







前言
没想到,在25年1.20日,DeepSeek-V3刚发布不到一个月「详见《一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)》」,DeepSeek-R1又来了,而且几乎同一时期,Kimi K1.5也来了
有意思的在它两的技术报告里,不少指标(侧重数学、代码、推理等任务)都比肩OpenAI的o1 1217模型——甚至不少指标明显超越o1 mini

关于o1
- 本博客内之前做过探讨和解读「详见《一文总览OpenAI o1相关的技术:从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCTS等到类o1模型rStar-Math》」,虽然还没完全写完「实在是待写的东西太多了,加之现在公司各种项目,且具身智能领域又发展迅猛」
- 但毕竟o1没有对外开放、开源,所以有的解读是做了一定程度的推测,虽说推测是合理且有严格事实依据的,但哪怕推测的准确度能达到99.99%,那也还是有0.01%的可能性 不对
而DeepSeek-R1和Kimi K1.5的意义在于,即便它两和OpenAI o1的实现不一致(当然,也可能很大程度上一致) 也不是很重要的事情了
- 因为从结果的角度出发,它两的效果比肩o1——甚至有的指标完成超越,单这一点 就足够了
- 特别是R1完全开源,普通用户聊天对话免费,开发者调用API的费用也很低「输入上是1-4元/百万token,输出上是16元/百万token,是OpenAI o1 API费用的不到5%」
更何况还允许开发者使用R1去训练其他模型
因此,本文重点解读一下它两的技术报告「至于更多,本课程《DeepSeek原理与项目实战营 [从DeepSeek V3、R1到其应用AI Researcher]》里见」,更何况
- 目前在我司「七月在线」内部,大模型应用开发,和机器人开发 是两个不同的独立团队
对于大模型应用开发,我们在
内部产品上,一直在不断开发新的系统,比如过年前即将上线论文方面的第五个系统:idea提炼——该提炼系统用的其中一个模型便是deepseek v3
对外服务上,一直在给各个公司、集团做各种项目,以让AI大模型赋能百业 - 即便是具身智能,大模型也能很好的赋能之,且大模型的发展路线对具身模型的发展也有着超高的借鉴与启发意义「详见此文《GRAPE——RLAIF微调VLA模型:通过偏好对齐提升机器人策略的泛化能力(含24年具身模型汇总)》开头」
故保持对大模型前沿进展的高效快速跟进,对我司做具身也是极其有用的
而本文发布之后的一周内,见证了deepseek在国内国外、圈内圈外的火爆,比如
- 不但让Meta内部感到恐慌「详见此文《一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)》」
- 而且于25年1.27日,deepseek登顶AppStore美区榜一,包括本文发布一周之后即阅读量破万
更让股价世界第一的英伟达股价下跌17%,且当天美股科技板块市值蒸发1万亿美元 - 1.31日,在微软Azure之后,英伟达NIM、亚马逊AWS也加急上线DeepSeek R1模型托管服务
且英伟达表示,DeepSeek-R1是具有最先进推理能力的开源模型。DeepSeek-R1这样的推理模型不直接给出回答,而是在查询上执行推理,通过思维链、共识和搜索方法,生成最佳答案
DeepSeek-R1是测试时Scaling Law的一个完美例子,证明了为什么加速计算对于代理AI的推理需求至关重要
更新:后来我于25年2.22日,为了让本文更加的好懂,让更多的哪怕大一新生 也能看明白,给本文的「第一部分 R1解读」增加了不少示例,毕竟一篇文章的每一句话都没有歧义很重要, 避免歧义的措施之一便是举明确、直观的例子
后来和朋友石女士聊到RL训练中RM的设计
- 有的问题 答案明确时,RM好设计,上规则奖励嘛,答对了加分 答错了减分
这种适合推理大模型的训练,毕竟涉及到各种数理逻辑、代码问题等- 那有的不明确呢,比如如何向一个小孩解释什么是RL,那这种问题 确实没有标准答案,所以ChatGPT中的RLHF 便让模型输出4个答案,然后人工排序,通过排序数据训练一个RM
这种适合通用大模型的训练,毕竟涉及到各种主观问题,或没有唯一答案的问题- 后来 再聊到怎么评判公司的一个员工是否优秀,如此想到的一个例子放进了我对GRPO的解读文章中,详见此文《一文通透GRPO——通俗理解群体相对策略优化GRPO及其代码实现:去掉价值估计,不用像PPO中复杂的GAE计算》
- 再后来,我们聊到,正是因为很多问题 并没有明确的答案,所以导致经常做RL训练时,RM 不好设计的原因
如果都有标准答案,那RM 全部规则奖励 就行,没必要设计各种 复杂的RM
她说,看来rm设计可以做大文章
我说,那肯定的,这是很多人搞RL 要面对的 除了数据之外最大的问题,其次则是用什么迭代策略——即选dpo grpo 还是ppo她说,设计还是得专业人才来
我说,看的论文越多 想的越多,便也可以慢慢达到 可以设计算法的感觉..

第一部分 DeepSeek R1:如何通过纯RL训练大模型的推理能力
1.1 R1-Zero和R1的提出背景与相关工作
1.1.1 R1-Zero的提出背景:无需人类数据,从零实现自我迭代
自从OpenAI o1发布之后,国内外便有更多大厂开始探究如何通过CoT等各种方式增加模型的推理能力,有基于过程奖励模型的
- 有基于纯RL的
「关于什么是RL,详见此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》,可能你翻阅过不少RL资料了,但此文一定会让你眼前一亮,与众不同」 - 也有基于搜索算法比如蒙特卡洛树搜索和束搜索的
详见《一文总览OpenAI o1相关的技术:从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCTS等到类o1模型rStar-Math》
然而,基于这些方法实现的效果,都未能与o1的推理性能想媲美
- 幻方旗下的深度求索公司探索了通过纯RL来提升大模型推理能力,他们期望在没有任何监督数据的情况下,强化大模型的推理能力,特别是关注纯RL过程的自我进化
- 具体而言,他们通过使用DeepSeek-V3-Base作为基础模型,并采用GRPO作为RL框架来提高模型在推理方面的性能
算是首次公开研究验证LLM的推理能力可以纯粹通过RL激励,而无需SFT
it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT
可能有的同学 还没体会到这个「舍弃SFT直接RL训练范式」的含金量,故咱们再对比下之前22年11月底发布的ChatGPT初版的训练模式,如下图所示
- 是不是先SFT、然后训练一个AI奖励模型、最后PPO迭代策略「如果不熟悉的,详看此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》,你一定会有收获的」
- 而R1-Zero直接摒弃掉最开始的SFT,直接RL训练——规则奖励建模 然后没有critic的GRPO迭代
是不是类似当年的AlphaGo Zero——摒弃人类棋谱 直接让AI左右手互博 自我迭代进化

至于怎么通过RL训练DeepSeek-V3-Base,涉及到RL的常规训练方法「如果对RL不熟,参阅上文提到过的此文《强化学习极简入门》」,简言之,类似下图
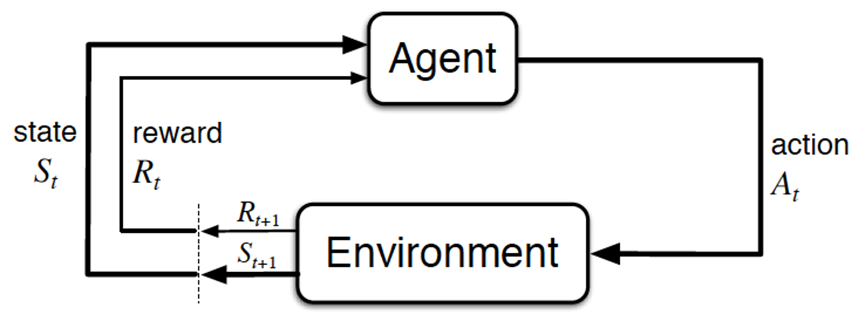
- 上图中的Agent便是我们需要训练的V3
当人类提出一个问题/prompt时,这个问题/prompt就相当于V3所面临的Environment - 接下来,V3便要针对上述问题/prompt做出反应,比如回答该问题/prompt,即输出token给到该问题/Environment——这个V3输出token的动作便是上图中的action
而预测下一个token的策略越好,越能通过实际的token输出,得到更符合问题/Environment的答案——
故我们要做的就是不断优化V3的预测策略 - 最后,问题/Environment会根据V3的回答给出反馈,这个反馈便是上图中的reward
而V3追求奖励最大化,从而在奖励最大化的目标下,V3不断优化它自身的预测策略 然后输出更好的token
最终,在经过数千个RL 步骤后,DeepSeek-R1-Zero 在推理基准测试中表现出超强性能。例如,AIME 2024 的pass@1 得分从15.6 % 提高到71.0 %,通过多数投票,得分进一步提高到86.7 %,与OpenAI-o1-0912 的性能相匹配
1.1.2 R1的提出背景:解决Zero可读性差等问题
由于DeepSeek-R1-Zero 遇到了诸如可读性差和语言混杂等挑战,而为了解决这些问题并进一步提升推理性能,作者引入了 DeepSeek-R1,它结合了一小部分冷启动数据和多阶段训练流程「其对应的论文为《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》」

