





Deep learning can be said as a subset of machine learning, which uses an artificial neural network to solve supervised, unsupervised and semi-supervised problems. Architectures of deep learning such as deep neural networks, recurrent neural networks(RNN), convolution neural network(CNN) are used in various fields such as computer vision(CV), speech recognition, natural language processing(NLP), bioinformatics, drug design and many more.
深度学习可以说是机器学习的子集,它使用人工神经网络来解决有监督,无监督和半监督问题。 深度学习的架构,例如深度神经网络 , 递归神经网络(RNN) , 卷积神经网络(CNN),被用于计算机视觉(CV),语音识别,自然语言处理(NLP),生物信息学,药物设计等各个领域还有很多。
Performance of every neural network depends on its building blocks, which are activation function, Loss function and Optimizer. Each new problem has different aspects, requirements, different data types and hence needs different building blocks to optimum accuracy. One cannot use the same neural network for every problem. That is why it is essential to understand which functions to use when. In this article we are going to talk about different loss functions and when to use them.
每个神经网络的性能取决于其构建模块,即激活函数,损失函数和优化器 。 每个新问题都有不同的方面,要求,不同的数据类型,因此需要不同的构造块才能达到最佳精度。 不能为每个问题都使用相同的神经网络。 因此,必须了解何时使用哪些功能。 在本文中,我们将讨论不同的损失函数以及何时使用它们。
Error /loss/ cost is just the discrepancy between the predicted value and actual value which we are trying to predict. Don’t worry if you don’t get a complete idea just here yet, we are going to talk about it in detail in this article.
误差/损失/成本只是我们试图预测的预测值与实际值之间的差异。 如果您还没有完整的想法,请不要担心,我们将在本文中详细讨论它。
Let’s first understand the different terminologies used in the industry which are error, loss function and cost function.
首先让我们了解行业中使用的不同术语,即误差,损失函数和成本函数。
Error is a broader term corresponding to error which could be associated with a single record of dataset, mini-batch or complete dataset. It simply signifies an error.
错误是与错误相对应的广义术语,它可能与数据集,小型批次或完整数据集的单个记录相关联。 它只是表示错误。
The loss function is the error associated with only one single record. whereas cost function is an error associated with the complete dataset(or batch). All the loss functions together contribute to cost function.
损失函数是仅与一条记录相关的错误。 而成本函数是与完整数据集(或批次)相关的错误。 所有损失函数共同构成成本函数。
In the below representation, the same is showcased visually. Summation of all the loss functions together with some normalization factor is basically a cost function which all come under the umbrella of error.
在下面的表示中,视觉上展示了相同的内容。 所有损失函数的求和加上一些归一化因子基本上是一个代价函数,所有这些函数都属于误差范围。

1. L1损失函数 (1. L1 Loss Function)
L1 loss function stands for Least Absolute Deviation(LAD). It is just the absolute magnitude of the difference between true output and the predicted output.
L1损失函数代表最小绝对偏差(LAD) 。 它只是真实输出与预测输出之差的绝对值。

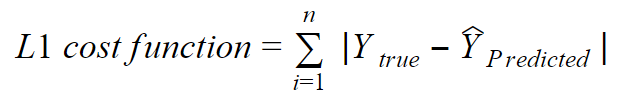
When the difference between true output and predicted output is very small(probably after some number of iterations), the cost is diminished as it is just linear difference between them and hence the learning becomes very slow, to resolve this issue L2 loss is introduced.
当真实输出与预测输出之间的差异很小时(可能在经过多次迭代之后),由于它们之间只是线性差异,因此成本降低了,因此学习变得非常缓慢,因此引入了L2损耗。
2. L2损失函数 (2. L2 Loss Function)
L2 loss stands for Least Square(LS) errors. In L2 loss, instead of taking absolute of difference between true output and predicted output, it is squared. Hence we get a positive value and also, the loss is magnified. It is like looking at a loss through lenses. So learning will be faster in case of L2 loss.
L2损失代表最小二乘(LS)错误。 在L2损失中,不是对真实输出与预测输出之间的差取绝对值,而是对其求平方。 因此,我们得到一个正值,并且损失也被放大了。 这就像透过镜头看损失一样。 因此,如果丢失L2,学习会更快。


