计
在pLSA模型中,我们按照如下的步骤得到“文档-词项”的生成模型:
- 按照概率
- 选定文档
- 从主题分布中按照概率
- 选定
- 从词分布中按照概率
下面,咱们对比下本文开头所述的LDA模型中一篇文档生成的方式是怎样的:
- 按照先验概率
- 从狄利克雷分布(即Dirichlet分布)
中取样生成文档
,换言之,主题分布
- 从主题的多项式分布
- 从狄利克雷分布(即Dirichlet分布)
中取样生成主题
对应的词语分布
,换言之,词语分布
- 从词语的多项式分布
”
从上面两个过程可以看出,LDA在PLSA的基础上,为主题分布和词分布分别加了两个Dirichlet先验。
继续拿之前讲解PLSA的例子进行具体说明。如前所述,在PLSA中,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。
- PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
- 但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定(即不知道),因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。
- pLSA中,主题分布和词分布确定后,以一定的概率(
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
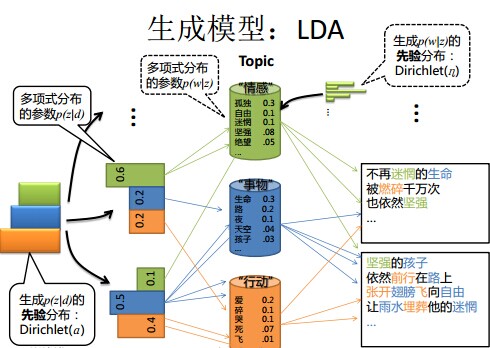
- 举个文档d产生主题z的例子。给定一篇文档d,主题分布是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,这3个主题被文档d选中的概率都是个固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下图所示(图截取自沈博PPT上):
- 文档d产生主题z的概率,主题z产生单词w的概率都是两个固定的值。
- 但在贝叶斯框架下的LDA中,我们不再认为主题分布(各个主题在文档中出现的概率分布)和词分布(各个词语在某个主题下出现的概率分布)是唯一确定的(而是随机变量),而是有很多种可能。但一篇文档总得对应一个主题分布和一个词分布吧,怎么办呢?LDA为它们弄了两个Dirichlet先验参数,这个Dirichlet先验为某篇文档随机抽取出某个主题分布和词分布。
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
- 还是举文档d具体产生主题z的例子。给定一篇文档d,现在有多个主题z1、z2、z3,它们的主题分布{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即这些主题被d选中的概率都不再认为是确定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主题分布到底是哪个取值集合我们不确定(为什么?这就是贝叶斯派的核心思想,把未知参数当作是随机变量,不再认为是某一个确定的值),但其先验分布是dirichlet 分布,所以可以从无穷多个主题分布中按照dirichlet 先验随机抽取出某个主题分布出来。如下图所示(图截取自沈博PPT上):