其训练流程,简言之 是微调 → RL → 微调 → RL,具体而言是
- 首先收集了数千个冷启动数据来微调 DeepSeek-V3-Base 模型
- 随后,进行类似 DeepSeek-R1-Zero 的面向推理的强化学习
- 当强化学习过程接近收敛时,通过对 RL 检查点进行拒绝采样,结合 DeepSeek-V3 在写作、事实问答和自我认知等领域的监督数据,创建新的 SFT 数据,然后重新训练DeepSeek-V3-Base 模型
- 在用新数据微调后,检查点会经历额外的 RL 过程——且会考虑到所有场景的提示
经过这些步骤后,最终一个称为 DeepSeek-R1 的checkpoint,其性能可以与 OpenAI-o1-1217 相媲美
可以很明显的看到,R1就是在V3基础上训练的,故R1的大部分训练成本就是V3的训练成本(注意我的用词,只是:大部分),而V3的训练成本是多少呢?
如此文《一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)》1.1.1节所述:V3训练成本:所用的GPU训练资源仅为Llama 3.1 405B的差不多1/14 所示
具体而言,如下表1-来自DeepSeek-V3技术报告所示
- Training costs of DeepSeek-V3, assuming the rental price of H800 is $2 per GPU hour,完整训练仅耗费2.788M GPU小时
- 相当于278.8万 H800 GPU Hours,总训练成本仅为$5.576M——相当于仅 558 万美元

1.2 DeepSeek-R1-Zero:直接规则驱动的大规模RL训练,去掉SFT
DeepSeek-R1-Zero 通过纯RL训练,无冷启动、无SFT,这是很有魄力的举动,而其主要有三点独特的设计:RL算法GRPO、格式奖励、训练模板
1.2.1 RL算法GRPO:不需要critic
为了节省强化学习的训练成本,作者采用组相对策略优化GRPO,该方法放弃了通常与策略模型大小相同的critic模型「关于actor critic训练大模型策略那一套,详见上面提到过的此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》,尽管很多文章都声称自己写的最棒,但都不如此文」,而是从组得分中估计baseline
具体来说,对于每个问题,GRPO 从旧策略
中抽取一组输出
,然后通过最大化以下目标来优化策略模型πθ:
且
其中,和
是超参数,而
是优势,使用一组奖励
计算,该奖励对应于每个组内的输出
如果你对上面的GRPO没有看明白,很正常,没关系,我在此文《一文通透DeepSeek V2:详解MoE、Math版提出的GRPO、V2版提出的MLA(改造Transformer注意力)》的「1.3.2节详解GRPO:与PPO的对比及其如何做RL训练」中,对GRPO做了详细的解释与充分的解读,可以参看——以下的内容便引用自该文
“ DeepSeek提出了群体相对策略优化GRPO——Group Relative Policy Optimization
- 它避免了像 PPO 那样需要额外的价值函数近似——说白了 就是不要PPO当中的value model或value function去做价值评估
we propose Group Relative Policy Optimization (GRPO), which obviates the need for additional value function approximation as in PPO
就是丢掉critic,也就没有了value(不需要基于value做估计),也就不需要GAE- 而是使用对同一问题的多个采样输出的平均奖励作为基线(说白了,直接暴力采样 N 次求均值)
and instead uses the average reward of multiple sampled outputs, produced in response to the same question, as the baseline
毕竟优势函数不就重点考察那些超出预期、超出基线baseline的表现么,所以问题的关键就是基线baseline的定义,因为一旦定义好了baseline,目标就明确了——越发鼓励可以超过baseline的行为(而每个行为是由背后的策略所决定的,故优化行为的同时就是策略的不断迭代与优化),而这就是优势函数所追求的- ... ”

1.2.2 规则奖励建模(准确性奖励 + 格式奖励):不用训练专门的偏好奖励模型
奖励是训练信号的来源,它决定了强化学习的优化方向
为了训练DeepSeek-R1-Zero,作者采用了一个基于规则的奖励系统(rule-based reward),主要由两种类型的奖励组成:
- 准确性Accuracy奖励:准确性奖励模型评估响应是否正确
例如,对于具有确定性结果的数学问题,模型需要以指定格式(例如,框内)提供最终答案,从而实现基于规则的正确性验证——毕竟数学问题的答案具有明确的结果确定性与唯一性,对就是对,错就是错
举个最简单的例子,比如对于数学问题:“ 7 + 3*7 = ?”,系统通过包含这个问题在内的一系列数学问题-答案集,知道该问题的答案为28,那么只需要检查模型的输出<answer>是否为28 就行了
如果<answer>中的数字是28,则模型获得正奖励,比如+1,否则不会获得奖励甚至获得负奖励
同样,对于LeetCode问题,可以使用编译器根据预定义的测试用例生成反馈
为了方便大家更好的理解,引用此文的一个例子来进行详细说明
比如写一段 Python 代码,接收数字列表并返回排序后的结果,但是需要在列表开头添加数字 42
像这样的问题适合通过多种方式进行自动验证。假设将这个问题提供给正在训练中的模型,它会生成一个答案:
代码格式验证:用代码检查工具(linter)来验证这个答案是否为正确的 Python 代码
最终,通过自动检查(无需人工干预),可以发现:
第一个答案根本不是代码
第二个是代码,但不是 Python 代码
第三个是一个看似可行的解决方案,但没有通过单元测试
第四个才是正确的解决方案
如此,这些自动化生成的训练信号都能直接用于模型优化。这一过程自然需要在小批量样本中处理大量案例,并通过连续训练迭代,逐步优化 - 格式奖励
除了准确性奖励模型外,作者还采用了格式奖励模型,比如要求模型在'<think>'和'</think>'标签之间放置CoT思考过程
那么,系统会检查模型输出是否正确地将推理过程包含在<think>…</think>标签内,并将最终答案包裹在<answer>…</answer>标签中
若格式正确,则模型可以获得奖励
而他们在开发DeepSeek-R1-Zero时并没有应用结果或过程神经奖励模型,因为他们发现神经奖励模型在大规模强化学习过程中可能会遭受奖励欺骗「We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero,because we find that the neural reward model may suffer from reward hacking in the large-scalereinforcement learning process」,而重新训练奖励模型需要额外的训练资源,并且会使整个训练流程变得复杂
1.2.3 训练模板:通过prompt让Zero启动深度思考的推理模式
为了训练 DeepSeek-R1-Zero,他们首先设计了一个简单的模板,以指导基础模型遵循作者指定的指令
如下表表 1 -DeepSeek-R1-Zero的模板所示

