






0、大模型&GPT产业技术交流群
欢迎大家微信搜索“AIGCmagic”关注公众号,回复“大模型”,加入大模型&GPT技术交流群,一起交流学习。
一、Llama系列技术细节汇总
1、llama1
技术详解
1.1、相关资源链接
论文题目:Open and Efficient Foundation Language Models Meta AI 23.02
论文地址:https://arxiv.org/pdf/2302.13971.pdf
入门指南:https://ai.meta.com/llama/get-started/
(这是 Meta AI发布的 Llama 入门指南。内容包含Llama 模型微调、服务、量化、提示、集成等的相关技巧。)
1.2、关键技术指标
由Meta AI 发布,包含 7B、13B、33B 和 65B 四种参数规模的开源基座语言模型。
数据集:模型训练数据集使用的都是开源的数据集。
模型结构:原始的Transformer由编码器(Encoder)和解码器(Decoder)两个部分构成。同时Encoder和Decoder这两部分也可以单独使用,llama是基于Transformer Decoder的架构,在此基础上上做了以下改进:
(1)llama将layer-norm 改成RMSNorm(Root Mean square Layer Normalization),并将其移到input层,而不是output层。
(2)采用SwiGLU激活函数。
(3)采用RoPE位置编码。
分词器:分词器采用BPE算法,使用 SentencePiece 实现,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符。词表大小为 32k 。
优化器:AdamW,是Adam的改进,可以有效地处理权重衰减,提供训练稳定性。
learning rate:使用余弦学习率调整 cosine learning rate schedule,使得最终学习率等于最大学习率的10%,设置0.1的权重衰减和1.0的梯度裁剪。warmup的step为2000,并根据模型的大小改变学习率和批处理大小。
模型效果:llama-13B(gpt-3 1/10大小)在多数benchmarks上超越gpt-3 (175B)。在规模较大的端,65B参数模型也与最好的大型模型(如Chinchilla或PaLM-540B)也具有竞争力。
2、llama2技术详解
2.1、相关资源链接
论文题目: Open Foundation and Fine-Tuned Chat Models Meta AI 23.07
原文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
论文地址:arXiv reCAPTCHA
项目地址:https://github.com/facebookresearch/llama
官方公告:https://ai.meta.com/llama/
官方论文:https://huggingface.co/papers/2307.09288
2.2、关键技术指标
由Meta AI 发布,包含 7B、13B 、 34B、70B 四种参数规模的基座语言模型,除了34B其他模型均以开源。开源且免费可商用
数据集:模型训练数据集使用的都是开源的数据集,相比上一代的训练数据增加了 40%,达到了增至2万亿个token,训练数据中的文本来源也更加的多样化。Llama 2对应的微调模型是在超过100万条人工标注的数据下训练而成。(但是Llama 2
语料库 仍以英文(89.7%)为主,而中文仅占据了其中的 0.13%。这导致 Llama 2 很难完成流畅、有深度的中文对话。)
模型结构:
(1)Llama 2与Llama 1的主要结构基本一致同样也是在transformer decoder结构上做了3大改进:将layer-norm改成RMSNorm(Root Mean square Layer Normalization),并将其移到input层,而不是output层、采用SwiGLU激活函数、采用旋转位置嵌入RoPE。
(2)Llama 2上下文长度由之前的2048升级到4096,可以理解和生成更长的文本。
(3)7B和13B 使用与 LLaMA 相同的架构,34B和70B模型采用分组查询注意力(GQA)。
优化器:AdamW 其中β1=0.9,β2=0.95,eps=10−5。
learning rate:使用cosine learning rate schedule,使得最终学习率等于最大学习率的10%,设置0.1的权重衰减和1.0的梯度裁剪。warmup的step为2000,并根据模型的大小改变学习率和批处理大小。
