







前言
本文的标题 最开始是《七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma》
- 后于25年1月31日,直接改成了新的内容,标题也就变成了
一文速览DeepSeekMath及GRPO:通俗理解群体相对策略优化GRPO及其代码实现(含DeepSeek-Coder的简介) - 而原有审稿的内容则别归并到了其他文章中,具体详情以及为何改成这样,在这篇文章《一文速览DeepSeekMoE:从Mixtral 8x7B到DeepSeekMoE(含DeepSeek LLM的简介)》的开头有说原因
再后来
- 25年2月,随着V3、特别是R1的爆火,网络上出现了很多试图复现R1的开源项目,而想复现R1,算法层面得先有GRPO的实现,好在TRL库实现了,故后来又给本文增加了「第三部分 对TRL框架中GRPO实现代码的解读」
毕竟,如果真的想深挖,任何一个细节都不能放过——类似我2年前研究ChatGPT原理一样 - 后来考虑到本文的重点就是GRPO,故标题后来又改成
一文速览GRPO:通俗理解群体相对策略优化GRPO及其代码实现(含DeepSeek-Coder和DeepSeekMath的简介) - 25年2.14情人节这天,花了半个下午,总算把本文的GRPO算法写清楚、写清晰了(但后来的修订历程证明,此时的版本还有待不断修订 )
也就把本文标题的开头由:一文速览GRPO,改成了:一文通透GRPO,很快本文也会广泛流传了
2.15,在出门捉鳖 老街品茶的路上,脑袋里一直在思考,如何把下文的GRPO介绍的更清晰 更准确 更一目了然
晚上到家后一顿狂改,顺带把那篇ChatGPT原理也再次修订了下(那篇ChatGPT原理都已经修订60多次了)
未来半个多月,还会再不断优化本文
顺带有感而发,大模型爆火的这两年来,每次写博客,都是在「自疑 自负 自信」当中反复循环
- 自疑,写完一版,自我怀疑 够深了么,是不这里还不够清晰,不够一目了然,这里讲明白了么,好像不行,能否更明白
- 自负,我写的必须全网最清晰,改 改 改 改到不想改为止
- 自信,嗯,差不多了
第二天,一看,不行,还是不行,于是开启新一轮循环..,直到循环N轮..,N很难说会到几
第一部分 基于DeepSeek-Coder
24年1.25日,深度求索公司再次提出DeepSeek-Coder系列,大小从1.3B到33B不等——其中的7B在与大五倍的模型「如CodeLlama-33B (Roziere et al., 2023)」相比时表现出竞争力,包括每种大小的基础版本和指令版本( )
- 该系列中的每个模型都是从头开始训练的,使用了来自87种编程语言的2万亿个标记,确保对编码语言和语法有全面的理解
- 此外,他们尝试在代码库级别组织预训练数据,以增强预训练模型在跨文件代码库中的理解能力。除了在预训练期间使用下一个token预测损失外,他们还结合了填充中间(FIM)方法(Bavarian等,2022年;Li等,2023年)——这种方法旨在进一步增强模型的代码补全能力
- 为了满足处理更长代码输入的要求,他们将上下文长度扩展到16K
1.1 数据收集
DeepSeek-Coder 的训练数据集由87 % 的源代码、10 % 的与代码相关的英文自然语言语料库和3 % 的与代码无关的中文自然语言语料库组成
- 英文语料库包括来自GitHub 的Markdown 和StackExchange 的材料,这些材料用于增强模型对代码相关概念的理解,并提高其处理库使用和修复错误等任务的能力
- 同时,中文语料库由高质量的文章组成,旨在提高模型理解中文的熟练程度
整个过程涉及数据抓取、基于规则的过滤、依赖解析、仓库级去重和质量筛选,如下图图2 所示

1.1.1 GitHub 数据爬取和过滤
他们收集了2023 年2 月之前在GitHub 上创建的公共仓库,并仅保留表1 中列出的87 种编程语言
为了减少需要处理的数据量,他们应用了类似于StarCoder 项目(Li 等,2023)中使用的过滤规则,以初步过滤掉质量较低的代码。通过应用这些过滤规则,作者将数据总量减少到原始大小的32.8 %
具体而言,StarCoder 数据项目中使用的过滤规则包括
- 首先,过滤掉平均行长度超过100 个字符或最大行长度超过1000 个字符的文件
- 此外,移除字母字符少于25 % 的文件
除了XSLT 编程语言外,进一步过滤掉在前100 个字符中出现字符串”<?xml version=” 的文件
对于HTML 文件,考虑可见文本与HTML 代码的比例 - 保留可见文本至少占代码20 % 且不少于100 个字符的文件
对于通常包含更多数据的JSON 和YAML 文件,只保留字符数在50 到5000 个字符之间的文件。这有效地去除了大多数数据量大的文件
1.1.2 依存句法分析
// 待更
第二部分 DeepSeekMath及其提出的GRPO
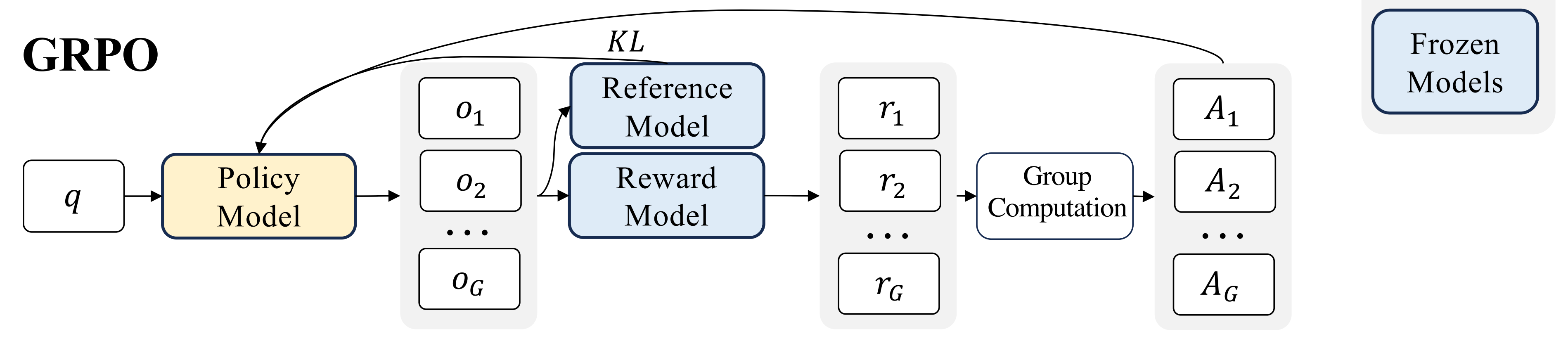
因为DeepSeek-V2涉及到了DeepSeekMath「其对应论文为 24年2月发表的《DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models》」中提出的群体相对策略优化——Group Relative Policy Optimization(简称GRPO)
故本节重点介绍一下DeepSeekMath及其提出的GRPO
2.1 DeepSeekMath的三阶段训练方式:预训练-微调-RL训练
DeepSeekMath是一个包含120B的数学token的大规模高质量预训练语料库,训练过程是经典的预训练-微调-RL训练三阶段
- DeepSeekMath-Base 7B
DeepSeekMath-Base 7B是在 DeepSeek-Coder-Base-v1.5 7B的基础上初始化的,因为他们注意到从代码训练模型开始比从通用 LLM 开始是一个更好的选择
具体而言
首先,通过从种子语料库OpenWebMath(一个高质量的数学网页文本集合)中随机选择50万个数据点作为正训练样本,训练一个fastText模型作为分类器
然后,使用该分类器从从Common Crawl(简称CC)中挖掘出更多的正例,且还选择其中的50万个网页作为负样本
当然,过程中,会对CC数据集做大量的去重,最终得到40B HTML网页
最后,针对这个去重后的40B CC数据集,直接人工标注出与数学相关的URL网页,然后归纳到种子数据集,从而通过这个扩大后的种子数据集去继续训练fastText,以提升其性能
最终,该模型与DeepSeek LLMs(DeepSeek-LLM 1.3B)有着相同的框架
1) 他们分别在每个数学语料库上训练模型,训练量为150B个token
2) 所有实验均使用高效且轻量级的HAI-LLM训练框架进行,且使用AdamW优化器,其中 𝛽1 = 0.9, 𝛽2 =0.95,weight_decay =0.1
3) 并采用多步学习率调度,学习率在2,000个预热步骤后达到峰值,在训练过程的80%后降至峰值的31.6%,在训练过程的90%后进一步降至峰值的10.0%
4) 另将学习率的最大值设置为5.3e-4,并使用包含4K上下文长度的4M token批量大小 - DeepSeekMath-Instruct
在预训练之后,对 DeepSeekMath-Base 应用了数学指令调优,且使用了CoT、program-of-thoug和tool-integrated reasonin数据
最终DeepSeekMath-Instruct 7B 在数学方面的能力,超越了所有 7B 同类模型,并且可以与 70B 开源指令微调模型相媲美 - DeepSeekMath-RL
此外,引入群体相对策略优化GRPO做进一步的RL训练,这是近端策略优化PPO的另一种变体算法
该方法放弃了通常与策略policy模型大小相同的critic模型,而是从群体得分中估计基线baseline,最终显著减少了所需的训练资源
In order to save the training costs of RL, we adopt Group Relative Policy Optimization (GRPO) (Shao et al., 2024), which foregoes the critic model that is typically with the same size as the policy model, and estimates the baseline from group scores instead
2.2 GRPO的背景知识:PPO
2.2.1 回顾:什么是PPO
首先,什么是PPO呢?
