







前言
实话讲,去年24年5月份 lerobot刚出来的时候,我就关注到了,如邓博士所说
- 用24年上半年 Stanford aloha 课题组提供的训练数据,训练他们研发的ACT动作规划模型「 详见此文《一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)》」,训练结果,能用,但是稳定性有待提高
要提高稳定性,看来必须修改ALOHA的源代码了,Stanford aloha课题组提供的初代源代码(特指24年上半年的版本),可读性不太好,改造起来略感吃力 - 好消息是,上周 LeRobot 在 Github 上开源了他们的源代码,LeRobot 试图构建机器人的标准化的 APIs,如同 Huggingface 上的 transformers 和 diffusers
目前该项目已经对几个知名的机器人项目的源代码,进行了重构,部分统一了 APIs,其中包括 Stanford aloha 的 ACT 模型,这就大大降低了改造 ACT 模型的工程难度
但后来各种事情太多了,导致此文迟迟不曾修改,更没想到这个修改竟然拖了整整9个月,直到25年q1,我因为和几个教授联合带了几个高校的硕士生(目前总计10多人),针对其中的具身课题组,3月份,打算让他们搞下lerobot,如此,加大了对lerobot的重视
加之博客的影响力越来越大,比如每周都有几个类似的私信
- 前两天一朋友私我说,July老师您好!我是科大的在读博士,去年的时候看您的博客入门了具身智能,非常感谢您高质量的文章
- 我感慨,从最早的数据结构/算法,后到机器学习 深度学习,再后来到大模型,及具身智能,博客帮助了好多80 90 00,算得上与三代人同行了
更何况对于本文而言,Google搜lerobot时,本文紧跟「lerobot官方GitHub、lerobot官方huggingface」的搜索结果之后,如此高的排名,我之前没想到
那就好好解读下这个lerobot吧,特别是其源码的分析——包括我会在整个项目库的运转流程(数据收集、训练、评估、部署)中分析清楚各个模块与模块之间的联系,以及互相的调用关系,这如此,哪怕代码再多,也能理清其中的来龙去脉而不混乱
第一部分 机器人领域的Transformer架构:LeRobot
1.1 lerobot:对ACT/dp/π0等策略的封装
1.1.1 什么是lerobot
24年5月6日,Hugging Face的机器人项目负责人雷米·卡德内Remi Cadene宣布推出LeRobot开源代码库,并形容它对于机器人的意义就如同“Transformer架构之于NLP”
Remi Cadene在推文中表示,LeRobot之于机器人就像Transformer架构之于NLP——它提供带有预训练检查点的高级AI模型的简洁实现。他们还复现了来自学术界的 31 个数据集和一些模拟环境,无需实体机器人即可开始使用
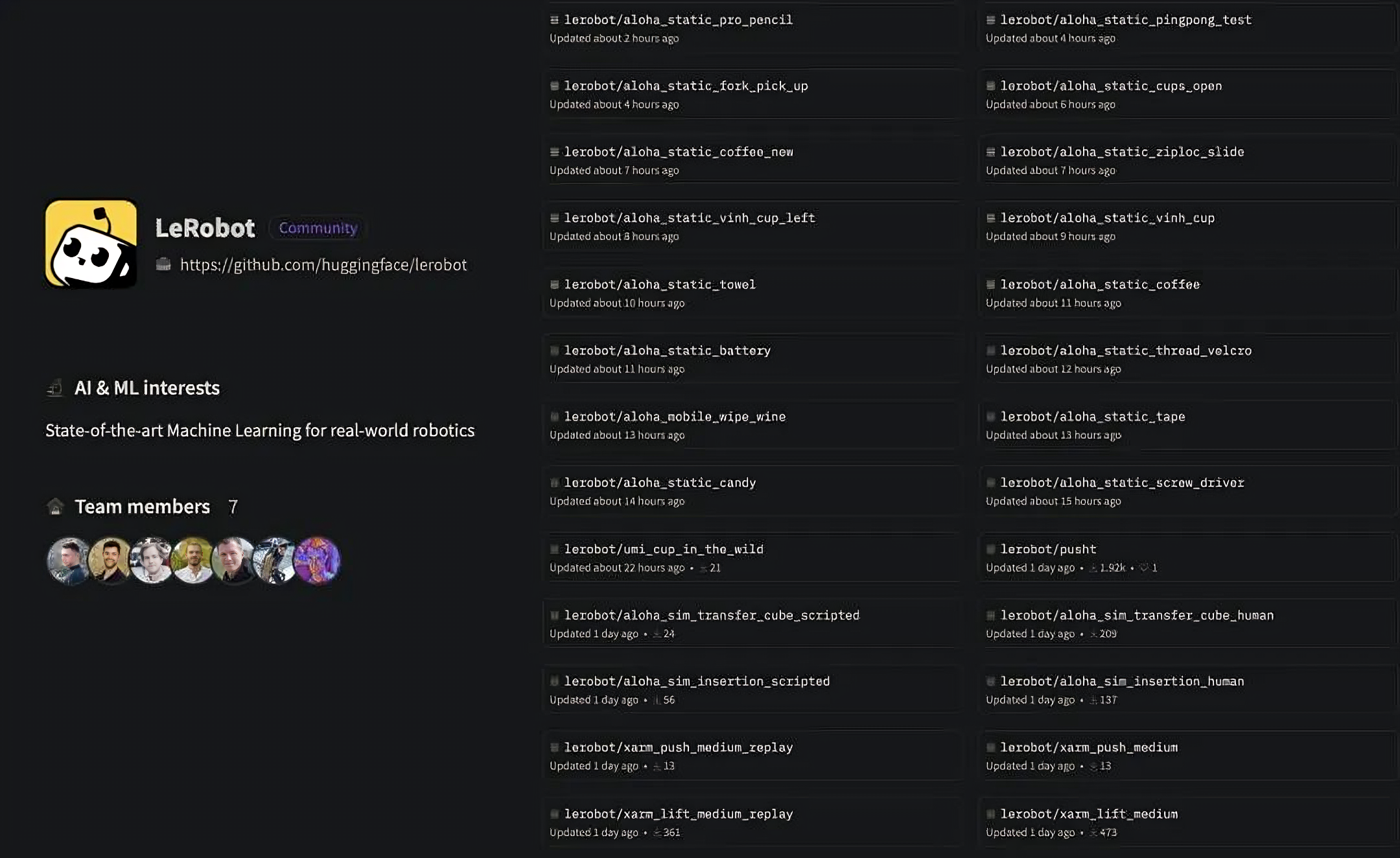
Cadene 发布了一些由Github上LeRobot库的代码提供的机器人功能的示例,它们都是在真实数据集上训练的
- 比如,在这个数据可视化的例子中,它展示了LeRobot是如何在Return(一个SDK和查看器,用于可视化与多模态数据流交互)上运行的,数据集来自ALOHA项目

- LeRobot的另一项可视化是在Mobile Aloha数据集上进行的,旨在完全端到端地学习导航和操作。以下例子展示了LeRobot控制下的两个机器人抓手/手臂之间传递物体:

上述两个数据集都是在机器人公司Trossen Robotics的机械臂上收集的
1.2 对ACT、diffusion policy、π0都做了良好的支持
1.2.1 对ALOHA ACT的支持
当Remi Cadene团队使用ACT策略对LeRobot开源代码库进行测试时,基于LeRobot的机器人在模拟环境下同样表现良好
ACT策略是一种机器人的动作分块算法,即Action Chunking with Transformers——详见此文《一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)》,它使用Transformer编码器合成来自多个视点、联合位置和风格变量的图像,并使用Transformer解码器预测一系列动作,通过预测动作序列来解决高精度领域中的问题。ACT策略可以在新环境干扰下做出反应,并且对一定程度的干扰具有鲁棒性

可以看到,两只机械手分别娴熟地捏起两块不同的积木并堆叠到了一起,证明了ACT策略下LeRobot的有效性
1.2.2 对Diffusion Policy的支持
同时,在Diffusion Policy——详见此文《Diffusion Policy——斯坦福UMI所用的动作预测算法:基于扩散模型的扩散策略(从原理到其编码实现)》、和TDMPC Policy——Temporal Difference Learning for Model Predictive Control 两种策略下,LeRobot同样表现出色,可以不断从与环境的交互中学习

第二部分 将LeRobot部署在简易的机械臂SO-ARM100上
本部分的参考:《将SO-100与 LeRobot配合使用》
2.1 LeRobot的安装与机械臂的搭建、校准
2.1.1 安装LeRobot
2.1.2 配置电机
2.1.3 SO-ARM100机械臂的组装
2.1.4 机械臂的校准
2.1.5 远程操作
依据此教程:将SO-100与 LeRobot配合使用,25年3月12日,我和985教授联合培养的一组具身研究生,把遥操作跑起来了「当然,还可以给机械臂安上摄像头,详见使用 OpenCVCamera 添加相机」
- 运行这个简单的脚本(它不会连接和显示摄像头)
python lerobot/scripts/control_robot.py \ --robot.type=so100 \ --robot.cameras='{}' \ --control.type=teleoperate - 带显示摄像头的 Teleop
按照本指南《使用 OpenCVCamera 添加摄像头》设置你的摄像头。然后,你将能够在远程操作时通过运行以下代码在计算机上显示摄像头。这有助于在记录第一个数据集之前做好准备