- 文档d产生主题z(准确的说,其实是Dirichlet先验为文档d生成主题分布Θ,然后根据主题分布Θ产生主题z)的概率,主题z产生单词w的概率都不再是某两个确定的值,而是随机变量。
 、
)加了两个先验分布的参数(
贝叶斯化):一个主题分布的先验分布Dirichlet分布
,和一个词语分布的先验分布Dirichlet分布
。
、
)加了两个先验分布的参数(
贝叶斯化):一个主题分布的先验分布Dirichlet分布
,和一个词语分布的先验分布Dirichlet分布
。
好比,我去一朋友家:
- 按照频率派的思想,我估计他在家的概率是1/2,不在家的概率也是1/2,是个定值。
- 而按照贝叶斯派的思想,他在家不在家的概率不再认为是个定值1/2,而是随机变量。比如按照我们的经验(比如当天周末),猜测他在家的概率是0.6,但这个0.6不是说就是完全确定的,也有可能是0.7。如此,贝叶斯派没法确切给出参数的确定值(0.3,0.4,0.6,0.7,0.8,0.9都有可能),但至少明白在哪个范围或哪些取值(0.6,0.7,0.8,0.9)更有可能,哪个范围或哪些取值(0.3,0.4) 不太可能。进一步,贝叶斯估计中,参数的多个估计值服从一定的先验分布,而后根据实践获得的数据(例如周末不断跑他家),不断修正之前的参数估计,从先验分布慢慢过渡到后验分布。
4.3.2 LDA生成文档过程的进一步理解
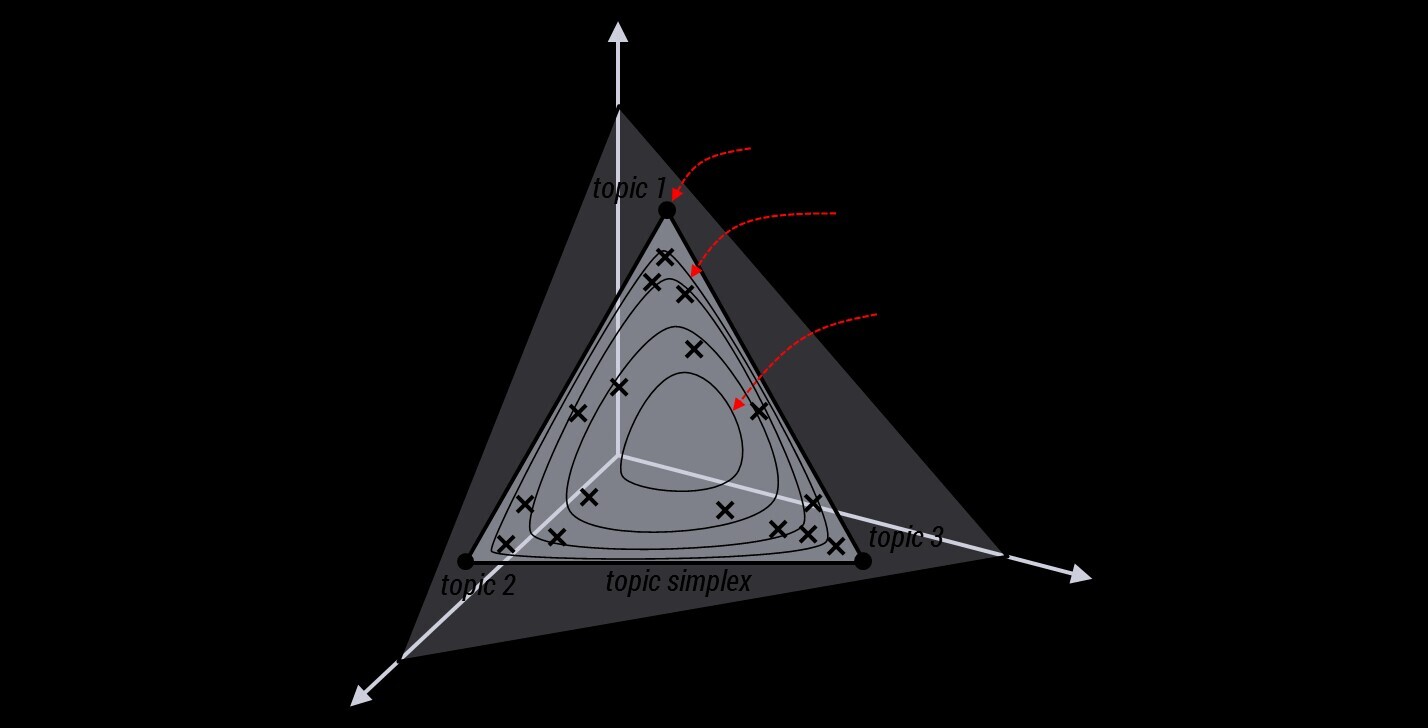
在这个三维坐标轴所划分的空间里,每一个坐标点(p1,p2,p3)就对应着一个主题分布,且某一个点(p1,p2,p3)的大小表示3个主题z1、z2、z3出现的概率大小(因为各个主题出现的概率和为1,所以p1+p2+p3 = 1,且p1、p2、p3这3个点最大取值为1)。比如(p1,p2,p3) = (0.4,0.5,0.1)便对应着主题分布{ P(zi), i =1,2,3 } = {0.4,0.5,0.1}。
可以想象到,空间里有很多这样的点(p1,p2,p3),意味着有很多的主题分布可供选择,那dirichlet分布如何选择主题分布呢?把上面的斜三角形放倒,映射到底面的平面上,便得到如下所示的一些彩图(3个彩图中,每一个点对应一个主题分布,高度代表某个主题分布被dirichlet分布选中的概率,且选不同的
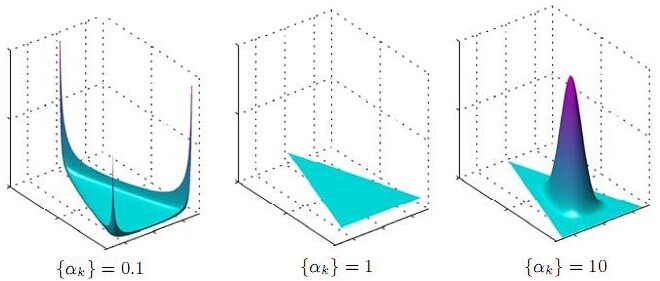
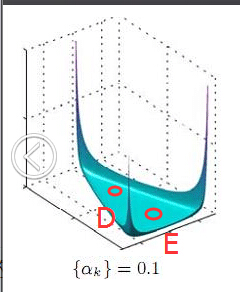 是如何决定dirichlet分布的形状的,可以从dirichlet分布的定义和公式思考。
是如何决定dirichlet分布的形状的,可以从dirichlet分布的定义和公式思考。
4.3.3 pLSA跟LDA的概率图对比
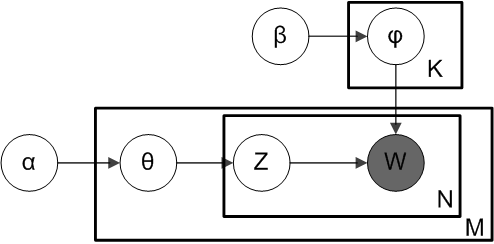 是主题分布Θ的先验分布(即Dirichlet 分布)的参数,
是词分布Φ的先验分布(即Dirichlet 分布)的参数,N表示文档的单词总数,M表示文档的总数。
确定某篇文档的主题分布θ,然后从该文档所对应的多项分布(主题分布)θ中抽取一个主题z,接着根据先验知识