通过本博客内的其他文章
- 如果对RLHF或PPO的原理及其在ChatGPT中的应用不了解,则可以看这三篇文章:RL极简入门、ChatGPT原理详解、从零实现带RLHF的类ChatGPT 即可,胜过网上其他类似资料
- 注意,如果你之前对RL 还不了解,则建议先看上面三篇文章中的第一篇《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》
如该文的最新一条读者评论所说,“ 写的真好,一下子懂了deepseek-r1论文里的GRPO公式啥意思了 ”
可知(如若对PPO不够熟练的,真心建议看下上面那三篇文章,看了后 事半功倍,不看 事倍功半)
近端策略优化PPO是一种actor-critic的RL算法,其通过最大化以下目标函数来优化LLM
或者
对于前者中的KL散度是在基于优势函数优化策略的过程中,新旧策略的差距不要太大
接下来,咱们直接看后者,其中
、
分别代表当前策略、旧策略,它两的比值就是重要性采样中的重要性比值
、
分别采样于问题数据集、旧策略
是PPO中引入的与裁剪clip相关的超参数,用于稳定训练
clip就是约束新旧策略重要性比值的大小,使得这个比值最大不大于,最小不小于
——相当于比值在这两个边界的中间了
是优势,其通过应用广义优势估计GAE计算出——基于奖励
和可学习的价值函数
因此,在PPO中,需要一个价值函数与策略模型一起训练
- 且为了减轻奖励模型的过度优化,会在每个token的奖励得分中添加一个来自reference模型中对应token的KL惩罚「the standard approach is to add a per-token KL penalty from a reference model in the reward at each token 」,即
其中,是奖励模型,
是基线模型(即reference model,其被SFT模型初始化),
是KL惩罚的系数
这个公式所表达的言外之意就是可以为讨领导喜欢而不断改进自己的行为,但一切行为的底限是:不与公司最初倡导的价值感
- 不过,按理来说,这里的
,类似如下所示
不知,你注意到了没有,在PPO的策略迭代中,是可能会出现两个KL散度的,而这两个KL散度的目的和作用的对象完全不一样:一个是约束训练策略的迭代,一个是约束奖励模型,要注意区分
2.2.2 PPO的问题是什么
其次,PPO的问题是什么呢?
由于 PPO 中使用的价值函数value function(相当于actor-critic中的critic)通常是与策略模型policy model相当规模的另一个模型,这带来了巨大的内存和计算负担
如此文《速读deepseek v2 (三)- 理解GRPO(deepseekmath 与 deepseek coder)》所说
PPO的算法中,有4个模型
- 一个actor,生成句子
- 一个critic模型,类似国内教练,输出value,也算做价值函数
- 一个reward模型,类似国际裁判
- 一个reference模型
PPO的效率缺陷主要在于actor和critic的交互,是否可以丢掉critic呢,让actor直接去对齐RM
其实在PPO之前,最早是没有 Critic 的,用 actor 去生成行为,然后利用所有行为共同获得分数来训练模型,但是,因为每一个action(对应生成句子中的每一个 token)都是一个随机变量,N 个随机变量加在一起,方差就会非常巨大,这通常会导致整个 RL 训练崩掉,ReMax 的工作中就有类似的说明
为了解决这个问题,可以寻找一个baseline,让每一个随机变量都减掉该baseline,从而降低方差,这样训练就稳定了
- 那如何得到该baseline?简单一点,随机采样 N 次,取 N 次采样结果的得分「均值」作为 baseline,不过这种策略下只有当采样 N 足够大时,方差才能足够小,否则采样的代表性可能不足
PPO 的处理方式是使用一个神经网络 Critic 去拟合该均值均值(并非直接叠加),以减小方差 - 此外,在 RL 训练期间,价值函数被视为计算优势的基线——
「注意体会这句话,特别是其中基线的意义」,以减少方差
而在有的 LLM 环境中,通常只有最后一个token由奖励模型分配奖励分数,这可能会使在每个token上想要得到准确的价值评估会比较复杂——即价值函数训练变得复杂
不过,话说回来,还有的LLM环境中,比如微软的deepspeed chat——简称DSC,其在实现PPO/RLHF时,会涉及到对每个token的价值评估,详见:从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码
2.3 GRPO:丢掉价值估计,没有PPO中复杂的GAE优势函数计算
2.3.1 GRPO的定义与其实际示例
最后,有没PPO的替代算法呢?
一方面,上文提过的DPO是一种
另一方面,DeepSeek提出了群体相对策略优化GRPO——Group Relative Policy Optimization

- 它避免了像 PPO 那样需要额外的价值函数近似——说白了 就是不要PPO当中的value model或value function去做价值评估——we propose Group Relative Policy Optimization (GRPO), which obviates the need for additional value function approximation as in PPO
即丢掉critic,也就没有了value(不需要基于value做估计),也就不需要GAE『GAE是微软DSC对于优势函数的计算方法,详见我写的《从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat的源码》一文』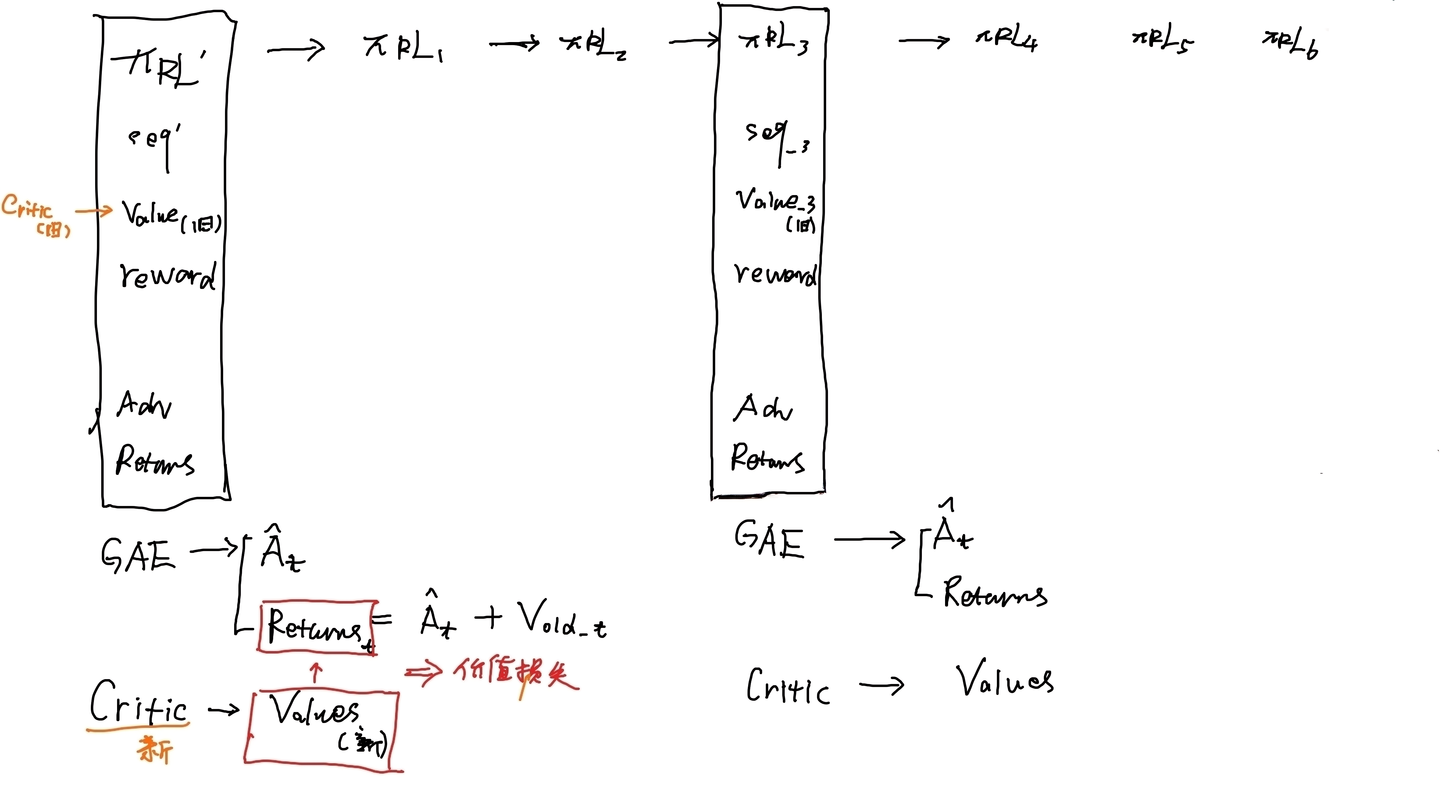
- 而是使用对同一问题的多个采样输出的平均奖励作为基线(说白了,直接暴力采样 N 次求均值)
and instead uses the average reward of multiple sampled outputs, produced in response to the same question, as the baseline
上面这句话有两个细节值得重点关注
- 举个例子,针对一个q采样出多个答案
,然后针对每个输出值,RM给出对应的
,最后计算出对应的优势值
,然后针对优势值大的——即超出平均水平线的策略 做重点关注,以此为依据更新策略
然后针对更多的q也采样出多个答案 - 优势函数不就重点考察那些超出预期、超出基线baseline的表现么,所以问题的关键就是基线baseline的定义,因为一旦定义好了baseline,我们的目标就明确了——越发鼓励可以超过baseline的行为(而每个行为是由背后的策略所决定的,故优化行为的同时就是策略的不断迭代与优化)
而这就是优势函数所追求的
举个例子,怎么评判公司的一个员工是否优秀呢?
