










Ref
VLLM paged attention和prefix cache:
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | vLLM Blog
Automatic Prefix Caching — vLLM
续接
KV cache block管理
KV cache管理核心逻辑在vllm.v1.core.kv_cache_manager.KVCacheManager。
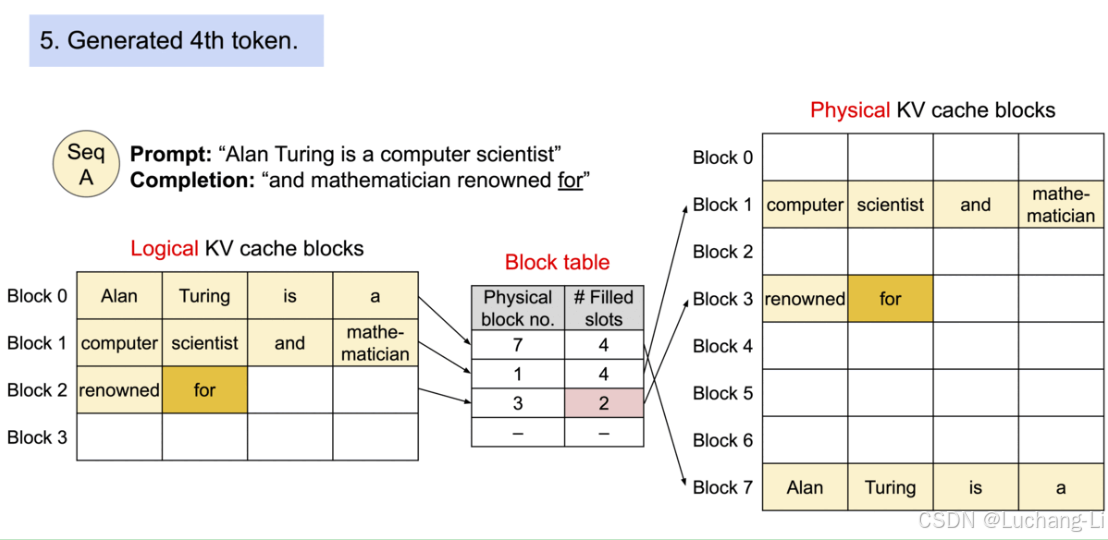
首先需要参考上面引用部分,明白paged attention管理kv cache的方式:
VLLM采用block的方式来管理kv cache,也就是连续block size个token使用一个连续的kv cache内存块。但是不同的block在内存中可能是不连续的。
如下图所示,VLLM会一次性根据GPU内存分配num_gpu_blocks个kv cache block在一个大内存块,作为kv cache pool。然后采用字典来管理每个block token的hash与对应的kv cache内存的映射。
KV block hash
prefix cache根据prompt token拆分为block后每个block的hash值来匹配之前计算过的kv cache从而进行复用。
每个block的hash函数的输入为3个部分:1是Parent hash value,也就是这个block之前所有token的hash值,因为当前block的hash不仅与这个block有关,还与之前token有关。2是当前block的token本身。3是Extra hashes,例如lora id或者多模态的输入。
hash计算主要代码逻辑:
def hash_request_tokens(block_size: int, request: Request) -> List[BlockHashType]:
"""Computes hash values of a chain of blocks given a sequence of
token IDs. The hash value is used for prefix caching.
"""
token_ids = request.all_token_ids
ret = []
parent_block_hash_value = None
for start in range(0, len(token_ids), block_size):
end = start + block_size
block_token_ids = token_ids[start:end]
# Add extra keys if the block is a multi-modal block.
if need_extra_keys:
extra_keys, curr_mm_idx = generate_block_hash_extra_keys(request, start, end, curr_mm_idx)
block_hash = hash_block_tokens(parent_block_hash_value, block_token_ids, extra_keys)
ret.append(block_hash)
parent_block_hash_value = block_hash.hash_value
return ret
KV block管理
KVCacheBlock和KVCacheManager数据结构(精简版):
@dataclass
class KVCacheBlock:
"""KV-cache block metadata."""