注意:要可视化数据,请启用--control.display_data=true。这将使用 来传输数据rerunpython lerobot/scripts/control_robot.py \ --robot.type=so100 \ --control.type=teleoperate
当然,遥操作 是为了采集数据 做进一步训练或微调
2.2 数据的准备:记录、可视化、上传
2.2.1 录制训练数据集
熟悉了远程操作之后,就可以使用 SO-100 记录第一个数据集
如果想使用 Hugging Face 平台的功能上传你的数据集,请确保你已使用具有写入权限的token登录,该token可在 Hugging Face 设置中生成
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential然后将 Hugging Face 存储库名称存储在变量中以运行以下命令:
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER如此,便可以录制 2 集并将数据集上传到中心:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=${HF_USER}/so100_test \
--control.tags='["so100","tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=2 \
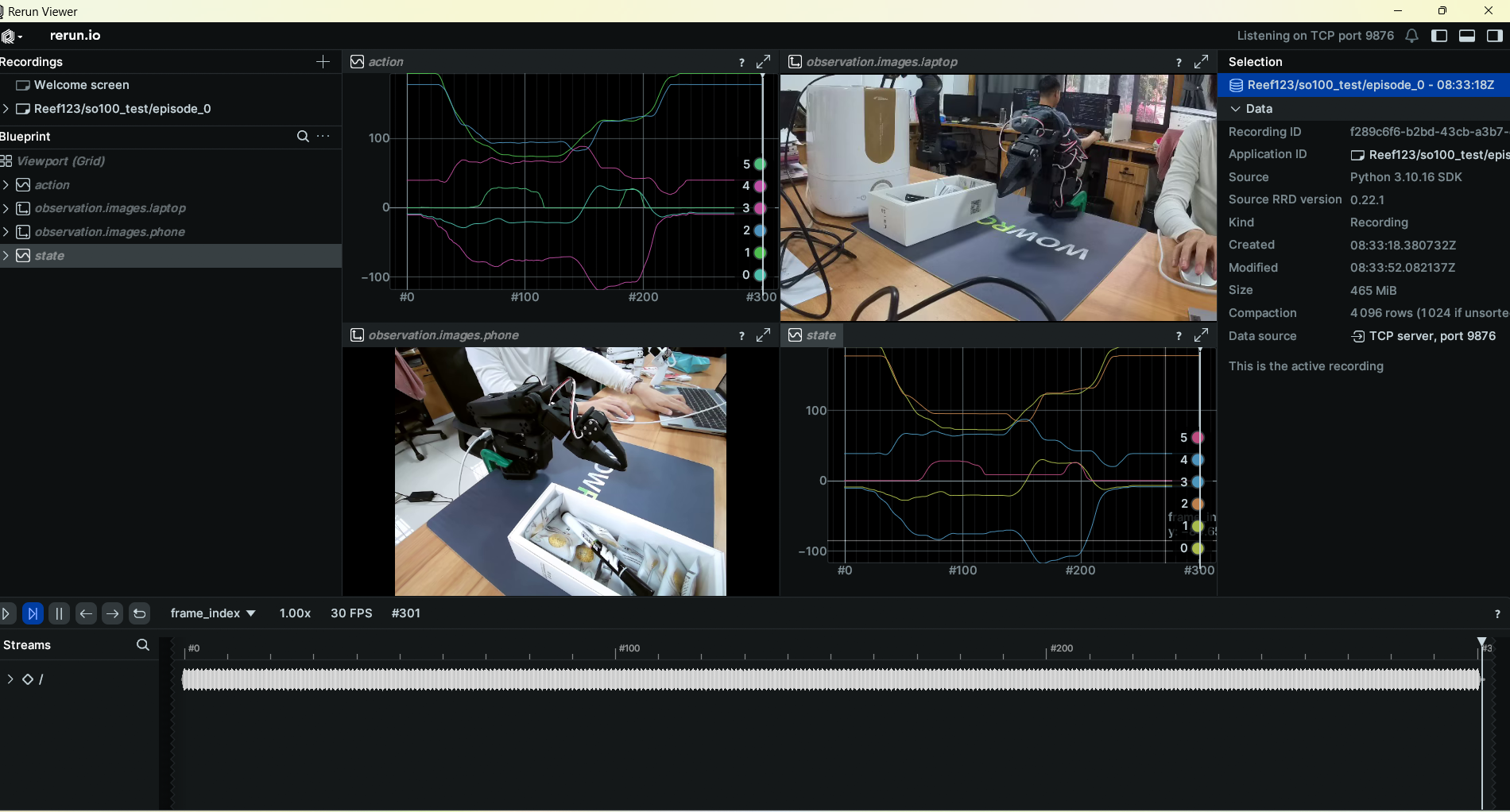
--control.push_to_hub=true2.2.2 数据集的可视化与重播
如下图所示,来自我和一985李教授联合带的具身研究生诗同学的记录
2.3 微调与推理
2.3.1 微调
接下来,参考lerobot库的说明:先用已有的数据集 训练某个策略,让机械臂自主做简单的任务
- 要训练策略来控制您的机器人,请使用python lerobot/scripts/train.py脚本『针对该脚本的分析,详见下文的「2.2.2 train.py节」』
以下是示例命令
其中第三行代码,设定了策略policy.type=actpython lerobot/scripts/train.py \ --dataset.repo_id=${HF_USER}/so100_test \ --policy.type=act \ --output_dir=outputs/train/act_so100_test \ --job_name=act_so100_test \ --policy.device=cuda \ --wandb.enable=true
这会从 configuration_act.py 中加载配置。重要的是,此策略会自动适应你数据集中保存的机器人(例如笔记本电脑和手机)的电机状态、电机动作和摄像头的数量 - 至于configuration_act.py,详见此文《LeRobot源码剖析——对机器人各个动作策略的统一封装:包含ALOHA ACT、Diffusion Policy、VLA模型π0》的「1.2 policies/act/configuration_act.py」
2.3.2 对策略的评估/推理:control_robot.py
可以使用来自 lerobot/scripts/control_robot.py 的record功能『其详细介绍,详见下文的《3.3.1 control_robot.py:多种模式控制实体机器人——校准、遥操、录制record、重放、远程》』,但要以策略检查点作为输入。例如,运行此命令来记录 10 个评估回合:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--control.type=record \
--control.fps=30 \
--control.single_task="Grasp a lego block and put it in the bin." \
--control.repo_id=${HF_USER}/eval_act_so100_test \
--control.tags='["tutorial"]' \
--control.warmup_time_s=5 \
--control.episode_time_s=30 \
--control.reset_time_s=30 \
--control.num_episodes=10 \
--control.push_to_hub=true \
--control.policy.path=outputs/train/act_so100_test/checkpoints/last/pretrained_model从上可以看出,其与之前用于记录训练数据集的命令几乎相同,但有两点变化:
- 还有一个附加--control.policy.path参数,用于指示策略检查点的路径「例如outputs/train/eval_act_so100_test/checkpoints/last/pretrained_model」
如果已将模型检查点上传到中心(例如${HF_USER}/act_so100_test),也可以使用模型存储库 - 数据集的名称以eval开头,反映正在运行推理——例如${HF_USER}/eval_act_so100_test)
// 待更
2.4 LeRobot 项目中各主要模块之间的定位、关联、调用
2.4.1 项目中核心模块的定位:顶层发号施令、中间执行、底层夯基
LeRobot 项目采用了模块化设计,整个项目大概分为以下三层
- 最顶层:scripts (命令行工具),属于发号施令层
- 中间层:common/policies (控制策略),属于中间执行层
- 底层支撑层:common/datasets, common/envs, common/robot_devices
基础配置层: configs, common/utils
属于底层基础层
具体而言,其中
- scripts:命令行工具,各种发号施令
包含一系列数据管理的脚本,涉及将本地数据集推动到hf、可视化数据集
几个模型相关的脚本,涉及上传预训练模型到hf、模型训练train.py、模型评估eval.py