这个 很难明确定义,谁给的定义 可能都没法让所有人信服
但至少有一个办法就是,拿他去和所有员工的平均水准 去对比(每个员工平时都是有得分项、失分项的),高于平均水准的 便是好员工
为方便大家更直观的理解,我引用此文《一文速览火爆全球的推理模型DeepSeek R1:如何通过纯RL训练以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》的一个示例:针对 7 + 3*7 = ?这个问题
训练的第一步是让模型按照旧策略(即 RL 更新前的 DeepSeek-V3-Base)生成多个可能的输出。在一次训练迭代中,假设 采样了 4 组不同的输出(G=4)
例如,针对 " What is 7 + 3*7 = ? " 这个问题,模型可能生成以下4种答案:
- o1:<think> 7 + 3 = 10, 10 * 7 = 70 </think> <answer> 70 </answer>
运算顺序错误- o2:<think> 3 * 7 = 21, 21 + 7 = 28 </think> <answer> 28 </answer>
答案正确- o3:<answer> 28 </answer>
答案正确,但缺少<think>标签- o4:<think> ...一些混乱的推理... </think> <answer> 7 </answer>
答案错误,且推理过程混乱然后使用基于规则的两个奖励:准确性奖励、格式奖励(当然,实践中,奖励函数是可以按需设计的,可以规则奖励,也可以偏好奖励,无论那种奖励,都可以用GRPO),对上面的4个输出分别进行奖励评分,假设奖励的分配如下
输出 准确性奖励 格式奖励 总奖励 o1 (答案错误) 0 0.1 0.1 o2 (答案正确) 1 0.1 1.1 o3 (答案正确,但缺少格式标签) 1 0 1.0 o4 (推理混乱且答案错误) 0 0.1 0.1 接下来,有了每个输出所对应的奖励,便可以计算奖励值的均值、优势值
- 可知标准差(近似计算) = 0.5
有了奖励值的均值、标准差,便可以根据GRPO中优势函数的计算公式
计算每个输出的优势值了
从上,可以看出来
- 输出 o2 和 o3 具有正优势,说明它们应该被鼓励;而 o1 和 o4 具有负优势,意味着它们应该被抑制
- 换言之,GRPO 使用这些计算得到的优势值来更新策略模型DeepSeek-V3-Base,提高 高优势输出(如 o2 和 o3)的生成概率,同时降低 负优势输出(如 o1 和 o4 )的生成概率
2.3.2 GRPO的目标函数:既约束新旧策略之间,也约束新策略与reference策略之间
对于每个问题,GRPO 从旧策略
中抽取一组输出
,然后GRPO通过最大化下述目标函数以优化策略模型——注意,前半部分clip约束的策略迭代中新旧策略之间的差距,后半部分的KL则约束的是新策略与reference模型策略之间的差距
其中,和
是超参数,
是基于每组内部输出的相对奖励计算的优势(ˆ𝐴𝑖,𝑡 is the advantage calculated based on relative rewards of the outputs inside each group on)
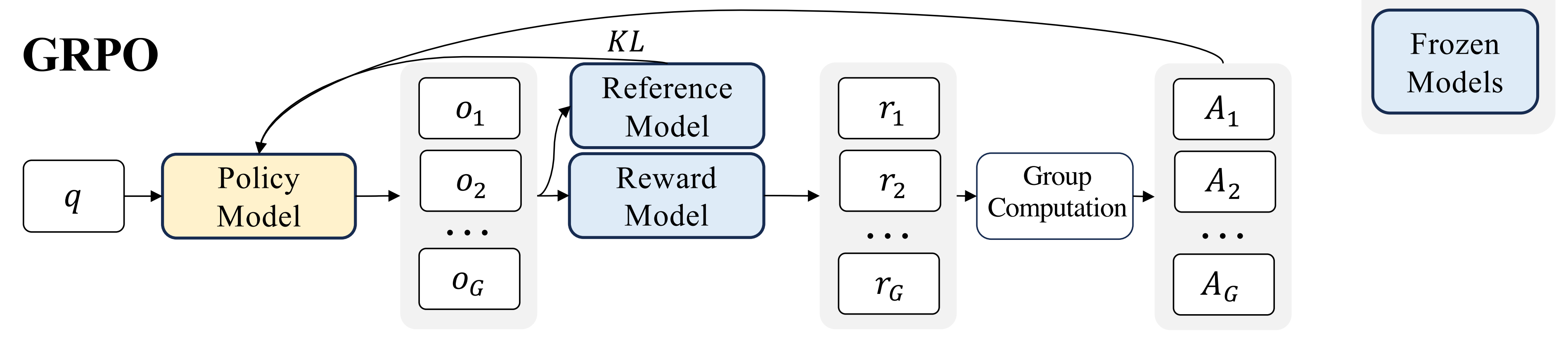
如此,GRPO 用的计算优势的群体相对方式,与奖励模型的比较性质非常契合,因为奖励模型通常是在同一问题的输出比较数据集上训练的
The group relative way that GRPO leverages to calculate the advantages, aligns well with the comparative nature of rewards models, as reward models are typically trained on datasets of comparisons between outputs on the same question
2.3.3 GRPO的KL惩罚项:不在奖励中添加KL惩罚,避免复杂的优势计算
原deepseekmath的论文中说,GRPO 不是在奖励中添加 KL 惩罚,而是通过直接将训练策略和reference策略之间的 KL 散度添加到损失中来进行正则化,从而避免了复杂的的计算——这句话可以反复体会5遍
instead of adding KL penalty in the reward, GRPO regularizes by directly adding the KL divergence between the trained policy and the reference policy to the loss, avoiding complicating the calculation of ˆ𝐴𝑖,𝑡 .
个人觉得如上表述,是带有一定歧义的,为什么呢
- 首先,给RM添加KL惩罚项 确实是增加了复杂度
- 其次,PPO中优势函数计算的复杂度 不是由『RM添加KL惩罚项』这一个因素导致的
而在于GAE中优势函数的计算确实复杂
因为A = returns - Value,但GAE中对returns的计算 不采用简单粗暴的「基于蒙特卡洛的回报计算方式」,而是让先计算优势函数,而优势函数的计算方式是
最后再通过下面式子计算回报
有了回报后,再让value去拟合returns- 正因为优势函数涉及到回报的计算、价值的估计,使得我们运用PPO迭代策略的同时,还得完成价值估计critic网络的迭代——相当于评估函数
这就是上节所说的,PPO 4个模型(ref模型、RM模型、PPO模型、critic模型),两个层面的迭代(策略的迭代、价值估计的迭代)如果忘了之前PPO时 得怎么算的,请查看上文提到过的此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》,特别是其中的第三部分
response 奖励,增加惩罚因子:πold/πref
优势值
此时的
为带时间步的
且此时的
为价值估计,一开始可以随机初始化
策略,迭代多次 回报returns
因为A = Returns - V,故Returns = A + V
价值估计
去拟合returnsprompt1-response1
RM
πold
returns
token 1、token 2、token 3、token k K个优势值 πRL1 prompt2-response2
RM
πold
returns
πRL2 prompt3-response3
RM
πold
returns
πRL3 - 也正因为以上种种,GRPO直接放弃了value model(即critic网络)——转而通过采集同一问题的多个输出,从而走出了不一样的道路..
