





深度学习 (Deep Learning)
The general understanding of neural networks is that computations are required in order to adjust the weights of a neural network so that it could perform a certain task on a given dataset. However, it seems like it is not quite true. Apparently, given a randomly initialized dense neural network:
对神经网络的一般理解是,需要进行计算才能调整神经网络的权重,以便它可以在给定的数据集上执行特定任务。 但是,这似乎不是真的。 显然,给定一个随机初始化的密集神经网络:
- There exist sub-networks that when trained, can achieve a performance as well as the original network after training. 存在子网,经过培训后,可以达到与培训后的原始网络相同的性能。
- Even more surprising, there exist sub-networks that without any training, can perform way better than the random initialization on a certain task. For example, on the MNIST dataset, it can achieve up to 86% accuracy and on the CIFAR-10 dataset, an accuracy of 41% can be achieved! 更令人惊讶的是,存在子网,无需进行任何培训,其性能就可以比对某些任务进行随机初始化更好。 例如,在MNIST数据集上,它可以达到86%的精度,而在CIFAR-10数据集上,可以达到41%的精度!
The sub-networks in the first case are called Lottery Tickets, as they have won the lottery of initialization. And in the second case, Supermasks are the means by which we can represent the chosen weights of sub-networks. In this post, I explain what is a Super mask and how we can find Supermasks through back-propagation.
第一种情况下的子网称为彩票 ,因为它们赢得了初始化的彩票。 在第二种情况下,“ 超级掩码”是我们可以用来表示所选子网权重的方法。 在这篇文章中,我将解释什么是超级蒙版以及如何通过反向传播找到超级蒙版。
我们为什么要费心寻找这样的子网? (Why should we bother look for such sub-networks?)
The weights of a neural network are generated randomly. However, in reality, the random numbers are not that random. I mean, with the same seed number, we can generate the same sequence of rAnDoM NuMbErS, DETERMINISTICALLY!
神经网络的权重是随机生成的。 但是,实际上,随机数并不是那么随机。 我的意思是,使用相同的种子编号,我们可以确定地生成相同的rAnDoM NuMbErS序列!
Also, the sub-networks can be presented with binary sequences. Therefore, the whole parameters of a huge neural network can be represented with a seed number and several binary masks. Which in practice are compressed representations of the weights of the neural network?
而且,可以用二进制序列来呈现子网。 因此,巨大的神经网络的整个参数可以用种子数和几个二进制掩码来表示。 实际上,神经网络权重的压缩表示形式是哪一种?
什么是超级面具? (What is a Supermask?)
Before getting hands-on code, let’s first discuss what a Supermask is. A Supermask is a binary matrix with a similar shape to the weight matrix of a linear layer. Wherever elements of the Supermask are 1, the corresponding elements on the weight matrix will be kept intact. Otherwise, they will be set to zero. A simple element-wise product of Supermask and the weight matrix will get the job done.
在获得动手代码之前,让我们首先讨论什么是超级掩码。 超级掩模是具有与线性层的权重矩阵相似的形状的二进制矩阵。 超级蒙版的元素为1时,权重矩阵上的相应元素将保持不变。 否则,它们将被设置为零。 Supermask和权重矩阵的简单元素乘积即可完成工作。
“A picture is worth a thousand words.” Right?
“一张图片胜过千言万语。” 对?
By setting the values of a weight matrix to zero with a mask, we are actually choosing a sub-network of the fully connected network. Just like the image below:
通过使用掩码将权重矩阵的值设置为零,我们实际上是在选择完全连接的网络的子网。 如下图所示:
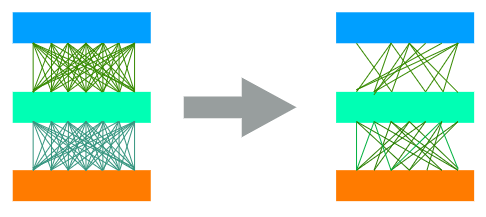
如何找到一个Supermask? (How to find a Supermask?)
