






零门槛AI视频生成技术解析:多模态模型应用实践及实操案例
一、技术演进背景
根据ICCV 2023会议报告,视频生成模型呈现三大突破:
- 运动连贯性提升:动作序列预测误差降低42%
- 物理仿真增强:布料/流体模拟真实度达87%
- 跨模态理解:文本-视觉语义匹配准确率91%
二、核心实现原理
2.1 运动动力学建模
采用双流神经网络架构:
class MotionGenerator(nn.Module):
def __init__(self):
self.spatial_stream = ResNet50()
self.temporal_stream = TransformerEncoder()
def forward(self, img):
spatial_feat = self.spatial_stream(img)
motion_params = self.temporal_stream(spatial_feat)
return motion_params
关键参数配置表:
| 模块 | 参数设置 | 作用说明 |
|---|---|---|
| 空间特征提取 | 输出维度512 | 捕捉静态特征 |
| 时间编码器 | 8头注意力机制 | 建模运动轨迹 |
| 运动解码器 | 三层LSTM | 生成连续帧数据 |
2.2 物理约束机制
建立三重约束体系:
- 碰撞检测:连续刚体动力学算法
- 材质模拟:基于PBR的物理渲染
- 环境交互:风场/重力场模拟
三、工程实践指南
3.1 标准工作流程
推荐技术路线:
输入预处理 → 特征编码 → 运动生成 → 物理渲染 → 后处理优化
具体实现步骤:
- 输入图像尺寸标准化(1024×1024)
- 使用MediaPipe进行关键点检测
- 运动轨迹生成(采样步长0.1秒)
- 添加环境光照效果(HDR全景贴图)
3.2 典型应用场景
| 场景类型 | 技术要点 | 质量评估指标 |
|---|---|---|
| 角色动画 | 骨骼绑定精度>90% | 关节运动平滑度 |
| 特效生成 | 粒子系统规模>10^6 | 物理仿真准确度 |
| 场景转换 | 语义分割准确率>95% | 过渡帧连贯性 |
四、质量优化方案
4.1 常见问题处理
(配图建议:错误案例修正流程图)
| 异常现象 | 优化策略 | 技术原理 |
|---|---|---|
| 运动失真 | 增加运动约束权重 | 拉格朗日乘数法 |
| 材质穿透 | 强化碰撞检测迭代次数 | GJK算法优化 |
| 光照不匹配 | 使用HDR环境贴图 | 基于图像的照明 |
4.2 效果增强技巧
- 时序一致性优化:光流引导的帧插值
- 细节增强:高分辨率分块渲染
- 艺术化处理:风格迁移后处理
技术总结:本文揭示了当前AI视频生成的核心技术原理,重点解析了运动建模与物理仿真的实现方法。建议开发者在实践中注意:
- 建立运动学约束规则集
- 采用渐进式渲染策略
- 进行多尺度质量评估
五、实操案例
猴哥以自己的动漫形象作为参考,给大家做了一些示范案例,老规矩,先一起来看看效果。
先来一个帅的:英雄觉醒
AI视频1
再来一个反差的:互换性别
AI视频2
呼声比较高的飞天梦轻松实现:一键飞行
AI视频3
还有能把心人萌化的萌芽熊:
AI视频4
怎么样?有没有觉得挺有趣挺好玩?除此之外,还有非常多的模型可以选择,比如:隔空拥抱、万物生花、人物亲吻、一键换衣等各种互联网上的爆款玩法。