几个机器人控制的脚本,涉及控制实际机器人、配置电机等脚本
比如`scripts` → `policies` → `datasets`/`envs`/`robot_devices`
命令行工具调用策略模型,策略模型需要数据、环境或真实机器人接口 - common/policies:控制策略
从 `datasets` 获取训练数据,与 `envs` 或 `robot_devices` 交互执行动作,通过 `scripts` 进行训练、评估和部署
即`policies` → `datasets`/`envs`,策略训练时需要数据集和/或仿真环境 - common/datasets:数据集处理
向 `policies` 提供训练数据,从 `robot_devices` 接收记录的数据,通过 `scripts` 实现数据可视化和处理 - common/envs:仿真环境
为 `policies` 提供训练和评估环境,通过 `scripts` 进行环境交互,与 `robot_devices` 共享接口设计,确保仿真与实际硬件交互一致 - common/robot_devices:真实机器人硬件接口
实现与 `policies` 相同的接口,使策略可以无缝应用,向 `datasets` 提供真实数据(记录数据时调用数据集模块进行存储),通过 `scripts` 进行控制和数据收集 - configs:配置系统
为所有模块提供参数配置,定义策略、环境、机器人等的接口规范,实现配置继承和覆盖机制
即所有模块几乎所有模块都依赖于配置系统进行参数管理
2.4.2 整个项目的运转流程:数据收集、训练、评估、部署
| 数据收集 | 控制脚本使用机器人收集数据,保存到数据集格式 | scripts/control_robot.py → robot_devices/ → datasets/ → configs/ |
| 训练流程 | 训练脚本加载策略配置,策略从数据集获取数据进行训练 | scripts/train.py → policies/ → datasets/ → configs/ |
| 评估流程 | 评估脚本加载训练好的策略,在仿真环境中评估性能 | scripts/eval.py → policies/ → envs/ → configs/ |
| 真实机器人控制 | 控制脚本加载策略和机器人配置,使策略控制真实机器人 | scripts/control_robot.py → robot_devices/ → policies/ → configs/ |
以下是一些特殊模块之间的依赖
- 循环依赖:
`policies` 和 `envs` 有时存在轻微的循环依赖,因为环境需要知道策略的动作空间,而策略需要知道环境的观察空间 - 替代关系:
`envs` 和 `robot_devices` 实现了类似的接口,使策略可以无缝地在仿真和真实环境中切换 - 工厂模式:
多个模块使用工厂模式创建实例,如 factory.py 允许通过配置动态创建相应的策略、环境或机器人对象
第三部分 顶层scripts的发号施令:涉及模型训练/评估、机器人控制
lerobot/scripts 模块包含12个不同的Python脚本
- 数据管理相关脚本
push_dataset_to_hub.py - 将本地数据集推送到HuggingFace Hub
visualize_dataset.py - 可视化数据集内容
visualize_dataset_html.py - 生成数据集的HTML可视化
visualize_image_transforms.py - 可视化图像变换效果 - 模型相关脚本
push_pretrained.py - 上传预训练模型到HuggingFace Hub
train.py - 模型训练主脚本
eval.py - 模型评估脚本 - 机器人控制相关脚本
control_robot.py - 控制实际机器人
control_sim_robot.py - 控制模拟机器人
configure_motor.py - 配置机器人电机参数
find_motors_bus_port.py - 查找机器人电机总线端口 - 系统信息脚本
display_sys_info.py - 显示系统信息(可能用于调试或环境检查)
3.1 数据管理相关脚本
3.2 模型相关脚本:上传模型、训练模型、评估模型
3.2.1 上传预训练模型
3.2.2 scripts/train.py
train.py 脚本实现了一个完整的机器人策略训练框架:
- 实现了基于 PyTorch 的模型训练流程
- 支持恢复训练、梯度裁剪、混合精度训练等高级功能
- 集成了 WandB 日志记录
- 支持训练期间的周期性评估和模型保存
- 使用 EpisodeAwareSampler 进行数据采样,特别针对机器人数据集
具体而言,,主要由两个部分组成:`update_policy` 用于执行一次完整的梯度更新,以及带有 `@parser.wrap()` 装饰器的 `train` 函数负责整个训练流程的搭建和循环。
- 首先,`update_policy` 接收当前的 `train_metrics`、策略模型 `policy`、一个数据 `batch`、优化器和混合精度梯度缩放器等参数
它会记录开始时间,把模型切换到训练模式,然后(在可选的 AMP 环境中)执行前向传播计算损失 `loss`,再通过 `grad_scaler.scale(loss).backward()` 进行反向传播
为了保证数值稳定性,先用 `grad_scaler.unscale_(optimizer)` 取消梯度缩放# 将策略模型设置为训练模式 policy.train() # 如果使用 AMP,则启用自动类型转换上下文,否则使用空上下文 with torch.autocast(device_type=device.type) if use_amp else nullcontext(): # 执行策略的前向传播,计算损失和输出 loss, output_dict = policy.forward(batch) 待办事项:对策略输出进行反归一化 # 使用梯度缩放器缩放损失,并执行反向传播计算梯度 grad_scaler.scale(loss).backward()