# Block ID, ranging from 0 to num_gpu_blocks - 1.
block_id: int
# Reference count.
ref_cnt: int = 0
# The hash of the block composed of (block hash, tuple of token IDs).
# It is only available when the block is full.
_block_hash: Optional[BlockHashType] = None
# Used to construct a doubly linked list for free blocks.
# These two attributes should only be manipulated by FreeKVCacheBlockQueue.
prev_free_block: Optional["KVCacheBlock"] = None
next_free_block: Optional["KVCacheBlock"] = None
prev_free_block和next_free_block用于指向前一个和后一个free cache block,用于KVCacheManager的双向链表FreeKVCacheBlockQueue对象free_block_queue。
class KVCacheManager:
def __init__(self, block_size: int, num_gpu_blocks: int, max_model_len: int,
sliding_window: Optional[int] = None, enable_caching: bool = True, num_preallocate_tokens: int = 64) -> None:
self.block_size = block_size
self.num_gpu_blocks = num_gpu_blocks
self.max_model_len = max_model_len
self.max_num_blocks_per_req = cdiv(max_model_len, block_size)
self.sliding_window = sliding_window
self.enable_caching = enable_caching
# NOTE(woosuk): To avoid frequent block allocation, we preallocate some blocks for each request.
# For example, when a request reaches the end of its block table, we preallocate N blocks in advance.
# This way, we reduce the overhead of updating free_block_ids and ref_cnts for each request every step (at the cost of some memory waste).
# After the request gets N empty blocks, it starts to use the blocks without
# further allocation. When it uses up all the N empty blocks, it gets N new empty blocks.
self.num_preallocate_tokens = num_preallocate_tokens
self.num_preallocate_blocks = cdiv(num_preallocate_tokens, block_size)
# A Block pool of all kv-cache blocks.
self.block_pool: List[KVCacheBlock] = [KVCacheBlock(idx) for idx in range(num_gpu_blocks)]
# Free block queue that constructs and manipulates a doubly linked
# list of free blocks (including eviction candidates when caching is enabled).
self.free_block_queue = FreeKVCacheBlockQueue(self.block_pool)
# {block_hash: {block ID: block}}.
# A cached block is a full block with a block hash that can be used for prefix caching.
# The cached block may be used by running requests or in the free_block_queue that could potentially be evicted.
# NOTE: We currently don't de-duplicate the blocks in the cache, meaning that if a block becomes full and is cached, we don't check
# if there is already an identical block in the cache.
# This is because we want to make sure the allocated block IDs won't change so that block tables are append-only.
self.cached_block_hash_to_block: Dict[BlockHashType, Dict[int, KVCacheBlock]] = defaultdict(dict)
# Mapping from request ID to blocks to track the blocks allocated
# for each request, so that we can free the blocks when the request is finished.
self.req_to_blocks: DefaultDict[str, List[KVCacheBlock]] = defaultdict(list)
最核心的几个部分:
block_pool就是num_gpu_blocks个kv cache block组成的List,因为实际会分配num_gpu_blocks个kv cache块的大内存作为kv cache pool。但是内存分配不在这里管理。这里只根据block id管理,不管理block id实际对应的内存。
free_block_queue: Free block queue that constructs and manipulates a doubly linked list of free blocks (including eviction candidates when caching is enabled).
维护了一个双向链表FreeKVCacheBlockQueue。初始化时根据block_pool构建了一个双向连接的链表。这里面也包含eviction candidates,也就是这里面有一些cache block可能也在下面的cached_block_hash_to_block里面,特点是ref_cnt=0。
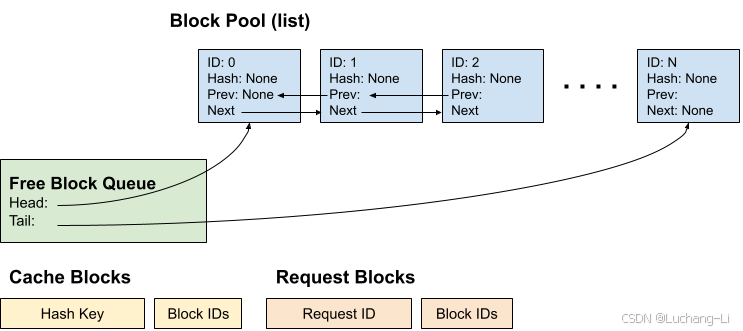
cached_block_hash_to_block存的是{block_hash: {block ID: block}},用于prefix caching.
