








书接上回,我们在之前的文章已经分析了直接把transformer应用到时间序列预测问题的不足,其中我们总结了4个不足:分别是:
-
注意力机制的计算复杂度高,为 O(N^2),并且计算得出的权重仅有少部分有用;
-
注意力机制仅建立单时间点位之间的关系,实际能提取到的信息非常有限;
-
对时序或者说位置的建模表示不够充分,而时序任务中前后位置关系是重中之重;
-
没有专门的机制在数据“平稳化(之后详解)”和“非平稳化”之间达到合适的平衡。
其中Informer对第一点做了较大的改进;Non-stationary Transformers围绕第四点做了较多改进。那么2023年ICLR的文章Patch TST,对第一、二、三点,特别是第二点做了极大的改进。Patch TST发表后,现在已经有大量的Patch相关的时序论文发表,如下是一些patch相关的时序论文,Patch俨然成为最新的时序热点趋势。
香港科技大学:A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
华为:Multi-resolution Time-Series Transformer for Long-term Forecasting
模型结构
我相信即便是非CV领域的同学,也一定听说过VIT(Vision Transformer)模型。这个VIT模型是Google在2020年提出的将Transformer应用在图像分类的模型。论文题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale。你可以发现Patch TST和VIT在题目上的相似性。
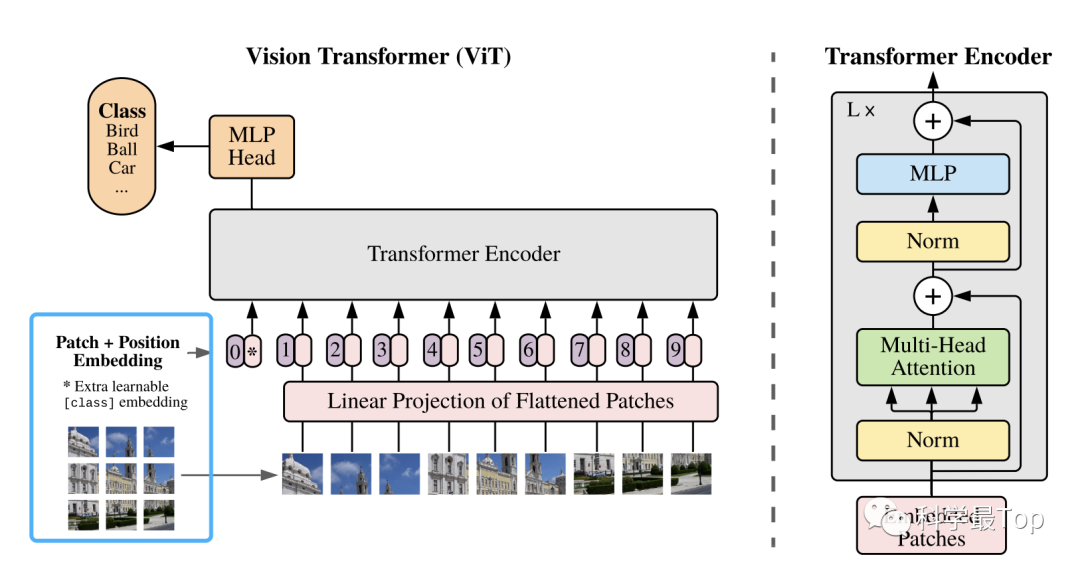
在VIT中,"patch" 是指将输入图像分割成均匀大小的小区域。这些小区域通常是正方形或矩形,并且被视为模型的基本单位。并且在输入到Transformer模型之前,通常会进行一些变换(如嵌入层),以便将它们转换为Transformer可接受的格式。每个图像块都被视为一个“标记”(token),它们被重新排列并输入到Transformer的注意力机制中进行处理,以捕获图像内部和区域之间的关系。
在Patch TST中,“patch”则是将输入时间序列按照一定大小的窗口和步长分割。并以分割形成的“时序块”作为输入,传输到Transformer进行建模的方式。
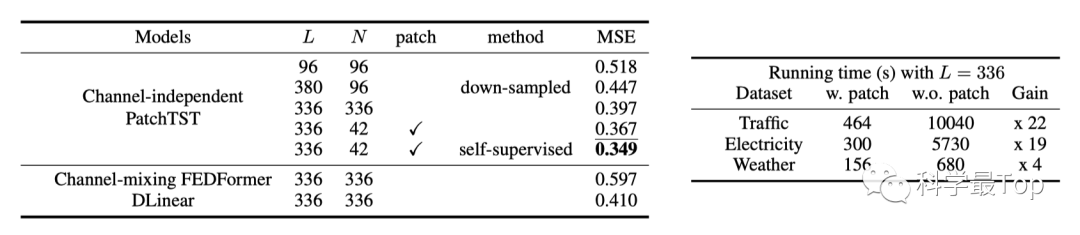