总之,与PPO中
![]()
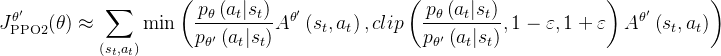
的奖励函数所使用的KL惩罚项不同
GRPO中使用以下无偏估计器估计KL散度
注意:我再强调一遍
- 在PPO中
目标函数中的KL散度或clip约束新旧策略之间的差距
分别如下述公式的第二行大中括号外、大中括号内的所示——来自 此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》
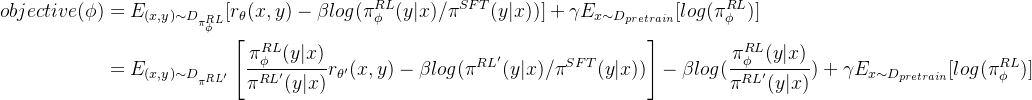
- 而GRPO一想,GAE之下的PPO那样操作太复杂了,既然GRPO中不再通过RM设置KL散度约束去:约束训练策略与reference策略之间的差距,那训练策略与reference之间的差距 放到哪呢?
有了,可以直接把这个“旧(训练)策略与reference模型策略之间的差距”,直接统一放在同一个目标函数的表达式里,即如下所示
对于此时的GRPO目标函数表达式,相当于就是对训练策略做两层约束:前半部分做新、旧策略之间的约束,后半部分做新策略、reference模型策略之间的约束
so,从而做到了一个表达式中——策略迭代中不与旧策略相差太远 也不与reference策略相差太远
反过来说,正因为GRPO的目标函数表达式已经有了对训练预测与reference策略的约束,所以在用GRPO做策略的迭代时——从旧策略迭代到新策略,设计对应的RM函数时,也就不用再考虑增加KL约束旧(训练)策略与reference模型策略之间的差距
可能还是有同学会疑问,为何后半部分不是像PPO里对RM做KL散度时旧策略与reference模型策略之间的约束,而是新策略与reference策略之间的约束?
我会先在这个「deepseek项目实战营」里讲清楚,至于本文后续更新,故在此之前,读者可以先想一想
2.3.4 GRPO的梯度计算
如果为了简化分析,比如假设模型在每个探索阶段之后只有一次更新,从而确保,在这种情况之下,便可以移除上面的clip操作「it is assumed that the model only has a single update following each exploration stage, there by ensuring that 𝜋𝜃𝑜𝑙𝑑 = 𝜋𝜃. In this case, we can remove the min and clip operation」
即如下图所示(虽然下图所示的过程是在PPO中,但本质是一个意思)

故类似的
- 把上面的
放入到下述表达式中
且在的情况下,即可去掉clip和min操作,得到新的目标表达式
- 接下来,便可以计算
如此,梯度系数是
其中的是基于组奖励分数计算的
2.4 GRPO中优势函数的设计
接下来,我们来看下优势函数如何设计
类似此文《ChatGPT原理解析 》3.2.1节如何更好的理解Actor-Critic架构中的Critic网络节最后有讲到的
优势的计算、回报的计算、Critic的输出等等都是开放性的话题
- 设计者认为Critic不需要去评价时间步、只需要评价完整序列,那么Critic就被设计成标量预测,比如colossalchat
- 设计者认为Critic需要严谨到对每个时间步做评价,那么Critic就会被设计成序列预测,比如微软deepspeed chat
可以有三种设计
2.4.1 使用GRPO的结果监督强化学习
第一种,使用GRPO的结果监督强化学习,相当于奖励模型只看最终生成句子的表现,不看生成过程中是否按预期进行
- 首先,对于每个问题,通过旧策略模型
Formally, for each question 𝑞, a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 } are sampled from the old policy model 𝜋𝜃𝑜𝑙𝑑 . - 其次,使用奖励模型对每个输出进行评分,从而得到G个奖励
A reward model is then used to score the outputs, yielding 𝐺 rewards r = {𝑟1, 𝑟2, · · · , 𝑟𝐺 } correspondingly. - 随后,通过减去组平均值并除以组标准差来规划化这些奖励
Subsequently, these rewards are normalized by subtracting the group average and dividing by the group standard deviation.
结果监督在每个输出结束时提供规范化的奖励,并将输出中所有token的优势
Outcome supervision provides the normalized reward at the end of each output 𝑜𝑖 and sets the advantages ˆ𝐴𝑖,𝑡 of all tokens in the output as the normalized reward, i.e., ˆ𝐴𝑖,𝑡 = e𝑟𝑖 = 𝑟𝑖 −mean(r) std(r) - 最后,通过最大化这个目标函数
and then optimizes the policy bymaximizing the objective defined in equation
2.4.2 使用GRPO进行过程监督RL
结果监督仅在每个输出的末尾提供奖励,这可能不足以有效监督复杂数学任务中的策略(毕竟数学计算讲究step by step,需要关注类似CoT那种推断的过程)
根据Wang等人(Math-shepherd: Verify and reinforce llms step-by-step without human annotations)的研究,deepseek还探索了过程监督,它在每个推理步骤结束时提供奖励
Outcome supervision only provides a reward at the end of each output, which may not be sufficient and efficient to supervise the policy in complex mathematical tasks. Following Wang et al. (2023b), we also explore process supervision, which provides a reward at the end of each reasoning step.
- 形式上,给定问题
采样输出
其中是第
步的结束token索引,
是第
个输出的总步骤数
Formally, given the question 𝑞 and 𝐺 sampled outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 }, a process reward model is used to score each step of the outputs, yielding corresponding rewards: R = { {𝑟𝑖𝑛𝑑𝑒𝑥 (1)1 , · · · , 𝑟𝑖𝑛𝑑𝑒𝑥 (𝐾1 )1 }, · · · , {𝑟𝑖𝑛𝑑𝑒𝑥 (1)𝐺 , · · · , 𝑟𝑖𝑛𝑑𝑒𝑥 (𝐾𝐺 )𝐺 }}, where 𝑖𝑛𝑑𝑒𝑥 ( 𝑗) is the end token index of the 𝑗-th step, and 𝐾𝑖 is the total number of steps in the 𝑖-th output.
我用下表对比下之前与现在的
相当于现在的很类似PPO中DSC那套做法了——详见 《ChatGPT原理解析 》:涉及到对每个token的奖励与优势值之前输出 之前奖励 之前优势值 现在输出 现在奖励 现在优势值 q 一个o1
一个r1 一个A1 token 1、token 2、token 3、token k K个优势值 一个o2 一个r2 一个A2 token 1、token 2、token 3、token k K个优势值 一个o3 一个 一个 一个 token 1、token 2、token 3、token k K个优势值 q' q''
而现在这种做法 还是比较复杂的,之前虽然也涉及到每个token的奖励,但好歹一个prompt只有一个response,但现在一个prompt还有多个response,而多个response又涉及到每个token的奖励
进一步而言
对于PPO DSC那一套,其涉及到每个token的奖励与优势值,这个是提高复杂度的,但至少一个prompt只有一个response 相当于复杂度降下来了
而对于结果奖励下的GRPO,一个prompt还有多个response 这个是提高复杂度的,但如果不涉及每个token的奖励与优势值 则复杂度降下更多 - 且还用平均值和标准差对这些奖励进行归一化,即
We also normalize these rewards with the average and the standard deviation, i.e., e𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 = 𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 −mean(R)std(R) . - 随后,过程监督计算每个token的优势作为以下步骤的归一化奖励的总和,即
最后,通过最大化
Subsequently,the process supervision calculates the advantage of each token as the sum of the normalized rewards from the following steps, i.e., ˆ𝐴𝑖,𝑡 = Í𝑖𝑛𝑑𝑒𝑥 ( 𝑗) ≥𝑡 e𝑟𝑖𝑛𝑑𝑒𝑥 ( 𝑗)𝑖 , and then optimizes the policy by maximizing the objective defined in equation
2.4.3 使用 GRPO 的迭代强化学习
随着强化学习训练过程的进展,旧的奖励模型可能不足以监督当前的策略模型
因此,他们还探索了使用 GRPO 的迭代强化学习,如下图所示

对于上面这个算法流程,总共有三个循环
第一个循环可以以月为单位,即每个月迭代大的一轮,迭代轮数为,
可以等于12,也意味着
每个月才更新一次
第二个循环可以以周为单位,在每月一轮的大迭代周期中,从现有数据集中每周采样一批
「比如
」做迭代,迭代次数为
,比如M 可以等于4
然后从每一批的数据集中均基于策略
——相当于
每周更新一次,针对每个问题
采样多个输出{
}
第三个循环可以以天为单位,每一天都针对上面一个个问题的输出、奖励分值、优势值进行一次次的策略迭代——相当于
每天更新一次
第一天针对问题采样多个输出{
},然后
给每个输出打个奖励分数得到{
},最后计算对应的优势值{
}
第二天针对问题采样多个输出{
},然后
给每个输出打个奖励分数得到{
},最后计算对应的优势值{
}
第三天针对问题采样多个输出{
},然后
给每个输出打个奖励分数得到{
},最后计算对应的优势值{
}
第七天...
