







| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 3.1 调试处理 | 回到目录 | 3.3 超参数训练的实践: Pandas vs. Caviar |
为超参数选择合适的范围 (Using an Appropriate Scale to Pick Hyperparameters)
在上一个视频中,你已经看到了在超参数范围中,随机取值可以提升你的搜索效率。但随机取值并不是在有效范围内的随机均匀取值,而是选择合适的标尺,用于探究这些超参数,这很重要。在这个视频中,我会教你怎么做。

假设你要选取隐藏单元的数量 n [ l ] n^{[l]} n[l] ,假设,你选取的取值范围是从50到100中某点,这种情况下,看到这条从50-100的数轴,你可以随机在其取点,这是一个搜索特定超参数的很直观的方式。或者,如果你要选取神经网络的层数,我们称之为字母 L L L ,你也许会选择层数为2到4中的某个值,接着顺着2,3,4随机均匀取样才比较合理,你还可以应用网格搜索,你会觉得2,3,4,这三个数值是合理的,这是在几个在你考虑范围内随机均匀取值的例子,这些取值还蛮合理的,但对某些超参数而言不适用。

看看这个例子,假设你在搜索超参数 α \alpha α (学习速率),假设你怀疑其值最小是0.0001或最大是1。如果你画一条从0.0001到1的数轴,沿其随机均匀取值,那90%的数值将会落在0.1到1之间,结果就是,在0.1到1之间,应用了90%的资源,而在0.0001到0.1之间,只有10%的搜索资源,这看上去不太对。
反而,用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取0.0001,0.001,0.01,0.1,1,在对数轴上均匀随机取点,这样,在0.0001到0.001之间,就会有更多的搜索资源可用,还有在0.001到0.01之间等等。
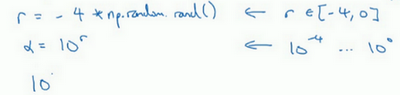
所以在Python中,你可以这样做,使r=-4*np.random.rand(),然后
a
a
a 随机取值,
a
=
1
0
r
a=10^r
a=10r ,所以,第一行可以得出
r
∈
[
−
4
,
0
]
r\in[-4,0]
r∈[−4,0] ,那么
a
∈
[
1
0
−
4
,
1
0
0
]
a\in[10^{-4},10^0]
a∈[10−4,100] ,所以最左边的数字是
1
0
−
4
10^{-4}
10−4 ,最右边是
1
0
0
10^0
100 。
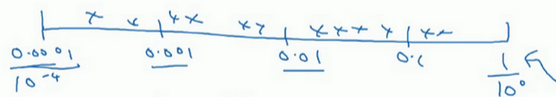
更常见的情况是,如果你在 1 0 a 10^a 10a 和 1 0 b 10^b 10b 之间取值,在此例中,这是 1 0 a 10^a 10a (0.0001),你可以通过 0.0001 0.0001 0.0001 算出 a a a 的值,即-4,在右边的值是 1 0 b 10^b 10b ,你可以算出 b b b 的值 1 1 1 ,即0。你要做的就是在 [ a , b ] [a,b] [a,b] 区间随机均匀地给 r r r 取值,这个例子中 r ∈ [ − 4 , 0 ] r\in[-4,0] r∈[−4,0] ,然后你可以设置 a a a 的值,基于随机取样的超参数 a = 1 0 r a=10^r a=10r 。
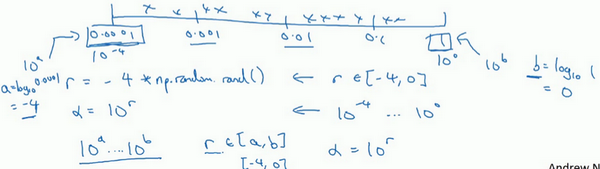
所以总结一下,在对数坐标下取值,取最小值的对数就得到 a a a 的值,取最大值的对数就得到 b b b 值,所以现在你在对数轴上的 1 0 a 10^a 10a 到 1 0 b 10^b 10b 区间取值,在 a , b a,b a,b 间随意均匀的选取 r r r 值,将超参数设置为 1 0 r 10^r 10r ,这就是在对数轴上取值的过程。

最后,另一个棘手的例子是给 β \beta β 取值,用于计算指数的加权平均值。假设你认为 β \beta β 是0.9到0.999之间的某个值,也许这就是你想搜索的范围。记住这一点,当计算指数的加权平均值时,取0.9就像在10个值中计算平均值,有点类似于计算10天的温度平均值,而取0.999就是在1000个值中取平均。
所以和上张幻灯片上的内容类似,如果你想在0.9到0.999区间搜索,那就不能用线性轴取值,对吧?不要随机均匀在此区间取值,所以考虑这个问题最好的方法就是,我们要探究的是 1 − β 1-\beta 1−β ,此值在0.1到0.001区间内,所以我们会给 1 − β 1-\beta 1−β 取值,大概是从0.1到0.001,应用之前幻灯片中介绍的方法,这是 1 0 − 1 10^{-1} 10−1 ,这是 1 0 − 3 10^{-3} 10−3 ,值得注意的是,在之前的幻灯片里,我们把最小值写在左边,最大值写在右边,但在这里,我们颠倒了大小。这里,左边的是最大值,右边的是最小值。所以你要做的就是在 [ − 3 , − 1 ] [-3,-1] [−3,−1] 里随机均匀的给 r r r 取值。你设定了 1 − β = 1 0 r 1-\beta=10^r 1−β=10r ,所以 β = 1 − 1 0 r \beta=1-10^r β=1−10r ,然后这就变成了在特定的选择范围内超参数随机取值。希望用这种方式得到想要的结果,你在0.9到0.99区间探究的资源,和在0.99到0.999区间探究的一样多。

所以,如果你想研究更多正式的数学证明,关于为什么我们要这样做,为什么用线性轴取值不是个好办法,这是因为当 β \beta β 接近1时,所得结果的灵敏度会变化,即使 β \beta β 有微小的变化。所以 β \beta β 在0.9到0.9005之间取值,无关紧要,你的结果几乎不会变化。
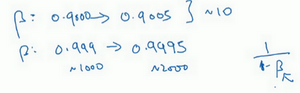
但 β \beta β 值如果在0.999到0.9995之间,这会对你的算法产生巨大影响,对吧?在这两种情况下,是根据大概10个值取平均。但这里,它是指数的加权平均值,基于1000个值,现在是2000个值,因为这个公式 1 1 − β \frac1{1-\beta} 1−β1 ,当 β \beta β 接近1时, β \beta β 就会对细微的变化变得很敏感。所以整个取值过程中,你需要更加密集地取值,在 β \beta β 接近1的区间内,或者说,当 1 − β 1-\beta 1−β 接近于0时,这样,你就可以更加有效的分布取样点,更有效率的探究可能的结果。
希望能帮助你选择合适的标尺,来给超参数取值。如果你没有在超参数选择中作出正确的标尺决定,别担心,即使你在均匀的标尺上取值,如果数值总量较多的话,你也会得到还不错的结果,尤其是应用从粗到细的搜索方法,在之后的迭代中,你还是会聚焦到有用的超参数取值范围上。
希望这会对你的超参数搜索有帮助,下一个视频中,我们将会分享一些关于如何组建搜索过程的思考,希望它能使你的工作更高效。
课程PPT




| ←上一篇 | ↓↑ | 下一篇→ |
|---|---|---|
| 3.1 调试处理 | 回到目录 | 3.3 超参数训练的实践: Pandas vs. Caviar |















 1425
1425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