Patch TST作者在论文中,首先进行了一个case study来验证时间序列Patch的好处。结果如下,其中L是look-back window的长度,N是input tokens的长度。右表说明进行patch后,运行时间大幅缩短约至L/N。左表说明两件事:首先,对比前两行说明L越大,提供的时序信息越多,预测误差越小(但L越大计算复杂度越高);其次,Patch之后进行self- supervised进一步降低了预测误差。
不拘泥于时序数据,我们将patch的好处总结如下:
-
适应Transformer模型: 对于图像任务而言,将图像分割成块状区域允许Transformer模型处理视觉数据。Transformer原本是为处理序列数据设计的,而将图像划分成块后,每个块可以被看作是序列中的一个token,这样Transformer模型可以直接处理图像。
-
区域特征提取: 每个时序/图像块捕捉了局部区域的信息,使模型能够关注不同区域的特征。这有助于模型更好地理解时序/图像的局部信息,特别是单纯建立。
-
减少参数量: 将时序/图像块划分成小块可以减少模型需要处理的维度。这样一来,模型不需要逐个时间点/每一个像素进行处理,而是集中在每个块上进行处理,有效减少了模型的参数量,降低了计算复杂度。
模型结构
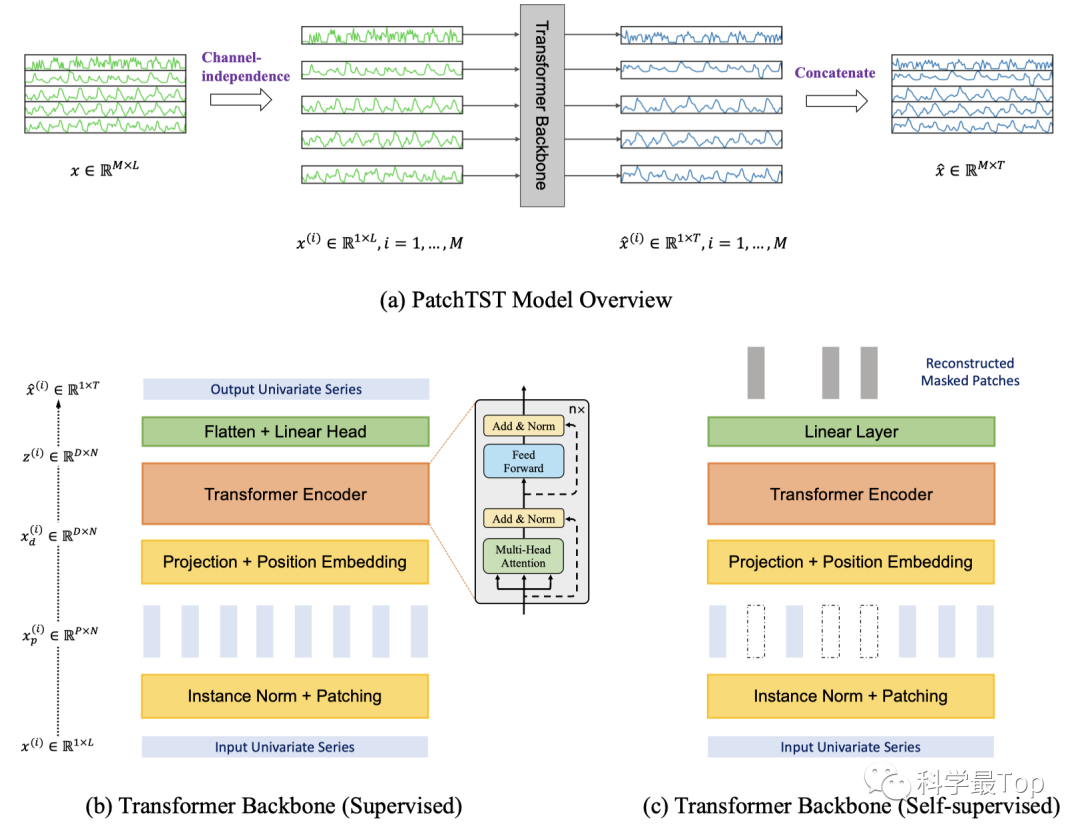
模型对每个输入的单变量时间序列进行分割,形成patch,注意这些patch可以是重叠的或非重叠的。Patch长度为 P,步长为 S(两个连续patch之间的不重叠区域),那么,patch的数量可以表示为N = [(L−P) /s] + 2。通过patch,输入的数量可以从 L 减少到大约 L/S。而注意力机制的内存使用和计算复杂度是成平方减少的。
图(b)和图(c)在结构上的区别在于图(b)最后进行了Flatten,然后进行预测。在训练方法上的主要区别在于,图(c)通过随机赋值为0的方式遮盖了部分patch,然后通过self-supervised重建被遮盖的数据。通过这种自监督学习的方式,模型可以更好地捕捉时间序列中的模式和特征。
我们自下而上逐层过一遍模型结构:
-
首先,使用基本的Transformer编码器将观测信号映射到潜在表示空间。该过程中,patch通过一个可训练的线性参数矩阵 和一个位置编码矩阵 ,将原始时间序列数据映射到维度为 D 的Transformer输入潜在空间。