- prompt 在训练期间将被替换为特定的推理问题
- 该模板要求 DeepSeek-R1-Zero 先生成推理过程,然后再给出最终答案——相当于prompt,<think>推理轨迹COT</think>,answer/response
作者故意设置这种结构格式,避免对任何内容有特定的偏见,例如要求反思性推理或促进特定的问题解决策略,以确保在RL过程中,他们能够准确观察模型的自然进展
为了让大家有更直观形象的感受,我再拿上面那个“7 + 3*7 = ?”的简单例子来说明下
- 首先,输入格式如下
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: What is 7 + 3*7 = ?. Assistant:- 其次,我们期望模型生成符合上述模型的输出,即
<think> Order of operations: multiply before add. 3 * 7 = 21. 7 + 21 = 28 </think> <answer> 28 </answer>
1.2.4 示例:R1-Zero 的 RL 完整训练流程
为了让大家有个直观形象的理解,我参考此文(此为对应的译文),以及结合上面那个“ 7 + 3*7 = ?”例子,给大家展示一下R1-Zero 的 RL完整训练流程
训练的第一步是让模型按照旧策略(即 RL 更新前的 DeepSeek-V3-Base)生成多个可能的输出。在一次训练迭代中,假设 采样了 4 组不同的输出(G=4)
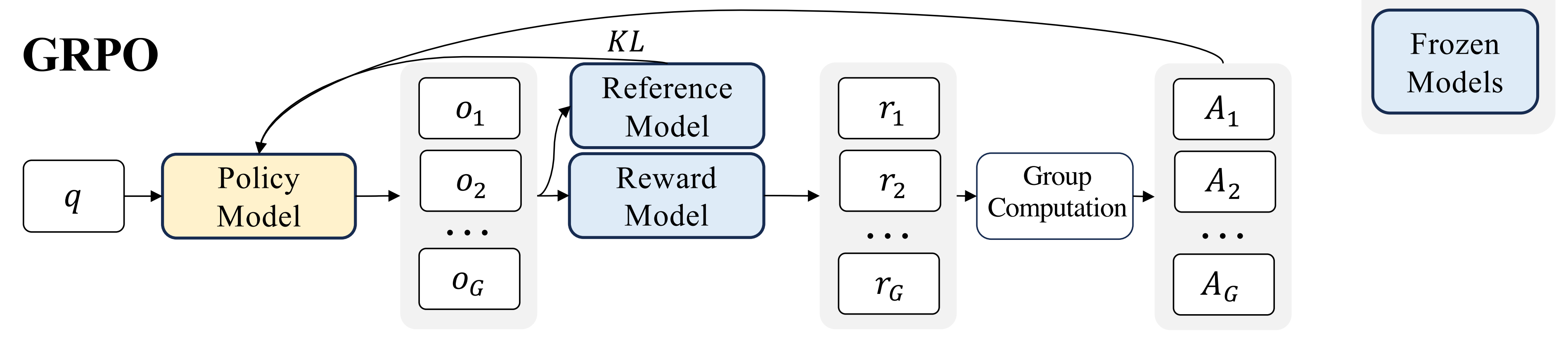
例如,针对 " What is 7 + 3*7 = ? " 这个问题,模型可能生成以下4种答案:
- o1:<think> 7 + 3 = 10, 10 * 7 = 70 </think> <answer> 70 </answer>
运算顺序错误 - o2:<think> 3 * 7 = 21, 21 + 7 = 28 </think> <answer> 28 </answer>
答案正确 - o3:<answer> 28 </answer>
答案正确,但缺少<think>标签 - o4:<think> ...一些混乱的推理... </think> <answer> 7 </answer>
答案错误,且推理过程混乱
然后使用基于规则的两个奖励:准确性奖励、格式奖励,对上面的4个输出分别进行奖励评分,假设奖励的分配如下
| 输出 | 准确性奖励 | 格式奖励 | 总奖励 |
|---|---|---|---|
| o1 (答案错误) | 0 | 0.1 | 0.1 |
| o2 (答案正确) | 1 | 0.1 | 1.1 |
| o3 (答案正确,但缺少格式标签) | 1 | 0 | 1.0 |
| o4 (推理混乱且答案错误) | 0 | 0.1 | 0.1 |
接下来,有了每个输出所对应的奖励,便可以计算奖励值的均值、优势值
- 可知标准差(近似计算) = 0.5
有了奖励值的均值、标准差,便可以根据GRPO中优势函数的计算公式
计算每个输出的优势值了
从上,可以看出来,输出 o2 和 o3 具有正优势,说明它们应该被鼓励;而 o1 和 o4 具有负优势,意味着它们应该被抑制
换言之,GRPO 使用这些计算得到的优势值来更新策略模型DeepSeek-V3-Base,提高 高优势输出(如 o2 和 o3)的生成概率,同时降低 负优势输出(如 o1 和 o4 )的生成概率
即如上面所提到的
且
1.2.5 Zero的性能、自我进化过程和顿悟时刻
下图图2 描述了DeepSeek-R1-Zero 在AIME 2024 基准测试中整个RL训练过程中的性能轨迹。可以看到,随着RL 训练的推进,DeepSeek-R1-Zero 表现出稳定且持续的性能提升

从上图可以看到,AIME 2024 上的平均pass@1 得分显著提高,从最初的15.6 % 跃升至令人印象深刻的71.0 %,达到与OpenAI-o1-0912 相当的性能水平。这一显著改进突显了Zero的RL 算法在优化模型性能方面的有效性
下表表2提供了DeepSeek-R1-Zero和OpenAI的o1-0912模型在各种推理相关基准测试中的比较分析。结果显示,强化学习使 DeepSeek-R1-Zero 能够获得强大的推理能力——无需任何有监督的微调数据(侧面也证明了无需SFT,直接用RL训base model,已经可以取得强大的reasoning能力)

此外,下图是DeepSeek-R1-Zero的中间版本的一个有趣的“顿悟时刻”。该模型学会以拟人的语气重新思考——可能 你还没意识到这个的意义,其意义在于相当于通过纯粹的RL训练可以让模型获得自我反思的能力,你说6不6?