此外,在迭代 GRPO 中,根据策略模型的采样结果为奖励模型生成新的训练集,并使用包含 10%历史数据的重放机制不断训练旧的奖励模型。然后,将参考模型设为策略模型,并使用新的奖励模型持续训练策略模型——换言之,RM同一样,每周更新一次
在本次对策略模型(基于DeepSeekMath-Instruct 7B)做强化学习的训练中
- 且强化学习的训练数据是与GSM8K和MATH相关的链式思维格式问题,这些问题来自SFT数据,总共约有144K个问题
- 排除其他SFT问题,以研究在整个强化学习阶段缺乏数据的基准测试上强化学习的影响
且按照(Wang etal., 2023b,即上文提过的Math-shepherd)构建奖励模型的训练集 - 基于DeepSeekMath-Base 7B训练初始奖励模型,学习率为2e-5
- 对于GRPO,将策略模型的学习率设为1e-6。KL系数为0.04
对于每个问题,采样64个输出,最大长度设置为1024,训练批量大小为1024 - 策略模型在每个探索阶段之后仅进行一次更新
在基准测试中评估了DeepSeekMath-RL 7B,遵循DeepSeekMath-Instruct 7B
对于DeepSeekMath-RL 7B,带有链式推理的GSM8K和MATH可以视为域内任务,所有其他基准测试可以视为域外任务
2.5 针对SFT、RFT、DPO、PPO、GRPO的统一范式
通常,训练方法相对于参数的梯度可以写成
其存在三个关键组成部分:1)数据来源 D,决定训练数据;2) 奖励函数,是训练奖励信号的
来源;3)算法 A:处理训练数据和奖励信号以获得梯度系数,决定数据的惩罚或强化的幅度
比如
- 对于监督微调SFT而言
SFT 在人工选择的 SFT 数据上微调预训练模型 - 对于拒绝采样微调 (RFT)而言
RFT基于SFT问题从SFT模型中采样的过滤输出进一步微调SFT模型,RFT根据答案的正确性过滤输出 - 对于直接偏好优化 (DPO)而言
DPO通过使用成对DPO损失在增强输出上微调SFT模型,从而进一步优化SFT模型 - 对于在线拒绝采样微调 (在线RFT)而言
与RFT不同,在线RFT使用SFT模型初始化策略模型,并通过在实时策略模型中采样的增强输出进行微调来优化它 - PPO/GRPO: PPO/GRPO使用SFT模型初始化策略模型,并通过从实时策略模型中采样的输出进行强化(当然,严格意义上,得区分策略模型的旧策略和当前策略)
第三部分 对TRL框架中GRPO实现代码的解读
著名的RL框架TRL实现了GRPO,详见:huggingface.co/docs/trl/main/en/grpo_trainer
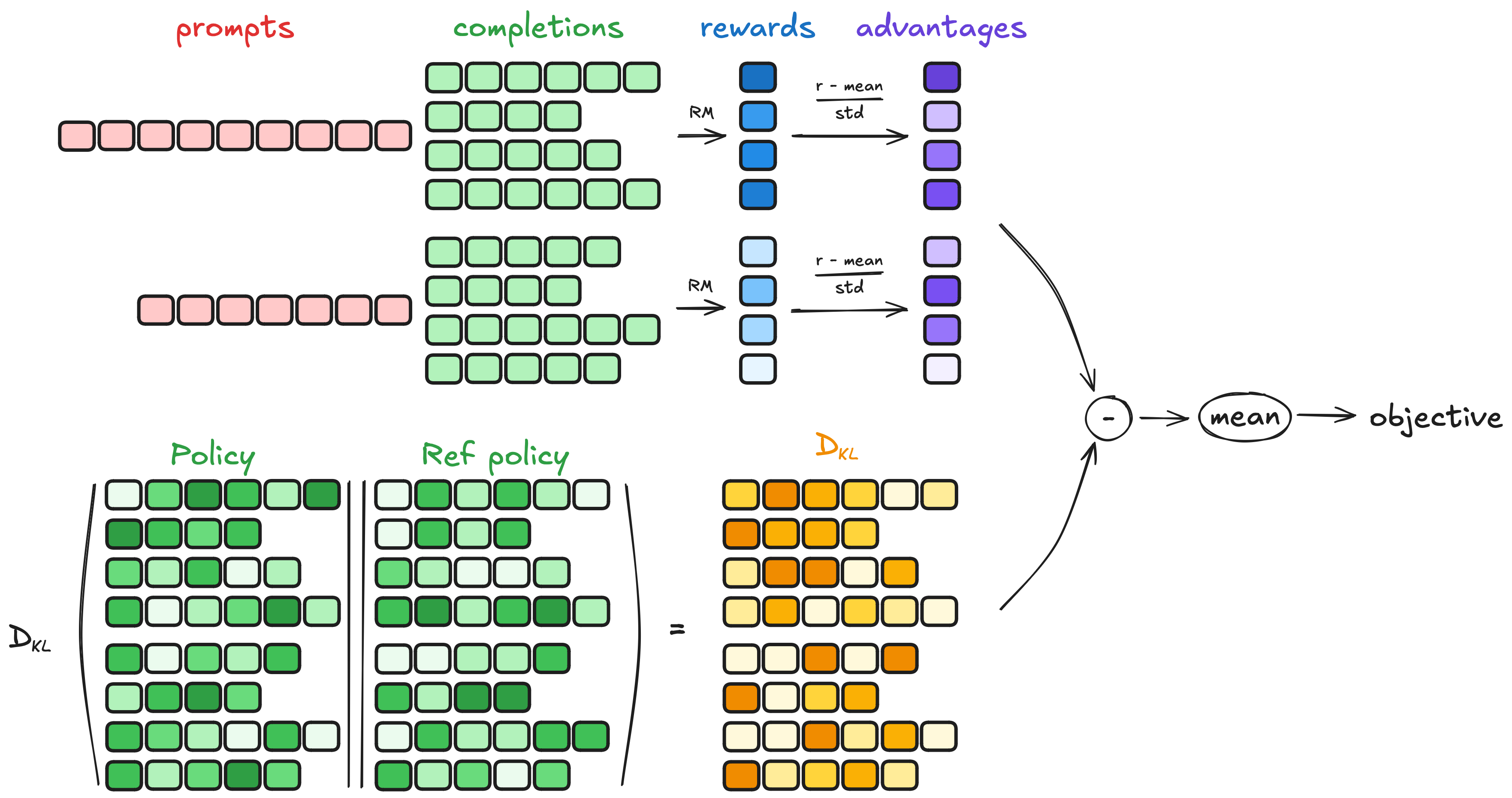
根据上图,再回顾一下
- GRPO的目标表达式为
而其中的KL散度是针对模型策略与reference策略之间的差距的
- 在
3.1 RepeatRandomSampler类的实现:对数据集做多次重复采样
在这段代码中,首先定义了一个类型别名 RewardFunc,它可以是一个字符串(表示模型 ID)、一个预训练模型 (PreTrainedModel),或者一个可调用对象(函数),该函数接受两个列表(提示和完成)并返回一个浮点数列表作为奖励
接下来定义了一个类 RepeatRandomSampler,它继承自 PyTorch 的 Sampler 类。这个类的作用是从数据集中重复采样索引
构造函数 __init__ 接受三个参数:data_source(数据集)、repeat_count(重复次数)和 seed(随机种子)
在初始化时,它会创建一个本地随机生成器,并根据提供的种子进行初始化
__iter__ 方法生成一个包含重复索引的列表。具体来说,它会先生成一个随机排列的索引列表,然后根据 repeat_count 参数重复这些索引
__len__ 方法返回数据集中样本的总数乘以重复次数。
这个类的一个示例用法是:创建一个 RepeatRandomSampler 实例,并将其应用于一个包含字符串的列表。通过调用 list(sampler) 可以得到一个重复采样后的索引列表
3.2 GRPOTrainer类的实现
`GRPOTrainer` 类继承自大名鼎鼎的hf-Transformer库的 `Trainer` 类,并扩展了其功能以支持 GRPO 方法
在 `GRPOTrainer` 的构造函数__init__ 中,接受多个参数,包括模型、奖励函数、训练和评估数据集、处理类、回调函数、优化器和 PEFT 配置
- 首先,根据提供的参数初始化模型和reference模型,并设置处理类和奖励函数
- 然后,定义了数据整理器和训练参数,并初始化一些内部变量和度量指标
- 最后,调用父类的构造函数进行初始化
`GRPOTrainer` 类中包含多个方法,例如`_set_signature_columns_if_needed``_get_train_sampler`、`_get_eval_sampler`、_get_per_token_logps、_move_model_to_vllm、_prepare_inputs、compute_loss、`prediction_step` 和 log
这些方法分别用于设置签名列、获取训练和评估采样器、计算每个 token 的对数概率、将模型移动到 vLLM 设备、准备输入数据、计算损失、执行预测步骤和记录日志
此外,`create_model_card` 方法用于生成模型卡片,包含模型和数据集的信息以及相关的引用。这个类通过整合多个组件和方法,实现了 GRPO 方法的训练和评估流程,允许用户使用自定义的奖励函数和数据集进行训练和评估
接下来,逐一解读
3.2.1 构造函数 `__init__
构造函数接受多个参数,包括模型、奖励函数、训练和评估数据集、处理类、回调函数、优化器和 PEFT 配置
def __init__( # 构造函数
self,
model: Union[str, PreTrainedModel], # 模型,可以是字符串或预训练模型对象
reward_funcs: Union[RewardFunc, list[RewardFunc]], # 奖励函数,可以是单个函数或函数列表
args: GRPOConfig = None, # 配置参数,默认为 None
train_dataset: Optional[Union[Dataset, IterableDataset]] = None, # 训练数据集
eval_dataset: Optional[Union[Dataset, IterableDataset, dict[str, Union[Dataset, IterableDataset]]]] = None, # 评估数据集
processing_class: Optional[PreTrainedTokenizerBase] = None, # 处理类
reward_processing_classes: Optional[Union[PreTrainedTokenizerBase, list[PreTrainedTokenizerBase]]] = None, # 奖励处理类
callbacks: Optional[list[TrainerCallback]] = None, # 回调函数列表
optimizers: tuple[Optional[torch.optim.Optimizer], Optional[torch.optim.lr_scheduler.LambdaLR]] = (None, None), # 优化器和学习率调度器
peft_config: Optional["PeftConfig"] = None, # PEFT 配置
):构造函数首先检查并设置传入的参数。如果没有提供 `args` 参数,则使用默认配置 `GRPOConfig`
# Args
if args is None: # 如果没有提供 args 参数
model_name = model if isinstance(model, str) else model.config._name_or_path # 获取模型名称
model_name = model_name.split("/")[-1] # 提取模型名称的最后一部分
args = GRPOConfig(f"{model_name}-GRPO") # 使用默认配置然后,根据提供的参数初始化模型和reference模型,并设置处理类和奖励函数,具体而言,如下所示
- 模型初始化
如果提供的是字符串形式的模型 ID,则使用 `AutoModelForCausalLM.from_pretrained` 方法加载预训练模型
如果模型不是以字符串形式提供的,即已经是一个预训练模型对象,则直接使用该对象
最后,如果提供了peft_config,则使用get_peft_model方法将模型包装为PEFT模型
对于reference模型,其在 GRPO 方法中用于计算 KL 散度等度量指标
首先,代码检查是否启用了 DeepSpeed Zero-3 优化 (is_deepspeed_zero3_enabled())。如果启用了 DeepSpeed Zero-3 优化,则使用 AutoModelForCausalLM.from_pretrained 方法从预训练模型中加载reference模型——使用了 model_id 和 model_init_kwargs 作为参数
如果没有启用 DeepSpeed Zero-3 优化,代码接着检查模型是否是 PEFT 模型 (is_peft_model(model))# Reference model if is_deepspeed_zero3_enabled(): # 如果启用了 DeepSpeed Zero3 self.ref_model = AutoModelForCausalLM.from_pretrained(model_id, **model_init_kwargs) # 加载参考模型
elif not is_peft_model(model): # 如果没有使用 PEFT 模型 # If PEFT configuration is not provided, create a reference model based on the initial model. self.ref_model = create_reference_model(model) # 创建参考模型else: # If PEFT is used, the reference model is not needed since the adapter can be disabled # to revert to the initial model. self.ref_model = None # 不需要参考模型 - 处理类和奖励处理类
如果没有提供处理类,则使用 `AutoTokenizer.from_pretrained` 方法加载默认的处理类
对于奖励函数 (reward_funcs) 的初始化# Processing class if processing_class is None: # 如果没有提供处理类 processing_class = AutoTokenizer.from_pretrained(model.config._name_or_path, padding_side="left") # 加载默认处理类
首先,代码检查 reward_funcs 是否是一个列表。如果 reward_funcs 不是列表,则将其转换为包含单个元素的列表。这确保了后续代码可以统一处理 reward_funcs,无论它最初是单个函数还是多个函数
接下来,代码遍历 reward_funcs列表中的每个奖励函数。如果奖励函数是以字符串形式提供的(表示模型 ID),则使用 AutoModelForSequenceClassification.from_pretrained 方法加载预训练的序列分类模型# Reward functions if not isinstance(reward_funcs, list): # 如果奖励函数不是列表 reward_funcs = [reward_funcs] # 转换为列表
