






代码:https://github.com/cure-lab/LTSF-Linear

主要提出了DLinear、NLinear,都是不太复杂的线性模型,但是效果却能在很多情况下比transformer好很多。
摘要
Transformers可以说是提取长序列中元素之间语义相关性的最成功的解决方案。然而,在时间序列建模中,我们要提取一组有序连续点中的时间关系。虽然使用位置编码和使用Token在Transformer中嵌入子序列有助于保留一些排序信息,但置换无效的自我注意机制的性质不可避免地会导致时间信息丢失。
为了验证我们的说法,我们引入了一组令人尴尬的简单单层线性模型,名为LTSF-Linear,用于比较。在九个真实数据集上的实验结果表明,LTSF-Linear在所有情况下都出乎意料地优于现有的基于Transformer的LTSF模型,而且通常有很大的优势。
Introduction
在过去的几十年里,时间序列预测解决方案经历了从传统统计方法(如ARIMA(Ariyo,Adewumi和Ayo 2014)和机器学习技术(如GBRT(Friedman 2001))到基于深度学习的解决方案(Bai,Kolter和Koltun 2018;Liu等人2022)的发展。
基于Transformer的时间序列分析解决方案也激增。最著名的模型侧重于探索较少且具有挑战性的长期时间序列预测(LTSF)问题,包括LogTrans(Li等人,2019年)(NeurIPS 2019年)、Informer(Zhou等人,2021年)(AAAI 2021最佳论文)、Autoformer(Xu等人,2021)(NeurIPS 2021年)、Pyraformer(Liu等人,2021a)(ICLR 2022 Oral)、Triformer(Cirstea等人,2022年)(IJCAI 2022年)和最近的FEDformer(Zhou等,2022)(ICML 2022年)。
Transformers的主要工作动力来自其多头自注意机制,该机制具有提取长序列中元素(例如文本中的单词或图像中的2D补丁)之间语义相关性的显著能力。然而,自注意在某种程度上是排列不变的和“反序的”。虽然使用各种类型的位置编码技术可以保留一些排序信息,但在它们之上应用自注意后,仍然不可避免地会丢失时间信息。对于语义丰富的应用程序(如NLP)来说,这通常不是一个严重的问题,例如,即使我们对句子中的一些单词进行重新排序,句子的语义也会在很大程度上得到保留。然而,在分析时间序列数据时,数值数据本身通常缺乏语义,我们主要感兴趣的是对一组连续点之间的时间变化进行建模。也就是说,秩序本身起着最关键的作用。
Transformer-based方法往往比较的baseline是自回归的预测方法,这种方法由于误差累积,长期预测能力通常较差。
不是所有时间序列可以预测,更不用说长期预测,假设长期预测仅适用于那些具有相对清晰趋势和周期性的时间序列。由于线性模型已经可以提取这些信息,我们引入了一组名为LTSF-Linear的简单模型作为比较的新基线。LTSF-Linear使用单层线性模型对历史时间序列进行回归,直接预测未来时间序列。结果表明,LTSF-Linear在所有情况下都优于现有的复杂基于Transformer-based的模型,而且通常有很大的优势(20%~50%)。
此外,与现有Transformer中的说法相反,它们中的大多数都无法从长序列中提取时间关系,即预测误差不会随着回顾窗口大小的增加而减少(有时甚至增加)。
论文贡献
To the best of our knowledge, this is the first work to challenge the effectiveness of the booming Transformers for the long-term time series forecasting task.
第一项挑战蓬勃发展的Transformer在长期时间序列预测任务中的有效性的工作。
To validate our claims, we introduce a set of embarrassingly simple one-layer linear models, named LTSFLinear, and compare them with existing Transformerbased LTSF solutions on nine benchmarks. LTSF-Linear can be a new baseline for the LTSF problem.
引入了一组简单得令人尴尬的单层线性模型,名为LTSF-Llinear,并在九个基准测试中将其与现有的基于Transformer的LTSF解决方案进行了比较。LTSF线性可以作为LTSF问题的新baseline。
We conduct comprehensive empirical studies on various aspects of existing Transformer-based solutions, including the capability of modeling long inputs, the sensitivity to time series order, the impact of positional encoding and sub-series embedding, and efficiency comparisons. Our findings would benefit future research in this area.
