










Generalized SAM: Efficient Fine-Tuning of SAM for Variable Input Image Sizes

Abstract
There has been a lot of recent research on improving the efficiency of fine-tuning foundation models. In this paper, we propose a novel efficient fine-tuning method that allows the input image size of Segment Anything Model (SAM) to be variable. SAM is a powerful foundational model for image segmentation trained on huge datasets, but it requires fine-tuning to recognize arbitrary classes. The input image size of SAM is fixed at 1024 × 1024, resulting in substantial computational demands during training. Furthermore, the fixed input image size may result in the loss of image information, e.g. due to fixed aspect ratios. To address this problem, we propose Generalized SAM (GSAM). Different from the previous methods, GSAM is the first to apply random cropping during training with SAM, thereby significantly reducing the computational cost of training. Experiments on datasets of various types and various pixel counts have shown that GSAM can train more efficiently than SAM and other fine-tuning methods for SAM, achieving comparable or higher accuracy.
关于提高基础模型微调效率的研究层出不穷。在本文中,我们提出了一种新颖且高效的微调方法,该方法允许“Segment Anything Model”(SAM)模型的输入图像尺寸可变。SAM是一个在大型数据集上训练得到的强大图像分割基础模型,但要识别任意类别,则需要对其进行微调。SAM的输入图像尺寸固定为1024×1024,这导致训练过程中的计算需求相当大。此外,固定的输入图像尺寸可能会导致图像信息丢失,例如由于固定的宽高比。为解决这一问题,我们提出了“Generalized SAM”(GSAM)。与以往方法不同,GSAM是首个在SAM训练过程中应用随机裁剪的方法,从而显著降低了训练的计算成本。在不同类型和不同像素数量的数据集上进行的实验表明,GSAM比SAM及其他针对SAM的微调方法训练效率更高,且达到了相当或更高的准确率。
Introduction
深度学习已被广泛应用于各种图像识别问题,并取得了巨大成功。特别是近年来,一种名为基础模型的大规模综合模型被提出,该模型以其能够在广泛任务中实现高性能而闻名。在语义分割领域,2023年提出了“Segment Anything Model”(SAM),它能够在不经过训练的情况下对自然图像进行高精度的分割。然而,如果想使用SAM来识别任意类别,就需要使用目标数据集的教师标签进行微调。由于SAM的输入图像尺寸固定为1024×1024,这导致在微调过程中产生了巨大的计算成本问题。