The cached block may be used by running requests or in the free_block_queue that could potentially be evicted。已缓存的块可能正被运行中的请求所使用,或者位于空闲块队列中,而该队列中的块有可能会被淘汰。
当前没有做查重处理:NOTE: We currently don't de-duplicate the blocks in the cache, meaning that if a block becomes full and is cached, we don't check if there is already an identical block in the cache. This is because we want to make sure the allocated block IDs won't change so that block tables are append-only.
细节参考:
https://docs.vllm.ai/en/latest/design/v1/prefix_caching.html
FreeKVCacheBlockQueue详细介绍
class FreeKVCacheBlockQueue:
def __init__(self, blocks: List[KVCacheBlock]) -> None:
self.num_free_blocks = len(blocks)
# Initialize the doubly linked list of free blocks.
self.free_list_head: Optional[KVCacheBlock] = blocks[0]
self.free_list_tail: Optional[KVCacheBlock] = blocks[-1]
for i in range(self.num_free_blocks):
if i > 0:
blocks[i].prev_free_block = blocks[i - 1]
if i < self.num_free_blocks - 1:
blocks[i].next_free_block = blocks[i + 1]
def popleft(self) -> KVCacheBlock:
"""Pop the first free block and reduce num_free_blocks by 1."""
if not self.free_list_head:
raise ValueError("No free blocks available")
block = self.free_list_head
self.remove(block)
return block
def remove(self, block: KVCacheBlock) -> None:
"""Remove a block in the free list and reduce num_free_blocks by 1."""
if block.prev_free_block is not None:
# Link the previous block to the next block.
block.prev_free_block.next_free_block = block.next_free_block
if block.next_free_block is not None:
# Link the next block to the previous block.
block.next_free_block.prev_free_block = block.prev_free_block
if block == self.free_list_head:
# Update the head if the block is the head.
self.free_list_head = block.next_free_block
if block == self.free_list_tail:
# Update the tail if the block is the tail.
self.free_list_tail = block.prev_free_block
# Remove the block from the linked list.
block.prev_free_block = block.next_free_block = None
self.num_free_blocks -= 1
def append(self, block: KVCacheBlock) -> None:
"""Put a block back into the free list and increase num_free_blocks by 1."""
if self.free_list_tail is not None:
# Link the last block to the new block.
self.free_list_tail.next_free_block = block
block.prev_free_block = self.free_list_tail
self.free_list_tail = block
else:
# The free list is empty.
assert self.free_list_head is None
self.free_list_head = self.free_list_tail = block
block.next_free_block = None
self.num_free_blocks += 1
这个类采用双向链表来管理kv cache block。We implement this class instead of using Python builtin deque to support removing a block in the middle of the queue in O(1) time.
首先初始化时从0:num_free_blocks个kv cache block顺序搭建了一个双向链表,并且free_list_head和free_list_tail分别指向第一个和最后一个。
remove是一个标准的删除双向链表中间任意一个元素的操作。
popleft调用remove删除第一个元素。append则是把输入的block添加到链表末尾。
The queue is ordered by block ID in the beginning.
When a block is allocated and then freed, it will be appended back with the eviction order:
1. The least recent used block is at the front (LRU).
2. If two blocks have the same last accessed time (allocated by the same sequence), the one with more hash tokens (the tail of a block chain) is at the front.
Note that we maintain this order by reversing the block order when free blocks of a request. This operation is outside of this class.
也就是一个request的blocks是按照反方向append到双向链表。因为前面的是最先被使用的。而一个request的blocks越往后cache命中可能性越低,因此应该反方向加入链表。
采用popleft来分配新的block,如果这个block是被cached,那么这个block旧的kv cache就被驱逐了。
KV cache block分配
KVCacheManager是Scheduler的核心成员,在Scheduler.schedule过程中,会使用kv_cache_manager进行kv cache block分配。
对于waiting queue中的新请求:
request = self.waiting[0]
# Get already-cached tokens.
computed_blocks, num_computed_tokens = self.kv_cache_manager.get_computed_blocks(request)
num_new_tokens = request.num_tokens - num_computed_tokens
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens, computed_blocks)
self.waiting.popleft()
self.running.append(request)
-
The scheduler calls
kv_cache_manager.get_computed_blocks()to get a sequence of blocks that have already been computed. This is done by hashing the prompt tokens in the request and looking up Cache Blocks. -
The scheduler calls
kv_cache_manager.allocate_slots(). It does the following steps:-
Compute the number of new required blocks, and return if there are no sufficient blocks to allocate.
