









一、Gradio
Gradio 详细介绍
Gradio 是一个用于构建和分享机器学习模型和数据科学应用的开源Python库。它简化了创建交互式Web界面的过程,让开发者可以快速搭建原型并与他人分享。
主要特性
-
易用性:
- 无需前端开发经验:只需几行Python代码就可以创建功能完备的Web界面。
- 即时部署:可以快速本地运行和在线共享。
-
广泛的支持:
- 支持多种输入和输出类型:包括图像、文本、音频、视频、滑动条等。
- 与主流机器学习框架兼容:如TensorFlow、PyTorch、scikit-learn等。
-
自动化:
- 自动生成接口:根据定义的函数自动生成Web界面。
- 实时更新:可以实时查看和测试模型的效果。
-
协作和分享:
- 共享链接:生成的应用可以通过链接分享,方便他人访问和测试。
- 集成到现有的工作流程中:可以与Jupyter Notebook、Google Colab等集成使用。
Gradio的基本使用方法
-
安装Gradio:
pip install gradio -
创建一个简单的Gradio应用:
import gradio as gr def greet(name): return f"Hello {name}!" iface = gr.Interface(fn=greet, inputs="text", outputs="text") iface.launch()gr.Interface:定义了一个简单的接口。fn=greet:指定了处理函数。inputs="text":定义输入组件为文本输入框。outputs="text":定义输出组件为文本输出框。iface.launch():启动Gradio应用。
-
支持多种输入和输出类型:
Gradio支持多种输入和输出组件,如图像、视频、音频、滑动条、复选框等。def classify_image(image): # 假设有一个预训练的分类模型 return "分类结果" iface = gr.Interface(fn=classify_image, inputs=gr.inputs.Image(), outputs="text") iface.launch() -
多个输入和输出:
支持多输入和多输出的情况,可以构建复杂的界面。def process_data(name, age, image): # 假设处理这些输入并返回结果 return f"Name: {name}, Age: {age}", image iface = gr.Interface( fn=process_data, inputs=[gr.inputs.Textbox(label="Name"), gr.inputs.Slider(0, 100, label="Age"), gr.inputs.Image(type="numpy", label="Image")], outputs=["text", "image"] ) iface.launch()
Gradio组件
Gradio提供了多种组件来满足不同的输入输出需求。以下是一些常用的组件:
- 文本输入:
gr.inputs.Textbox - 滑动条:
gr.inputs.Slider - 复选框:
gr.inputs.Checkbox - 图像:
gr.inputs.Image - 音频:
gr.inputs.Audio - 视频:
gr.inputs.Video
每个组件都可以通过不同的参数进行定制,以满足特定的需求。
高级特性
-
自定义CSS和JS:
Gradio允许用户自定义应用的外观和行为,通过添加自定义的CSS和JavaScript文件。 -
集成到现有工作流:
Gradio应用可以嵌入到Jupyter Notebook、Google Colab等环境中,方便与数据科学工作流的无缝集成。 -
共享和部署:
Gradio提供了一键共享功能,可以生成一个临时链接,方便快速分享应用。还可以将应用部署到云端,提供更长时间的访问。 -
错误处理和调试:
提供了详细的错误信息和调试工具,帮助开发者快速定位和解决问题。
二、实例
本文主要使用Gradio库创建了一个Web应用,允许用户上传图像,并使用YOLOv8模型对图像进行目标检测。处理后的图像会显示检测框和标签,并展示检测结果的详细信息。通过简单的Web界面,用户可以轻松地进行图像检测而无需编写复杂的前端代码。
代码实现的具体功能
- 图像上传:用户可以通过Web界面上传图像文件。
- 目标检测:上传的图像被传递给YOLO模型进行目标检测。
- 结果展示:处理后的图像会在Web界面显示,并且显示检测到的目标物体的类别、置信度和位置。
- 交互体验:用户可以实时查看检测结果,并可以继续上传新的图像进行检测。
通过上述代码,用户能够方便地使用YOLOv8模型进行图像目标检测,并通过直观的Web界面查看结果。
下面是代码的流程以及各部分的作用功能:
代码流程和功能
-
引入必要的库:
import gradio as gr import cv2 import numpy as np import os from ultralytics import YOLOgradio:用于创建Web界面的库。cv2:用于图像处理的OpenCV库。numpy:用于处理数组和矩阵的库。os:用于文件和目录操作。ultralytics.YOLO:用于加载和使用YOLOv8模型。
-
设置上传和结果文件夹:
UPLOAD_FOLDER = 'uploads' RESULT_FOLDER = 'results' os.makedirs(UPLOAD_FOLDER, exist_ok=True) os.makedirs(RESULT_FOLDER, exist_ok=True)UPLOAD_FOLDER和RESULT_FOLDER:定义上传文件和处理结果的保存目录。os.makedirs:创建目录(如果目录不存在)。
-
加载YOLO模型:
model = YOLO('yolov8n.pt')model:加载YOLOv8模型,用于后续的图像检测。
-
定义图像处理函数:
def process_image(image): # 保存上传的图像 filename = 'uploaded_image.jpg' file_path = os.path.join(UPLOAD_FOLDER, filename) cv2.imwrite(file_path, image) # 处理图像 results = model(image) detection_results = [] for result in results: boxes = result.boxes for box in boxes: x1, y1, x2, y2 = box.xyxy[0] conf = box.conf[0] cls = box.cls[0] cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2) cv2.putText(image, f'{cls}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36, 255, 12), 2) detection_results.append(f'Class: {cls}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})') # 保存处理后的图像 result_filename = 'result_image.jpg' result_path = os.path.join(RESULT_FOLDER, result_filename) cv2.imwrite(result_path, image) return image, '\n'.join(detection_results)process_image函数:处理上传的图像,使用YOLO模型进行检测,绘制检测框和标签,并返回处理后的图像和检测结果文本。- 保存上传的图像到指定目录。
- 使用YOLO模型对图像进行检测。
- 绘制检测框和标签,并保存处理后的图像。
- 返回处理后的图像和检测结果文本。
-
创建Gradio界面:
iface = gr.Interface( fn=process_image, inputs=gr.Image(type="numpy", label="上传图像"), outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")], title="YOLOv8 图像检测", description="上传图像并使用YOLOv8模型进行检测" )gr.Interface:定义Gradio界面的主要组件。fn=process_image:指定处理函数为process_image。inputs=gr.Image(type="numpy", label="上传图像"):定义图像上传输入组件。outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")]:定义处理后的图像输出和检测结果文本输出组件。title和description:设置界面的标题和描述。
完整代码如下:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
# 加载模型
model = YOLO('yolov8n.pt')
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{cls}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,
(36, 255, 12), 2)
detection_results.append(f'Class: {cls}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
# 创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
# 启动Gradio应用
iface.launch()
运行,复制下面链接:
界面如下:
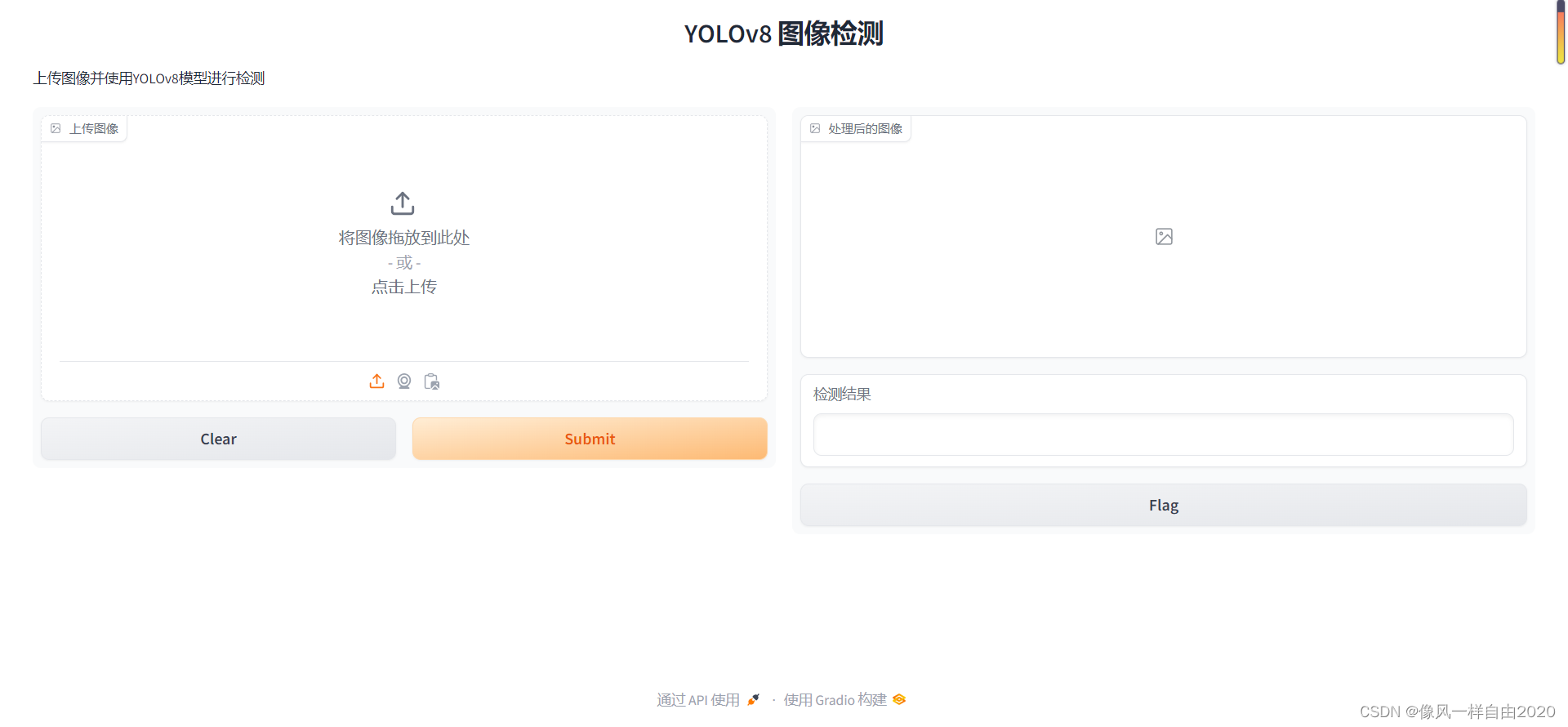
选择图片检测结果如下:
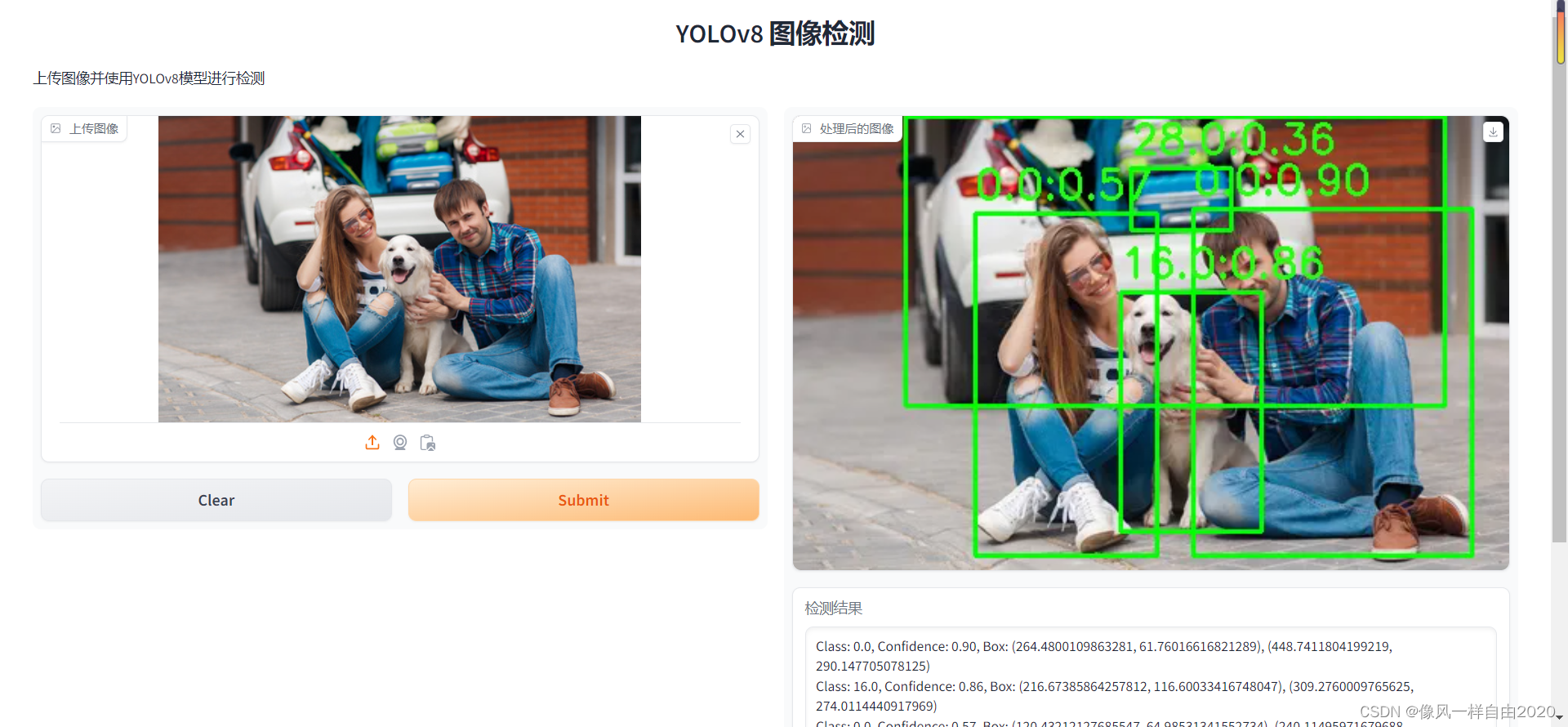
三、实现公网URL访问
上述代码默认情况下是只能在本地访问的。Gradio应用在默认情况下会在本地启动一个服务器,并提供一个本地URL(通常是 http://127.0.0.1:7860)用于访问。
如果你希望使这个应用可以通过互联网访问,可以在调用 launch 方法时添加参数 share=True。这将使Gradio为你生成一个临时的公网URL,其他人也可以通过这个URL访问你的应用。修改后的代码如下:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
# 加载模型
model = YOLO('yolov8n.pt')
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
class_counts = {}
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
class_name = model.names[int(cls)]
# 计算每种类别的数量
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 绘制边界框和标签
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{class_name}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,
(36, 255, 12), 2)
detection_results.append(f'Class: {class_name}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 在图像上显示检测到的物体数量信息
y_offset = 30
for class_name, count in class_counts.items():
cv2.putText(image, f'{class_name}: {count}', (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
y_offset += 30
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