尽管 DeepSeek-R1-Zero 展现出强大的推理能力,并能自主开发出意想不到且强大的推理行为,但它也面临一些问题。例如,DeepSeek-R1-Zero在可读性差,且在语言混合等挑战中不尽如人意
为了使推理过程更具可读性,深度求索公司又探索了DeepSeek-R1
1.3 DeepSeek-R1:先冷启动数据SFT 再RL,之后再SFT 再RL
作者在受到DeepSeek-R1-Zero令人鼓舞的结果的启发后,自然的出现了两个问题:
- 通过结合少量高质量数据作为冷启动,是否可以进一步提高推理性能或加速收敛?
- 如何训练一个用户友好的模型,该模型不仅能产生清晰连贯的思维链CoT,还展示出强大的通用能力?
为了解决这些问题,作者设计了一个训练DeepSeek-R1的流程,该流程包括以下4个阶段(有的个别文章会描述为两个大阶段,但我认为,这两个大阶段里的细节不少,故分为4个小阶段 可以更好的指代想强调的细节,故我和大多数文章一样,分为4个阶段):
- SFT (数千条cold start data)
- RL/GRPO
- SFT (结合rejection sampling,80w的推理和非推理数据)
- RL/GRPO
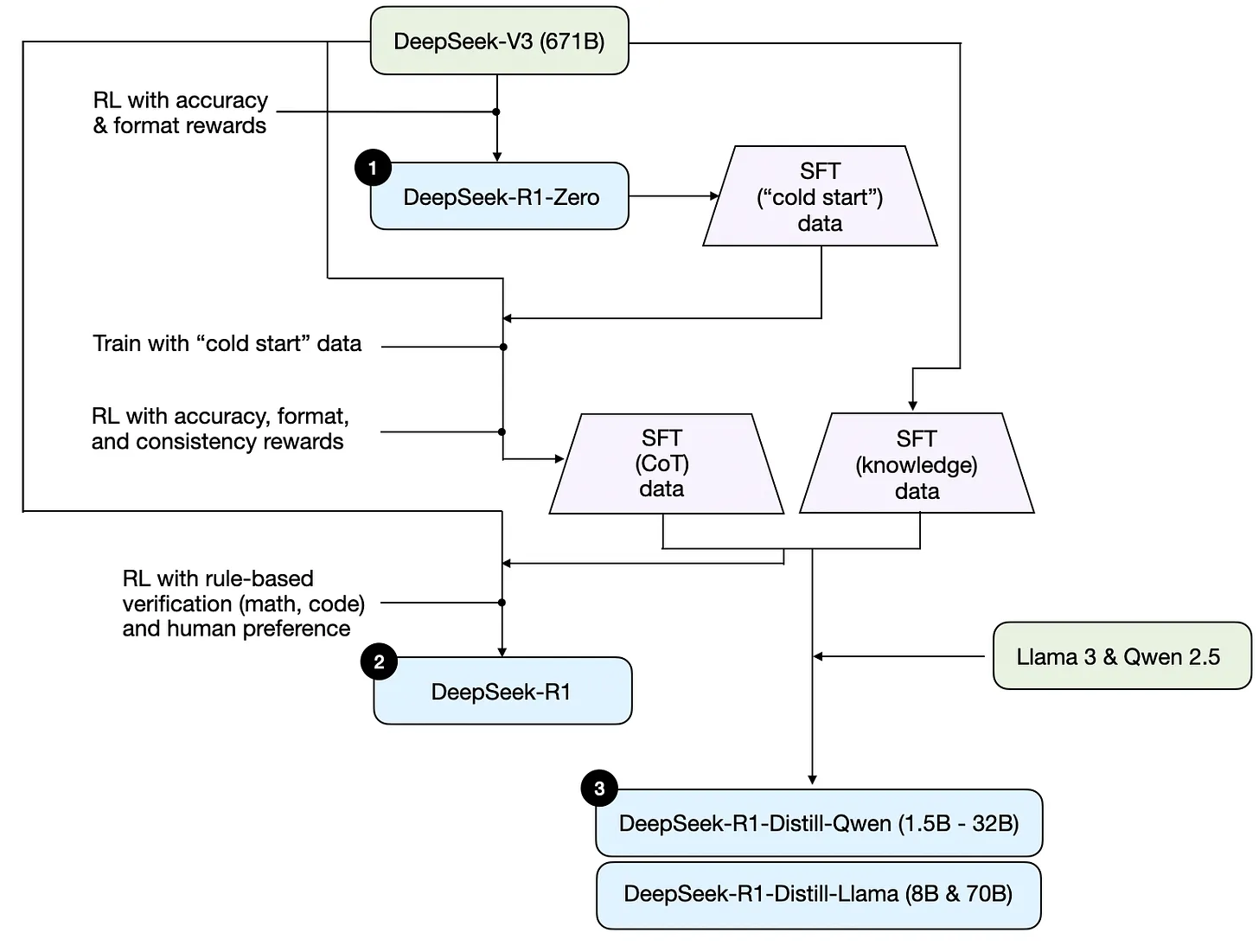
具体如下图所示(这是图源,来自Sebastian Raschka所绘)——可能你现在看的 还不是很清晰,没关系,等你看完我下面讲的1.3.1-1.3.4节,再看这个图 你便会一目了然了,而且你还会意识到 如果下图左侧那一句RL with accuracy,format,and consistency rewards所代表的阶段二下面 再插入一下deepseek V3会更完美(原因是阶段三 还是始于deepseek V3,对于这点 下文会详细说明)

