



Doc2X:高效代码提取工具
从 PDF 中快速提取代码块,并转换为 Markdown 或 HTML,便于开发与交流。
Doc2X: Efficient Code Extraction Tool
Quickly extract code blocks from PDFs and convert them into Markdown or HTML for seamless development and sharing.
👉 了解更多 Doc2X | Learn More About Doc2X
https://arxiv.org/ftp/arxiv/papers/1804/1804.07573.pdf
MobileFaceNets: Efficient CNNs for Accurate Real- Time Face Verification on Mobile Devices
MobileFaceNets:适用于移动设备上准确实时人脸验证的高效卷积神经网络
Sheng Chen 1 , 2 {}^{1,2} 1,2 ,Yang Liu 2 {}^{2} 2 ,Xiang Gao 2 {}^{2} 2 ,and Zhen Han 1 {}^{1} 1 1 {}^{1} 1 School of Computer and Information Technology,Beijing Jiaotong University,Beijing, China
盛晨 1 , 2 {}^{1,2} 1,2,刘洋 2 {}^{2} 2,高翔 2 {}^{2} 2,和韩振 1 {}^{1} 1 1 {}^{1} 1 北京交通大学计算机与信息技术学院,北京,中国
2 {}^{2} 2 Research Institute,Watchdata Inc.,Beijing,China
2 {}^{2} 2 研究院,Watchdata Inc.,北京,中国
{sheng.chen, yang.liu.yj, xiang.gao}@watchdata.com,
{sheng.chen, yang.liu.yj, xiang.gao}@watchdata.com,
zhan@bjtu.edu.cn
Abstract. We present a class of extremely efficient CNN models, MobileFaceNets, which use less than 1 million parameters and are specifically tailored for high-accuracy real-time face verification on mobile and embedded devices. We first make a simple analysis on the weakness of common mobile networks for face verification. The weakness has been well overcome by our specifically designed MobileFaceNets. Under the same experimental conditions, our MobileFaceNets achieve significantly superior accuracy as well as more than 2 times actual speedup over MobileNetV2. After trained by ArcFace loss on the refined MS-Celeb-1M, our single MobileFaceNet of 4.0MB size achieves 99.55% accuracy on LFW and 92.59% TAR@FAR1e-6 on MegaFace, which is even comparable to state-of-the-art big CNN models of hundreds MB size. The fastest one of MobileFaceNets has an actual inference time of 18 milliseconds on a mobile phone. For face verification, MobileFaceNets achieve significantly improved efficiency over previous state-of-the-art mobile CNNs.
摘要。我们提出了一类极其高效的卷积神经网络模型,MobileFaceNets,其参数数量少于100万,并且专门为移动和嵌入设备上的高精度实时人脸验证而设计。我们首先对常见移动网络在人脸验证中的弱点进行了简单分析。这些弱点已通过我们专门设计的MobileFaceNets得到了很好的克服。在相同的实验条件下,我们的MobileFaceNets在准确性方面显著优于MobileNetV2,并且实际速度提高了2倍以上。通过在精炼的MS-Celeb-1M上使用ArcFace损失进行训练后,我们单个4.0MB大小的MobileFaceNet在LFW上达到了99.55%的准确率,在MegaFace上达到了92.59%的TAR@FAR1e-6,这甚至可以与数百MB大小的最先进的大型卷积神经网络模型相媲美。最快的MobileFaceNets在手机上的实际推理时间为18毫秒。对于人脸验证,MobileFaceNets在效率上显著优于之前最先进的移动卷积神经网络。
Keywords: Mobile network, face verification, face recognition, convolutional neural network, deep learning.
关键词:移动网络,人脸验证,人脸识别,卷积神经网络,深度学习。
1 Introduction
1 引言
Face verification is an important identity authentication technology used in more and more mobile and embedded applications such as device unlock, application login, mobile payment and so on. Some mobile applications equipped with face verification technology, for example, smartphone unlock, need to run offline. To achieve user-friendliness with limited computation resources, the face verification models deployed locally on mobile devices are expected to be not only accurate but also small and fast. However, modern high-accuracy face verification models are built upon deep and big convolutional neural networks (CNNs) which are supervised by novel loss functions during training stage. The big CNN models requiring high computational resources are not suitable for many mobile and embedded applications. Several highly efficient neural network architectures, for example, MobileNetV1 [1], ShuffleNet [2], and MobileNetV2 [3], have been proposed for common visual recognition tasks rather than face verification in recent years. It is a straight-forward way to use these common CNNs unchanged for face verification, which only achieves very inferior accuracy compared with state-of-the-art results according to our experiments (see Table 2).