-
“Touch” the computed blocks. It increases the reference count of the computed block by one, and removes the block from the free queue if the block wasn’t used by other requests. This is to avoid these computed blocks being evicted. See the example in the next section for illustration.
-
Allocate new blocks by popping the heads of the free queue. If the head block is a cached block, this also “evicts” the block so that no other requests can reuse it anymore from now on.
-
If an allocated block is already full of tokens, we immediately add it to the Cache Block, so that the block can be reused by other requests in the same batch.
-
allocate_slots(request: Request, num_tokens: int, new_computed_blocks: Optional[List[KVCacheBlock]] = None)三个参数,这里第三个computed_blocks是一个List。
对于running的请求:
request = self.running[req_index]
num_new_tokens = request.num_tokens - request.num_computed_tokens
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens)
# if new_blocks is None, Preempt the lowest-priority request from running to waiting
-
The scheduler calls
kv_cache_manager.append_slots(). It does the following steps:-
Compute the number of new required blocks, and return if there are no sufficient blocks to allocate.
-
Allocate new blocks by popping the heads of the free queue. If the head block is a cached block, this also “evicts” the block so that no other requests can reuse it anymore from now on.
-
Append token IDs to the slots in existing blocks as well as the new blocks. If a block is full, we add it to the Cache Block to cache it.
-
实际调用的allocate_slots,与上面区别是这里第三个参数new_computed_blocks是None。
allocate_slots
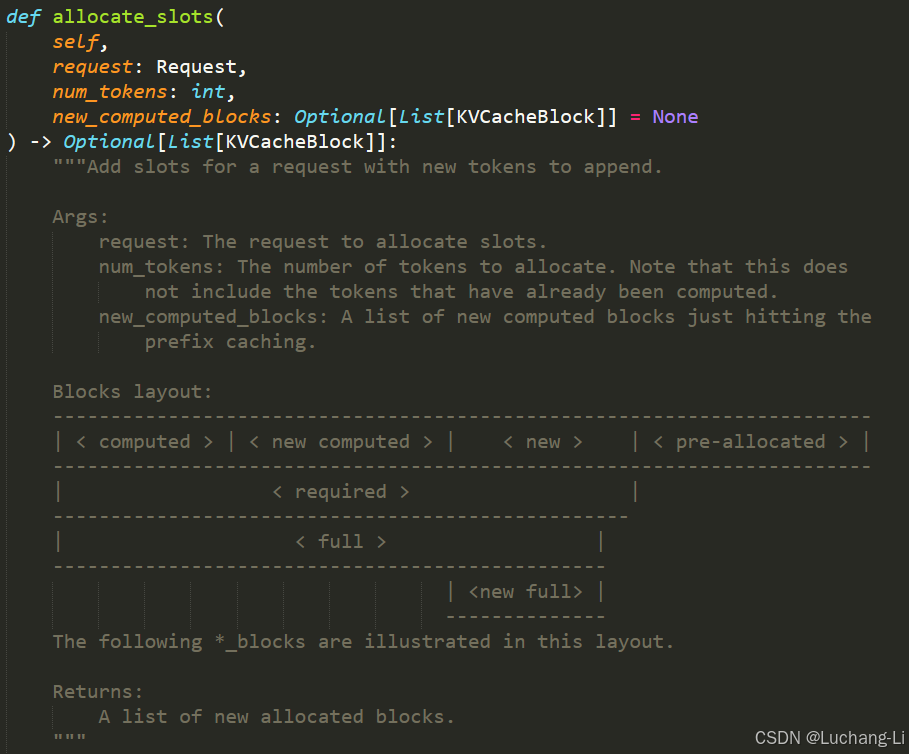
为啥第三个参数名称为new_computed_blocks而不直接是computed_blocks?前面有一段是computed,什么场景下使用?