分词器:分词器采用BPE算法,使用 SentencePiece 实现,将所有数字拆分为单独的数字,并使用字节来分解未知的 UTF-8 字符。词汇量为 32k token。
模型效果:从模型评估上看,Llama 2在众多的基准测试中,如推理、编程、对话能力和知识测验上,都优于Llama1和现有的开源大模型。Llama 2 70B在MMLU和GSM8K上接近GPT-3.5(OpenAI,2023),但在编码基准方面存在显著差距。Llama 2 70B的结果在几乎所有基准上都与PaLM(540B)(Chowdhery et al.,2022)不相上下或更好。Llama 2 70B与GPT-4 和PaLM-2-L在性能上仍有很大差距。
Llama2相比Llama1的升级:
(1)LLama2训练数据相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,模型理解能力得以提升可以生成更长的文本。
(2)模型训练数据集使用的相比上一代的训练数据增加了 40%,并且更加注重安全&隐私问题。
(3)发布了llama-2-chat。(在公开数据集上预训练以后引入SFT(有监督微调)、RLHF(人类反馈强化学习)+拒绝采样+近端策略优化 (PPO)两个优化算法)。
由于Llama2的性能比较优秀,Meta在2023年8月发布了专注于代码生成的Code-Llama,包含 7B、13B 、 34B、70B 四个版本。
Meta试图证明小模型在足够多的的数据上训练后,效果也能达到甚至超过大模型。
3、llama3技术详解
3.1、相关资源链接
Meta 最新开源的大语言模型Llama 3 ,于2024 年 4 月 18 日发布,这也是号称目前开源最强的 LLM。
官方文档链接:https://ai.meta.com/blog/meta-llama-3/
在线体验:https://www.llama2.ai/
github:GitHub - meta-llama/llama3: The official Meta Llama 3 GitHub site
LMSYS Chatbot Arena 排行榜:https://chat.lmsys.org/?leaderboard
Hugging Faced:meta-llama/Meta-Llama-3-8B · Hugging Face
3.2、关键技术指标
数据集:llama2相比上一代的训练数据增加了 40%,达到了2T个token,Llama 3 的预训练数据集增加至15T,这些数据都是从公开来源收集的高质量数据集(依旧强调高质量的训练数据集至关重要)。其中包括了4 倍以上的代码 token 以及 30 种语言中 5% 的非英语 token(这意味着LLAMA-3在代码能力以及逻辑推理能力的性能将大幅度提升)。微调数据包括公开可用的指令数据集以及超过1000万个人工注释的示例。预训练和微调数据集均不包含元用户数据。(主要还是以英语为主了,中文占比依旧很低,前面测试也可以看出来) 。通过开发一系列数据过滤流程:包括使用启发式筛选器、NSFW 筛选器、语义重复数据删除方法和文本分类器
来预测数据质量。以及使用 Llama 2 为 Llama 3 提供支持的文本质量分类器生成训练数据。
模型结构:Llama 3 中选择了相对标准的纯解码器decoder-only transformer架构,总体上与 Llama 2 相比没有重大变化。在 Llama 2 中只有34B,70B使用了分组查询注意 (GQA),但为了提高模型的推理效率,Llama 3所有模型都采用了GQA。
分词器:与Llama 2不同的是,Llama 3将tokenizer
由sentencepiece换成tiktoken,词汇量从 的32K增加到 128K,增加了 4 倍。更大的词汇库能够更高效地编码文本,增加编码效率,可以实现更好的下游性能。不过这也会导致嵌入层的输入和输出矩阵尺寸增大,模型参数量也会增大。
序列长度:输入上下文长度从 4096(Llama 2)和 2048(Llama 1)增加到 8192。但相对于GPT-4 的 128K来说还是相当小。
缩放定律:对于像 8B 参数这样“小”的模型来说,扩展法则
Chinchilla 最优训练计算量对应于 ~200B Tokens,但是Meta使用到了 15T Tokens。从目前模型效果来看,Meta使用的Scaling Law法则是非常有效的,Meta得到了一个非常强大的模型,它非常小,易于使用和推理,而且mate表示,即使这样,该模型似乎也没有在标准意义上“收敛”,性能还能改善。这就意味着,一直以来我们使用的 LLM 训练是不足的,远远没有达到使模型收敛的那个点。较大的模型在训练计算较少的情况下可以与较小模型的性能相匹配,但考虑到推理过程中使效率更高,还是会选择小模型。如此说来训练和发布更多经过长期训练的甚至更小的模型,会不会是以后大模型发展的一个方向?