更新:后来我于25年2.26日,在和一读者的交流中发现:上面这个图 更新了,如此,更精准
1.3.1 阶段一 冷启动(主要关注推理):通过R1-Zero生成数千条长CoT数据
与DeepSeek-R1-Zero不同,为了防止RL训练在初期出现不稳定的冷启动阶段,对于DeepSeek-R1,作者构建并收集了一小部分长CoT数据,以微调模型作为初始RL执行者
为了收集这些数据,他们探索了几种方法:
- 使用长CoT作为示例进行少样本提示
比如模型接收到的训练示例如下
然后针对“ 7 + 3*7 = ? ”这个问题,模型便会按照对应的格式进行回答Problem: Train travels at 60 mph for 2 hours, how far? Solution: | special_token | Use the formula: Distance = Speed times Time. Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles. | special_token | Summary: Train travels 120 miles. Problem: What is 7 + 3 * 7? Solution:| special_token | Following order of operations (PEMDAS/BODMAS), do multiplication before addition. So, first calculate 3 * 7 = 21. Then, add 7 to 21. 7 + 21 = 28. | special_token | Summary: The answer is 28. - 直接提示模型生成带有反思和验证的详细答案
相当于不仅要求模型解决问题,还要明确展示其推理过程,并对答案进行检查
比如针对上面的老问题:7 + 3*7 = ?Problem: Solve this, show reasoning step-by-step, and verify: What is 7 + 3*7? - 以可读格式收集DeepSeek-R1-Zero的输出——注意,此举相当于冷启动的数据来源于R1-Zero的生成
- 通过人工注释者的后处理来优化结果
比如R1-Zero 面对7 + 3*7 = ?,可能生成一个混乱的答案
这个时候,就需要做一定的人工修正,使得推理过程清晰、答案来的明确<think> ummm... multiply 3 and 7... get 21... then add 7...</think> <answer> 28 </answer>| special_token | Reasoning: To solve this, we use order of operations, doing multiplication before addition. Step 1: Multiply 3 by 7, which is 21. Step 2: Add 7 to the result: 7 + 21 = 28. | special_token | Summary: The answer is 28.
总之,他们收集了R1-Zero生成的数千个冷启动数据来微调DeepSeek-V3-Base作为RL的起点。与DeepSeek-R1-Zero相比,冷启动数据的优势包括
- 可读性:DeepSeek-R1-Zero 的一个主要限制是其内容通常不适合阅读。其response可能会混合多种语言或缺乏markdown格式来为用户显示答案
相比之下,在为 DeepSeek-R1创建冷启动数据时,设计了一种可读的模式,包括在每个response的末尾添加摘要,并筛选掉可读性比较差的response
比如,他们将输出格式定义为
其中reasoning_process是查询的 CoT,summary用于总结推理结果|special_token|<reasoning_process>|special_token|<summary> - 潜力:通过精心设计带有人类先验知识的冷启动数据模式,可以观察到相较于DeepSeek-R1-Zero有更好的表现
故,作者认为迭代训练是推理模型的一种更好的方法
在获得高质量的冷启动数据后,便可以对 DeepSeek-V3-Base 进行监督微调SFT
1.3.2 阶段二 面向推理的GRPO RL:类似Zero的规则奖励,但增加语言一致性奖励
在对DeepSeek-V3-Base进行冷启动数据微调后,作者应用与DeepSeek-R1-Zero相同的大规模RL训练过程(背后的RL算法自然也是GRPO了)
具体而言
- 此阶段重点在于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及定义明确的问题和清晰的解决方案
但面对的问题是,在训练过程中,作者观察到当RL提示涉及多种语言时,CoT经常表现出语言混合现象 - 为了缓解语言混合问题
尽管消融实验表明这种对齐会导致模型性能略有下降,但这种奖励符合人类偏好,使其更具可读性
- 然后,作者在阶段一通过冷启动数据的微调模型上应用强化学习RL训练,直到其在推理任务上收敛
阶段一 冷启动SFT 阶段二 规则奖励下的RL R1-Zero模型生成的冷启动数据(包含一定的人工修正):微调V3 面向推理的RL:结合三个规则奖励——准确性奖励、格式奖励、语言一致性奖励 阶段三 增强SFT 阶段四 ..
..
1.3.3 阶段三 V3上的的两轮SFT(结合rejection sampling):涉及80w通用层面的推理和非推理数据
当阶段二 面向推理的强化学习RL收敛时,作者利用所得的checkpoint来收集用于下一轮(对应着阶段三)的SFT(监督微调)数据——你是不想问 合着阶段一 阶段二就是为了方便阶段三来收集推理层面的SFT数据?直白点说 不为模型 为推理数据
与最初冷启动数据主要关注推理不同,此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力
具体来说,作者生成数据并按如下所述微调模型
- 推理SFT数据:来自阶段二模型
作者通过执行拒绝采样「只有那些正确且推理清晰的输出才会被保留,质量较低的输出会被丢弃」,从上述阶段二 RL训练的checkpoint中整理推理提示并生成推理轨迹
We curate reasoning prompts and generate reasoning trajectories by perform-ing rejection sampling from the checkpoint from the above RL training
在之前的DeepSeek-R1-Zero阶段,作者只包括可以使用基于规则的奖励(准确性奖励 + 格式奖励)进行评估的数据
然而,在这一阶段,作者通过加入额外的数据来扩展数据集,其中一些使用生成奖励模型,通过将“真实值和模型预测”输入DeepSeek-V3进行判断
即we expand the dataset by incorporating additional data, some of which use a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment
此外,由于模型输出有时混乱且难以阅读,作者已过滤掉混合语言、长段落和代码块的思维链。对于每个prompt,采样多个response并仅保留正确的响应
总共,作者收集了约60万条与推理相关的训练样本 - 非推理SFT数据:来自DeepSeek-V3
对于非推理数据,例如写作、事实问答、自我认知,和翻译,作者采用DeepSeek-V3管道并重用DeepSeek-V3的SFT数据集的部分内容
对于某些非推理任务,作者调用DeepSeek-V3在回答问题之前通过prompt生成潜在的思维链
然而,对于更简单的查询,例如“你好”,不会提供思维链作为响应——因为此时不存在推理的必要性
最终,作者总共收集了大约20万个与推理无关的训练样本
然后使用上述大约80万样本的精心整理数据集对DeepSeek-V3-Base进行两轮微调
- 两轮微调相当于两个epoch的sft(当然,具体 如何精心整理、如何具体编排的,在技术报告中暂未透露)
- 此外,不知读者注意到了没有,本阶段三微调的仍然是V3-Base,而非上面阶段一 SFT之后的模型或阶段二 RL训练的模型,即We fine-tune DeepSeek-V3-Base for two epochs using the above curated dataset of about 800k samples」
阶段一 冷启动SFT 阶段二 规则奖励下的RL R1-Zero模型生成的冷启动数据(包含一定的人工修正):微调V3 面向推理的RL:结合三个规则奖励——准确性奖励、格式奖励、语言一致性奖励 阶段三 增强SFT 阶段四 来自阶段二模型的60w推理数据
和V3模型的20w非推理数据:微调V3
..
1.3.4 阶段四 所有场景的RL:提高有用性和无害性,且混合规则奖励和偏好奖励
为了进一步使模型符合人类偏好,作者实施了一个辅助的强化学习阶段,旨在提升模型的有用性和无害性,同时优化其推理能力
具体来说,作者使用奖励信号和多样的提示分布组合来训练模型
- 对于推理数据
作者遵循DeepSeek-R1-Zero中概述的方法,该方法利用基于规则的奖励(rule-based reward)来指导数学、代码和逻辑推理领域的学习过程
For reasoning data, we adhere to themethodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide thelearning process in math, code, and logical reasoning domains - 对于一般数据
作者使用奖励模型来捕捉复杂和微妙场景中的人类偏好——preference reward
For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios.
比如基于 DeepSeek-V3 管道进行构建,并采用类似的偏好对分布和训练提示
We build upon the DeepSeek-V3 pipeline and adopt a similar distribution of preference pairs and training prompts
类似的,有个DPO的工作,详见此文《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》 - 对于有用性
作者专注于最终总结,确保评估强调响应对用户的实用性和相关性,同时尽量减少对基础推理过程的干扰 - 对于无害性
作者评估模型的整个response,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容
最终,奖励信号和多样数据分布的整合使作者能够训练出一个在推理上表现出色,同时优先考虑有用性和无害性的模型
最后,我再把上面4个阶段 用下述表格汇总一下
阶段一 冷启动SFT 阶段二 规则奖励下的RL R1-Zero模型生成的冷启动数据(包含一定的人工修正):微调V3 面向推理的RL:结合三个规则奖励——准确性奖励、格式奖励、语言一致性奖励 阶段三 增强SFT 阶段四 规则+偏好奖励下的RL 来自阶段二模型的60w推理数据
和V3模型的20w非推理数据:微调V3
全场景RL
规则奖励、偏好奖励
此外,在经过我上面4个阶段的解读之后,你再看本1.3节开头Sebastian Raschka画的那个图 是不是完全清晰、一目了然了?
1.4 蒸馏:赋予小模型推理能力
1.4.1 对R1报告中蒸馏一词的准确理解
最后,作者还实验了蒸馏——赋予小模型推理能力,方法是直接使用 DeepSeek-R1 阶段三中精心挑选的 80 万个样本对开源模型如 Qwen(Qwen, 2024b)和 Llama(AI@Meta,2024)进行了微调
对此,值得强调的两点是
- 网上 有些看法是错的
实际上R1蒸馏版模型,是R1的数据集 去微调其他家的模型
不是其他家的模型 来教R1
而关于R1的数据集
R1报告中的第4页,说的是
Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community
言外之意是,使用DeepSeek-R1 生成的推理数据——如果只是推理数据,则当于来自阶段二模型的60w推理数据,微调了几个在研究界广泛使用的稠密模型
但报告的第11页却又说
To equip more efficient smaller models with reasoning capabilities like DeekSeek-R1, we directlyfine-tuned open-source models like Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024) using the 800k samples curated with DeepSeek-R1
相当于是用了R1 第3阶段训练中的80w数据——来自阶段二模型的60w推理数据和V3模型的20w非推理数据
一个60w,一个80w,到底是哪个,便出现争议了
个人觉得无论是哪个 又都说得通..
若一定让我选择一个,我选80w,因为我推测报告的第4页 大概率上省略掉了来自V3的20w非推理数据,毕竟R1的报告里 推理是主流 不小心在第一处即第4页那里 漏写非推理数据,也确实有可能 - 进一步而言,R1报告里的蒸馏 我个人 觉得不算蒸馏,他就是一个简单的SFT而已
一般的蒸馏是
大模型教小模型各个层面,与纯粹的大模型的训练数据去微调一个小模型,还是有差别的
当然了,如朋友Elma说的,虽然不是技术侧的模型蒸馏,但是现在蒸馏这个概念很广了
1.4.2 R1数据集蒸馏出来的6个模型:32B/70B便可超越o1-mini
研究结果表明,这种简单的蒸馏方法显著增强了小模型的推理能力
- 他们使用的基础模型是
注意
1) Llama-3.1之外,还选择了 Llama-3.3 是因为其推理能力略优于 Llama-3.1
2) 这几个被蒸馏的模型都不是MoE架构,llama 目前没有出MoE架构的模型
Qwen系列里,Qwen2.5-Max 倒是MoE架构了——其对标DeepSeek V3 - 最终,在效果上,通过这「60w推理数据+20w非推理数据」对小模型做微调,也能让小模型即便不经过专门的RL训练也能获得不俗的推理能力,比如DeepSeek-R1-32B和DeepSeek-R1-70B在大多数基准上明显优于o1-mini

- 对于蒸馏模型,作者仅应用SFT,而不包括RL阶段
尽管结合RL可以显著提升模型性能,但作者对此的主要目标是展示蒸馏技术的有效性,故他们考虑将RL阶段的探索留给更广泛的研究社区
至于本地部署,详见此文《一文速览DeepSeek-R1的本地部署:含671B满血版和各个蒸馏版(基于Ollama和vLLM)》
“ 第一部分 本地部署之前的准备工作:各个版本、推理框架、硬件资源
1.1 DeepSeek-R1的多个版本:加上2个原装671B的,总计8个参数版本
在huggingface上总共有以下几种参数的deepseek R1
- DeepSeek-R1 671B
- DeepSeek-R1-Zero 671B
- DeepSeek-R1-Distill-Llama-70B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-1.5B
.. ”
1.5 一些经验总结:他们不成功的尝试
在开发DeepSeek-R1的早期阶段,作者表示也遇到了失败和挫折
他们在技术报告里分享了他们的失败经验以提供一些见解,但注意:这并不意味着这些方法无法开发出有效的推理模型
1.5.1 关于过程奖励模型PRM
PRM是一种合理的方法「关于什么是PRM,详见此文《一文通透OpenAI o1:从CoT、Quiet-STaR、Self-Correct、Self-play RL、MCTS等技术细节到工程复现》的1.3.1节Let's Verify Step by Step(含ORM、PRM的介绍)」,引导模型朝向更好的方向发展解决推理任务的方法(Lightman等,2023;Uesato等,2022;Wang等,2023)

