







前段时间,给微信机器人-小爱(AI)新增了一个 AI日报的功能。

有朋友问怎么做的?
其实,这里只用了最简单的爬虫,然后通过定时任务发送。
今天,看到一个更加简单易用、功能强大爬虫工具 - Crawl4AI,几行代码,就能实现高效的网页爬取,分享给大家。
1. Crawl4AI 简介
Crawl4AI 是一个开源免费的自动化数据提取工具,曾荣登 GitHub Trending 榜一!
老规矩,简单介绍下项目亮点:
- AI 驱动:利用大型语言模型(LLM)智能识别和解析网页数据。
- 结构化输出:将数据转换为 JSON、Markdown 等格式,便于分析和AI模型训练。
- 高度定制化:允许自定义认证、请求头、页面修改、用户代理和执行JavaScript。
2. 安装
推荐两种安装方式。
2.1 使用 pip 安装
pip install crawl4ai
默认情况下,这将安装异步版本 Crawl4AI,并使用 Playwright 进行网页爬取。
👉 注意:安装脚本会自动安装并设置 Playwright。如果遇到与 Playwright 相关的报错,可使用以下方法手动安装:
playwright install
2.2 使用 docker 安装
直接拉取官方镜像,跑一个容器:
docker pull unclecode/crawl4ai:basic # Basic crawling features
# 或者
docker pull unclecode/crawl4ai:all # Full installation (ML, LLM support)
# 或者
docker pull unclecode/crawl4ai:gpu # GPU-enabled version
# Run the container
docker run -p 11235:11235 unclecode/crawl4ai:basic # Replace 'basic' with your chosen version
如果镜像拉取失败,也可以拉取官方仓库,自己构建镜像:
git clone https://github.com/unclecode/crawl4ai.git
cd crawl4ai
# Build the image
docker build -t crawl4ai:local \
--build-arg INSTALL_TYPE=basic \ # Options: basic, all
.
# Run your local build
docker run -p 11235:11235 crawl4ai:local
3. 使用
3.1 本地pip包
如果是本地 pip 安装,使用非常简单,采用异步函数实现,示例如下:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.nbcnews.com/business")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
如果要抓取外网内容,需要加上代理:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True, proxy="http://127.0.0.1:7890") as crawler:
result = await crawler.arun(
url="https://www.nbcnews.com/business",
bypass_cache=True
)
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
3.2 docker 容器
如果是 docker 镜像安装的,调用需分两步。
因为是异步服务,所以:
- 第一步请求会拿到 task_id,
- 第二步基于 task_id 轮询获取结果。
import requests
# Submit a crawl job
response = requests.post(
"http://localhost:11235/crawl",
json={"urls": "https://example.com", "priority": 10}
)
task_id = response.json()["task_id"]
# Get results
result = requests.get(f"http://localhost:11235/task/{task_id}")
4. 效果展示
下面,以抓取一个 html 页面,并输出为 markdown 格式,给大家展现下效果。
速度超快:
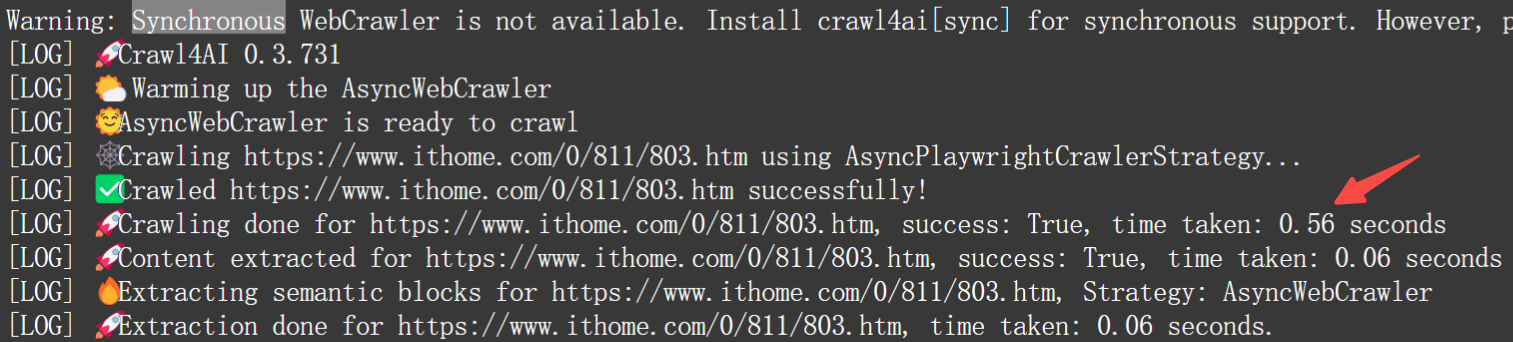
首页内容:

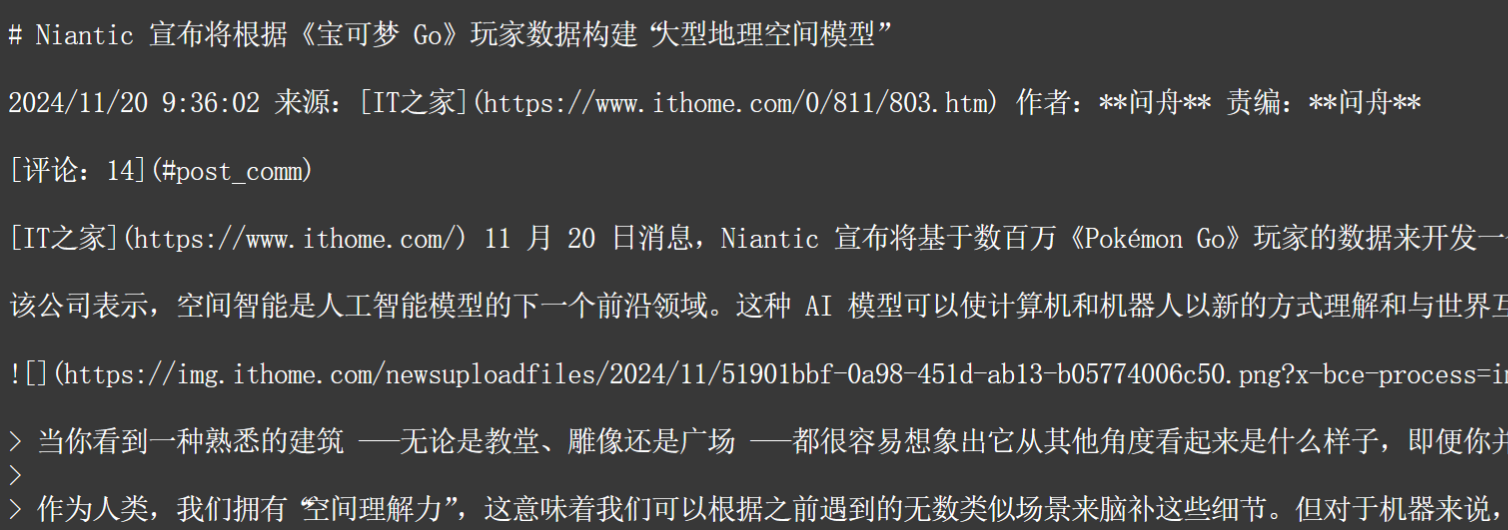
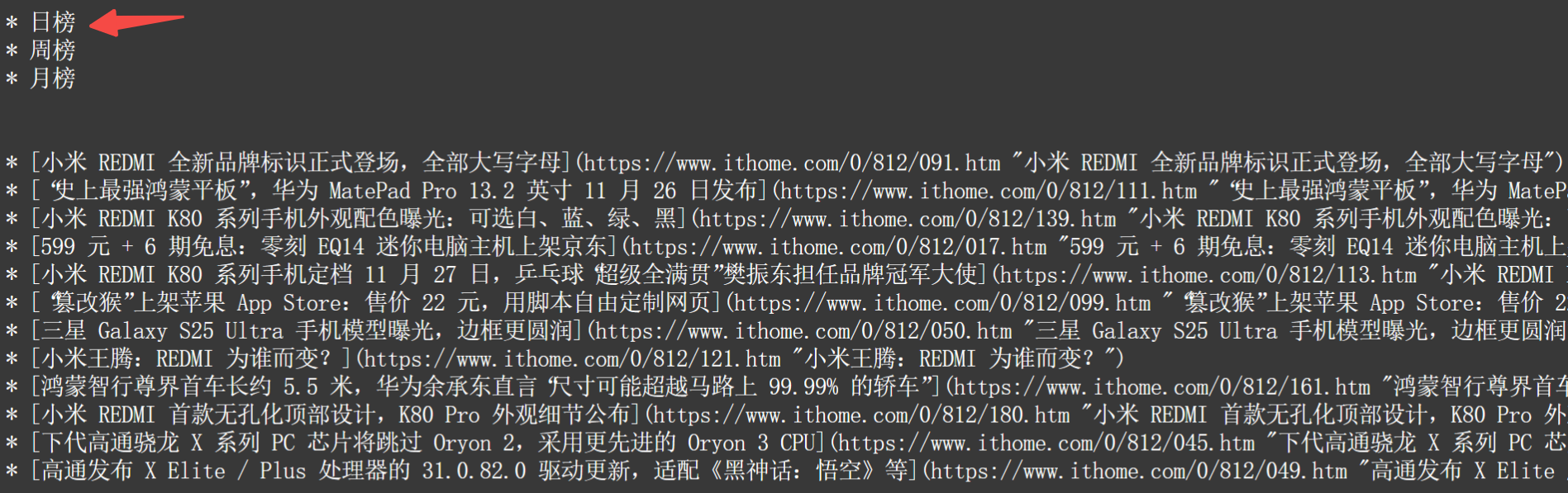
页面底部:


侧边栏:

怎么样?
更多高级策略使用,可参考官方仓库:https://github.com/unclecode/crawl4ai
写在最后
Crawl4AI,一款功能强大且简单易用的网页爬虫工具,而且速度超快,有需要的朋友,可以去试试了。
如果对你有帮助,欢迎点赞收藏备用。

















 4290
4290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