人脸验证是一种重要的身份认证技术,越来越多地应用于设备解锁、应用程序登录、移动支付等移动和嵌入式应用中。一些配备人脸验证技术的移动应用程序,例如智能手机解锁,需要在离线状态下运行。为了在有限的计算资源下实现用户友好性,部署在移动设备上的本地人脸验证模型不仅需要准确,还需要小巧和快速。然而,现代高精度人脸验证模型是基于深度和庞大的卷积神经网络(CNNs)构建的,这些网络在训练阶段由新颖的损失函数监督。这些需要大量计算资源的大型CNN模型并不适合许多移动和嵌入式应用。近年来,针对常见的视觉识别任务而非人脸验证,提出了几种高效的神经网络架构,例如MobileNetV1 [1]、ShuffleNet [2] 和 MobileNetV2 [3]。直接使用这些常见的CNN进行人脸验证是一种直接的方法,但根据我们的实验(见表2),这种方法的准确性远低于最先进的结果。
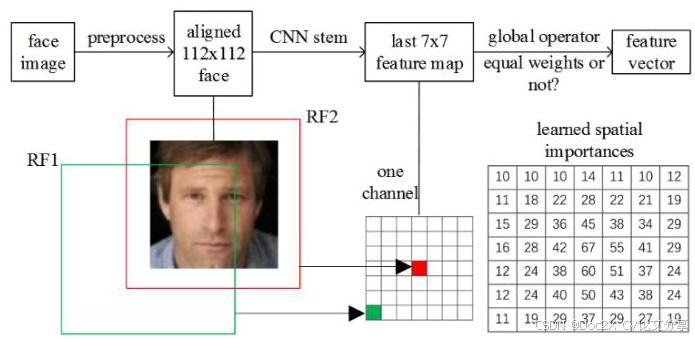
Fig. 1. A typical face feature embedding CNN and the receptive field (RF). The last 7x7 feature map is denoted as FMap-end. RF1 and RF2 correspond to the corner unit and the center unit in FMap-end respectively. The corner unit should be of less importance than the center unit. When a global depthwise convolution (GDConv) is used as the global operator, for a fixed spatial position, the norm of the weight vector consisted of GDConv weights in all channels can be considered as the spatial importance. We show that GDConv learns very different importances at different spatial positions after training.
图1. 典型的人脸特征嵌入CNN及其感受野(RF)。最后一个7x7特征图表示为FMap-end。RF1和RF2分别对应于FMap-end中的角单元和中心单元。角单元的重要性应低于中心单元。当全局深度卷积(GDConv)用作全局操作符时,对于固定的空间位置,由所有通道中的GDConv权重组成的权重向量的范数可以被视为空间重要性。我们表明,经过训练后,GDConv在不同空间位置学习到非常不同的重要性。
In this paper, we make a simple analysis on common mobile networks’ weakness for face verification. The weakness has been well overcome by our specifically designed MobileFaceNets, which is a class of extremely efficient CNN models tailored for high-accuracy real-time face verification on mobile and embedded devices. Our MobileFaceNets use less than 1 million parameters. Under the same experimental conditions, our MobileFaceNets achieve significantly superior accuracy as well as more than 2 times actual speedup over MobileNetV2. After trained on the refined MS-Celeb-1M [4] by ArcFace [5] loss from scratch, our single MobileFaceNet model of 4.0MB size achieves 99.55 % {99.55}\% 99.55% face verification accuracy (see Table 3) on LFW [6] and 92.59% TAR@FAR10-6 (see Table 4) on MegaFace Challenge 1 [7], which is even comparable to state-of-the-art big CNN models of hundreds MB size. Note that many existing techniques such as pruning [37], low-bit quantization [29], and knowledge distillation [16] are able to improve MobileFaceNets’ efficiency additionally, but these are not included in the scope of this paper.