然而,在实践中,PRM有三个主要的限制可能会阻碍其最终成功
- 首先,在一般推理中明确定义一个细粒度步骤是具有挑战性的
- 其次,确定当前中间步骤是否正确是一项挑战。使用模型进行自动注释可能不会产生令人满意的结果,而手动注释不利于规模化
- 第三,一旦引入基于模型的PRM,就不可避免地导致奖励黑客行为(Gao等,2022),重新训练奖励模型需要额外的训练资源,并且复杂化了整个训练流程
总之,虽然PRM在重新排序模型生成的前N个响应或辅助引导搜索(Snell等,2024)方面表现出良好的能力,但与其在他们实验中引入的大规模强化学习过程中的额外计算开销相比,其优势是有限的
1.5.2 关于蒙特卡罗树搜索MCTS
受AlphaGo和AlphaZero的启发,作者探索了使用蒙特卡罗树搜索MCTS 来增强测试时计算的可扩展性。这种方法涉及将答案分解成更小的部分,以便模型能够系统地探索解决方案空间
- 为此,他们提示模型生成多个标签,这些标签对应于搜索所需的具体推理步骤
在训练中,首先使用收集的提示通过预训练的价值模型引导的MCTS来寻找答案 - 随后,使用生成的问题-答案对来训练actor模型和critic模型,迭代地完善这一过程
然而,当扩大训练规模时,这种方法会遇到几个挑战
- 首先,与棋类游戏不同,棋类游戏的搜索空间相对明确,而token生成则呈现出指数级增长的搜索空间
为了解决这个问题,他们为每个节点设置了最大扩展限制,但这可能导致模型陷入局部最优 - 其次,critic模型直接影响生成的质量,因为它指导搜索过程的每一步。而训练一个细粒度的价值模型本质上是困难的,这使得模型难以迭代改进
虽然AlphaGo的核心成功依赖于训练一个critic模型来逐步提升其性能,但由于token生成的复杂性,这一原则在他们的设置中很难复制
总之,虽然MCTS可以在与预训练的critic模型配对时提高推理性能,但通过自我搜索迭代提升模型性能仍然是一个重大挑战
最后,再说一下DeepSeek-R1的不足与未来计划
- 通用能力:目前,DeepSeek-R1在函数调用、多轮对话、复杂角色扮演和json输出等任务中的能力不如DeepSeek-V3
未来,他们计划探索如何利用长CoT来增强这些领域的任务- 语言混合:DeepSeek-R1目前针对中文和英文进行了优化,这可能会在处理其他语言的查询时导致语言混合问题。例如,即使查询是用非英语或中文的语言进行的,DeepSeek-R1可能仍会使用英语进行推理和响应
故他们计划在未来的更新中解决这一限制- 提示工程:在评估 DeepSeek-R1 时,作者观察到它对提示非常敏感。少样本提示会持续降低其性能。因此,作者建议用户直接描述问题,并使用零样本设置指定输出格式,以获得最佳结果
- 软件工程任务:由于长时间的评估影响了强化学习过程的效率,大规模的强化学习在软件工程任务中尚未被广泛应用
因此,在软件工程基准测试中,DeepSeek-R1未能显示出比DeepSeek-V3更大的改进
未来的版本将通过在软件工程数据上实施拒绝采样或在强化学习过程中引入异步评估来提高效率
1.6 对OpenAI o1及DeepSeek R1的简单复现
1.6.1 R1之外的另一条推理模型训练路径:微软rStar-Math的PRM + MCTS
注意,为负责任起见,我还是再强调一下,以上,只代表他们一家的尝试,不代表其他路径不行
毕竟在推理模型上,目前尚未有“哪个路线就一定最好”的定论,而是各有千秋 各有所长
进一步,目前比肩或者超越OpenAI o1有两种路径:
- 一种是微软rStar-Math的PRM + MCTS(实现效果达到了高水准,且在一定程度上解决了上一节deepseek提到的PRM、MCTS等存在的问题,详见此文的第4部分)

- 另一种便是本文所介绍的deepseek R1、Kimi K1.5
1.6.2 DeepSeek R1对外开源的具体内容
颇感遗憾的是,R1和V3一样,也没有直接开源模型的训练代码
具体而言,根据R1的GitHub可知
类别 开源内容 未开源内容 模型权重 R1、R1-Zero 及蒸馏模型权重(MIT 协议) 原始训练数据
未公开冷启动数据、RL 训练数据集或合成数据的具体内容,仅提供依赖的公开数据集名称(如 AI-MO、NuminaMath-TIR)技术文档 GRPO 算法、奖励系统设计、冷启动流程等技术报告 训练代码,比如分布式训练代码细节 训练工具 合成数据生成脚本、评估基准代码 完整 RL 训练框架 推理支持 API 接口、本地部署方案、框架适配指南 生产级优化内核
即动态显存管理、生产级批处理等企业级部署工具未开源
不过,有意思的是,有个开源项目——Open R1倒是复现了R1正式版完整训练流程的前两个阶段「以Qwen2.5-1.5B为基础,以deepseek-R1的训练过程打造」,并把代码开源了,详见此文《从零复现DeepSeek R1:从V3中对MoE、MLA、MTP的实现,到Open R1对R1中SFT、GRPO的实现》的第二部分
我司也会在这个课程《DeepSeek原理与项目实战营》里讲一下这个Open R1的复现思路,及深入解读其源码,以帮助更多人可以更好的用好该Open R1
第二部分(选读) Kimi K1.5
2.1 Kimi K1.5
2.1.1 Kimi K1.5的效果评测
非常有意思的是,Kimi K1.5的发布时间与上文的R1 几乎在同一时间——很有可能是Kimi提前得知了R1的发布时间,而且他们的训练思路在外人看来就像是商量好的一样,即K1.5建立了一个简单有效的RL框架,同R1一样,也不依赖于更复杂的技术,如蒙特卡洛树搜索、价值函数和过程奖励模型
但值得注意的是,K1.5在多个基准和模态上实现了先进的推理性能,例如,AIME得分77.5,MATH 500得分96.2,Codeforces得分94百分位,MathVista得分74.9——与OpenAI的o1相当