我们对现有基于Transformer的解决方案的各个方面进行了全面的实证研究,包括建模长输入的能力、对时间序列顺序的敏感性、位置编码和子序列嵌入的影响以及效率比较。我们的发现将有助于该领域的未来研究。
时序预测问题
对于含有个变量的时间序列,根据历史数据
预测未来数据
。 其 中
和
分 别 为 历 史 时 间 序 列 长 度 和 未 来 时 间 序 列 长 度 。
表 示 第
个 时 间 步 第
个 变 量 的 值 。
当 时,可以通过迭代单步预测来获得多步预测,也可以直接优化多步预测目标,前者称为iterated multi-step (IMS) forecasting,后者称为direct multi-step (DMS) forecasting。IMS会受到误差累积的影响。
当存在高度精确的单步预测器并且相对较小时,IMS(iterated multi-step)预测是优选的。相比之下,当难以获得无偏的单步预测模型或
较大时,DMS(direct multistep)预测会产生更准确的预测。
Transformer-based 模型
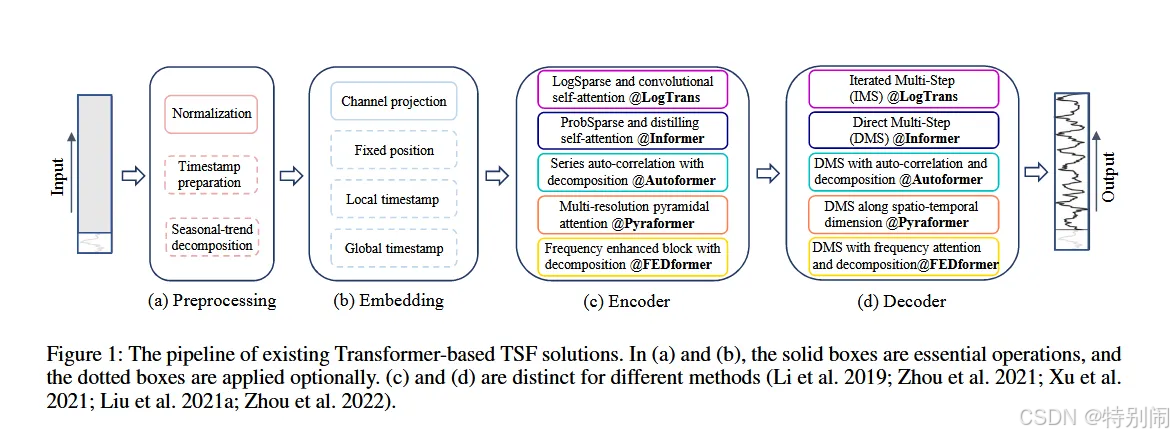
时间序列分解
数据预处理:零均值归一化
Autoformer(Xu等人,2021)首先在每个神经块后面应用季节趋势分解,这是时间序列分析中的一种标准方法,可以使原始数据更具可预测性。他们在输入序列上使用移动平均核来提取时间序列的趋势周期分量。原始序列和趋势分量之间的差异被视为季节分量。
在Autoformer的分解方案之上,FEDformer(Zhou等人,2022)进一步提出了混合专家策略,将移动平均核提取的趋势分量与各种核大小混合在一起。
输入嵌入策略
自注意力层无法保留时间序列的位置信息。然而,本地位置信息,即时间序列的排序,很重要。而且,全局时间信息,如分层时间戳(周、月、年)和不可知时间戳(假期和事件),也是有信息量的。
为了增强时间序列输入的时间上下文,基于SOTA Transformer的方法中的一种实用设计是在输入序列中注入几个嵌入,如固定位置编码、通道投影嵌入和可学习的时间嵌入。此外,引入了具有时间卷积层(Li等人,2019)或可学习时间戳(Xu等人,2021)的时间嵌入。
自注意力策略
最近的工作提出了两种提高效率的策略。
一方面,LogTrans和Pyraformer在自注意方案中明确引入了稀疏偏差。具体来说,LogTrans使用Logsparse掩码将计算复杂度降低到O(LlogL),而Pyraformer采用金字塔注意力,以O(L)的时间和内存复杂度捕获分层多尺度时间依赖关系。
另一方面,Informer和FEDformer利用自注意矩阵中的低秩特性。Informer提出了ProbSparse自注意机制和自注意提取操作,将复杂度降低到O(LlogL),FEDformer设计了一个傅里叶增强块和一个随机选择的小波增强块,以获得O(L)复杂度。