尽管已经提出了如LoRA[16]和AdaptFormer[9]等方法来更有效地微调SAM,但这些方法的输入图像尺寸仍固定为与SAM相同的1024×1024,因此由输入图像尺寸引起的计算成本问题并未得到解决。还提出了一种将SAM的输入图像尺寸减小到如256×256等小尺寸进行训练的微调方法[20],但输入图像尺寸仍然需要固定。由于每个数据集的像素数量不同,使用固定数量的像素可能会导致诸如图像信息丢失等严重问题。
本文提出了Generalized SAM(GSAM),它能够在输入图像尺寸可变的情况下进行训练。在SAM之前提出的基于卷积神经网络(CNN)的传统分割模型中,即使训练和推理时的输入图像尺寸不同,也能进行分割,因此可以在训练时输入小的随机裁剪图像,在推理时输入原始图像尺寸以获得分割结果。
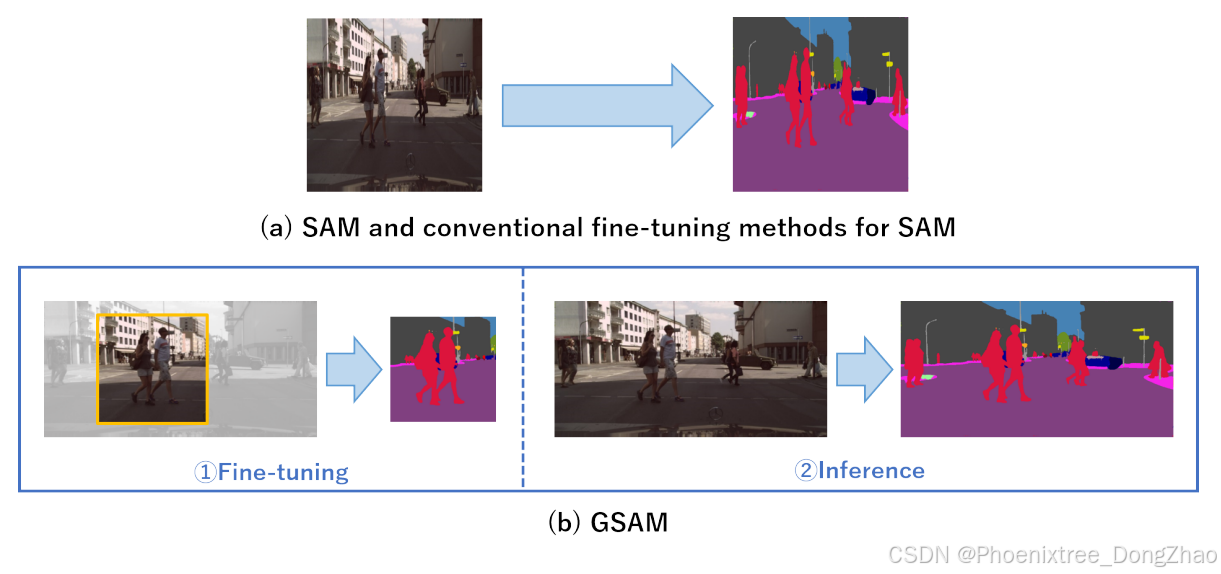

如图1所示,GSAM是首个在训练时能够对SAM应用随机裁剪的方法,使用小的随机裁剪尺寸降低了训练时的计算成本。SAM的固定输入尺寸是由于固定大小的位置编码所致。因此,GSAM通过使用由深度卷积层组成的位置编码生成器(PEG)来替代位置编码,从而支持可变输入图像尺寸。
此外,还提出了Spatial-Multiscale(SM)AdaptFormer,以便在微调时考虑更多的空间信息。SM-AdaptFormer具有多尺度结构,能够处理整合了更多样化和更广泛范围空间信息的特征向量。由于适当的分割需要各种尺度的信息,因此这是一种针对分割任务的特定微调方法。
通过对包括车内图像、卫星图像、显微图像、内窥镜图像、CT图像和透明物体图像在内的七个不同数据集进行的评估实验,与传统的SAM微调方法相比,所提出的GSAM能够显著降低训练的计算成本,并达到相当或更高的分割精度。
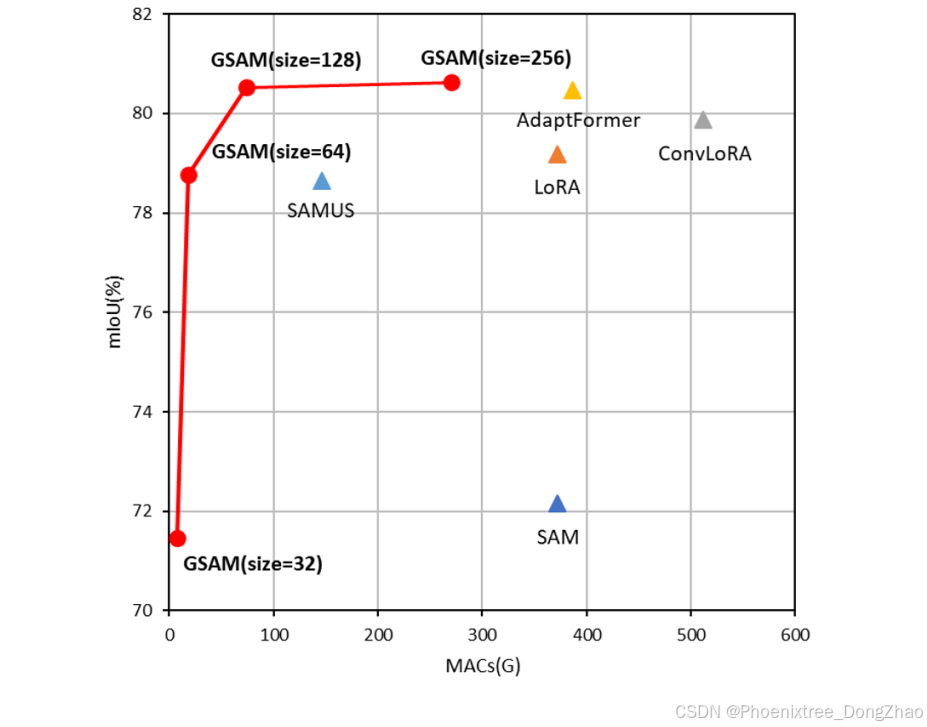
如图2所示,GSAM通过启用随机裁剪实现了较低计算成本和较高精度的平衡。特别是在Synapse多器官数据集(CT图像)上,GSAM的分割精度比传统的SAM微调方法高出11%以上,这表明我们提出的方法在某些领域可能非常有效。