再调用 `clip_grad_norm_` 对所有可学习参数做梯度裁剪# 在梯度裁剪之前,原地取消优化器参数梯度的缩放 # 取消优化器梯度的缩放 grad_scaler.unscale_(optimizer)
接下来在可选的线程锁内完成 `scaler.step(optimizer)`,并调用 `scaler.update()` 更新下次迭代的缩放因子# 对策略参数的梯度进行裁剪 grad_norm = torch.nn.utils.clip_grad_norm_( # 需要裁剪梯度的参数 policy.parameters(), # 裁剪的范数阈值 grad_clip_norm, # 如果梯度包含 inf 或 NaN,不报错 error_if_nonfinite=False, )
优化器清零梯度后,如果提供了学习率调度器则调用 `lr_scheduler.step()`,若策略实现了 `update()` 方法还会触发内部状态(如 EMA)的更新# 优化器的梯度已经取消缩放,所以 scaler.step 不会再次取消缩放它们, # 但如果梯度包含 inf 或 NaN,它仍然会跳过 optimizer.step()。 # 如果提供了锁,则在锁的保护下执行,否则使用空上下文 with lock if lock is not None else nullcontext(): # 执行优化器步骤(如果梯度有效) grad_scaler.step(optimizer) # 更新下一次迭代的缩放因子,即更新梯度缩放器的缩放因子 grad_scaler.update()
最后,函数将本次的损失、梯度范数、学习率和耗时写入 `train_metrics` 并返回,以供上层循环记录# 清空优化器的梯度 optimizer.zero_grad() # 在每个批次而不是每个 epoch 步进 pytorch 调度器 # 如果提供了学习率调度器 if lr_scheduler is not None: # 执行学习率调度器的步进 lr_scheduler.step() # 如果策略对象有 "update" 方法 if has_method(policy, "update"): # 可能用于更新内部缓冲区(例如 TDMPC 中的指数移动平均) # 调用策略的 update 方法 policy.update() - 主入口 `train(cfg: TrainPipelineConfig)` 则通过 `@parser.wrap()` 自动解析命令行或预训练配置,先校验并打印配置信息。根据配置决定是否初始化 WandB 日志同步,否则提示本地记录;若指定了随机种子,则调用 `set_seed` 保证结果可复现
接着根据 `cfg.device` 选取合适的 PyTorch 设备,并打开 CuDNN 和 TF32 加速
然后依次创建数据集(`make_dataset`)、可选的并行评估环境(`make_env`)、策略模型(`make_policy`)、优化器与调度器(`make_optimizer_and_scheduler`)以及混合精度 `GradScaler`
如果开启了恢复模式,会通过 `load_training_state` 恢复训练步数、优化器和调度器状态 - 在打印了输出目录、任务名称、总步数、数据量及参数规模等信息后,代码根据策略配置决定是否使用 `EpisodeAwareSampler`(用于时序数据的分段采样),否则简单打乱
然后通过标准的 `DataLoader` 载入样本,并用自定义的 `cycle` 生成无限迭代器 `dl_iter`。训练指标器 `MetricsTracker` 配置了诸如损失、梯度范数、学习率、加载时间和更新耗时等度量,并在主循环中遍历 `step` 到 `cfg.steps`
每一步先记录数据加载耗时,再将张量移动到目标设备,然后调用 `update_policy` 更新模型并获取可能的额外日志数据。步数自增后,`train_tracker.step()` 更新样本、回合和 epoch 计数 - 根据 `cfg.log_freq`,在日志步打印 `train_tracker` 并同步到 WandB;根据 `cfg.save_freq` 或收尾步骤,调用 `save_checkpoint`、`update_last_checkpoint` 保存模型与训练状态,并将模型 artifact 上传至 WandB;若满足评估频率且已配置环境,则进入无梯度和 AMP 上下文运行 `eval_policy`,收集奖励、成功率等评估指标,并将结果与视频一并记录
循环结束后,若创建了评估环境则关闭,最后打印 “End of training” 提示训练完成。
整体而言,这段代码通过结构化、模块化的方式串联了配置解析、数据加载、设备管理、策略构建、混合精度训练、动态日志、定期评估与检查点管理,为机器人策略的离线学习提供了一套完整且可扩展的流水线
// 待更
3.3 机器人控制相关脚本:比如control_robot.py、control_sim_robot.py
3.3.1 scripts/control_robot.py:多种模式控制实体机器人——校准、遥操、录制record、重放、远程
control_robot.py提供了多种控制模式:
- 校准模式(calibrate)
用于校准机器人的各个部件,特别是机械臂 - 远程操作模式(teleoperate)
允许用户通过界面或输入设备实时控制机器人 - 录制模式(record)
记录机器人动作序列,创建数据集,可以:
设置预热时间、录制时间和环境重置时间
支持键盘控制录制流程
可选择将数据集推送到HuggingFace Hub - 重放模式(replay)
从已记录的数据集中重放动作序列 - 远程机器人模式(remote_robot)
特别为远程控制的机器人(如LeKiwi)设计
脚本支持通过命令行参数配置复杂的机器人控制任务,还集成了声音反馈和键盘监听器以改善用户体验
3.3.1.1 机器人校准 (`calibrate`)
- 为机器人执行校准程序
- 对于某些机器人(如 stretch),它会检查连接和归位状态
- 对于其他机器人,它通常通过删除旧的校准文件,然后重新连接机器人来触发校准(连接过程会在缺少校准文件时自动执行校准)
- 支持指定要校准的机械臂