本文对常见移动网络在人脸验证中的弱点进行了简单分析。这些弱点已被我们专门设计的 MobileFaceNets 很好地克服,MobileFaceNets 是一类针对移动和嵌入设备上高精度实时人脸验证而定制的极其高效的 CNN 模型。我们的 MobileFaceNets 使用不到 100 万个参数。在相同的实验条件下,我们的 MobileFaceNets 不仅实现了显著更高的准确性,而且实际速度提高了 2 倍以上。在通过 ArcFace [5] 损失从头开始训练的精炼 MS-Celeb-1M [4] 数据集上,我们单个 4.0MB 大小的 MobileFaceNet 模型在 LFW [6] 上达到了 99.55 % {99.55}\% 99.55% 的人脸验证准确率(见表 3),在 MegaFace 挑战赛 1 [7] 上达到了 92.59% 的 TAR@FAR10-6(见表 4),这甚至可以与数百 MB 大小的最先进大型 CNN 模型相媲美。需要注意的是,许多现有技术,如剪枝 [37]、低比特量化 [29] 和知识蒸馏 [16],可以进一步提高 MobileFaceNets 的效率,但这些不在本文的讨论范围内。
The major contributions of this paper are summarized as follows: (1) After the last (non-global) convolutional layer of a face feature embedding CNN, we use a global depthwise convolution layer rather than a global average pooling layer or a fully connected layer to output a discriminative feature vector. The advantage of this choice is also analyzed in both theory and experiment. (2) We carefully design a class of face feature embedding CNNs, namely MobileFaceNets, with extreme efficiency on mobile and embedded devices. (3) Our experiments on LFW, AgeDB ([8]), and MegaFace show that our MobileFaceNets achieve significantly improved efficiency over previous state-of-the-art mobile CNNs for face verification.
本文的主要贡献总结如下:(1) 在人脸特征嵌入 CNN 的最后一个(非全局)卷积层之后,我们使用全局深度卷积层而不是全局平均池化层或全连接层来输出一个判别特征向量。这一选择的优点也在理论和实验中进行了分析。(2) 我们精心设计了一类人脸特征嵌入 CNN,即 MobileFaceNets,在移动和嵌入设备上具有极高的效率。(3) 我们在 LFW、AgeDB ([8]) 和 MegaFace 上的实验表明,我们的 MobileFaceNets 在人脸验证方面显著优于之前最先进的移动 CNN。
2 Related Work
2 相关工作
Tuning deep neural architectures to strike an optimal balance between accuracy and performance has been an area of active research for the last several years [3]. For common visual recognition tasks, many efficient architectures have been proposed recently [ 1 , 2 , 3 , 9 ] \left\lbrack {1,2,3,9}\right\rbrack [1,2,3,9] . Some efficient architectures can be trained from scratch. For example, SqueezeNet ([9]) uses a bottleneck approach to design a very small network and achieves AlexNet-level [10] accuracy on ImageNet [11, 12] with 50x fewer parameters (i.e., 1.25 million). MobileNetV1 [1] uses depthwise separable convolutions to build lightweight deep neural networks, one of which, i.e., MobileNet-160 (0.5x), achieves 4% better accuracy on ImageNet than SqueezeNet at about the same size. ShuffleNet [2] utilizes pointwise group convolution and channel shuffle operation to reduce computation cost and achieve higher efficiency than MobileNetV1. MobileNetV2 [3] architecture is based on an inverted residual structure with linear bottleneck and improves the state-of-the-art performance of mobile models on multiple tasks and benchmarks. The mobile NASNet [13] model, which is an architectural search result with reinforcement learning, has much more complex structure and much more actual inference time on mobile devices than MobileNetV1, ShuffleNet, and MobileNetV2. However, these lightweight basic architectures are not so accurate for face verification when trained from scratch (see Table 2).
调整深度神经网络架构以在准确性和性能之间找到最佳平衡点一直是过去几年活跃的研究领域 [3]。对于常见的视觉识别任务,最近提出了许多高效的架构 [ 1 , 2 , 3 , 9 ] \left\lbrack {1,2,3,9}\right\rbrack [1,2,3,9]。一些高效的架构可以从头开始训练。例如,SqueezeNet ([9]) 使用瓶颈方法设计了一个非常小的网络,并在 ImageNet [11, 12] 上实现了与 AlexNet [10] 相当的准确性,参数减少了 50 倍(即 125 万个参数)。MobileNetV1 [1] 使用深度可分离卷积构建轻量级深度神经网络,其中之一,即 MobileNet-160 (0.5x),在 ImageNet 上的准确性比 SqueezeNet 高出 4%,且大小相当。ShuffleNet [2] 利用逐点分组卷积和通道混洗操作来降低计算成本,并实现了比 MobileNetV1 更高的效率。MobileNetV2 [3] 架构基于倒置残差结构和线性瓶颈,改进了移动模型在多个任务和基准上的最先进性能。移动 NASNet [13] 模型是使用强化学习进行架构搜索的结果,其结构比 MobileNetV1、ShuffleNet 和 MobileNetV2 复杂得多,在移动设备上的实际推理时间也更长。然而,这些轻量级基础架构在从头开始训练时,对于人脸验证的准确性并不高(见表 2)。
Accurate lightweight architectures specifically designed for face verification have been rarely researched. [14] presents a light CNN framework to learn a compact embedding on the large-scale face data, in which the Light CNN-29 model achieves 99.33 % {99.33}\% 99.33% face verification accuracy on LFW with 12.6 million parameters. Compared with MobileNetV1, Light CNN-29 is not lightweight for mobile and embedded platform. Light CNN-4 and Light CNN-9 are much less accurate than Light CNN-29. [15] proposes ShiftFaceNet based on ShiftNet-C model with 0.78 million parameters, which only achieves 96.0 % {96.0}\% 96.0% face verification accuracy on LFW. In [5],an improved version of MobileNetV1, namely LMobileNetE, achieves comparable face verification accuracy to state-of-the-art big models. But LMobileNetE is actually a big model of 112MB model size, rather than a lightweight model. All above models are trained from scratch.