确定当前主题的词语分布ϕ,然后从主题z所对应的多项分布(词分布)ϕ中抽取一个单词w。然后将这个过程重复N次,就产生了文档d。
是主题分布Θ的先验分布(即Dirichlet 分布)的参数,
是词分布Φ的先验分布(即Dirichlet 分布)的参数,N表示文档的单词总数,M表示文档的总数。
确定某篇文档的主题分布θ,然后从该文档所对应的多项分布(主题分布)θ中抽取一个主题z,接着根据先验知识
确定当前主题的词语分布ϕ,然后从主题z所对应的多项分布(词分布)ϕ中抽取一个单词w。然后将这个过程重复N次,就产生了文档d。
- 假定语料库中共有M篇文章,每篇文章下的Topic的主题分布是一个从参数为
- 对于某篇文章中的第n个词,首先从该文章中出现的每个主题的Multinomial分布(主题分布)中选择或采样一个主题,然后再在这个主题对应的词的Multinomial分布(词分布)中选择或采样一个词。不断重复这个随机生成过程,直到M篇文章全部生成完成。
- 其中,
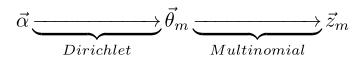
- 类似的,
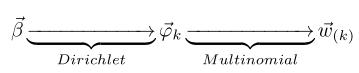
4.3.4 pLSA跟LDA参数估计方法的对比
- 在pLSA中,我们使用EM算法去估计“主题-词项”矩阵Φ(由
- 而在LDA中,估计Φ、Θ这两未知参数可以用变分(Variational inference)-EM算法,也可以用gibbs采样,前者的思想是最大后验估计MAP(MAP与MLE类似,都把未知参数当作固定的值),后者的思想是贝叶斯估计。贝叶斯估计是对MAP的扩展,但它与MAP有着本质的不同,即贝叶斯估计把待估计的参数看作是服从某种先验分布的随机变量。
- 关于贝叶斯估计再举个例子。假设中国的大学只有两种:理工科和文科,这两种学校数量的比例是1:1,其中,理工科男女比例7:1,文科男女比例1:7。某天你被外星人随机扔到一个校园,问你该学校可能的男女比例是多少?然后,你实际到该校园里逛了一圈,看到的5个人全是男的,这时候再次问你这个校园的男女比例是多少?
- 因为刚开始时,有先验知识,所以该学校的男女比例要么是7:1,要么是1:7,即P(比例为7:1) = 1/2,P(比例为1:7) = 1/2。
- 然后看到5个男生后重新估计男女比例,其实就是求P(比例7:1|5个男生)= ?,P(比例1:7|5个男生) = ?
- 用贝叶斯公式
,可得:P(比例7:1|5个男生) = P(比例7:1)*P(5个男生|比例7:1) / P(5个男生),P(5个男生)是5个男生的先验概率,与学校无关,所以是个常数;类似的,P(比例1:7|5个男生) = P((比例1:7)*P(5个男生|比例1:7)/P(5个男生)。
- 最后将上述两个等式比一下,可得:P(比例7:1|5个男生)/P(比例1:7|5个男生) = {P((比例7:1)*P(5个男生|比例7:1)} / { P(比例1:7)*P(5个男生|比例1:7)}。
- 关于贝叶斯估计再举个例子。假设中国的大学只有两种:理工科和文科,这两种学校数量的比例是1:1,其中,理工科男女比例7:1,文科男女比例1:7。某天你被外星人随机扔到一个校园,问你该学校可能的男女比例是多少?然后,你实际到该校园里逛了一圈,看到的5个人全是男的,这时候再次问你这个校园的男女比例是多少?