3.3.1.2 机器人遥操作 (`teleoperate`)
允许用户通过输入设备(如游戏手柄,未在代码中直接显示,但由 `control_loop` 处理)实时控制机器人
可以设置控制频率 (`fps`) 和持续时间
可以选择是否显示摄像头画面
3.3.1.3 数据录制 (`record`)
- 数据集初始化与管理
函数开始时会根据配置决定是恢复现有录制 [`cfg.resume`]还是创建新数据集
如果恢复录制,它会加载指定仓库 ID 的现有数据集,为摄像头设置异步图像写入器
并通过 [`sanity_check_dataset_robot_compatibility`] 确保当前机器人配置与数据集兼容# 如果设置为恢复录制模式 if cfg.resume: # 加载现有数据集 dataset = LeRobotDataset( cfg.repo_id, # 使用配置中的仓库ID root=cfg.root, # 使用配置中的根目录 ) if len(robot.cameras) > 0: # 如果机器人有摄像头 dataset.start_image_writer( # 启动图像写入器 # 设置图像写入进程数 num_processes=cfg.num_image_writer_processes, # 设置每个摄像头的线程数 num_threads=cfg.num_image_writer_threads_per_camera * len(robot.cameras), )# 检查数据集与机器人的兼容性 sanity_check_dataset_robot_compatibility(dataset, robot, cfg.fps, cfg.video)
然后通过 [`LeRobotDataset.create`]) 创建空数据集对象# 如果不是恢复录制(新建录制) else: # 创建空数据集或加载现有已保存的片段 # 检查数据集名称的合法性 sanity_check_dataset_name(cfg.repo_id, cfg.policy)
这个对象会基于机器人配置设置适当的元数据、帧率和视觉特征# 创建新的数据集 dataset = LeRobotDataset.create(cfg.repo_id, # 使用配置中的仓库ID cfg.fps, # 使用配置中的帧率 root=cfg.root, # 使用配置中的根目录 robot=robot, # 传入机器人对象 use_videos=cfg.video, # 设置是否使用视频格式 # 设置图像写入进程数 image_writer_processes=cfg.num_image_writer_processes, # 设置图像写入线程数 image_writer_threads=cfg.num_image_writer_threads_per_camera * len(robot.cameras), ) - 策略加载与机器人准备
如果配置中指定了策略路径 [`cfg.policy`],函数会加载预训练模型 这使得录制过程可以既支持人类遥操作(当 `policy` 为 None 时),也支持自主策略执行(用于评估)
接着它确保机器人已连接# 加载预训练策略 # 如果配置了策略则创建策略对象,否则为None policy = None if cfg.policy is None else make_policy(cfg.policy, cfg.device, ds_meta=dataset.meta)
并初始化键盘监听器,使用户可以通过箭头键和 Esc 键实时控制录制流程if not robot.is_connected: # 如果机器人未连接 robot.connect() # 连接机器人# 初始化键盘监听器,获取监听器和事件字典 listener, events = init_keyboard_listener() - 预热阶段
录制前有一个预热期[`warmup_record`],期间可以遥操作机器人(如果未使用自主策略),让硬件和连接稳定下来,并可以合理排布摄像头窗口
对于支持安全停止功能的机器人,预热后会调用其 `teleop_safety_stop` 方法以确保操作安全# 执行几秒钟不录制以: # 1. 如果没有提供策略,遥操作机器人移动到起始位置 # 2. 给机器人设备连接和开始同步的时间 # 3. 在屏幕上放置摄像头窗口 # 如果没有策略则启用遥操作 enable_teleoperation = policy is None # 记录并可能播放声音提示"预热录制" log_say("Warmup record", cfg.play_sounds) # 执行预热录制 warmup_record(robot, events, enable_teleoperation, cfg.warmup_time_s, cfg.display_cameras, cfg.fps)# 如果机器人有遥操作安全停止方法 if has_method(robot, "teleop_safety_stop"): # 调用机器人的遥操作安全停止方法 robot.teleop_safety_stop() - 主录制循环
主循环是函数的核心,它会持续直到达到目标片段数或用户手动停止
每次迭代中:# 初始化已录制片段计数器 recorded_episodes = 0 # 开始录制循环 while True: # 如果已录制片段数达到目标 if recorded_episodes >= cfg.num_episodes: break
1. 使用 [`log_say`]提示当前录制状态,可选择语音播报
2. 通过 [`record_episode`] 执行单个片段的录制,该函数会在内部构建控制循环,收集状态、动作和传感器数据# 记录并可能播放声音提示当前录制的片段编号 log_say(f"Recording episode {dataset.num_episodes}", cfg.play_sounds)
