









一、基本概念
将视觉输入分为不同的语义可解释类别;通俗点说就是区分不同部分。

分类:
b)语义分割 c)实例分割 d)全景分割

语义分割一般以平均IOU(Intersection Over Union,并交比)来评价性能,其公式如下:
目的是使得目标与预测尽可能交叠。
除此之外还有可以选择像素正确率:PA=正确像素之和 / 总像素之和
像素正确率平均值:MPA=1 / (k+1)*PA
一般而言语义分割分为以下流程。
输入-->分类器-->后处理-->最终结果
二、DeeplabV3+模型
①网络结构

!DeeplabV3+在编码器部分引入了大量空洞卷积;可以在不损失信息的情况下增大感受野(提升每个卷积输出包含的信息量)
②BackBone
原文采用的主干网络为Xceprion,如算力不足也可用MobileNetV2作为主干网络。
MobileNetV2由Inverted resblock组成,其网络结构如下:

分为左半边的主干部分和右半边的残差部分。主干部分的组成及其作用:
1x1卷积核:升维
3x3卷积核:特征提取
1x1卷积核:降维
!!!一般DeepLabV3中会进行3次或4次下采样(但不会是5次)
使用BackBone提取后会得到两个有效特征层:压缩2次的结果和压缩4次的结果
③加强特征提取结构
可分为两部分:Encoder和Decoder。
| Encoder | 对压缩4次的有效特征层 分别用不同rate的空洞卷积 进行特征提取,合并,再通过1x1卷积进行压缩
|
| Decoder | 对压缩2次的有效特征层 利用1x1卷积调整通道数,再和空洞卷积后的有效特征层上采样的结果进行堆叠,随后进行两次深度可分离卷积块。
|
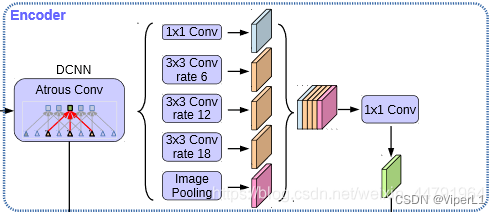

④利用特征预测结果
可以分为2步:
1.利用1x1卷积进行通道调整,调整成Num_Class
2.利用resize进行上采样,最终得到和输入图片长宽一致的输出层。(放大)
特别鸣谢Bubbliiiing,大家也可以去看他的原文DeepLabV3+















 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









