







 本文档概述了并行计算的基础知识,包括异构计算、MPI消息传递接口、并发与多处理、CPU信息、ARM CPU特性、CPU基准测试、压力测试等。同时介绍了OpenMP、OpenACC、Intel TBB、GPU编程和软件优化的相关工具和教程。
本文档概述了并行计算的基础知识,包括异构计算、MPI消息传递接口、并发与多处理、CPU信息、ARM CPU特性、CPU基准测试、压力测试等。同时介绍了OpenMP、OpenACC、Intel TBB、GPU编程和软件优化的相关工具和教程。
Overview
-
cggos
-
StreamHPC is a software development company in parallel software for many-core processors.
Heterogeneous Computing
MPI (Message Passing Interface)
Concurrency
- task switching
- hardware concurrency
Multi-Processing
IPC
Multi-Threading
- POSIX C pthread
- boost::thread
- c++11 std::thread
CPU
- Intel® 64 and IA-32 Architectures Software Developer Manuals
- Hotspots, FLOPS, and uOps: To-The-Metal CPU Optimization
CPU Info
8 commands to check cpu information on Linux:
-
/proc/cpuinfo: The
/proc/cpuinfofile contains details about individual cpu cores. -
lscpu: simply print the cpu hardware details in a user-friendly format
-
cpuid: fetches
CPUIDinformation about Intel and AMD x86 processors -
nproc: just prints out the number of processing units available, note that the number of processing units might not always be the same as number of cores
-
dmidecode: displays some information about the cpu, which includes the socket type, vendor name and various flags
-
hardinfo: would produce a large report about many hardware parts, by reading files from the
/procdirectory -
lshw -class processor: lshw by default shows information about various hardware parts, and the
-classoption can be used to pickup information about a specific hardware part -
inxi: a script that uses other programs to generate a well structured easy to read report about various hardware components on the system
ARM CPU features
CPU Benchmark
Sysbench
Sysbench – Scriptable database and system performance benchmark, a cross-platform and multi-threaded benchmark tool
sysbench --test=cpu --cpu-max-prime=20000 --num-threads=4 run
htop
-
htop - an interactive process viewer for Unix
-
htop explained - Explanation of everything you can see in htop/top on Linux

