






前言
早在20世纪40年代数字革命开始之前,图像配准就已经成为一个具有重要现实意义的过程。这技术首次应用于彩印,即将几种单色图案叠加在一起形成多色图案。为了生成最终所需的多色印刷品,各个层相对于另一个层的对齐必须是精确的。若个别层发生错位,称为失配。因此,为了确保准确的配准,人们开发了检测和校正任何偏差的流程。
随着数字革命开启了现代医学成像时代,图像配准已经成为医疗成像研究中不可或缺的工具。虽然MRI不是最早使用图像配准的成像技术之一,但它可以说是受益最多的一种技术。在MRI技术中,大多数都需要图像配准作为必要的预处理步骤。对于许多MRI技术,最终的图像必须由一组精确对应的输入图像合成。由于输入图像集是连续获取的,在获取过程中如果出现被试运动等问题,可能会导致一些或所有输入图像失配,因此需要使用图像配准。
然而,这只是图像配准现今在MRI以及更广泛的医学成像中发挥的许多重要作用之一。为了满足这种多样化的需求,在过去的几十年里,各种各样的图像配准技术不断发展。此外,在过去的几年里,就像在许多其他领域一样,深度学习在解决一般图像分析问题方面的显著成功导致了人们对使用这种新兴技术来重新开发图像配准技术的兴趣激增。在此背景下,本文的目的是概述图像配准在MRI中的关键应用;为解决这些挑战而开发的图像配准技术的类别;以及深度学习带来的未来。
应用
图像配准的应用可以根据获取图像的对象分为两大类:受试者内(也称为被试内),即待配准的图像来自同一被试;受试者间(也称为被试间),即待配准的图像来自不同被试。
被试内应用是医学图像配准的原始驱动力。20世纪80年代,随着多种医学成像技术的快速发展,这些技术很好地提供了成像主体的互补信息,不同模态的数据融合引起了人们的极大兴趣。特别是,一个主要研究重点是融合来自同一个体的MRI和PET数据,这不仅可以将PET提供的详细生理信息归因于特定的解剖位置,而且MRI可以比PET更准确地确定这些解剖位置。被试内图像配准需要校正被试在定位、图像分辨率和图像失真方面的差异。如今,数据融合仍然是被试内图像配准的一个重要应用。由于典型的成像过程可能持续半小时或更长时间,即使是最顺从的参与者也不可能在这么长时间内保持静止。此外,不同的MRI模态通常表现出不同的图像失真,也可能在图像分辨率上存在差异,使得被试内图像配准对于多模态融合至关重要。
第二类被试内应用是作为一系列MRI模态的必要预处理步骤,这些模态通常在不同的实验设置下,从一组连续获得的图像中合成其输出。虽然在许多情况下,如fMRI,被试运动是图像失配准的主要原因,但扩散MRI例外。所谓的多壳层采集,通常用于神经成像,可以由数百个具有两个或多个扩散敏感因子(b值)和数百个不同的扩散敏感梯度方向连续获取的单个图像组成。不同的扩散敏感因子,加上不同的扩散敏感梯度方向,会导致图像出现不同程度和形式的畸变。因此,即使在没有被试运动的情况下,这些图像也会出现失配。在对这些图像进行组合以估计目标量(如弥散张量和纤维束方向分布函数)之前,必须进行被试内图像配准。
最后一类被试内应用是利用连续获得的MRI扫描来评估随时间的变化情况。个体的基线MRI扫描可以与一个或多个后续扫描进行比较,以量化解剖结构在形态学或对比度方面的时间变化。这种比较已被用于建立正常发育过程中大脑结构的生长轨迹,以及量化痴呆患者加速脑萎缩的模式。在这里,需要被试内图像配准来校正和量化相应解剖结构在形态学上的差异。另一个重要应用是图像引导的神经导航,以补偿神经外科手术中大脑结构的变形场,称为脑移位。图像引导的神经外科手术是根据术前扫描进行规划的,但大脑移位可能会导致严重的导航错误,必须加以补偿。这可以通过在操作过程中获取额外的扫描来实现。配准前和术中扫描可以确定和校正脑移位的程度。从连续扫描中估计形变的想法对于MR引导放疗也很重要,这通常涉及到多次就诊的一系列分步治疗。随着混合MR-linac系统的发展,每次就诊时都可以很容易地获取MRI数据,从而提供治疗靶点及其周围结构的最新图像。借助目前最快的MRI技术,甚至可以监测靶区运动,从而实现实时补偿,这为放疗带来了前所未有的准确性。