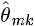 、
、
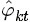 )!
)!
4.3.5 LDA参数估计:Gibbs采样
理清了LDA中的物理过程,下面咱们来看下如何学习估计。
类似于pLSA,LDA的原始论文中是用的变分-EM算法估计未知参数,后来发现另一种估计LDA未知参数的方法更好,这种方法就是:Gibbs Sampling,有时叫Gibbs采样或Gibbs抽样,都一个意思。Gibbs抽样是马尔可夫链蒙特卡尔理论(MCMC)中用来获取一系列近似等于指定多维概率分布(比如2个或者多个随机变量的联合概率分布)观察样本的算法。
OK,给定一个文档集合,w是可以观察到的已知变量,
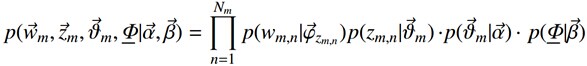
注:上述公式中及下文中,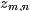
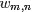
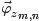
等价于上文中定义的
因为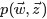
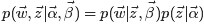
其中,第一项因子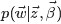
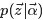
由于这两个过程是独立的,所以下面可以分别处理,各个击破。
第一个因子
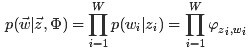
由于样本中的词服从参数为主题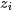
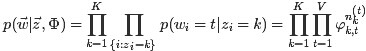
其中,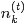
回到第一个因子上来。目标分布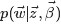
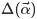
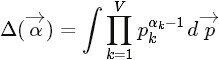
可得:
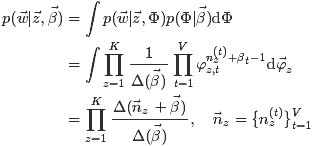
这个结果可以看作K个Dirichlet-Multinomial模型的乘积。
现在开始求第二个因子
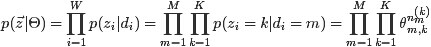
其中,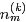
对主题分布Θ积分可得:
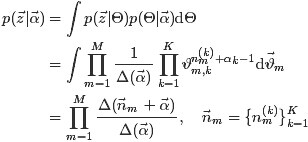
综合第一个因子和第二个因子的结果,得到
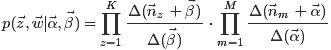 ,咱们便可以通过联合分布来计算在给定可观测变量 w 下的隐变量 z 的条件分布(后验分布)
,咱们便可以通过联合分布来计算在给定可观测变量 w 下的隐变量 z 的条件分布(后验分布)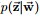 来进行贝叶斯分析。
来进行贝叶斯分析。
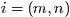 的词)的全部条件概率就好求了。
的词)的全部条件概率就好求了。
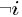 表示除去
表示除去
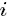 的词,
的词,
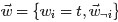 ,
,
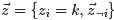 。
。
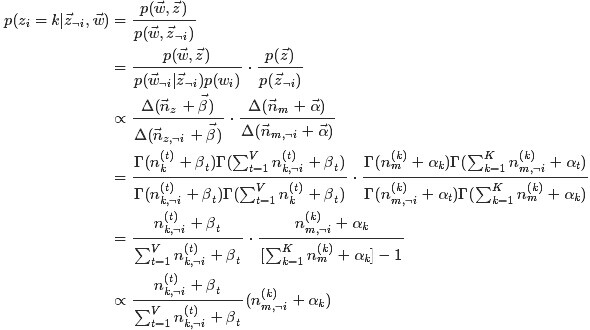
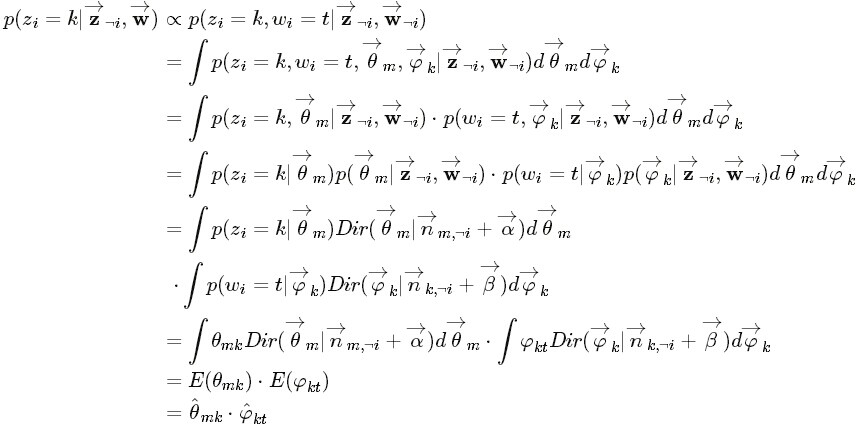 获取主题分布的参数Θ和词分布的参数Φ。
获取主题分布的参数Θ和词分布的参数Φ。