这里使用了 reward_func 作为模型 ID,并传递了 num_labels=1 和 model_init_kwargs 作为参数。这样,字符串形式的奖励函数会被转换为预训练模型对象
最后,将处理后的 reward_funcs 列表赋值给实例变量 self.reward_funcsfor i, reward_func in enumerate(reward_funcs): # 遍历奖励函数 if isinstance(reward_func, str): # 如果奖励函数是字符串 reward_funcs[i] = AutoModelForSequenceClassification.from_pretrained( reward_func, num_labels=1, **model_init_kwargs )
通过这种方式,代码确保了 reward_funcs 列表中的每个元素都是一个有效的奖励函数,无论它们最初是字符串形式的模型 ID 还是已经是预训练模型对象self.reward_funcs = reward_funcs # 设置奖励函数 - 数据整理器和训练参数
定义了一个数据整理器 `data_collator`,在 GRPO 中不需要数据整理。设置了最大提示长度、最大完成长度、生成次数和其他相关参数。还包括对 vLLM 的支持,如果启用 vLLM,则会进行相应的初始化和配置 - 其他初始化
初始化度量指标 `_metrics` 和日志记录选项 `log_completions`。调用父类 `Trainer` 的构造函数进行初始化。
其次是,训练和评估设置
检查每个设备的训练和评估批量大小是否可以被生成次数整除。如果不能整除,则抛出错误。确保每个进程接收到唯一的种子,防止生成重复的完成。
以及vLLM 支持
如果启用了 vLLM,则进行相应的初始化和配置,包括检查设备可用性、设置设备和内存利用率等。确保主进程负责加载模型权重,并在 vLLM 完全初始化后同步所有进程。
至于设置梯度累积所需的损失缩放,添加模型标签,并根据需要准备reference模型。如果启用了 `sync_ref_model`,则添加相应的回调函数
3.2.2 借助RepeatRandomSampler类进行数据重复采样
在这段代码中,`GRPOTrainer` 类定义了几个辅助方法,用于处理数据预处理、采样和计算对数概率
- 首先,_set_signature_columns_if_needed 方法用于设置模型的签名列。如果 self.args.remove_unused_columns 为 `True`,则会移除非签名列。默认情况下,该方法会将 self._signature_columns 设置为模型预期的输入列
然而,在 `GRPOTrainer` 中,数据需要预处理,因此使用模型的签名列并不适用。相反,该方法将签名列设置为 `training_step` 方法预期的列,即 `["prompt"]`def _set_signature_columns_if_needed(self): # If `self.args.remove_unused_columns` is True, non-signature columns are removed. # By default, this method sets `self._signature_columns` to the model's expected inputs. # In GRPOTrainer, we preprocess data, so using the model's signature columns doesn't work. # Instead, we set them to the columns expected by the `training_step` method, hence the override. if self._signature_columns is None: self._signature_columns = ["prompt"] - 接下来,_get_train_sampler 方法返回一个训练采样器。该采样器确保每个提示在多个进程中重复。这保证了相同的提示被分配到不同的 GPU,从而在每个提示组内正确计算和归一化奖励。通过在多个进程中使用相同的种子,可以确保一致的提示分配,防止组形成中的差异
具体实现中,使用了 RepeatRandomSampler 类,该类会重复采样数据集中的索引def _get_train_sampler(self) -> Sampler: # Returns a sampler that ensures each prompt is repeated across multiple processes. This guarantees that # identical prompts are distributed to different GPUs, allowing rewards to be computed and normalized correctly # within each prompt group. Using the same seed across processes ensures consistent prompt assignment, # preventing discrepancies in group formation. return RepeatRandomSampler(self.train_dataset, self.num_generations, seed=self.args.seed) - 类似地,_get_eval_sampler 方法返回一个评估采样器。该采样器的工作方式与训练采样器相同,确保每个提示在多个进程中重复,从而在评估过程中正确计算和归一化奖励
- 最后,_get_per_token_logps 方法用于计算模型和reference模型的每个 token 的对数概率
首先,该方法接受四个参数:model 表示要计算对数概率的模型,input_ids 是输入的 token ID,attention_mask 是注意力掩码,logits_to_keep 表示要保留的 logits 数量
在方法内部,首先将 logits_to_keep 加 1,因为序列的最后一个 logits 会被排除。然后,调用模型的 `forward` 方法,传入 input_ids、attention_mask 和 logits_to_keep + 1,获取模型的 logits# 获取模型和参考模型的每个 token 的对数概率 def _get_per_token_logps(self, model, input_ids, attention_mask, logits_to_keep):
接着,排除序列的最后一个 logits,因为它对应的是下一个 token 的预测——这里 我解释一下,为何最后一个logit是对应下一个token的预测时,要排除掉呢?其实原因也很简单,比如对于输入序列A B C D,这4个token被预测的概率都对应一个logit,那很明显,预测出了token D后,模型还会会生成一个额外的第五个logits——对应于下一个token的预测概率,但这已经没有意义了,因为没有第五个token E去验证# 我们将 logits_to_keep 加 1,因为序列的最后一个 logits 会被排除 logits = model(input_ids=input_ids, attention_mask=attention_mask, logits_to_keep=logits_to_keep + 1).logits
接下来,调整 input_ids 的形状,只保留需要的 token ID# (B, L-1, V),排除最后一个 logits,因为它对应的是下一个 token 的预测 logits = logits[:, :-1, :]
且对于 transformers 版本小于等于 4.48 的情况,logits_to_keep 参数不被支持,因此需要手动丢弃多余的 logits。具体来说,调整 logits 的形状,只保留需要的 logitsinput_ids = input_ids[:, -logits_to_keep:] # 调整 input_ids 的形状,只保留需要的 token ID
最后,使用 selective_log_softmax 方法计算输入 token 的对数概率,并返回结果。selective_log_softmax 方法会对 logits 进行 softmax 计算,并返回每个 token 的对数概率# 对于 transformers 版本小于等于 4.48 的情况,logits_to_keep 参数不被支持,因此需要手动丢弃多余的 logits # 参见 https://github.com/huggingface/trl/issues/2770 logits = logits[:, -logits_to_keep:] # 调整 logits 的形状,只保留需要的 logits
最终,通过这种方式,_get_per_token_logps 方法能够有效地计算模型和reference模型的每个 token 的对数概率,为后续的奖励计算和模型评估提供必要的信息return selective_log_softmax(logits, input_ids) # 计算输入 token 的对数概率并返回结果
通过这些方法,`GRPOTrainer` 类能够有效地处理数据预处理、采样和对数概率计算,确保在训练和评估过程中正确计算奖励和其他度量指标
3.2.3 _move_model_to_vllm
_move_model_to_vllm,主要用于将模型移动到 vLLM(虚拟大语言模型)设备上。
- 首先,代码使用 unwrap_model_for_generation方法解包模型,以便进行生成操作。这个方法接受模型、加速器和 DeepSpeed Zero-3 参数作为输入,并返回解包后的模型对象 unwrapped_model
- 接下来,代码检查 unwrapped_model是否是编译模块(is_compiled_module)。如果是编译模块,则将其替换为原始模块(_orig_mod)
然后,代码检查 unwrapped_model 是否是 PEFT 模型(is_peft_model)。如果是 PEFT 模型,则需要合并适配器(merge_adapter),并获取模型的状态字典(state_dict)。在获取状态字典后,取消合并适配器(unmerge_adapter)
在处理状态字典时,代码移除 `base_model` 和 `base_layer` 前缀,并删除带有适配器前缀(例如 `_lora`)的值。最后,移除 `modules_to_save.default.` 前缀,并丢弃原始模块的条目
如果 unwrapped_model不是 PEFT 模型,则直接获取其状态字典 - 最后,如果当前进程是主进程(self.accelerator.is_main_process),则将状态字典加载到 vLLM 模型中。具体来说,获取 vLLM 模型对象,并调用其 load_weights方法,将状态字典中的权重加载到模型中
通过这种方式,_move_model_to_vllm方法确保模型的权重能够正确加载到 vLLM 设备上,以便进行高效的生成操作
3.2.4 _prepare_inputs:准备输入数据并生成模型的输出和奖励
prepare_inputs主要用于准备输入数据并生成模型的输出和奖励
- 首先,方法获取当前设备,并从输入数据中提取提示(prompts)和提示文本(prompts_text)
然后,使用处理类(self.processing_class)将提示文本转换为张量格式,并进行填充和其他预处理操作def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]: device = self.accelerator.device # 获取设备 prompts = [x["prompt"] for x in inputs] # 提取输入中的提示 prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs] # 应用聊天模板
