







在深度学习中,使用公开数据集具有以下优点:
- 提供了一个标准化的基准来比较不同算法或模型的性能,因为这些公共数据集被广泛使用,许多研究人员都使用它们来评估他们的方法。
- 可以节省大量的时间和金钱,因为这些数据集已经被标注,从而避免了手动标注数据所需的努力和成本。
- 允许研究人员在自己的算法或模型上进行测试,而无需担心数据的版权问题。
- 跑开源代码时,可以使用公开数据快速测试。测试通后再使用的自己的数据。
为了快速开始使用公开的数据集(如 MedNIST 和 DecathlonDataset),MONAI 提供了几个开箱即用的函数(例如MedNISTDataset、DecathlonDataset、TciaDataset),其中包括数据下载,解压以及创建dataset(继承了MONAI 的 CacheDataset,训练的时候数据加载的嘎嘎快)。 预定义数据集的常用工作流程:
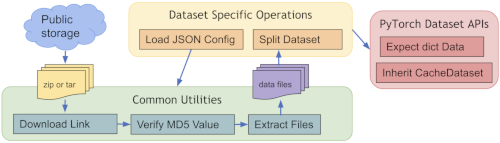
本次以DecathlonDataset,MedNISTDataset为例,说明如何在MONAI中使用这些数据,并简要介绍这些数据集
DecathlonDataset
医学分割十项全能挑战数据集(DecathlonDataset)是一个用于医学图像分割任务的数据集(very hot!)。该数据集包含来自不同医学影像模态(如MRI、CT等)的图像数据以及标签。数据可以从官网进行下载
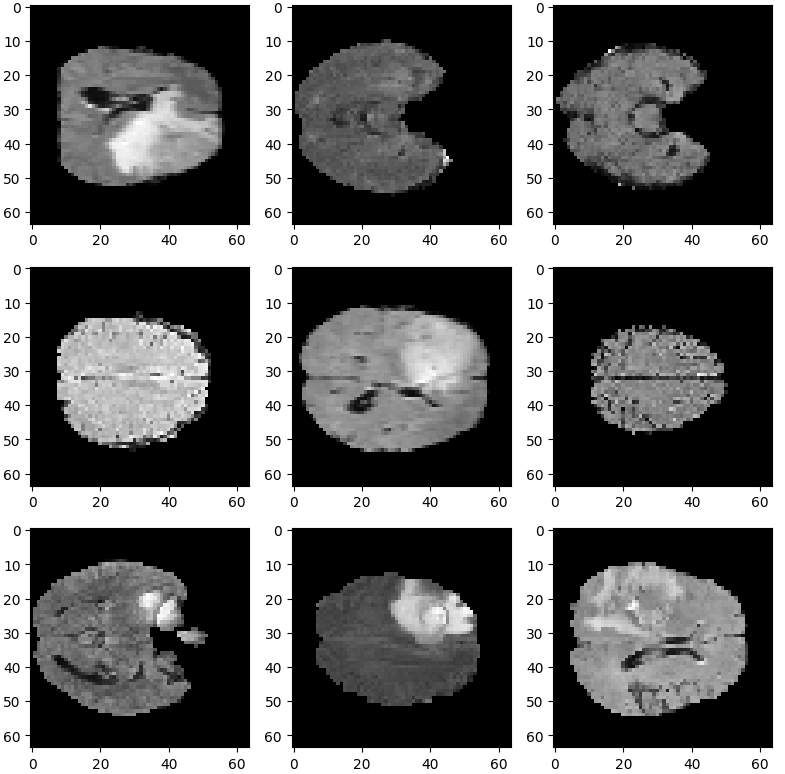
MONAI的DecathlonDataset会自动该数据集,并且分好了训练、验证和测试集。它还基于monai.data.CacheDataset类来加速训练过程。
先来看一下代码
train_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
section="training",
cache_rate=1.0, # you may need a few Gb of RAM... Set to 0 otherwise
num_workers=4,
download=True, # Set download to True if the dataset hasnt been downloaded yet
seed=0,
transform=train_transforms,
)
train_loader = DataLoader(
train_ds, batch_size=32, shuffle=True, num_workers=4, drop_last=True, persistent_workers=True
)
参数解析:
- root_dir:用户用于缓存和加载 MSD 数据集的本地目录。
task:要下载和执行的任务:一共10个数据集,选择你要用的下载 (“Task01_BrainTumour”、“Task02_Heart”、“Task03_Liver”、“Task04_Hippocampus”、“Task05_Prostate”、“Task06_Lung”、“Task07_Pancreas”、“Task08_HepaticVessel”、“Task09_Spleen”、“Task10_Colon”)。- section:选择下载训练集还是其他,可以是:training、validation 或 test。
- transform:MONAI 的常规 transform
download:需要下载设置为True,下载好后再运行设置为False- seed:随机种子,用于随机拆分训练、验证和测试数据集,默认为 0。
- val_frac:验证数据分数百分比,默认为 0.2。Decathlon 数据仅包含带标签的训练部分和不带标签的测试部分,因此从训练部分随机选择一部分作为验证部分。
- cache_rate:总缓存数据的百分比,默认为 1.0(全部缓存)。将取 (cache_num,data_length x cache_rate,data_length) 中的最小值。
- num_workers:要使用的工作线程数。如果为 0,则使用单个线程。默认为 0。