系统:为了训练最大的 Llama 3 模型,Meta结合了三种类型的并行化:数据并行化、模型并行化
和管道并行化。最高效的实现是在 16K GPU 上同时训练时,每个 GPU 的计算利用率超过 400 TFLOPS。在两个定制的 24K GPU 集群上进行了训练。
指令微调:为了在聊天用例中充分释放预训练模型的潜力,Meta对指令调整方法进行了创新。训练方法结合了监督微调 (SFT)、拒绝采样、近端策略优化(PPO) 和直接策略优化 (DPO) 的组合。这种组合训练,提高了模型在复杂推理任务中的表现。
模型效果:LLaMA 3有基础版,和 instruct两个版本。每个版本拥有 8B 和 70B 两种参数规模的模型,它们在多项行业基准测试中展示了最先进的性能,而且 instruct效果相当炸裂。
4、llama3.1技术详解
2024年7月23日,Meta重磅推出Llama 3.1。发布的模型有 8B、70B 和 405B 三个尺寸。
其中最受关注的是 Llama 3.1 405B。Meta 表示 Llama 3.1 405B 是目前全球最大、功能最强的公共基础模型,可与 OpenAI 和 Google 开发的顶级模型一争高下。
Meta 在官方博客中表示:“Llama 3.1 405B 是首个公开可用的模型,在通用常识、可引导性、数学、工具使用和多语言翻译方面可与顶级 AI 模型相媲美。405B 模型的发布将带来前所未有的创新和探索机会。”
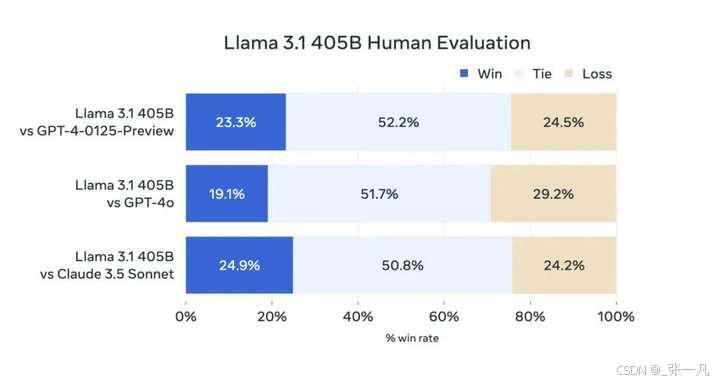
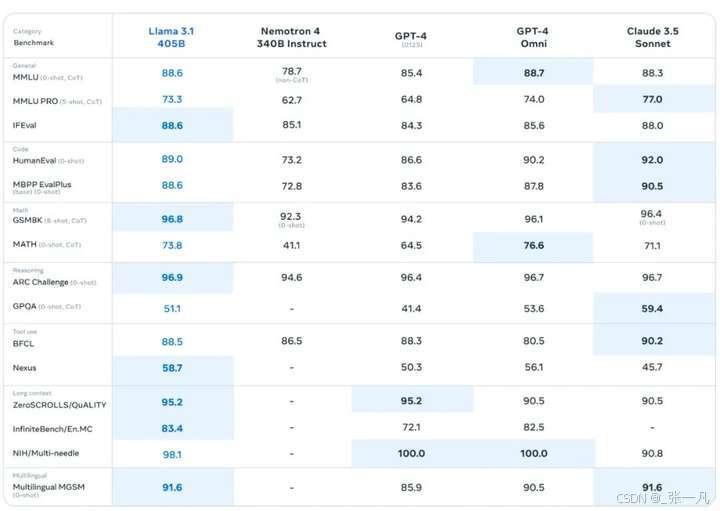
Meta 称他们在超过 150 个基准数据集上进行了性能评估,并将 Llama 3.1 与竞品进行了比较,结果显示 Llama 3.1 405B 在各项任务中都有能力与当前最先进的闭源模型一较高下。
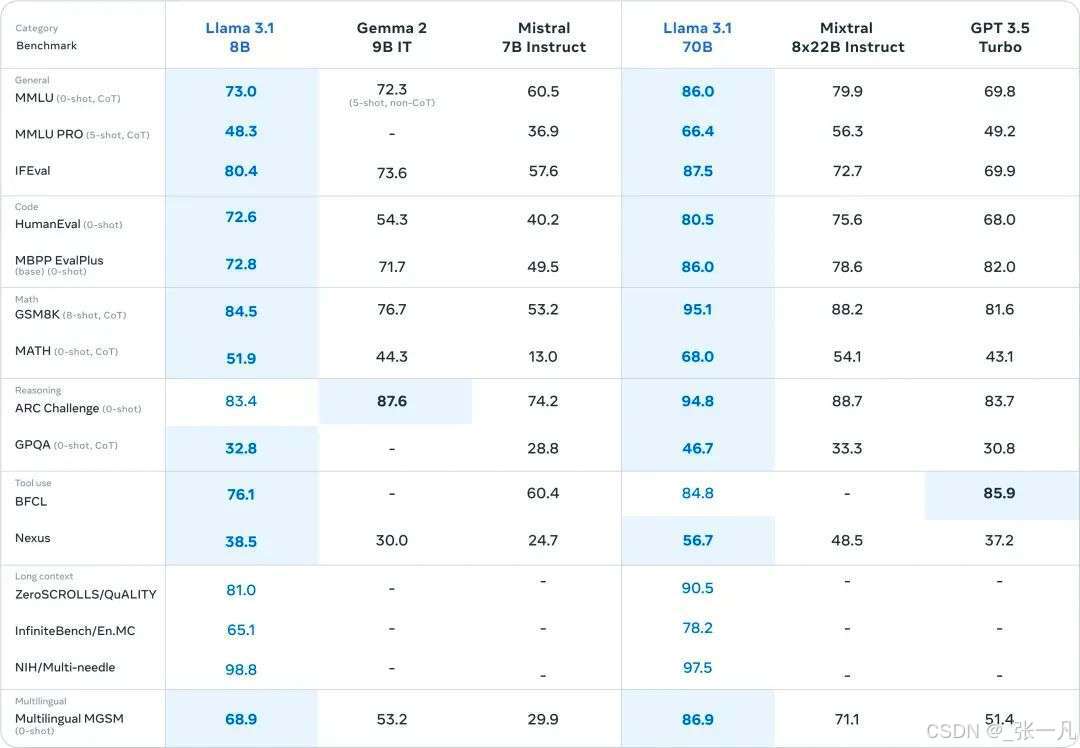
8B 和 70B 在与同级别的小参数模型对比中也表现优异。
 4.1、相关资源链接
4.1、相关资源链接
官网地址:https://ai.meta.com/blog/meta-llama-3-1/
论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
文档地址:https://llama.meta.com/docs/overview/