3. 如果不是最后一个片段且用户未请求停止,进入环境重置阶段,调用 [`reset_environment`]record_episode( # 调用录制单个片段的函数 robot=robot, # 传入机器人对象 dataset=dataset, # 传入数据集对象 events=events, # 传入键盘事件字典 episode_time_s=cfg.episode_time_s, # 设置片段录制时长 display_cameras=cfg.display_cameras, # 设置是否显示摄像头画面 policy=policy, # 传入策略对象 device=cfg.device, # 设置计算设备 use_amp=cfg.use_amp, # 设置是否使用自动混合精度 fps=cfg.fps, # 设置帧率 single_task=cfg.single_task, # 设置单一任务描述 )
4. 处理用户事件,如果请求重录,则重置事件标志并调用 [`dataset.clear_episode_buffer()`]清除缓冲数据# 执行几秒钟不录制以给手动重置环境的时间 # 当前代码逻辑不允许在此期间进行遥操作 # 待办:添加在重置期间启用遥操作的选项 # 跳过最后一个要录制的片段的重置 # 如果未触发停止录制事件 并且 if not events["stop_recording"] and ( (recorded_episodes < cfg.num_episodes - 1) or # 不是最后一个片段或需要重新录制 events["rerecord_episode"] ): # 记录并可能播放声音提示"重置环境" log_say("Reset the environment", cfg.play_sounds) # 执行环境重置 reset_environment(robot, events, cfg.reset_time_s, cfg.fps)
5. 将片段持久化到磁盘——调用 [`dataset.save_episode()`]# 如果触发了重新录制事件 if events["rerecord_episode"]: # 记录并可能播放声音提示"重新录制片段" log_say("Re-record episode", cfg.play_sounds) # 重置重新录制事件标志 events["rerecord_episode"] = False # 重置提前退出事件标志 events["exit_early"] = False dataset.clear_episode_buffer() # 继续下一次循环(重新录制) continue
6. 递增已录制片段计数# 保存当前片段数据到磁盘 dataset.save_episode()
检查是否收到停止事件# 已录制片段计数加1 recorded_episodes += 1
这种设计允许灵活中断和恢复录制流程,以应对各种现实环境中的突发情况# 如果触发了停止录制事件 if events["stop_recording"]: # 跳出循环 break - 清理与分享
录制完成后,函数执行清理工作:通知录制停止、断开机器人连接、停止键盘监听器和关闭摄像头窗口
如果启用了[`cfg.push_to_hub`],会将本地数据集上传至 Hugging Face Hub,便于共享和复现# 记录并可能播放声音提示"停止录制"(阻塞模式) log_say("Stop recording", cfg.play_sounds, blocking=True) # 停止录制(关闭监听器和摄像头窗口) stop_recording(robot, listener, cfg.display_cameras)# 如果配置了推送到Hub if cfg.push_to_hub: # 将数据集推送到Hugging Face Hub dataset.push_to_hub(tags=cfg.tags, private=cfg.private) # 记录并可能播放声音提示"退出" log_say("Exiting", cfg.play_sounds) # 返回完成的数据集对象 return dataset
3.3.1.4 数据回放 (`replay`)
- 加载之前录制好的数据集中某个特定片段 (`episode`) 的动作序列
- 将这些动作按录制时的频率 (`fps`) 发送给机器人,让机器人重现之前的动作
3.3.1.5 远程机器人控制 (`RemoteRobotConfig`)
针对像 LeKiwi 这样的远程控制机器人,此脚本可以在机器人端的设备(如树莓派)上运行,接收远程指令
3.3.1.6 配置和入口 (`control_robot`, `if __name__ == "__main__":`)
- 使用 `lerobot.configs.parser` 来解析命令行参数,这些参数决定了执行哪个控制模式以及具体的配置(如机器人类型、频率、数据集ID等)
- `control_robot` 函数根据解析后的配置,调用相应的 `calibrate`, `teleoperate`, `record`, `replay` 或 `run_lekiwi` 函数
- @safe_disconnect` 装饰器确保在程序结束或出错时,机器人能够安全断开连接
总之,这个脚本提供了一个统一的命令行接口,用于与物理机器人交互以进行校准、遥操作、数据录制(手动或自动)、数据回放等任务。它是 `lerobot` 框架中连接模拟/策略训练与物理机器人部署的关键部分。用户通过不同的命令行参数来配置和启动所需的功能
3.3.2 scripts/control_sim_robot.py
// 待更
第四部分 common/datasets:数据集(处理/加载/转换训练所需的数据)
lerobot/common包含以下几大模块
- datasets:数据集相关
- policies:策略实现
- envs:仿真环境模块
- robot_devices:实际机器人硬件控制
本部分侧重分析其中的数据集模块
支持多种格式的数据集:aloha_hdf5, pusht_zarr, xarm_pkl 等,且提供 LeRobotDataset 类用于加载和处理数据,以及包含数据增强和变换工具,提供了一个统一的接口来处理不同来源和格式的数据
总的来说,`datasets` 模块提供了一个全面的系统来管理机器人学习所需的不同类型的数据,特别是处理多模态时间序列数据(状态、动作和视觉输入)的能力,使它成为 LeRobot 框架的核心组件