所有的玩法,不需要复杂的提示词指令和昂贵的创作成本,直接点击一键制作,就能轻松生成同款AI视频。
具体操作如下:
-
打开Vidu
-
点击AI模板
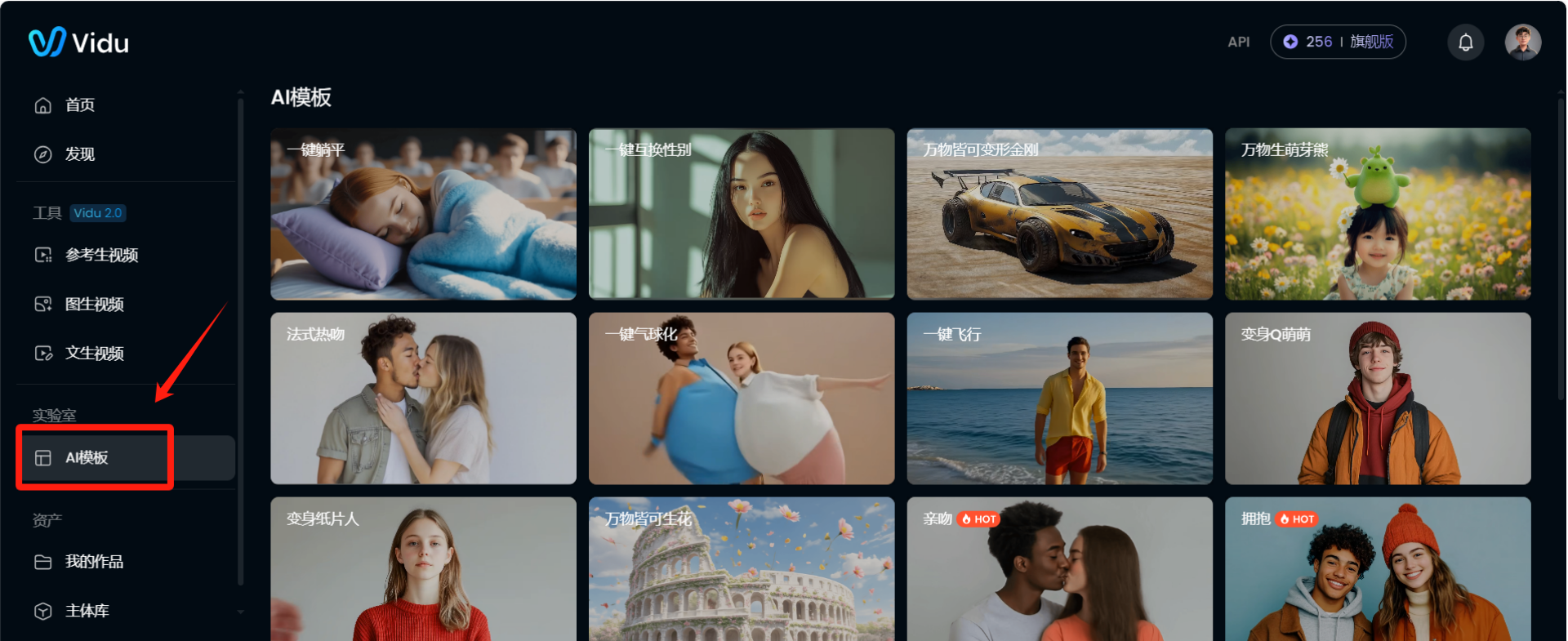
-
进入模板界面
-
选择想要生成的内容(猴哥以“人物飞行”为例,给大家举例说明)
-
点击创作
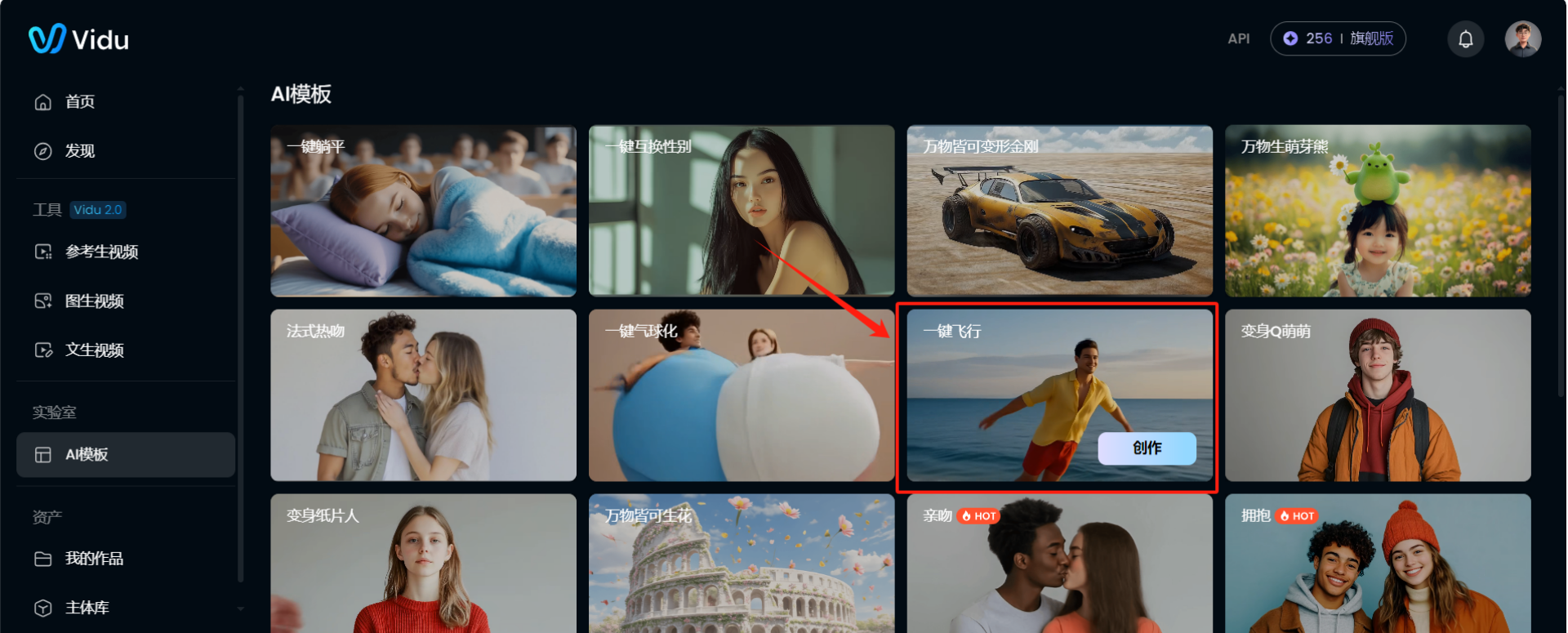
-
上传图片(注意查看标题下方注意事项)
-
点击创作
-
等待生成
-
下载保存


只需按要求上传照片,就能轻松制作想要的视频,其他的内容操作方法相同,只需动动手指便可轻松完成。
当然在快速制作,收获快乐的同时,也可以想想如何利用这些黑科技去进行变现。
比如:有人通过制作隔空拥抱视频,在自媒体平台接订单、接工具推广等。有人通过A试衣,帮服装制造业的老板做落地服务等,这些都是变现的路径。
关于工具的使用:Vidu目前没有上线手机端,建议大家用电脑直接登录官网使用。新人每天送免费积分,可以多注册几个号薅羊毛。有条件的也可以选择开会员。
以上就是今天分享的内容啦,觉得猴哥的文章有用,记得点赞、关注、收藏、转发,祝大家发财!

















 64
64

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