只贴上了关键代码,文末取所有代码,包括import类和可视化数据代码.至于下载速度,我的v-p-n很快,不挂V-P-N速度未知。
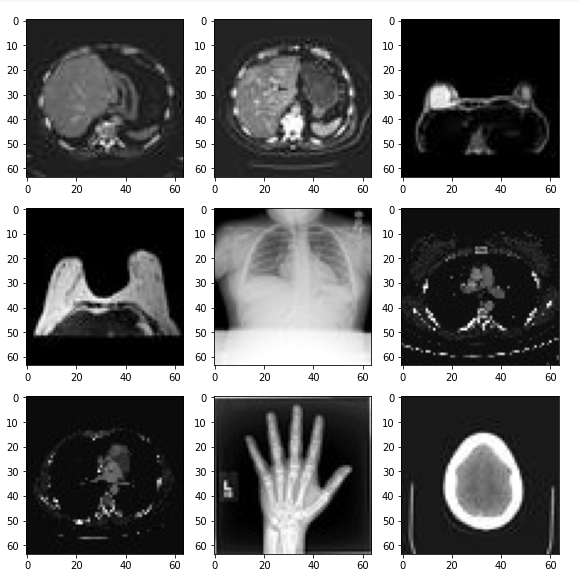
MedNISTDataset
受 Medical Segmentation Decathlon(医学分割十项全能)的启发,上海交通大学的研究人员创建了医疗图像数据集 MedMNIST,共包含 10 个预处理开放医疗图像数据集(其数据来自多个不同的数据源,并经过预处理)。和 MNIST 数据集一样,MedMNIST 数据集在轻量级 28 × 28 图像上执行分类任务,所含任务覆盖主要的医疗图像模态和多样化的数据规模,作为 AutoML 在医疗图像分类领域的基准。
代码如下:
train_ds = MedNISTDataset(root_dir=root_dir, transform=transform, section="training", download=True)
# the dataset can work seamlessly with the pytorch native dataset loader,
# but using monai.data.DataLoader has additional benefits of mutli-process
# random seeds handling, and the customized collate functions
train_loader = DataLoader(train_ds, batch_size=300, shuffle=True, num_workers=10)
参数同DecathlonDataset基本一致,不再解析。不了解的可以查看源码
最后附上整个代码
import os
from monai.data import DataLoader, Dataset
from monai import transforms
from monai.apps import MedNISTDataset, DecathlonDataset
import matplotlib.pyplot as plt
# create a directory and load decathlon dataset
root_dir = './data'
if not os.path.exists(root_dir):
os.makedirs(root_dir)
print(root_dir)
# transform for train set
train_transforms = transforms.Compose(
[
transforms.LoadImaged(keys=["image"]),
transforms.EnsureChannelFirstd(keys=["image"]),
transforms.ScaleIntensityRanged(keys=["image"], a_min=0.0, a_max=255.0, b_min=0.0, b_max=1.0, clip=True),
]
)
# create a training dataset and dataloader for MedNISTDataset and DecathlonDataset
# train_ds = MedNISTDataset(root_dir=root_dir, section="training", download=True, seed=0, transform=train_transforms)
# train_loader = DataLoader(train_ds, batch_size=32, shuffle=True, num_workers=4, persistent_workers=True)
train_ds = DecathlonDataset(
root_dir=root_dir,
task="Task01_BrainTumour",
section="validation",
cache_rate=1.0, # you may need a few Gb of RAM... Set to 0 otherwise
num_workers=4,
download=False, # Set download to True if the dataset hasnt been downloaded yet
seed=0,
transform=train_transforms,
)
train_loader = DataLoader(
train_ds, batch_size=32, shuffle=True, num_workers=4, drop_last=True, persistent_workers=True
)
print(f"Length of training data: {len(train_ds)}")
print(f'Train image shape {train_ds[0]["image"].shape}')
文章持续更新,可以关注微公【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持以实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连



















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