贡献如下:
– 为SAM提出了一种新颖且高效的微调方法,即GSAM。GSAM能够处理可变输入图像尺寸,使得在SAM的微调过程中首次可以使用随机裁剪。
– 还提出了SM-AdaptFormer,以便在SAM的微调过程中获取多尺度特征。
– 通过在各种数据集上的评估实验,证实了与传统的SAM微调方法相比,GSAM能够显著降低训练的计算成本,并达到相当或更高的分割精度。
Application of Random Cropping during
训练中的随机裁剪应用
由于SAM的输入必须是固定大小为1024×1024,因此在训练过程中无法处理小图像尺寸的随机裁剪。SAM输入必须为固定大小的最重要原因是,作为SAM组成部分的Transformer编码器中的位置编码(Positional Encoding)是固定大小的。
位置编码是一种结构,它为每个标记添加信息,以告知其在视觉Transformer中的位置。在SAM的情况下,位置编码是一个具有固定大小的可学习权重参数。
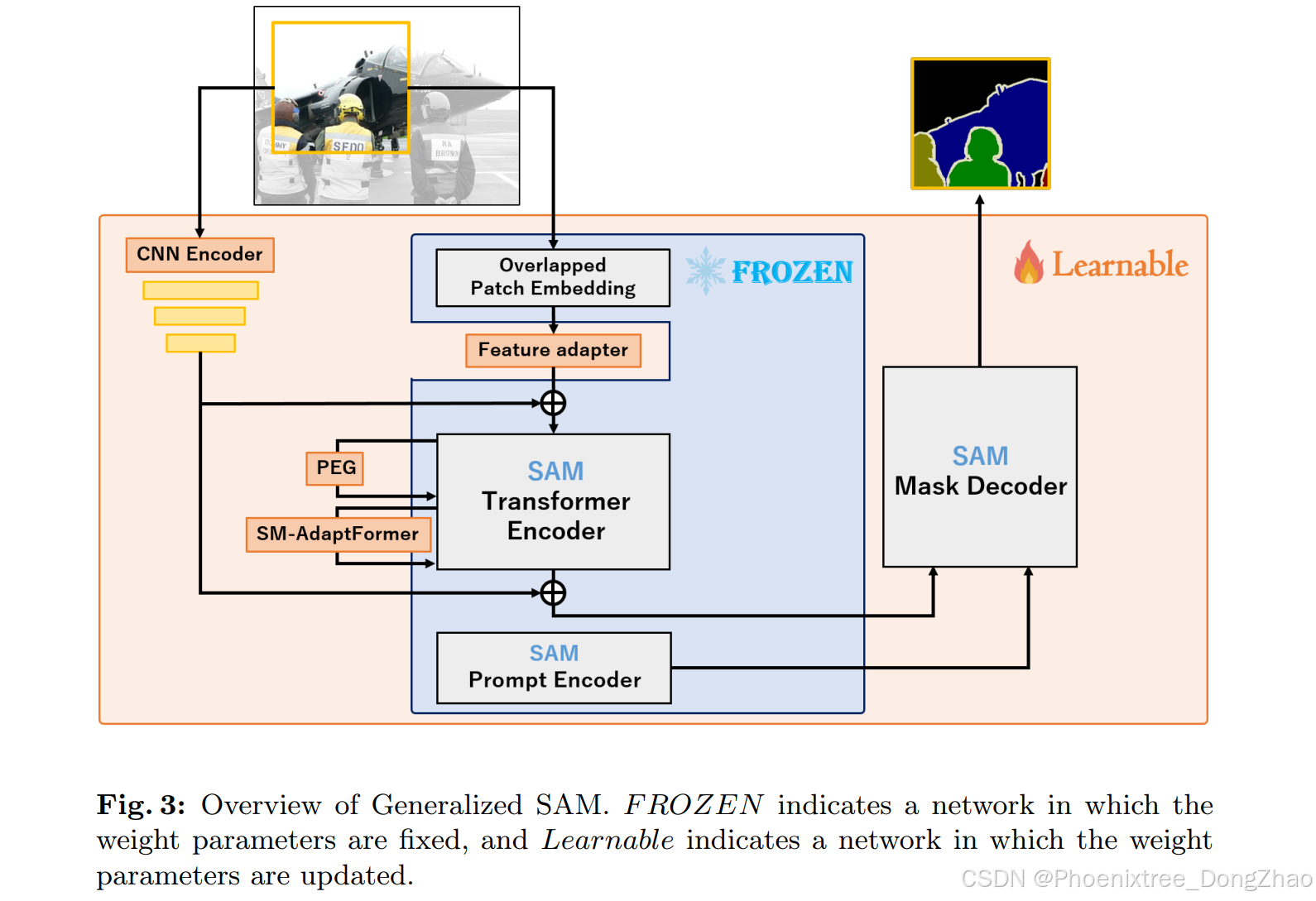
因此,GSAM采用位置编码生成器(Positional Encoding Generator, PEG)[10]作为位置编码的替代品。PEG由一个仅考虑空间方向的深度卷积层组成,这使得即使特征图的输入尺寸可变,也能保留位置信息。
然而,原始的预训练SAM不支持随机输入,并且可能仅通过Transformer编码器中的自注意力进行全局学习对于小且可变的输入来说是不够的。
因此,本文使用了一个由卷积神经网络(CNN)组成的新网络,如图3中的CNN编码器所示,以便通过整合CNN特征和SAM特征来进行学习。
由于CNN的局部核学习对于较小的输入图像是有效的,因此它被认为可以补充SAM中Transformer编码器的特征图。GSAM将保留一些空间信息的ResNet101[14]的第三块特征图添加到Transformer编码器的预输入和后输出特征图中。这使得能够使用随机裁剪进行有效的微调。综上所述,PEG和CNN编码器的引入使得能够使用随机裁剪和相应的特征提取。