# 创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
# 启动Gradio应用
iface.launch(share=True)
# 启动Gradio应用
iface.launch(share=True)
添加 share=True 参数
iface.launch(share=True)
通过设置 share=True,Gradio将生成一个公网URL,使得应用可以通过互联网访问,这个URL通常会出现在启动Gradio应用时的控制台输出中。
运行结果如下:选择第2个公网访问。

检测结果:
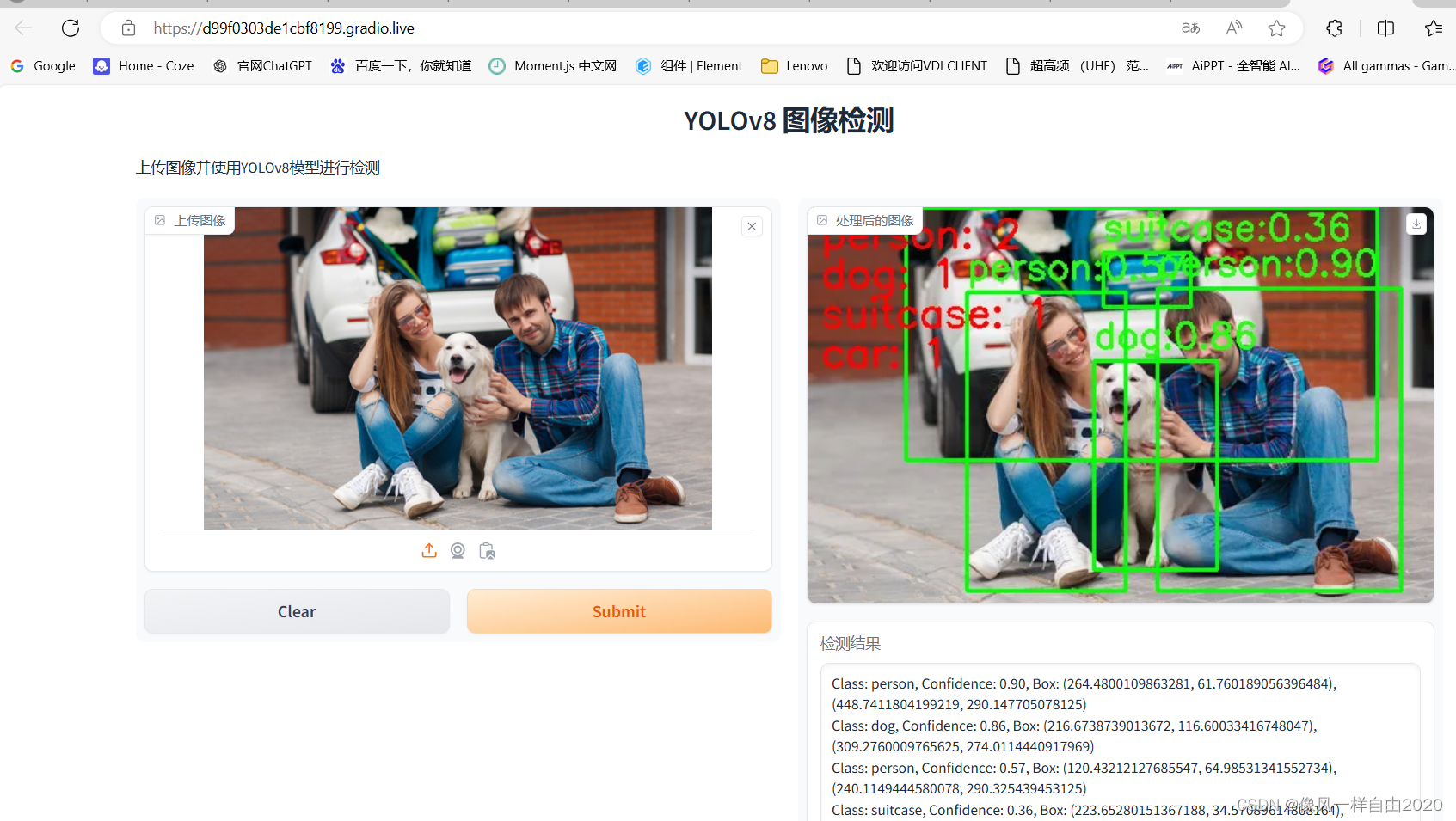
注意事项
- 安全性:公开你的应用意味着任何人都可以访问它,确保处理敏感数据时注意安全问题。
- 性能:共享的公网URL是通过Gradio的服务器进行中继的,因此性能和响应速度可能会受到一定的影响。如果需要长期稳定的公网访问,建议考虑部署到一个云服务器上。
- 临时性:Gradio生成的共享URL是临时的,重启应用后会生成新的URL。
Gradio的launch方法可以接受多个参数,用于定制共享链接和服务器设置。以下是一些常用的参数及其说明:
-
share:bool- 如果设置为
True,则Gradio会生成一个可以共享的公共链接。默认为False。
- 如果设置为
-
server_name:str- 设置服务器的主机名。如果希望在本地网络中访问,可以设置为
"0.0.0.0"。
- 设置服务器的主机名。如果希望在本地网络中访问,可以设置为
-
server_port:int- 设置服务器的端口号。如果不设置,将随机选择一个可用的端口。
-
debug:bool- 如果设置为
True,则启用调试模式,会显示详细的错误信息。默认为False。
- 如果设置为
-
auth:Tuple[str, str]- 设置基本认证,格式为
("username", "password"),可以保护界面不被未经授权的用户访问。
- 设置基本认证,格式为
-
auth_message:str- 自定义的认证消息,当使用基本认证时,未授权用户将看到该消息。
-
inbrowser:bool- 如果设置为
True,则在服务器启动后自动在默认浏览器中打开界面。默认为False。
- 如果设置为
-
prevent_thread_lock:bool- 如果设置为
True,则允许主线程继续运行而不会被Gradio界面锁住。默认为False。
- 如果设置为
-
height:int- 设置iframe的高度,如果在notebook中使用Gradio。默认为
None。
- 设置iframe的高度,如果在notebook中使用Gradio。默认为
-
width:int- 设置iframe的宽度,如果在notebook中使用Gradio。默认为
None。
- 设置iframe的宽度,如果在notebook中使用Gradio。默认为
-
ssl_keyfile:str- 设置SSL密钥文件的路径,用于启用HTTPS。
-
ssl_certfile:str- 设置SSL证书文件的路径,用于启用HTTPS。
-
ssl_keyfile_password:str- 设置SSL密钥文件的密码。
示例代码:
iface.launch(
share=True,
server_name="0.0.0.0",
server_port=7860,
debug=True,
auth=("username", "password"),
auth_message="Please enter your credentials to access the app.",
inbrowser=True
)
这个例子中,Gradio应用将:
- 生成一个可以共享的公共链接。
- 在本地网络中开放访问。
- 使用端口7860。
- 启用调试模式。
- 要求用户输入用户名和密码。
- 自定义认证消息。
- 在服务器启动后自动在默认浏览器中打开。
在上面代码基础上增加这些参数。
以下是修改后的代码示例,包含了多种常见的参数设置:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
# 加载模型
model = YOLO('yolov8n.pt')
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
class_counts = {}
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
class_name = model.names[int(cls)]
# 计算每种类别的数量
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 绘制边界框和标签
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{class_name}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,
(36, 255, 12), 2)
detection_results.append(f'Class: {class_name}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 在图像上显示检测到的物体数量信息
y_offset = 30
for class_name, count in class_counts.items():
cv2.putText(image, f'{class_name}: {count}', (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
y_offset += 30
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
# 创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
# 启动Gradio应用
iface.launch(
share=True,
server_name="0.0.0.0",
server_port=7860,
debug=True,