4.1 lerobot_dataset.py:包含 `LeRobotDataset类
LeRobotDataset` 是数据集的主要接口,支持从本地文件或 HuggingFace Hub 加载数据,其支持视频和图像数据的处理,且提供了数据同步检查、时间戳处理等功能,具体而言,包括
4.1.1 LeRobotDatasetMetadata类
这段代码定义了一个名为`LeRobotDatasetMetadata`的类,用于管理和处理机器人数据集的元数据。该类的主要功能包括加载元数据、从远程仓库拉取数据、获取数据文件路径和视频文件路径、更新视频信息等。
- 首先,`LeRobotDatasetMetadata`类的构造函数接受数据集的仓库ID、根目录、版本和是否强制同步缓存等参数
- 构造函数尝试加载元数据,如果失败,则从远程仓库拉取数据并重新加载元数据
`load_metadata`方法负责加载数据集的基本信息、任务、集和统计信息,并根据版本号选择合适的加载方式
`pull_from_repo`方法使用`huggingface_hub`库的`snapshot_download`函数从远程仓库下载数据,支持指定允许和忽略的文件模式 - `get_video_file_path`方法根据集索引和视频键生成视频文件的路径,`get_episode_chunk`方法根据集索引计算所属的块
- 类中定义了一些属性,如`data_path`、`video_path`、`robot_type`、`fps`、`features`等,用于获取数据集的相关信息
- `get_task_index`方法根据任务名称返回任务索引
`add_task`方法用于向任务字典中添加新任务
`save_episode`方法用于保存集的信息,包括更新元数据、写入集和统计信息等
`update_video_info`方法更新视频的相关信息,假设所有视频都以相同的方式编码 - 最后,`create`类方法用于创建一个新的`LeRobotDatasetMetadata`实例,接受仓库ID、帧率、根目录、机器人实例、机器人类型、特征和是否使用视频等参数
该方法会根据传入的参数初始化元数据,并返回一个新的实例
4.1.2 LeRobotDataset类
总的而言,`LeRobotDataset`类继承自`torch.utils.data.Dataset`,用于管理和处理机器人数据集
该类的构造函数接受多个参数,包括数据集的仓库ID、根目录、集列表、图像转换、时间戳差异、容差、版本、是否强制同步缓存、是否下载视频和视频后端等
构造函数根据这些参数初始化类的属性,并创建必要的目录结构
class LeRobotDataset(torch.utils.data.Dataset):
def __init__(
self,
repo_id: str, # 仓库ID,用于获取数据集
root: str | Path | None = None, # 根目录路径,用于下载/写入文件
episodes: list[int] | None = None, # 要加载的特定集的列表,如果为None则加载所有集
image_transforms: Callable | None = None, # 用于视觉模态的图像转换函数
delta_timestamps: dict[list[float]] | None = None, # 时间戳差异字典
tolerance_s: float = 1e-4, # 时间戳同步容差(秒)
revision: str | None = None, # Git版本ID(分支名、标签或提交哈希)
force_cache_sync: bool = False, # 是否强制同步本地缓存
download_videos: bool = True, # 是否下载视频文件
video_backend: str | None = None, # 视频解码后端
):该类提供了两种实例化方式:一种是加载已经存在的数据集,另一种是创建一个新的空数据集
- 对于已经存在的数据集,可以从本地磁盘或Hugging Face Hub加载数据
- 对于新的数据集,可以使用`create`类方法创建一个空的数据集,用于记录新的数据或将现有数据集转换为LeRobotDataset格式
`create`类方法用于从头创建一个新的`LeRobotDataset`实例,以便记录数据
该方法接受多个参数,包括仓库ID、帧率、根目录、机器人对象、机器人类型、特征、是否使用视频、时间容差、图像写入进程数、图像写入线程数和视频后端。
- 首先,该方法调用`cls.__new__(cls)`创建一个新的类实例。接着,它调用`LeRobotDatasetMetadata.create`方法创建元数据对象,并将其分配给`obj.meta`。元数据对象包含数据集的基本信息,如仓库ID、根目录、帧率、机器人类型和特征等
- 然后,该方法初始化实例的其他属性,如`repo_id`、`root`、`revision`、`tolerance_s`和`image_writer`
如果指定了图像写入进程数或线程数,则调用`start_image_writer`方法启动异步图像写入器- 接下来,该方法调用`create_episode_buffer`方法创建一个集缓冲区,用于临时存储集数据
- 然后,它调用`create_hf_dataset`方法创建一个新的HF数据集对象,并将其分配给`obj.hf_dataset`
- 此外,还初始化了其他一些属性,如`image_transforms`、`delta_timestamps`、`delta_indices`和`episode_data_index`
- 最后,该方法返回创建的`LeRobotDataset`实例
通过这种方式,用户可以从头创建一个新的数据集实例,并准备好记录和处理机器人数据
在文件结构方面,LeRobotDataset包含三个主要部分:元数据、hf_dataset和视频
├── data/ # 包含主要数据(以parquet格式存储)
│ ├── chunk-000/ # 数据分块存储
│ │ ├── episode_000000.parquet
│ │ ├── episode_000001.parquet
│ │ └── ...
│ └── ...
