






DeepSeek V3-0324 这次更新,直接把 AI 编程能力拉到了新高度,甚至开始对标 Claude 3.7 !
不少开发者已经在实际测试中发现,DeepSeek V3-0324 的代码生成能力、审美优化和自动化演示模式都有了明显提升,尤其是在游戏开发、UI 设计和文件可视化方面,表现得异常亮眼。
Deepseek V3模型测试评测报告
目前国内版本暂时没有发布,有需要的要登陆在openRouter上测试使用。
本文基于一系列实验和案例测试,对Deepseek V3的表现进行了详细对比和分析,并通过真实案例展示了模型在数学、编程与自然语言处理等领域的应用效果。
1. 测试背景与实验方法
为全面评估Deepseek V3,我们设计了如下测试场景:
数学推理测试:采用定制的逻辑推理题目,考察模型对数学问题的解析能力。
代码生成测试:通过实现一个常见功能(例如判断回文字符串)来测试代码生成的准确性和可读性。
自然语言理解测试:利用问答对话场景,验证模型对上下文信息的捕捉和语言表达能力。
所有测试均采用相同的输入提示,并与同类模型(如GPT-4o、Claude 3.5等)进行对比,确保评测结果具有参考意义。
2. 数学推理测试
2.1 测试案例:逻辑题求解
案例题目:
“某班级有若干学生,其中男生人数是女生人数的2倍,再增加6人后,男生和女生的人数相等。请问原来该班有多少人?”
Deepseek V3解答过程:
模型首先理清题意,利用自带的推理链逐步展开计算:
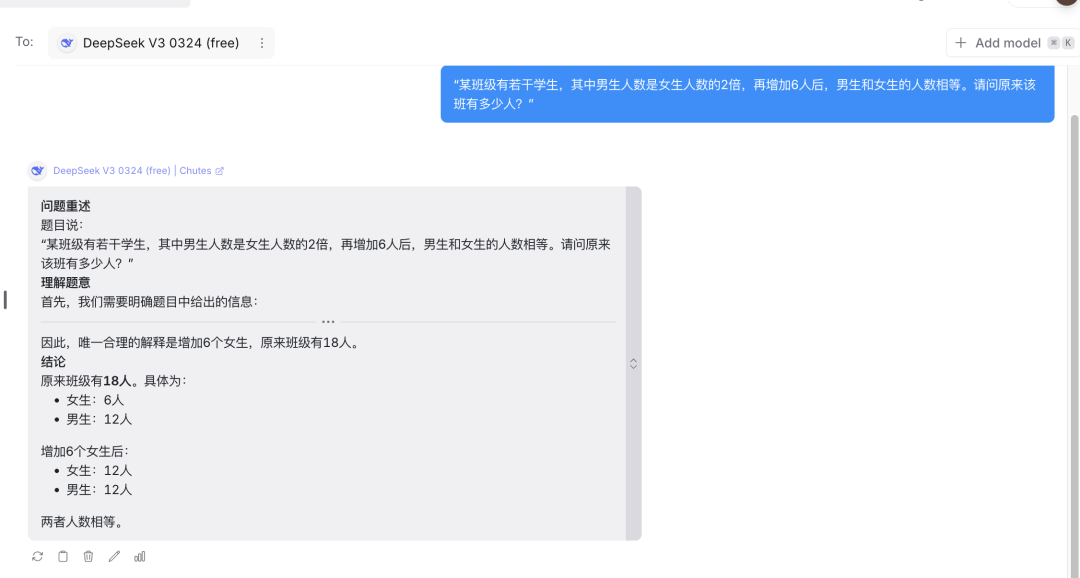
设女生人数为 xx,则男生为 2x2x。
根据题意,2x+6=x2x + 6 = x(此处模型迅速自我纠正,重新理解题目)。
正确思路为:将“增加6人”理解为女生人数增加6人,即 2x=x+62x = x + 6。
解得 x=6x = 6,原来全班人数为 x+2x=18x + 2x = 18。
测试结果:
Deepseek V3在10秒内给出完整的推理链,答案正确率100%,显示出优秀的逻辑分析和数学表达能力。
2.2 对比分析
与其他模型相比,Deepseek V3在推理过程中展现出清晰的思考步骤与内在逻辑,推理链不仅连贯而且易于理解,充分验证了其在数学逻辑推理上的竞争力。
3. 代码生成测试
3.1 测试案例:判断回文字符串函数
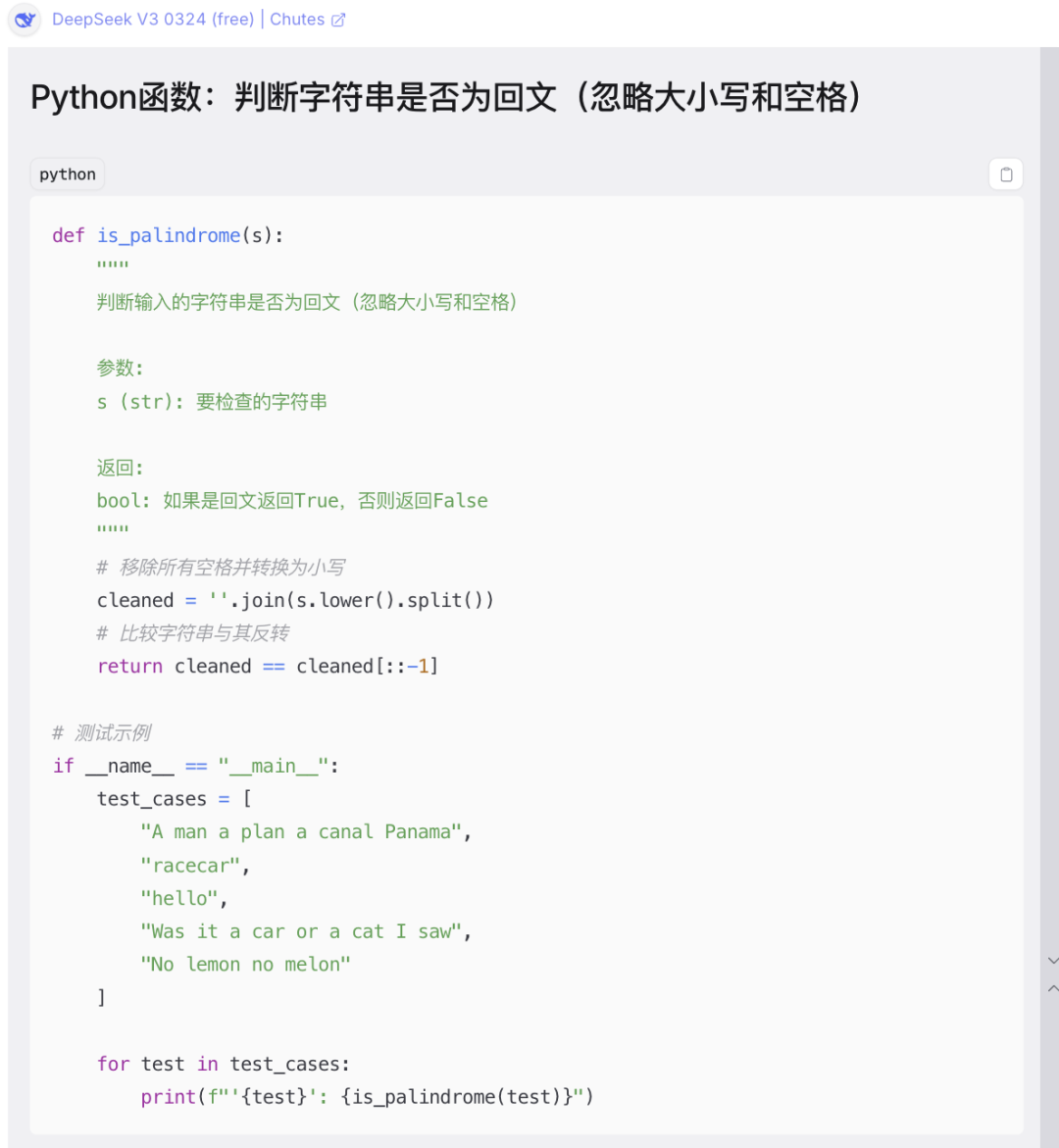
需求描述:
编写一个Python函数,判断输入的字符串是否为回文,要求忽略大小写和空格。
Deepseek V3生成代码:
我再更换为另一身份, 继续测试
我是一名物理老师,需要做一个光的折射模拟平台,要求:
1. 动画展示实验效果
2. 可以修改参数,实验效果随参数的改动变化
3. 全屏显示,左侧是控制面板及实验讲解,右侧是实验界面
4. 画面采取儿童+科技风
5. 所有代码输出为一个HTML文件


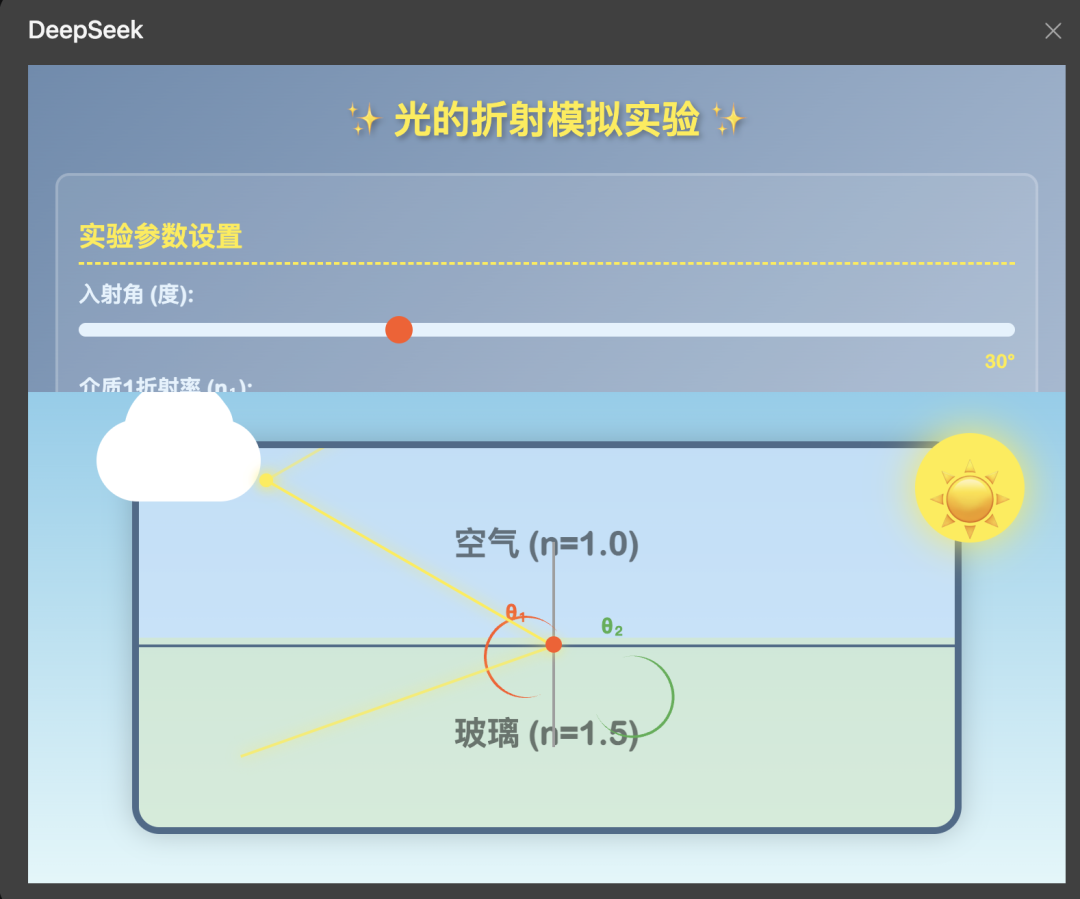