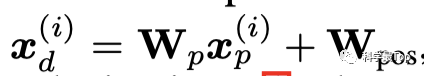
两个矩阵在这个过程中起到了不同的作用:
主要作用是特征映射或转换,将patch数据转换为更适合Transformer处理的表示形式; 是一个可学习的位置编码矩阵,用于捕获patch之间的时间顺序信息。
-
最终得到的 就是将patch映射到Transformer编码器中的输入。和经典的transformer一样,也对经过patch之后数据进行了多头注意力的计算,这一步是为了建立不同patch之间的联系。最后,如前所述Flatten之后进行预测。
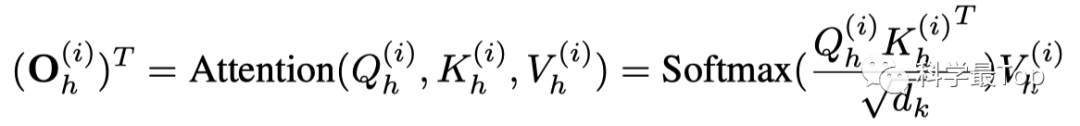
可以发现,如果没有self-supervised,本文其实就是把时序数据切块,然后把切块数据做了一个线性映射,作为transformer输入,最后进行预测。看起来无比简单,但是据作者进行的实验,效果和计算效率提升还是巨大的。这就是patch带来的好处。
自监督模型
自监督表示学习已成为从未标记数据中提取高层抽象表示的热门方法。在PatchTST中,作者也是故意随机移除输入序列的一部分内容,并训练模型恢复缺失的内容。然而,不同于文本,如果我们不进行patch,直接把时序数据输入则会存在两个潜在问题:
-
当前时间步的遮罩值可以通过与前后的时间值进行插值轻易推断,而不需要对整个序列有高层次的理解,这与我们学习整个信号的重要抽象表示的目标不符合。
-
已知我们有L 个时间步的表示向量,D维空间, M 个变量,每个变量具有预测范围 T。则输出需要一个维度为 (L⋅D)×(M⋅T)的参数矩阵 。如果这四个值中的任何一个或所有值都很大,那么这个矩阵可能会特别大。当下游训练样本数量稀缺时,这可能导致过拟合问题。
但是进行Patch后可以自然地克服前面提到的问题。按照我自己的理解,我们现在遮住的是“数据块”,而非“数据点”。预测的也是一个patch块,自然也就不存在插值的问题。
未来把Patch作为一个基础模块,围绕Patch进行改进,一定会出很多时序论文,不过Patch是CV2020的产物,时序研究落后有点严重啊
如有问题,请大家指正!
欢迎大家关注我的公众号【科学最top】,回复‘论文2024’可获取,2024年ICLR、ICML、KDD、WWW、IJCAI五个顶会的时间序列论文整理列表和原文。















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