专门为面部验证设计的准确轻量级架构很少被研究。[14] 提出了一种轻量级 CNN 框架,用于在大规模面部数据上学习紧凑嵌入,其中 Light CNN-29 模型在 LFW 上实现了 99.33 % {99.33}\% 99.33% 的面部验证准确率,参数数量为 1260 万。与 MobileNetV1 相比,Light CNN-29 对于移动和嵌入式平台来说并不轻量级。Light CNN-4 和 Light CNN-9 的准确率远低于 Light CNN-29。[15] 提出了基于 ShiftNet-C 模型的 ShiftFaceNet,参数数量为 78 万,仅在 LFW 上实现了 96.0 % {96.0}\% 96.0% 的面部验证准确率。在 [5] 中,MobileNetV1 的改进版本,即 LMobileNetE,实现了与最先进大型模型相当的面部验证准确率。但 LMobileNetE 实际上是一个模型大小为 112MB 的大型模型,而不是轻量级模型。所有上述模型都是从头开始训练的。
Another approach for obtaining lightweight face verification models is compressing pretrained networks by knowledge distillation [16]. In [17], a compact student network (denoted as MobileID) trained by distilling knowledge from the teacher network DeepID2+ [33] achieves 97.32% accuracy on LFW with 4.0MB model size. In [1], several small MobileNetV1 models for face verification are trained by distilling knowledge from the pretrained FaceNet [18] model and only face verification accuracy on the authors’ private test dataset are reported. Regardless of the small student models’ accuracy on public test datasets, our MobileFaceNets achieve comparable accuracy to the strong teacher model FaceNet on LFW (see Table 3) and MegaFace (see Table 4).
另一种获得轻量级面部验证模型的方法是压缩预训练网络,通过知识蒸馏 [16]。在 [17] 中,通过从教师网络 DeepID2+ [33] 中提取知识训练的紧凑学生网络(记为 MobileID)在 LFW 上实现了 97.32% 的准确率,模型大小为 4.0MB。在 [1] 中,通过从预训练的 FaceNet [18] 模型中提取知识训练了几个用于面部验证的小型 MobileNetV1 模型,仅报告了作者私有测试数据集上的面部验证准确率。无论小型学生模型在公共测试数据集上的准确率如何,我们的 MobileFaceNets 在 LFW(见表 3)和 MegaFace(见表 4)上实现了与强大的教师模型 FaceNet 相当的准确率。
3 Approach
3 方法
In this section, we will describe our approach towards extremely efficient CNN models for accurate real-time face verification on mobile devices, which overcome the weakness of common mobile networks for face verification. To make our results totally reproducible, we use ArcFace loss to train all face verification models on public datasets, following the experimental settings in [5].
在本节中,我们将描述我们针对移动设备上高效且准确的实时人脸验证的 CNN 模型方法,这些方法克服了常见移动网络在人脸验证中的弱点。为了使我们的结果完全可复现,我们使用 ArcFace 损失在公共数据集上训练所有人脸验证模型,遵循 [5] 中的实验设置。
3.1 The Weakness of Common Mobile Networks for Face Verification
3.1 常见移动网络在人脸验证中的弱点
There is a global average pooling layer in most recent state-of-the-art mobile networks proposed for common visual recognition tasks, for example, MobileNetV1, ShuffleNet, and MobileNetV2. For face verification and recognition, some researchers ([14], [5], etc.) have observed that CNNs with global average pooling layers are less accurate than those without global average pooling. However, no theoretical analysis for this phenomenon has been given. Here we make a simple analysis on this phenomenon in the theory of receptive field [19].