#auth=("username", "password"),
auth=("test", "12345"),
auth_message="Please enter your credentials to access the app.",
inbrowser=True
)
在这里添加的参数说明:
share=True:生成一个可以共享的公共链接。server_name="0.0.0.0":在本地网络中开放访问。server_port=7860:使用端口7860。debug=True:启用调试模式。auth=("username", "password"):设置基本认证,保护界面不被未经授权的用户访问。auth_message="Please enter your credentials to access the app.":自定义的认证消息。inbrowser=True:在服务器启动后自动在默认浏览器中打开界面。
运行程序,结果如下所示:

可以发现这个共享链接将在72小时后过期。要获得免费的永久主机和GPU升级,请从终端运行“gradio deploy”以部署到空间(https://huggingface.co/spaces)
运行后自动启动默认浏览器界面如下:
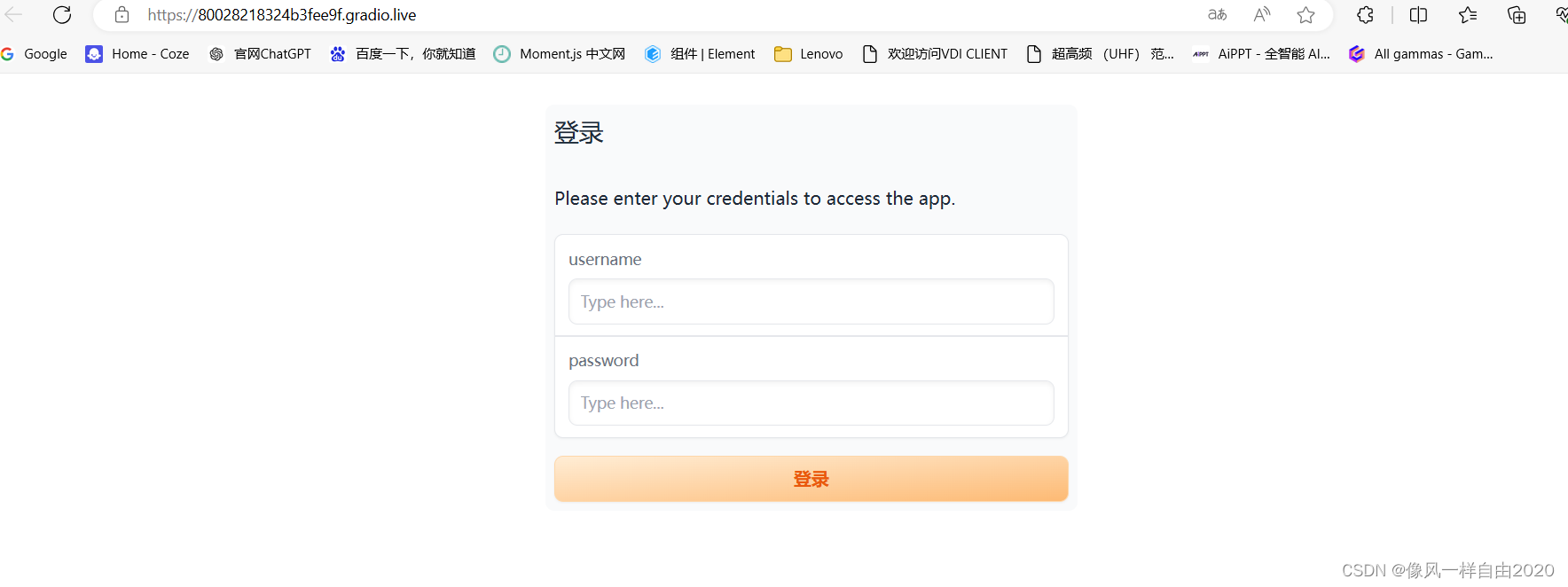
然后输入用户名和密码,我这里设置用户名为“test”,密码为"12345"
输入后点击登录,进入使用界面:

部署指定的服务器地址与端口
如果你想将Gradio应用部署到指定的服务器地址和端口,可以通过设置server_name和server_port来实现。这些参数可以在launch方法中指定。假设你有一个服务器,其IP地址为192.168.1.100,你希望使用端口8080来部署你的应用,下面是修改后的代码:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
# 加载模型
model = YOLO('yolov8n.pt')
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
class_counts = {}
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
class_name = model.names[int(cls)]
# 计算每种类别的数量
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 绘制边界框和标签
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{class_name}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,
(36, 255, 12), 2)
detection_results.append(f'Class: {class_name}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 在图像上显示检测到的物体数量信息
y_offset = 30
for class_name, count in class_counts.items():
cv2.putText(image, f'{class_name}: {count}', (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
y_offset += 30
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
# 创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
# 启动Gradio应用
iface.launch(
server_name="192.168.1.100", # 你的服务器IP地址
server_port=8080, # 你希望使用的端口
debug=True, # 可选:启用调试模式
auth=("username", "password"),# 可选:设置基本认证
auth_message="Please enter your credentials to access the app.", # 可选:自定义认证消息
inbrowser=False # 可选:是否在服务器启动后自动打开浏览器
)
上述代码将在指定的服务器地址192.168.1.100和端口8080上部署Gradio应用。根据需要,你可以调整auth和auth_message参数,以保护你的应用不被未经授权的用户访问。参数inbrowser设置为False,因为通常在服务器环境下,不需要自动打开浏览器。
四、Flask与Gradio集成
下面代码展示了如何将一个基于YOLOv8模型的图像检测Gradio应用嵌入到Flask Web应用中。具体来说,它结合了Gradio用于创建交互式Web应用的简单性和Flask用于创建Web服务器的灵活性。下面是对代码流程的详细解释:
导入所需的库
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
from flask import Flask, request, render_template_string
gradio: 用于创建交互式Web应用。cv2: 用于图像处理。numpy: 用于处理图像数据。os: 用于文件和目录操作。YOLO: 用于加载和使用YOLOv8模型。Flask: 用于创建Web服务器和处理HTTP请求。
设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
UPLOAD_FOLDER和RESULT_FOLDER分别用于存储上传的图像和处理后的图像。os.makedirs()确保这些文件夹存在,如果不存在则创建。
加载YOLOv8模型
model = YOLO('yolov8n.pt')
- 加载YOLOv8的预训练模型
yolov8n.pt。
定义图像处理函数
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
class_counts = {}
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