最后,Autoformer设计了一个系列自相关机制来取代原有的自注意力层。
解码器Decoder
vanilla Transformer解码器以自回归方式输出序列,导致推理速度慢和误差累积效应,特别是对于长期预测。Informer为DMS预测设计了一个生成式解码器。其他Transformer变体采用类似的DMS策略。例如,Pyraformer使用连接时空轴的全连接层作为解码器。Autoformer从趋势周期分量和季节分量的堆叠自相关机制中总结出两个精细的分解特征,以获得最终的预测。FEDformer还使用具有所提出的频率注意块的分解方案来解码最终结果。
Transformer模型的前提是成对元素之间的语义相关性,而自注意机制本身是置换不变的,其建模时间关系的能力在很大程度上取决于与输入标记相关的位置编码。考虑到时间序列中的原始数值数据(例如股票价格或电力价值),它们之间几乎没有任何逐点的语义相关性。
在时间序列建模中,我们主要关注一组连续点之间的时间关系,这些元素的顺序而不是成对关系起着最关键的作用。
虽然采用位置编码和使用Token嵌入子序列有助于保留一些排序信息,但置换不变自注意机制的性质不可避免地导致时间信息丢失
LSTF-Linear
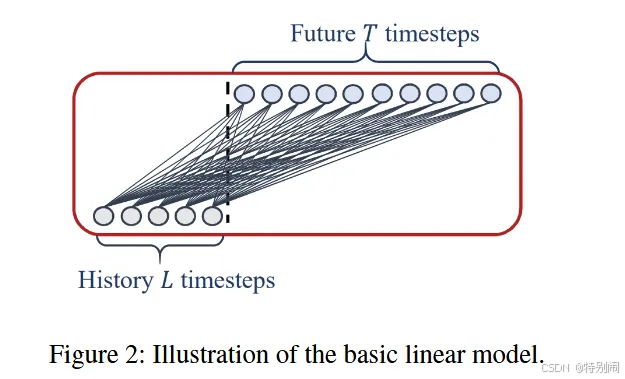
基础的线性模型,LTSF-Linear的基本公式通过加权求和运算直接回归历史时间序列以进行未来预测,LTSF-Linear在不同变量之间共享权重,并且不模拟任何空间相关性。
LTSF-Linear是一组线性模型。Vanilla Linear是一个单层线性模型。为了处理不同领域(如金融、交通和能源领域)的时间序列,我们进一步引入了两种具有两种预处理方法的变体,分别命名为DLlinear和NLlinear。
DLinear
具体来说,DLlinear是Autoformer和FEDformer中使用的分解方案与线性层的组合。它首先通过移动平均核和残差(季节性)分量将原始数据输入分解为趋势分量。然后,将两个单层线性层应用于每个组件,并将这两个特征相加以获得最终预测。DLlinear在数据中存在明显趋势时提高了vanilla linear的性能。
NLinear
为了在数据集中存在分布偏移时提高LTSF-Linear的性能,NLlinear首先将输入减去序列的最后一个值。然后,输入通过一个线性层,在做出最终预测之前,将减去的部分加回去。NLinear中的减法和加法是输入序列的简单归一化。
实验
咕咕咕……后面再补
反正当时算是sota了
# 有空再更新(
参考资料
长时间预测模型DLinear、NLinear模型(论文解读)-CSDN博客

















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