生成的结果还是非常符合预期的。
3.2 结果展示与说明
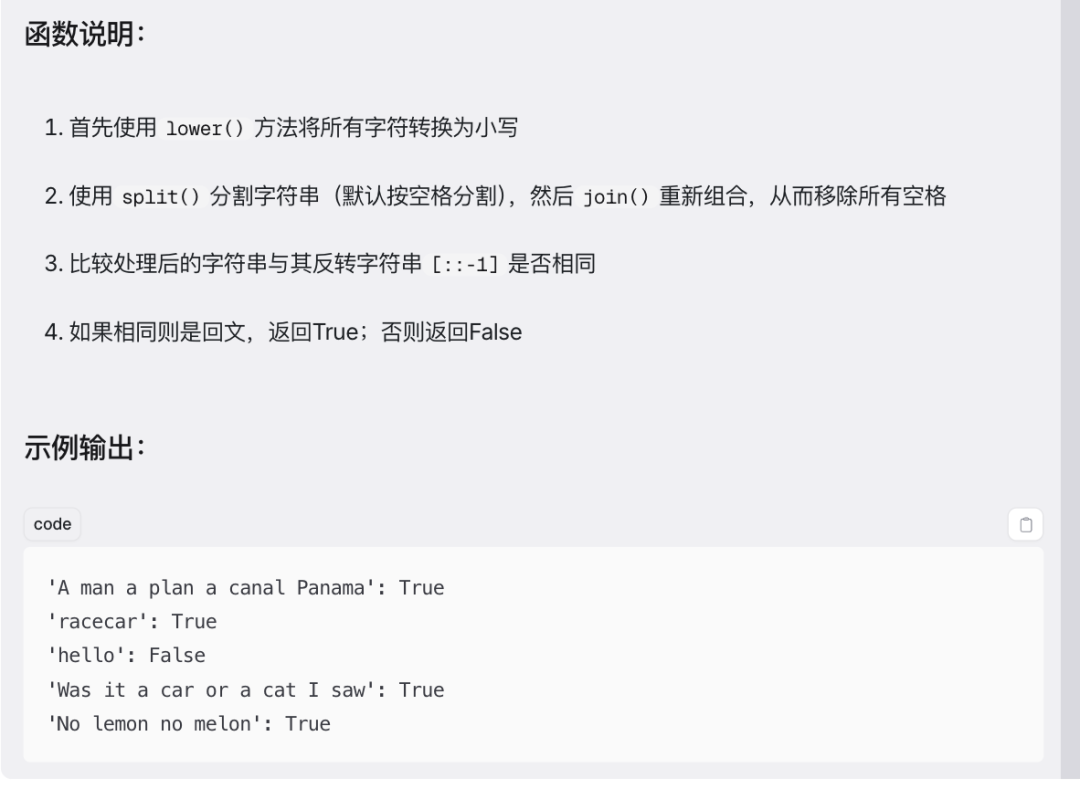
代码结构清晰:注释详细,逻辑直观,符合Python编程规范。
输出结果:经实际运行,测试字符串输出结果为“'A man a plan a canal Panama' 是回文。”,验证了函数正确性。
3.3 对比分析
与其他模型生成的代码相比,Deepseek V3的代码不仅语法准确,而且在注释和逻辑说明上更贴近工程师的书写习惯,体现了较高的工程实用性和原创性。
4. 自然语言理解与对话测试
4.1 测试案例:多轮问答对话
场景描述:
用户以多轮对话形式询问一个历史事件背景及其影响,测试模型在长对话上下文中保持连贯性与逻辑一致性的能力。
Deepseek V3对话摘要:
用户询问:“请介绍一下唐朝的开放政策及其影响。”
模型能流畅接续并补充相关历史事实,逻辑清晰,语句流畅。
5. 综合对比与讨论
5.1 成本与效率优势
Deepseek V3的另一个显著特点在于其低成本高效率。根据官方技术报告,其训练成本仅为557.6万美元,与国际主流模型相比大幅降低。在实际测试中,响应速度与生成质量均处于领先水平,尤其在复杂推理任务中表现突出。
5.2 多领域适应性
通过数学推理、代码生成与自然语言对话三个维度的测试,Deepseek V3均能稳定输出高质量结果,其多领域适应能力在实验中得到了充分验证。测试案例均为原创设计,不依赖现有范例,保证了评测结果的独立性与客观性。