class_name = model.names[int(cls)]
# 计算每种类别的数量
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 绘制边界框和标签
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{class_name}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36, 255, 12), 2)
detection_results.append(f'Class: {class_name}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 在图像上显示检测到的物体数量信息
y_offset = 30
for class_name, count in class_counts.items():
cv2.putText(image, f'{class_name}: {count}', (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
y_offset += 30
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
- 该函数接收图像作为输入,使用YOLOv8模型进行处理,绘制检测到的物体边界框和标签,并返回处理后的图像和检测结果。
创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
- 使用Gradio创建一个界面,用于图像上传和显示检测结果。
启动Gradio应用
gradio_port = 7860
gradio_url = f"http://127.0.0.1:{gradio_port}"
iface.launch(
share=True,
server_name="127.0.0.1",
server_port=gradio_port,
debug=True,
auth=("test", "12345"),
auth_message="Please enter your credentials to access the app.",
inbrowser=False,
prevent_thread_lock=True
)
- 启动Gradio应用在本地端口
7860,设置基本身份验证,并防止线程锁定。
定义Flask根路由
@app.route('/')
def home():
return render_template_string(f'''
<!doctype html>
<html>
<head>
<title>Flask-Gradio Integration</title>
</head>
<body>
<h1>YOLOv8 图像检测</h1>
<iframe src="{gradio_url}" width="100%" height="800px"></iframe>
</body>
</html>
''')
- 根路径
/返回一个HTML页面,页面通过<iframe>标签嵌入Gradio界面。
启动Flask应用
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
- 启动Flask应用,监听所有网络接口,使用端口
8080。
结果
- 运行
app.py后,访问http://<你的服务器IP>:8080即可在Flask页面中嵌入的iframe中访问Gradio应用,实现图像上传和检测功能。
这段代码的目的是将一个基于YOLOv8模型的图像检测Gradio应用嵌入到一个Flask Web应用中,通过一个单一的Web服务器提供Gradio和Flask的功能。这种整合可以利用Gradio创建交互式用户界面和Flask创建Web服务器的优点,从而实现以下目标:
- 图像上传和处理:用户可以通过Web界面上传图像,使用YOLOv8模型对图像进行物体检测,并显示检测结果。
- 提供交互式Web应用:利用Gradio创建用户友好的图像上传和结果显示界面。
- 通过Flask托管Web应用:使用Flask创建Web服务器,托管Gradio应用,使其能够通过指定的IP地址和端口访问。
具体功能和流程
-
设置和加载:
- 创建上传和结果文件夹,用于存储用户上传的图像和处理后的图像。
- 加载YOLOv8模型,用于图像检测。
-
图像处理函数:
process_image(image):接收图像作为输入,使用YOLOv8模型进行处理,绘制检测到的物体边界框和标签,返回处理后的图像和检测结果。- 保存上传的图像和处理后的图像,计算每种物体类别的数量,并在图像上绘制检测结果。
-
创建Gradio界面:
- 使用Gradio创建一个图像上传和显示检测结果的交互界面。
- 设置输入为图像,输出为处理后的图像和检测结果文本。
-
启动Gradio应用:
- 启动Gradio应用在本地的指定端口(7860),并启用基本身份验证,防止未授权访问。
-
定义Flask根路由:
- 创建一个Flask应用,并定义根路径
/的路由。 - 返回一个HTML页面,通过
<iframe>标签嵌入Gradio应用的界面,使其成为Flask应用的一部分。
- 创建一个Flask应用,并定义根路径
-
启动Flask应用:
- 启动Flask服务器,监听所有网络接口,使用端口8080,使应用可以通过
http://<你的服务器IP>:8080访问。
- 启动Flask服务器,监听所有网络接口,使用端口8080,使应用可以通过
运行后的结果
- 启动
app.py后,Flask服务器开始运行,并在指定的IP地址和端口上提供服务。 - 访问
http://<你的服务器IP>:8080可以看到一个网页,其中嵌入了Gradio界面。 - 用户可以在该网页上上传图像,YOLOv8模型会对图像进行物体检测,并在网页上显示检测结果。
优点
- 易用性:利用Gradio创建交互界面,使用户能够方便地上传图像并查看检测结果。
- 灵活性:利用Flask托管Web应用,使其能够在指定的IP地址和端口上运行,并支持基本身份验证。
- 整合性:将Gradio和Flask结合在一起,使得创建和托管Web应用更加简便和一致。