L2 loss does the square of difference so it is sensitive to outliers(As for outliers, the difference is large and its square is even larger). Hence L2 loss does not perform well with a dataset with a lot of outliers.
L2损失具有差异的平方,因此它对异常值敏感(对于异常值,差异较大,并且其平方甚至更大)。 因此,L2损失对于具有大量异常值的数据集的效果不佳。
3.胡贝尔损失 (3. Huber Loss)
L1 loss has an issue when the difference between true and predicted output is small and L2 loss has an issue when the difference is large(i.e. in case of outliers). To deal with both issues of L1 and L2 loss, Huber loss is introduced. Huber loss is a combination of both L1 and L2 loss. for small differences, it uses least square and for large differences linear difference.
当真实输出与预测输出之间的差异较小时,L1损失会出现问题;当差异较大时(即,在离群值的情况下),L2损失会出现问题。 为了处理L1和L2损耗这两个问题,引入了Huber损耗。 胡贝尔损耗是L1和L2损耗的组合。 对于小差异,使用最小二乘;对于大差异,使用线性差异。

a delta is generally a small number defined by us. Huber loss is one of the best option available.
增量通常是我们定义的少量数字。 胡贝尔损耗是可用的最佳选择之一。
4.铰链损失 (4. Hinge Loss)
Hinge loss is used only in case of a classification problem. It cannot be used in regression problems. It is useful for maximum margin classification, so works well with Support Vector Machine(SVM)
铰链损耗仅在分类问题的情况下使用。 它不能用于回归问题。 它对于最大边距分类很有用,因此可以与支持向量机(SVM)一起很好地工作
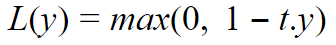
Depending on what class we are trying to predict, t is +1 or -1. When t & y are of the same sign, it means the class predicted is correct and hence loss will be 0. Otherwise, for the opposite signs, of y & t, loss linearly increases with the value of y.
根据我们尝试预测的类, t是+1或-1 。 当t & y具有相同的符号时,这意味着预测的类是正确的,因此损失将为0 。 否则,对于y & t的相反符号,损耗随y的值线性增加。
5.交叉熵损失函数 (5. Cross-Entropy Loss Function)
Cross-Entropy Loss function, also known as log loss function is used for measuring the performance of the classification problem whos output is between 0 to 1. Value of cross-entropy loss function increases as the predicted probability diverges from the actual label.
交叉熵损失函数(也称为对数损失函数)用于测量输出在0到1之间的分类问题的性能。 交叉熵损失函数的值随着预测概率与实际标记的偏离而增加。
For two-class classification, the loss function is given as follows:
对于两类分类,损失函数如下:

For multi-class classification, it can be generalised to:
对于多类分类,可以将其概括为:

Cross-entropy and log loss are slightly different terms but in machine learning, they achieve the same.
交叉熵和对数损失是稍微不同的术语,但是在机器学习中,它们达到相同的效果。
Following two combinations are used frequently in practice:
在实践中经常使用以下两种组合:
Softmax交叉熵 (Softmax Cross-Entropy)
It is a combination of softmax activation function plus cross-entropy loss, used for multiclass classification problem.
它是softmax激活函数加交叉熵损失的组合,用于多类分类问题。
乙状结肠交叉熵 (Sigmoid Cross-Entropy)
It is a combination of sigmoid activation function plus cross-entropy loss. Unlike softmax cross-entropy, the outcome of this is not affected by the output of other neurons in the same layer. Hence it is used for multi-class classification problem when one class’s outcome should not affect the outcome of other class.
它是乙状结肠激活功能加交叉熵损失的组合。 与softmax交叉熵不同,它的结果不受同一层中其他神经元输出的影响。 因此,当一个类别的结果不应影响另一类别的结果时,它可用于多类别分类问题。















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