接着,调用父类的 _prepare_inputs方法进一步处理这些输入,并提取 input_ids 和 attention_maskprompt_inputs = self.processing_class( prompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False ) # 处理提示文本prompt_inputs = super()._prepare_inputs(prompt_inputs) # 调用父类方法处理输入 prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"] # 获取输入ID和注意力掩码 - 如果设置了最大提示长度(self.max_prompt_length),则截断提示 ID 和掩码,使其不超过最大长度
if self.max_prompt_length is not None: prompt_ids = prompt_ids[:, -self.max_prompt_length :] # 截断提示ID prompt_mask = prompt_mask[:, -self.max_prompt_length :] # 截断提示掩码 - 接下来,方法根据是否使用 vLLM(self.args.use_vllm)选择不同的生成路径
然后,将生成的完成文本广播到所有进程,并确保每个进程接收到相应的切片# 使用vLLM生成补全:收集所有提示并在主进程中一次性调用 all_prompts_text = gather_object(prompts_text) # 收集所有提示文本 if self.accelerator.is_main_process: outputs = self.llm.generate(all_prompts_text, sampling_params=self.sampling_params, use_tqdm=False) # 生成输出 completion_ids = [out.token_ids for completions in outputs for out in completions.outputs] # 获取补全ID else: completion_ids = [None] * len(all_prompts_text) # 初始化补全ID
最后,将完成文本填充并与提示文本连接# 从主进程广播补全到所有进程,确保每个进程接收其对应的切片 completion_ids = broadcast_object_list(completion_ids, from_process=0) # 广播补全ID process_slice = slice( self.accelerator.process_index * len(prompts), (self.accelerator.process_index + 1) * len(prompts), ) # 计算进程切片 completion_ids = completion_ids[process_slice] # 获取进程切片的补全ID# 填充补全,并将其与提示连接 completion_ids = [torch.tensor(ids, device=device) for ids in completion_ids] # 转换补全ID为张量 completion_ids = pad(completion_ids, padding_value=self.processing_class.pad_token_id) # 填充补全ID prompt_completion_ids = torch.cat([prompt_ids, completion_ids], dim=1) # 连接提示和补全ID
然后,计算提示长度,并提取完成 IDelse: # 常规生成路径 with unwrap_model_for_generation(self.model, self.accelerator) as unwrapped_model: prompt_completion_ids = unwrapped_model.generate( prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config ) # 生成提示补全ID# 计算提示长度并提取补全ID prompt_length = prompt_ids.size(1) # 获取提示长度 prompt_ids = prompt_completion_ids[:, :prompt_length] # 提取提示ID completion_ids = prompt_completion_ids[:, prompt_length:] # 提取补全ID - 接下来,方法对生成的完成文本进行后处理
首先,掩码掉第一个 EOS(结束)token之后的所有内容
然后,将提示掩码与完成掩码连接,以便后续计算 logits# 在第一个EOS标记后屏蔽所有内容 is_eos = completion_ids == self.processing_class.eos_token_id # 检查是否为EOS标记 # 初始化EOS索引 eos_idx = torch.full((is_eos.size(0),), is_eos.size(1), dtype=torch.long, device=device) # 更新EOS索引 eos_idx[is_eos.any(dim=1)] = is_eos.int().argmax(dim=1)[is_eos.any(dim=1)] # 生成序列索引 sequence_indices = torch.arange(is_eos.size(1), device=device).expand(is_eos.size(0), -1) # 生成补全掩码 completion_mask = (sequence_indices <= eos_idx.unsqueeze(1)).int()# 将提示掩码与补全掩码连接以进行logit计算 attention_mask = torch.cat([prompt_mask, completion_mask], dim=1) # 连接提示掩码和补全掩码 - 在推理模式下,计算reference模型或当前模型的每个 token 的对数概率
然后,解码生成的完成文本。如果输入数据是对话形式,则将完成文本与提示文本结合,生成对话形式的完成文本# 只需计算补全token的logits logits_to_keep = completion_ids.size(1) with torch.inference_mode(): if self.ref_model is not None: ref_per_token_logps = self._get_per_token_logps( self.ref_model, prompt_completion_ids, attention_mask, logits_to_keep ) # 获取参考模型的每个token的log概率 else: with self.accelerator.unwrap_model(self.model).disable_adapter(): ref_per_token_logps = self._get_per_token_logps( self.model, prompt_completion_ids, attention_mask, logits_to_keep ) # 获取模型的每个token的log概率# 解码生成的补全 completions_text = self.processing_class.batch_decode(completion_ids, skip_special_tokens=True) # 解码补全文本 if is_conversational(inputs[0]): completions = [] for prompt, completion in zip(prompts, completions_text): bootstrap = prompt.pop()["content"] if prompt[-1]["role"] == "assistant" else "" # 获取引导内容 completions.append([{"role": "assistant", "content": bootstrap + completion}]) # 生成对话补全 else: completions = completions_text # 生成补全文本 - 接下来,方法计算每个奖励函数的奖励
对于每个奖励函数,如果是模块(nn.Module),则将提示和完成文本转换为文本格式,并使用处理类进行预处理
然后,计算奖励并存储在 rewards_per_func中
如果奖励函数是自定义函数,则直接调用该函数计算奖励# 初始化每个函数的奖励 rewards_per_func = torch.zeros(len(prompts), len(self.reward_funcs), device=device) for i, (reward_func, reward_processing_class) in enumerate( zip(self.reward_funcs, self.reward_processing_classes) ): # 模块而不是预训练模型以兼容编译模型 if isinstance(reward_func, nn.Module): if is_conversational(inputs[0]): messages = [{"messages": p + c} for p, c in zip(prompts, completions)] # 生成消息 texts = [apply_chat_template(x, reward_processing_class)["text"] for x in messages] # 应用聊天模板 else: # 生成文本 texts = [p + c for p, c in zip(prompts, completions)] # 处理奖励输入 reward_inputs = reward_processing_class( texts, return_tensors="pt", padding=True, padding_side="right", add_special_tokens=False ) # 调用父类方法处理输入 reward_inputs = super()._prepare_inputs(reward_inputs) with torch.inference_mode(): # 获取奖励函数的logits rewards_per_func[:, i] = reward_func(**reward_inputs).logits[:, 0]else: # 重复所有输入列(但“prompt”和“completion”除外)以匹配生成的数量 # 获取输入键 keys = [key for key in inputs[0] if key not in ["prompt", "completion"]] # 生成奖励参数 reward_kwargs = {key: [example[key] for example in inputs] for key in keys} # 调用奖励函数 output_reward_func = reward_func(prompts=prompts, completions=completions, **reward_kwargs) # 转换奖励为张量 rewards_per_func[:, i] = torch.tensor(output_reward_func, dtype=torch.float32, device=device) - 根据上文第二部分所介绍的GRPO算法流程,其中的第一种优势函数的设计是使用GRPO的结果监督强化学习
首先,对于每个问题,通过旧策略模型采样一组输出
Formally, for each question 𝑞, a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺 } are sampled from the old policy model 𝜋𝜃𝑜𝑙𝑑 .