A supermask may be found through back-propagation by the method described in this paper. Let Wf represent the weight matrix of a linear layer that is initialized randomly and remains constant afterward. And let Wm represent another weight matrix that is also initialized randomly and has the same shape as Wf. Unlike Wf, the matrix Wm will be updated through backpropagation. Wm is passed through an element-wise sigmoid function to generate probabilities for the Bernoulli function:
超级掩模可以通过本文描述的方法通过反向传播找到。 令Wf代表线性层的权重矩阵,该权重矩阵是随机初始化的,之后保持不变。 令Wm代表另一个权重矩阵,该矩阵也被随机初始化并且具有与Wf相同的形状。 与Wf不同,矩阵Wm将通过反向传播进行更新。 Wm通过按元素的S型函数传递,以生成Bernoulli函数的概率:
Then, an element-wise Bernoulli function, generates a binary mask by considering each element of Wb as the probability of Bernouli distribution:
然后,通过将Wb的每个元素视为伯努利分布的概率,逐元素伯努利函数生成二进制掩码:
The matrix M, is a binary mask. It is then used for masking the values of the fully connected weight matrix (Wf) in order to calculate Ws, the effective weight matrix (i.e weights of the sub-network):
矩阵M 1是二进制掩码。 然后,它用于掩盖完全连接的权重矩阵( Wf)的值 ,以便计算Ws ,即有效权重矩阵(即子网的权重):
Finally, the weight of the sub-network can be applied to the inputs and then passed through the activation function in order to calculate the predicted output:
最后,可以将子网的权重应用于输入,然后通过激活函数传递,以计算预测的输出:
As we will see in the implementation, this can be extended to multi-layer architecture as well. In the back-propagation process, the gradients of loss w.r.t Wm are calculated. So, the Wm is updated iteratively.
正如我们将在实现中看到的那样,这也可以扩展到多层体系结构。 在反向传播过程中,将计算损耗wrt Wm的梯度。 因此, Wm会进行迭代更新。
In the following section, I discuss the implementation of this procedure, in PyTorch.
在以下部分中,我将在PyTorch中讨论此过程的实现。
给我看代码! (Show me the Code!)
Now that we got a general idea and the mathematical foundations, implementing it is straightforward. First of all, I should mention that the Bernouli function in PyTorch, does not keep track of gradients. So, I define my own version of Bernouli function that supports gradients:
现在我们有了一个一般的想法和数学基础,实现它很简单。 首先,我要提到的是PyTorch中的Bernouli函数不能跟踪渐变。 因此,我定义了自己的支持梯度的Bernouli函数版本:
class Bern(torch.autograd.Function):
"""
Custom Bernouli function that supports gradients.
The original Pytorch implementation of Bernouli function,
does not support gradients.
First-Order gradient of bernouli function with prbabilty p, is p.
Inputs: Tensor of arbitrary shapes with bounded values in [0,1] interval
Outputs: Randomly generated Tensor of only {0,1}, given Inputs as distributions.
"""
@staticmethod
def forward(ctx, input):
# inputs are element-wise probability for bernouli functions.
ctx.save_for_backward(input)
# element-wise sampling
return torch.bernoulli(input)
@staticmethod
def backward(ctx, grad_output):
# the inputs are probability values(p)
pvals = ctx.saved_tensors
# 1st-order derivation of bernouli function with probability p, equals to p.
return pvals[0] * grad_outputThe next step is to create a custom linear layer, that supports masking internally. Which I call MaskedLinear. Although the codes are self-explanatory (Thanks to Facebook for PyTorch :D ), I have provided comments for more clarity:
下一步是创建一个自定义线性层,该层内部支持遮罩。 我称其为MaskedLinear。 尽管代码是不言自明的(感谢PyTorch:D的Facebook支持),但我还是提供了一些注释,以使内容更加清晰:
class MaskedLinear(nn.Module):
"""
Which is a custom fully connected linear layer that its weights $W_f$
remain constant once initialized randomly.