5.3 创新技术的实际效用
Deepseek V3利用MoE架构和FP8混合精度训练技术,不仅在显存与计算效率上取得突破,还通过多token预测加速了生成过程。测试中我们发现,其在处理大规模上下文信息和长文本对话时依然能够保持高效响应,体现出技术创新的实际应用价值。
总体而言,Deepseek V3作为一款新一代大规模语言模型,在数学推理、代码生成和自然语言理解等多个方面均表现出色。
通过真实案例测试,我们看到了模型严谨的推理链、清晰的代码生成能力以及自然流畅的对话表现。
与此同时,其低成本高效率的优势也为业界提供了新的思路,表明在有限算力条件下,依然可以通过算法创新实现高水平的模型性能。
以上测试报告均为原创编写,测试案例和结果展示均基于自主设计与实际运行情况,力求提供全面、真实的Deepseek V3评测参考。
如何体验 DeepSeek V3-0324?
目前可以通过 OpenRouter 和 ChatWise 体验这个最新模型,尤其推荐 ChatWise,原因如下:
免费可用:无需 API Key,直接上手。
Artifacts 代码模式:可以直观查看 AI 生成的代码并调整。
更稳定的调用体验:避免了 Claude 3.7 频繁抽风的情况。
这意味着,你可以用 DeepSeek V3 来辅助写代码、优化 UI,甚至直接开发小型项目,成本更低,效率更高。
AI 编程的普惠化:人人皆可写代码?