在大多数为常见视觉识别任务提出的最新移动网络中,例如 MobileNetV1、ShuffleNet 和 MobileNetV2,都包含一个全局平均池化层。对于人脸验证和识别,一些研究人员([14]、[5] 等)观察到,带有全局平均池化层的 CNN 在准确性上不如没有全局平均池化层的 CNN。然而,目前还没有对此现象的理论分析。在这里,我们根据感受野理论 [19] 对此现象进行了简单的分析。
A typical deep face verification pipeline includes preprocessing face images, extracting face features by a trained deep model, and matching two faces by their features’ similarity or distance. Following the preprocessing method in [5, 20, 21, 22], we use MTCNN [23] to detect faces and five facial landmarks in images. Then we align the faces by similarity transformation according to the five landmarks. The aligned face images are of size 112 × 112 {112} \times {112} 112×112 ,and each pixel in RGB images is normalized by subtracting 127.5 then divided by 128. Finally, a face feature embedding CNN maps each aligned face to a feature vector, as shown in Fig. 1. Without loss of generality, we use MobileNetV2 as the face feature embedding CNN in the following discussion. To preserve the same output feature map sizes as the original network with 224 × 224 {224} \times {224} 224×224 input,we use the setting of stride = 1 = 1 =1 in the first convolutional layer instead of stride = 2 = 2 =2 ,where the latter setting leads to very poor accuracy. So, before the global average pooling layer, the output feature map of the last convolutional layer, denoted as FMap-end for convenience, is of spatial resolution 7 × 7 7 \times 7 7×7 . Although the theoretical receptive fields of the corner units and the central units of FMap-end are of the same size, they are at different positions of the input image. The receptive fields’ center of FMap-end’s corner units is in the A typical deep face verification pipeline includes preprocessing face images, extracting face features by a trained deep model, and matching two faces by their features’ similarity or distance. Following the preprocessing method in [ 5 , 20 , 21 , 22 ] \left\lbrack {5,{20},{21},{22}}\right\rbrack [5,20,21,22] ,we use MTCNN [23] to detect faces and five facial landmarks in images. Then we align the faces by similarity transformation according to the five landmarks. The aligned face images are of size 112 × 112 {112} \times {112} 112×112 ,and each pixel in RGB images is normalized by subtracting 127.5 then divided by 128 . Finally, a face feature embedding CNN maps each aligned face to a feature vector, as shown in Fig. 1. Without loss of generality, we use MobileNetV2 as the face feature embedding CNN in the following discussion. To preserve the same output feature map sizes as the original network with 224 × 224 {224} \times {224} 224×224 input,we use the setting of stride = 1 = 1 =1 in the first convolutional layer instead of stride = 2 = 2 =2 ,where the latter setting leads to very poor accuracy. So, before the global average pooling layer,
典型的深度人脸验证流程包括预处理人脸图像、通过训练好的深度模型提取人脸特征,以及通过特征的相似度或距离匹配两个人脸。按照[5, 20, 21, 22]中的预处理方法,我们使用MTCNN [23]检测图像中的人脸和五个面部标志。然后根据这五个标志通过相似变换对人脸进行对齐。对齐后的人脸图像大小为 112 × 112 {112} \times {112} 112×112,RGB图像中的每个像素通过减去127.5再除以128进行归一化。最后,一个人脸特征嵌入CNN将每个对齐后的人脸映射为一个特征向量,如图1所示。在不失一般性的情况下,我们在接下来的讨论中使用MobileNetV2作为人脸特征嵌入CNN。为了保持与原始网络相同的输出特征图大小,输入为 224 × 224 {224} \times {224} 224×224,我们在第一个卷积层中使用步长 = 1 = 1 =1而不是步长 = 2 = 2 =2,后者的设置会导致非常差的准确性。因此,在全局平均池化层之前,最后一个卷积层的输出特征图(为方便起见记为FMap-end)的空间分辨率为 7 × 7 7 \times 7 7×7。尽管FMap-end的角单元和中心单元的理论感受野大小相同,但它们在输入图像中的位置不同。FMap-end角单元的感受野中心位于
—— 更多内容请到Doc2X翻译查看——
—— For more content, please visit Doc2X for translations ——

















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