├── meta/ # 元数据
│ ├── episodes.jsonl # 剧集信息
│ ├── info.json # 数据集信息(形状、帧率等)
│ ├── stats.json # 统计信息(均值、标准差等)
│ └── tasks.jsonl # 任务描述
└── videos/ # 视频数据(可选)
├── chunk-000/
│ ├── observation.images.camera1/
│ │ ├── episode_000000.mp4
│ │ └── ...
│ └── ...
└── ...- 元数据包括数据集的各种信息,如形状、键、帧率等;
- hf_dataset是一个datasets.Dataset对象,用于读取parquet文件中的数据
- 视频部分用于同步从parquet文件中加载的数据帧
具体而言,类中定义了多个方法,用于处理数据集的不同操作,首先
- `push_to_hub`方法用于将数据集推送到Hugging Face Hub
- `pull_from_repo`方法用于从远程仓库拉取数据
- `download_episodes`方法用于下载指定版本的数据集
- `get_episodes_file_paths`方法用于获取集文件的路径
- `load_hf_dataset`方法用于加载hf_dataset
- `create_hf_dataset`方法用于创建一个新的hf_dataset
其次,类中定义了一些属性和辅助方法,用于获取数据集的帧率、帧数、集数、特征等信息,以及处理查询索引、时间戳、视频帧等操作
- 首先,`fps`属性返回数据采集过程中使用的每秒帧数。`num_frames`属性返回所选集中的帧数,如果`hf_dataset`存在,则返回其长度,否则返回元数据中的总帧数
`num_episodes`属性返回所选集的数量,如果`episodes`存在,则返回其长度,否则返回元数据中的总集数
`features`属性返回数据集的特征字典,而`hf_features`属性返回`hf_dataset`的特征,如果`hf_dataset`不存在,则从特征中获取 - `_get_query_indices`方法用于获取查询索引和填充信息。它根据给定的索引和集索引,计算每个特征的查询索引,并生成填充信息以处理超出当前集范围的情况
- `_get_query_timestamps`方法用于获取查询时间戳。它根据查询索引从`hf_dataset`中选择时间戳,如果查询索引不存在,则返回当前时间戳
- `_query_hf_dataset`方法用于查询`hf_dataset`,根据查询索引返回相应的特征数据
- `_query_videos`方法用于查询视频帧。它根据查询时间戳从视频文件中解码帧,并返回这些帧。需要注意的是,当使用数据工作者时,不应在主进程中调用此函数,否则会导致分段错误
- `_add_padding_keys`方法用于添加填充键,将填充信息添加到查询结果中
- `__len__`方法返回数据集的帧数,`__getitem__`方法根据索引返回数据项
`__getitem__`方法首先从`hf_dataset`中获取数据项,然后根据需要查询额外的特征和视频帧,并应用图像转换 - `__repr__`方法返回数据集的字符串表示,包括仓库ID、所选集数、样本数和特征
- `create_episode_buffer`方法用于创建集缓冲区,用于临时存储集数据`_get_image_file_path`方法用于获取图像文件路径,`_save_image`方法用于保存图像
最后,还定义了一下方法
- `add_frame`方法用于向集缓冲区添加帧
- `save_episode`方法用于将当前集保存到磁盘
- `_save_episode_table`方法用于保存集表
- `clear_episode_buffer`方法用于清除集缓冲区
- `start_image_writer`和`stop_image_writer`方法用于管理异步图像写入器
- `encode_videos`和`encode_episode_videos`方法用于将帧编码为视频
总的来说,`LeRobotDataset`类提供了一个灵活且高效的框架,用于管理和处理机器人数据集,特别是涉及视频和图像数据的处理
4.2 compute_stats.py
用于计算数据集的统计信息(均值、标准差等),为数据归一化提供必要的统计参数
4.3 image_writer.py
处理数据收集期间的异步图像写入,提高数据收集过程的效率
4.4 push_dataset_to_hub
包含将数据集转换和上传到 HuggingFace Hub 的功能,支持多种格式的转换(如 aloha_hdf5, pusht_zarr, xarm_pkl 等)
4.5 transforms.py
提供数据转换和增强功能,用于训练时的数据预处理
4.6 utils.py
包含各种辅助函数,如时间戳检查、版本兼容性检查等,以及处理数据集元数据和文件路径
4.7 video_utils.py
处理视频编码和解码,支持从视频文件中提取特定时间戳的帧
4.8 online_buffer.py
用于在线数据收集和缓存,支持实时数据处理
4.9 sampler.py
提供数据采样策略,用于训练时的批量生成
4.10 v2和v21
包含不同版本的数据集格式处理代码,确保向后兼容性
第五部分 common/policies:策略实现
该模块包含以下策略
- act:Action Chunking Transformer 策略
- diffusion:扩散策略
- tdmpc:时序差分模型预测控制
- vqbet:向量量化行为变换器
- pi0:基础策略实现
5.1 ALOHA ACT
5.2 diffusion policy
5.3 tdmpc
5.4 vqbet
5.5 pi0:涉及配置、模型训练/推理、attention优化等
后已把本部分独立出去成为,详见《LeRobot源码剖析——对机器人各个动作策略的统一封装:包含ALOHA ACT、diffusion policy、VLA模型π0》
第六部分 仿真环境与实际机器人控制
6.1 common/envs:仿真环境下的任务示例
- aloha:双臂机器人操作环境
- pusht:推动物体任务环境
- xarm:机械臂控制环境
且每个环境都定义了观察空间和动作空间
6.2 common/robot_devices:实际机器人硬件控制
本部分包含:相机控制cameras(OpenCV, Intel RealSense)、电机控制motors(Dynamixel, Feetech)、机器人配置和控制robots
其中机器人又包括以下这几种机器人
- aloha: 双臂机器人
- koch: 单臂机器人
- so100: 廉价机器人实现
- moss: 模块化机器人
- lekiwi: 移动机器人平台
第七部分 configs配置系统:涉及策略/训练/评估的一系列配置
- default.py:默认配置
- eval.py:评估配置
- policies.py:策略配置
- train.py:训练配置
- parser.py:配置解析器
- types.py:类型定义
// 待更


















 2998
2998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