在过去的20年里,被试内的应用推动了图像配准的最早应用,而被试间的应用则推动了图像配准的大部分研究。特别是,自MRI扫描仪上市以来,从大量活人身上获取具有精细解剖细节的脑部扫描图像成为了可能。这一进展使神经科学家能够在一个大队列中研究脑解剖的共性和变异性,以及研究队列之间的差异,例如健康对照组和痴呆患者之间的差异。需要克服的关键挑战是来自不同个体的扫描空间对齐,因为被试之间的大脑大小和形状差异远远大于早期为被试内应用开发的图像配准方法。解决空间标准化的这一挑战促进了越来越复杂的图像配准技术的发展,这将在后文进行阐述。
图像配准算法的结构
虽然近年来已经开发出了大量的图像配准算法,但它们都有一个共同的结构和一组标准的构建块,只是在实现细节上有所不同。接下来,本文将介绍这种常见的结构和图像配准算法的标准组成部分。它将为理解各类算法之间的差异以及如何使用深度学习开发下一代方法提供概念框架。
图像配准的共同结构和构建块可以从前人的研究中加以理解。关于图像配准算法的几个要点是:首先,配准两张图像的任务可以表述为找到一个图像(运动图像)相对于另一个图像(固定图像)的位置调整,即几何变换,将运动图像与固定图像对齐。然后是图像配准算法的第一个基本构建块:两个图像之间对齐质量的度量,称为相似性度量。相似性度量需要从图像对的某些特征中确定,所选择的特征集合通常被称为特征空间。
简而言之,配准两幅图像的算法是在预先指定的变换空间内,遵循一定的搜索策略来寻求几何变换的过程。当应用于运动图像时,期望的几何变换应该最大化其与目标图像的对齐,由定义在某些特征空间上的预定义相似性度量来评估。图像配准算法的三个基本要素是:①变换空间;②基于变换空间的搜索策略;③定义在某些特征空间上的相似性度量。
图像配准算法的分类
基于变换空间的分类
基于变换空间的一种最常见分类方案是将图像配准算法分为线性和非线性两类。如果从该算法的变换空间中绘制的变换总是将一组平行直线变换为另一组平行直线,则认为该算法是线性的;这种变换称为线性或仿射变换。相反,如果一个算法的变换空间包含可以将直线变换成曲线的候选点,则认为该算法是非线性的,这种变换被称为非线性或可变形变换。
基于变换空间,图像配准算法也可分为刚性配准和非刚性配准。如果一个算法的候选变换是线性的,并且保留了直线段的长度,则认为该算法是刚性的;这种保持长度的线性变换称为刚性变换。刚性图像配准通常用于被试内的应用,当预期大小和形状无差异时,以校正相同被试图像之间的位置和方向差异,例如运动校正。图1d通过其在图1c所示的规则网格上的作用说明了刚性变换的效果。如果一个算法的候选变换是非线性的,则认为该算法是非刚性的;这种变换称为非刚性变换。非刚性变换包括所有可变形变换和非刚性线性变换。
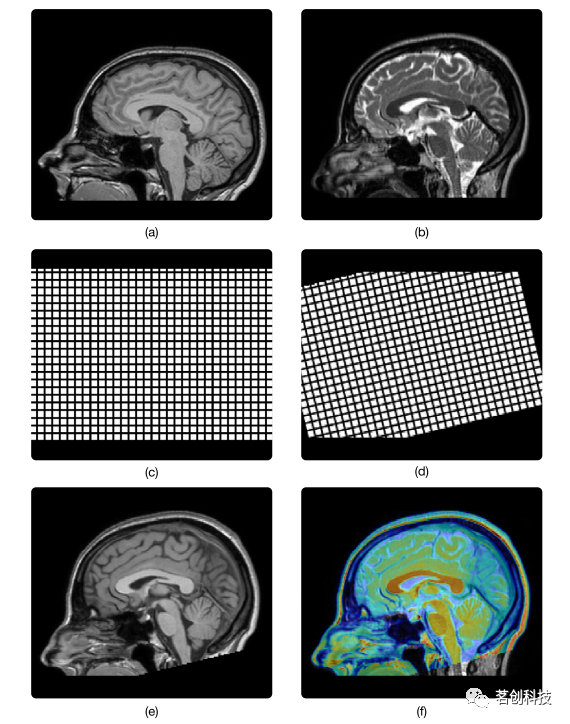
图1.被试内配准的图像融合示意图。图(a)和(b)显示了健康个体的T1加权(T1w)和T2加权(T2w) MRI脑部扫描。几何变换可以用一个规则的网格来可视化,如图(c)所示,应用变换后的相同网格,如图(d)所示。图(e)显示了应用这个变换后的T1w扫描,现在与T2w扫描对齐。图(f)所示实现了来自同一被试的两种不同对比的融合。
被试之间的应用通常需要使用非刚性图像配准来校正被试之间的大小和形状的显著差异。特别地,采用非刚性线性图像配准来匹配图像的全局形状和大小,以及位置和方向;示例如图2c所示。然后应用可变形图像配准来匹配局部形状和大小;示例如图2e所示。一些被试内的应用也需要非刚性图像配准。一个重要的例子是对扩散MRI中涡流引起的几何畸变校正。由扩散敏感梯度产生的涡流会导致所获得的图像产生几何畸变。事实证明,这种几何畸变可以很好地近似为非刚性线性变换。因此,采用非刚性线性图像配准方法对其进行校正。此外,非刚性线性变换的形式在很大程度上取决于扩散敏感梯度的性质。一些技术利用这种关系来产生所需线性变换的高质量初始猜测。另一个例子是回波平面成像(EPI)中由磁化率引起的几何畸变校正。软组织与骨骼或空气界面之间的敏感性差异会导致高度局部化、非线性、几何畸变。在没有任何附加信息的情况下,例如在其他方面都相同的采集过程中,但EPI相位编码方向相反,可以通过将EPI图像与同一个体的T1加权扫描进行非线性图像配准来校正几何畸变。
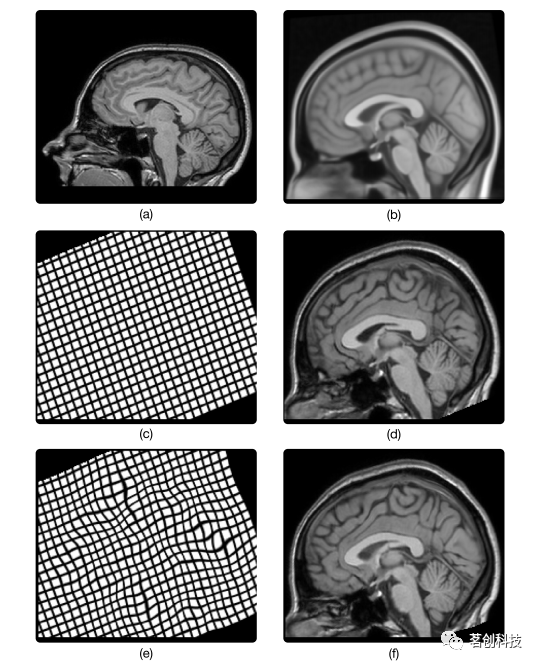
