







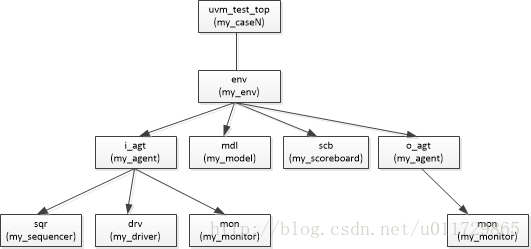
uvm树形结构图
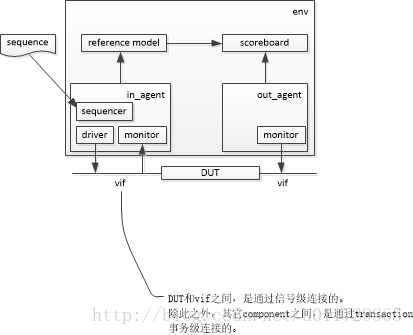
uvm验证平台
uvm启动过程

源代码理解:top_tb.v
`timescale 1ns/1ps
/*
* 1. uvm package. include all uvm classes and macros.
* 2. uvm systemverilog 固定写法。
*/
`include "uvm_macros.svh"
import uvm_pkg::*;
/*
* 1. driver,transaction转为信号,然后驱动DUT;
*/
`include "my_driver.sv"
/*
* 1. interface
* 2. 与module同级
* 3. 在class里,不能直接实例化,需要virtual interface。
* 4. dut相连的components,都是信号级连接;除此之外,UVM其它components都是transaction事务级连接。
*/
`include "my_if.sv"
/*
* 1. dut相连的components,都是信号级连接;除此之外,UVM其它components都是transaction事务级连接。
* 2. transaction继承自uvm_sequence_item
* 3. transaction/driver/sequence/sequencer ?
* - transaction,事务。一般对应的是完成一个请求。transaction相对简单的driver来说,实现了信号的随机和约束。
* - driver,transaction转为信号,然后驱动DUT;(只负责驱动transaction,不负责产生transaction)
* - sequence,负责transaction的调用;(sequence不属于验证平台的任何一部分,但是它负责把transaction送给driver)
* - sequencer,控制sequence的启动,控制sequence与其它component的通信。(sequencer负责产生transaction)
*/
`include "my_transaction.sv"
/*
* 1. env是作为一个容器引入的。目的是把UVM所有component形成特有的UVM树形结构。
* 2. UVM树形结构的意义,是把UVM验证环境通过层次结构的形式连接在一起。
*/
`include "my_env.sv"
/*
* 1. 收集DUT信号,转换为transaction级别,交给reference model或者scoreboard处理。
* 2. 分为i_monitor和o_monitor;区别是检测DUT的输入、输出。
*/
`include "my_monitor.sv"
/*
* 1. 一般来说,一个agent对应一种协议。
* 2. agent是把driver和monitor封装在一起,因为driver和monitor的主体代码近乎相同。
* 3. 另外,因为sequencer与driver的关系非常密切,所以sequencer也在agent里。
*/
`include "my_agent.sv"
/*
* 1. reference model,参考模型,黄金模型。根据DUT功能,验证者提供的一个专用于仿真的模型。
* 2. 一般验证来说,这个model不存在。比如一般验证过程,都是提供driver,通过o_monitor确认验证结果是否符合预期。
* 3. 不过,很多专业验证,都带有BFM或者VIP(验证IP),集成了reference model;可以很方便的确认验证结果。
* 4. 对于我来说,简单的验证,足够了。很少有IP提供了reference model。
*/
`include "my_model.sv"
/*
* 1. 计分板,比较o_monitor和reference_model的数据,给出最终的比较结果。
*/
`include "my_scoreboard.sv"
/*
* 1. sequencer,控制sequence的启动,控制sequence与其它component的通信。
*/
`include "my_sequencer.sv"
/*
* 1. UVM树形结构,增加最顶层的case层;
* 2. 作用一:设置验证平台的超时退出时间;
* 3. 作用二:通过config_db设置验证平台中某些参数的值;
* 4. base_test在每个公司,做的事情各不相同。
* 5. 还没理解透彻。。。。。。。。TODO
*/
`include "base_test.sv"
/*
* 1. 不同测试用例,sequence都是不一样的;所以
* 2. run_test不加参数,利用仿真工具命令参数UVM_TEST_NAME可以不必重新编译验证环境,而仿真不同的case。(这类似于verilog的$test$plusargs和$value$plusargs)
*/
`include "my_case0.sv"
`include "my_case1.sv"
module top_tb;
reg clk;
reg rst_n;
reg [7:0] rxd;
reg rx_dv;
wire [7:0] txd;
wire tx_en;
my_if input_if(clk, rst_n);
my_if output_if(clk, rst_n);
dut my_dut(.clk(clk),
.rst_n(rst_n),
.rxd(input_if.data),
.rx_dv(input_if.valid),
.txd(output_if.data),
.tx_en(output_if.valid));
initial begin
clk = 0;
forever begin
#100 clk = ~clk;
end
end
initial begin
rst_n = 1'b0;
#1000;
rst_n = 1'b1;
end
/*
1. DUT内部是基于时刻的仿真,所以能够probe波形;UVM的验证代码,大多类似与软件,与时间无关,所以不能probe波形。
2. UVM运行,是基于phase。启动是run_test;
- 显式实例化(实例化的名字是固定的,为umv_test_top),及main_phase的调用。
- 如果run_test不加参数,那么UVM会从仿真命令行参数UVM_TEST_NAME去获取,创建该实例,并运行main_phase。
这样的好处是:不同case不需要重新编译仿真环境了。
- 脱离top_tb层次结构的实例,建立了UVM树形结构。
*/
initial begin
run_test();
end
initial begin
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.i_agt.drv", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.i_agt.mon", "vif", input_if);
uvm_config_db#(virtual my_if)::set(null, "uvm_test_top.env.o_agt.mon", "vif", output_if);
end
endmodule















 2244
2244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