其次,使用奖励模型对每个输出进行评分,从而得到G个奖励
A reward model is then used to score the outputs, yielding 𝐺 rewards r = {𝑟1, 𝑟2, · · · , 𝑟𝐺 } correspondingly
故方法还会收集每个奖励函数,并对其进行归一化和加权计算
然后,计算分组奖励的均值# 收集每个函数的奖励:这部分很关键,因为奖励是按组归一化的,补全可能分布在多个进程中 rewards_per_func = gather(rewards_per_func) # 收集奖励 # 将权重应用于每个奖励函数的输出并求和 rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).sum(dim=1) # 计算总奖励和标准差
接下来,便可以使用这些值归一化奖励以计算优势(advantages),对应的公式为上文提到的# 计算分组奖励 mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1) # 计算分组平均奖励 # 计算分组标准差奖励 std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)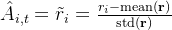
# 归一化奖励以计算优势 mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0) # 重复分组平均奖励 std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0) # 重复分组标准差奖励 advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4) # 计算优势 - 最后,方法记录度量指标,并在需要时进行日志记录。返回的字典包含提示 ID、提示掩码、完成 ID、完成掩码、reference模型的对数概率和优势
通过这种方式,_prepare_inputs方法确保输入数据得到正确处理,并生成模型的输出和奖励,为后续的训练和评估提供必要的信息
3.2.5 compute_loss:计算模型的损失
- 首先,方法接受四个参数:`model` 表示要计算损失的模型,`inputs` 是输入数据,`return_outputs` 指示是否返回输出(在此方法中不支持),`num_items_in_batch` 是批次中的项目数量
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None): - 方法开始时检查 `return_outputs` 是否为 `True`,如果是,则抛出一个 `ValueError` 异常,因为 `GRPOTrainer` 不支持返回输出
if return_outputs: raise ValueError("The GRPOTrainer does not support returning outputs") # 如果需要返回输出,则抛出异常 - 接下来,方法从输入数据中提取提示 ID(`prompt_ids`)和提示掩码(`prompt_mask`),以及完成 ID(`completion_ids`)和完成掩码(`completion_mask`)
然后,将提示 ID 和完成 ID 连接起来,形成完整的输入 ID(`input_ids`),并将提示掩码和完成掩码连接起来,形成完整的注意力掩码(`attention_mask`)# 获取提示ID和提示掩码 prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"] # 获取补全ID和补全掩码 completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"]# 连接提示ID和补全ID input_ids = torch.cat([prompt_ids, completion_ids], dim=1) # 连接提示掩码和补全掩码 attention_mask = torch.cat([prompt_mask, completion_mask], dim=1) # 我们只需要计算补全token的logits logits_to_keep = completion_ids.size(1) - 方法调用 `_get_per_token_logps` 计算模型的每个 token 的对数概率
然后,从输入数据中提取reference模型的每个 token 的对数概率(`ref_per_token_logps`),并计算模型和reference模型之间的 KL 散度(`per_token_kl`)# 获取每个token的log概率 per_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep)
可能有同学疑问为何要这样,对此,可以回顾下本文第二部分的相关内容# 计算模型和参考模型之间的KL散度 ref_per_token_logps = inputs["ref_per_token_logps"] # 获取参考模型的每个token的log概率 # 计算KL散度 per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1
- 接下来,方法从输入数据中提取优势(`advantages`),并计算每个 token 的损失
具体来说,计算模型对数概率与其分离版本之间的差异,并乘以优势
然后,减去 KL 散度的加权值(`self.beta * per_token_kl`),并取负值# x - x.detach() 允许保留x的梯度 advantages = inputs["advantages"] # 获取优势 per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1) # 计算每个token的损失
最终的损失是每个 token 损失的加权平均值per_token_loss = -(per_token_loss - self.beta * per_token_kl) # 计算总损失
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean() # 计算平均损失 - 方法还记录了一些度量指标,包括完成长度和 KL 散度的均值
完成长度是完成掩码中非零元素的平均值
KL 散度的均值是每个 token KL 散度的加权平均值# 记录指标,计算补全长度 completion_length = self.accelerator.gather_for_metrics(completion_mask.sum(1)).float().mean().item() # 记录补全长度 self._metrics["completion_length"].append(completion_length)
# 计算平均KL散度 mean_kl = ((per_token_kl * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean() # 记录KL散度 self._metrics["kl"].append(self.accelerator.gather_for_metrics(mean_kl).mean().item()) - 最后,方法返回计算得到的损失值
return loss # 返回损失
通过这种方式,compute_loss方法能够有效地计算模型的损失,并记录相关的度量指标,为模型的训练和评估提供必要的信息
3.2.6 prediction_step:预测步骤中计算损失
首先,方法接受四个参数:model表示要进行预测的模型,inputs 是输入数据,prediction_loss_only 指示是否只返回损失,ignore_keys是一个可选的列表,用于指定在输出中忽略的键
方法开始时调用 _prepare_inputs方法对输入数据进行预处理。这个方法会根据输入数据生成提示和完成文本,并进行必要的预处理操作
接下来,方法使用 torch.no_grad()上下文管理器禁用梯度计算,以确保在预测步骤中不会计算梯度。这有助于减少内存使用并加快计算速度。
在禁用梯度计算的上下文中,方法使用 compute_loss_context_manager上下文管理器计算损失。具体来说,调用 compute_loss方法计算模型的损失
compute_loss方法会根据输入数据和模型计算每个 token 的对数概率、KL 散度和最终的损失值。计算损失后,方法将损失的均值取出并分离(detach)以确保不会计算梯度
最后,方法返回损失值以及两个 `None` 值,因为在预测步骤中只需要返回损失。
通过这种方式,prediction_step方法能够在预测过程中有效地计算模型的损失,并确保不会计算梯度,从而提高预测步骤的效率
此外,最后还有两个函数的实现
- log:记录训练和评估过程中的度量指标
- create_model_card,用于生成模型卡片的草稿。模型卡片包含有关模型和训练过程的详细信息,便于分享和复现
// 待更
3.3 对GRPO包的使用
3.3.1 DeepSeek R1中的格式奖励函数
经过此文《一文速览火爆全球的推理模型DeepSeek R1:如何通过纯RL训练以比肩甚至超越OpenAI o1(含Kimi K1.5的解读)》可知,R1中有个格式奖励的函数,专为对话格式而设计
import re
def format_reward_func(completions, **kwargs):
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]可以如此测试是否完成
prompts = [
[{"role": "assistant", "content": "What is the result of (1 + 2) * 4?"}],
[{"role": "assistant", "content": "What is the result of (3 + 1) * 2?"}],
]
completions = [
[{"role": "assistant", "content": "<think>The sum of 1 and 2 is 3, which we multiply by 4 to get 12.</think><answer>(1 + 2) * 4 = 12</answer>"}],
[{"role": "assistant", "content": "The sum of 3 and 1 is 4, which we multiply by 2 to get 8. So (3 + 1) * 2 = 8."}],
]
format_reward_func(prompts=prompts, completions=completions)// 待更


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