图2.被试间配准的空间标准化示意图。图(a)显示了一个健康被试的T1加权(T1w) MRI脑部扫描。图(b)显示了蒙特利尔神经研究所(MNI)通过对152名健康被试的平均脑MRI扫描而开发的MNI152 T1w模板。应用被试间配准使T1w扫描与MNI152模板对齐。这涉及到首先应用线性配准来找到线性变换,使T1w扫描在大小和形状上与模板大致相似。由此产生的线性变换及其在规则网格上的作用如图(c)所示。这种变换对T1w扫描的影响如图(d)所示。在线性配准之后,应用非线性配准来找到一个非线性变换,以将T1w扫描与模板详细匹配。图(e)将产生的非线性变换可视化。图(f)显示了应用此变换后的T1w扫描,该扫描现在相对于模板定义的标准空间进行了空间标准化。
另一种对图像配准算法进行分类的有用方法是利用变换空间的维数。顾名思义,变换空间的维数是用于搜索最优变换空间大小的度量;维数越大,高效寻找最优变换的难度就越大。对于一个变换空间,其维数被定义为属于该空间中变换的自由度(DoF)。例如,刚性变换有6个自由度(3个用于平移,3个用于旋转),它是我们考虑过的最小的变换空间,因此是寻找解变换最简单的空间。一般的线性变换(刚性变换是一种特殊情况)有6个额外的自由度(3个用于缩放,3个用于切变),使得线性图像配准比刚性图像配准更为复杂。相比之下,非线性变换的自由度可以大很多个数量级。
这种大维度的变换空间为描述被试之间复杂的形态差异提供了灵活性,但同时也带来了两个重大挑战。一是如何在如此大的空间中高效地寻找正确解;这一挑战将在后面的搜索策略中进行讨论。另一个是可能找到不适当的变换的问题,例如,那些在变换后的图像中留下褶皱或撕裂。不引起折叠或撕裂的变换称为拓扑保持。除了拓扑保持之外,我们通常还要求变换是平滑的。平滑性保证了变换是可微的。这个性质保证了雅可比矩阵的存在,雅可比矩阵可以被认为是一个变换的一阶导数。这个矩阵的行列式,通常被称为雅可比行列式或雅可比矩阵,它提供了一个对局部变形有用的概括度量:大于1的值表示展开;大于0但小于1的值表示压缩。重要的是,它提供了一种实用的方法来检测变换是否具有拓扑保持性。一个保持拓扑的变换必须只有正的雅可比行列式。总而言之,理想的变换应该是拓扑保持和可微的;这样的映射被称为差分同构变换或差分同构。
对每个高维非线性图像配准进行积分是一种防止算法产生非同构变换的策略;这种策略被称为转换正则化。正则化策略是对形变图像配准算法进行分类的重要方法。广义上,它们可以分为显式方法或隐式方法。在显式方法中,引入正则化项来度量候选变换的适宜性;该算法的目标是寻找最优变换,使相似性度量和正则化项的加权和最大化。正则化项通常由雅可比行列式构成,用于惩罚任何接近0的值。相比之下,隐式方法通过构造对变换的所需属性进行编码,也就是说,根据变换的数学表示进行编码。例如,通过使用三次b样条基函数进行自由变形,可以保证得到的变换是光滑的。通常,隐式方法需要与一些显式正则化相结合。自由变形再次提供了一个例子,因为构造不保证拓扑保持。因此,有必要额外包含一个正则化项,以阻止使用任何破坏拓扑的映射。
基于相似性度量的分类
对于图像配准,人们提出了各种各样的相似性度量方法。它们可以在特征空间的选择上有所不同,也可以在使用特征评估图像相似性的方式上不同。在早期的医学图像配准中,特征空间通常是一组对应的地标点,这些地标点需要提前识别,例如通过专家的人工检查或一些自动化方法。这种基于地标点的图像配准的相似性度量通常是对应地标点之间距离的平方和。但是识别相应的地标点并不简单,特别是当需要大量地标点时,例如,对于需要高维非线性变换的被试间应用程序。对基于地标的方法的一个自然泛化是使用相应的表面作为特征空间。这利用了这样一个事实,即在两张图像中识别相应的表面相当容易,因为这不需要像基于地标的匹配那样建立逐点对应关系的繁重任务。这种方法对于调整特定的解剖结构特别有用,比如海马体。这种基于表面的匹配的相似性度量通常是一个表面顶点到另一个表面顶点之间最近距离的总和。如今,基于地标和表面的方法通常不用于某些特定的被试内应用,在这些应用中,刚性或线性变换就足够了。现在所选择的特征空间是整个图像体素集;使用该特征空间的相似性度量被称为基于体素的或基于强度的相似性度量。