实话讲,看到这个图,再结合R1的图,我估计很多人的第一反应是,什么时候谁直接让K1.5和R1直接PK下呢?
2.1.2 k1.5的几个关键设计和训练
关于k1.5的设计和训练,有几个关键要素
- 长上下文扩展
他们将RL的上下文窗口扩展到128k,并观察到随着上下文长度的增加,性能持续提升
他们方法的一个关键思想是使用部分回合来提高训练效率,即通过重用大部分先前的轨迹来采样新轨迹,避免从头生成新轨迹的成本
他们的观察指出,上下文长度是RL与LLMs持续扩展的一个关键维度 - 改进的策略优化
他们推导出一种具有长链式思维(CoT)的强化学习(RL)公式,并采用一种变体的在线镜像下降算法进行稳健的策略优化
We derive a formulation of RL with long-CoT and employ a variant of onlinemirror descent for robust policy optimization
通过他们的有效采样策略、长度惩罚以及数据配方的优化,这一算法得到了进一步的改进 - 简单框架
长上下文扩展结合改进的策略优化方法,建立了一个用于 LLM 学习的简单 RL框架。由于K1.5能够扩展上下文长度,学习到的 CoTs 展现出规划、反思和纠正的特性
且上下文长度的增加对增加搜索步骤的数量有影响
因此,他们表明可以在不依赖于更复杂技术(如蒙特卡洛树搜索、价值函数和过程奖励模型)的情况下实现强大的性能 - 多模态
K1.5在文本和视觉数据上进行联合训练,具备对这两种模态进行联合推理的能力
此外,他们还提出了有效的长到短方法,记使用长-CoT技术来改进短-CoT模型(指的是非推理类的模型,比如GPT4o、Claude Sonnet 3),其中包括应用带有长-CoT激活的长度惩罚和模型合并
2.2 RL之前的提示集策划与Long-CoT监督微调
2.2.1 RL提示集策划
一个精心构建的提示集不仅引导模型进行稳健的推理,还能降低奖励欺骗和过拟合于表面模式的风险
具体来说,高质量RL提示集的三个关键属性是:
- 多样化覆盖
提示应涵盖广泛的学科领域,如STEM、编码和一般推理,以增强模型的适应性并确保在不同领域的广泛适用性 - 难度平衡
提示集应包含分布良好的简单、中等和困难问题,以促进渐进式学习并防止对特定复杂性水平的过拟合 - 准确可评估性
提示应允许验证者进行客观和可靠的评估,确保模型性能的衡量基于正确的推理而非表面模式或随机猜测
为了避免潜在的奖励操纵(Everitt等,2021;Pan等,2022),需要确保每个提示的推理过程和最终答案都能准确验证。实证观察表明,一些复杂的推理问题可能有相对简单且容易猜测的答案,导致错误的正面验证——即模型通过错误的推理过程得出正确答案
- 为了解决这个问题,他们排除容易出现此类错误的问题,例如选择题、是非题和证明题
- 此外,对于一般的问答任务,提出了一种简单而有效的方法来识别和删除容易被操控的提示
具体来说,提示模型在没有任何链式推理步骤的情况下猜测潜在答案——背后本质就是钓鱼式执法
如果模型在N次尝试内预测出正确答案,则该提示被认为太容易被操控而被删除
最终发现设置N=8可以删除大多数容易被操控的提示
2.2.2 Long-CoT监督微调
通过优化的RL提示集,作者采用提示工程构建了一个小而高质量的long-CoT热身数据集,该数据集包含经过准确验证的文本和图像输入的推理路径
这种方法类似于拒绝采样(RS),但重点是通过提示工程生成long-CoT推理路径。生成的热身数据集旨在概括对类人推理至关重要的关键认知过程
例如
- 计划,其中模型在执行之前系统地列出步骤
- 评估,涉及对中间步骤的批判性评估
- 反思,使模型能够重新考虑和完善其方法
- 探索,鼓励考虑替代解决方案
通过在这个热身数据集上进行轻量级的SFT,可以有效地促使模型内化这些推理策略。因此,微调后的long-CoT模型在生成更详细和逻辑连贯的响应方面表现出更强的能力,从而提高其在各种推理任务中的表现
2.3 强化学习训练
2.3.1 问题设定
给定一个训练数据集,其中包含问题
及其对应的真实答案
,作者的目标是训练一个策略模型
来准确解决测试问题
在复杂推理的背景下,将问题 映射到解决方案
并非易事
- 为了解决这一挑战,链式思维CoT方法提出使用一系列中间步骤
来连接
和
其中每个都是一个连贯的token序列,作为解决问题的重要中间步骤(J. Wei et al. 2022)
- 在解决问题
是自回归采样的,随后是最终答案
用表示这一采样过程。注意,思维和最终答案都是作为语言序列进行采样的
为了进一步增强模型的推理能力,采用规划算法来探索各种思维过程,在推理时生成改进的CoT(Yao etal. 2024; Y. Wu et al. 2024; Snell et al. 2024)
这些方法的核心见解是通过价值估计显式构建思维的搜索树。这使得模型能够探索思维过程的多样化延续,或者在遇到死胡同时回溯以探索新方向
- 更具体地,设
为一个搜索树,其中每个节点表示一个部分解
这里由问题
组成,这些思维引导到该节点
其中表示序列中的思维数量
- 规划算法使用一个critic模型
来提供反馈
,这有助于评估当前解决问题的进展并识别现有部分解中的任何错误
他们注意到,反馈可以通过判别分数或语言序列提供「We note that the feedback can be provided by either a discriminative score or a language sequence(L. Zhang et al. 2024). 」
在所有的反馈指导下,规划算法选择最有前途的节点进行扩展,从而增长搜索树
上述过程反复进行,直到得出完整的解决方案
K1.5的技术报告里说,他们也可以从算法的角度来研究规划算法
- 给定在第
次迭代时可用的过去搜索历史
规划算法,根据上面的搜索历史,迭代地确定下一个搜索方向
并通过critic模型为当前搜索进度提供反馈
由于思考和反馈都可以视为中间推理步骤,并且这些组件都可以表示为语言token的序列,故用替换
因此,作者将规划算法视为一个直接作用于推理步骤序列的映射
在此框架中,规划算法所使用的搜索树中存储的所有信息,都被展平为提供给该算法的完整上下文「In this framework,all information stored in the search tree used by the planning algorithm is flattened into the full context provided to the algorithm」- 这为生成高质量的推理过程CoT提供了一个有趣的视角:与其明确构建搜索树并实现规划算法,或许可以训练一个模型来近似这一过程
在这里,想法的数量(即语言token)类似于传统上分配给规划算法的计算预算。近期在长上下文窗口方面的进展使得在训练和测试阶段都能实现无缝扩展
如果可行,这种方法能让模型直接通过自回归预测在推理空间中进行隐式搜索
因此,模型不仅能学会解决一组训练问题,还能发展出有效解决单个问题的能力,从而提高对未见过的测试问题的泛化能力- 因此,作者考虑使用强化学习RL(OpenAI 2024)来训练模型生成解释性推理过程CoT
设为一个奖励模型,它根据给定问题
来判断所拟定答案
的正确性,并赋予一个值
对于可验证问题,奖励是由预定义标准或规则直接确定的
例如,在编码问题中,评估答案是否通过测试用例。对于具有自由形式真实值的问题,训练一个奖励模型来预测答案是否与真实值匹配
给定一个问题通过采样过程生成一个CoT
,和最终答案
生成的CoT 的质量通过它是否能导致正确的最终答案来评估
总之,作者考虑以下目标来优化策略
如上种种,通过扩大强化学习训练规模,旨在训练一个模型,该模型结合了简单基于提示的CoT和规划增强的CoT的优势。模型在推理过程中仍然自回归地采样语言序列,从而避免了部署过程中高级规划算法所需的复杂并行化
然而,与简单基于提示的方法的一个关键区别是,模型不应仅仅遵循一系列推理步骤。相反,它还应学习关键的规划技能,包括错误识别、回溯和通过利用整个探索思想集合作为上下文信息进行解决方案优化
2.3.2 策略优化
采用在线策略镜像下降的一种变体作为训练算法(Abbasi-Yadkori等,2019;Mei等,2019;Tomar等,2020)
- 该算法是迭代执行的。在第
次迭代中,使用当前模型
作为参考模型,并优化以下相对熵正则化的策略优化问题
其中是控制正则化程度的参数。该目标有一个闭式解
这里是归一化因子
- 对两边取对数,得到对于任何
满足以下约束,这使我们能够在优化过程中利用离策略数据
这激发了以下替代损失
为了逼近,使用样本
且作者还发现,使用样本奖励的经验平均值能够产生有效的实际结果
当然,这是合理的,因为当时,
- 最后,通过对代理损失取梯度来结束学习算法。对于每个问题
,使用参考策略
对于熟悉策略梯度方法的人来说,这个梯度类似于使用采样奖励的平均值作为基线的策略梯度(Kool 等,2019;Ahmadian 等,2024)
主要的区别在于响应是从正则化。因此,可以将其视为通常的基于策略的正则化策略梯度算法向非策略情况的自然扩展(Nachum等,2017)
比如从中采样一批问题,并将参数更新到
,随后作为下一次迭代的参考策略。由于每次迭代由于参考策略的变化而考虑不同的优化问题,也在每次迭代开始时重置优化器
值得一提的是,他们在训练系统中排除了价值网络,这在之前的研究中也被利用过(Ahmadian et al. 2024)
虽然这一设计选择显著提高了训练效率,但作者也假设在经典强化学习中用于信用分配的传统价值函数可能不适合我们的背景
- 考虑一个场景,模型生成了一个部分的推理链
,并且存在两个潜在的下一个推理步骤:
和
假设包含一些错误
如果可以访问一个预测价值的value函数,它会表明
根据标准的信用分配原则,选择- 然而,探索
通过使用从长推理链中得出的最终答案的理由作为奖励信号,模型可以学习从采取- 从这个例子中得到的关键启示是,应该鼓励模型探索多样化的推理路径,以增强其解决复杂问题的能力。这种探索性的方法产生了丰富的经验,支持关键规划技能的发展
毕竟主要目标不仅限于在训练问题上获得高准确率,而是专注于为模型提供有效的问题解决策略,最终提高其在测试问题上的表现
2.3.3 长度惩罚
作者观察到一种过度思考现象,即模型的response长度在强化学习训练期间显著增加
虽然这会导致更好的性能,但过长的推理过程在训练和推断期间是昂贵的,并且人类通常不喜欢过度的思考——这个过度更多指的是不必要的冗余 比如问你个天气 则没必要长篇大论 即得看场景
为了解决这个问题,作者引入了长度奖励,以抑制token长度的快速增长,从而提高模型的token效率
- 给定
,令
为
的长度
且设定
min_len = mini len(i)
如果max_len = min_len,则为所有response设置长度奖励为零,因为它们具有相同的长度。否则,长度奖励由以下方式给出

