







关于 YOLACT,目前中文互联网上的资料多数是对论文的总结。YOLACT 的源代码已经公开,下文是我在阅读之后对这个模型的理解。希望对大家——尤其是像我一样初涉图像领域的新手——有所裨益。由于个人水平有限,加上代码也没有全部看完,若有错漏,还请多多指正。
YOLACT: Real-time Instance Segmentation
首先分析一下论文题目。
- YOLACT:You Only Look At CoefficienTs 的简写,其中 coefficients 是这个模型的输出之一,这个命名风格应是致敬了另一目标检测模型 YOLO;
- Real-time:根据评估,当 YOLACT 处理 550*550 大小的图片时,其速度达到了 33FPS,而互联网上多数视频一般是 30FPS 的,这也就是实时的含义了;
- Instance segmentation:实例分割是一个目前很难的领域。在 semanitc segmentation 语义分割中,模型只需要判断每一个像素属于哪一类。而在实例分割中,模型还需要在此基础上分割出每一个实例。例如若图像中有两个人站在一块,实例分割模型不仅要判断出这是人,还要确定这两个人各自的轮廓。
主要贡献
这篇论文的主要贡献一是在 MS COCO 数据集上做出了第一个实时的实例分割模型;二是对模型的各种表现进行了评估;此外还提出了比 NMS 算法更快的 Fast NMS;最后是将代码开源了,源代码 https://github.com/dbolya/yolact 。其效果样例图如下:


YOLACT 为了保证速度,设计了两个分支网络,并行地进行以下操作:
- Prediction Head 分支生成各候选框的类别 confidence、anchor 的 location 和 prototype mask 的 coefficient;
- Protonet 为每张图片生成 k 个 prototype mask。在代码中 k = 32。Prototype mask 和 coefficients 的数量相等。
Prototype 意为“原型”。COCO 数据集共有 81 类物体,但每张图片只有 32 个 prototype mask,图片中无论什么类型的实例都可以通过这些 prototype mask 与 coefficient 相乘获得其自己的 mask。这就是“原型”的含义。
YOLACT 是一个 one-stage 模型,这类模型相比于 two-stage 模型往往更快,但效果稍差。较为典型的 two-stage 模型是 Faster R-CNN。我推荐这篇文章及其中的代码:https://zhuanlan.zhihu.com/p/32404424
彻底理解 Faster R-CNN 的代码后,应该能掌握 anchor、proposal 和 RoI等重要概念。
YOLACT 的框架图如下:

下面以源代码默认的 550*550 大小输入为例,分模块解读。
预处理
预处理左下方绿色的原图。论文使用了 MS COCO 数据集,这个数据集的内容非常多。预处理步骤包括将图片调整到合适的大小、转换 bbox 坐标和转换 mask 矩阵等。
Backbone
预处理后的图片输入进 backbone 网络,论文中使用了 ResNet101,源代码中作者还实现了 ResNet50 和 DarkNet53。ResNet 的网络结构如下图:

可以看出它的卷积模块有五个,分别是 conv1、conv_2x 到 conv5x,这五个模块的输出分别对应上图的 C1 到 C5。和 SSD 模型相似,YOLACT 也采用了多个尺度的特征图。这样做的好处之一就是可以检测到不同尺度的物体,也就是在大特征图上检测小物体,在小特征图上检测大物体。下图可以很好地说明这一点:

8*8 的特征图相当于将原图分为 64 份,这样每个 anchor 比较小,而 4*4 的则相反。
FPN
橙色的 P3-P7 是 FPN 网络。这个网络的生成是由 C5 经过一个卷积层得到 P5 开始的。接下来,对 P5 进行一次双线性插值将其放大,与经过卷积的 C4 相加得到 P4,同样的方法得到 P3。此外,还对 P5 进行了卷积得到 P6,对 P6 进行卷积得到 P7。
论文中解释了使用 FPN 的原因:作者注意到更深层的特征图能生成更鲁棒的 mask,而更大的 prototype mask 能确保最终的 mask 质量更高且更好地检测到小物体。又想特征深,又想特征图大,那就得使用 FPN 了。
接下来是并行的操作。P3 被送入 Protonet,P3-P7 也被同时送到 Prediction Head 中。
Protonet

Protonet 的设计是受到了 Mask R-CNN 的启发,它由若干卷积层组成。其输入是 P3,其输出的 mask 维度是 138*138*32,即 32 个 prototype mask,每个大小是 138*138。
Prediction Head

