









论文中解释是:向量的点积结果会很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。怎么理解将sotfmax函数push到梯度很小区域?还有为什么scaled是维度的根号,不是其他的数?
答案:q,k向量点积后的结果数量级变大,经历过softmax函数的归一化之后,后续反向传播的过程中梯度会很小,造成梯度消失。进行scaled能够缓解这种情况。
Multi-head Attention为什么要做scaled - 卷王李狗蛋的文章 - 知乎
目录
为什么在其他 softmax 的应用场景,不需要做 scaled?
为什么在分类层(最后一层),使用非 scaled 的 softmax?
为什么会梯度消失的原因?
数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。
点积后的结果数量级大会导致反向传播梯度变小。造成梯度消失,参数更新困难。
 当输入g(x)函数的logits的数量级很大时,g(x)输出的是一个非常接近one-hot的向量[0,0,...1,...0,0]。
当输入g(x)函数的logits的数量级很大时,g(x)输出的是一个非常接近one-hot的向量[0,0,...1,...0,0]。
在self-attention中为什么要除以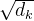 ?
?

方差越大也就说明,点积的数量级越大(以越大的概率取大值)。那么一个自然的做法就是把方差稳定到1,做法是将点积除以,将方差控制为1,也就有效地控制了前面提到的梯度消失的问题。
为什么要假设为均值为0,方差为1?
浅谈Transformer的初始化、参数化与标准化 - 科学空间|Scientific Spaces
在一般的教程中,推导初始化方法的思想是尽量让输入输出具有同样的均值和方差,通常会假设输入是均值为0、方差为1的随机向量,然后试图让输出的均值为0、方差为1。
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
核心是让输入输出具有同样的均值和方差,保持相同的数据分布。挑正态分布可能因为常见,均值为0、方差为1。因为简单?
为什么在其他 softmax 的应用场景,不需要做 scaled?
transformer中的attention为什么scaled? - 小莲子的回答 - 知乎


为什么在分类层(最后一层),使用非 scaled 的 softmax?
因为木有两个随机变量相乘的情况,所以不存在点积后的结果数量级大会导致反向传播梯度变小!

注意力机制的softmax溢出怎么解决?

原文链接
transformer中的attention为什么scaled? - TniL的回答 - 知乎

















 3127
3127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