Spatial-Multiscale AdaptFormer
空间多尺度AdaptFormer
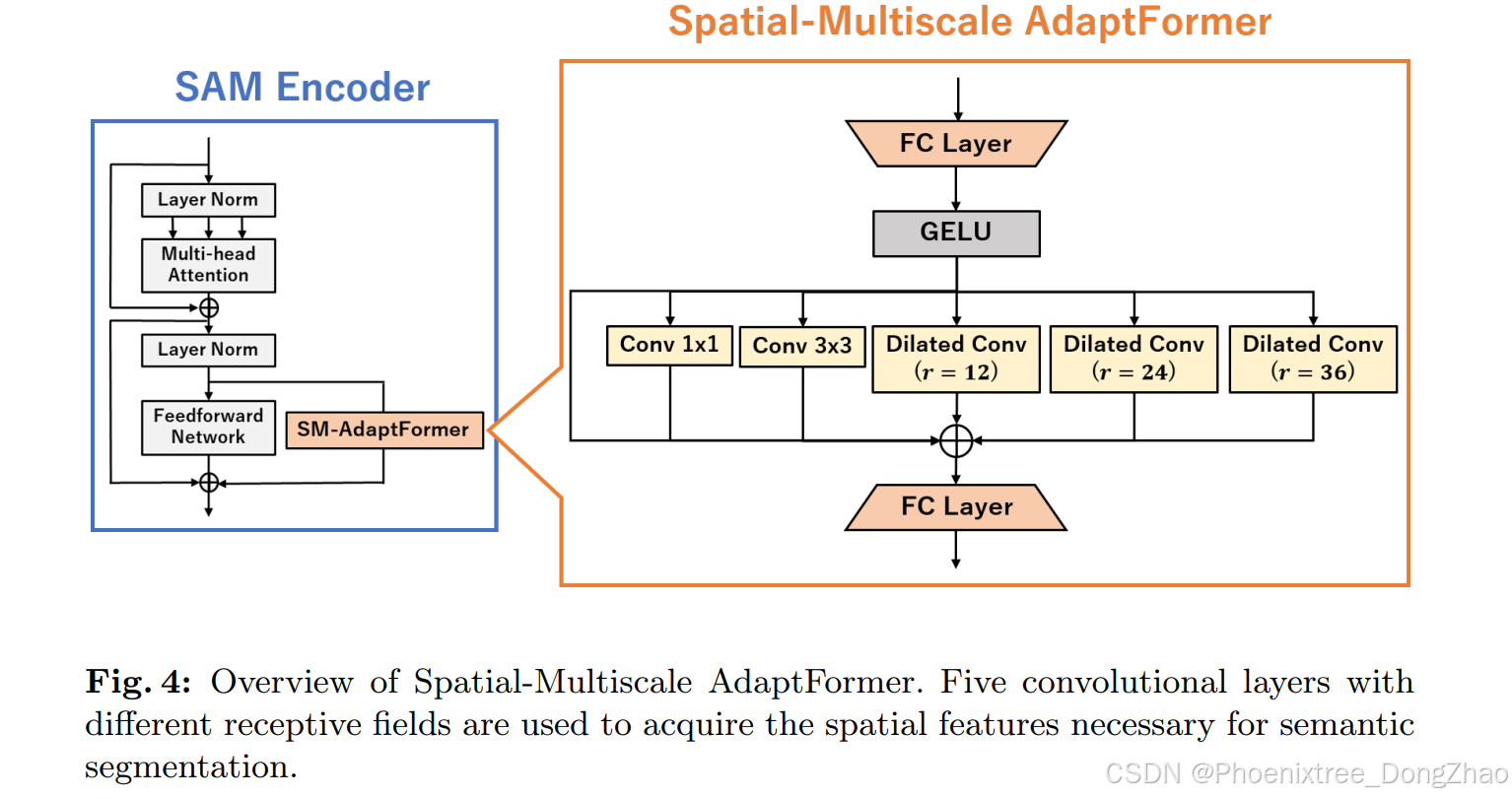
为了进一步提高目标数据集的判别精度,提出了空间多尺度(Spatial-Multiscale, SM)AdaptFormer。图4展示了SM-AdaptFormer的概述。
AdaptFormer[9]作为一种低计算成本和高性能的SAM微调方法而广为人知,但AdaptFormer并未考虑空间信息。由于空间特征是语义分割中的重要信息,因此所提出的SM-AdaptFormer准备了多个具有各种范围内核的卷积层,并获取多尺度特征。
对于具有广泛内核范围的卷积层,采用了扩张卷积(Dilated Convolution)。扩张卷积可以在保持相同内核大小的同时扩大感受野,从而允许在不增加计算成本的情况下进行全局特征提取。
当将扩张卷积应用于输入特征图x时,输出特征图y可以使用每个像素的位置i和卷积核w表示为公式(1)。
![]()
其中,r是决定步长宽度的参数,通过改变r可以自适应地改变卷积层的感受野。SM-AdaptFormer提供了两种卷积层,内核大小分别为1×1和3×3,以及扩张卷积(r=12)、扩张卷积(r=24)和扩张卷积(r=32),共五种类型的感受野。
通过学习这些小到大的感受野所覆盖的多尺度特征,并将它们相加来进行学习。在原始的AdaptFormer中,全连接层中的维度首先被减少,然后在全连接层中恢复到原始维度,以便以较低的计算成本学习参数,SM-AdaptFormer也采用了相同的结构。
因此,即使在获取多尺度特征时,输入也是低维的,从而避免了计算膨胀。

















 2026
2026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