GitHub地址:GitHub - meta-llama/llama-models: Utilities intended for use with Llama models.
llama-agentic-system地址:GitHub - meta-llama/llama-stack-apps: Agentic components of the Llama Stack APIs
4.2、关键技术介绍
模型架构:纯解码器decoder-only transformer架构,进行小幅改动以最大化训练稳定性。
训练规模:在超过16,000个H100 GPU上进行训练,处理超过15万亿个token的语料库上预训练语言模型。
数据处理:优化预训练和后训练数据的质量和多样性,采用更严格的数据预处理和过滤方法。采用合成数据生成、数据过滤等技术大规模生成高质量指令fine-tune数据。
多语言支持:支持8种语言翻译等能力,扩展了上下文长度至128K。
工具使用:支持调用外部工具、代码生成等功能。
量化技术:将模型从16位量化到8位,降低推理计算需求,使405B模型能够在单节点服务器上运行。
指令和聊天微调:通过多轮对齐和合成数据生成,提升模型对用户指令的响应能力、质量和详细程度。
开源和可定制性:坚持开源理念,确保AI公平获取,避免权力过度集中。Llama模型权重公开可供下载,开发者可以完全定制模型以满足其需求,支持定制训练和推理部署。支持合成数据生产、模型蒸馏等前沿工作流,释放更多创新可能。真正实现开放获取的AI,推动AI技术更广泛应用。更新了许可协议,允许开发者使用Llama模型的输出来改进其他模型。
低成本:提供业内最低的每token成本,使更多开发者能够负担得起。与闭源模型相比,总体拥有更低的成本和更高的灵活性、可定制性。提供极低成本的产品服务。
广泛应用:支持实时和批量推理、监督微调、模型评估、连续预训练等多种高级工作流程。
生态系统支持:提供完善的工具和合作伙伴支持,从第一天起就可以进行生产部署,多家云供应商提供服务。
安全和责任:通过多种措施(如红队测试和安全微调)识别、评估和缓解潜在风险,持续致力于安全和负责任的开发。
5、llama3.2技术详解
5.1、相关资源链接
GitHub项目链接:GitHub - meta-llama/llama-models: Utilities intended for use with Llama models.