这个分支的输入是 P3-P7 共五个特征图,Prediction Head 也有五个共享参数的预测层与之一一对应。
输入的特征图先生成 anchor。每个像素点生成 3 个 anchor,比例是 1:1、1:2 和 2:1。五个特征图的 anchor 基本边长分别是 24、48、96、192 和 384。基本边长根据不同比例进行调整,确保 anchor 的面积相等。
为了便于理解,接下来以 P3 为例,标记它的维度为 W3*H3*256,那么它的 anchor 数就是 a3 = W3*H3*3。接下来 Prediction Head 为其生成三类输出:
- 类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a3*81;
- 位置偏移,维度为 a3*4;
- mask coefficient,维度为 a3*32。
对 P4-P7 进行的操作是相同的,最后将这些结果拼接起来,标记 a = a3 + a4 + a5 + a6 + a7,得到:
- 全部类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a*81;
- 全部位置偏移,维度为 a*4;
- 全部 mask coefficient,维度为 a*32。
Fast NMS
在得到位置偏移后,可以通过 anchor 的位置加上位置偏移得到 RoI 位置。RoI 存在重叠,NMS 是常用的筛选算法。在这里解读一下论文新提出的 Fast NMS。
同样地,为了便于理解,下面依旧举例说明。假设我们有 5 个 RoI,对于 person 这一类,按照置信度由高到低分别是 b1、b2、b3、b4 和 b5。接下来通过矩阵运算得出它们彼此之间的 IoU,假设结果如下:
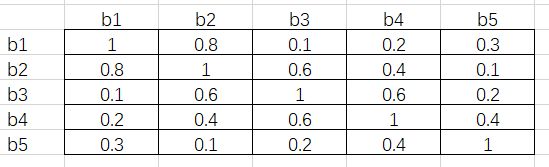
接下来将这个矩阵的下三角和对角线元素删去,得到下面的结果:
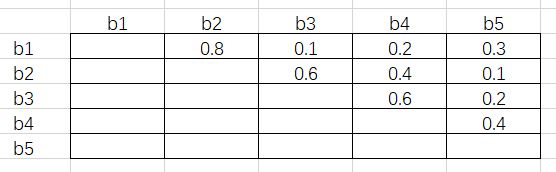
这其中的每一个元素都满足行号小于列号。接下来对每一列取最大值,得到 [-, 0.8, 0.6, 0.6, 0.4]。假设阈值为 0. 5,即 IoU 超过 0.5 的两个 RoI 需要舍弃掉置信度低的那一个。根据最大值,b2、b3 和 b4 对应的列都超出了阈值,所以这三个 RoI 会在这一步舍去。
这样做的原因是,由于每一个元素都是行号小于列号,而序号又是按照置信度从高到低降序排列的,因此任一元素大于阈值,代表着这一列对应的 RoI 与一个比它置信度高的 RoI 过于重叠了,需要将它舍去。
这里需要注意的是,b3 虽然和 b2 过于重叠(IoU 为 0.6),但 b3 与 b1 的 IoU 只有 0.1,而 b2 与 b1 的 IoU 为 0.8。按照传统 NMS 算法,b2 会在第一轮循环中被舍去,这样 b3 将会被保留。这也是 Fast NMS 与 NMS 不同的地方,即原文所述:
..., we simply allow already-removed detections to suppress other detections, which is not possible in traditional NMS.
Crop 和 Threshold
将 mask coefficient 和 prototype mask 做矩阵乘法,就得到了图像中的一个个 mask。Crop 指的是将边界外的 mask 清零,训练阶段的边界是 ground truth bounding box,评估阶段的边界是预测的 bounding box。
Threshold 指的是以 0.5 为阈值对生成的 mask 进行二值化。
Loss
论文中讲到的 loss 分三类:
- 类别置信度的 loss,使用 smooth L1;
- 位置偏移的 loss,也使用 smooth L1;
- mask loss,使用的是 pixel-wise 的二分类交叉熵。
其中 mask loss 在计算时,因为 mask 的大小是 138*138,需要先将原图的 mask 数据通过双线性插值缩小到这一尺寸。
除了上面的三个 loss,源代码中还多了 prototype loss、coefficient diversity loss、class existence loss 和 semantic segmentation loss。这些我就没有细看了。
以上就是全部内容了,论文中还有很多内容没有讲到,不过我觉得对于理解这个模型的原理和实现已经足够了。如果有疑问可以留言。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