A second weight matrix $W_m$ with the same shape as $W_f$ is used for
generating a binary mask. This weight matrix can be trained through
backpropagation. Each unit of $W_f$ may be passed through sigmoid
function to generate the $p$ value of the $Bern(p)$ function.
"""
def __init__(self, in_features, out_features, device=None):
super(MaskedLinear, self).__init__()
self.device = device
# Fully Connected Weights
self.fcw = torch.randn((out_features,in_features),requires_grad=False,device=device)
# Weights of Mask
self.mask = nn.Parameter(torch.randn_like(self.fcw,requires_grad=True,device=device))
def forward(self, x):
# Generate probability of bernouli distributions
s_m = torch.sigmoid(self.mask)
# Generate a binary mask based on the distributions
g_m = Bern.apply(s_m)
# Keep weights where mask is 1 and set others to 0
effective_weight = self.fcw * g_m
# Apply the effective weight on the input data
lin = F.linear(x, effective_weight)
return lin
def __str__(self):
prod = torch.prod(*self.fcw.shape).item()
return 'Mask Layer: \n FC Weights: {}, {}, MASK: {}'.format(self.fcw.sum(),torch.abs(self.fcw).sum(),self.mask.sum() / prod)Now, we can put these layers together to form a fully connected neural network:
现在,我们可以将这些层放在一起以形成一个完全连接的神经网络:
class MaskedANN(nn.Module):
def __init__(self, device):
super(MaskedANN, self).__init__()
self.ml1 = MaskedLinear(784, 1200,device)
self.ml2 = MaskedLinear(1200, 1200,device)
self.ml3 = MaskedLinear(1200,10,device)
def forward(self, x):
x = self.ml1(x)
x = F.relu(x)
x = self.ml2(x)
x = F.relu(x)
x = self.ml3(x)
return x
def get_layers(self):
return [self.ml1, self.ml2, self.ml3]
def print_weights(self):
print('FC 1: ', self.ml1.weight.sum().item(), torch.abs(self.ml1.weight).sum().item())
print('FC 2: ', self.ml2.weight.sum().item(), torch.abs(self.ml2.weight).sum().item())
print('FC 3: ', self.ml3.weight.sum().item(), torch.abs(self.ml3.weight).sum().item())Finally, this model can be trained with the regular built-in back-propagation of PyTorch:
最后,可以使用PyTorch的常规内置反向传播训练此模型:
mask_net = MaskedANN(device)
loss_func = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(mask_net.parameters())
epochs = 50
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = mask_net(data)
loss = loss_func(output, target)
loss.backward()
optimizer.step()
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))I have provided the complete source code of this project available on Github. It is accessible on my own account. And can be run directly on google colab.
我已经在Github上提供了该项目的完整源代码。 可通过我自己的帐户访问。 并且可以直接在google colab上运行。
总结讨论! (Wrapping The Discussion Up!)
I find the concept of Lottery Tickets and Supermasks so fascinating. There has been extensive on-going research concerning these topics. And the algorithm implemented here was the most simple one to implement among others. However, I encourage the readers to check out the main references upon which I wrote this article. Also, I appreciate the time you spent reading this. Please let me know of any scientific and/or technical errors that might be present in this article. And share this article if you find it interesting and useful!
我发现彩票和超级面具的概念非常有趣。 关于这些主题已经进行了广泛的研究。 在这里实现的算法是最简单的实现之一。 但是,我鼓励读者阅读撰写本文的主要参考资料。 另外,我感谢您花时间阅读本文。 请让我知道本文中可能存在的任何科学和/或技术错误。 如果您觉得这篇文章有趣且有用,请与我们分享!















 6152
6152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