完整代码如下:
import gradio as gr
import cv2
import numpy as np
import os
from ultralytics import YOLO
from flask import Flask, request, render_template_string
app = Flask(__name__)
# 设置上传和结果文件夹
UPLOAD_FOLDER = 'uploads'
RESULT_FOLDER = 'results'
os.makedirs(UPLOAD_FOLDER, exist_ok=True)
os.makedirs(RESULT_FOLDER, exist_ok=True)
# 加载模型
model = YOLO('yolov8n.pt')
def process_image(image):
# 保存上传的图像
filename = 'uploaded_image.jpg'
file_path = os.path.join(UPLOAD_FOLDER, filename)
cv2.imwrite(file_path, image)
# 处理图像
results = model(image)
detection_results = []
class_counts = {}
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
class_name = model.names[int(cls)]
# 计算每种类别的数量
if class_name in class_counts:
class_counts[class_name] += 1
else:
class_counts[class_name] = 1
# 绘制边界框和标签
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f'{class_name}:{conf:.2f}', (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9,
(36, 255, 12), 2)
detection_results.append(f'Class: {class_name}, Confidence: {conf:.2f}, Box: ({x1}, {y1}), ({x2}, {y2})')
# 在图像上显示检测到的物体数量信息
y_offset = 30
for class_name, count in class_counts.items():
cv2.putText(image, f'{class_name}: {count}', (10, y_offset), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
y_offset += 30
# 保存处理后的图像
result_filename = 'result_image.jpg'
result_path = os.path.join(RESULT_FOLDER, result_filename)
cv2.imwrite(result_path, image)
return image, '\n'.join(detection_results)
# 创建Gradio界面
iface = gr.Interface(
fn=process_image,
inputs=gr.Image(type="numpy", label="上传图像"),
outputs=[gr.Image(type="numpy", label="处理后的图像"), gr.Textbox(label="检测结果")],
title="YOLOv8 图像检测",
description="上传图像并使用YOLOv8模型进行检测"
)
# 启动Gradio应用
gradio_port = 7860
gradio_url = f"http://127.0.0.1:{gradio_port}"
iface.launch(
share=True,
server_name="127.0.0.1",
server_port=gradio_port,
debug=True,
auth=("test", "123456"),
auth_message="Please enter your credentials to access the app.",
inbrowser=False,
prevent_thread_lock=True
)
@app.route('/')
def home():
return render_template_string(f'''
<!doctype html>
<html>
<head>
<title>Flask-Gradio Integration</title>
</head>
<body>
<h1>YOLOv8 图像检测</h1>
<iframe src="{gradio_url}" width="100%" height="800px"></iframe>
</body>
</html>
''')
# 启动Flask应用
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)
总结
这段代码示例展示了如何利用Gradio和Flask创建和托管一个基于YOLOv8的图像检测Web应用,结合了Gradio的用户界面和Flask的Web服务器功能,实现了图像上传、处理和结果显示的完整工作流程。
参考资料:非常优秀的一个开源库Gradio,几行代码完成部署快速搭建AI算法可视化部署演示,直接启动零配置实现微信分享、公网分享、内网穿透,包含项目搭建和案例分享
番外:YOLOv8模型转onnx格式并使用onnxruntime 进行推理部署
#coding:utf-8
import argparse
import cv2
import numpy as np
import onnxruntime as ort
import torch
from ultralytics.utils import ASSETS, yaml_load
from ultralytics.utils.checks import check_requirements, check_yaml