基于体素的相似性度量可以分为模态内相似性度量和模态间相似性度量。模态内相似性度量是为具有相同模态的两张图像而设计的。最简单的体素相似性度量——强度差平方和(SSD)就是这类方法。它假设在解剖上对应的结构应该具有相似的体素值,任何差异都可以归因于噪声。然而,由于B0或B1场的不均匀性等因素,在被试内和被试间经常观察到解剖上均匀的组织内强度不均匀,这足以导致SSD表现不佳。虽然这个问题可以通过应用强度不均匀性校正作为预处理步骤来缓解,但也有研究开发出了对图像强度做出较弱假设的替代相似性度量。一个常用的例子是归一化交叉相关(NCC),它是图像对的相应强度值之间的相关系数。与SSD相比,NCC仅假设解剖对应体素强度之间存在线性关系。然而,对于关联不同模态图像之间的强度来说,这种假设仍然太过强烈。为了用模态内的相似性度量来支持模态间的配准,一种方法是将一幅图像转换为另一幅图像的模态。例如,这可以用于校正涡流引起的失真,以考虑不同扩散加权因子和梯度获得的体积之间的对比度变化。另外,还可以使用多模态相似性度量,其中最著名的是互信息。互信息(MI)是信息论相似性度量的一个例子。从信息论的角度看待图像配准,并将其重新定义为一个预测问题,其目标是寻求一种从固定图像中最大化概率预测运动图像的变换。其基本假设是,解剖上对应的体素的强度值是彼此良好的预测指标。
基于搜索策略的分类
图像配准采用了多种搜索策略。尽管种类繁多,但它们有一个共同的特征,即它们本质上是迭代的。其工作原理是,首先从所选择的变换空间中,选择一个初始的猜测作为搜索的起点。然后迭代地完善这个初始估计。在每次迭代中,将变换的当前估计应用于运动图像。然后,计算选择的相似性度量,以评估变换后的运动图像和固定图像之间的对齐质量。迭代继续进行,直到某些预先指定的收敛标准来度量所提出的细化改进被认为可以忽略不计。
在迭代搜索的共同框架中,不同的策略在如何对当前变换估计进行细化方面有所不同。在这里,变换空间由允许平移(上/下和左/右)(2 DoF)和旋转(1 DoF)的2D刚性变换组成。所以任何细化都有3个DoF,可以看作是一个有方向和大小的矢量。换句话说,算法不仅要决定调整的方向,还要决定调整的大小。大致有两种选择细化方向的方法。第一种是使用交替策略的方法,每次总是对一个DoF进行细化,同时保持其余DoF不变。这种方法实现起来很简单,通常用于线性配准。但当变换空间的维数较大时,该方法的配准效果不佳,不适合非线性图像配准。对于可变形图像的配准,基于梯度的策略是标准的,其中最简单的例子是梯度上升法。这里计算了相似性度量相对于变换的梯度向量。由于沿梯度向量的调整在局部产生最大的相似性度量增加,因此将梯度方向作为搜索方向。一旦选择了搜索方向,确定调整的幅度就变得棘手了,因为它必须确保这个选择不会降低相似性度量。在实践中,可以谨慎地进行一些预先定义的小调整,并在需要时减少调整,或者通过反复试验来实现。
迭代搜索面临的一个常见挑战是存在许多局部极大值。根据最初的猜测,迭代搜索可以收敛到任何一个局部极大值,但只有其中一个对应于正确的对齐。为了解决这个问题,人们开发了两种方法。最常用的是所谓的多分辨率策略。在这里,通过逐步模糊和降采样来构建一个图像金字塔,由此产生的金字塔中的图像就可以在一定尺度范围内捕获空间细节。配准从只包含最大尺度信息的图像开始,这往往具有更少的局部极大值。然后在该尺度下估计的变换用于与捕获下一尺度细节的图像进行初始配准。重复这个过程,直到与原始图像进行配准。第二种方法被称为多起点策略。顾名思义,其想法是从多个起点重复配准,希望从这些初始猜测中至少有一个能够达到正确的匹配。
基于深度学习的图像配准
2012年是深度学习首次在图像识别领域取得里程碑式突破的一年。因此值得注意的是,仅仅在一年之后,第一个应用深度学习的医学图像配准方法就问世了。此后,关于这一主题的研究文章呈指数级增长,并且已经出现了许多综述文章,他们对利用深度学习重新开发图像配准表现出了极大的兴趣。