这个函数的功能流程如下,注意上面图中的block和token排布:
1, Compute the number of new required blocks
# The number of computed tokens is the number of computed tokens plus the new prefix caching hits
num_computed_tokens = (request.num_computed_tokens + len(new_computed_blocks) * self.block_size)
num_required_blocks = cdiv(num_computed_tokens + num_tokens, self.block_size)
req_blocks = self.req_to_blocks[request.request_id]
num_new_blocks = (num_required_blocks - len(req_blocks) - len(new_computed_blocks))
num_new_blocks可能是负数,因为len(req_blocks)可能大于num_required_blocks。
2, return if there are no sufficient blocks to allocate
# If a computed block of a request is an eviction candidate (in the free queue and ref_cnt == 0),
# it cannot be counted as a free block when allocating this request.
num_evictable_computed_blocks = sum(1 for blk in new_computed_blocks if blk.ref_cnt == 0)
if (num_new_blocks > self.free_block_queue.num_free_blocks - num_evictable_computed_blocks):
# Cannot allocate new blocks
return None
对于new_computed_blocks,也就是cached cache blocks,如果ref_cnt==0,意味着在free_block_queue里面,这部分在这个request推理时需要拿出来,因此free_block_queue里面能够实际分配的block数量是free_block_queue的长度减去new_computed_blocks里面evictable的部分。
3, Touch the computed blocks to make sure they won't be evicted.
对于prefix cache的block,引用次数加一,并且从free_block_queue拿出来。
if self.enable_caching:
self._touch(new_computed_blocks)
def _touch(self, blocks: List[KVCacheBlock]) -> None:
"""Touch a block increases its reference count by 1, and may remove
the block from the free queue. This is used when a block is hit by another request with the same prefix.
"""
for block in blocks:
# ref_cnt=0 means this block is in the free list (i.e. eviction candidate), so remove it.
if block.ref_cnt == 0:
self.free_block_queue.remove(block)
block.incr_ref()
4,Allocate new blocks by popping the heads of the free queue. If the head block is a cached block, this also “evicts” the block so that no other requests can reuse it anymore from now on.
# Append the new computed blocks to the request blocks until now to avoid the case where the new blocks cannot be allocated.
req_blocks.extend(new_computed_blocks)
# Start to handle new blocks
if num_new_blocks <= 0:
# No new block is needed.
new_blocks = []
else:
# Get new blocks from the free block pool considering preallocated blocks.
num_new_blocks = min(
num_new_blocks + self.num_preallocate_blocks,
self.free_block_queue.num_free_blocks,
# Should not exceed the maximum number of blocks per request.
# This is especially because the block table has the shape
# [..., max_num_blocks_per_req].
# TODO(woosuk): Check and reject requests if
# num_prompt_tokens + max_tokens > max_model_len.
self.max_num_blocks_per_req - len(req_blocks),
)
assert num_new_blocks > 0
# Concatenate the computed block IDs and the new block IDs.
new_blocks = self._get_new_blocks(num_new_blocks)
req_blocks.extend(new_blocks)
def _get_new_blocks(self, num_blocks: int) -> List[KVCacheBlock]:
"""Get new blocks from the free block pool. Note that we do not check block cache in this function."""
ret: List[KVCacheBlock] = []
idx = 0
while idx < num_blocks:
# First allocate blocks.
curr_block = self.free_block_queue.popleft()
assert curr_block.ref_cnt == 0
# If the block is cached, evict it.
if self.enable_caching:
self._maybe_evict_cached_block(curr_block)
curr_block.incr_ref()
ret.append(curr_block)
idx += 1
return ret可以看到资源充足的情况下,实际分配的block数量是:num_new_blocks + self.num_preallocate_blocks。num_preallocate_blocks默认是64/block_size。
5,If an allocated block is already full of tokens, we immediately add it to the Cache Block, so that the block can be reused by other requests in the same batch.