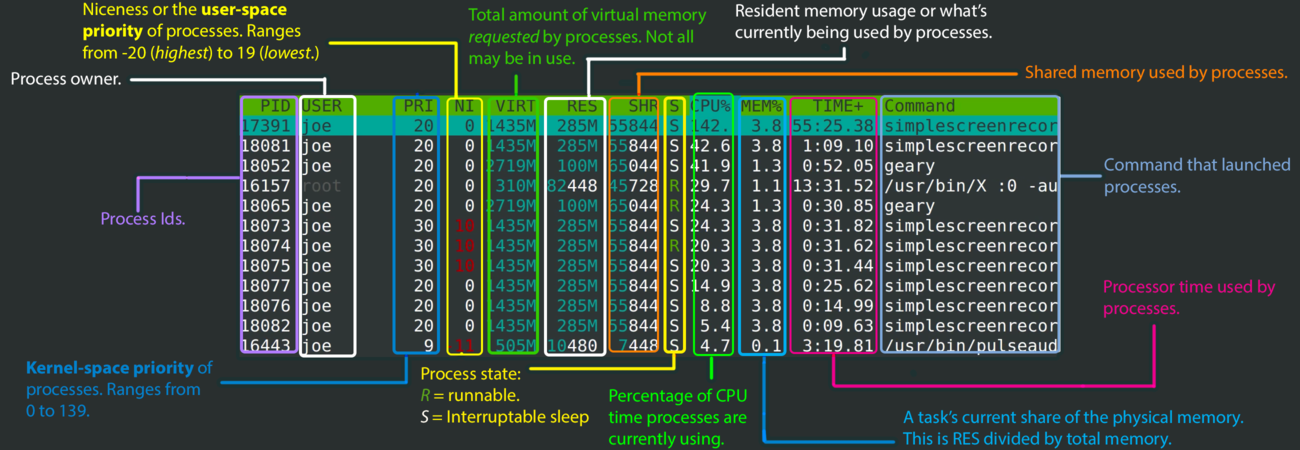
压力测试
https://www.tecmint.com/linux-cpu-load-stress-test-with-stress-ng-tool/
cat /sys/class/thermal/thermal_zone0/temp
# stress
stress --cpu 4 --io 4 --vm 1 --vm-bytes 1G
CPU Instructions & Intrinsics
Assembly
-
winasm: The x86 Assembly community and official home of WinAsm Studio and HiEditor
-
0xAX/asm: Learning assembly for linux-x64
SIMD
Intel MMX & SSE
-
SSE (Streaming SIMD Extentions)
ARM NEON
Arm NEON technology is an advanced SIMD (single instruction multiple data) architecture extension for the Arm Cortex-A series and Cortex-R52 processors.
Compiler Options:
-
test ARM NEON
gcc -dM -E -x c /dev/null | grep -i -E "(SIMD|NEON|ARM)" -
Raspberry Pi 3 Model B
- g++ options
-std=c++11 -O3 -march=native -mfpu=neon-vfpv4 -mfloat-abi=softfp -ffast-math - for the compilation error
error: ‘vfmaq_f32’ was not declared in this scope, you might add the option-mfpu=neon-vfpv4to enable__ARM_FEATURE_FMAin arm_neon.h
- g++ options
Reference Books:
- NEON Programmer’s Guide
- ARM® NEON Intrinsics Reference
Converter
- jratcliff63367/sse2neon
- From ARM NEON* to Intel® SSE - The Automatic Porting Solution, Tips and Tricks
OpenMP
The OpenMP API specification for parallel programming, an Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism.
OpenMP有两种常用的并行开发形式: 一是通过简单的 fork/join 对串行程序并行化,二是采用 单程序多数据 对串行程序并行化。
OpenMP in CMakeLists.txt:
find_package(OpenMP)
if (OPENMP_FOUND)
set (CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS}")
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
set (CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif()
OpenACC
OpenACC is a user-driven directive-based performance-portable parallel programming model designed for scientists and engineers interested in porting their codes to a wide-variety of heterogeneous HPC hardware platforms and architectures with significantly less programming effort than required with a low-level model.
Intel TBB
Intel Threading Building Blocks (TBB) lets you easily write parallel C++ programs that take full advantage of multicore performance, that are portable and composable, and that have future-proof scalability.
Intel IPP
GPU
GPU Benchmark
-
For the Raspberry Pi GPU benchmark, use the OpenGL 2.1 test that comes with GeeXLab
-
msalvaris/gpu_monitor: Monitor your GPUs whether they are on a single computer or in a cluster
watch -n 10 nvidia-smi # 每隔10秒更新一下显卡
# on Android
watch -n 0.1 adb shell cat /sys/class/kgsl/kgsl-3d0/gpu_busy_percentage # 0.1s
Platforms
-
Nvidia GPU
Languages
OpenCL
OpenCL™ (Open Computing Language) is the open, royalty-free standard for cross-platform, parallel programming of diverse processors found in personal computers, servers, mobile devices and embedded platforms.
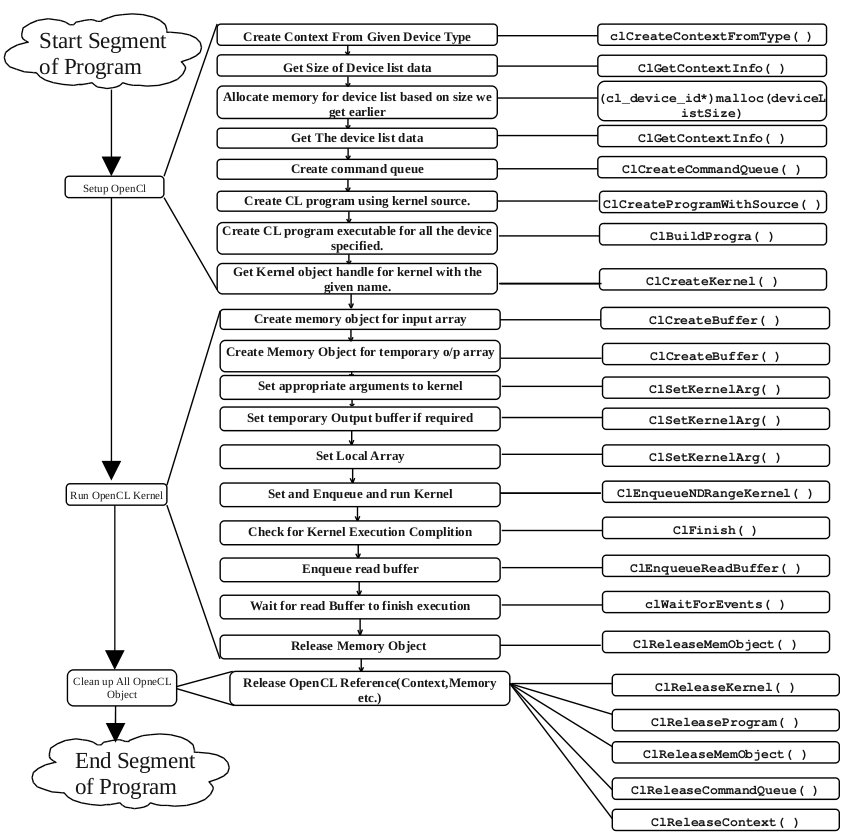
-
install OpenCL
# required: Ubuntu 16.04, nvidia GPU and nvidia driver installed sudo apt-get install nvidia-prime nvidia-modprobe nvidia-opencl-dev sudo ln -s /usr/lib/x86_64-linux-gnu/libOpenCL.so.1 /usr/local/lib/libOpenCL.so -
build program
g++ main.cpp -lOpenCL
CUDA
CUDA® is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs).



















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