首先出现的策略是使用深度学习来制定更好的相似性度量。该方法的第一个例子利用了深度学习的独特能力来学习图像中的显著特征,从而用于分类任务。其思想是,对目标识别很重要的特征通常对目标匹配也很重要。因此,一种被称为堆叠卷积自编码器的深度学习模型被用于学习待配准图像类的新表征。根据两幅图像的新表征之间的相似性来评估两幅图像之间的相似性。这种方法的一个局限性是图像必须是相同的模态。最近的发展集中于多模态应用中有效的相似性度量上。一个例子是训练一个深度学习模型,从未对齐的图像块中分类对齐的图像块。当呈现新的一对图像块时,得到的模型将产生一个介于-1到1之间的评分,其中-1表示模型认为图像对未对齐,1表示图像对是对齐的。在进行配准时,在每次迭代时,将变换后的运动图像和固定图像分割成相应的patch,并对每对patch进行模型评分。然后,相似性度量可以用所有patch对的得分总和来评估。该方法的一个局限性是需要现有的多模态图像是对齐的。最近有研究已经开发出了放弃这一要求的策略。
另一种策略是利用深度学习来改进搜索策略。避免局部极大值对于标准迭代搜索来说是一个明显的挑战。解决这个问题的一种方法是使用深度强化学习,这就是阿尔法围棋成功打败世界上最优秀的人类围棋选手的背后原因。在这里,一个高度鲁棒的搜索策略是从以前的无数尝试中学习到的。从先前经验中学习的能力是传统搜索策略的关键优势。这种方法的一个局限性是它保留了图像配准的迭代性质。为了使图像配准一次完成,已经开发了多种方法。大致可以分为监督和非监督两类。监督方法的工作原理是训练深度学习模型,该模型将一对图像作为输入,并预测将这两幅图像进行配准的变换。它们被称为有监督的模型,因为模型必须用已知正确变换的成对图像进行训练。创建此类训练数据面临的挑战促使我们开发了无监督方法,而无监督方法不需要此类数据。这一突破来自于所谓的空间变换器网络(STN)的发明,它允许在深度学习模型中编码几何变换。在模型训练过程中,对于每对输入图像,模型参数被调整,使预测变换最大化某些预设的相似性度量。换句话说,它本质上就像运行一个传统的迭代图像配准算法。关键的区别在于,该模型从过去的经验中学习。随着越来越多的训练图像对输入到模型中,模型在预测正确变换方面的性能越来越好。最重要的是,在训练完模型后,当有一对新的图像需要配准时,模型可以在一次中预测合适的变换,而不需要多次迭代。因此,这些方法现在可以在传统算法所需时间的一小部分内就完成图像配准。例如,对于一对T1加权扫描的配准,计算时间可以从约1小时减少到约1分钟。更值得注意的是,它们可以在获得这样的计算效率增益的同时,匹配最先进的传统技术的配准性能。这样的进展使得基于深度学习的图像配准的未来真正令人期待。
参考文献:
Brown, Lisa G., 1992. A survey of image registration techniques. ACM Computing Surveys 24 (4), 325–376. https://doi.org/10.1145/146370.146374.
Fonov, Vladimir, et al., 2011. Unbiased average age-appropriate atlases for pediatric studies. NeuroImage 54 (1), 313–327. https://doi.org/10.1016/j.neuroimage.2010.07.033.
Friston, Karl J., et al., 1995. Spatial registration and normalization of images. Human Brain Mapping 3 (3), 165–189. https://doi.org/10.1002/hbm.460030303.
Fu, Fabo, et al., 2020. Deep learning in medical image registration: a review. Physics in Medicine and Biology 65 (20), 20TR01. https://doi.org/10.1088/1361-6560/ab843e.
Hajnal, Joseph V., Hill, Derek L.G., Hawkes, David J. (Eds.), 2001. Medical Image Registration, 1st ed. CRC Press. ISBN 9780429114991.