# NOTE(rickyx): We are assuming the `num_tokens` are actual
# tokens rather than lookahead slots (e.g. for speculative decoding).
# TODO(rickyx): When supporting speculative decoding, we will need to
# differentiate between them so that we can know how many blocks are
# full after appending the actual tokens.
num_full_blocks = (num_computed_tokens + num_tokens) // self.block_size
num_computed_full_blocks = num_computed_tokens // self.block_size
new_full_blocks = req_blocks[num_computed_full_blocks:num_full_blocks]
if new_full_blocks:
# Cache a list of full blocks for prefix caching
self._cache_full_blocks(
request=request,
blk_start_idx=num_computed_full_blocks,
# The new full blocks are the full blocks that are not computed.
full_blocks=new_full_blocks,
prev_block=(req_blocks[num_computed_full_blocks - 1] if num_computed_full_blocks > 0 else None))
参考上面的allocate_slots关于new_full_blocks部分的示意图,这个指新分配的完整的block部分,因为实际token可能不整除block_size。这部分token虽然实际kv cache值还没有算出来,kv block被立即加入cached block从而同一个batch相同prefix能够复用。
KV cache block释放
在一个请求计算完成后,Scheduler会调用kv_cache_manager.free(request)释放request kv cache,引用次数减1,按照请求反方向添加到free_block_queue里面。但是这部分仍然是在prefix cache字典里面的。如果后续请求占用这些cached block作为新的block,那么旧的cache被evict.
def free(self, request: Request) -> None:
"""Free the blocks allocated for the request.
When caching is enabled, we free the blocks in reverse order so that
the tail blocks are evicted first."""
# Default to [] in case a request is freed (aborted) before alloc.
blocks = self.req_to_blocks.pop(request.request_id, [])
ordered_blocks: Iterable[KVCacheBlock] = blocks
if self.enable_caching:
# Free blocks in reverse order so that the tail blocks are freed first.
ordered_blocks = reversed(blocks)
for block in ordered_blocks:
block.decr_ref()
if block.ref_cnt == 0:
self.free_block_queue.append(block)
KV cache物理内存分配
Scheduler和KVCacheManager只负责管理和分配kv cache的id,对应的KV cache物理内存分配和使用在GPUModelRunner进行管理。
EngineCore._initialize_kv_caches
def _initialize_kv_caches(self, vllm_config: VllmConfig) -> Tuple[int, int]:
# Get all kv cache needed by the model
kv_cache_spec = self.model_executor.get_kv_cache_spec()
# Profiles the peak memory usage of the model to determine how much
# memory can be allocated for kv cache.
availble_gpu_memory = self.model_executor.determine_available_memory()
# Get the kv cache tensor size
kv_cache_config = get_kv_cache_config(vllm_config, kv_cache_spec, availble_gpu_memory)
num_gpu_blocks = kv_cache_config.num_blocks
num_cpu_blocks = 0
# Initialize kv cache and warmup the execution
self.model_executor.initialize(kv_cache_config)
return num_gpu_blocks, num_cpu_blocks
首先调用了model_executor.get_kv_cache_spec获取kv_cache_spec,这最终调用了vllm.v1.worker.gpu_model_runner.get_kv_cache_spec,获取每一层attention kv cache信息:
def get_kv_cache_spec(self) -> KVCacheSpec:
"""
Generates the KVCacheSpec by parsing the kv cache format from each
Attention module in the static forward context.
Returns:
KVCacheSpec: A dictionary mapping layer names to their KV cache
format. Layers that do not need KV cache are not included.
"""
forward_ctx = self.vllm_config.compilation_config.static_forward_context
block_size = self.vllm_config.cache_config.block_size
kv_cache_spec: KVCacheSpec = {}
for layer_name, attn_module in forward_ctx.items():
# TODO: Support other attention modules, e.g., sliding window, cross-attention, MLA.
assert isinstance(attn_module, Attention)
if attn_module.attn_type == AttentionType.DECODER:
kv_cache_spec[layer_name] = FullAttentionSpec(
block_size=block_size,
num_kv_heads=attn_module.num_kv_heads,
head_size=attn_module.head_size,
dtype=attn_module.dtype,
)
return kv_cache_spec
kv_cache_spec结果样例:
kv_cache_spec: {
'model.layers.0.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.1.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.2.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.3.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16)}
kv_cache_config样例:
KVCacheConfig(
num_blocks=153259,
tensors={
'model.layers.0.self_attn.attn': KVCacheTensor(size=2510995456),
'model.layers.1.self_attn.attn': KVCacheTensor(size=2510995456),
'model.layers.2.self_attn.attn': KVCacheTensor(size=2510995456),
'model.layers.3.self_attn.attn': KVCacheTensor(size=2510995456)},
groups=[['model.layers.0.self_attn.attn',
'model.layers.1.self_attn.attn',
'model.layers.2.self_attn.attn',
'model.layers.3.self_attn.attn']],
kv_cache_spec={
'model.layers.0.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.1.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.2.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16),
'model.layers.3.self_attn.attn': FullAttentionSpec(block_size=16, num_kv_heads=2, head_size=128, dtype=torch.bfloat16)})
对于作者使用的模型和GPU,每个key和Value的FP16 cache大小为16*2*128*2字节,Key+Value总共分配num_gpu_blocks=153259个block总内存为2510995456字节。
这个num_gpu_blocks是VLLM KV cache pool的大小。
其次,model_executor.initialize(kv_cache_config)里面worker.initialize_cache进行实际内存分配:
class Worker:
def initialize_cache(self, kv_cache_config: KVCacheConfig) -> None:
"""Allocate GPU KV cache with the specified kv_cache_config."""