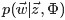 和
和
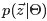 各自被分解成两部分乘积的结果,可以计算得到
每个文档上Topic的后验分布和每个Topic下的词的后验分布分别如下(据上文可知:
其后验分布跟它们的先验分布一样,也都是
Dirichlet 分布
):
各自被分解成两部分乘积的结果,可以计算得到
每个文档上Topic的后验分布和每个Topic下的词的后验分布分别如下(据上文可知:
其后验分布跟它们的先验分布一样,也都是
Dirichlet 分布
):
 是构成文档m的主题数向量,
是构成文档m的主题数向量,
 是构成主题k的词项数向量。
是构成主题k的词项数向量。
“ 如果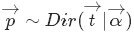
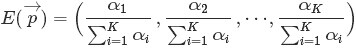
 ,则
,则
 中的任一元素
中的任一元素
 的期望是:
的期望是:
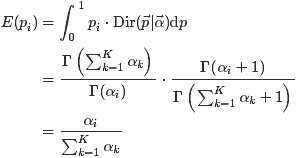
 的直观意义就是事件先验的伪计数(prior pseudo-count)。
”
的直观意义就是事件先验的伪计数(prior pseudo-count)。
”
所以, 最终求解的Dirichlet 分布期望为:
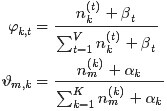
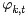 和
和
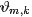 的结果代入之前得到的
的结果代入之前得到的
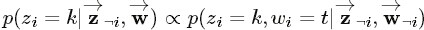 的结果中,可得:
的结果中,可得:
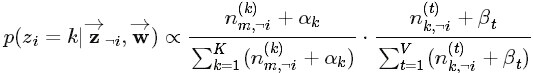
 ,这个概率的值对应着
,这个概率的值对应着
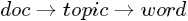 的路径概率。如此,K 个topic 对应着K条路径,Gibbs Sampling 便在这K 条路径中进行采样,如下图所示:
的路径概率。如此,K 个topic 对应着K条路径,Gibbs Sampling 便在这K 条路径中进行采样,如下图所示:

5 读者微评
- @SiNZeRo:lda 如果用em就是 map估计了. lda本意是要去找后验分布 然后拿后验分布做bayesian分析. 比如theta的期望 . 而不是把先验作为正则化引入。最后一点gibbs sampling其实不是求解的过程 是去explore后验分布 去采样 用于求期望.
- @研究者July:好问题好建议
,这几天我陆续完善下!//@帅广应s:LDA这个东西该怎么用?可以用在哪些地方?还有就是Gibbs抽样的原理是什么?代码怎么实现?如果用EM来做,代码怎么实现? LDA模型的变形和优化有哪些?LDA不适用于解决哪类的问题?总之,不明白怎么用,参数怎么调优?
- @xiangnanhe:写的很好,4.1.3节中的那两个图很赞,非常直观的理解了LDA模型加了先验之后在学参数的时候要比PLSI更灵活;PLSI在学参数的过程中比较容易陷入local minimum然后overfitting。
- @asker2:无论是pLSA中,还是LDA中,主题分布和词分布本身是固定的存在,但都未知。pLSA跟LDA的区别在于,去探索这两个未知参数的方法或思想不一样。pLSA是求到一个能拟合文本最好的参数(分布),这个值就认为是真实的参数。但LDA认为,其实我们没法去完全求解出主题分布、词分布到底是什么参数,我们只能把它们当成随机变量,通过缩小其方差(变化度)来尽量让这个随机变量变得更“确切”。换言之,我们不再求主题分布、词分布的具体值,而是通过这些分布生成的观测值(即实际文本)来反推分布的参数的范围,即在什么范围比较可能,在什么范围不太可能。所以,其实这就是一种贝叶斯分析的思想,虽然无法给出真实值具体是多少,但可以按照经验给一个相对合理的真实值服从的先验分布,然后从先验出发求解其后验分布。

















 5002
5002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