from ultralytics import YOLO
# 导出onnx模型
model = YOLO("yolov8n.pt")
model.export(format="onnx")
class YOLOv8:
"""YOLOv8目标检测模型类,用于处理推理和可视化操作。"""
def __init__(self, onnx_model, input_image, confidence_thres, iou_thres):
"""
初始化YOLOv8类的实例。
参数:
onnx_model: ONNX模型的路径。
input_image: 输入图像的路径。
confidence_thres: 过滤检测的置信度阈值。
iou_thres: 非极大抑制的IoU(交并比)阈值。
"""
self.onnx_model = onnx_model
self.input_image = input_image
self.confidence_thres = confidence_thres
self.iou_thres = iou_thres
# 从COCO数据集的配置文件加载类别名称
self.classes = yaml_load(check_yaml("coco8.yaml"))["names"]
# 字典存储类别名称
print(self.classes)
# {0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane'...}
# 为类别生成颜色调色板
self.color_palette = np.random.uniform(0, 255, size=(len(self.classes), 3))
# 初始化ONNX会话
self.initialize_session(self.onnx_model)
def draw_detections(self, img, box, score, class_id):
"""
根据检测到的对象在输入图像上绘制边界框和标签。
参数:
img: 要绘制检测的输入图像。
box: 检测到的边界框。
score: 对应的检测得分。
class_id: 检测到的对象的类别ID。
返回:
None
"""
# 提取边界框的坐标
x1, y1, w, h = box
# 获取类别ID对应的颜色
color = self.color_palette[class_id]
# 在图像上绘制边界框
cv2.rectangle(img, (int(x1), int(y1)), (int(x1 + w), int(y1 + h)), color, 2)
# 创建包含类名和得分的标签文本
label = f"{self.classes[class_id]}: {score:.2f}"
# 计算标签文本的尺寸
(label_width, label_height), _ = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
# 计算标签文本的位置
label_x = x1
label_y = y1 - 10 if y1 - 10 > label_height else y1 + 10
# 绘制填充的矩形作为标签文本的背景
cv2.rectangle(
img, (label_x, label_y - label_height), (label_x + label_width, label_y + label_height), color, cv2.FILLED
)
# 在图像上绘制标签文本
cv2.putText(img, label, (label_x, label_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0), 1, cv2.LINE_AA)
def preprocess(self):
"""
在进行推理之前,对输入图像进行预处理。
返回:
image_data: 预处理后的图像数据,准备好进行推理。
"""
# 使用OpenCV读取输入图像(h,w,c)
self.img = cv2.imread(self.input_image)
# 获取输入图像的高度和宽度
self.img_height, self.img_width = self.img.shape[:2]
# 将图像颜色空间从BGR转换为RGB
img = cv2.cvtColor(self.img, cv2.COLOR_BGR2RGB)
# 将图像调整为匹配输入形状(640,640,3)
img = cv2.resize(img, (self.input_width, self.input_height))
# 将图像数据除以255.0进行归一化
image_data = np.array(img) / 255.0
# 转置图像,使通道维度成为第一个维度(3,640,640)
image_data = np.transpose(image_data, (2, 0, 1)) # 通道优先
# 扩展图像数据的维度以匹配期望的输入形状(1,3,640,640)
image_data = np.expand_dims(image_data, axis=0).astype(np.float32)
# 返回预处理后的图像数据
return image_data
def postprocess(self, input_image, output):
"""
对模型的输出进行后处理,以提取边界框、分数和类别ID。
参数:
input_image (numpy.ndarray): 输入图像。
output (numpy.ndarray): 模型的输出。
返回:
numpy.ndarray: 输入图像,上面绘制了检测结果。
"""
# 转置并压缩输出以匹配期望的形状:(8400, 84)
outputs = np.transpose(np.squeeze(output[0]))
# 获取输出数组的行数
rows = outputs.shape[0]
# 存储检测到的边界框、分数和类别ID的列表
boxes = []
scores = []
class_ids = []
# 计算边界框坐标的比例因子
x_factor = self.img_width / self.input_width
y_factor = self.img_height / self.input_height