Haskins, Grant, Kruger, Uwe, Yan, Pingkun, 2020. Deep learning in medical image registration: a survey. Machine Vision and Applications 31 (8). https://doi.org/10.1007/s00138-020-01060-x.
Hill, Derek L.G., et al., 2001. Medical image registration. Physics in Medicine and Biology 46 (3), R1–R45. https://doi.org/10.1088/0031-9155/46/3Z201.
Maes, Frederik, et al., 1997. Multimodality image registration by maximization of mutual information. IEEE Transactions on Medical Imaging 16 (2), 187–198. https://doi.org/10.1109/42.563664.
Maintz, J.B. Antoine, Viergever, Max A., 1998. A survey of medical image registration. Medical Image Analysis 2 (1), 1–36. https://doi.org/10.1016/S1361-8415(01)80026-8.
Rueckert, Daniel, et al., 1999. Nonrigid registration using free-form deformations: application to breast MR images. IEEE Transactions on Medical Imaging 18 (8), 712–721. https://doi.org/10.1109/42.796284.
Sotiras, Aristeidis, Davatzikos, Christos, Paragios, Nikos, 2013. Deformable medical image registration: a survey. IEEE Transactions on Medical Imaging 32 (7), 1153–1190. https://doi.org/10.1109/TMI.2013.2265603.
Toga, Arthur (Ed.), 1998. Brain Warping, 1st ed. Academic Press. ISBN 9780126925357. Viergever, Max A., et al., 2016. A survey of medical image registration - under review. Medical Image Analysis 33, 140–144. https://doi.org/10.1016/j.media.2016.06.030.
Wells, William M., et al., 1996. Multi-modal volume registration by maximization of mutual information. Medical Image Analysis 1 (1), 35–51. https://doi.org/10.1016/S1361-8415(01)80004-9.
Yoshida, Toshi, Yuki, Rei, 1966. Japanese Print-Making: A Handbook of Traditional & Modern Techniques, 1st ed. Charles E. Tuttle Company.
Zhang, Hui, 2021. Medical Image Registration Demo. https://github.com/garyhuizhang/MedicalImageRegistrationDemo.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