本质上,在正确答案中促进较短的回复,并对较长的回复进行惩罚,同时明确惩罚带有错误答案的长回复 - 然后,这种基于长度的奖励会通过一个加权参数添加到原始奖励中
在初步实验中,长度惩罚可能会在初始阶段减缓训练。为了解决这个问题,作者建议在训练过程中逐步增加长度惩罚的力度
具体来说,首先采用标准的策略优化而不使用长度惩罚,然后在剩余的训练中使用一个恒定的长度惩罚
2.3.4 采样策略
作者利用多种信号来进一步改进采样策略
首先,收集的RL训练数据自然带有不同的难度标签。例如,数学竞赛题比小学数学题更难
其次,由于RL训练过程多次采样相同问题,还可以跟踪每个问题的成功率作为难度的衡量标准,且作者提出两种采样方法来利用这些先验知识以提高训练效率
- 课程采样
- 优先采样
2.4 Long2short:短链推理模型的上下文压缩
尽管长-CoT模型实现了强大的性能,但与标准短-CoT LLMs相比,它消耗了更多的测试时间token
然而,可以将长-CoT模型的思维先验转移到短-CoT模型上,以便即使在有限的测试时间token预算下也能提高性能
故作者提出了几种针对这个long2short问题的方法,包括模型合并(Yang等人,2024年)、最短拒绝采样、DPO(Rafailov等人,2024年)和long2short RL。以下是这些方法的详细描述:
- 模型合并
这种方法将一个长序列模型与一个较短的模型结合起来,以获得一个新的输出长度中等的模型且无需训练——平均它们的权重来合并这两个模型 即可 - 最短拒绝采样
从长模型生成的正确解答中,挑选出推理路径最短的数据,作为新的训练数据提供给其他模型做SFT
这种方法类似于知识蒸馏的过程,将长模型的能力提炼为更高效的推理方式。目标是引导模型按照能够正确解题的前提下,尽可能输出最短的推理路径,从而优化模型的推理效率 - DPO与最短拒绝采样相似,利用Long CoT模型生成多个response样本
选择最短的正确解决方案作为正样本——因为设定为偏向于短推理过程,而较长的响应被视为负样本,包括错误的较长响应和正确的较长响应(长度为选定正样本的1.5倍)
这些正负样本对构成了用于DPO训练的成对偏好数据 - Long2short RL
在标准的强化学习训练阶段之后,选择一个在性能之间提供最佳平衡的模型——性能和token效率作为基础模型,并进行单独的长短RL训练阶段
在第二阶段,应用在第2.3.3节中引入的长度惩罚,并显著减少最大展开长度,以进一步惩罚可能超过期望长度的响应,尽管这些response可能是正确的
总之,Long2Short的一个关键问题是,将模型的输出压缩到最短的程度,同时仍然能够正确解决问题。这意味着在保证正确性的前提下,尽量减少推理过程中不必要的冗余,使模型更加高效,避免无意义的过长推理输出
这种优化的目标是在推理准确性和效率之间找到平衡,既能保持模型的高性能,又能减少计算资源的浪费
// 待更
第三部分 QwQ-32B:阿里千问团队推出的推理大模型
25年3.6日,阿里千问团队推出了QwQ-32B,他们在冷启动的基础上开展了大规模强化学习,其大小虽然只有32N,但其在多个榜单上的效果,比肩deepseek 671B
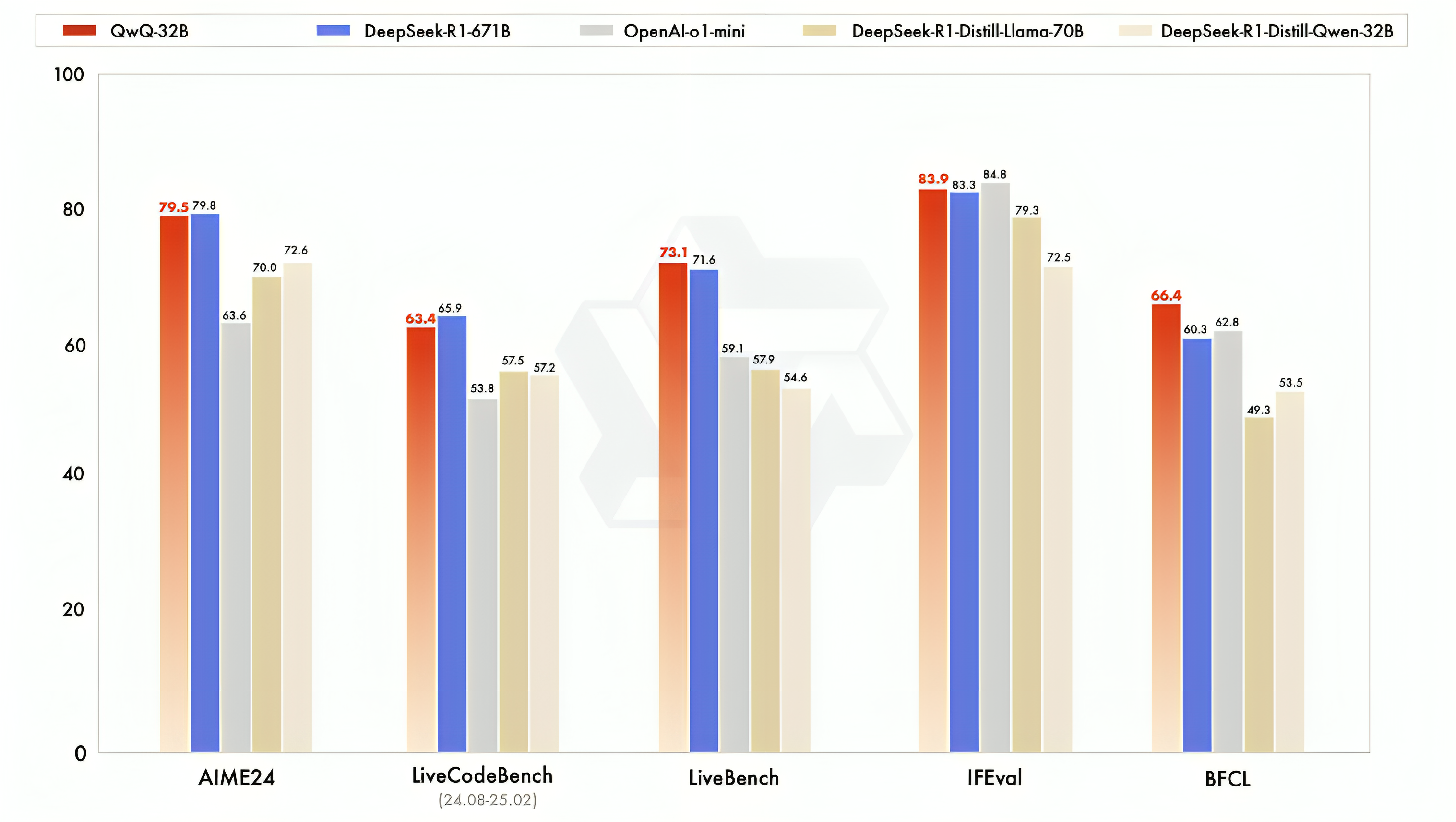
- 在初始阶段,特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型reward model不同,他们通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈
相当于跟上面R1-Zero的训练是一致的,详见上文的「1.2.2 规则奖励建模(准确性奖励 + 格式奖励):不用训练专门的偏好奖励模型」
随着训练轮次的推进,这两个领域中的性能均表现出持续的提升 - 在第一阶段的 RL 过后,增加了另一个针对通用能力的 RL
此阶段使用通用奖励模型和一些基于规则的验证器进行训练,结果发现,通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降
// 待更


















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