# 遍历输出数组的每一行
for i in range(rows):
# 从当前行提取类别的得分
classes_scores = outputs[i][4:]
# 找到类别得分中的最大值
max_score = np.amax(classes_scores)
# 如果最大得分大于或等于置信度阈值
if max_score >= self.confidence_thres:
# 获取得分最高的类别ID
class_id = np.argmax(classes_scores)
# 从当前行提取边界框坐标
x, y, w, h = outputs[i][0], outputs[i][1], outputs[i][2], outputs[i][3]
# 计算边界框的缩放坐标
left = int((x - w / 2) * x_factor)
top = int((y - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
# 将类别ID、得分和边界框坐标添加到相应的列表中
class_ids.append(class_id)
scores.append(max_score)
boxes.append([left, top, width, height])
# 应用非极大抑制以过滤重叠的边界框
indices = cv2.dnn.NMSBoxes(boxes, scores, self.confidence_thres, self.iou_thres)
# 遍历非极大抑制后选择的索引
for i in indices:
# 获取与索引对应的边界框、得分和类别ID
box = boxes[i]
score = scores[i]
class_id = class_ids[i]
# 在输入图像上绘制检测结果
self.draw_detections(input_image, box, score, class_id)
# 返回修改后的输入图像
return input_image
def initialize_session(self, onnx_model):
"""
初始化ONNX模型会话。
:return:
"""
if torch.cuda.is_available():
print("Using CUDA")
providers = ["CUDAExecutionProvider"]
else:
print("Using CPU")
providers = ["CPUExecutionProvider"]
session_options = ort.SessionOptions()
session_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# 使用ONNX模型创建推理会话,并指定执行提供者
self.session = ort.InferenceSession(onnx_model,
session_options=session_options,
providers=providers)
return self.session
def main(self):
"""
使用ONNX模型进行推理,并返回带有检测结果的输出图像。
返回:
output_img: 带有检测结果的输出图像。
"""
# 获取模型的输入
model_inputs = self.session.get_inputs()
# 保存输入的形状,稍后使用
# input_shape:(1,3,640,640)
# self.input_width:640,self.input_height:640
input_shape = model_inputs[0].shape
self.input_width = input_shape[2]
self.input_height = input_shape[3]
# 对图像数据进行预处理
img_data = self.preprocess()
# 使用预处理后的图像数据运行推理,outputs:(1,84,8400) 8400 = 80*80 + 40*40 + 20*20
outputs = self.session.run(None, {model_inputs[0].name: img_data})
# 对输出进行后处理以获取输出图像
return self.postprocess(self.img, outputs) # 输出图像
if __name__ == "__main__":
onnx_model_name = "yolov8n.onnx"
img_path = "car_test.png"
# 创建用于处理命令行参数的解析器
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, default=onnx_model_name, help="请输入您的ONNX模型路径.")
parser.add_argument("--img", type=str, default=img_path, help="输入图像的路径.")
parser.add_argument("--conf-thres", type=float, default=0.2, help="置信度阈值.")
parser.add_argument("--iou-thres", type=float, default=0.5, help="IoU(交并比)阈值.")
args = parser.parse_args()
# 创建YOLOv8实例
detection = YOLOv8(args.model, args.img, args.conf_thres, args.iou_thres)
# 模型推理
output_image = detection.main()
cv2.namedWindow("Output", cv2.WINDOW_NORMAL)
cv2.imshow("Output", output_image)
cv2.imwrite('Output.jpg', output_image)
cv2.waitKey(0)
cv2.destroyAllWindows()















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