Llama 3.2官方链接:https://www.llama.com/
Llama 3.2 HuggingFace模型下载链接:https://huggingface.co/collections/meta-llama/
Llama 3.2博客文章链接:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
5.2、关键技术介绍
Llama 3.2系列涵盖了小型和中型视觉LLM(参数分别为11B和90B)以及适用于边缘和端侧的轻量级纯文本模型(1B和3B),包含了预训练和指令调优版本。该系列的特点如下:
1B和3B模型:这些模型能够处理长达128K的令牌上下文,位于行业前列,适用于设备端的总结、指令追踪以及边缘环境中的文本重写任务。
11B和90B视觉模型:在图像理解方面,性能超越了诸如Claude 3 Haiku等封闭模型,能够处理文档理解(包括图表和图形)、图像字幕生成以及基于自然语言描述的图像中对象精确定位等任务。
视觉LLM的训练过程始于Llama 3.1文本模型的预训练,并经历多个阶段:
-
首先集成图像适配器和编码器,并在大规模的噪声图像-文本对数据集上进行预训练。
-
然后在中等规模的、高质量且知识增强的图像-文本对数据集上进行进一步训练。
3.在Llama 3.2模型的后期训练阶段,采用了与文本模型相似的策略,进行了多轮的监督微调、拒绝采样和直接偏好优化以实现模型对齐。
4.在训练过程中,利用Llama 3.1模型生成合成数据,这些数据基于领域内图像,通过过滤和丰富问题与答案来提升质量。此外,采用奖励模型对所有的候选答案进行排序,以确保微调数据的高质量。
1B和3B的轻量级模型具备出色的多语言文本生成和工具调用能力,便于在端侧设备如手机或PC上部署,确保了数据的隐私性,因为所有数据都保持在设备上。
对于1B和3B模型,采用了剪枝和知识蒸馏两种技术,以实现设备的高效适配和高性能:
4.1 剪枝技术用于缩减现有模型的大小,同时在尽可能保留知识和性能的基础上,对Llama模型进行精简。
4.2 1B和3B模型采用了从Llama 3.1 8B模型中提取的结构化剪枝方法。该方法涉及有系统地移除网络中的某些部分,并调整权重和梯度的大小,以构建一个更小、更有效的模型,同时保持原始模型的性能。知识蒸馏则通过将较大网络的知识传递给较小网络,使得小模型能够通过教师模型获得比从头训练更好的性能。在剪枝之后,知识蒸馏被用来恢复模型的性能。
5.3、核心特性综述
轻量级文本模型:1B和3B模型针对移动和边缘设备优化,体积小巧却依然保持强大的文本处理能力,支持128K令牌的大语境,适用于文本摘要、重写和指令遵循等。
视觉模型:11B和90B模型擅长处理图像理解任务,支持图像与文本结合的多模态任务,如文档分析、图像描述生成、视觉推理和目标检测,通过集成图像编码器来处理复杂的视觉问题。
本地处理与隐私保护:模型可在设备本地运行,减少数据传输延迟,提高数据隐私保护,适用于手机、平板和物联网设备等对效率和隐私要求高的场景。
开放性与可定制性:Llama 3.2开放给开发者下载、修改和定制,满足不同应用需求,支持使用开源工具如torchtune和torchchat进行微调和部署。
硬件兼容性:模型针对Qualcomm、MediaTek、Arm等移动平台优化,并在AMD、NVIDIA、Intel、AWS、Google Cloud等主流云平台和硬件上提供支持。
开发工具套件:Llama 3.2提供LlamaStack工具集,包括CLI、API和Docker容器,便于在不同环境中部署模型,支持从单节点到云服务的多样化部署。
模型压缩与知识蒸馏:通过修剪和蒸馏技术减小模型尺寸,保持性能,使1B和3B模型在资源受限的设备上高效运行。
多语言支持:模型在多语言文本生成和理解方面表现优异,适用于全球化的应用场景。
安全性加强:配备Llama Guard保护系统,过滤不当输入和输出,确保模型在处理文本和图像时的安全性和责任感。
5.4、模型性能评估测试
Llama 3.2的视觉模型在图像辨识和多种视觉理解任务中,与顶尖的基础模型Claude 3 Haiku和GPT4o-mini展现了竞争力。3B模型在执行指令遵循、内容总结、快速文本重写和工具应用等任务时,超越了Gemma 22.6B和Phi 3.5-mini模型。同时,1B模型的表现与Gemma模型相当。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









