







大模型的基础模式是transformer,所以很多芯片都实现先专门的transformer引擎来加速模型训练或者推理。本文将拆解Transformer的算子组成,展开具体的数据流分析,结合不同的芯片架构实现,分析如何做性能优化。
Transformer结构
transformer结构包含两个过程,Encoder和Decoder。其中Decoder较Encoder结构相同,多了对于kv_cache的处理。
如下图经典的结构示意图,可以看到在Decoder阶段的Multi-Head Attentiond的三个输入箭头其中两个来自Encoderde输出,关于kv-cache对内容管理的优化也是一个很重要的研究方向。本文暂时重点关注与Transformer的Encoder阶段的优化分析。
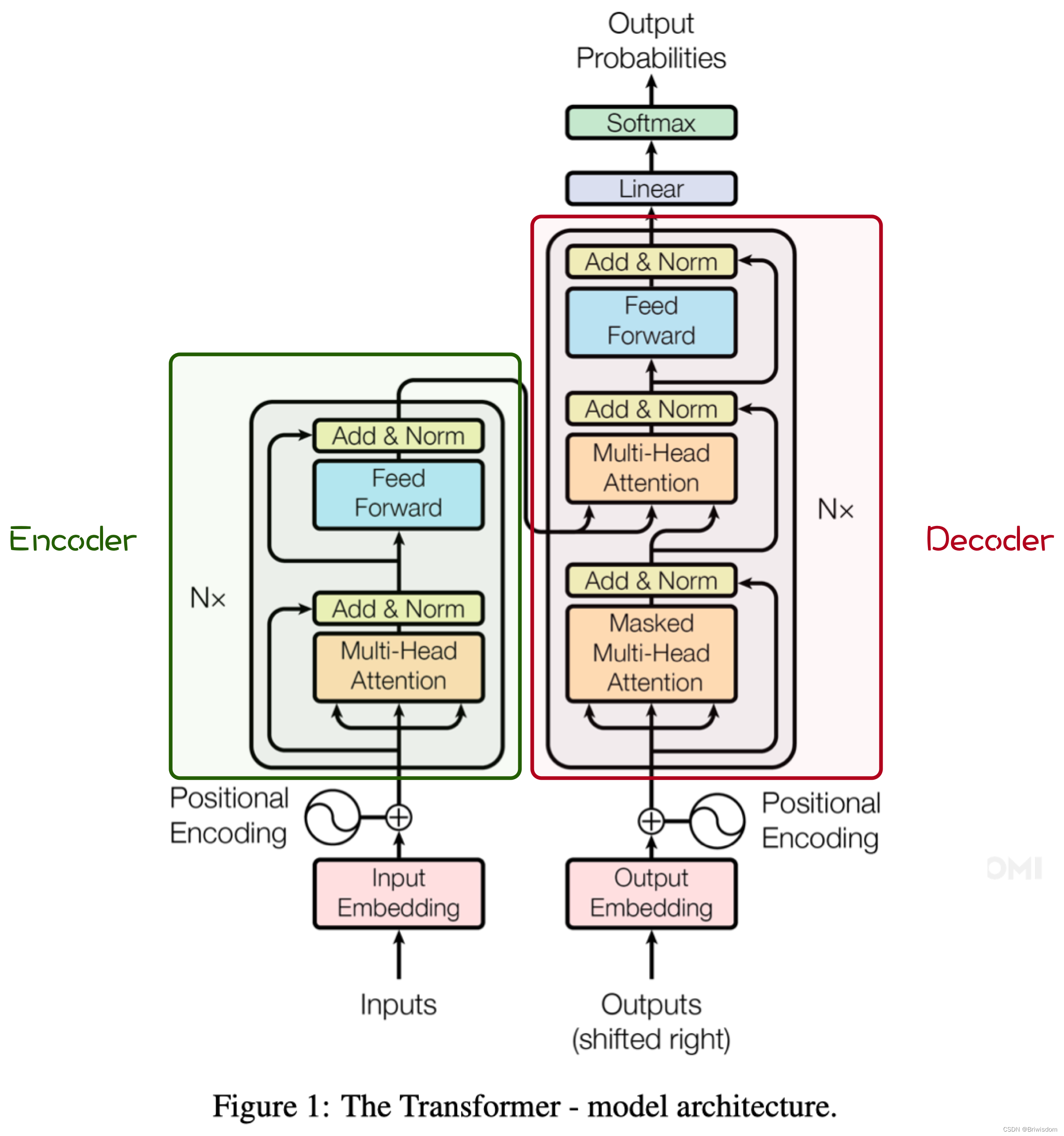
Transformer的数据流图
下图对应上面transformer的左边Encoder阶段。不同颜色表示不同的算子,其中linear, 其实也是一种matmul算子,只不过它的两个输入一个来自tensor, 一个来自常量。蓝色标记的matmul算子则两个输入全部是tensor。
包含的算子为:linear, matmul, transpose, softmax, add_layernorm。
通过代入参数,了解具体的数据流执行过程,可以让我们更加直观的理解下面的优化之后,得到相同的输出数据的思路。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