if self.vllm_config.model_config.enable_sleep_mode:
allocator = CuMemAllocator.get_instance()
context = allocator.use_memory_pool(tag="kv_cache")
else:
from contextlib import nullcontext
context = nullcontext()
with context:
self.model_runner.initialize_kv_cache(kv_cache_config)
class GPUModelRunner:
def initialize_kv_cache(self, kv_cache_config: KVCacheConfig) -> None:
"""
Initialize KV cache based on `kv_cache_config`.
Args:
kv_cache_config: Configuration for the KV cache, including the KV cache size of each layer
"""
kv_caches: Dict[str, torch.Tensor] = {}
for layer_name, layer_spec in kv_cache_config.kv_cache_spec.items():
tensor_config = kv_cache_config.tensors[layer_name]
assert tensor_config.size % layer_spec.page_size_bytes == 0
num_blocks = tensor_config.size // layer_spec.page_size_bytes
if isinstance(layer_spec, FullAttentionSpec):
kv_cache_shape = FlashAttentionBackend.get_kv_cache_shape(
num_blocks, layer_spec.block_size, layer_spec.num_kv_heads, layer_spec.head_size)
dtype = layer_spec.dtype
kv_caches[layer_name] = torch.zeros(kv_cache_shape, dtype=dtype, device=self.device)
bind_kv_cache(kv_caches, self.vllm_config.compilation_config.static_forward_context, self.kv_caches)
get_kv_cache_shape获得的kv shape为(2, num_gpu_blocks, block_size, num_kv_heads, head_size),也就是为每一个模型层分配了一个shape为这个大小的张量作为kv cache pool。这里第第一个维度的2分别是key和value的cache部分。
创建好的kv_caches是一个name到KV cache pool tensor的dict。
最后bind_kv_cache(kv_caches, self.vllm_config.compilation_config.static_forward_context, self.kv_caches)干了两件事:
一是把kv_caches按照layer id把cache tensor弄成一个list,赋值给self.kv_caches,也就是GPUModelRunner.kv_caches。这个后续作为了GPUModelRunner.model推理的输入,最后每一层的kv cache tensor传给attention层。也就是传入给attention层的是这个层的kv cache pool。
二是把kv cache赋值给forward_context: forward_context[layer_name].kv_cache = [kv_cache]
也就是最后GPUModelRunner保存了kv_cache内存作为成员变量,以及self.vllm_config.compilation_config.static_forward_context里面也保存了kayer_name到kv cache内存的map。
实际推理时Qwen2ForCausalLM.forward函数里面输入的kv_caches是一个长度为模型层数的list,包含每个layer的kv cache pool,kv cache pool shape为(2, num_gpu_blocks, block_size, num_kv_heads, head_size).
但是Qwen2ForCausalLM.forward并没有传入token的kv cache block ids,那么实际在哪里传入的呢:在GPUModelRunner.execute_model里面_prepare_inputs把相关信息放到attn_metadata然后设置到了context里面:
attn_metadata, logits_indices = self._prepare_inputs(scheduler_output)
# Use persistent buffers for CUDA graphs.
with set_forward_context(attn_metadata, self.vllm_config):
positions = self.mrope_positions[:, :num_input_tokens] if self.model_config.uses_mrope else self.positions[:num_input_tokens]
hidden_states = self.model(
input_ids=input_ids,
positions=positions,
kv_caches=self.kv_caches,
attn_metadata=None,
inputs_embeds=inputs_embeds,
)
vllm\attention\layer.py的attention计算时会get_forward_context拿取context获取相关信息。


















 5749
5749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