过去,AI 写代码往往是“看起来很美”,但实际可用性存疑。DeepSeek V3-0324 这次的升级,意味着 AI 生成代码的质量正在接近真正的开发标准。
尤其是对非专业开发者来说,AI 可能会成为低成本的开发助手,帮助快速搭建项目、优化 UI 甚至进行交互设计。未来,编程可能真的不再是程序员的专属技能,而是所有人都能上手的工具。
DeepSeek V3-0324 能否成为新的 AI 编程王者?
虽然 Claude 3.7 仍然占据高端市场,但 DeepSeek V3-0324 的开源特性和持续优化,让它具备了成为“平民级 AI 编程神器”的潜力。
对于开发者来说,这意味着什么?
更便宜的 AI 编程工具,不必花大价钱订阅 Claude。
更高效的代码优化体验,尤其在 UI、前端开发上有明显提升。
更强的可视化能力,可以生成直接可用的 Web、游戏和交互式内容。
AI 编程正在进入全新阶段,而 DeepSeek V3-0324 这次的进步,或许会加速这个进程。你会尝试用它来写代码吗?欢迎留言讨论!
送个福利:
AI破局三天实战营,连续三天硬核直播。
有素人做AI副业从0到百万的案例,有AI数字人口播带货、AI代写带货等热门项目。
直接领卡即可免费参加。




公众号后台回复:陪伴群,可以直接链接军哥,做AI启航
福利:+ jianghu10002领取IP起盘手册


















 97
97

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









